2020李宏毅机器学习笔记-More about Auto-encoder
目录
摘要
1. More about Auto-Encoder
1.1 What is good embedding
1.2 Beyond Reconstruction:Discriminator
2. Sequential Data
2.1 Skip thought
2.2 Quick thought
2.3 Contrastive Predictive Coding(CPC)
3. Feature Disentangle(特征解耦)
3.1 Feature Disentangle
3.2 Feature Disentangle- Voice Conversion
3.3 How Feature Disentangle?
3.3.1 使用GAN对抗的思想
3.3.2 改变网络结构
4. Discrete Representation(离散表示)
4.1 one-hot
4.2 VQVAE
4.3 Sequence as Embedding
结论与展望
摘要
回顾上节讲过的encoder的output一个向量,我们叫做embedding,在训练的时候,要最小化重构误差,让encoder的输入和decoder的输出越接近越好。今天要讲两个内容:为什么是最小化重构误差,有没有其他做法以及让encoder的向量更有解释性。
具体来说,对于数据是有顺序的,除了训练一个auto-encoder,输入自己预测自己之外,还可以训练一个model,它是输入一个句子,预测前一个句子跟下一个句子,这个方法叫做skip thought,和其改进的方法quick thought以及CPC。本节最后讲的是为了使Embedding具有更好的可解释性,使用的两大类方法Feature Disentangle和Discrete Representation。
1. More about Auto-Encoder

Auto-encoder是一个基本的生成模型,更重要的是它提供了一种encoder-decoder的框架思想,广泛的应用在了许多模型架构中。简单来说,Auto-encoder可以看作是如下的结构,它主要包含一个编码器(Encoder)和一个解码器(Decoder),通常它们使用的都是神经网络。Encoder接收一张图像(或是其他类型的数据,这里以图像为例)输出一个vector,它也可称为Embedding、Latent Representation或Latent code,不管它叫什么,我们只需要知道它是关于输入图像的表示;然后将vector输入到Decoder中就可以得到重建后的图像,希望它和输入图像越接近越好,即最小化重建误差(reconstruction error),误差项通常使用的平方误差。
1.1 What is good embedding

之前要做embedding的根本原因是:An embedding should represent the object.虽然我们希望Decoder输出的重建图像和输入到Encoder中的图像越接近越好,但是通常我们并不关注重建后的图像是什么样的,更多的希望得到一个关于输入图像有意义、解释性强的embedding。
如何评价一个embedding是否是好的呢?最直观的想法是它应该包含了关于输入的关键信息,从中我们就可以大致知道输入是什么样的。或是从流形学习的角度来看,希望它可以学到关于高维输入数据的低维嵌入。比如当我们看到蓝色耳机时,我们想到的是三九,而不应是一花,那么蓝色耳机对于三九就是一个好的embedding,对于一花来说就不是一个好的embedding。
1.2 Beyond Reconstruction:Discriminator

除了使用重建误差来驱动模型训练外,可以使用其他的方式来衡量Encoder是否学到了关于输入的重要表征吗?答案自然是YES!假设我们现在有两类动漫人物的图像,一类是三玖,一类是凉宫春日。如果将三玖的图像丢给Encoder后,它就会给出一个蓝色的Embedding;如果Encoder接收的是凉宫春日的图像,它就会给出一个黄色的Embedding。那么除了Encoder之外,还有一个Discriminator(这里可以就看作一个二分类的Classifier),它接收图像和Embedding,然后给出一个结果表示它们是否是两两对应的。
希望通过训练最小化D的损失函数,loss of the classification task is 输出与标签的交叉熵。

- 如果LD 的值比较小,就认为Encoder得到的Embedding很有代表性
- 相反如何LD的值很大时,就认为得到的Embedding不具有代表性

既然我们知道如何来评估向量表示的好和不好,我们就是要调整encoder的参数 θ,然后用评估方法(根据L∗D 来评估)来让生成向量最优。
也就是说我们要训练encoder的参数θ \thetaθ和discriminator的参数ϕ ,使得LD最小化。
这个东西实际可以类比到最原始的auto-encoder模型要同时训练encoder和decoder使得reconstruction error最小。也就是说auto-encoder模型:

我们现在知道,auto-encoder跟刚才所说的,同使训练encoder和binary classifer一样,只是可以将auto-encoder视为一个特别情况。
如上图所示,刚才我们所说的discriminator是同时将image与embedding做为输入,但如果先将embedding做为input,得到的结果再跟image相减,那它就是一个reconstruction error了。
2. Sequential Data
除了图像数据外,我们也可以在序列数据上使用Encoder-Decoder的结构模型。
2.1 Skip thought
模型在大量的文档数据上训练结束后,Encoder接收一个句子,然后给出输入句子的上一句和下一句是什么。

这个模型训练过程和训练word embedding很像,因为训练word embedding的时候有这么一个原则,就是两个词的上下文很像的时候,这两个词的embedding就会很接近。换到句子的模型上,如果两个句子的上下文很像,那么这两个句子的embedding就应该很接近。
例如:
发现答案一样,所以问句的embedding是很接近的。
2.2 Quick thought
而Quick thought是对于Skip thought的改进版本,它不使用Decoder,而是使用一个辅助的分类器。它将当前的句子、当前句子的下一句和一些随机采样得到的句子分别送到Encoder中得到对应的Embedding,然后将它们丢给分类器。因为当前的句子的Embedding和它下一句的Embedding应该是越接近越好,而它和随机采样句子的Embedding应该差别越大越好,因此分类器应该可以根据Embedding判断出哪一个代表的是当前句子的下一句。

模型中的classifier吃当前句子(Spring had come.)的向量表示,还吃下一句(And yet his crops didn’t grow.)和其它几个随机生成的句子的向量表示,这个classifier可以输出正确的下一句。
classifier和encoder是一起训练的。
实作上classifier做的事情很简单,就是直接拿当前句子的向量表示和所有句子的向量表示做内积,看谁的内积最大,谁就是下一个句子。这里为了防止机器作弊,直接把输入作为下一句(这样内积最大),还要附加条件:使得当前句的向量表示和随机句子的向量表示越不像越好。
2.3 Contrastive Predictive Coding(CPC)
这个模型和Quick thought的思想是一样的,不过是用在声音信号上的。它称为Contrastive Predictive Coding (CPC)的技术,它同样接收一段序列数据,然后给出它的接下来数据的预测结果。模型结构如下所示:

3. Feature Disentangle(特征解耦)
3.1 Feature Disentangle
接下来我们来看如何得到解释性更好的Embedding,这样的方法也可以称为Feature Disentangle(特征结构)。因为对于Encoder的输入数据来说,经过Encoder得到的Embedding其实包含了关于它的很多类型的信息。例如,如果现在输入的是一段声音讯号,那么Embedding可能包含内容信息、讲话者的信息……
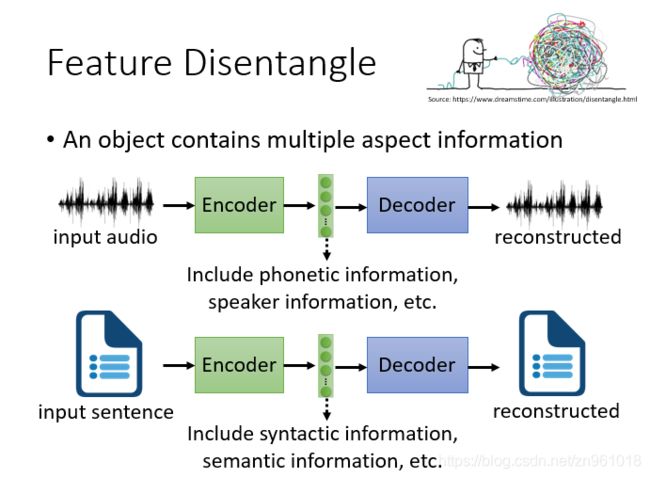
如果输入的是一段文字,Embedding可能包含关于它的句法信息、语义信息……
我们希望计算机告诉我们各个维度的embedding代表的关系。我们以声音讯号为例,假设通过Encoder得到的Embedding是一个100维 的向量,它只包含内容和讲话者身份两种信息。我们希望经过不断的训练,它的前50维代表内容信息,后50维代表讲话者的身份信息。

举例来说,我们希望输入一段声音讯号,而输出的假设是一个200维的向量,前100维是语音信息(语意内容的资讯),而后100维则是语者信息(说话那个人的资讯)。这样训练出来的语音Encoder可以处理与人无关的语音,直接提取出语音特征;训练出来的语者Encoder可以用来做为识别语者身份的声纹特征。
又或者,我们可以有两个Encoder,一个负责处理语意内容,一个负责处理说话人的资讯,两个输出再合并给Decoder来做reconstructed。
3.2 Feature Disentangle- Voice Conversion

人和说话的内容是放在同一个向量里面的。

然后把女生说话的内容,和男生说话的特点合起来,就变成了男生在说How are you?

3.3 How Feature Disentangle?
3.3.1 使用GAN对抗的思想
一种方法就是使用GAN对抗的思想,我们在一般的Encoder-Decoder架构中引入一个Classifier,判别Embedding某个具体的部分是否代表了讲话者身份的信息,通过不断地训练,希望Encoder得到的Embedding可以骗过Classifier,那么那个具体的部分就表示了讲话者的信息。Classifier用来分辨语者的性别,encoder的原目标要加上一个限制,就是要使得不能让Classifier分辨出语者的性别,因此在训练的过程中就会把语者的性别放到后100维中去了,前100维就只剩下内容的信息了。

3.3.2 改变网络结构
另一种方式是改变网络结构,比如使用两个Encoder来分别得到内容信息和讲话者身份信息的Embedding,同时在Encoder中使用instance normalization,直接除掉global information。然后将得到的两个Embedding结合起来送入Decoder重建输入数据。
除了将两个Embedding直接组合起来的方式,还可以在Decoder中使用Adaptive instance normalization。

所以以上图架构来看,Encoder 1我们加入了IN layer,那就可能可以直接消掉说话人的资讯。但这还不能有任何的保证,因此我们还会在Decoder中加入AdaIN layer(adaptive instance normalization)让Encoder 2的output可以加到AdaIN内,来调整global information。
4. Discrete Representation(离散表示)
如果模型可以从连续型的向量表示变成输出离散的表示,那么对于表示的解释性估计会有更好的理解。(Easier to interpret or clustering)
主要方法有:
4.1 one-hot
例如:用独热编码表示图片,做法很简单,在连续向量后面接相同维度的独热编码,看连续变量的哪个维度最大就用哪个做独热编码的1。

通常情况下,Encoder输出的Embedding都是连续值的向量,这样才可以使用反向传播算法更新参数。但如果可以将其转换为离散值的向量,例如one-hot向量或是binary向量,我们就可以更加方便的观察Embedding的哪一部分表示什么信息。当然此时不能直接使用反向传播来训练模型,一种方式就是用强化学习来进行训练。
同样可以用Binary向量来表示图片,只不过判断0/1的方法不一样,这里如果大于0.5取1,小于取0,
但是上面的模型在连续向量转离散向量的步骤上是不可做偏导的(无法GD)但是有办法:
当然,上面两个离散向量的模型比较起来,Binary模型要好,原因有两点:
4.2 VQVAE

VQVAE(Vector Quantized Variational Auto-encoder,矢量量化变分自动编码器),它引入了一个Code book。它是将Embedding分为了很多的vector,然后比较哪一个和输入更像,就将其丢给Decoder重建输入。
上面的模型中,如果输入的是语音信息,那么语者信息和噪音信息会被过滤掉,因为上面的Codebook中保存的是离散变量,而内容信息是一个个的token,是容易用离散向量来表示的,而其他信息不适合用离散变量表示,因此会被过滤掉。
因此过滤信息是VQVAE的一个应用。
4.3 Sequence as Embedding
既然可以用离散向量来表示输入信息,那么我们也可以考虑用序列来embedding

如果我们要训练一个seq2seq2seq的Auto-encoder时,使用其他对抗的思想进行训练,就可以得到类似关于输入文档的摘要信息
结论与展望
本节主要讲的是两方面内容:
第一方面是一种新的训练encoder的方式,过去训练encoder的时候是要最小化重构误差,现在我们知道可以训练一个二分类器(discriminator)去评估一个encoder,我们要做的事情就是调整encoder的参数,让encoder去学习使得在当前评估标准下结果最好。auto-encoder就是二分类器看encoder是好是坏的一种特例。假设discriminator里有一个NN decoder,接收一个向量,输出一个和输入图片大小一样的图片,然后把两张图片做相减,计算它们之间的差异,重构误差就是二分类器输出的值。当我们训练encoder的时候,是和discriminator一起训练的,这件事就好像训练一般的auto-encoder的时候,同时训练encoder和decoder,输出的重构误差要越小越好。
第二方面是使得Embedding更具体可解释性的具体方法,Feature Disentangle(特征解耦),具体是使用两种方法,第一种是使用GAN对抗的思想,迭代训练分类器和encoder,第二种方法使用改变网络结构,可以把我们不要的资讯过滤掉。