概率论复习笔记二——离散型分布和连续型分布
一、离散型分布
1.1 伯努利分布
在一次试验中,事件 A A A出现的概率为 p p p,不出现的概率为 q = 1 − p q=1-p q=1−p,若以 β \beta β记事件 A A A出现的次数,则 β \beta β取 0 , 1 0, 1 0,1两值,相应的概率分布为 b k = P { β = k } = p k q 1 − k , k = 0 , 1 (1) b_k=P\{\beta=k\}=p^kq^{1-k}, k=0,1\tag1 bk=P{β=k}=pkq1−k,k=0,1(1)
这个分布称为伯努利分布,亦称为两点分布。
1.2 二项分布
在 n n n重伯努利试验中,若以 μ \mu μ记作成功的次数,则它是一个随机变量, μ \mu μ可能取的值为 0 , 1 , 2 ⋯ , n 0,1,2\cdots,n 0,1,2⋯,n,其对应的概率分布为 b ( k ; n , p ) = P { μ = k } = C n k p k q n − k , k = 0 , 1 , 2 ⋯ , n (2) b(k;n,p)=P\{\mu=k\}=C_n^kp^kq^{n-k}, k=0,1,2\cdots,n\tag2 b(k;n,p)=P{μ=k}=Cnkpkqn−k,k=0,1,2⋯,n(2)
简记为 μ ∼ B ( n , p ) \mu\sim B(n,p) μ∼B(n,p)
1.3泊松分布
若随机变量 ξ \xi ξ可取一切非负整数值,且 p { ξ = k } = λ k k ! e − λ , k = 0 , 1 , 2 ⋯ (3) p\{\xi=k\}=\frac{\lambda^k}{k!}e^{-\lambda}, k=0,1,2\cdots\tag3 p{ξ=k}=k!λke−λ,k=0,1,2⋯(3)
其中, λ > 0 \lambda\gt0 λ>0,则称 ξ \xi ξ服从泊松分布,简记为 ξ ∼ P ( λ ) \xi\sim P(\lambda) ξ∼P(λ)
1.4 几何分布
在成功概率为 p p p的伯努利试验中,若以 η \eta η记成功首次出现时的试验次数,则 η \eta η为随机变量,它可能取的值为 1 , 2 , 3 ⋯ 1,2,3\cdots 1,2,3⋯,其概率分布为 g ( k , p ) = P { η = k } = q k − 1 p , k = 1 , 2 , ⋯ (4) g(k,p)=P\{\eta=k\}=q^{k-1}p, k=1, 2, \cdots\tag4 g(k,p)=P{η=k}=qk−1p,k=1,2,⋯(4)
简记为 η ∼ g ( k , p ) \eta\sim g(k,p) η∼g(k,p)
几何分布有一个重要的性质——无记忆性:
假定已知在前 m m m次试验中没有出现成功,那么为了达到首次成功还需要再等待的次数为 η ′ \eta^{'} η′,其概率分布为 P { η ′ = k } = P { η = m + k ∣ η > m } = P { η = m + k } P { η > m } = q m + k − 1 p q m = q k − 1 p , k = 1 , 2 , ⋯ P\{\eta^{'}=k\}=P\{\eta=m+k|\eta\gt m\}=\frac{P\{\eta=m+k\}}{P\{\eta\gt m\}}=\frac{q^{m+k-1}p}{q^m}=q^{k-1}p, k=1,2,\cdots P{η′=k}=P{η=m+k∣η>m}=P{η>m}P{η=m+k}=qmqm+k−1p=qk−1p,k=1,2,⋯
可见, η ′ \eta^{'} η′的分布还是几何分布,即为了达到首次成功还需要再等待的次数与前面的失败次数无关。
1.5 帕斯卡分布
在成功概率为 p p p的伯努利试验中,若以 ζ \zeta ζ记第 r r r次成功出现时的试验次数,则 ζ \zeta ζ是随机变量,取值 r , r + 1 , ⋯ r, r+1, \cdots r,r+1,⋯,其概率分布为帕斯卡分布: P { ζ = k } = C k − 1 r − 1 p r q k − r , k = r , r + 1 , ⋯ (5) P\{\zeta=k\}=C_{k-1}^{r-1}p^{r}q^{k-r},k=r,r+1,\cdots\tag 5 P{ζ=k}=Ck−1r−1prqk−r,k=r,r+1,⋯(5)
二、连续型分布
首先需要知道的是,连续型随机变量取个别值的概率为 0 0 0,即 P { ξ = c } = 0 P\{\xi=c\}=0 P{ξ=c}=0。在图型上,密度函数对各种分布的特征的显示要比分布函数优胜的多,因此它比分布函数更加常用。
2.1 均匀分布
若 a , b a, b a,b为有限数,由下列密度函数定义的分布称为 [ a , b ] [a,b] [a,b]上的均匀分布: p ( x ) = { 1 b − a , a ≤ x ≤ b 0 , x < a 或 x > b (6) p(x)=\begin{cases}\frac{1}{b-a}, &a\le x \le b\\ 0, &x\lt a或x\gt b \end{cases}\tag6 p(x)={b−a1,0,a≤x≤bx<a或x>b(6)
记作 U [ a , b ] U[a,b] U[a,b]
2.2 正态分布
密度函数为 p ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 , − ∞ < x < ∞ (7) p(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}, -\infty\lt x\lt \infty\tag7 p(x)=2πσ1e−2σ2(x−μ)2,−∞<x<∞(7)
其中, σ > 0 \sigma\gt0 σ>0, μ \mu μ和 σ \sigma σ均为常数,这种分布称为正态分布,简记为 N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2)。特别的,当 μ = 0 , σ = 1 \mu=0, \sigma=1 μ=0,σ=1时,称为标准正态分布,记为 N ( 0 , 1 ) N(0,1) N(0,1),相应的密度函数和分布函数记为 φ ( x ) \varphi(x) φ(x)和 Φ ( x ) \Phi(x) Φ(x)。
可以验证,如果随机变量 ξ \xi ξ服从正态分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2),那么 ξ − μ σ \frac{\xi-\mu}{\sigma} σξ−μ服从 N ( 0 , 1 ) N(0,1) N(0,1)。而且 p { ∥ ξ − μ ∣ < σ } ≈ 68.27 % (8) p\{\|\xi-\mu|\lt\sigma\}\approx68.27\%\tag8 p{∥ξ−μ∣<σ}≈68.27%(8)
p { ∥ ξ − μ ∣ < 2 σ } ≈ 95.45 % (9) p\{\|\xi-\mu|\lt2\sigma\}\approx95.45\%\tag9 p{∥ξ−μ∣<2σ}≈95.45%(9)
p { ∥ ξ − μ ∣ < 3 σ } ≈ 99.73 % (10) p\{\|\xi-\mu|\lt3\sigma\}\approx99.73\%\tag{10} p{∥ξ−μ∣<3σ}≈99.73%(10)
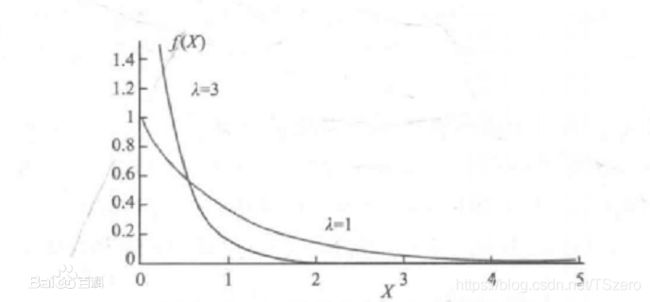
2.3 指数分布
密度函数为 p ( x ) = { λ e − λ x , x ≥ 0 0 , x < 0 p(x)=\begin{cases} \lambda e^{-\lambda x}, &x\ge0\\ 0, &x\lt0 \end{cases} p(x)={λe−λx,0,x≥0x<0,分布函数为 F ( x ) = { 1 − e − λ x , x ≥ 0 0 , x < 0 F(x)=\begin{cases} 1 - e^{-\lambda x}, &x\ge0\\ 0, &x\lt0 \end{cases} F(x)={1−e−λx,0,x≥0x<0,其中 λ > 0 \lambda\gt0 λ>0为参数,这分布称为指数分布,简记为 E x p ( λ ) Exp(\lambda) Exp(λ)。常用它来作各种“寿命”分布的近似,例如电子元件的寿命,某些动物的寿命,电话问题中的通话时间等。
另外,与几何分布类似, p { ξ ≥ s + t ∣ ξ ≥ s } = P { ξ ≥ t } p\{\xi\ge s+t|\xi\ge s\}=P\{\xi\ge t\} p{ξ≥s+t∣ξ≥s}=P{ξ≥t}。