python爬取B站视频弹幕分析并制作词云
1.分析网页
视频地址: www.bilibili.com/video/BV19E… 本身博主同时也是一名up主,虽然已经断更好久了,但是不妨碍我爬取弹幕信息来分析呀。 这次我选取的是自己 唯一的爆款视频 。就是下面这个。
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
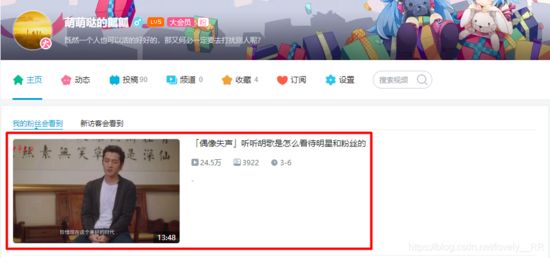
希望大家能够多多支持up,up在这里谢过大家了。 打开网址我们能够发现弹幕信息是存储在这一块的。
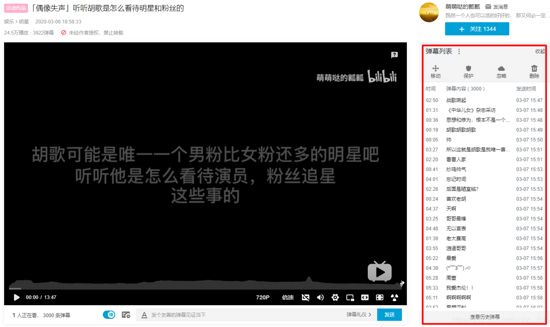
本来以为是可以直接爬到的,但是当我点开F12检查网页的时候却发现:
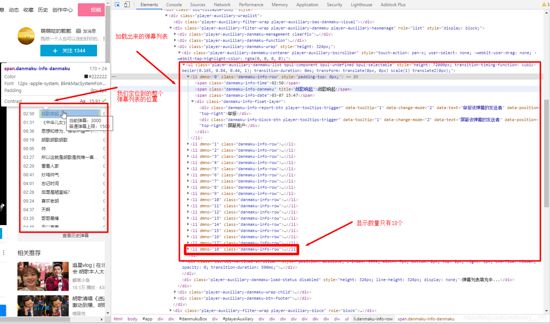
他很明显只加载了一部分的弹幕信息,那么怎么获取呢,别急下面有一个查看历史弹幕信息,我们点击一下试试看。
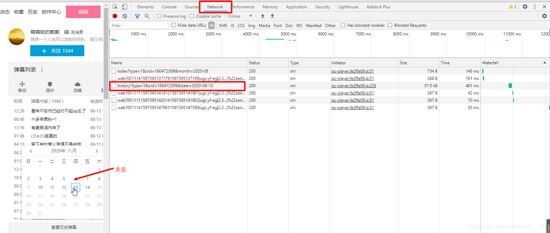
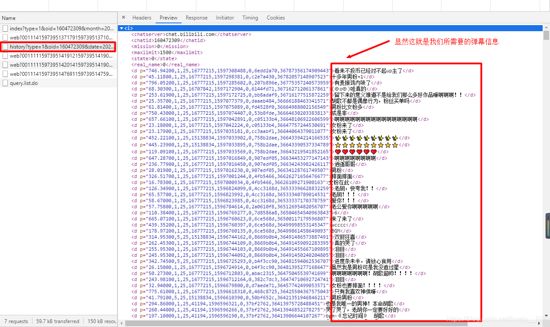
既然知道了信息是藏在哪里的,那么接下来就是简单分析一下他的 url地址的格式
了。

可以看到重点其实就在date上,只要更换date就能获得那一天的弹幕了,所以我们基本确定我们的URL地址。接下来就是爬虫了。
2.爬虫+jieba分词+制作词云
2.1爬虫
首先是简单的先获取整个网页信息,但是获取的过程中,出现了这个错误。

这个大家都懂是啥意思,那么我们怎么解决的?很简单,我们将账号信息带进去就行了,那么怎么带呢?这里我选择的是直接将 cookie信息
放入请求头之中。这个cookie信息大家需要根据自己的浏览返回的信息进行选择。
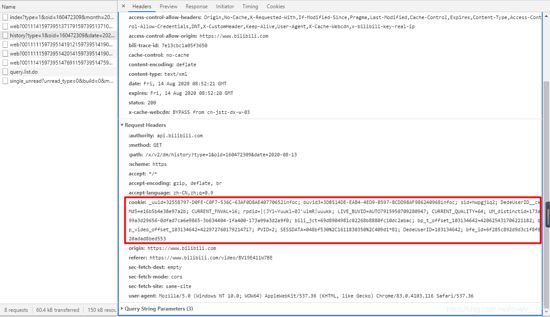
像这样,放入headers中。
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
"cookie": "_uuid=32558797-D0FE-C0F7-536C-63AF0D8AE40770652infoc; buvid3=3DB514DE-EAB4-4ED9-B597-BCDD98AF986240968infoc; sid=hwpgj1q2; DedeUserID__ckMd5=e16b5b4e38e97a2b; CURRENT_FNVAL=16; rpdid=|(JYl~Yuukl~0J'ulmR|uuukk; LIVE_BUVID=AUTO7915950709280947; CURRENT_QUALITY=64; UM_distinctid=173a99a3d29656-0dfad7ca6e9865-3b634404-1fa400-173a99a3d2a9f0; bili_jct=69d8904981c02268b8880fc10dc2abac; bp_t_offset_103134642=420625431706221182; SESSDATA=048bf530%2C1611830350%2C409d1*81; DedeUserID=103134642; PVID=1; bp_video_offset_103134642=422972760179214717; bfe_id=6f285c892d9d3c1f8f020adad8bed553"}
复制代码
这样我们便能爬取到了

接下来获取弹幕信息。这里很简单通过xpath就能获取到。
parse=parsel.Selector(html)
links=parse.xpath("//d/text()").getall()
print(links)
复制代码

既然已经获取到弹幕了,我们就需要将这些信息存储起来,用于我们接下来的操作。 这里我们选择将它存储到CSV文件中具体操作其实和之前的文件下载操作相差不大。
for i in links:
with open(r'C:\Users\瓤瓤\Desktop\B站弹幕.csv','a',newline='',encoding='utf-8-sig') as f:
writer=csv.writer(f)
links=[]
links.append(i)
writer.writerow(links)
复制代码
打开之后就是这样的:

2.2jieba分词
文件都存储好了,那么我接下来的第一步就是将我们的弹幕进行jieba分词,拆解成一个一个的词语
f =open(r'C:\Users\瓤瓤\Desktop\B站弹幕.csv',encoding='utf-8')#打开文件 text=f.read() #读取文件 text_list=jieba.analyse.extract_tags(text,topK=40)#进行jieba分词,并且取频率出现最高的40个词 text_list=" ".join(text_list)#用空格将这些字符串连接起来 print(text_list) 复制代码
效果:

2.3制作词云
既然词我们已经准备好了,那么我们接下来就是将它制作成词云。
#创建自定义图片样式
img=plt.imread('./img/huge.jpg')
w=wordcloud.WordCloud(
width=1500,
height=1000,
font_path="STXIHEI.TTF",#设置字体的格式 字体所在位置C:\Windows\Fonts
background_color="white",
scale=50,
contour_width=5,
contour_color="red",
mask=img,#图片遮罩层
#设置屏蔽词
stopwords={"00","天下第一","bgm","周董","真的","胡是","你币","肖战","游记","周杰伦","陈奕迅","这个"}
)
w.generate_from_text(text_list)
#绘制图片
fig=plt.figure(1)
plt.imshow(w)
plt.axis("off")
plt.show() #显示生成的词云文件
复制代码
在设置字体样式的过程中千万要 选用能够识别中文的字体样式 ,否则会变成一堆方框。字体所在位置字体所在位置 C:\Windows\Fonts 接着只要耐心等程序运行完就行了。
3.成品展示

4.完整代码
import requests
import parsel
import csv
import jieba.analyse
import wordcloud
from matplotlib import pylab as plt
url='https://api.bilibili.com/x/v2/dm/history?type=1&oid=160472309&date=2020-08-12'
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
"cookie": "_uuid=32558797-D0FE-C0F7-536C-63AF0D8AE40770652infoc; buvid3=3DB514DE-EAB4-4ED9-B597-BCDD98AF986240968infoc; sid=hwpgj1q2; DedeUserID__ckMd5=e16b5b4e38e97a2b; CURRENT_FNVAL=16; rpdid=|(JYl~Yuukl~0J'ulmR|uuukk; LIVE_BUVID=AUTO7915950709280947; CURRENT_QUALITY=64; UM_distinctid=173a99a3d29656-0dfad7ca6e9865-3b634404-1fa400-173a99a3d2a9f0; bili_jct=69d8904981c02268b8880fc10dc2abac; bp_t_offset_103134642=420625431706221182; SESSDATA=048bf530%2C1611830350%2C409d1*81; DedeUserID=103134642; PVID=1; bp_video_offset_103134642=422972760179214717; bfe_id=6f285c892d9d3c1f8f020adad8bed553"}
response=requests.get(url,headers=headers)
html=response.content.decode("utf-8")
# print(html)
parse=parsel.Selector(html)
links=parse.xpath("//d/text()").getall()
# print(links)
for i in links:
with open(r'C:\Users\瓤瓤\Desktop\B站弹幕.csv','a',newline='',encoding='utf-8-sig') as f:
writer=csv.writer(f)
links=[]
links.append(i)
writer.writerow(links)
# #制作词云图
f =open(r'C:\Users\瓤瓤\Desktop\B站弹幕.csv',encoding='utf-8')
text=f.read()
text_list=jieba.analyse.extract_tags(text,topK=40)
text_list=" ".join(text_list)
print(text_list)
#
img=plt.imread('./img/huge.jpg')
w=wordcloud.WordCloud(
width=1500,
height=1000,
font_path="STXIHEI.TTF",
background_color="white",
scale=50,
contour_width=5,
contour_color="red",
mask=img,
stopwords={"00","天下第一","bgm","周董","真的","胡是","你币","肖战","游记","周杰伦","陈奕迅","这个"}
)
w.generate_from_text(text_list)
#绘制图片
fig=plt.figure(1)
plt.imshow(w)
plt.axis("off")
plt.show() #显示生成的词云文件
复制代码