PointNet:基于深度学习的3D点云分类和分割模型
这篇文章是点云神经网络的鼻祖,它提出了一种网络结构,可以直接从点云中学习特征。如何设计出符合点云特点的网络是一个难点。在了解这个神经网络之前,容本小白先了解一下3D点云的基本知识。
首先要说清楚,PointNet所作的事情就是对点云做特征学习,并将学习到的特征去做不同的应用:分类(shape-wise feature)、分割(point-wise feature)等。
PointNet之所以影响力巨大,就是因为它为点云处理提供了一个简单、高效、强大的特征提取器(encoder),几乎可以应用到点云处理的各个应用中,其地位类似于图像领域的AlexNet。
目录
0x01 3D点云的基本知识
(一)点云概述
(二)点云的获取
(三)点云的内容
(四)点云的属性
(五)点云的存储格式
(六)相应基础算法库对不同格式的支持
(七)点云分割
(八)点云补全
(九)点云生成
(十)点云物体检测
(十一)点云配准
0x02 PointNet:3D点集分类与分割深度学习模型
(一)点云数据的特点
(二)PointNet基本出发点
(三)PointNet算法网络架构解读
0x01 3D点云的基本知识
点云数据现在已经在自动驾驶、医学、建筑建图、工业应用等方面都应用起来了,现在发展可以说是比较成熟了。那么在开始了解PointNet模型时,我们先来了解3D点云这个东西。
所谓的三维图像,可以理解为是在二维彩色图像的基础上又多了一个维度,即深度(Depth,D),那么用一个很直观的公式可以表示为:三维图像 = 普通的RGB三通道彩色图像+Depth Map。也就是我们平时所了解到的RGB-D。RGB-D是广泛使用的3D格式,其图像每个像素都有四个属性:即红(R)、绿(G)、蓝(B)和深度(D)。在一般的基于像素的图像中,我们可以通过(x,y)坐标定位任何像素,分别获得三种颜色属性(R,G,B)。而在RGB-D图像中,每个(x,y)坐标将对应于四个属性(深度D,R,G,B)。
(一)点云概述
回到点云,在做3D视觉的时候,处理的主要是点云,点云就是一些点的集合。相对于图像,点云有其不可替代的优势——深度,也就是说三维点云直接提供了三维空间的数据,而图像则需要通过透视几何来反推三维数据,这个透视几何可能推出来的数据并不符合要求,会有一些偏差。点云其实就是某个坐标系下的点的数据集,点包含了丰富的信息,包括三维坐标X,Y,Z、颜色、分类值、强度值、时间等等。点云在组成特点上分为两种,一种是有序点云,一种是无序点云:
-
有序点云:一般由深度图还原的点云,有序点云按照图方阵一行一行的,从左上角到右下角排列,当然其中有一些无效点云。有序点云按顺序排列,可以很容易找到他的相邻点信息。有序点云在某些处理的时候还是很便利的,但是很多情况下是无法获取有序点云的。
-
无序点云:无序点云就是其中的点的集合,点排列之间没有任何顺序,点的顺序交换后没有任何影响。是比较普通的点云形式,有序点云也可以看作无序点云来处理。
点云的表示优点:点云表示保留了三维空间中原始的几何信息,不进行离散化。
点云当前面临的挑战:
-
数据集规模小
-
高维性
-
3维点云的非建构化特性
(二)点云的获取
点云不可以通过普通摄像机获取,一般是通过三维成像传感器获得,比如双目相机、三维扫描仪、RGB-D相机等。目前主流的 RGB-D 相机有微软的 Kinect 系列、Intel 的 realsense 系列、structure sensor(需结合 iPad 使用)等。点云可通过扫描的RGB-D图像,以及扫描相机的内在参数创建点云,方法是通过相机校准,使用相机内在参数计算真实世界的点(x,y)。因此,RGB-D图像是网格对齐的图像,而点云则是更稀疏的结构。此外,获得点云的较好方法还包括LiDAR激光探测与测量,主要是通过星载、机载和地面三种方式获取。
(三)点云的内容
根据激光测量原理得到的点云,包括三维坐标(XYZ)和激光反射强度(Intensity),强度信息与目标的表面材质、粗糙度、入射角方向以及仪器的发射能量、激光波长有关。
根据摄影测量原理得到的点云,包括三维坐标(XYZ)和颜色信息(RGB)。
结合激光测量和摄影测量原理得到点云,包括三维坐标(XYZ)、激光反射强度(Intensity)和颜色信息(RGB)。
(四)点云的属性
-
空间分辨率、点位精度、表面法向量等
-
点云可以表达物体的空间轮廓和具体位置,我们能看到街道、房屋的形状,物体距离摄像机的距离也是可知的;其次,点云本身和视角无关,可以任意旋转,从不同角度和方向观察一个点云,而且不同的点云只要在同一个坐标系下就可以直接融合。
(五)点云的存储格式
点云目前的主要存储格式包括:pts、LAS、PCD、.xyz 和. pcap 等。
-
pts点云文件格式:是最简单的点云格式,直接按XYZ顺序存储点云数据,可以是整型或者浮点型。
-
LAS点云文件格式:是激光雷达数据(LiDAR),存储格式比pts复杂,旨在提供一种开放的格式标准,允许不同的硬件和软件提供商输出可互操作的统一格式。LAS 格式点云截图,其中 C:class(所属类),F:flight(航线号),T:time(GPS 时间),I:intensity(回波强度),R:return(第几次回波),N:number of return(回波次数),A:scan angle(扫描角),RGB:red green blue(RGB 颜色值)。
-
PCD点云文件格式:PCD 格式具有文件头,用于描绘点云的整体信息:定义数字的可读头、尺寸、点云的维数和数据类型;一种数据段,可以是 ASCII 码或二进制码。数据本体部分由点的笛卡尔坐标构成,文本模式下以空格做分隔符。PCD 存储格式是 PCL 库官方指定格式,典型的为点云量身定制的格式。优点是支持 n 维点类型扩展机制,能够更好地发挥 PCL 库的点云处理性能。文件格式有文本和二进制两种格式。
-
.xyz点云文件格式:一种文本格式,前面 3 个数字表示点坐标,后面 3 个数字是点的法向量,数字间以空格分隔。
-
. pcap点云文件格式:是一种通用的数据流格式,现在流行的 Velodyne 公司出品的激光雷达默认采集数据文件格式。它是一种二进制文件。整体一共全局头部(GlobalHeader),然后分成若干个包(Packet),每个包又包含头部(Header)和数据(Data)部分。
-
obj是一种文本文件,通常用以“#”开头的注释行作为文件头,数据部分每一行的开头关键字代表该行数据所表示的几何和模型元素,以空格做数据分隔符
(六)相应基础算法库对不同格式的支持
-
PCL(Point Cloud Library)库支持跨平台存储,可以在 Windows、Linux、macOS、iOS、Android 上部署。可应用于计算资源有限或者内存有限的应用场景,是一个大型跨平台开源 C++ 编程库,它实现了大量点云相关的通用算法和高效数据结构,其基于以下第三方库:Boost、Eigen、FLANN、VTK、CUDA、OpenNI、Qhull,实现点云相关的获取、滤波、分割、配准、检索、特征提取、识别、追踪、曲面重建、可视化等操作,非常方便移动端开发。
-
VCG 库(Visulization and Computer Graphics Libary)是专门为处理三角网格而设计的,该库很大,且提供了许多先进的处理网格的功能,以及比较少的点云处理功能。
-
CGAL(Computational Geometry Algorithms Library)计算几何算法库,设计目标是以 C++ 库的形式,提供方便、高效、可靠的几何算法,其实现了很多处理点云以及处理网格的算法。
-
Open3D 是一个可以支持 3D 数据处理软件快速开发的开源库。支持快速开发处理 3D 数据的软件。Open3D 前端在 C++ 和 Python 中公开了一组精心选择的数据结构和算法。后端经过高度优化,并设置为并行化。Open3D 是从一开始就开发出来的,带有很少的、经过仔细考虑的依赖项。它可以在不同的平台上设置,并且可以从源代码进行最小的编译。代码干净,样式一致,并通过清晰的代码审查机制进行维护。在点云、网格、rgbd 数据上都有支持。
(七)点云分割
点云分割是根据空间、几何和纹理等特征对点云进行划分,使得同一划分内的点云拥有相似的特征。
(八)点云补全
整体来说类似GAN和Unet那种感觉(编码解码网络)

点云补全(Point Cloud Completion)用于修补有所缺失的点云(Point Cloud),从缺失点云出发估计完整点云,从而获得更高质量的点云。

(九)点云生成

例如像模型PointFlow,即可通过将3D点云建模为分布的分布来生成3D点云。
(十)点云物体检测

点云物体检测流程主要由三个部分组成:(1)数据表示(2)特征提取和(3)基于模型的检测。
(十一)点云配准

点云配准分为粗配准(Coarse Registration)和精配准(Fine Registration)两个阶段。
精配准的目的是在粗配准的基础上让点云之间的空间位置差别最小化。应用最为广泛的精配准算法应该是ICP以及ICP的各种变种(稳健ICP、point to plane ICP、Point to line ICP、MBICP、GICP、NICP)。
粗配准是指在点云相对位姿完全未知的情况下对点云进行配准,可以为精配准提供良好的初始值。当前较为普遍的点云自动粗配准算法包括基于穷举搜索的配准算法和基于特征匹配的配准算法。
0x02 PointNet:3D点集分类与分割深度学习模型
在上面所提及到的点云的各种操作,其实都可以使用PointNet来解决。
打开点云数据可以使用软件:CloudCompare

论文地址:https://arxiv.org/pdf/1612.00593.pdf
GitHub:GitHub - charlesq34/pointnet: PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation

那么这个网络架构可以做什么:
-
分类
-
部件分割
-
语义分割

最后实现的效果是如下的:
场景分割任务(左)、部件分割任务(右):
如何处理3D数据?其实方式有很多种:

可以用很多张照片通过很多个CNN,然后把它合并拼接,这样效率可谓是非常低,所以才需要有PointNet这样的存在。
(一)点云数据的特点
-
无序性:只是点而已,排列顺序不同,顺序无所谓。
-
近密远疏:扫描与视角不同导致。
-
信息量有限:非结构化数据,直接CNN有点难。

所以要解决的任务就是如何对点云数据进行特征提取。
要站在网络的角度理解点云的特点,其实转换下来也是非常好理解:
-
排列不变性:重拍一遍所有点的输入顺序,所表示的还是同一个点云数据,网络数据的输出应该相同。
-
点集之间的交互性:点与点之间有未知的关联性。
-
变换不变性:对于某些变换,例如仿射变换,应用在点云上时,不应该改变网络对点云的理解。
(二)PointNet基本出发点
-
由于点的无序性导致,需要模型具有置换不变性
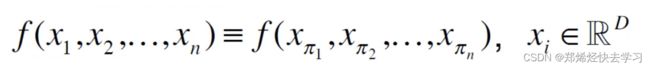
那么可以使用这些公式来体现:

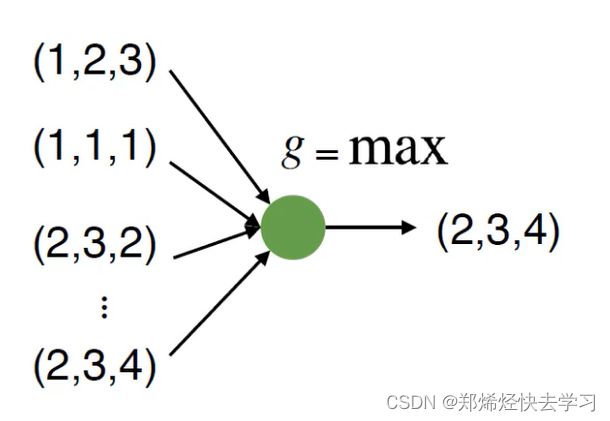
求max值与位置没有关系,使用加法也是与位置无关。那么我们就直接使用Max函数叭,简单粗暴:
但是这样会导致我们的特征太少,损失太多。那么如何解决?论文中的思想是:先升维然后再做Max操作(其实就是神经网络的隐层)
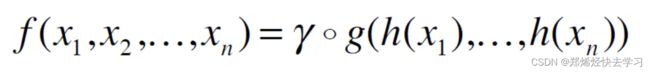
上面提及到了升维这个东西,神经网络本质就是一个特征提取器,下面的MLP可以理解为一个感知机,可以为全连接层、卷积等等,把它上升为一个高维特征,再经过max函数得到全局再进行输出。

(三)PointNet算法网络架构解读
分类就是得到整体特征再输出;分割就是各个点特征输出结果。

上面蓝色的部分即为分类任务,而下面黄色那块,则为分割任务。
其实这个网络它并不复杂,分类网络对于输入的点云进行输入变换(input transform)和特征变换(feature transform),随后通过最大池化将特征整合在一起。分割网络则是分类网络的延伸,其将整体和局部特征连接在一起出入每个点的分数。
分类的时候基本思想跟刚刚上面所说的使用max操作是一样的,可以看见他输入的是 n 个三维坐标(实际上可以更多维度),预测了一个变换矩阵做了变换,然后使用 MLP 对每个点做一个 embedding,之后再在 feature 空间中预测了变换矩阵做变换,然后又做了 embedding,最后 maxpooling 得到全局特征。用全局特征过一个 MLP 来做 label prediction。其中,mlp是通过共享权重的卷积实现的,第一层卷积核大小是1x3(因为每个点的维度是xyz),之后的每一层卷积核大小都是1x1。即特征提取层只是把每个点连接起来而已。经过两个空间变换网络和两个mlp之后,对每一个点提取1024维特征,经过maxpool变成1x1024的全局特征。再经过一个mlp(代码中运用全连接)得到k个score。分类网络最后接的loss是softmax。
分割的时候,相比于分类,分割需要每个点捕捉全局信息后才能知道自己是哪一类,于是把每个点的 feature 和全局 feature 做一个 concat,过 MLP,之后对每个点做 label prediction。
简言意骇来说:
PointNet因为是只使用了MLP和max pooling,没有能力捕获局部结构,因此在细节处理和泛化到复杂场景上能力很有限。
所以这个代码就不详细去看了,详细的看下一篇PointNet++叭!