(一)网络爬虫小姐姐图片---谷歌浏览器浏览的某些网站被禁用”右键检查“和“F12”,不能查看源代码。将爬取的图片重命名。
网络爬虫小姐姐图片—谷歌浏览器浏览的某些网站被禁用”右键检查“和“F12”,不能查看源代码
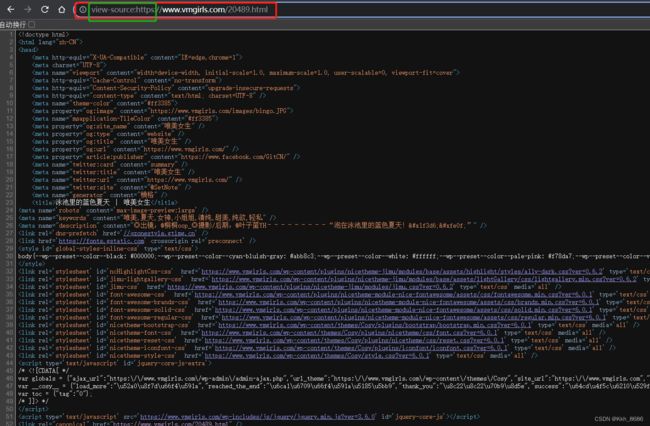
(1)对于某些网站被禁用”右键检查“和“F12”,不能查看源代码,可以在输入框先输入:“view-source:”,后面接需要爬虫的网址。例如:
原网站:
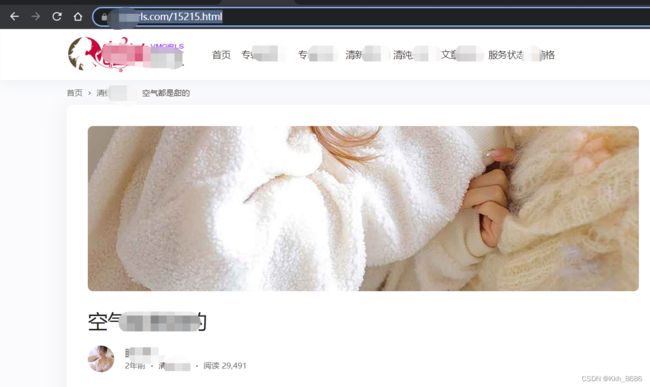
查看网页源代码:
当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
import requests
# 当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
# headers = {
# "User-Agent":"hdy"
# }
# response = requests.get("https://www.vmgirls.com/15215.html, headers=headers")
response = requests.get("https://www.vmgirls.com/15215.html")
print(response.text)
如下图能显示html格式,表示网站能被爬虫:
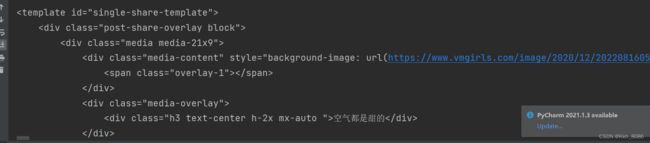
完整代码解析:
# 在某一个网页中爬取图片
import requests
import re # 正则(最简单的爬虫方法)
import os
# 当爬虫程序运行爬网站,若不设置header为任意一个名字,会被有些网站检查出是python爬虫,被禁止访问
headers = {
"User-Agent" : "hdy"
}
# 请求网页
print("输入需要爬取图片的网站连接:")
urls = input()
response = requests.get(urls, headers=headers)
# print(response.request.headers)
# print(response.text)
html = response.text
# 解析网页
# dir_name = re.findall('空气都是甜的
', html)
dir_name = re.findall('(.*?)
', html)[-1] # 正则
print("*", dir_name)
# 在指定文件夹中创建文件夹,如果文件目录不存在,创建目录
path = "F:\\PyQt_Serial_Assistant_Drive_Detect\\Friuts_Classify\\Data\\"
folder = os.path.exists(path + dir_name)
if not folder:
os.makedirs(path + dir_name)
else:
pass
# 正则查找图片链接
# urls = re.findall('')
urls = re.findall('', html) # 找全部图片所对应的网址
print("**", urls) # 打印全部图片的地址(数组的形式)
# 遍历每张图片
for url in urls:
name = url.split('/')[-1] # 分割每张图片所对应网址以获取每张图片名字
print(name)
# 网页get请求
response=requests.get(url, headers=headers)
# ”wb“以二进制方式打开dir_name文件夹下的命名为name并写入response.content进而得到图片
with open(path + dir_name + '/' + name, 'wb') as f:
f.write(response.content)
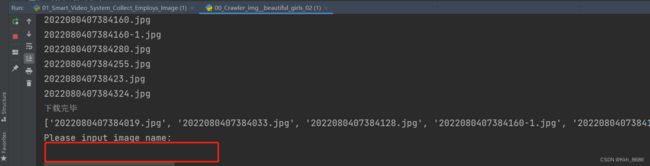
print("下载完毕")
# 批量修改图片命名,对图片以数字顺序进行批量重命名
data_path = path + dir_name # 将要批量重命名的文件夹
class_name = ".jpg" # 重命名后的文件后缀
all_file = os.listdir(data_path) # 返回文件夹包含的所有文件
all_file_num = len(all_file) # 获取文件数目
print(all_file, all_file_num)
for i in range(0, all_file_num):
num = str(i + 1)
new_name = os.rename(data_path + '/' + all_file[i], data_path + '/' + num + class_name) # 重命名
file_out = os.listdir(data_path) # 返回文件夹里面的所有文件
print(file_out)
{kind=link}
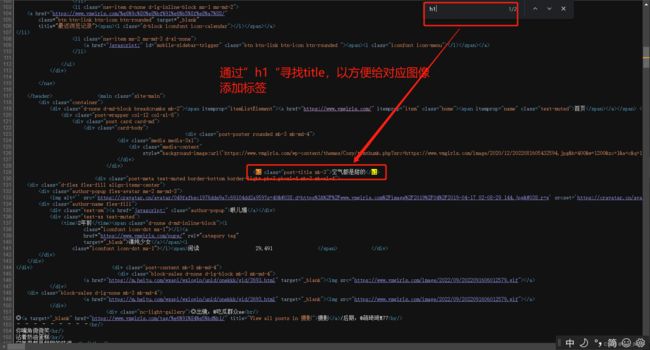
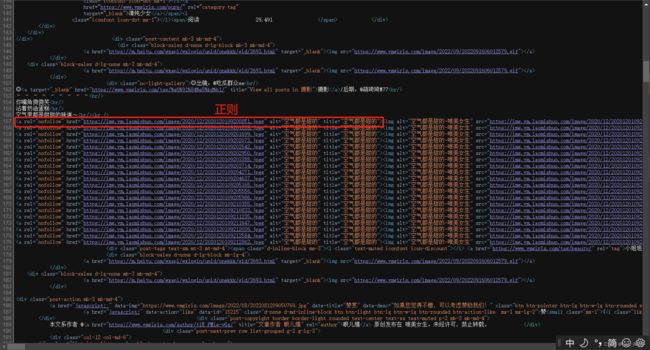
代码中的两个正则分别是网址的title、和图片的对应信息,复制红色框信息到程序,并用正则修改。
运行程序:输入网址(程序适用这个网址)

输入标注名,对批量下载的图片进行标注归类: