浅谈音视频开发入门基础及进阶资源分享
导言:音视频开发涉及的知识面比较广,知识点又相对独立琐碎,入门门槛相对较高。想要对音视频开发具有深入全面的了解,需要在行业深耕多年。本文将简单介绍音视频的采集,编解码,传输,渲染四个技术点并对涉及到的知识点和原理进行解释,希望你可以对音视频开发窥见一斑。
目录
一、简化的音视频客户端的架构图
二、各模块拆解
(1)音视频采集模块
(2)音视频编解码模块
(3)网络传输模块
(4)音视频渲染模块
三、资源推荐
(1)网站:
(2)博客
(3)书籍
(4)github仓库
一、简化的音视频客户端的架构图

图2.1 音视频客户端架构图
二、各模块拆解
从图2.1我们可以看到一个音视频客户端架构图大致可以分为以下几个模块:
- 音视频采集模块(因为涉及到跨平台通信所以音视频采集又涉及到各操作系统的API)
- 音视频编解码模块(涉及到编解码器的插件化管理)
- 网络传输模块
- 音视频渲染模块
接下来,我将为大家介绍每个模块涉及到的相关知识:
(1)音视频采集模块
音频篇:
首先我们来介绍一下音频采集的原理,音频采样就是通过麦克风等录音设备将声音信号(声音是由物体震动产生的一种疏密相间的纵波)转化为电信号(声音传递的能量会导致麦克风内部的电压发生变化从而产生电流,可参考动圈麦),然后经过采样,量化,编码的方式将电信号转换成数字信号,最后得到一组二进制码流的过程。上述模数转换的过程也被称为PCM(Pulse Code Modulation,脉冲编码调制)。PCM编码是一种最原始的音频编码,其他编码方式都是在此基础上再次编码和压缩的。
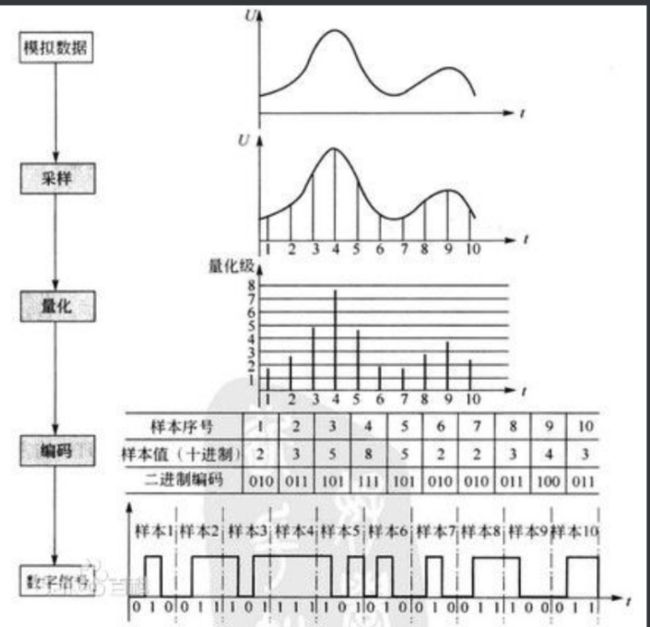
图3.1 模/数转换示意图
采样 是指在时间轴上对模拟信号进行数字化,采样频率是指单位时间内从连续信号中提取并组成离散信号的采样个数,单位是Hz。而且奈奎斯特采样定理指出,如果信号是无限的,并且采样频率高于信号带宽的两倍,那么原来的连续信号就可以从采样样本中完全重建出来。所以采样频率越高,对声音的还原度越高。人耳可以感受到的震动频率是20Hz-20000Hz,所以一般采样频率是40000Hz,常用的采样频率有22.05kHz(FM广播的品质),44.1kHz(CD声音品质),48kHz(高品质无损音乐)
量化 是指在振幅轴上对模拟信号进行数字化,但由于抽样信号在时间轴上虽然是离散的信号,但仍然是模拟信号,其取值在一定范围内可以有无限多个值(比如49.999999....) ,所以为了用准确的数字表示采样值,我们需要对采样值进行“取整”。量化位宽是指用几位二进制数来存储采样的数据,量化位数越大,声音的质量越高。常用的位宽有8bit和16bit。
编码 是指将量化后的采样的十进制数字码流转换成给定字长(量化位深)的二进制码流的过程。
视频篇:
常见的视频采集方式有摄像头采集,屏幕录制采集,从视频文件推流。这里我们以摄像头采集视频为例简单讲解一下视频采集的原理:
被拍摄物体通过镜头(lens),将生成的光学图像投射到感光传感器(sensor)上,把光信号转换成电信号,电信号再经过模数转换把电信号转换成数字信号,数字信号经过DSP图像处理器加工处理,转换成标准的RGB、YUV等格式图像信号存储在设备上最终通过显示器可以看到图像了
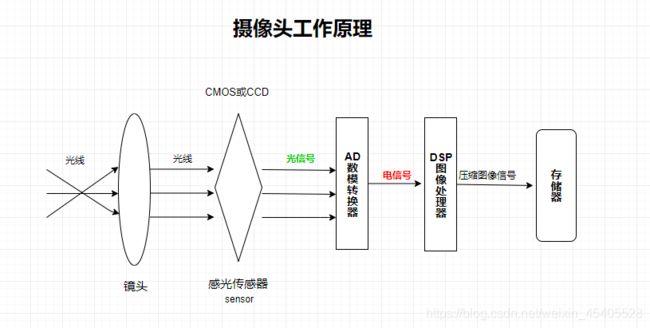
图3.2 摄像头工作原理图
图像采集常会涉及到以下几个技术参数:
- 像素
- 颜色编码方式
- 分辨率
- 帧率
- 采样频率
接下来简单介绍一下各个参数的含义:
像素:像素是组成图像的基本单位,像素的大小不是固定的,是由屏幕的大小决定,像素的纵横比也不是固定的,一般来说,电视上显示的像素是矩形的,而电脑上显示的像素是正方形的。
颜色编码方式:主要有RGB和YUV,RGB表示每个像素点都由红、绿、蓝三个颜色组成,每中颜色用8个bit表示,也就是一个字节,所以一个像素点的大小是三个字节。而YUV采用明亮度和色度来表示像素的颜色,Y表示明亮度,UV表示色度(色调和饱和度),和RGB不同的是Y和UV可以分离的,没有UV分量同样可以表示一幅完整的图像,但是是黑白的。对于图像显示器来说,通常选择RGB模型来显示图像。而在传输的图像时使用的是YUV模型,因为YUV模型可以节省带宽。比如采用主流的YUV 4:2:0的方式,可以比采用RGB方式节省一半的带宽,所以在采集时需要将RGB先通过公式转换成YUV(算法原理可以参考一文读懂 YUV 的采样与格式)
分辨率:是指纵横向上的像素点数,它的表达式为:“水平像素数*垂直像素数”。常见的图像分辨率有QCIF(176×144),CIF(352×288),D1(704×576),720P(1280×720),1080P(1920*1080)。摄像机成像的最大分辨率是由CCD或CMOS感光器件决定的。现在有些摄像机支持修改分辨率,是通过摄像机自带软件裁剪原始图像生成的
帧率:一帧就是一副静止的画面,连续的帧就形成动画,如电影等。我们通常所说的帧数就是在1秒钟时间里传输的图片的数量,通常用fps(Frames Per Second)表示。每一帧都是静止的图像,快速连续地显示帧便形成了运动的假象,还原了物体当时的状态。高帧率可以得到更流畅、更逼真的动画。每秒钟帧数 (fps) 愈多,所显示的动作就会愈流畅。一般来说,图像帧率设置为25fps或30fps已经足够
采样率:同音频采样率,采样率越高,还原的图像越精确
这里需要顺带提一下的部分是音视频采集需要调用系统API这部分,如果我们不采用一个第三方的跨平台解决方案的话,由于各个平台的API设计架构是不一样的,调用方式和使用逻辑也是千差万别的,这部分对于开发者是费事费力的。就以音频采集为例。PC端使用的是CoreAudio;Mac端使用的系统API也称 为CoreAudio,不过具体的函数名是不同的;Android端使用的AudioRecord;iOS端使用的是AudioUnit;Linux端使用的是 PulseAudio。(如果你想深入了解一下CoreAudio,可以参考这篇文章What Is Core Audio? - 知乎)。所以我们在实际开发中,往往会选择像webrtc这样已经支持跨平台的解决方案。
(2)音视频编解码模块
首先我们先来了解一下为什么要编码?从信息论的观点来看,描述信源的数据是信息和数据冗余之和,即:数据 = 信息+数据冗余。音视频编码的本质就是减少音视频中的冗余,从而达到压缩体积的效果。
那么音频和视频数据的冗余主要体现在哪些方面呢?
音频数据的冗余主要体现在(1)时域冗余 (2)频域冗余 (3)听觉冗余
想要详细了解的朋友可以参考这篇文章音频冗余的主要表现形式_技术文章 - 讯维官网
视频数据的冗余主要体现在:
- 空间冗余:图像相邻像素之间有较强的相关性;
- 时间冗余:视频序列的相邻图像之间内容相似;
- 编码冗余:不同像素值出现的概率不同;
- 视觉冗余:人的视觉系统对某些细节不敏感;
- 知识冗余:规律性的结构可由先验知识和背景知识得到
想要详细了解的朋友可以参考这篇文章 视频压缩之冗余_Mr_Wing5的博客-CSDN博客_冗余压缩法
消除数据冗余,比如空间冗余,时间冗余,编码冗余等并不会导致信息损失,属于无损压缩。
而消除视觉冗余,因为人眼对于亮度和色度的敏感度不同,使得再编码的时候引入适量的误差,也不会被人眼所察觉,以一定的客观失真换取数据压缩,这种压缩属于有损压缩。
一般的数字视频压缩编码方法都是混合编码,即将变换编码,运动估计和运动补偿,以及熵编码三种方式相结合来进行压缩编码。通常使用变换编码来消去除图像的帧内冗余,用运动估计和运动补偿来去除图像的帧间冗余,用熵编码来进一步提高压缩的效率。对于音视频编码底层原理感兴趣的朋友,可以参考雷神(雷霄骅)的这篇文章视频压缩编码和音频压缩编码的基本原理_雷霄骅的博客-CSDN博客_音频编码
接下来介绍一些常见的音视频编码方式:
音频编码方式:
MP3(MPEG Audio Layer III,动态影像专家压缩标准音频层面3),它是一种有损音频压缩技术,它是在1991年由位于德国的研究组织Fraunhofer-Gesellschaft的一组工程师发明和 标准化的。利用人耳对高频信号不敏感的特性,将音频信号划分成多个频段,对不同的频段使用不同的压缩率,对高频加大压缩比(甚至忽略信号),对于低频信号使用小压缩比,保 证信号不失真,相当于抛弃人耳听不到的高频声音,从而将声音用10:1甚至12:1的压缩率压缩。
简单介绍一下MPEG是什么,MPEG全称是Moving Picture Experts Group,动态图像专家组。它是ISO(International Standardization Organization,国际标准化组织)与IEC(International Electrotechnical Commission,国际电工委员会)于1988年成立的专门针对运动图像和语音压缩制定国际标准的组织,MPEG标准主要有MPEG-1、MPEG-2、MPEG-4·、MPEG-7及MPEG-21等。那么上面所说的Audio Layer III又是什么呢,这里我们以MPEG-1标准为例介绍它的三个层次
- Layer I: 编码简单,压缩率4:1 常用于数字盒式录音磁带
- Layer II: 编码难度中等,压缩率 8:1-6:1 常用于数字音频广播(DAB)和VCD等
- Layer III: 编码复杂,压缩率12:1-10:1 常用于互联网上的高质量声音的传输。
这里有一个常见的误区就是把MPEG-3等同于MP3,但实际上MPEG-3标准已经被废弃。
AAC(Advanced Audio Coding,高级音频编码)是Fraunhofer IIS与AT&T 、杜比实验室、索尼等公司共同研发的一种有损音频压缩方式,于1997年提出的基于MPEG-2的音频编码技术,目的是取代MP3格式(因为随着时间的推移,MP3越来越不能满足需求,比如压缩率不够高,音质不够理想,仅有两个声道等等),2000年,MPEG-4标准出现后,AAC又重新集成了其特性,加入了SBR(Spectral Band Replication,频段复制)技术和PS(parametric stereo,参数立体声)技术。AAC通常压缩比是18:1远胜MP3,而且它还同时支持48个音轨,15个低频音轨和更多种的采样率和比特率,多种语言的兼容能力,更高的解码效率。号称最大能容纳48通道的音轨,采样率达96KHz。总之,AAC可以在比MP3文件节省大约30%的存储空间和带宽的前提下提供更好的音质。
iLBC(internet Low Bitrate Codec,互联网低比特率编解码器)是由全球著名的语音引擎供应商GIPS(Global IP Sound,webrtc的前身)于2000年开发并被IETF标准化的语音编解码器。iLBC是一种非常适合在IP网络上进行语音通信的编解码,主要为窄带语音通信而设计,但在实际的应用中它已突破了窄带的限制。iLBC有2种基本数据帧格式。一种是20ms的帧格式,语音数据经过编码之后的速率为15.2Kbps;另一种是30ms的帧格式,编码后的语音速率为13.3Kbit/s。由于编码独立于块,iLBC实际减小了由于丢包带来的知觉降低的传播。在高丢包率的IP包交换网络环境下,iLBC可获得非常清晰的语音效果。在窄带应用环境中,iLBC几乎没有语音延迟,断续或杂音,通话效果完全可以和传统电话媲美。由于iLBC算法具有较强的抗丢包率,因此该编解码器可以降低VoIP系统语音质量差的瓶颈,在实时通信系统如电话系统,视频会议,语音流和及时消息中有可观的应用前景。
Opus是一个有损音频编码格式,由Xiph.Org基金会(官网介绍:Xiph.Org is a collection of open source, multimedia-related projects)和Skype提案开发,之后于2012年被IETF(Internal Engineering Task Force,国际互联网工程任务组)批准用于标准化RFC 6716。Opus集成了两种声音编码的技术:Skype的以语音编码为导向的SILK和Xiph.org的低延迟的CELT。Opus可以无缝调节高低比特率。在编码器内部它在较低比特率时使用线性预测编码在高比特率时候使用变换编码(在高低比特率交界处也使用两者结合的编码方式)。Opus具有非常低的算法延迟(默认为22.5 ms),非常适合用于低延迟语音通话的编码,像是网上上的即时声音流、即时同步声音旁白等等,此外Opus也可以透过降低编码码率,达成更低的算法延迟,最低可以到5 ms。在多个听觉盲测中,Opus都比MP3、AAC、HE-AAC(High Efficiency AAC,也称AAC+,融合了AAC与SBR技术)等常见格式,有更低的延迟和更好的声音压缩率。Opus可以处理各种音频应用,包括IP语音、视频会议、游戏内聊天、流音乐、甚至远程现场音乐表演。
视频编码方式:
H.264/H.265 : 这里要先介绍一下两个组织,在国际上指定视频编码技术的组织有两个,一个是ITU(International Telecommunication Union,国际电信联盟) 它指定的标准有H.261、H.263、H.263+等(是H.26x系列。另一个就是ISO(国际标准化组织,它制定的标准有MPEG-1、MPEG-2、MPEG-4等,而H.264是ITU和ISO共同提出的继MPEG4之后的新一代数字视频压缩格式。于2003年3月正式发布,2005年又开发了H.264更高级应用标准MVC和SVC版本。所以它既是ITU的H.264又是ISO的MPEG-4 AVC(Advanced Video Coding,高级视频编码)的第十部分。H.264提出的主要目标是与其他现有的视频编码标准相比,在相同的带宽下提供更加优秀的图像质量。在同等图像质量的压缩效率比MPEG2提高了2倍左右。H.265编码器于2012年被爱立信公司推出,六个月后就被ITU正式批准通过了HEVC/H.265标准(HEVC,高效视频编码),与H.264相比,H.265在同等画质下提供的压缩比可以提升50%-100%,同时对4K、8k、HDR、高帧率视频等场景都有很好的支持能力。
VP8/VP9:VP8是由美国一家视频压缩科技公司On2 Technologies开发的,以开发TrueMotion2、VP3、VP4、VP5、VP8等产品闻名,后于2009年8月被Google收购,Google在2010年开源了VP8,VP8 号称比H.264性能高出50%。但是外界对此一直有争议的,经常拿H.264和VP8进行比较,然后ffmpeg的开发者之一Jason Garrett-Glaser,出了一篇详细的评估。国内也有很多博主在翻译的基础上提出了自己的看法,可以参考雷神的这篇文章深入了解 VP8_雷霄骅的博客-CSDN博客_vp8。 VP9是Google于2011年开始开发的一款免费的开源视频编码标准,最初是用于压缩Youtube上的超高清内容,VP9的目标是在相同质量下相对于VP8可以减少50%的比特率。VP9也经常拿来与H.265进行比较,可以参考这篇文章VP9与H.265的6个不同点 - 知乎
AV1(AOMedia Video 1) 是一种开源、免版税的编解码器,最初设计用于Internet上的视频传输。它是由开放媒体联盟(AOMedia)于VP9的继任者开发的,成立于2015年,包括半导体公司,视频点播提供商,视频内容生产商,软件开发公司和网络浏览器供应商。AV1比特流规范包括参考视频编解码器。AV1参考编码器分别比libvpx-vp9,x264高配置文件和x264主配置文件分别实现了34%,46.2%和50.3%的数据压缩。像VP9一样,但与H.264 / AVC和HEVC不同,AV1具有免版税的许可模式。另外,AV1图像文件格式(AVIF)是一种使用AV1压缩算法的图像文件格式.想要深入了解的可以参考这篇文章走进音视频的世界——新一代开源编解码器AV1_徐福记456的博客-CSDN博客_av1开源。
音视频编码器插件化管理
不同的音视频编码器有各自的有缺点,也有各自适用的使用场景。比如G.711/G.722主要用于电话系统,Opus主要用于实时通信,AAC主要用于音乐类应用,如钢琴教学等。我们可以想像这样一个场景,假设一个视频会议系统只支持Opus编码器,此时想要把一路电话语音添加进来,那么这个系统此时就无能为力了。因此,这个时候就体现出插件化管理的优势,我们可以将各种音视频编解码器作为一个插件注册到管理器种。当想要使用某种编码器的时候,可以通过参数设定,这样从音视频采集模块采集到的数据就会被送往对应的编码器进行编码。
webrtc(C++ sdk)中用于创建音频编码/解码器的类是AudioEncoderFactory/AudioDecoderFactory,用于创建视频编码/解码器的类是WebRtcVideoEncoderFactory/WebRtcDecoderFactory
感兴趣的朋友可以找源码来看看。
(3)网络传输模块
这部分我讲简单介绍一下webrtc涉及到的网络传输协议RTP和RTCP,RTP(Realtime Transport Protocol,实时传输协议)主要用来传输对实时性要求比较高的数据,比如音频频数据。RTCP(RTP Transport Control Protocol,RTP传输控制协议),主要用来监控数据传输的质量,并在会话双方之间进行同步,方便webrtc根据传输质量进行动态调整,比如传输速率,视频的码率等。
我们先来看一下RTP协议头的组成部分:

图3.3 RTP协议头
虽然TCP是一种可靠的传输协议,它可以保证数据在传输过程中不丢失,不乱序。但是它的可靠性是以牺牲实时性为代价的。特别是在一些极端的网络情况下,每个包的时延可以达到秒级以上,这个对于音视频实时通信是不能接受的。所以RTP选择的传输协议是UDP,但是为了保证数据的传输的可靠性就需要引入上面这些字段作为校验。
| 字段名 | 字段位数(bit) | 字段含义 |
| V | 2 | Version字段,表示RTP的版本 |
| P | 1 | Padding字段,表示RTP包是否有填充值,为1时表示有填充,填充以字节为单位。 |
| X | 1 | extension字段,表示是否有扩展头,如果有,则会放在CSRC后面 |
| CC | 4 | CSRC Count字段,表示CSRC的数量,每个CSRC占4个字节。 |
| M | 1 | Mark字段,其含义由配置文件决定。一般情况下用于标识边界,比如一帧H264被分成多个包发送,最后一个包的M位会被置位,表示这一帧数据结束了 |
| PT | 7 | PayloadType字段,通过该字段可以将不用类型的数据区分出来,比如VP8的PT一般是96,而Opus的PT一般为111 |
| Sequence Number | 16 | 编号字段,编号是连续的,接受端可以通过编号来判断哪些包丢失了。 |
| timeStamp | 32 | 时间戳字段,标识着RTP数据包中第一个字节的采样时间。 |
| SSRC | 32 | Synchronization Source字段,同步源标识符,流媒体可以将多个不同源的数据包通过同一个端口发送给客户端,SSRC就是用来标识数据包的来源,每个流的SSRC都不同,SSRC的值是一个随机数 |
| CSRC list | N*32位 | Contributing Source,用于标识此RTP数据包中的数据来源。比如混音数据是由三个音频混合而成,那么这三个音频源的SSRC标识符就会放入此表中,N由CC决定。最大数量为15个,当数量超过15个时,仅识别15个 |
我们再来看一下RTCP的协议头组成

图3.4 RTCP协议头
| 字段名 | 字段位数(bit) | 字段含义 |
| Version | 2 | 版本号 |
| P | 1 | Padding字段,表示RTCP包是否有填充值,1为有填充 |
| PT | 8 | Payload Type,消息类型 ,详见表3.5 |
| Count | 5 | 该值针对RTCP中不同报文有不同的含义: 对于RR/SR报文而言,Count表示它们所携带 的接收报告的个数;对SDES报文而言,Count表示SDES报文中item的个 数;对于BYE报文而言,Count表示BYE报文中SSRC/CSRC的个数;而对 于APP报文来说变化就比较大了,Count用于标识应用自定义的子消息 类型 |
| Length | 16 | 表示整个RTCP包的大小,包括RTCP头,RTCP负载以及填充字节,该字段中大小的表示比较有意思,使用4个字节为1组,长度共有几个4个字节的组,然后用该长度减去1,即为RTCP包中的长度!举个例子:假设RTCP数据包的长度为32个字节,32/4=8,总共有8组4个字节,8-1=7,此时RTCP数据包中length的值为7。 |
| Data | N*32 | 不同类型的RTCP中存放的Data千差万别 |

图3.5 RTCP支持的消息类型
(4)音视频渲染模块
音视频渲染简单来说就是音视频采集的逆向过程,客户端将接收到的音视频数据包送入相对应的解码器解码得到PCM数据或者是YUV/RGB数据,然后经过数模转换通过麦克风播放或者在屏幕上显示出来。常见的渲染引擎有DirectX,OpenGL,SDL等
三、资源推荐
(1)网站:
移动端实时音视频直播技术详解(一):开篇-实时音视频/专项技术区 - 即时通讯开发者社区!
推荐理由:这是一个有一定年代但一直比较活跃的即时通信社区,涵盖了网络编程基础,即时通信系统架构,大厂技术解决方案,音视频技术,流媒体开发等相关的各种优质资源。
(2)博客
[总结]视音频编解码技术零基础学习方法_雷霄骅的博客-CSDN博客_雷霄骅
推荐理由:雷神就不需要我多说了,许多音视频开发小白路上的指路明灯,对于音视频的底层原理了解的非常透彻,博客总计有1634万+次访问。(但是很不幸,作者在2016年去世 了)。
(3)书籍
《WebRTC音视频实时互动技术:原理、实战与源码分析》
推荐理由:作者李超,有十多年的实时音视频开发经验,先后任职沪江网高级架构师、新东方音视频技术专家。想推荐这本书的原因主要是(1)这本书是2021年出版的,是可以跟上这个时代的 (2)书不太长,很容易读 (3)书中的原理图非常多而且画的很生动清晰,对于理解内容很有帮助 (4)书中的叙述接近于口语化,就好像你公司的技术大牛在讲给你听一样 (5)书中讲的内容实操性很强,可以跟着做。(最后有一点要提醒一下,就是书中有一些错误,作者已经在下面这个网站标注出来了,再版的时候应该会改掉,可以结合书一起看《WebRTC音视频实时互动技术--原理、实战与源码分析》勘误表 | 音视跳动科技
(4)github仓库
GitHub - 0voice/audio_video_streaming: 音视频流媒体权威资料整理,500+份文章,论文,视频,实践项目,协议,业界大神名单。
推荐理由:音视频流媒体权威资料整理,精选文章,学术论文,大佬视频,实践项目,开源框架,协议,业界大神一览。star数有2.9k。
本文参考:
语音编解码器 2 - c6000 - 博客园
移动端实时音视频直播技术详解(四):编码和封装-实时音视频/专项技术区 - 即时通讯开发者社区!
[总结]视音频编解码技术零基础学习方法_雷霄骅的博客-CSDN博客_雷霄骅
走进音视频的世界——新一代开源编解码器AV1_徐福记456的博客-CSDN博客_av1开源
《WebRTC音视频实时互动技术:原理、实战与源码分析》(作者:李超)