猿创征文|电商 “猜你喜欢“ 商品推荐TiKV应用实战
一 背景介绍
为了提供用户体验,促进交易转化,公司计划上线"猜你喜欢"商品推荐功能。一句话描述,就是针对不同的用户,"猜你喜欢"展示不同的商品。"猜你喜欢"的功能类似如下图:

这是一个重要的功能,需要跨部门合作完成。算法部门的同学主要负责分析用户行为,使用模型,计算出不同用户展示的商品信息。基础架构部门负责提供相应的数据存储。我作为服务端的研发同学,主要负责"猜你喜欢"功能与APP前端交互部分,主要涉及到具体推荐数据存储,API交互等部分。我们协同作战,一起完成这个项目。
二 需求分析
开展具体技术研发之前,我首先需要对数据指标进行了确定,主要分为容量预估和响应时间预估两部分。
容量预估
我们公司的APP目前DAU100w, MAU 2500 w。对于存量用户数据,需要处理最近3个月登陆过APP的用户,按照平均MAU预估, 2500w * 3 = 7500 w。
对于增量用户,每天约有 10w, 一个月新增约为 10w * 31 = 310w 。因此,未来 6 个月预计的数据总量为 7500w + 310w * 6 = 9360 w。
我们在预估数据存储容量的时候,一般会留有40%的空间, 9360w ➗ 0.6 = 15600 w。
根据上面的计算,我们的数据存储服务,需要满足 15600 w 的数据存储。
响应时间预估
我们的服务是直接面向用户的交互,"猜你喜欢"的RT需要在 100 ms 内完成。
数据存储设计
根据上述的分析,推荐数据量大,响应时间短,我们计划存储设计为Key-Value 结构。其中Key 为recommendGoods:userId,Value 为 {"goodsIds":"1,2,3,4"} 只存储推荐商品的id。
根据上面的容量预估,响应时间预估,存储设计,我需要调研一种支持大数据量的Key-Value 结构,持久化的数据库。
三 TiKV实战
基于以上数据指标,我开始搜索查阅相关资料,发现了 TiKV 这个国产数据库。TiKV是 TiDB 的重要组成部分。
为什么会选择TiKV呢?
首先,TiKV 支持 Key-Value 模型,并且提供有序遍历方法。我们可以把 TiKV 看做一个巨大的 Map,其中 Key 和 Value 都是原始的 Byte 数组,在这个 Map 中,Key 按照 Byte 数组总的原始二进制比特位比较顺序排列。
其次,TiKV 把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。RocksDB 是一个非常优秀的开源的单机存储引擎,可以简单的认为 RocksDB 是一个单机的 Key-Value Map。
TiKV 还是分布式数据库,TiKV 实现了Raft协议,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到 Group 的多数节点中。 通过实现 Raft,TiKV拥有了一个分布式的 KV,实现了数据的高可用。
理解了TiKV的基本概念,那一次具体读写的过程是如何完成的呢?
我参考官方文档,总结了下图:
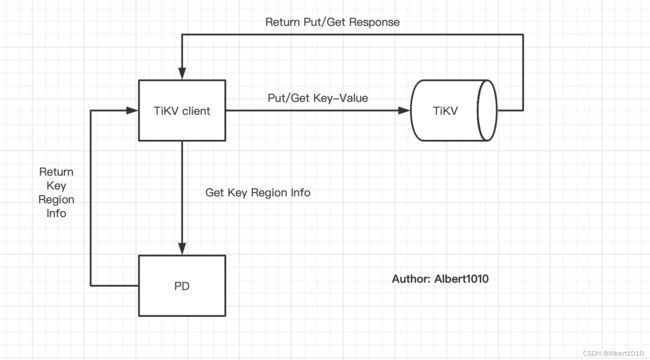
上图中有一些名词需要说明一下,其中 PD 是 Placement Driver 的缩写,是整个 TiDB 集群的元信息管理模块,主要负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构。
另一个名词是 Region。TiKV 是一个巨大的有序的 Key-Value Map,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,其中每一段叫做一个 Region,并且我们会尽量保持每个 Region 中保存的数据不超过一定的大小(默认是 96mb)。
我们以写入数据 key: recommendGoods:1 value: {"goodsIds":"1"} 为例子,描述一下具体写过程,主要步骤如下:
1. Client 向 PD 获取 recommendGoods:1 所在的 Region
2. PD 返回 Region 相关信息。
3. Client 将 PUT 命令相关信息发送给 Leader 所在的 TiKV。
4. Leader 所在的 TiKV 接受请求之后执行 Raft 流程,将 key: recommendGoods:1,value: {"goodsIds":"1"} 写入到 RocksDB 并将结果返回Client。
我们以获取数据 key: recommendGoods:1 为例子,描述一下具体读过程,主要步骤如下:
1. Client 向 PD 获取 recommandGoods:1 所在的 Region
2. PD 返回 Region 相关信息。
3. Client 将 GET 命令相关信息发送给 Leader 所在的 TiKV。
4. Leader 所在的 TiKV 接受请求之后执行 GET 并将结果返回Client。
基本读写过程清楚之后,如何在项目中使用呢?
首先,在POM中,引入TiKV包
org.tikv
tikv-client-java
2.0-SNAPSHOT
接着编写配置类:
@Slf4j
@Configuration
public class TiKvConfig {
@Value("${tikv.address}")
private String address;
@Bean("rawKVClient")
public RawKVClient rawKVClient() {
TiConfiguration configuration = TiConfiguration.createRawDefault(address);
TiSession session = TiSession.create(configuration);
return session.createRawClient();
}
}编写 Service
@Service
@Slf4j
public class TiKvService {
final
RawKVClient rawKVClient;
@Autowired
public TiKvService(RawKVClient rawKVClient) {
this.rawKVClient = rawKVClient;
}
public void put(ByteString key, ByteString value) {
rawKVClient.put(key, value);
}
public String get(ByteString key) {
ByteString result = rawKVClient.get(key);
if (result == null) {
return "";
}
return result.toStringUtf8();
}
}
完成上述基础功能编码之后,TiKV就可以在我们的项目中使用了,编写相关的业务逻辑,实现功能。上面的内容只介绍了基本的概念和特性,深入的源码分析,请大家去阅读一下TiDB官方文档,会很有收获。
四 小结
通过上述的技术调研分析,确定了选取TiKV做为“猜你喜欢”的数据存储。后续,与基础架构,算法,前端,测试,产品等同学一起合作,上线了项目,提升了交易转化率。
各个系统千差万别,建议大家在实战中,更深的体会TiKV的用途。希望本文介绍实战经验,比如如何进行容量预估,存储设计与选型,能给大家一些借鉴和参考。