100天精通Python(数据分析篇)——第58天:Pandas读写数据库(read_sql、to_sql)

文章目录
- 每篇前言
- 一、read_sql()
-
- 1. sql
- 2. con
- 3. index_col
- 4. coerce_float
- 5. params
- 6. parse_dates
- 7. columns
- 8. chunksize
- 二、to_sql()
-
- 1. name
- 2. con
- 3. schema
- 4. if_exists
- 5. index
- 6. index_label
- 7. chunksize
- 8. dtype
每篇前言
作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进两百人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!


支持大部分主流关系型数据库,例如MySQL,需要相应的数据库模块支持,相应接口为read_sql()和to_sql()
一、read_sql()
语法格式:
pandas.read_sql(
sql,
con,
index_col: str | Sequence[str] | None = None,
coerce_float: bool = True,
params=None,
parse_dates=None,
columns=None,
chunksize: int | None = None,
)
参数说明:
-
sql:需要执行的sql语句
-
con:连接sql数据库的engine,通常用sqlalchemy (首选)、pymysql等包建立
-
index_col:选择哪列作为index
-
coerce_float:将数字形字符串转为float
-
params:list,tuple或dict,optional,default:None; 要传递给执行方法的参数列表。
-
parse_dates:将某列日期型字符串转换为datetime型数据
-
columns:选择想要保留的列。这个参数很少用到,因为一般SQL里面就选择需要的列了
-
chunksize:每次输出多少行数据
1. sql
需要执行的sql语句,类型为字符串
# 需要执行的SQL语句
sql = "SELECT * FROM table"
2. con
连接sql数据库的engine,通常用sqlalchemy (首选)、pymysql等包建立
(1)方式1:sqlalchemy
import pandas as pd
import sqlalchemy
# 创建数据库连接
conn= sqlalchemy.create_engine('mssql+pymssql://账号:密码@服务器地址:端口号/库名')
# 需要查询的sql语句
sql = "SELECT * FROM table"
data_df = pd.read_sql(sql, conn)
(2)方式2:pymysql,其他数据库也是同理
import pymysql
import pandas as pd
# 创建数据连接
conn = pymysql.connect(
host='服务器地址',
port=端口号,
user=账号,
passwd=密码,
db=库名,
charset='utf8'
)
# 需要查询的sql语句
sql = "SELECT * FROM table"
data_df = pd.read_sql(sql, conn)
表中数据如下:
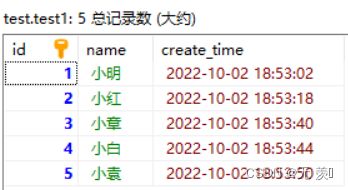
运行结果:

3. index_col
选择哪列作为index。字符串或字符串列表,可选,默认值:无
(1)接收字符串:
import pandas as pd
import sqlalchemy
import pymysql
# 创建数据库连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="123456",
database="test")
sql = "SELECT * FROM test1"
# 已id列作为索引
data = pd.read_sql(sql, conn, index_col='id')
print(data)
运行结果:

(2)接收列表:
import pandas as pd
import sqlalchemy
import pymysql
# 创建数据库连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="123456",
database="test")
sql = "SELECT * FROM test1"
# 以id、name两列为索引
data = pd.read_sql(sql, conn, index_col=['id','name'])
print(data)
运行结果:

4. coerce_float
接收boolean,默认为True。尝试将非字符串,非数字对象(如decimal.Decimal)的值转换为浮点,这对SQL结果集很有用。
5. params
检查数据库驱动程序文档。接收参数:list,tuple或dict,optional,default:None,要传递给执行方法的参数列表。用于传递参数的语法取决于数据库驱动程序。
import pandas as pd
import sqlalchemy
import pymysql
# 创建数据库连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="123456",
database="test")
sql = "SELECT * FROM test1 WHERE id BETWEEN %(low)s and %(high)s"
# 查询id在1-2之间的数据
data = pd.read_sql(sql, conn, params={"low": 1, "high": 2})
print(data)
运行结果:

6. parse_dates
将某列日期型字符串转换为datetime型数据,与pd.to_datetime()函数功能类似。接收参数:list or dict, default: None,列表或者字典,默认为 None
(1)接收字符串:
import pandas as pd
import sqlalchemy
import pymysql
# 创建数据库连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="123456",
database="test")
sql = "SELECT * FROM test1"
data = pd.read_sql(sql, conn, parse_dates=['create_time'])
print(data)
print(data.dtypes)
运行结果:

(2)接收字典:
import pandas as pd
import sqlalchemy
import pymysql
# 创建数据库连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="123456",
database="test")
sql = "SELECT * FROM test1"
data = pd.read_sql(sql, conn, parse_dates={'create_time': {"format": "%Y:%m:%H:%M:%S"}})
print(data)
print(data.dtypes)
7. columns
选择想要保留输出的列,接收类型列表字符串。这个参数很少用到,因为一般SQL里面就选择需要的列了
import pandas as pd
import sqlalchemy
import pymysql
# 创建数据库连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="123456",
database="test")
sql = "SELECT * FROM test1"
# 读取id、name两列
data = pd.read_sql(sql, conn, columns=['id', 'name'])
print(data)
8. chunksize
设置整数,如20000,⼀次写⼊数据时的数据⾏数量,当数据量很⼤时,需要设置,否则会链接超时写⼊失败。设置后返回一个迭代器对象
import pandas as pd
import sqlalchemy
import pymysql
# 创建数据库连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="123456",
database="test")
sql = "SELECT * FROM test1"
# 查询id在1-2之间的数据
data = pd.read_sql(sql, conn, chunksize=3)
print(data)
运行结果:

二、to_sql()
语法格式:
pd.to_sql(
self,
name: str,
con,
schema=None,
if_exists: str = "fail",
index: bool_t = True,
index_label=None,
chunksize=None,
dtype: DtypeArg | None = None,
method=None,
) -> None:
参数说明:
- name:指定插入数据的数据库中的表名。
- con:与read_sql中相同,数据库连接的驱动。推荐使⽤sqlalchemy的engine类型
- schema:相应数据库的引擎,不设置则使⽤数据库的默认引擎,如mysql中的innodb引擎
- if_exists:当数据库中已经存在数据表时对数据表的操作,有replace替换、append追加,fail则当表存在时提⽰
- index:是否写入DataFrame对象的索引。默认TRUE写入
- index_label:当上⼀个参数index为True时,设置写⼊数据表时index的列名称
- chunksize:设置整数,如20000,⼀次写⼊数据时的数据⾏数量,当数据量很⼤时,需要设置,否则会链接超时写⼊失败。
- dtype: 指定列的输出到数据库中的数据类型。字典形式储存:{column_name: sql_dtype}
1. name
需要操作数据库的表名,接收字符串类型。
2. con
与read_sql中相同,数据库连接的驱动。推荐使⽤sqlalchemy的engine类型
3. schema
相应数据库的引擎,不设置则使⽤数据库的默认引擎,如mysql中的innodb引擎
4. if_exists
当数据库中的这个表存在的时候,采取的措施是什么,包括三个值,默认为fail
- fail:若表不存在新建表;若表存在,则报错
- replace:将数据库表中的数据覆盖
- append(常用):在数据表后面追加数据
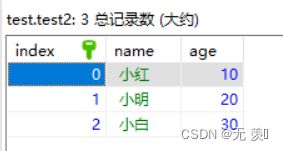
(1)fail:
import pandas as pd
from sqlalchemy import create_engine
data = {'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]}
df = pd.DataFrame(data)
print(df)
con = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
df.to_sql('test2', con, if_exists='fail')
运行结果:直接给我们创建了新表
(2)replace:
import pandas as pd
from sqlalchemy import create_engine
# 把名字修改了
data = {'name': ['张三', '李四', '王五'], 'age': [10, 20, 30]}
df = pd.DataFrame(data)
print(df)
con = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
df.to_sql('test2', con, if_exists='replace')
运行结果:

(3)append:
import pandas as pd
from sqlalchemy import create_engine
data = {'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]}
df = pd.DataFrame(data)
print(df)
con = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
df.to_sql('test2', con, if_exists='append')
运行结果:

5. index
对DataFrame的index索引的处理,为True时索引也将作为数据写⼊数据表
(1)index=TRUE:
import pandas as pd
from sqlalchemy import create_engine
data = {'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]}
df = pd.DataFrame(data)
print(df)
con = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
df.to_sql('test2', con, if_exists='fail',index=True)
运行结果:直接给我们创建了新表
(2)index=False:
import pandas as pd
from sqlalchemy import create_engine
data = {'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]}
df = pd.DataFrame(data)
print(df)
con = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
df.to_sql('test3', con, if_exists='fail', index=False)
运行结果:

6. index_label
当上⼀个参数index为True时,可以修改写⼊数据表时index的列名称,接收列表类型参数。
import pandas as pd
from sqlalchemy import create_engine
data = {'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]}
df = pd.DataFrame(data)
print(df)
con = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
df.to_sql('test4', con, if_exists='fail', index=True, index_label='RID')
运行结果:可以看到索引列名已修改

7. chunksize
设置整数,如20000,⼀次写⼊数据时的数据⾏数量,当数据量很⼤时,需要设置,否则会链接超时写⼊失败。
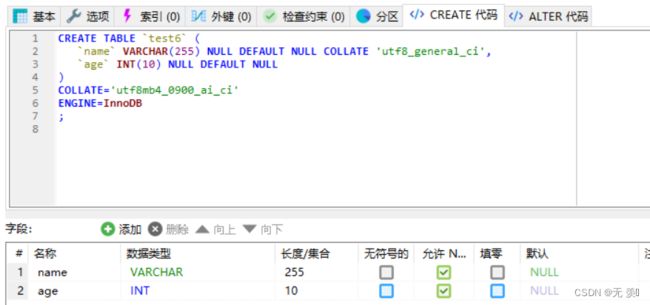
8. dtype
指定列的输出到数据库中的数据类型。字典形式储存:{column_name: sql_dtype}
import pandas as pd
from sqlalchemy import create_engine
import sqlalchemy
data = {'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]}
df = pd.DataFrame(data)
print(df)
# 设置数据库字段类型
dtype = {'name': sqlalchemy.types.VARCHAR(length=255),
'age': sqlalchemy.types.INT,
}
con = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
df.to_sql('test6', con, if_exists='fail', index=False,dtype=dtype)
运行结果: