【目标检测-YOLO】YOLOX(第一篇)
文章链接:https://arxiv.org/pdf/2107.08430.pdf
YOLOX是2021年8月 旷视发布的一篇论文,它是继YOLOv1后第一篇Anchor-free 的YOLO目标检测框架。本文对论文进行学习。
YOLOX: Exceeding YOLO Series in 2021
摘要
YOLOX:anchor-free;decoupled head;label assignment strategy:SimOTA
YOLONano:0.91M parameters;1.08G FLOPs;COCO:25.3% AP,超过 NanoDet 1.8% AP;
YOLOv3:COCO:47.3% AP;
YOLOX-L:COCO:50.0% AP;Tesla V100:68.9 FPS;超过 YOLOv5-L 1.8% AP;
源码:https://github.com/ Megvii-BaseDetection/YOLOX
1. 引言
YOLOv2:anchors;YOLOv3:Residual Net;YOLOv5-L:COCO:48.2%AP,13.7 ms(这里是YOLOv5-5.0版本,新版本6.1已经是49%AP)。
过去两年,学术界主要在研究:anchor-free detectors,advanced label assignment strategies,end-to-end (NMS-free) detectors。YOLO家族里还没这些玩意,因为 YOLOv4 and YOLOv5 仍然是anchor-based的检测器,带有 hand-crafted 的训练分配规则。
本文目的是将这些玩意引入到YOLO架构中,选择基线模型:YOLOv3-SPP。
2. YOLOX
2.1. YOLOX-DarkNet53
baseline:YOLOv3 with Darknet53
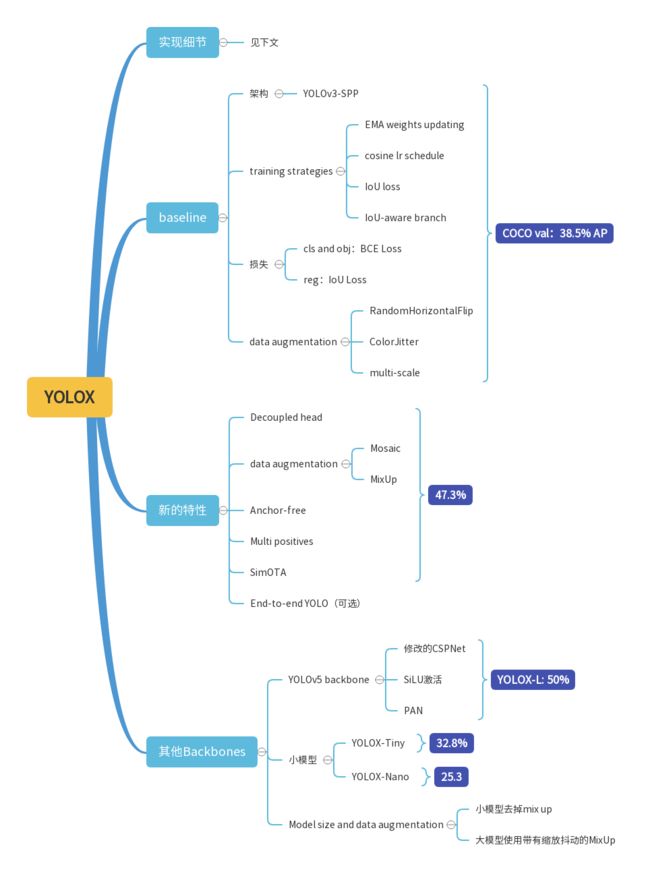
实现细节
COCO train2017上:5 epochs warmup,总计 300 epochs;SGD;learning rate:lr×BatchSize/64 (linear scaling),initial lr = 0.01 and the cosine lr schedule;weight decay:0.0005;SGD momentum:0.9;batch size:128,8-GPU;input size:from 448 to 832 with 32 strides;FPS and latency:a single Tesla V100 FP16-precision and batch=1。
YOLOv3 baseline
YOLOv3-SPP 架构:DarkNet53 backbone,SPP
training strategies 改变:
- EMA weights updating
- cosine lr schedule
- IoU loss
- IoU-aware branch
cls and obj:BCE Loss; reg:IoU Loss
data augmentation:RandomHorizontalFlip, ColorJitter and multi-scale
去掉 RandomResizedCrop:原因与 mosaic augmentation 重叠
以上全部作为:baseline,COCO val:38.5% AP
Decoupled head
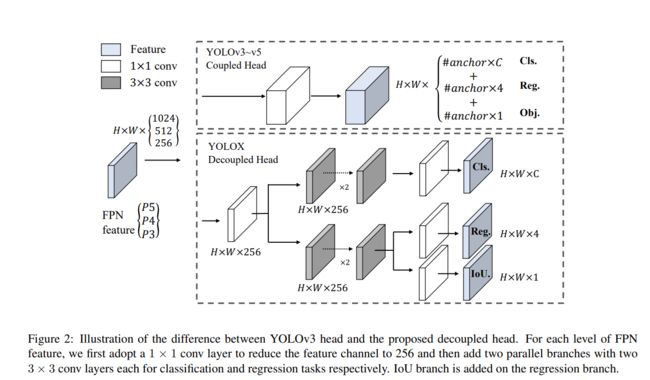
在目标检测中,分类和回归任务之间的冲突是一个众所周知的问题。因此,用于分类和定位的Decoupled head 被广泛应用于大多数单级和两级探测器中。然而,作为YOLO系列的backbones和特征金字塔(如FPN,PAN)不断演化,它们的detection heads 保持耦合,如图2所示。
我们的两个分析实验表明,耦合检测头可能会损害性能。

- 解耦后的YOLO head大大提高了收敛速度,如图3所示。
- 解耦的头对于端到端版本的YOLO是必不可少的(将在下面描述)。
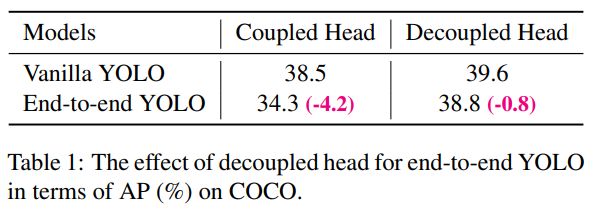
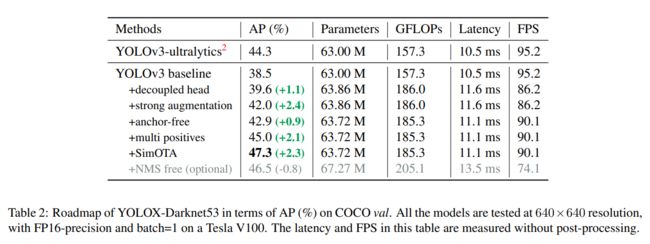
从表1可以看出,耦合头的端到端特性会减少4.2% AP,而解耦头的端到端特性会减少0.8% AP。因此,我们将YOLO检测head替换为一个简单的解耦head,如图2所示。具体来说,它包含一个1 × 1的conv层来减小通道的维数,然后是两个平行分支,分别包含两个3 × 3的conv层。我们在表2中报告了V100上batch=1的推理时间,解耦头带来了额外的1.1ms (11.6 ms vs 10.5 ms)。
Strong data augmentation
Mosaic and MixUp
MixUp 最初是为图像分类任务而设计的,后来在BoF(论文:Bag of freebies for training object detection neural networks.)中进行了修改,用于目标检测训练。
在最后的15个 epochs时候关闭它们。42.0% AP。
在使用Strong data augmentation后,我们发现ImageNet的预训练并没有更大的好处,因此我们从头开始训练以下所有模型。
Anchor-free
anchor mechanism有许多已知的问题:
- 为了达到最优的检测性能,需要在训练前进行聚类分析,确定一组最优的anchors。这些聚集的anchors是domain-specific 的,less generalized。
- anchor mechanism增加了检测头的复杂度,也增加了每幅图像的预测的个数。在一些边缘AI系统中,在设备之间移动如此大量的预测(例如,从NPU到CPU)可能会成为整体延迟的潜在瓶颈。
Anchor-free detectors 在过去的两年中发展迅速。许多工作表明,Anchor-free detectors 的性能可以与anchor-based detectors 相媲美。Anchor-free mechanism 大大减少了需要启发式调优的设计参数的数量和许多技巧(如Anchor Clustering,Grid Sensitive),从而获得了良好的性能,使检测器,特别是其训练和解码阶段,大大简化。
将YOLO转换为anchor-free 模式非常简单。我们将每个位置的预测从3减少到1,并让它们直接预测4个值,即网格左上角的两个偏移量,以及预测框的高度和宽度。我们分配每个目标定位中心作为正样本,正如 Fcos 做的一样,预先定义一个scale范围来指定每个目标的FPN level。这样的修改降低了detector的参数和GFLOPs,使其速度更快,但获得了更好的性能- 42.9%的AP,如表2所示。
Multi positives
与YOLOv3的分配规则一致,以上的 anchor-free 版本为每个目标只选择一个正样本(中心位置),同时忽略其他高质量的预测。然而,优化这些高质量的预测也可能带来有益的梯度,这可能会缓解正/负采样在训练中的极端不平衡。我们简单地将中心3×3区域赋值为正,在 FCOS 中也称为“中心采样”。检测器的性能提高到45.0%的AP,如表2所示,已经超过了 ultralytics-YOLOv3 (44.3% AP2 )目前的最佳实践。
SimOTA
基于旷世自己的研究 OTA ,总结了四个关于高级标签分配的关键观点:
- loss/quality aware
- center prior
- dynamic number of positive anchors(在anchorfree detectors 上下文中 anchor 指的是“anchor point”,在YOLO上下文中指的是““grid”。) for each ground-truth (abbreviated(简称) as dynamic top-k)
- global view
OTA满足上述四个规则,因此我们选择它作为候选标签分配策略。
具体来说,OTA 从全局的角度分析标签分配,并将分配过程表述为一个最优运输(Optimal Transport, OT)问题,产生了当前分配策略中的SOTA性能。然而,在实践中,我们发现通过Sinkhorn-Knopp 算法来解决OT问题带来了25%的额外训练时间,这对于训练300个epoch来说是相当昂贵的。因此,我们将其简化为dynamic top-k策略,命名为SimOTA,以得到近似解。
SimOTA首先计算成对匹配度,对每个 prediction-gt pair 对用 cost 表示或 quality 。例如,在SimOTA中,gt 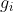 与 prediction
与 prediction 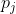 之间的 cost 计算如下:
之间的 cost 计算如下:
![]() (1)
(1)
这里,λ是一个平衡系数。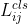 和
和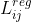 是 gt 与 prediction 之间的分类损失和回归损失。然后,对于 gt ,我们选择固定中心区域内cost最小的前k个预测作为其正样本。最后,将这些正预测对应的grids赋值为正,其余grids赋值为负。注意,k值随 ground-truth 的不同而变化。更多细节请参考OTA 中的Dynamic k Estimation策略。
是 gt 与 prediction 之间的分类损失和回归损失。然后,对于 gt ,我们选择固定中心区域内cost最小的前k个预测作为其正样本。最后,将这些正预测对应的grids赋值为正,其余grids赋值为负。注意,k值随 ground-truth 的不同而变化。更多细节请参考OTA 中的Dynamic k Estimation策略。
SimOTA不仅减少了Sinkhorn-Knopp算法的训练时间,而且避免了额外的求解超参数。如表2所示,SimOTA将 detector 的AP从45.0%提高到47.3%,比SOTA ultralytics-YOLOv3提高了3.0% AP,显示了该高级分配策略的威力。
End-to-end YOLO
我们按照(Object detection made simpler by eliminating heuristic nms)添加两个额外的 conv 层,one-to-one label assignmen 和stop gradient。
这使得检测器能够以端到端方式执行,但会略微降低性能和推理速度,如表2所示。因此,我们将它作为一个可选模块,不涉及到我们的最终模型。
2.2 其他的Backbones
Modified CSPNet in YOLOv5
为了进行比较,我们采用的正是YOLOv5的backbone,包括经过修改的CSPNet、SiLU激活和PAN head。产出了 YOLOXS, YOLOX-M, YOLOX-L, and YOLOX-X models 均遵循其比例规律。与表3中的YOLOv5相比,我们的模型得到了AP ~ 3.0% ~ 1.0%的一致改善,只增加了很小的时间(来自decoupled head)。
Tiny and Nano detectors
为了与YOLOv4-Tiny 相比较,我们进一步缩小了我们的模型YOLOX-Tiny。对于移动设备,我们采用深度卷积的方法来构建YOLOX-Nano模型,该模型只有0.91M参数和1.08G FLOPs。如表4所示,YOLOX即使在模型较小的情况下也表现良好。

Model size and data augmentation
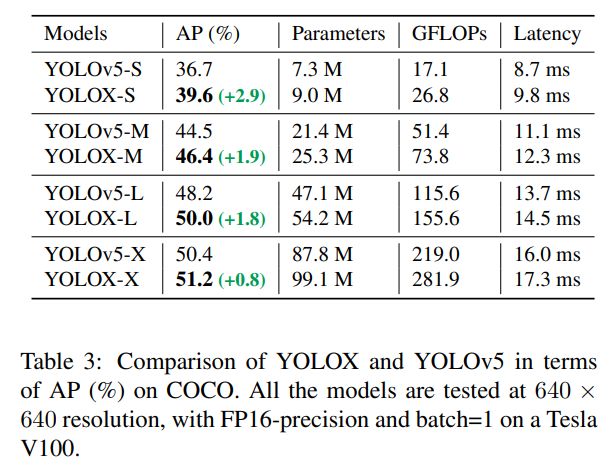
在我们的实验中,所有的模型保持了几乎相同的learning schedule和优化参数,如2.1所示。然而,我们发现合适的augmentation策略因模型大小的不同而不同。如表5所示,在对YOLOX-L应用MixUp可以提高AP 0.9%的同时,对于YOLOX-Nano这样的小模型,减弱增强效果更好。具体来说,我们在训练小型模型(即YOLOX-S、YOLOX-Tiny和YOLOX-Nano)时,去除mix up增强,削弱mosaic (将尺度范围从 [0.1, 2.0] 减小到[0.5, 1.5])。通过这种修改,YOLOX-Nano的AP从24.0%提高到了25.3%。
对于大型模型,我们还发现更强的增强效果更有帮助。实际上,我们的MixUp实现比(Bag of freebies for training object detection neural networks.)中的原始版本更重。受 Copypaste 的启发,我们在 mixing up 它们之前,通过随机采样比例因子来抖动这两个图像。为了理解带有缩放抖动的Mixup的功能,我们将其与YOLOX-L上的 Copypaste 进行了比较。注意,Copypaste 需要额外的实例掩码注释,而MixUp不需要。但如表5所示,这两种方法获得了有竞争的性能,表明当没有实例掩码注释可用时,带有缩放抖动的MixUp是Copypaste的合格替代品。
3. Comparison with the SOTA
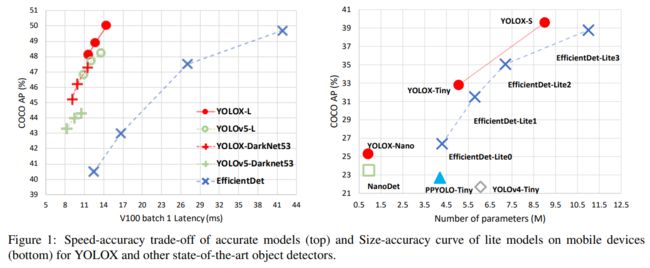
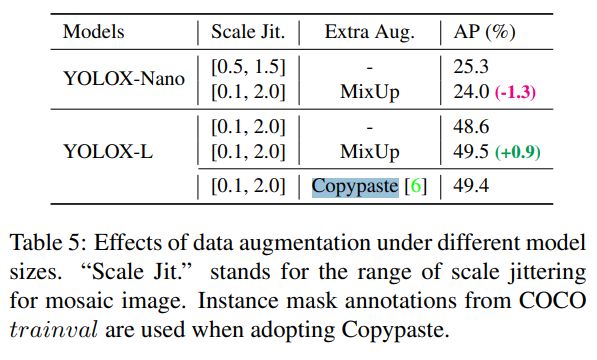
有一个传统来显示SOTA比较表,如表6所示。但是,请记住,该表中模型的推理速度通常是不受控制的,因为速度随软件和硬件的不同而不同。因此,对于图1中的所有YOLO系列,我们都使用相同的硬件和代码库,绘制出稍微受控制的速度/精度曲线。
我们注意到有一些模型较大的高性能YOLO系列,如 Scale-YOLOv4和YOLOv5-P6。目前基于Transformer(Swin transformer)的detectors 将精确度- sota提升到60 AP。由于时间和资源的限制,我们在本报告中没有探讨这些重要的特性。然而,它们已经在我们的视野内。
4. 1st Place on Streaming Perception Challenge (WAD at CVPR 2021)
Streaming Perception Challenge on WAD 2021 是通过一个最近提出的 metric: streaming accuracy,对准确性和延迟的联合评估。这个metric背后的关键点是,在每个时刻联合评估整个感知堆栈的输出,迫使堆栈考虑当计算发生时应该忽略的流数据的数量。我们发现,在30 FPS 的数据流上,metric 的最佳权衡点是一个推理时间为33ms的强大模型。所以我们采用了一个带有TensorRT的YOLOX-L模型来制作我们的最终模型,来挑战赢得第一名。详情请参考挑战网站。
5. Conclusion
在本报告中,我们介绍了一些实验更新到YOLO系列中,形成高性能anchorfree detectorYOLOX。YOLOX配备了一些最新的先进检测技术,如decoupled head、anchor-free和advanced label assigning strategy,在所有模型尺寸中,YOLOX实现了速度和准确性之间的更好的平衡。值得注意的是,我们将YOLOv3的架构提升到了47.3%的AP,比目前的最佳实践高出了3.0% AP。YOLOv3仍然是行业中使用最广泛的检测器之一,因为它具有广泛的兼容性。