ELK+zookeeper+kafka+filebeat集群
zookeeper:
为读多写少的场景所设计 并不是存储大规模业务数据
而是用于存储少量的状态和 配置信息,每个节点存储数据不能超过1MB
数据存储基于节点 znode(包含数据子节点 子节点引用 访问权限)
Zookeeper service 一主多从结构:
更新数据时 首先更新到主节点 (主节点是服务器)
leader:事务请求的调度处理者 负责投票的发起和决议 处理写请求 保证集群事务处理的顺序性
follower:转发事务请求给leader 参与投票 参与leader选举投票
observer:不参与投票 同步leader状态 目的是扩展系统 提高读取速度
client:执行读写请求的发起方
ZAB协议: 为了保证主从节点数据一致 采用ZAB协议
ZAB的三种节点状态:
looking:选举状态
following:从节点所处状态
leading:主机所处状态
崩溃恢复:zookeeper当前的主节点挂掉 集群就会进行 崩溃恢复
ZAB的崩溃恢复分为三个阶段:
1.leader election:选举阶段
2.discovery:发现阶段
3.synchornization:同步阶段
Zab 协议既不是强一致性 也不是弱一致性 而是处于两者之间的单调一致性 他依靠事务id和版本号 保证数据的更新和读取是有序的 。
zookeeper应用场景:
1.分布式锁:利用zookeeper的临时顺序节点 可以轻松实现分布式锁
2.服务器注册和发现:利用znode和watcher 可以实现分布式服务的注册和发现 阿里的分布式RPC框架和Dubbo
3.共享配置和状态信息:redis的分布式解决codis 就利用zookeeper 来存放 数据路由表和codis-proxy 节点的元信息 通过zookeeper同步到各个存活的的codis-proxy 此外,Kafka Hbase Hadoop 也都依靠zookeeper同步节点信息 是实现高可用。
zookeeper工作模式:
单机 集群 伪集群(就是在一台物理机上运行多个Zookeeper 实例)
集群模式:
实验环境:(搭建elk平台的Kafka集群 本节先部署zookeeper)
IP sever myid
192.168.42.101 kafka+zookeeper 1
192.168.42.102 kafka+zookeeper 2
192.168.42.103 kafka+zookeeper 3
zk服务器集群规模不得小于3个节点
要求各个服务器之间的系统时间保持一致。
zookeeper集群安装:
1.在三个节点解压程序 创建 数据库目录 安装jdk:
#创建zookeeper存放目录及数据库目录:
mkdir -p /opt/zookeeper/data
#解压程序:
tar -xf zookeeper-3.4.14.tar.gz -C /opt/zookeeper/
#安装JDK(如果已经安装过,可以跳过)
rpm -ivh jdk-8u45-linux-x64.rpm
echo -e 'export JAVA_HOME=/usr/java/jdk1.8.0_45\nexport CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH\nexport PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOMR/bin'>>/etc/profile
source /etc/profile
2.在192.168.42.101上修改配置文件,然后同步到其他两台上边:

!!!:zookeeper集群 每个节点的配置文件都是一样的 所以直接同步过去 不需要做任何修改。
3.创建myid文件:
#192.168.42.101
echo 1 > /opt/zookeeper/data/myid
#192.168.42.102
echo 2 > /opt/zookeeper/data/myid
#192.168.42.103
echo 3 > /opt/zookeeper/data/myid
4.启动服务和查看节点状态:
#三台节点同时执行如下命令启动服务并查看是否正常
/opt/zookeeper/zookeeper-3.4.14/bin/zkServer.sh start
页面结果显示:
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
/opt/zookeeper/zookeeper-3.4.14/bin/zkServer.sh status
页面结果显示:
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
5.输入jps查看进程:

6.查看zookeeper服务输出日志信息:
zookeeper常用操作指令:

消息队列:将信息(传输的)放入一个队列中
两种模式:点对点 发布订阅(对同一个主题,任何订阅的消费者都可以拉取信息)
在一个消息系统中,服务端是消息处理端 ,消息爆发时消息队列是一个很好的选择
什么是消息队列呢?
可以把它理解为 介于客户端与服务端之间的一个 消息中转站
三个主要作用:
1.应用解耦(高内聚低耦合)
2.流量削峰 (将客户端请求积压在消息队列里 服务器按照自己所能处理的速率按顺序来消费这些请求 保证服务器在任何情况下正常服务)
3.异步消息 (主要应用于请求需要等待的反馈结果情况:常用方式:用户通过网页下达了一条指令,当后台接收到这条指令并将它压到消息队列时就立即返回 “成功” 的提示,随后再等待各模块去执行这一指令。这种方式可以大大提升用户验)
Kafka: 发布订阅式的分布式流处理平台 主要是用于对数据流的存储和处理
kafka既然被当作消息队列来使用 核心功能: 高性能的消息发送与消费
它也是依赖于zookeeper的分布式消息队列。
Kafka:是一个分布式的流媒体平台,流媒体平台有三大功能:
1.发布和订阅记录流 类似于消息队列或者企业消息传递系统;
2.容错持久的方式存储记录流;
3.处理记录发生的流;
通常用于两大类应用:
1.构建可在系统或应用程序之间可靠获取数据的实时流数据管道
2.构建实时流应用程序 用于转换或响应数据流
特性:
高吞吐量 低延迟 可扩展性 (支持集群热扩展)
持久性可靠性 (消息队列被持久化到磁盘 并且支持数据备份防止丢失)
容错性(允许集群中节点失败 ) 高并发(支持数千客户端同时读写)
应用场景:
1.日志收集
2.消息系统
3.用户活动追踪(web用户或者app用户的各种活动 如 浏览网页等 把这些活动信息记录到Kafka的topic中进行实时的监控分析)
4.运营指标(用来记录运营监控数据 包括收集各种分布式应用的数据 生产各种操作的集中反馈 比如报警和报告)
5.流式处理:比如spark streaming和storm
6.事件源
Kafka 是依赖zookeeper集群的 一般最少要三台服务器来实现HA:三层
1.produces:消息生产者 (push消息给Brokers.发送时根据不同topic选择不同分区(在Broker上))
2.Brokers:注册在zookeeper节点上
3.Consumers:消息消费者
(从brokers上根据订阅的topic选择不同分区,poll数据,执行消费。)
topic:主题 是发布的消息的类别 一个主题可以有零个 一个或者多个 一个或者多个写入数据的消费者,对于每一个主题 Kafka集群都会维护一个分区日志
(在每个分区中 消息以顺序存储 最晚接收的 最后被消费)
Kafka基础知识及环境搭建:
实验环境:(搭建elk平台的Kafka集群 )
| IP |
Server |
broker.id |
| 192.168.42.101 |
Kafka+ZooKeeper |
1 |
| 192.168.42.102 |
Kafka+ZooKeeper |
2 |
| 192.168.42.103 |
Kafka+ZooKeeper |
3 |
1.在三个节点上解压程序:
先创建解压目录 mkdir /opt/kafka
tar -xf kafka_2.22-2.2.1.tgz -C /opt/kafka/
创建数据目录:
mkdir /opt/kafka/data
2.在192.168.42.101节点上修改配置文件并同步到其他两个节点上
绿色是需要修改的或者添加的:

.#同步配置文件到其他两台节点:
scp server.properties [email protected]:/opt/kafka/kafka_2.11-2.2.1/config/
scp server.properties [email protected]:/opt/kafka/kafka_2.11-2.2.1/config/
3.其他两个节点修改broker.id及监听IP
#192.168.42.102
broker.id=2
listeners=PLAINTEXT://192.168.42.102:9092
#192.168.42.103
broker.id=3
listeners=PLAINTEXT://192.168.42.103:9092
4.启动服务:
./bin/kafka-server-start.sh -daemon config/server.properties # 其他两台节点启动方式相
同
或者nohup bin/kafka-server-start.sh config/server.properties &
Kafka需要用到ZooKeepr所以需要先启动一个ZooKeepr服务端如果没有单独的ZooKeeper
服务端可以使用Kafka自带的脚本快速启动一个单节点ZooKeepr实例
# 启动zookeeper服务端实例
bin/zookeeper-server-start.sh config/zookeeper.properties
# 启动kafka服务端实例
bin/kafka-server-start.sh config/server.properties
验证操作:
1.新建一个主题topic:kafka-topic.sh
创建一个只有一个分区和一个备份名为“test”的topic
# ./bin/kafka-topics.sh --create --zookeeper 192.168.42.101:2181 --replication-factor 1 --partitions 1 --topic test
页面展示结果:
Created topic "test".
2.查看主题:运行list topic命令,查看该主题:
# ./bin/kafka-topics.sh --list --zookeeper localhost:2181
页面结果展示:
test
![]()
Kafka带有一个命令行客户端,它将从文件或标准输入中获取输入,并将其作为消息发送到Kafka集群。默认情况下,每行将作为单独的消息发送。
3、运行producer生产者,然后在控制台输入几条消息到服务器。
# ./bin/kafka-console-producer.sh --broker-list 192.168.42.101:9092 --topic test
>111
>this is a message
>this is anothet message
4、消费消息: kafka-console-consumer.sh
Kafka也提供了一个消费消息的命令行工具,将存储的信息输出出来
在另一台机器上或者不同终端上执行此命令,这样就能将消息键入生产者终端,并将它们显示在消费者终端
# ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.42.101:9092 --topic test --from-beginning
!接收到的消息可能会有延迟 比较慢
5.查看topic详细信息:
# ./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: 主题名称
Partition: 分片编号
Leader: 该分区的leader节点
Replicas: 该副本存在于哪个broker节点
Isr: 活跃状态的broker
![]()
ELK日志分析平台加入Kafka消息队列:
在之前的搭建elk环境中,日志的处理流程为:filebeat --> logstash --> elasticsearch,随着业务量的增长,需要对架构做进一步的扩展,引入kafka集群。日志的处理流程变为:filebeat --> kafka --> logstash --> elasticsearch
架构图如下所示:


ELK配置安装参考之前的课件
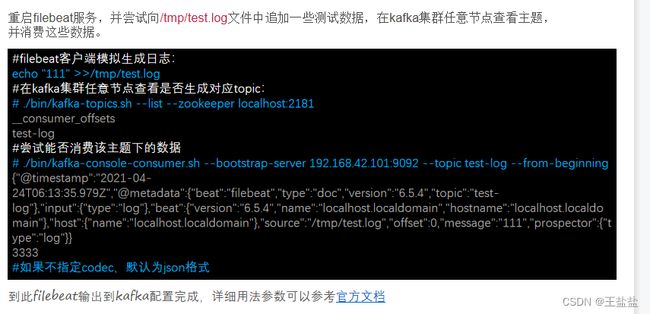
配置filebeat输出到kafka集群:
修改filebeat配置文件,配置输出到kafka:

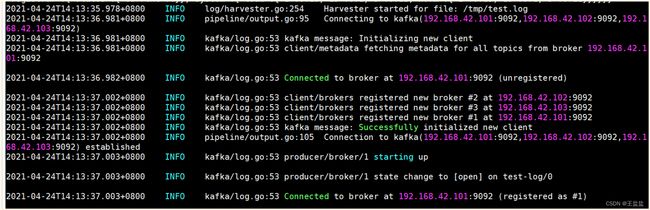
出现以下日志代表filebeat采集上了数据: