AI绘画发展史(伪):从免费到吃屎;YSDA·自然语言处理课程8K Star;伯克利CS285·深度强化学习课程;前沿论文 | ShowMeAI资讯日报

日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子
AI绘画发展史(伪) :不能提升生产力的创新,都是伪创新
微博博主 @西仔LittileC 绘制了一份AI绘画发展史,展示了从业者的担忧——并非抗拒技术进步带来的竞争和压力,而是担心已有行业的种种乱象在绘画行业重演,最终导致所有用户被动『吃屎』。
大平台免费致使从业人数减少、平台收取低价使用费用、用户必须购买会员/按月订阅/按年订阅才能使用、内容趋同千人一面··· 这个发展历程,我们太熟悉了···
工具&框架
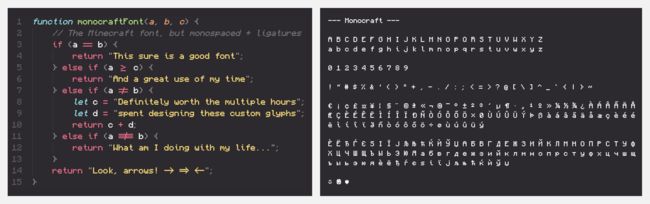
『Monocraft』Minecraft 前端字体
https://github.com/IdreesInc/Monocraft
https://idreesinc.com/
Monocraft 是为那些喜欢 Minecraft 的开发者提供的字体,这款字体模仿了 Minecraft UI 中使用的字体,但它不包括原游戏中的任何资产或字体文件。
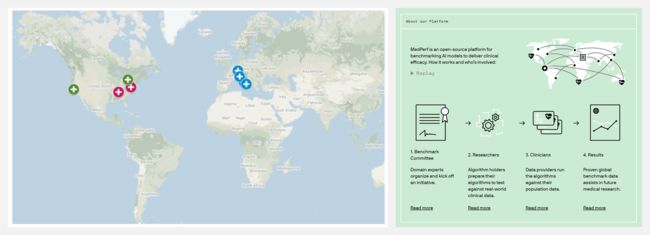
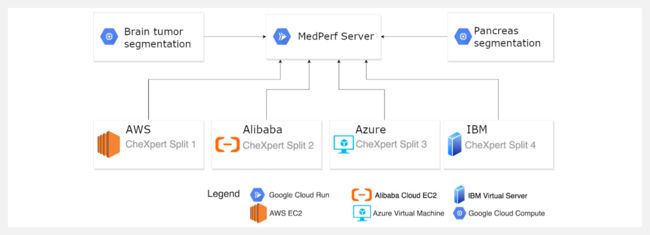
『MedPerf』医疗人工智能开放基准测试平台
https://github.com/mlcommons/medperf
https://www.medperf.org/
Medperf 是一个使用联邦评估的医疗人工智能开放基准测试平台。Repo中你可以找到运行 MedPerf 的所有重要部分,包括:MedPerf 服务器、MedPerf CLI、试点结果。
『streamlit audio recorder』麦克风管理器
https://github.com/stefanrmmr/streamlit_audio_recorder
https://stefanrmmr-streamlit-audio-recorder-streamlit-app-4wiha3.streamlitapp.com/
Streamlit 自定义组件,允许部署到 Web 的应用程序录制客户端麦克风的音频。通过浏览器的 Media-API 管理对麦克风的访问,在 streamlit 应用程序中录制、播放和恢复音频捕获,并将最终录制文件下载到本地系统(WAV,16 位,44kHz)。
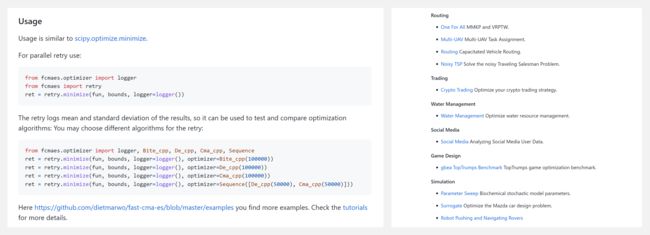
『fcmaes』一个 Python3 无梯度优化库
https://github.com/dietmarwo/fast-cma-es
『PainterEngine』由C语言编写的跨平台图形应用框架
https://github.com/matrixcascade/PainterEngine
PainterEngine是一个由C语言编写的跨平台图形应用框架,可运行于Windows Linux Android iOS 支持WebAssembly的Web端及嵌入式MCU上。
- PainterEngine由C89标准及部分拓展编写,不依赖任何C标准库及三方库
- PainterEngine是平台、编译环境、运行时无关的
- 包含一套完整的内存管理及常用数据结构算法的实现
- 包含一套完整软2D/3D渲染器实现
- 包含一套完整编译型脚本引擎实现(编译器、虚拟机、调试器)
- 包含一套完整游戏世界框架(对象及资源管理器,事件调度器,碰撞优化及物理计算模板)
- 包含一套完整的Live2D动画系统实现(骨骼及物理模拟、动作追踪、独立的图元光栅化实现,配套建模编辑器)
- 常用的反走样几何绘制及光栅化算法
- 图像信号及音频信号处理算法(常用滤波器、声码编码器、ZCR、MFCC等特征采集算法)

博文&分享
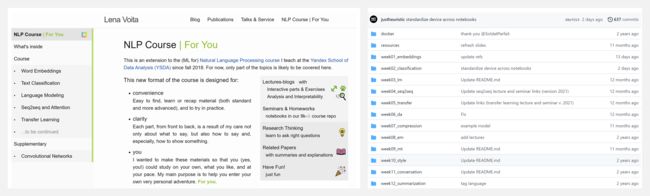
『YSDA Natural Language Processing course』YSDA 的自然语言处理课程 8.1k stars
https://github.com/yandexdataschool/nlp_course
https://lena-voita.github.io/nlp_course.html
YSDA是 Yandex School of Data Analysis 的首字母缩写,出品了很多优质的数据类课程。这门 NLP 课程在GitHub上已经收获了8K+个Star,可谓广受认可。课程包含以下主题,资料见 GitHub项目的对应的文件夹:
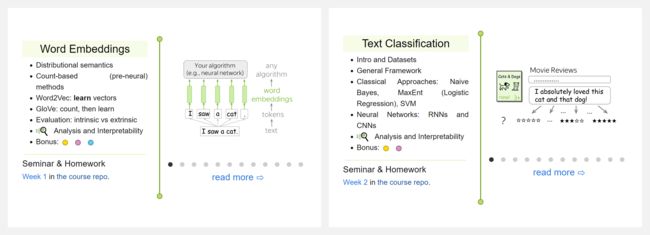
- Word Embeddings
- Text Classification
- Language Modeling
- Seq2seq and Attention
- Transfer Learning
- Domain Adaptation
『(CS285) Deep Reinforcement Learning』 Berkeley伯克利 · 深度强化学习课程
https://www.showmeai.tech/article-detail/345
CS285 课程来自著名的顶级院校UC伯克利,结合了最新的研究进展,讲解深度强化学习领域的前沿知识和实践。课程覆盖了使用深度学习神经网络进行强化学习的各类方法模型,对强化学习感兴趣的同学可以借此全面了解神经网络在其中的应用。

- Introduction and Course Overview(课程速览与介绍)
- Supervised Learning of Behaviors(行为监督学习)
- Introduction to Reinforcement Learning(强化学习介绍)
- Policy Gradients(梯度策略)
- Actor-Critic Algorithms(Actor-Critic 算法)
- Value Function Methods(价值函数方法)
- Deep RL with Q-functions(基于Q函数的的深度强化学习)
- Advanced Policy Gradients(前沿梯度策略)
- Model-based Planning(基于模型的规划)
- Model-based Reinforcement Learning(基于模型的强化学习)
- Model-based Policy Learning(基于模型的策略学习)
- Exploration(探索与利用)
- Offline Reinforcement Learning(离线强化学习)
- Introduction to RL Theory(强化学习理论)
- Deep RL Algorithm Design(深度强化学习算法设计)
- Probability and Variational Inference Primer(概率与变分推断初步)
- Connection between Inference and Control(推断与控制联系)
- Inverse Reinforcement Learning(逆强化学习)
- Transfer Learning and Multi-Task Learning(迁移学习与多任务学习)
- Meta-Learning(元学习)
- Challenges and Open Problems(挑战与开放待解决的问题)
课程对应的资料和视频公开放出,ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
课件。Lecture 1~23所有章节。
代码作业与参考答案-数据文件&.py文件。Homework 1~5所有作业的参考答案。
『(ENGR108) Introduction to Applied Linear Algebra: Vectors, Matrices, and Least Squares』 Stanford斯坦福 · 线性代数与矩阵方法导论课程
https://www.showmeai.tech/article-detail/346
ENGR108 (曾用名:EE103、CME103)是全球顶级院校斯坦福开设的以线性代数和矩阵论为主题的专业课程。不同于定理证明、矩阵运算的传统内容,这门课程更直观,用非常多的例子和图标,来表示向量、矩阵与复杂世界的关系,并能够解决现实问题。

- Linear functions(线性函数)
- Intro to Julia Tutorial(Julia 入门教程)
- Norm and distance(范数与距离度量)
- Clustering(聚类)
- Linear independence(线性无关)
- Matrices(矩阵)
- Linear equations(线性方程)
- Linear dynamical systems(线性动态系统)
- Matrix multiplication(矩阵乘法)
- Matrix inverses(逆矩阵)
- Regression(回归)
- Least squares classification(最小二乘法)
- Multi-objective least squares(多目标最小二乘)
- Constrained least squares(受约束的最小二乘)
课程对应的资料和视频公开放出,ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
e-book:课程对应的电子书。
课件:Chapter 1-19的所有课件PDF版本。
作业: Stephen Boyd (课程讲师) 和 Lieven Vandenberghe 整理的课程练习题,共20多页,21章。

数据&资源
『Graph Adversarial Learning Literature』图对抗学习文献集
https://github.com/safe-graph/graph-adversarial-learning-literature
https://arxiv.org/pdf/1812.10528.pdf
关于图结构数据的对抗性攻击和防御论文的精选列表。论文按上传日期降序排列。对应论文『Adversarial Attack and Defense on Graph Data: A Survey 』 见上方第二个链接。
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.09.21 『数据增强』 Deep Learning for Medical Image Segmentation: Tricks, Challenges and Future Directions
- 2022.09.21 『3D姿态预估』 Benchmarking and Analyzing 3D Human Pose and Shape Estimation Beyond Algorithms
- 2022.09.21 『图像分类』 HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
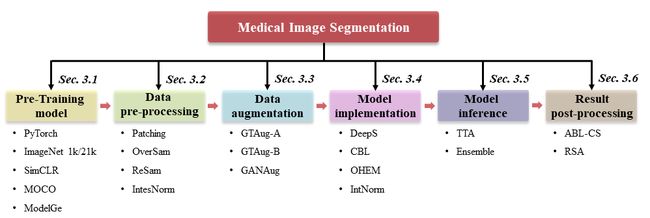
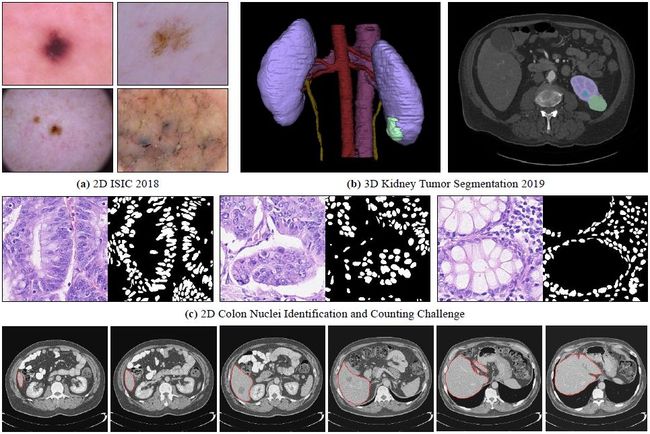
⚡ 论文:Deep Learning for Medical Image Segmentation: Tricks, Challenges and Future Directions
论文时间:21 Sep 2022
领域任务:Data Augmentation, Domain Adaptation, 数据增强,域自适应
论文地址:https://arxiv.org/abs/2209.10307
代码实现:https://github.com/hust-linyi/seg_trick
论文作者:Dong Zhang, Yi Lin, Hao Chen, Zhuotao Tian, Xin Yang, Jinhui Tang, Kwang Ting Cheng
论文简介:Over the past few years, the rapid development of deep learning technologies for computer vision has greatly promoted the performance of medical image segmentation (MedISeg)./在过去的几年里,计算机视觉深度学习技术的快速发展大大促进了医学图像分割(MedISeg)的性能。
论文摘要:在过去的几年里,计算机视觉深度学习技术的快速发展极大地促进了医学图像分割(MedISeg)的性能。然而,最近的MedISeg出版物通常集中在对主要贡献的介绍上(如网络架构、训练策略和损失函数),而不知不觉地忽略了一些边缘的实现细节(也称为 “技巧”),导致了不公平的实验结果比较的潜在问题。在本文中,我们针对不同的模型实施阶段(即预训练模型、数据预处理、数据增强、模型实施、模型推理和结果后处理)收集了一系列MedISeg技巧,并通过实验探索这些技巧对一致的基线模型的有效性。与那些只基础地关注分割模型的优势和局限性分析的论文驱动的调查相比,我们的工作提供了大量扎实的实验,在技术上更具有可操作性。通过对具有代表性的二维和三维医学图像数据集的大量实验结果,我们明确地阐明了这些技巧的效果。此外,基于所调查的技巧,我们还开源了一个强大的MedISeg资源库,其中的每个组件都具有即插即用的优势。我们相信,这项里程碑式的工作不仅完成了对最先进的MedISeg方法的全面和补充调查,而且还为解决未来的医学图像处理挑战提供了实用指南,包括但不限于小数据集学习、类不平衡学习、多模式学习和领域适应。该代码已在以下网站发布:https://github.com/hust-linyi/MedISeg
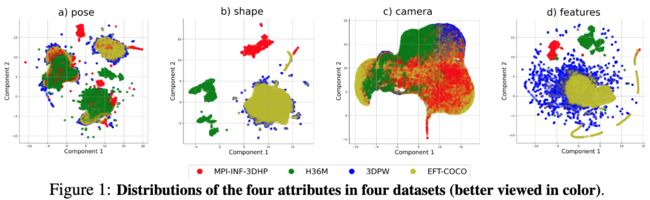
⚡ 论文:Benchmarking and Analyzing 3D Human Pose and Shape Estimation Beyond Algorithms
论文时间:21 Sep 2022
领域任务:3D human pose and shape estimation, Human Mesh Recovery,3D姿态预估
论文地址:https://arxiv.org/abs/2209.10529
代码实现:https://github.com/smplbody/hmr-benchmarks
论文作者:Hui En Pang, Zhongang Cai, Lei Yang, Tianwei Zhang, Ziwei Liu
论文简介:Experiments with 10 backbones, ranging from CNNs to transformers, show the knowledge learnt from a proximity task is readily transferable to human mesh recovery./用10个骨干(从CNN到transformers)进行的实验表明,从接近任务中学到的知识很容易转移到人类网格恢复中。
论文摘要:3D人类姿势和形状估计(又称 “人类网格恢复”)已经取得了实质性进展。研究人员主要集中在新算法的开发上,而对所涉及的其他关键因素关注较少。这可能导致不太理想的基线,阻碍了对新设计的方法进行公平和忠实的评估。为了解决这个问题,这项工作从算法以外的三个未充分开发的角度提出了第一个全面的基准研究。1)数据集。对31个数据集的分析揭示了数据样本的不同影响:具有关键属性的数据集(即不同的姿势、形状、相机特征、骨干特征)更加有效。战略性地选择和组合高质量的数据集可以对模型的性能产生显著的提升。2) 骨干。用10个骨干进行的实验,从CNN到transformers,表明从接近任务中学到的知识很容易转移到人类网格恢复上。3) 训练策略。适当的增强技术和损失设计是至关重要的。有了上述发现,我们用一个相对简单的模型在3DPW测试集上实现了47.3毫米的PA-MPJPE。更重要的是,我们为算法的公平比较提供了强有力的基线,并为将来建立有效的训练配置提供了建议。代码库可在 http://github.com/smplbody/hmr-benchmarks
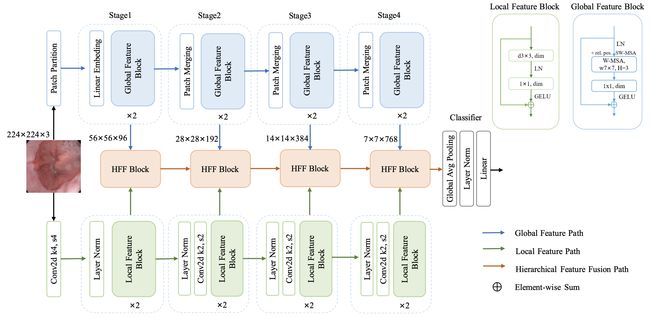
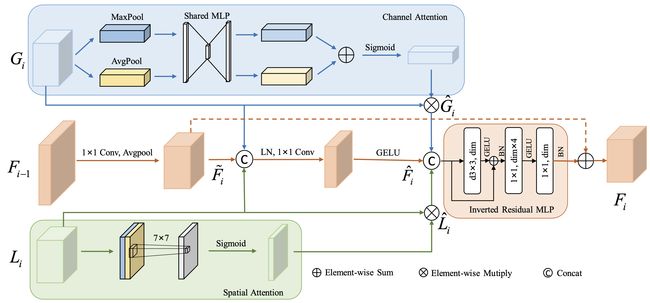
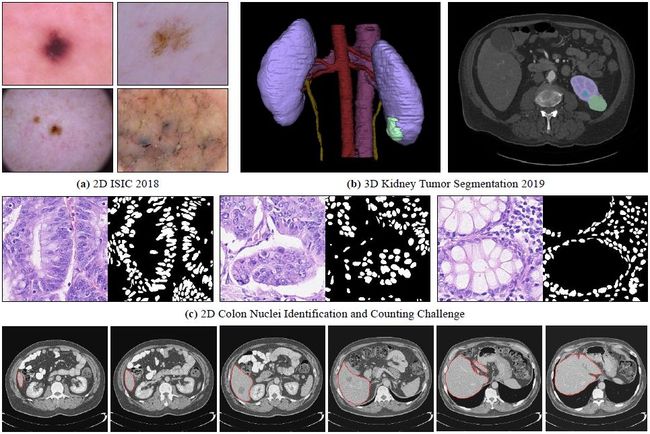
⚡ 论文:HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
论文时间:21 Sep 2022
领域任务:Image Classification, Inductive Bias, 归纳偏置,图像分类
论文地址:https://arxiv.org/abs/2209.10218
代码实现:https://github.com/huoxiangzuo/HiFuse
论文作者:Xiangzuo Huo, Gang Sun, Shengwei Tian, Yan Wang, Long Yu, Jun Long, Wendong Zhang, Aolun Li
论文简介:A parallel hierarchy of local and global feature blocks is designed to efficiently extract local features and global representations at various semantic scales, with the flexibility to model at different scales and linear computational complexity relevant to image size./设计了一个局部和全局特征块的并行层次结构,以有效地提取不同语义尺度的局部特征和全局表征,具有在不同尺度上建模的灵活性和与图像大小相关的线性计算复杂性。
论文摘要:在卷积神经网络(CNN)的推动下,医学图像分类得到迅速发展。由于卷积核的接受域的固定大小,很难捕捉到医学图像的全局特征。虽然基于自注意力的Transformer可以模拟长距离的依赖关系,但它的计算复杂度很高,而且缺乏局部的归纳偏置。许多研究表明,全局和局部特征对图像分类至关重要。然而,医学图像有很多嘈杂、分散的特征,类内变化和类间相似。本文提出了一种三分支分层多尺度特征融合网络结构,称为HiFuse,作为一种新的方法用于医学图像分类。它可以在不破坏各自建模的前提下,融合多尺度层次结构的Transformer和CNN的优点,从而提高各种医学图像的分类精度。设计了一个由局部和全局特征块组成的平行层次结构,以有效地提取不同语义尺度的局部特征和全局表征,具有在不同尺度上建模的灵活性和与图像大小相关的线性计算复杂性。此外,还设计了一个自适应的分层特征融合块(HFF块),以全面利用在不同分层层次上获得的特征。HFF块包含空间注意力、通道注意力、残差倒置MLP和快捷键,以适应性地融合各分支的不同尺度特征之间的语义信息。我们提出的模型在ISIC2018数据集上的准确率比基线高7.6%,在Covid-19数据集上高21.5%,在Kvasir数据集上高10.4%。与其他高级模型相比,HiFuse模型的表现最好。我们的代码是开源的,可从 https://github.com/huoxiangzuo/HiFuse 获取。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
