kafka处理大数据包
与任何技术一样,Kafka 也有其局限性 - 其中之一是 1 MB 的最大封装大小。这只是默认设置,但不应轻易更改。
有三种可能性:
调整默认设置
某些较大的消息 (10 MB) 也会影响群集的性能,因此不建议这样做。
将数据集划分为较小的单元
这是可能的,但会显著增加复杂性,同时增加使用者对内存的需求。 仅向 Kafka 群集发送对数据的引用,并存储在另一个容器中的数据包这是大多数应用程序的建议方法。它只是稍微增加了应用程序的复杂性,并保留了所有使Kafka如此有趣的功能。
在下面,我将详细介绍不同的方法以及如何实现它们。
1. 调整默认设置message.max.bytes
必须以下四个都要设置
Producer: max.request.size
Broker: replica.fetch.max.bytes
Broker: message.max.bytes
Consumer: fetch.message.max.bytes
调整这些设置后,从技术上讲,您可以处理消息,达到新设置的限制。但是,您很快就会注意到性能问题。从 10 MB 开始,损伤变得明显 (1)。您可以通过大幅提高堆空间来解决此问题。但是,没有好的经验法则。此外,它影响不同的组件:生产者,消费者和broker。
2. 将数据包划分为小型单元
这是一个显而易见的方法,因为不需要其他技术,因此性能完全取决于 Kafka 群集。但是,此方法要求对生产者进行一些调整,增加逻辑,增加使用者的内存需求。
额外的复杂性产生于这样一个事实,即消息的段通常不会在日志中一个又一个写入,而是被另一个消息的段中断。

注意:只有在只有单个幂等生产者写入每个分区的特殊情况下,消息的段是连续的。在这些情况下,实现相对简单,并且最多需要从使用者那里获得尽可能多的内存,因为消息可以很大。
生产者:
生产者将消息拆分为段,并为这些段提供其他元数据。一方面,需要段计数器,以便使用者能够按正确的顺序将段放在一起。另一方面,需要消息 ID,以便段可以分配给消息。第三,您应该确保包括段数和校验和,以便整个事情可以轻松和一致地重新放在一起。
由于生产者仅在成功传输最后一段后调用生产者回调来确认消息的发送,因此此 ID 可以从消息本身确定派生,这一点很重要。当生产者在已发送某些段后崩溃时,将这样做。
producer_fault.svg
图 2:生产者在传输消息的所有段之前崩溃
如果另一个生产者接手,他不知道哪些段已发送到群集。因此,他或她再次传输整个消息。这意味着第一个段发送两次。使用者必须能够确定这一点。这可以通过从消息派生的 ID 来保证。但是,对于随机 UUID,这是不可能的。

消费者:
由于一条消息的段可以被另一个消息的段中断,使用者必须缓冲后续消息的段,直到它完全读取它最初接收段的消息。只有当邮件的所有部分都重新组合以形成原始邮件时,才能处理它。
使用者偏移量也只会更新为缓冲区中剩余消息的最旧段的偏移量。

为了确保使用者可靠工作,使用者中的段缓冲区绝不能大于可用内存。可以通过首先处理消息(首先完成)来减少内存需求。这意味着您不应处理您首次收到段的消息,如上所述。但是,消费者偏移处理会更加复杂,并且该过程有进一步的限制 (2)。
还可以以内存要求限制为原始消息的大小的方式构建使用者。但是,这需要具有更多逻辑的多级使用者。如果您想了解更多有关此信息的信息,请亲自与我联系。
3. 处理引用而不是数据
最安全、最简单的过程是将数据存储在外部内存中,并且只使用 Kafka 处理对外部存储数据的引用。使用者读取对数据的引用并从外部内存中检索它们。当然,外部内存必须是故障安全和快速的,因为外部内存中的写入和读取是此系统中的限制因素。因此,我们建议您使用高度可用的云存储,并允许并行读写。
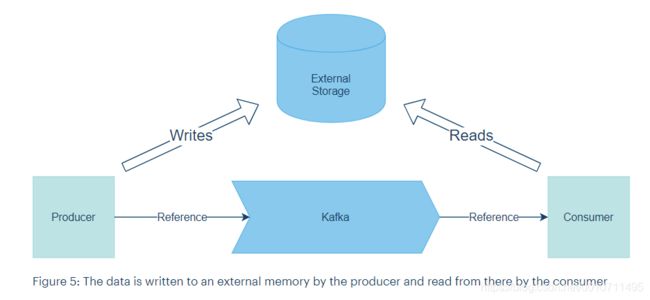
还有一个问题,即何时应该删除外部内存中的数据。如果只有一个使用者从分区读取,则可以在读取或更新使用者偏移量后立即删除数据。否则,建议为数据选择与引用位于主题相同的保留时间。
选择方式
只有当数据包小于10M时更改默认设置才有意义,另外还必须在测试环境测试是否需要额外的资源.
如果您希望不需使用其他技术,并愿意研究更复杂的消费者,建议将消息细分为较小的包。同时,应当考虑到生产者的性质。如果很可能同时发送许多大型消息,则可能需要切换到不同的模式。
在所有其他情况下,建议将数据存储在外部,并且仅使用 Kafka 处理对数据的引用。
参考
彻底搞懂 Kafka 消息大小相关参数设置的规则
https://objcoding.com/2020/05/18/kafka-msg-size-setting/
Bericht - Large data packets and Kafka
https://ipt.ch/en/impuls/large-data-packets-and-kafka