一文搞懂oracle存储过程、函数、触发器和程序包
文章目录
-
- 一、存储过程
-
- 1、简介
- 2、创建存储过程
- 3、存储过程的参数
-
- 3.1、IN模式参数
- 3.2、out模式参数
- 3.3、in out模式参数
- 4、删除存储过程
- 二、函数
-
- 1、创建函数
- 2、调用函数
- 3、删除函数
- 三、触发器
-
- 1、什么是触发器?
- 2、什么是触发事件
- 3、触发器的语法格式
- 4、触发器的5种类型
-
- 4.1、语句级触发器
- 4.2、行级触发器
- 4.3、替换触发器
- 4.4、用户事件触发器
- 4.5、系统事件触发器
- 四、程序包
-
- 1、程序包规范
- 2、程序包主体
最近在公司用到orale数据库,以前都是用的mysql。相较于oracle,mysql的存储过程就显得比较鸡肋了,所以系统的学习了一下,写下本文记录一下,以后也可以翻看学习, 本文所用到的例子均来自oracle11g自带的scott模式,参考书籍清华大学出版社Oracle从入门到精通,还请大家支持购买正版书籍,话不多说,直接开始!
一、存储过程
1、简介
- 存储过程是一种命名的PL/SQL块
- 可以没有参数,也可以有若干个输入、输出函数,通常没有返回值
- 保存在数据库中,不可以被SQL语句直接调用
调用存储过程
- execut(exec)存储过程名:该命令只可在SQLPLUS里使用
- call 存储过程名() : call是sql命令,任何可视化工具都可以使用,但是存储过程名后得接括号,无论有没有参数
2、创建存储过程
创建的存储过程一般包含三个模块,即声明部分、执行部分、异常处理部分,语法如下
-- OR REPLACE 表示,如果已经存在改存储过程,那么创建的存储过程hi直接替换原有的
CREATE OR REPLACE procedure 存储过程名(参数1,参数2,...参数n) is/as -- is as可以互换
BEGIN
SQL语句;
EXCEPTION
SQL语句;
end 存储过程名;
举例:
CREATE OR REPLACE procedure insertDept is
BEGIN
insert into dept values(66,'Test66','BeiJing'); -- 插入数据
commit; -- 提交
dbms_output.put_line('插入成功') ; -- 提示插入成功
end insertDept;
此时可以看到已经多了一个insertDept 存储过程

但是数据还未插入数据库,需要我们调用存储过程执行编译
call insertDept();
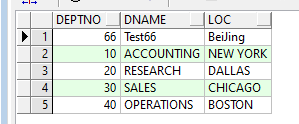
此时可以看到数据库里已经有我们插入的对应的信息了
select * from dept;
如果在创建存储过程中出现错误,在SQLPLUS里可以使用show error来查看错误信息
3、存储过程的参数
- 存储过程的参数增加了oracle的灵活性
- 参数是一种向程序单元输入和输出数据的机制
- 存储过程可以接受多个参数
- 参数模式有三种:IN、OUT和IN OUT
3.1、IN模式参数
-是一种输入类型的参数,参数值由调用方法传入,并且只能被存储过程读取,关键字IN位于参数名之后
举例:创建一个存储过程并定义三个IN模式变量,然后将变量值参数表中
create or replace procedure insertDept_IN(
num_deptno in number, -- 定义IN模式变量存储部门编号
var_ename in varchar2, -- 定义IN模式变量存储部门名称
var_loc in varchar2) is -- 定义IN模式变量存储地址
begin
insert into dept
values(num_deptno,var_ename,var_loc); -- 插入记录
commit; -- 提交数据库
end insertDept_IN;
存储过程创建成功,需要注意的是IN模式参数类型不能指定长度。
在调用IN模式存储过程时,用户需要向存储过程中传递若干参数值,以保证执行部分(即BEGIN部分)有具体的数值参与数据操作。
向存储过程传入参数有如下三种方式,我们以上面创建的存储过程insertDept_IN为例讲解一下“”
- 按指定名称传递:指定名称传递是指在向存储过程传递参数时需要指定参数名称,其格式是
// =>是赋值号
参数名称=>参数值
举例
call insertdept_in(var_ename=>'Test3',var_loc => '汕尾',num_deptno => '12');
可以看到,使用指定名称传递参数,我们调用存储过程的参数顺序可以和我们定义存储过程的参数顺序不一样,即使用“指定名称”的方式传递参数值与参数的定义顺序无关,但与参数个数有关。
- 按位置传递:顾名思义,用户传值时提供的参数顺序必须与存储过程中定义的参数顺序相同。
举例
call insertdept_in(11,'Tes4t','成都');
- 混合方式传递
,这种情况下按位置传递参数用户
当参数过多时,按指定名称传入参数虽然直观易读,但缺点是代码冗长,按位置传递的话用户也可能记不清参数顺序,所以采用两者混合的方式,可以兼顾两者的优点
举例
call insertdept_in(18,var_loc => '广州',var_ename=>'Test5');
需要注意的是,使用混合方式传值时,在某个位置已经使用按指定名称传入参数值后,后面的参数值也要使用指定参数名称传递,因为指定参数名称传递有可能已经破坏了参数原始的定义顺序。
3.2、out模式参数
- 输出类型的参数
- 参数在存储过程中已经被赋值,并且可以被传递到当前存储过程以外的环境中
- 关键字out位于参数名称之后
举例
-- 创建一个存储过程,定义两个out参数
-- 将dept表中检索到的一行部门信息存储到这两个参数中
create or replace procedure select_dept(
num_deptno in number, -- 定义in模式变量,要求输入模式编号
var_dname out dept.dname%type, -- 定义out模式变量,存储部门名称并输出
var_loc out dept.loc%type) is
begin
select dname,loc into var_dname,var_loc from dept
where deptno = num_deptno;
exception
when no_data_found then -- 定义异常
dbms_output.put_line('部门编号不存在'); -- 输出信息
end select_dept;
由于存储过程通过out返回参数值,调用或执行这个存储过程时,我们需要定义变量来保存两个参数,调用过程如下
set serverout on -- 注意,此句第一句只在sqlplus环境中有效,用于输出信息
declare
var_dname dept.dname%type; -- 声明变量
var_loc dept.loc%type; -- 声明变量
begin
scott.select_dept(10,var_dname,var_loc); -- 传入部门编号
dbms_output.put_line(var_dname||'位于:'||var_loc); -- 输出部门信息
end;
3.3、in out模式参数
顾名思义,兼顾两种模式参数的优点
举例:新建一个存储过程计算平方或者平方根
create or replace procedure square_inout(
num in out number, -- 定义一个in out 参数
flag in boolean) is -- 计算平方或平方根的标识,一个In参数
i int :=2; -- 表示计算平方,这是一个内部变量
begin
if flag then -- 若为true
num :=power(num,i); -- 计算平方
else
num :=sqrt(num); -- 计算平方根
end if;
end;
调用
set serverout on -- 注意,此句第一句只在sqlplus环境中有效,用于输出信息
declare
var_number number; -- 存储要进行运算的值和愶的后果
var_temp number; -- 存储要进行运算的值
boo_flag boolean; -- 平方或平方根的逻辑标记
begin
var_temp := 3; -- 变量赋值
var_number := var_temp;
boo_flag := false; -- true => 计算平方 false => 计算平方根
square_inout(var_number,boo_flag); -- 调用存储过程
if boo_flag then
dbms_output.put_line(var_temp || '的平方是' || var_number); -- 输出计算结果
else
dbms_output.put_line(var_temp || '的平方跟是' || var_number);
end if;
end;
4、删除存储过程
-- drop procedure 存储过程名;
drop procedure square_inout;
当一个存储过程已经过时想重新定义时,不必先删除再创建,在create关键字后加or replace 即可。
二、函数
- sql有一些常用函数,函数一般用于计算和返回一个值,但可以将我们经常需要使用的计算活功能写成一个函数。
- 创建函数与存储过程的形式上有些相似,也是编译后放在内存供用户使用
- 调用函数时要用表达式,而存储过程不用
- 函数必须要有一个返回值,存储过程没有
1、创建函数
create or replace function 函数名称(参数1 参数1类型,参数2 参数2类型) return 函数的返回值类型 is
函数的内部变量(可选项);
begin
sql语句;
exception
异常处理代码;
end;
举例
-- 定义一个函数,用于计算emp表中的平均工资
create or replace function get_avg_pay(num_deptno number) return number is
num_avg_pay number; -- 保存平均工资
begin
select avg(sal) into num_avg_pay from emp where deptno=num_deptno; -- 返回平均工资
return (round(num_avg_pay,2));
exception
when no_data_found then
dbms_output.put_line('该部门编号不存在');
return (0);
end;
2、调用函数
set serveroutput on -- 注意,此句第一句只在sqlplus环境中有效,用于输出信息
SQL> declare
2 avg_pay number;
3 begin
4 avg_pay:=get_avg_pay(10); -- 调用函数,获取返回值
5 dbms_output.put_line('平均工资是:'||avg_pay);
6 end;
7 /
3、删除函数
drop function 函数名
举例
drop function get_avg_pay;
三、触发器
1、什么是触发器?
- 触发器可以看作是一种“特殊“的存储过程,它定义了一些数据库相关事件发生时执行的”功能代码块“(如insert、update等)
- 通常用于管理完整性约束、监控对表的修改,或者通知其他程序,甚至可以实现对数据的审计功能
2、什么是触发事件
- 能够引起触发器运行的事件叫做触发事件。如执行DDL、DML语句,引发数据可系统事件、用户事件等
- 存储过程的调用或执行是由用户或应用程序进行的,与存储过程不同的是,触发器是通过触发事件来执行的。
3、触发器的语法格式
create or replace trigger tri_name
before/after/instead of tri_event
on table_name/view_name/user_name/db_name
for each row when tri_condition
begin
sql_sentences;
end tri_name;
- trigger :创建触发器的关键字
- tri_name:触发器名称
- before/after/instead of:触发时机的关键字,before/after——表示在执行DML语句等操作 之前/之后 发生,instead of表示触发器为替代触发器
- tri_event:触发器事件
- for each row :指定触发器为行级触发器
- tri_condition:触发条件,只有该表达式为true时,才会引发触发事件
- sql_sentences:SQL语句、触发器功能实现的主体
4、触发器的5种类型
- 行级触发器:当DML语句对每一行数据进行操作时都会引起该触发器
- 语句级触发器:无论DML影响多少行数据,其所引起的触发器仅执行一次
- 替换触发器:定义在视图上的触发器,用来替换所使用的实际语句的触发器
- 用户事件触发器:用户登录到数据库或者使用ALTER语句修改表结构等事件的触发器
- 系统事件触发器:只Oracle数据库系统的事件中进行的触发器,如Oracle实例的启动与关闭
下面一个一个解释一下
4.1、语句级触发器
顾名思义是针对一条DML语句引起的触发器执行。不使用for each row子句,无论操作数据影响多少行,触发器都只会执行一次。
下面通过例子来认识。
创建一个日志表dept_log
create table dept_log
(
operate_tag varchar2(20), -- 定义字段,存储操作种类信息
operate_time date -- 定义字段,存储操作日期
);
创建一个关于dept表的语句级触发器
create or replace trigger tri_dept
before insert or update or delete on dept --创建触发器
declare
var_tag VARCHAR2 (10); -- 存储操作类型
begin
if inserting then -- 当触发事件为Insert时
var_tag :='插入'; -- 标识插入操作
elsif updating then -- 但出发事件为Update时
var_tag :='修改'; -- 标识修改操作
elsif deleting then -- 但出发事件为delete时
var_tag := '删除'; -- 标识删除操作
end if;
insert into dept_log
values (var_tag,sysdate ) ;-- 向日志表中插入对dept表的操作信息
end tri_dept;
在上述代码中,使用before关键字指定触发器的“触发时机”,指定当前触发器在DML语句执行前触发,这使得它非常适合于强化安全性、启用业务逻辑和进行日志信息记录。
另外,为了具体判断对dept表进行了何种操作,代码中还是用了条件谓词,由关键字if或elsif和谓词inserting 、updating、deleting组成。如果条件谓词值为true,那么就执行相应的触发器语句。
另外,用户可以通过条件谓词判断特定列是否被更新。
在这里插入代码片举例:判断用户是否对dept表中的dname进行修改
if updating(dname) then -- 若dname被修改
do something about update dname
end if;
创建完触发器我们需要执行,触发器的执行不像存储过程由用户或者程序调用,而是通过一定的触发事件来诱发执行。我们在对dept表进行一定的操作时,就会引发触发器,然后触发器执行往dept_log表插入数据。
insert into dept values(87,'业务部','北京');
update dept set loc='广州' where deptno=101;
delete from dept where deptno=87;
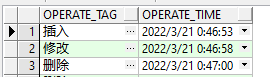
执行完操作之后查询一下日志表
select * from dept_log;
可以发现相关触发器已执行
4.2、行级触发器
- 行级触发器会针对DML操作所影响的每一行数据都执行一次触发器。
- 必须在语法中使用
for each row - 典型应用:给数据表生成主键值
举例:创建一个商品种类表,包括商品序列号和商品名称列
create table goods(
id int primary key,
good_name varchar2(50)
);
为了让id生成不重复的有序值,这里需要创建一个序列
create sequence seq_id;
创建一个行级触发器,为id赋值
create or replace trigger tri_insert_good
before insert on goods --在goods表里,insert数据前引起本触发器运行
for each row --设置行级出发
begin
select seq_id.nextval
into :new.id --:new.id 列标识符,用来指向新行的id列
from dual; --从序列中生成一个新值,赋值个当前插入行的id列
end;
我们可以通过上面的列标识符来访问当前正在受到影响(添加、修改、删除等操作)的数据行,列标识符可以分为“原值标识符”和“新值标识符”,写法是old.列名和new.列名。
new.id通常在insert和update中使用,因为delete无法产生新值。
向表中插入两条数据,一条指定id,一条不指定,并查询
insert into goods(good_name) values('苹果');
insert into goods(id,good_name) values(9,'西瓜');
select * from goods;
查询结果
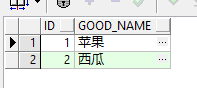
可以发现,无论指定与否,数据均插入成功,但是西瓜的序号并不是我们插入的9,而是2。
这是因为在触发器中将序列seq_id的nextval属性值赋给了:new.id,其属性值是不间断的,这个咧标识符的值就是当前插入行的id列的值。
4.3、替换触发器
- INSTEAD OF 替换触发器,触发关键字是`INSTEAD OF
- 替换触发器是定义在视图上的而不是定义在表上的,因此用户一般不允许DML操作
- 当用户编写替换触发器后,用户对视图的DML操作实际上就吧变成了执行触发器中的PL/SQL块,这样就可以通过在替换触发器编写适当的代码对构成视图的基表进行操作
举例:创建视图,保罗dept表与emp表
首先需要进入system模式给scott分配创建视图权限
grant create view to scott;
创建视图
create or replace view v_emp_dept
as select empno,ename,dept.deptno,dept.dname,job,hiredate
from dept,emp
where emp.deptno=dept.deptno;
在没创建触发器之前,尝试向视图中插入数据就会报错。
创建一个关于v_emp_dept视图的替换触发器,在该触发器下插入两行相互关联的数据
create or replace trigger tri_insert_view
instead of insert --创建触发器
on v_emp_dept --行级视图
for each row
declare
row_dept dept%rowtype;
begin
select * into row_dept from dept where deptno = :new.deptno; --检索部门指定编号记录行
if sql%notfound then
insert into dept(deptno , dname) values ( :new.deptno,:new.dname) ; --向dept表中插入数据
end if;
insert into emp(empno ,ename ,deptno ,job ,hiredate)
values(:new.empno, :new.ename , :new.deptno , :new.job, :new.hiredate) ; --向emp表中插入数据
end tri_insert_view ;
向视图中插入一条记录,然后检索插入的记录行
insert into v_emp_dept(empno,ename,deptno,dname,job,hiredate)
values(8888,'东方',10,'test','test',sysdate);
select * from v_emp_dept where empno=8888;
查询结果

4.4、用户事件触发器
- 用户事件触发器是因为进行DDL操作或用户登录、退出等操作引起的
- 常见的用户事件包括
CREATE、ALTER、DROP、ANALYZE、COMMENT、GRANT、REVOKE等
举例:创建一个日志信息表
create table ddl_oper_log
(
db_obj_name varchar2(20), --数据对象名称
db_obj_type varchar2(20), --数据对象类型
oper_action varchar2(20), --具体DDL行为
oper_user varchar2(20), --操作用户
oper_data date --操作日期
);
创建一个关于scott用户的DDL操作的触发器,然后将DDL相关操作信心插入到日志表中
create or replace trigger tri_ddl_oper
before create or alter or drop
on scott.schema --scott模式下,在创建、修改、删除数据对象之前将引发该触发器运行
begin
insert into ddl_oper_log values(
ora_dict_obj_name, --操作的数据对象名称
ora_dict_obj_type, --对象类型
ora_sysevent, --系统事件名称
ora_login_user, --登录用户
sysdate);
end;
在scott模式下进行如下操作,引发触发器运行,然后并查询日志表
create table tb_test(id number);
create view v_test as select empno,ename from emp;
alter table tb_test add(name varchar2(10));
drop view v_test;
select * from ddl_oper_log;
查询结果:

4.5、系统事件触发器
指Oracle数据库系统的事件中进行出发的触发器,如Oralce实例的启动与关闭
四、程序包
- 程序包是由PL/SQL程序元素(如类型、变量)和匿名PL/SQL块(如游标)、命名PL/SQL块(如存储过程、函数)组成
- 程序包可以被整体加载到内存中,从而大大加快其组成部分的访问速度
1、程序包规范
程序包规范规定了程序包中可以使用哪些变量、类型、游标和子程序
create or replace package 程序包名 is
规范内声明的变量;
规范内声明的类型;
规范内定义的游标;
规范内声明的函数;
规范内声明的存过过程;
end 程序包名;
举例:创建一个程序包规范,首先在该程序包中声明一个可以获取指定部门的平均工资的函数,然后声明一个可以实现按照指定比例上调指定职务工资的存储过程
create or replace package pack_emp is
function fun_avg_sal(num_deptno number) return number; --获取指定部门的平均工资
procedure pro_regulate_sal(var_job varchar2,num_proportion number); --按照指定比例上调指定职务的工资
end pack_emp;
从代码中可以看到,在规范声明的函数和存储过程只有头部的声明,而没有函数体和存储过程主体,符合规范特点。
2、程序包主体
- 程序包主体包含了规范中的游标、过程和函数的实现代码
- 程序包的主题名称必须与规范名称相同
- 创建程序包主体使用
create package body语句
create or replace package body 包名 is
程序包主体的内部变量
游标主体
从规范中引入的头部声明
{begin
SQL语句,函数功能主要实现部分;
exception
异常处理语句
end 函数名称}
从规范中引入的存储过程声明
{begin
SQL语句,存储过程功能主要实现部分;
exception
异常处理语句
end 存储过程名称}
...
end 包名
举例:创建程序包pack_emp,并在该主体中实现规范中声明的函数与存储过程对应
create or replace package body pack_emp is
function fun_avg_sal(num_deptno number)return number is --引入规范中的函数
num_avg_sal numberm --定义内部变量
begin
select avg(sal) into nu_avg_sal from emp
where deptno=num_deptno; --计算某个部门的平均工资
return(num_avg_sal); --返回平均工资
exception
when no_data_found then --若未发现记录
dbms_output.put_line('该部门编号不存在员工记录');
return 0; --返回0
end fun_avg_sal;
procedure pro_regulate_sal(var_job varchar2,
num_proportion number) is --引入规范中的存储过程
begin
update emp set sal=sal*(1+num_proportion)
where job=var_job;
end pro_regulate_sal;
end pack_emp;
删除程序包
drop package 包名