ElasticSearch 一文读懂
目录
1、Elasticsearch 简介
2、Docker 安装 Elasticsearch
2.1 使用Docker安装ElasticSearch7.6.2
2.2Elasticsearch 目录详解
2.3 使用Docker安装elasticSearch--head
通过Chrome 插件安装ElasticSearch-head
2.4 了解ELK
ELK 功能结构图
Docker 安装Kibana
3 ElasticSearch 核心概念
3.1索引 index
3.2 映射 mapping
3.3 字段Field
3.4 字段类型 Type
3.5 文档 document
3.6 集群 cluster
3.7 节点 node
3.8 分片和副本 shards&replicas
分片
副本
ElasticSearch 分词原理之倒排索引
ElasticSearch 集成IK分词
IK分词效果:
4、ElasticSearch 数据管理
4.1 ElasticSearch 基本操作
1) 创建索引
2) 查询索引
3) 删除索引
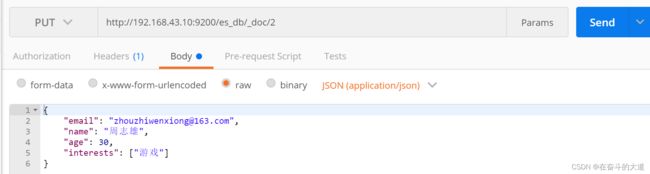
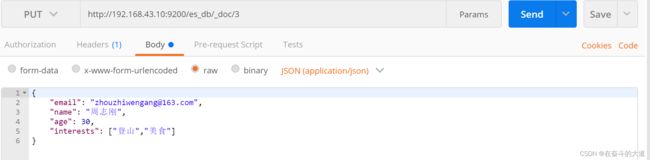
4) 添加文档
5) 修改文档
6) 查询文档
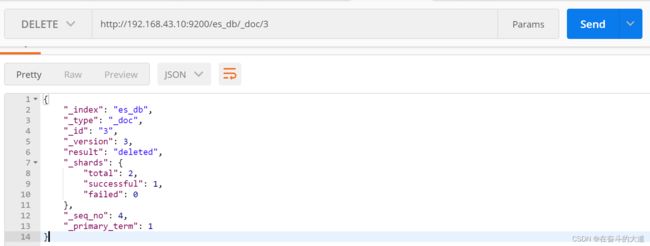
7) 删除文档
8) 查询操作
9) 文档批量操作
5、ElasticSearch之DSL
DSL 思维导图
DSL 操作
(1)无查询条件
(2)有查询条件
2.2 组合条件查询(多条件查询)
2.3 连接查询(多文档合并查询)
DSL 检索实例
6、ElasticSearch 之文档映射
动态映射实操
静态映射实操
核心类型(Core datatype)
静态映射指定text类型的ik分词器
7、Elasticsearch架构原理
Elasticsearch节点类型
Master节点
DataNode节点
分片和副本机制
分片(Shard)
副本
8、Elasticsearch重点工作流程
Elasticsearch文档写入原理
Elasticsearch检索原理
Elasticsearch准实时索引实现
1.溢写到文件系统缓存
2.写translog保障容错
3. flush到磁盘
4. segment合并
9、ElasticSearch 进级
人工控制搜索结果精准度
实现方式二:使用should+bool搜索,控制搜索条件的匹配度。
Boost 权重控制
基于dis_max实现best fields策略进行多字段搜索
基于tie_breaker参数优化dis_max搜索效果
使用multi_match简化dis_max+tie_breaker
cross fields搜索
copy_to fields 搜索
match phrase 搜索
前缀搜索 prefix search
通配符搜索
正则搜索
搜索推荐
fuzzy模糊搜索
高亮显示
10、ElasticSearch聚合搜索
bucket和metric概念简介
聚合操作案例
根据color分组统计销售数量
统计不同color车辆的平均价格
统计不同color不同brand中车辆的平均价格
统计不同color中的最大和最小价格、总价
统计不同品牌汽车中价格排名最高的车型
histogram 区间统计
date_histogram区间分组
_global bucket
aggs+order
search+aggs
filter+aggs
聚合中使用filter
11、ElasticSearch 嵌套对象
nested object 嵌套对象
父子关系数据建模
父子关系
1、Elasticsearch 简介
Elasticsearch是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,具有HTTP Web接口和无模式JSON文档。Elasticsearch是用Java开发的,并在Apache许可证下作为开源软件发布。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。[5]根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
2、Docker 安装 Elasticsearch
2.1 使用Docker安装ElasticSearch7.6.2
# elasticsearch 镜像检索
docker search elasticsearch
# 下载elasticsearch 指定版本7.6.2
docker pull elasticsearch:7.6.2
# 创建elasticsearch 容器挂载目录地址(配置文件、数据和插件)
mkdir -p /usr/local/es/config /usr/local/es/data /usr/local/es/plugins
# 简单运行elasticsearch 容器
docker run -d \
--name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
elasticsearch:7.6.2
# 拷贝elasticsearch 容器中的配置文件
docker cp elasticsearch:/usr/share/elasticsearch/config /usr/local/es
docker cp elasticsearch:/usr/share/elasticsearch/data /usr/local/es
docker cp elasticsearch:/usr/share/elasticsearch/plugins /usr/local/es
# 通过SFTP将下载的IK插件上传至/usr/local/es/plugins 目录下。
[root@localhost plugins]# ls -a
. .. elasticsearch-analysis-ik-7.6.2
# 修改jvm 运行参数
[root@localhost plugins]# vim /usr/local/es/config/jvm.options
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms64m
-Xmx512m
# 解决跨越配置
[root@localhost plugins]# vim /usr/local/es/config/elasticsearch.yml
添加如下代码片段
http.cors.enabled: true
http.cors.allow-origin: "*"
# 移除简单elasticsearch 容器
[root@localhost plugins]# docker rm -f elasticsearch
elasticsearch
# 再重新启动挂卷elasticsearch 容器实例
[root@localhost config]# docker run -d \
> --name elasticsearch \
> -p 9200:9200 -p 9300:9300 \
> -e "discovery.type=single-node" \
> -v /usr/local/es/config:/usr/share/elasticsearch/config \
> -v /usr/local/es/data:/usr/share/elasticsearch/data \
> -v /usr/local/es/plugins:/usr/share/elasticsearch/plugins \
> elasticsearch:7.6.2
# 检查elasticsearch 服务是否正常启动
[root@localhost config]# curl http://localhost:9200
{
"name" : "0f6f368c4c1d",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "B_p4MWplSiO2cNp3EE9AOg",
"version" : {
"number" : "7.6.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
MobaXterm 实际操作:
# 查看本地镜像资源
[root@localhost docker]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest 0e901e68141f 3 weeks ago 142MB
mysql 5.7 2a0961b7de03 3 weeks ago 462MB
delron/fastdfs latest 8487e86fc6ee 4 years ago 464MB
# 检索elasticsearch 镜像资源
[root@localhost docker]# docker search elasticsearch
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
elasticsearch Elasticsearch is a powerful open source sear… 5665 [OK]
kibana Kibana gives shape to any kind of data — str… 2421 [OK]
bitnami/elasticsearch Bitnami Docker Image for Elasticsearch 54 [OK]
bitnami/elasticsearch-exporter Bitnami Elasticsearch Exporter Docker Image 4 [OK]
# 下载elasticsearch 镜像资源指定版本7.6.2
[root@localhost docker]# docker pull elasticsearch:7.6.2
7.6.2: Pulling from library/elasticsearch
ab5ef0e58194: Pull complete
c4d1ca5c8a25: Pull complete
941a3cc8e7b8: Pull complete
43ec483d9618: Pull complete
c486fd200684: Pull complete
1b960df074b2: Pull complete
1719d48d6823: Pull complete
Digest: sha256:1b09dbd93085a1e7bca34830e77d2981521a7210e11f11eda997add1c12711fa
Status: Downloaded newer image for elasticsearch:7.6.2
# 创建elasticsearch 容器挂载宿主主机文件目录创建
[root@localhost docker]# mkdir -p /usr/local/es/config /usr/local/es/data /usr/local/es/plugins
[root@localhost docker]# cd /usr/local/es
[root@localhost es]# ls -al
总用量 0
drwxr-xr-x. 5 root root 47 6月 21 16:29 .
drwxr-xr-x. 16 root root 192 6月 21 16:29 ..
drwxr-xr-x. 2 root root 6 6月 21 16:29 config
drwxr-xr-x. 2 root root 6 6月 21 16:29 data
drwxr-xr-x. 2 root root 6 6月 21 16:29 plugins
# 简单运行elasticsearch 容器,为了拷贝elasticsearch 容器相关配置文件
[root@localhost es]# docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" elasticsearch:7.6.2
# 进入elasticsearch 容器,下载IK 分词插件
[root@localhost es]# docker exec -it elasticsearch /bin/bash
[root@93e38d04a341 elasticsearch]
# 温馨提示:es 从 v5.5.1 版本开始支持自带的 es 插件命令来安装。
[root@93e38d04a341 elasticsearch]#./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
-> Installing https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
-> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
-> Failed installing https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
-> Rolling back https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
-> Rolled back https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
Exception in thread "main" java.net.UnknownHostException: github.com
at java.base/sun.nio.ch.NioSocketImpl.connect(NioSocketImpl.java:567)
at java.base/java.net.SocksSocketImpl.connect(SocksSocketImpl.java:339)
at java.base/java.net.Socket.connect(Socket.java:603)
无法解析github.com网站,导致elasticsearch-analysis-ik-7.6.2.zip 指定资源无法下载。
解决办法:宿主主机下载elasticsearch-analysis-ik-7.6.2.zip 压缩包,解压压缩包并上传宿主主机的 /usr/local/es/plugins 文件目录下。
# 退出elasticsearch 容器
[root@93e38d04a341 elasticsearch]# exit
exit
# 拷贝elasticsearch 容器配置文件
[root@localhost ~]# docker cp elasticsearch:/usr/share/elasticsearch/config /usr/local/es
[root@localhost ~]# docker cp elasticsearch:/usr/share/elasticsearch/data /usr/local/es
[root@localhost ~]# docker cp elasticsearch:/usr/share/elasticsearch/plugins /usr/local/es
#编辑jvm.option
[root@localhost config]# vim jvm.options
#编辑elasticsearch.yml
[root@localhost config]# vim elasticsearch.yml
#移除简单elasticsearch 容器
[root@localhost plugins]# docker rm -f elasticsearch
elasticsearch
#重新 启动elasticsearch 容器
[root@localhost config]# docker run -d \
> --name elasticsearch \
> -p 9200:9200 -p 9300:9300 \
> -e "discovery.type=single-node" \
> -v /usr/local/es/config:/usr/share/elasticsearch/config \
> -v /usr/local/es/data:/usr/share/elasticsearch/data \
> -v /usr/local/es/plugins:/usr/share/elasticsearch/plugins \
> elasticsearch:7.6.2
0f6f368c4c1d57046f9476bfe63a436c4ee153a4bc677be774a6b0145cf33881
[root@localhost config]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0f6f368c4c1d elasticsearch:7.6.2 "/usr/local/bin/dock…" 4 seconds ago Up 3 seconds 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch
#验证elasticsearch 服务是否正常
[root@localhost config]# curl http://localhost:9200
{
"name" : "0f6f368c4c1d",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "B_p4MWplSiO2cNp3EE9AOg",
"version" : {
"number" : "7.6.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
2.2Elasticsearch 目录详解
ElasticSearch 官网地址:https://www.elastic.co


下载ElasticSearch-7.6.2.zip 包,解压至当前文件目录

目录文件说明:
bin: 启动命令
config: 配置文件
log4j2: 日志配置文件
jvm.options: Java虚拟机 相关配置
elasticsearch.yml: elasticsearch 配置文件
lib: 依赖的相关jar包
log: 日志输出
modules:功能模块
plugins: 插件存放位置,如IK2.3 使用Docker安装elasticSearch--head
- 源码安装,通过npm run start启动(不推荐)
- 通过docker安装(推荐)
- 通过chrome插件安装(推荐)
- 通过ES的plugin方式安装(不推荐)
通过Chrome 插件安装ElasticSearch-head


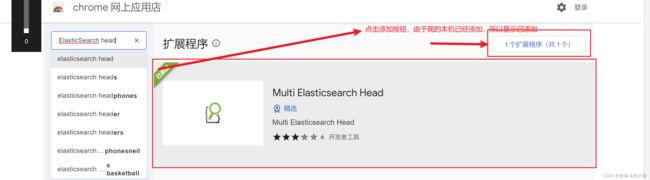
ElasticSearch-Head 插件安装后的效果:

启动ElasticSearch-Head 插件,连接ElasticSearch 服务。

启动ElasticSearch-Head 插件后, 插件默认首页。

点击New 按钮,添加ElasticSearch 服务的IP地址。
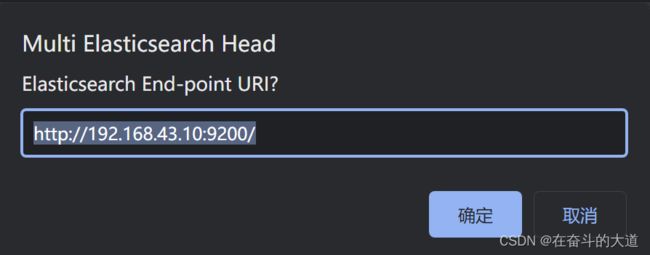

至此,ElasticSearch-Head 插件安装成功,并成功连接ElasticSearch 服务。
ElasticSearch-Head 之Google 插件下载地址:
2.4 了解ELK
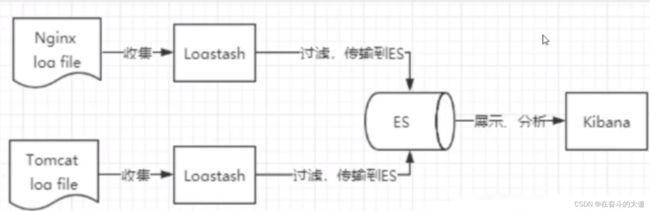
ELK 是ElasticSearch、Logstash、Kibana 三大开源框架首字母。市面上也被称为Elastic Stack。其中ElasticSearch 是一个基于Lucene、分布式、通过Restful方式进行交互的近实时检索平台框架。Logstash 是ELK的中央数据流引擎,用于从不同的目标(文件/数据 存储/MQ)收集不同格式的数据,经过过滤后支持输出到不同的目的地(文件/MQ/Redis/ElasticSearch/KaKa等)。Kibana 可以将ElasticSearch 的数据通过友好的页面展示出来,提供实时分析的功能。
ELK 功能结构图
Docker 安装Kibana
1、下载Kibana
# 检索Kibana 镜像
docker search kibana
# 下载Kibana 镜像指定版本7.4.1
docker pull kibana:7.4.1
# 查看本地镜像资源
docker images
2、编辑kibana的配置文件kibana.yml
在宿主主机上 创建/usr/local/kibana/conf 文件目录用于存放kibana.yml 配置文件。
mkdir -p /usr/local/kibana/conf编辑kibana.yml 文件内容如下:
# Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://192.168.43.10:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true注意:elasticsearch.hosts为Elasticsearch实例。
3、运行 Kibana
# Kibana 运行命令
docker run -d --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name es-kibana -p 5601:5601 -v /usr/local/kibana/conf/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.4.1
# 查看容器启动状态
docker ps
3 ElasticSearch 核心概念
3.1索引 index
3.2 映射 mapping
3.3 字段Field
3.4 字段类型 Type
3.5 文档 document
3.6 集群 cluster
3.7 节点 node
3.8 分片和副本 shards&replicas
分片
- 一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10 亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或 者单个节点处理搜索请求,响应太慢。
- 为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些 份就叫做分片。
- 当创建一个索引的时候,可以指定你想要的分片的数量。
- 每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以 被放置到集群中的任何节点上。
- 分片很重要,主要有两方面的原因
- 允许水平分割/扩展你的内容容量
- 允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
- 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由 Elasticsearch管理的,对于作为用户来说,这些都是透明的
副本
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎 么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转 移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分 片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本
副本之所以重要,有两个主要原因
1) 在分片/节点失败的情况下,提供了高可用性。 注意到复制分片从不与原/主要(original/primary)分片置于同一节点 上是非常重要的
2) 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行
每个索引可以被分成多个分片。一个索引有0个或者多个副本。
一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数 量可以在索引创建的时候指定
在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变 分片的数量
ElasticSearch 分词原理之倒排索引



ElasticSearch 集成IK分词
# 首先官网下载elasticsearch-analysis-ik-7.6.2 分词
官网地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
# 将elasticsearch-analysis-ik-7.6.2 解压文件目录,通过ftp/sftps上传至es plugin挂载卷地址
/usr/local/es/plugins
[root@localhost plugins]# pwd
/usr/local/es/plugins
[root@localhost plugins]# ls -al
总用量 0
drwxr-xr-x. 3 root root 45 6月 21 17:09 .
drwxr-xr-x. 5 root root 47 6月 21 16:29 ..
drwxr-xr-x. 3 root root 243 6月 21 17:09 elasticsearch-analysis-ik-7.6.2
# 重新启动elasticSearch 容器
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0f6f368c4c1d elasticsearch:7.6.2 "/usr/local/bin/dock…" 40 hours ago Up 40 hours 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch
[root@localhost ~]# docker restart 0f6f368
0f6f368
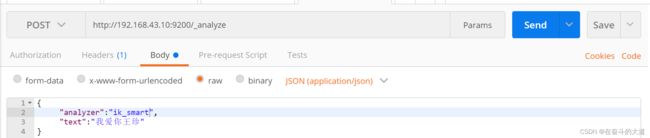
IK分词效果:



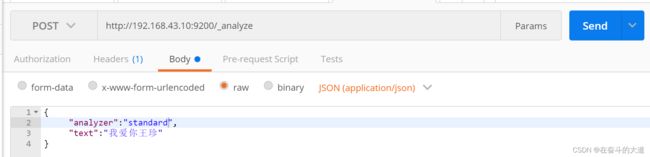

4、ElasticSearch 数据管理
{
"email": "[email protected]",
"name": "周志文",
"age": 30,
"interests": ["厨艺", "阅读"]
}4.1 ElasticSearch 基本操作
1) 创建索引

2) 查询索引

3) 删除索引

4) 添加文档
PUT http://192.168.43.10:9200/es_db/_doc/1
{
"email": "[email protected]",
"name": "周志文",
"age": 30,
"interests": ["厨艺", "阅读"]
}
PUT http://192.168.43.10:9200/es_db/_doc/2
{
"email": "[email protected]",
"name": "周志雄",
"age": 30,
"interests": ["游戏"]
}
PUT http://192.168.43.10:9200/es_db/_doc/3
{
"email": "[email protected]",
"name": "周志刚",
"age": 30,
"interests": ["登山","美食"]
}
5) 修改文档
PUT http://192.168.43.10:9200/es_db/_doc/3
{
"email": "[email protected]",
"name": "周志刚修改",
"age": 29,
"interests": ["编程","美食"]
}
6) 查询文档
GET http://192.168.43.10:9200/es_db/_doc/3
7) 删除文档
DELETE http://192.168.43.10:9200/es_db/_doc/3
8) 查询操作
8.1 查询当前类型中的所有文档 _search
GET http://192.168.43.10:9200/es_db/_doc/_search
8.2 条件查询, 如要查询age等于30岁的 _search?q=*:***
GET http://192.168.43.10:9200/es_db/_doc/_search?q=age:30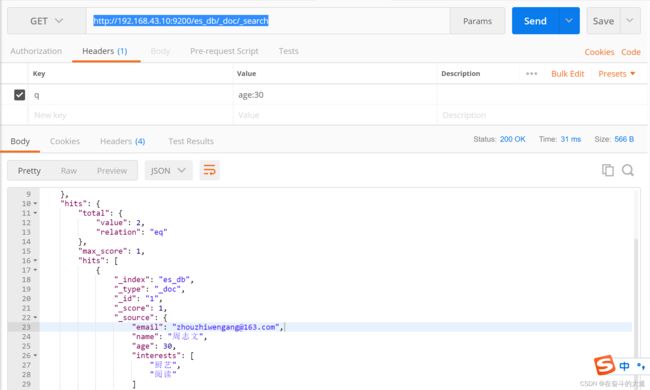
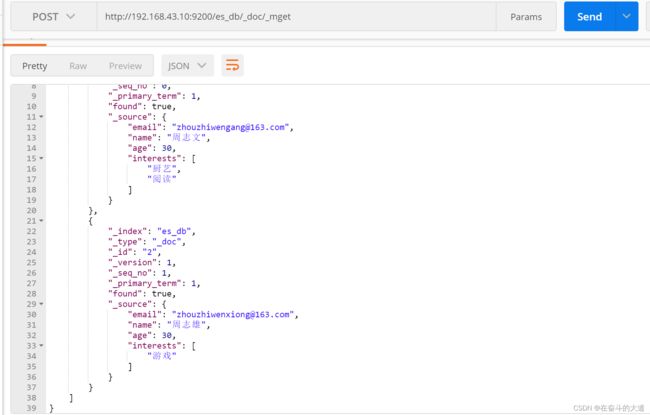
8.3 范围查询, 如要查询age在25至26岁之间的 _search?q=***[** TO **] 注意: TO 必须为大写

POST http://192.168.43.10:9200/es_db/_doc/_mget
{
"ids": [1, 2]
}
8.5 查询年龄小于等于28岁的 :<=
GET http://192.168.43.10:9200/es_db/_doc/_search?q=age:<=28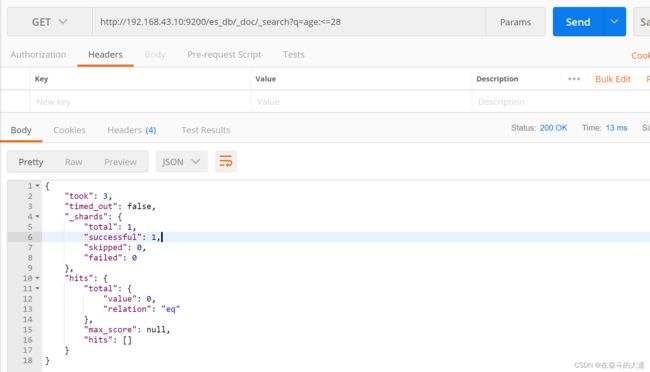
8.6 查询年龄大于28前的 :>=
GET http://192.168.43.10:9200/es_db/_doc/_search?q=age:>=28
GET http://192.168.43.10:9200/es_db/_doc/_search?q=age:>=28&from=0&size=1
8.8 对查询结果只输出某些字段 _source=字段,字段
GET http://192.168.43.10:9200/es_db/_doc/_search?_source=name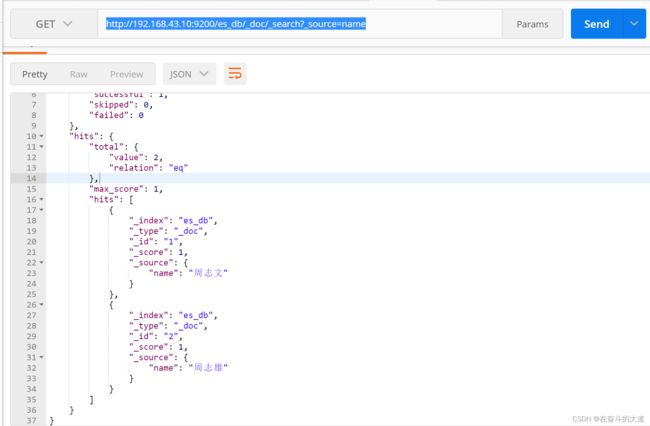
8.9 对查询结果排序 sort=字段:desc/asc
http://192.168.43.10:9200/es_db/_doc/_search?sort=age:desc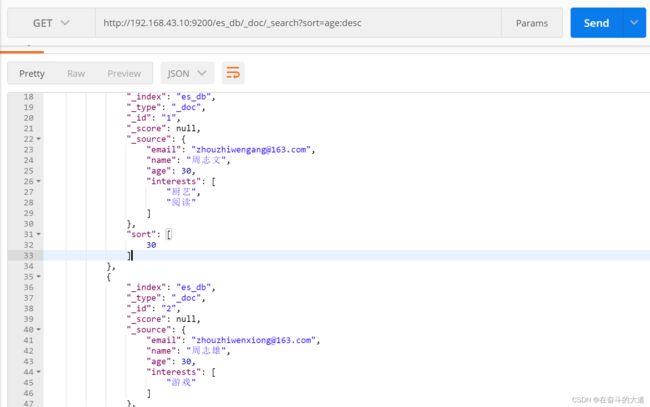
9) 文档批量操作
多个文档是指,批量操作多个文档。
9.1 批量获取文档数据
格式: POST /索引名称/类型/_mget
POST http://192.168.43.10:9200/es_db/_doc/_mget
{
"ids":[1, 2]
}
9.2 批量操作文档数据
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}
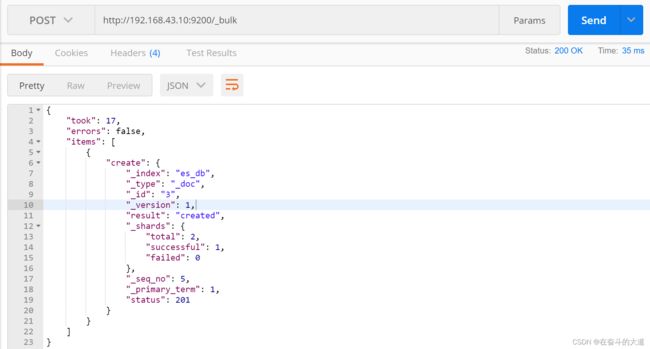
温馨提示:actionName:表示操作类型,主要有create,index,delete和update(1) 批量新增create
POST http://192.168.43.10:9200/_bulk
Content-Type:application/json
{"create": {"_index": "es_db", "_type": "_doc", "_id": 3}}
{"email": "[email protected]", "name": "周志刚", "age": 30, "interests": ["登山","美食"]}
(2) 批量新增或替换index
POST http://192.168.43.10:9200/_bulk
Content-Type:application/json
{"index": {"_index": "es_db", "_type": "_doc", "_id": 3}}
{"email": "[email protected]", "name": "周志刚修改", "age": 28, "interests": ["登山","美食"]}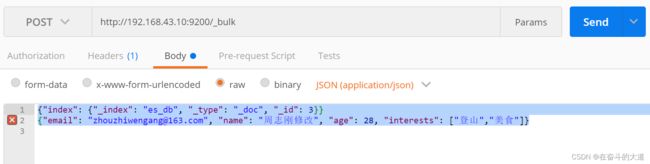

(3)批量删除delete
POST http://192.168.43.10:9200/_bulk
Content-Type:application/json
{"delete": {"_index": "es_db", "_type": "_doc", "_id": 3}}

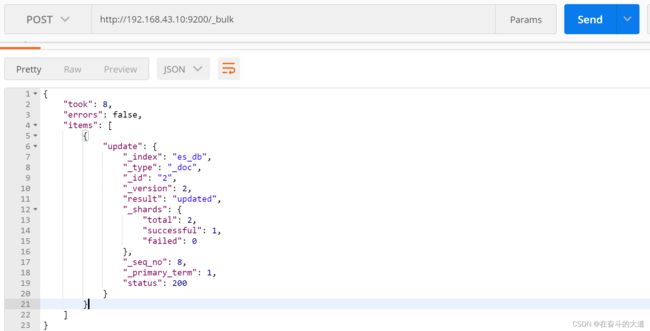
(4)批量修改update
POST http://192.168.43.10:9200/_bulk
Content-Type:application/json
{"update": {"_index": "es_db", "_type": "_doc", "_id": 2}}
{"doc": {"name":"修改"}}

5、ElasticSearch之DSL
Elasticsearch提供了基于JSON的完整查询DSL(特定于域的语言)来定义查询。将查询DSL视为查询的AST(抽象语法树),它由两种子句组成:
- 叶子查询子句:
叶查询子句中寻找一个特定的值在某一特定领域,如 match,term或 range查询。这些查询可以自己使用。 - 复合查询子句
复合查询子句包装其他叶查询或复合查询,并用于以逻辑方式组合多个查询(例如 bool或dis_max查询),或更改其行为(例如 constant_score查询)。
查询子句的行为会有所不同,具体取决于它们是在 查询上下文中还是在过滤器上下文中使用。
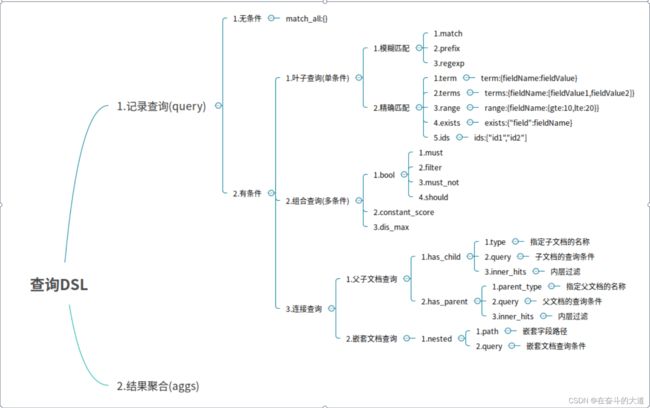
DSL 思维导图
DSL 操作
(1)无查询条件
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"match_all": {}
}
}

(2)有查询条件
- match : 通过match关键词模糊匹配条件内容
- prefix : 前缀匹配
- regexp : 通过正则表达式来匹配数据
query : 指定匹配的值
operator : 匹配条件类
and : 条件分词后都要匹配
or : 条件分词后有一个匹配即可(默认)
minmum_should_match : 指定最小匹配的数量- term : 单个条件相等
- terms : 单个字段属于某个值数组内的值
- range : 字段属于某个范围内的值
- exists : 某个字段的值是否存在
- ids : 通过ID批量查询
2.2 组合条件查询(多条件查询)
bool : 各条件之间有and,or或not的关系
must : 各个条件都必须满足,即各条件是and的关系
should : 各个条件有一个满足即可,即各条件是or的关系
must_not : 不满足所有条件,即各条件是not的关系
filter : 不计算相关度评分,它不计算_score即相关度评分,效率更高
constant_score : 不计算相关度评分温馨提示:must/filter/shoud/must_not 等的子条件是通 过 term/terms/range/ids/exists/match 等叶子条件为参数的 注:以上参数,当只有一个搜索条件时,must等对应的是一个对象,当 是多个条件时,对应的是一个数组。
2.3 连接查询(多文档合并查询)
- 父子文档查询:parent/child
- 嵌套文档查询: nested
DSL 检索实例
查询所有(match_all)
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"match_all": {}
}
}查询结果中返回指定条数(size)
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"match_all": {}
},
"size":1
}

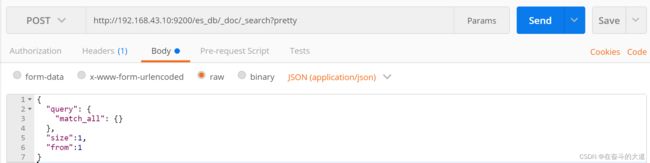
分页查询(from)
from 关键字: 用来指定起始返回位置,和size关键字连用可实现分页效果
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"match_all": {}
},
"size":1,
"from":1
}

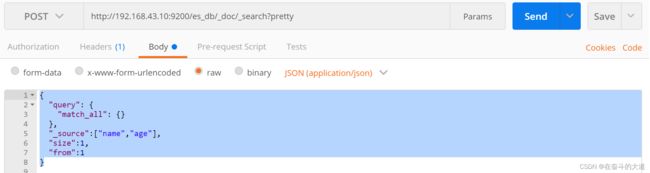
查询结果中返回指定字段(_source)
source 关键字: 是一个数组,在数组中用来指定展示那些字段
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"match_all": {}
},
"_source":["name","age"],
"size":1,
"from":1
}

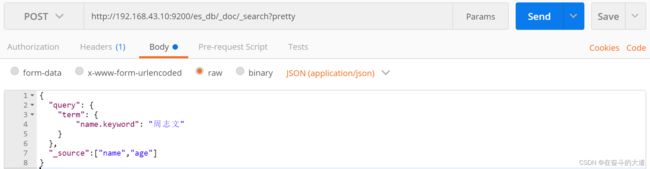
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"term": {
"name.keyword": "周志文"
}
},
"_source":["name","age"]
}

POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"match": {
"name": "周"
}
},
"_source":["name","age"]
}


POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"multi_match": {
"query": 30,
"fields":["age"]
}
},
"_source":["name","age"]
}


等于SQL:
SQL: select * from t_user where age like '%30%'- 未指定字段条件查询 query_string , 含 AND 与 OR 条件
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"query_string": {
"query": "周 or 30"
}
},
"_source":["name","age"]
}


- 指定字段条件查询 query_string , 含 AND 与 OR 条件
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"query_string": {
"query": "周 and zhou",
"fields":["name"]
}
},
"_source":["name","age"]
}

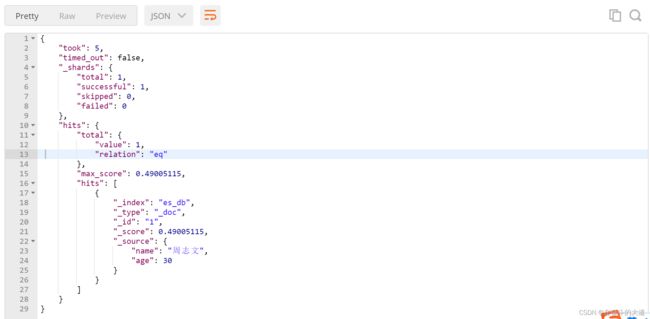
Rang 范围查询
大于、等于和小于转义
- gte 大于等于
- lte 小于等于
- gt 大于
- lt 小于
- now 当前时间
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"range": {
"age":{
"gte": 25,
"lte":31
}
}
},
"_source":["name","age"]
}


等于SQL:
select * from t_user where age between 25 and 31前缀查询(prefix)
prefix 关键字: 用来检索含有指定前缀的关键词的相关文档
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"prefix": {
"name":{
"value": "修"
}
}
},
"_source":["name","age"]
}


通配符查询(wildcard)
wildcard 关键字: 通配符查询 ? 用来匹配一个任意字符 * 用来匹配多个任意字符
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"wildcard": {
"name":{
"value": "周*"
}
}
},
"_source":["name","age"]
}

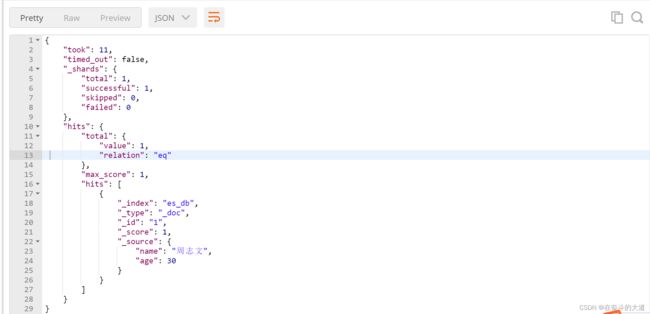
多id查询(ids)
ids 关键字 : 值为数组类型,用来根据一组id获取多个对应的文档
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"ids": {
"values":[1,2]
}
},
"_source":["name","age"]
}

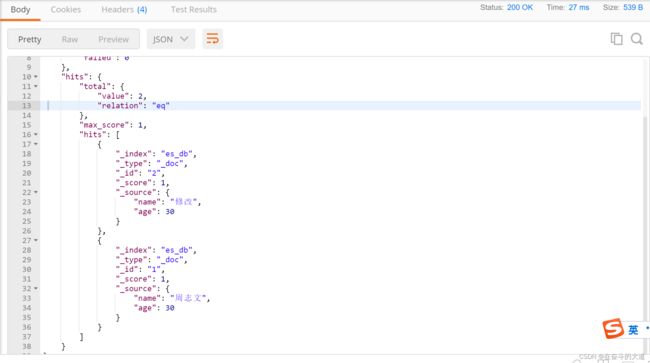
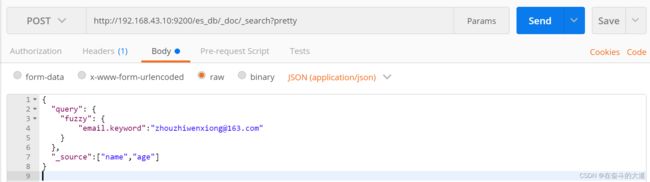
模糊查询(fuzzy)
fuzzy 关键字: 用来模糊查询含有指定关键字的文档。
POST http://192.168.43.10:9200/es_db/_doc/_search?pretty
{
"query": {
"fuzzy": {
"email.keyword":"[email protected]"
}
},
"_source":["name","age"]
}

6、ElasticSearch 之文档映射

动态映射实操
DELETE http://192.168.43.10:9200/es_db
PUT http://192.168.43.10:9200/es_dbPUT http://192.168.43.10:9200/es_db/_doc/1
{
"name":"周志文",
"sex":1,
"age":31,
"book":"java入门至精通",
"address":"广东深圳"
}GET http://192.168.43.10:9200/es_db/_mapping
响应结果:
{
"es_db": {
"mappings": {
"properties": {
"address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
},
"book": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "long"
}
}
}
}
}
静态映射实操
删除原创建的索引
DELETE http://192.168.43.10:9200/es_dbPUT http://192.168.43.10:9200/es_db
{
"mappings":{
"properties":{
"address":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"age":{
"type":"long"
},
"book":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"name":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"sex":{
"type":"long"
}
}
}
}PUT http://192.168.43.10:9200/es_db/_doc/1
{
"name":"周志刚",
"sex":1,
"age":31,
"book":"elasticSearch入门至精通",
"address":"广东深圳"
}获取文档映射
GET http://192.168.43.10:9200/es_db/_mapping核心类型(Core datatype)
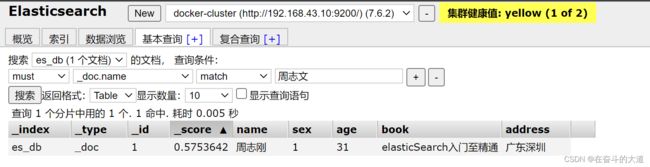
静态映射指定text类型的ik分词器
PUT http://192.168.43.10:9200/es_db/
{
"mappings":{
"properties":{
"address":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"age":{
"type":"long"
},
"book":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"name":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
},
"index":true,
"store":true,
"analyzer":"ik_smart",
"search_analyzer": "ik_smart"
},
"sex":{
"type":"long"
}
}
}
}
7、Elasticsearch架构原理
Elasticsearch节点类型
Master节点
- 管理索引(创建索引、删除索引)、分配分片
- 维护元数据
- 管理集群节点状态
- 不负责数据写入和查询,比较轻量级
DataNode节点
分片和副本机制
分片(Shard)
副本
PUT http://192.168.43.10:9200/es_db/
{
"mappings":{
"properties":{
"address":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"age":{
"type":"long"
},
"book":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"name":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
},
"index":true,
"store":true,
"analyzer":"ik_smart",
"search_analyzer": "ik_smart"
},
"sex":{
"type":"long"
}
}
},
"settings":{
"number_of_shards":1,
"number_of_replicas":1
}
}8、Elasticsearch重点工作流程
Elasticsearch文档写入原理

1.选择任意一个DataNode发送请求,例如:node2。此时,node2就成为一个coordinating node(协调节点)2.计算得到文档要写入的分片`shard = hash(routing) % number_of_primary_shards`routing 是一个可变值,默认是文档的 _id3.coordinating node会进行路由,将请求转发给对应的primary shard所在的DataNode(假设primary shard在node1、replica shard在node24.node1节点上的Primary Shard处理请求,写入数据到索引库中,并将数据同步到Replica shard5.Primary Shard和Replica Shard都保存好了文档,返回client
Elasticsearch检索原理

1.client发起查询请求,某个DataNode接收到请求,该DataNode就会成为协调节点 (Coordinating Node)2.协调节点(Coordinating Node)将查询请求广播到每一个数据节点,这些数据节点的分片会处理该查询请求3.每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档ID、节点信息、分片信息返回给协调节点4.协调节点将所有的结果进行汇总,并进行全局排序5.协调节点向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据返回给客户端
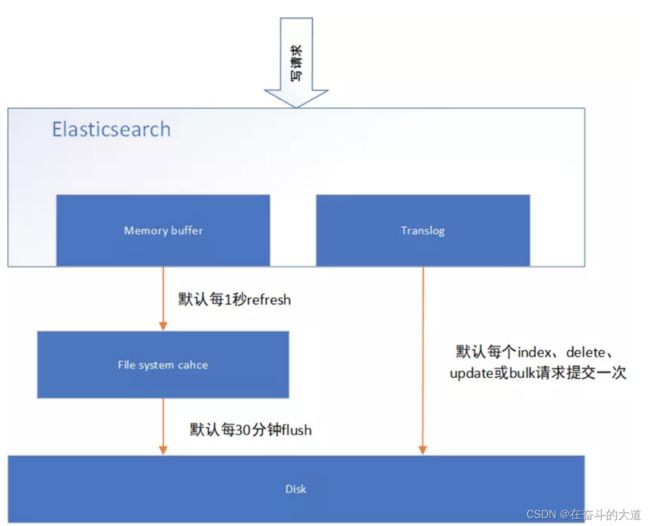
Elasticsearch准实时索引实现
1.溢写到文件系统缓存
2.写translog保障容错
3. flush到磁盘
4. segment合并
9、ElasticSearch 进级
人工控制搜索结果精准度
演示数据:
PUT http://192.168.43.10:9200/db/_doc/1
{
"name":"周志熊",
"sex":1,
"age":31,
"remark":"java developer",
"address":"广东深圳"
}
PUT http://192.168.43.10:9200/db/_doc/2
{
"name":"周志文",
"sex":1,
"age":26,
"remark":"vue developer",
"address":"广东广州"
}
PUT http://192.168.43.10:9200/db/_doc/3
{
"name":"周志钢",
"sex":1,
"age":29,
"remark":"elasticsearch developer",
"address":"广东广州"
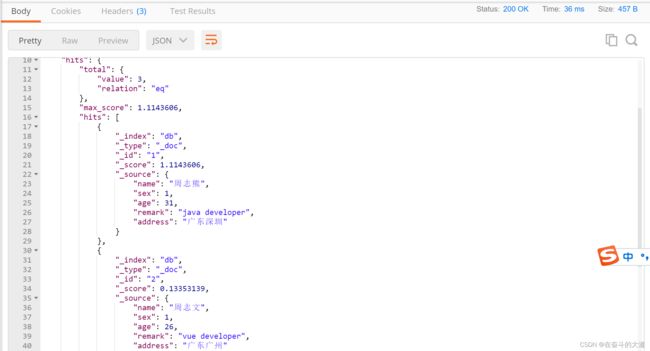
}功能实现:在索引库(db)中,文档(document)中的remark字段包含java或developer词组,都符合搜索条件
POST http://192.168.43.10:9200/db/_search
{
"query": {
"match": {
"remark": "java developer"
}
}
}
POST http://192.168.43.10:9200/db/_search
{
"query": {
"match": {
"remark": {
"query": "java developer",
"operator": "and"
}
}
}
}
温馨提示:如果将operator的值改为or。则与第一个案例搜索语法效果一致。默认的ES执行搜索的时候,operator就是or。
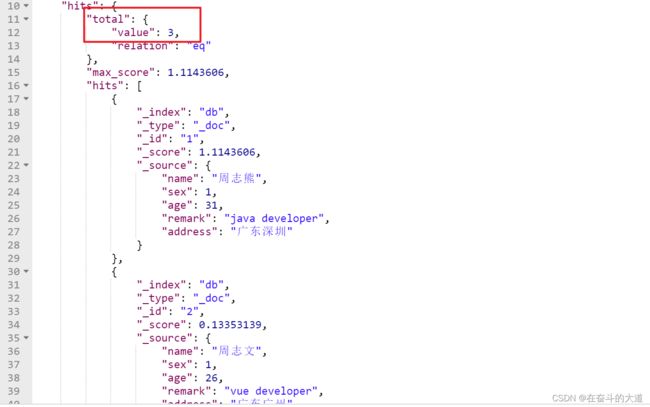
功能升级:如果要求在搜索的文档document中,需要remark字段中包含多个搜索词条中的一定比 例,可以使用下述方式实现。
实现方式一:minimum_should_match百分比或固定数字。
POST http://192.168.43.10:9200/db/_search
{
"query": {
"match": {
"remark": {
"query": "java developer",
"minimum_should_match": "50%"
}
}
}
}
更新db/1 的索引 数据
PUT http://192.168.43.10:9200/db/_doc/1
{
"name":"周志熊",
"sex":1,
"age":31,
"remark":"java developer china",
"address":"广东深圳"
}温馨提示:搜索条件中词条百分比,如果无法整除,向下匹配 (如,query条件有3个单词,如果使用百分比提供精准度计算,那么是无法除尽的,如果需要至少匹配两个单词,则需要用67%来进行描述。如果使用66%描述,ES则认为匹配一个单词即可。)
POST http://192.168.43.10:9200/db/_search
{
"query": {
"match": {
"remark": {
"query": "java developer china",
"minimum_should_match": "68%"
}
}
}
}
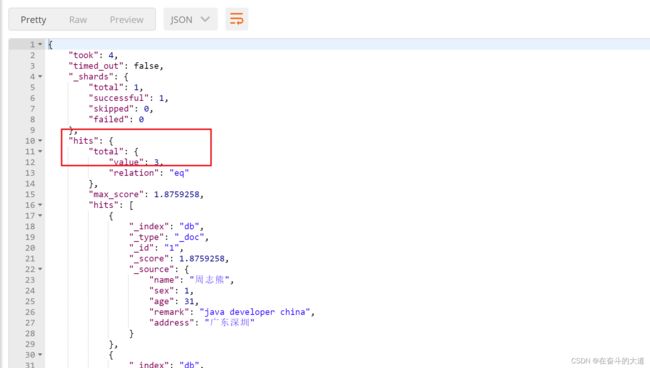
POST http://192.168.43.10:9200/db/_search
{
"query": {
"match": {
"remark": {
"query": "java developer china",
"minimum_should_match": "30%"
}
}
}
} 
实现方式二:使用should+bool搜索,控制搜索条件的匹配度。
具体操作如下:下述案例代表搜索的document中的remark字段中,必须匹配java、developer、 China三个词条中的至少2个。
POST http://192.168.43.10:9200/db/_search
{
"query": {
"bool": {
"should": [{
"match": {
"remark": "java"
}
}, {
"match": {
"remark": "developer"
}
}, {
"match": {
"remark": "china"
}
}],
"minimum_should_match": 2
}
}
}
Boost 权重控制
POST http://192.168.43.10:9200/db/_search
{
"query": {
"bool": {
"must":[{
"match":{
"remark":"java"
}
}],
"should": [{
"match": {
"remark": {
"query":"developer",
"boost": 1
}
}
}, {
"match": {
"remark":{
"query":"china",
"boost": 3
}
}
}]
}
}
}
基于dis_max实现best fields策略进行多字段搜索
POST http://192.168.43.10:9200/db/_search
{
"query": {
"dis_max": {
"queries": [{
"match": {
"name": "周志熊"
}
}, {
"match": {
"remark": "java developer"
}
}]
}
}
}
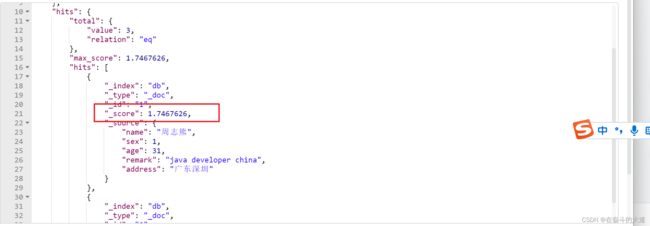
基于tie_breaker参数优化dis_max搜索效果
POST http://192.168.43.10:9200/db/_search
{
"query": {
"dis_max": {
"queries": [{
"match": {
"name": "周志熊"
}
}, {
"match": {
"remark": "java developer"
}
}],
"tie_breaker":0.5
}
}
}
使用multi_match简化dis_max+tie_breaker
ES中相同结果的搜索也可以使用不同的语法语句来实现。
POST http://192.168.43.10:9200/db/_search
{
"query": {
"dis_max": {
"queries": [{
"match": {
"name": "周志熊"
}
}, {
"match": {
"remark":{
"query": "java developer",
"boost" : 2,
"minimum_should_match": 2
}
}
}],
"tie_breaker":0.5
}
}
}
cross fields搜索
POST http://192.168.43.10:9200/db/_search
{
"query": {
"multi_match": {
"query": "java developer",
"fields": ["name", "remark"],
"type": "cross_fields",
"operator": "and"
}
}
}
上述功能说明:搜索条件中的java必须在name或remark字段中匹配, developer也必须在name或remark字段中匹配。
温馨提示:
most field策略问题:most fields策略是尽可能匹配更多的字段,所以会导致精确搜索结果排序问题。又因为cross fields搜索,不能使用minimum_should_match来去除长尾数据。所以在使用most fields和cross fields策略搜索数据的时候,都有不同的缺陷。所以商业项目开发中,都推荐使用best fields策略实现搜索。
copy_to fields 搜索
{
"category_name":"手机",
"product_name":"一加6T手机",
"price":568800,
"sell_point":"国产最好的Android手机",
"tags":[
"8G+128G",
"256G可扩展"
],
"color":"红色",
"keyword":"手机 一加6T手机 国产最好的Android手机"
}PUT http://192.168.43.10:9200/es_product/
{
"mappings":{
"properties":{
"provice":{
"type":"text",
"analyzer":"ik_smart",
"copy_to":"address"
},
"city":{
"type":"text",
"analyzer":"ik_smart",
"copy_to":"address"
},
"street":{
"type":"text",
"analyzer":"ik_smart",
"copy_to":"address"
},
"address":{
"type":"text",
"analyzer":"ik_smart"
}
}
}
}PUT http://192.168.43.10:9200/es_product/_doc/1
{
"provice":"广东.深圳.华为技术有限公司",
"city":"深圳.龙华区.华为技术研发中心",
"street":"天安街道.华为大道",
"address":"华为产业园"
}copy_to 查询:
POST http://192.168.43.10:9200/es_product/_doc/_search?pretty
{
"query": {
"match": {
"address": "广东"
}
}
}
match phrase 搜索
POST http://192.168.43.10:9200/db/_doc/_search?pretty
{
"query":{
"match_phrase":{
"remark":"vue developer"
}
}
}
前缀搜索 prefix search
POST http://192.168.43.10:9200/db/_doc/_search
{
"query":{
"prefix":{
"address.keyword":{
"value":"广"
}
}
}
}通配符搜索
- ? - 一个任意字符
- * - 0~n个任意字符
POST http://192.168.43.10:9200/db/_doc/_search
{
"query":{
"wildcard":{
"address.keyword":{
"value":"?东*"
}
}
}
}
不推荐使用。
正则搜索
- [] - 范围,如: [0-9]是0~9的范围数字
- . - 一个字符
- + - 前面的表达式可以出现多次。
POST http://192.168.43.10:9200/db/_doc/_search
{
"query":{
"regexp":{
"address.keyword":"[A‐z].+"
}
}
}
搜索推荐
fuzzy模糊搜索
POST http://192.168.43.10:9200/db/_doc/_search
{
"query":{
"fuzzy":{
"remark":{
"value":"develop",
"fuzziness": 2
}
}
}
}
高亮显示
POST http://192.168.43.10:9200/db/_doc/_search
{
"query":{
"match":{
"address":"广东"
}
},
"highlight":{
"fields":{
"address":{}
}
}
}
10、ElasticSearch聚合搜索
bucket和metric概念简介
POST http://192.168.43.10:9200/es_cars/
{
"mappings":{
"properties":{
"price":{
"type":"long"
},
"color":{
"type":"keyword"
},
"brand":{
"type":"keyword"
},
"model":{
"type":"keyword"
},
"sold_date":{
"type":"date",
"format": "yyyy-MM-dd||epoch_millis"
},
"remark":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}添加验收数据:
PUT http://192.168.43.10:9200/es_cars/_doc/1
{
"price": 123000,
"color": "金色",
"brand": "大众",
"model": "大众速腾",
"sold_date": 1636076363000,
"remark": "大众神车"
}
PUT http://192.168.43.10:9200/es_cars/_doc/2
{
"price": 123000,
"color": "金色",
"brand": "大众",
"model": "大众速腾",
"sold_date": 1636076363000,
"remark": "大众神车"
}
PUT http://192.168.43.10:9200/es_cars/_doc/3
{
"price": 239800,
"color": "白色",
"brand": "标志",
"model": "标志508",
"sold_date": 1621301963000,
"remark": "标志品牌全球上市车型"
}
PUT http://192.168.43.10:9200/es_cars/_doc/4
{
"price": 148800,
"color": "白色",
"brand": "标志",
"model": "标志408",
"sold_date": 1625296980000,
"remark": "比较大的紧凑型车"
}
PUT http://192.168.43.10:9200/es_cars/_doc/5
{
"price": 1998000,
"color": "黑色",
"brand": "大众",
"model": "大众辉腾",
"sold_date": 1629444180000,
"remark": "大众最让人肝疼的车"
}
PUT http://192.168.43.10:9200/es_cars/_doc/7
{
"price": 218000,
"color": "红色",
"brand": "奥迪",
"model": "奥迪A4",
"sold_date": 1636183380000,
"remark": "小资车型"
}
PUT http://192.168.43.10:9200/es_cars/_doc/8
{
"price": 489000,
"color": "黑色",
"brand": "奥迪",
"model": "奥迪A6",
"sold_date": 1641108180000,
"remark": "政府专用?"
}
PUT http://192.168.43.10:9200/es_cars/_doc/9
{
"price": 1899000,
"color": "黑色",
"brand": "奥迪",
"model": "奥迪A 8",
"sold_date": 1644736980000,
"remark": "很贵的大A6。。。"
}
聚合操作案例
根据color分组统计销售数量
POST http://192.168.43.10:9200/es_cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"_count": "desc"
}
}
}
}
}结果:
统计不同color车辆的平均价格
POST http://192.168.43.10:9200/es_cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_by_price": "asc"
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}温馨提示:size可以设置为0,表示不返回ES中的文档,只返回ES聚合之后的数据,提高查询速度,当然如果你需要这些文档的话,也可以按照实际情况进行设置。
POST http://192.168.43.10:9200/es_cars/_search
{
"size":0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_by_price": "asc"
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}统计不同color不同brand中车辆的平均价格
POST /index_name/type_name/_search
{
"aggs": {
"定义分组名称(最外层)": {
"分组策略如:terms、avg、sum": {
"field": "根据哪一个字段分组",
"其他参数": ""
},
"aggs": {
"分组名称1": {},
"分组名称2": {}
}
}
}
}POST http://192.168.43.10:9200/es_cars/_search
{
"size":0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_by_price_color": "asc"
}
},
"aggs": {
"avg_by_price_color": {
"avg": {
"field": "price"
}
},
"group_by_brand": {
"terms": {
"field": "brand",
"order": {
"avg_by_price_brand": "desc"
}
},
"aggs": {
"avg_by_price_brand": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}统计不同color中的最大和最小价格、总价
POST http://192.168.43.10:9200/es_cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price": {
"min": {
"field": "price"
}
},
"sum_price": {
"sum": {
"field": "price"
}
}
}
}
}
}统计不同品牌汽车中价格排名最高的车型
POST http://192.168.43.10:9200/es_cars/_search
{
"size": 0,
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"top_car": {
"top_hits": {
"size": 1,
"sort": [{
"price": {
"order": "desc"
}
}],
"_source": {
"includes": ["model", "price"]
}
}
}
}
}
}
}histogram 区间统计
POST http://192.168.43.10:9200/es_cars/_search
{
"size":0,
"aggs": {
"histogram_by_price": {
"histogram": {
"field": "price",
"interval": 1000000
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}date_histogram区间分组
POST http://192.168.43.10:9200/es_cars/_search
{
"aggs": {
"histogram_by_date": {
"date_histogram": {
"field": "sold_date",
"calendar_interval": "month",
"format": "epoch_millis",
"min_doc_count": 1,
"extended_bounds": {
"min": 1609469857000,
"max": 1672455457000
}
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}_global bucket
POST http://192.168.43.10:9200/es_cars/_search
{
"size": 0,
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"volkswagen_of_avg_price": {
"avg": {
"field": "price"
}
},
"all_avg_price": {
"global": {},
"aggs": {
"all_of_price": {
"avg": {
"field": "price"
}
}
}
}
}
}aggs+order
POST http://192.168.43.10:9200/es_cars/_search
{
"size": 0,
"aggs": {
"group_of_brand": {
"terms": {
"field": "brand",
"order": {
"sum_of_price": "desc"
}
},
"aggs": {
"sum_of_price": {
"sum": {
"field": "price"
}
}
}
}
}
}POST http://192.168.43.10:9200/es_cars/_search
{
"size":0,
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"sum_of_price": "desc"
}
},
"aggs": {
"sum_of_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
}
}search+aggs
POST http://192.168.43.10:9200/es_cars/_search
{
"size": 0,
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"histogram_by_date": {
"date_histogram": {
"field": "sold_date",
"calendar_interval": "quarter",
"min_doc_count": 1
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}filter+aggs
POST http://192.168.43.10:9200/es_cars/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 100000,
"lte": 500000
}
}
}
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}聚合中使用filter
- 12M/M 表示 12 个月。
- 1y/y 表示 1年。
- d 表示天
POST http://192.168.43.10:9200/es_cars/_search
{
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"count_last_year": {
"filter": {
"range": {
"sold_date": {
"gte":1640919457000
}
}
},
"aggs": {
"sum_of_price_last_year": {
"sum": {
"field": "price"
}
}
}
}
}
}11、ElasticSearch 嵌套对象
案例:设计一个用户document数据类型,其中包含一个地址数据的数组,这种设计方式相对复杂,但是在管理数据时,更加的灵活。
PUT http://192.168.43.10:9200/es_user/
{
"mappings": {
"properties": {
"login_name": {
"type": "keyword"
},
"age ": {
"type": "short"
},
"address": {
"properties": {
"province": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"street": {
"type": "keyword"
}
}
}
}
}
}
PUT http://192.168.43.10:9200/es_user/_doc/1
{
"login_name": "jack",
"age": 25,
"address": [{
"province": "北京",
"city": "北京",
"street": "枫林三路"
}, {
"province": "天津",
"city": "天津",
"street": "华夏路"
}]
}
PUT http://192.168.43.10:9200/es_user/_doc/2
{
"login_name": "rose",
"age": 21,
"address": [{
"province": "河北",
"city": "廊坊",
"street": "燕郊经济开发区"
}, {
"province": "天津",
"city": "天津",
"street": "华夏路"
}]
}POST http://192.168.43.10:9200/es_user/_search
{
"query": {
"bool": {
"must": [{
"match": {
"address.province": "北京"
}
}, {
"match": {
"address.city": "天津"
}
}]
}
}
}nested object 嵌套对象
PUT http://192.168.43.10:9200/es_user_nested
{
"mappings": {
"properties": {
"login_name": {
"type": "keyword"
},
"age": {
"type": "short"
},
"address": {
"type": "nested",
"properties": {
"province": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"street": {
"type": "keyword"
}
}
}
}
}
}POST http://192.168.43.10:9200/es_cars/_search
{
"query": {
"bool": {
"must": [{
"nested": {
"path": "address",
"query": {
"bool": {
"must": [{
"match": {
"address.province": "北京"
}
}, {
"match": {
"address.city": "北京"
}
}]
}
}
}
}]
}
}
}父子关系数据建模
父子关系
- 设置索引的 Mapping
- 索引父文档
- 索引子文档
- 按需查询文档
设置Mapping
PUT http://192.168.43.10:9200/my_blogs
{
"mappings": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
}
}
}
}上述代码建立了一个my_blogs的索引,其中blog_comments_relation是一个用于join的字段,type为join,关系relations为:父为blog, 子为comment
至于建立一父多子关系,只需要改为数组即可:"blog": ["answer", "comment"]
PUT http://192.168.43.10:9200/my_blogs/_doc/blog1
{
"title": "Learning Elasticsearch",
"content": "learning ELK is happy",
"blog_comments_relation": {
"name": "blog"
}
}
温馨提示:可以省略name
PUT http://192.168.43.10:9200/my_blogs/_doc/blog2
{
"title": "Learning Hadoop",
"content": "learning Hadoop",
"blog_comments_relation": {
"name": "blog"
}
}
插入子文档
子文档的插入语法如下,注意routing是父文档的id,平时我们插入文档时routing的默认就是id此时name为answer,表示这是个子文档。
PUT http://192.168.43.10:9200/my_blogs/_doc/comment1?routing=blog1
{
"comment": "I am learning ELK",
"username": "Jack",
"blog_comments_relation": {
"name": "comment",
"parent": "blog1"
}
}
PUT http://192.168.43.10:9200/my_blogs/_doc/comment2?routing=blog2
{
"comment": "I like Hadoop!!!!!",
"username": "Jack",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}
PUT http://192.168.43.10:9200/my_blogs/_doc/comment3?routing=blog2
{
"comment": "Hello Hadoop",
"username": "Bob",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}- 查询所有文档
- Parent Id 查询
- Has Child 查询
- Has Parent 查询
# 查询所有文档
POST http://192.168.43.10:9200/my_blogs/_search
{}
#根据父文档ID查看
GET http://192.168.43.10:9200/my_blogs/_doc/blog2
# Parent Id 查询
POST http://192.168.43.10:9200/my_blogs/_search
{ "query": { "parent_id": { "type": "comment", "id": "blog2" } } }
# Has Child 查询,返回父文档
POST http://192.168.43.10:9200/my_blogs/_search
{ "query": { "has_child": { "type": "comment", "query" : { "match": { "username" : "Jack" } } } } }
# Has Parent 查询,返回相关的子文档
POST http://192.168.43.10:9200/my_blogs/_search
{ "query": { "has_parent": { "parent_type": "blog", "query" : { "match": { "title" : "Learning Hadoop" } } } } }