机器学习西瓜书&南瓜书 线性模型
机器学习西瓜书&南瓜书 线性模型
1. 基本形式
给定由d个属性描述的示例 x = ( x 1 ; x 2 ; . . . x d ) x=(x_1;x_2;...x_d) x=(x1;x2;...xd),其中 x i x_i xi是x在第i个属性上的取值,线性模型(linear model)试图学得一个通过属性的线性组合来进行预测的函数,即:
f ( x ) = ω 1 x 1 + ω 2 x 2 + . . . + ω d x d + b f(x) = \omega_1x_1 + \omega_2x_2 + ... + \omega_dx_d + b f(x)=ω1x1+ω2x2+...+ωdxd+b
一般用向量形式写成:
f ( x ) = ω T x + b f(x) = \omega^T\boldsymbol{x} + b f(x)=ωTx+b
其中 w = ( w 1 ; w 2 ; . . . w d ) w=(w_1;w_2;...w_d) w=(w1;w2;...wd),w和b学得之后,模型就得以确定。
2.线性回归
2.1 一元线性回归
当给定数据集 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) , . . . , ( x m , y m ) D = {(x_1, y_1 ), (x_2, y_2 ), (x_3, y_3),...,(x_m, y_m)} D=(x1,y1),(x2,y2),(x3,y3),...,(xm,ym),其中 x i = ( x i 1 ; x i 2 ; . . . ; x i d ) , y i ∈ R \boldsymbol{x}_i = (x_{i1}; x_{i2}; ...; x_{id}), y_i \in \mathbb{R} xi=(xi1;xi2;...;xid),yi∈R。线性回归(linear regression)试图学得一个线性模型尽可能准确地预测实值输出标记。
对于离散属性,若属性间存在“序”order关系,可通过连续化将其转换为连续值,例如高度中的“高”、“中”、“矮”可转化为{1.0, 0.5, 0.0};若属性值间不存在序关系,则通常转换为k维向量。
若将无序属性连续化,则会不恰当地引入序关系,对后续处理如距离计算等造成误导。
线性回归试图学得:
f ( x i ) = ω x i + b , 使 得 f ( x i ) ≃ y i f(x_i) = \omega x_i + b, 使得f(x_i) \simeq y_i f(xi)=ωxi+b,使得f(xi)≃yi
如何确定 ω \omega ω和b呢,关键在于衡量f(x)与y之间的差别,其中均方误差(又称平方损失square loss)是回归任务中最常用的性能度量,因此我们试图让均方误差最小化,即:
( w ∗ , b ∗ ) = a r g m i n ( w , b ) ∑ i = 1 m ( f ( x i ) − y i ) 2 = a r g m i n ( w , b ) ∑ i = 1 m ( y i − ω x i − b ) 2 (w^*, b^*) = argmin_{(w, b)}\sum_{i=1}^m(f(x_i) - y_i) ^2 \\ = argmin_{(w, b)}\sum_{i=1}^m(y_i - \omega x_i - b) ^ 2 (w∗,b∗)=argmin(w,b)i=1∑m(f(xi)−yi)2=argmin(w,b)i=1∑m(yi−ωxi−b)2
均方误差对应了常用的欧几里得距离或简称“欧式距离”(Euclidean distance)
基于均方误差最小化来进行模型求解的方法称为“最小二乘法”(least square method)。
求解 ω \omega ω和b使 E ( w , b ) = ∑ i = 1 m ( y i − ω x i − b ) 2 E_{(w, b)} = \sum_{i=1}^m(y_i - \omega x_i - b)^2 E(w,b)=∑i=1m(yi−ωxi−b)2最小化的过程,称为线性回归模型的最小二乘“参数估计”(parameter estimation),可对 E ( w , b ) E_{(w, b)} E(w,b)分别对 ω \omega ω和b求导,得到:
∂ E ( w , b ) ∂ b = 2 ( ω ∑ i = 1 m x i 2 − ∑ i = 1 m ( y i − b ) x i ) ∂ E ( w , b ) ∂ b = 2 ( m b − ∑ i = 1 m ( y i − ω x i ) ) \frac{\partial E_{(w, b)}}{\partial b} = 2(\omega \sum_{i=1}^mx_i^2 - \sum_{i=1}^m(y_i - b)x_i) \\ \frac{\partial E_{(w, b)}}{\partial b} = 2(mb - \sum_{i=1}^m(y_i - \omega x_i)) ∂b∂E(w,b)=2(ωi=1∑mxi2−i=1∑m(yi−b)xi)∂b∂E(w,b)=2(mb−i=1∑m(yi−ωxi))
然后令上式为0可得到 ω \omega ω和b最优解的闭式(closed-form)解
ω = ∑ i = 1 m y i ( x i − x ˉ ) ∑ i = 1 m x i 2 − 1 m ( ∑ i = 1 m x i ) 2 b = 1 m ∑ i = 1 m ( y i − ω x i ) \omega = \frac{\sum_{i=1}^my_i(x_i - \bar{x})}{\sum_{i=1}^mx_i^2 - \frac{1}{m}(\sum_{i=1}^mx_i)^2} \\ b = \frac{1}{m}\sum_{i=1}^m(y_i - \omega x_i) ω=∑i=1mxi2−m1(∑i=1mxi)2∑i=1myi(xi−xˉ)b=m1i=1∑m(yi−ωxi)
其中 x ˉ = 1 m ∑ i = 1 m x i \bar{x} = \frac{1}{m}\sum_{i=1}^mx_i xˉ=m1∑i=1mxi为x的均值
2.2 多元线性回归
多元线性回归(multivariate linear regression):若数据集D,样本由d个属性描述,此时我们试图学得:
f ( x i ) = ω x i + b , 使 得 f ( x i ) ≃ y i f(x_i) = \boldsymbol{\omega}\boldsymbol{x}_i + b, 使得f(\boldsymbol{x}_i) \simeq y_i f(xi)=ωxi+b,使得f(xi)≃yi
2.3 广义线性回归
一般线性回归模型简写为:
y = ω T x + b y = \omega^Tx+b y=ωTx+b
有时候可令模型预测值逼近y的衍生物(即y的函数),如可将输出标记的对数作为线性模型逼近的目标,即:
l n y = ω T x + b lny = \omega^Tx + b lny=ωTx+b
该式在求取输入空间到输出空间的非线性函数映射,这里的对数函数将线性回归模型的预测值与真实标记联系起来,称为“对数线性回归”(log-linear regression)。
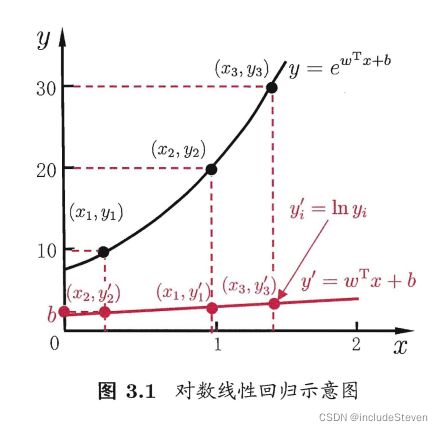
更一般地,考虑单调可微函数 g ( ⋅ ) g(\cdot) g(⋅),令
y = g − 1 ( ω T x + b ) y = g^{-1}(\omega^Tx + b) y=g−1(ωTx+b)
这里得到的模型称为“广义线性模型”(generalizaed linear model),其中函数 g ( ⋅ ) g(\cdot) g(⋅)称为联系函数(link function),显然对数线性回归是广义线性模型在 g ( ⋅ ) = l n ( ⋅ ) g(\cdot) = ln(\cdot) g(⋅)=ln(⋅)的特例。
3. 对数几率回归
3.1 模型定义
在线性模型中主要进行回归学习,若要做的是分类任务,只需要找一个单调可微函数将分类任务的真实标记y与线性回归模型的预测值联系起来。
考虑二分类问题,其输出标记 y ∈ 0 , 1 y \in {0, 1} y∈0,1,而线性回归模型产生的预测值 z = ω T x + b z = \omega^Tx + b z=ωTx+b是实值,于是需将实值z转换为0/1指,最理想的是“单位阶跃函数”(unit-step function)
KaTeX parse error: Undefined control sequence: \mbox at position 24: …gin{cases} 0, &\̲m̲b̲o̲x̲{z < 0} \\ 0.5,…
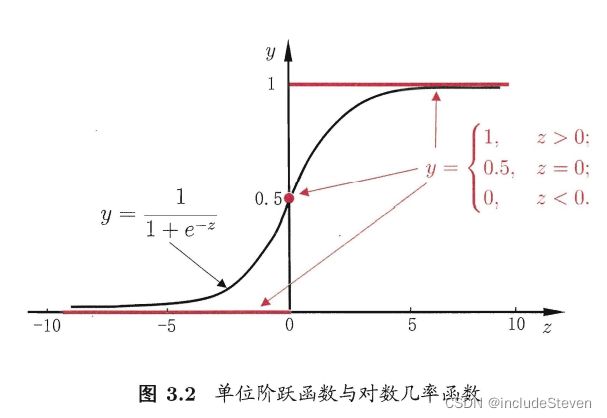
即预测值z大于零判为正例,小于零为反例,预测值为临界值零则可任意判定。因此不能直接用做 g − ( ⋅ ) g^-(\cdot) g−(⋅),于是希望能够找到一定程度上近似单位阶跃函数的“替代函数”(surrogate function),并希望单调可微。对数几率函数(logistic function)满足该条件:
y = 1 1 + e − z y = \frac{1}{1 + e^{-z}} y=1+e−z1
从图3.2可以看出,对数几率函数是一种Sigmoid函数(形似S的函数),将z指转化为一个接近0或1的y值,并且其输出值在z=0附近变化很陡,将对数几率函数作为 g − ( ⋅ ) g^-(\cdot) g−(⋅),得到:
y = 1 1 + e − ( ω T x + b ) y = \frac{1}{1 + e^{-(\omega^Tx + b)}} y=1+e−(ωTx+b)1
两边同时取对数,变化可得:
l n y 1 − y = ω T x + b ln \frac{y}{1-y} = \omega^Tx + b ln1−yy=ωTx+b
若将y视为样本x为正例的可能性,则1-y是其反例可能性,两者的比值 y 1 − y \frac{y}{1-y} 1−yy称为几率(odds),反映了x作为正例的相对可能性,对纪律取对数得到“对数几率”(log odds,亦称logit)
对应的模型称为“对数几率回归”(logistic regression),虽然它的名字是回归,但实际上是一种分类学习方法。
可直接对分类可能性进行建模,无需事先假设数据分布,避免了假设分布不准确所带来的问题;不仅预测出“类别”,而且可得到近似概率预测,对许多需要利用概率辅助决策的任务很有用;对率回归求解的目标函数是任意阶可导的凸函数,有很好的数学性质。
3.2 模型参数求解
待补充
4. 线性判别分析(Linear Discriminant Analysis)
4.1 基本思想
线性判别分析(LDA)是一种经典的线性学习方法,亦称“Fisher判别分析”。
LDA的思想十分朴素:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的直线上,再根据投影点的位置来确定新样本的类别,如下图:

4.2 LDA模型构建
4.3 LDA模型参数求解
4.4 LDA的推广
可以将LDA推广到多分类任务中,假定存在N个类,且第i类示例数位 m i m_i mi,我们先定义“全局散度矩阵”
5.多分类学习
5.1 基本概念
现实中有很多多分类学习任务,有些二分类学习方法可直接推广到多酚类(如LDA),但更多情况下,是基于一些基本策略,利用二分类学习器来解决多分类问题。
考虑到N个类别 C 1 , C 2 , . . . , C N C_1, C_2, ..., C_N C1,C2,...,CN,多分类学习的基本思路是“拆解法”,即将多分类任务拆为若干个二分类任务求解。具体来讲,先对问题进行拆分,然后为拆分的每个二分类任务训练一个分类器;在测试时,对这些分类器的预测结果进行集成以获得最终的多分类结果。因此存在两个问题:
- 如何对多分类任务进行拆分
- OvO
- OvR
- MvM
- 如何对多个分类器进行集成:
- 投票
- 考虑各分类器的预测置信度
5.2 拆分策略
最经典的拆分策略有三种:“一对一”(One vs. One,简称OvO)、“一对其余”(One vs. Rest,简称OvR)和多对多(Many vs. Many,简称MvM)。
给定数据集D= ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) , y i ∈ C 1 , C 2 , . . . , C N {(x_1, y_1), (x_2, y_2), ..., (x_m, y_m)}, y_i \in {C_1, C_2, ..., C_N} (x1,y1),(x2,y2),...,(xm,ym),yi∈C1,C2,...,CN
1.OvO策略
将这N个类别两两配对,从而产生N(N-1)/2个二分类任务,如OvO将为区分类别 C i C_i Ci和 C j C_j Cj训练一个分类器,该分类器把D中的 C i C_i Ci类样例作为正例, C j C_j Cj类样例作为反例。在测试阶段,新样本将同时提交给所有分类器,于是得到N(N-1)/2个分类结果,最终结果可通过投票产生:即把预测得最多的类别作为最终分类结果。
2.OvR策略
每次将一个类的样例作为正例,其他类的样例作为反例来训练N个分类器。在测试时若仅有一个分类器为正类,则对应的类别标记作为最终分类结果;若有多个分类其预测为正类,则通常考虑各分类器的预测置信度,选择置信度最大的类别标记作为分类结果。
3.OvO与OvR对比
-
训练器数量:容易看出,OvR只需训练N个分类器,而OvO需训练N(N-1)/2个分类器,因此OvO的存储开销和测试时间开销通常比OvR更大。
-
训练样例数量:但在训练时,OvR的每个分类器均使用全部训练样例,而OvO的每个分类器仅用到两个类的样例。
因此,在类别很多时,OvO的训练时间开销通常比OvR更小。
预测性能,则取决于具体的数据分布,在多数情况下两者差不多。两者的示意图如下:

4.MvM策略
每次将若干个类作为正类,若干个其他类作为反类。显然,OvO和OvR是MvM的特例。MvM的正、反类构造必须有特殊的设计,不能随意选取。
常见的MvM技术:“纠错输出码”(Error Correcting Output COdes, 简称ECOC):将编码的思想引入类别拆分,并尽可能在解码过程中具有容错性,其主要有两步:
- 编码:对N个类别做M次划分,每次划分将一部分类别划为正类,一部分划为反类,从而形成一个二分类训练集;这样一共产生M个训练集,可训练出M个分类器。
- 解码:M个分类器分别对测试样本进行预测,这些预测标记组成一个编码。将这个预测编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测结果。
5.3 ECOC编码
类别划分通过“编码矩阵”(coding matrix)指定,编码矩阵有多种形式,常见的主要有二元码(将每个类别分为正类和反类)和三元码(将每个类别分为正类、反类和停用类)。
在解码阶段,各分类器的预测结果联合形成了测试示例的编码,该编码与各类所对应的编码进行比较,将距离最小的编码所对应的类别作为预测结果。具体示例如下图:

5.4 纠错输出码的原因
在测试阶段,ECOC编码对分类器的错误有一定的容忍和修正能力。如图3.5(a),假设对测试示例的正确预测编码是(-1, +1, +1, -1, +1),而f2出错从而导致了错误编码(-1, -1, +1, -1, +1),但基于这个编码仍能产生正确的最终分类结果 C 3 C_3 C3。
一般来说,对同一个学习任务,ECOC编码越长,纠错能力越强。然而编码越长,意味着需要训练的分类器越多,计算、存储开销都会增大;另一方面,对有限类别数,可能的组合数是有限的,码长超过一定范围后就失去了意义。
6.类别不平衡问题
类别不平衡问题:分类任务中不同类别的训练样例数目差别很大。
解决方法:
再缩放(rescaling),前提:训练集是真实样本的无偏采样
y ′ 1 − y ′ = y 1 − y ∗ m − m + \frac{y'}{1-y'} = \frac{y}{1-y} * \frac{m^-}{m^+} 1−y′y′=1−yy∗m+m−
- 欠采样(undersampling):去除一些反例使得正、反例数目接近
- 过采样(oversampling):增加一些正例使得正、反例数目接近
- 阈值移动(threshold-moving):基于原始训练集进行学习,但在训练好的分类器进行预测时,将“再缩放”嵌入到决策过程中
补:”再缩放“是“代价敏感学习”(cost-sensitive learning)的基础,在代价敏感学习中将 m − m + \frac{m^-}{m^+} m+m−替换为 c o s t + c o s t − \frac{cost^+}{cost^-} cost−cost+,其中 c o s t + cost^+ cost+是将正例误分为反例的代价, c o s t − cost^- cost−是将反例误分为正例的代价。