YOLO系列知识点整理
之前系列博客中,各类深度学习的框架,一些新东西的接触都是从官网去接触的,好的东西必然有详尽的资料去阐述,很多都是外文网站,老外讲一些东西不是那么抽象,逻辑也很清楚,能理解的更为透彻,也可以去看看一些帖子,看看和自己的实现是不是差不多。对于各类算法,主要还是要去读读原作者的paper,理解不清楚的看看一些帖子,效果会更好。
深度学习在目标检测领域有很多的算法了,博主会有系列博客来记录,下面浅谈下博主的一个理解基调。
卷积神经网络,我们大概知道就是给输入(比如图像),给输出(打好的标签),然后拿预测出来的结果和输出进行比较,通过损失函数去更新输入到输出的权重值。对于classification来讲,输出就是一维向量,各分量表示该类别出现的概率;对于segmentation来讲,输出是一张图像,图像上各像素表示此存在目标的可能性;对于detection来讲,输出就很灵活,一般需要满足规则的解析,比如是一个7x7x85大小的数组,那么这个数组中的一个元素,比如(2,2,:)就表示了特征图上(3,3)像素处存在一个目标的信息,此时可以拿到该店表示的1x85维向量,第0~3分量表示的是此处存在目标的框的位置,第4个分量表示置信度,表示此存在目标的可能性,剩下的5~85表示,若第四个分量是表示存在目标的,那么此为目标属于某个类别的可能性。
所以可以看到目标检测算法虽然众多,但大家都是在干一件事,就是设定输入和输出之间的这么一个关系,然后训练的时候给定准备好的输入(这里指的图像),输出(按照规则得到的ground truth);还有一个说明的是如果如果网络中有全连接层,那么图像大小不一致时就会导致全连接层的输入神经元个数不一致,往往需要一些技巧,比如输入的时候就调整到相同分辨率,或者在全连接层前设置一个SPP,这样不管图像分辨率如何,经过SPP后都能获得固定大小的向量;如果是全卷积层,就能避免这个问题,因为要训练的参数只和滤波器相关,而滤波器并不会随图像大小而变化,这样比如128*128*3的图像卷积到最后为,输出为8*8*85大小,256*256*3的图像卷积到最后,输出为16*16*85大小,虽然输出大小不一致,但你能知道它们对应的输出ground truth是什么,这两者大小都能共同去训练处网络中的参数。
下面就开始回归主题吧。
1.YOLO(2016年)
paper如下

https://arxiv.org/pdf/1506.02640.pdf https://arxiv.org/pdf/1506.02640.pdf要点:
https://arxiv.org/pdf/1506.02640.pdf要点:
将一幅图像分成SxS个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。每个bounding box要预测(x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor,网络主干是GooleNet

不足:
1.损失函数中localization error和classification error同等重要(解决办法可以是:对没有object的box的confidence loss,赋予小的loss weight; 只有当某个网格中有object的时候才对classification error进行更新)
2.输出为全连接层,只支持与训练图像相同的输入分辨率
3.YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有对很小的物体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。
4.测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
5.对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点肯定更不能被忍受的。而sum-square error loss中对同样的偏移loss是一样(为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width)。定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
6.YOLO loss函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。
2.YOLOv2(2016年)

https://arxiv.org/pdf/1612.08242.pdfhttps://arxiv.org/pdf/1612.08242.pdf
相较于YOLO主要有两个大方面的改进:
第一,作者使用了一系列的方法对原来的YOLO多目标检测框架进行了改进,在保持原有速度的优势之下,精度上得以提升。
第二,作者提出了一种目标分类与检测的联合训练方法,通过这种方法,YOLO9000可以同时在COCO和ImageNet数据集中进行训练,训练后的模型可以实现多达9000种物体的实时检测。
这一系列方法可见作者论文里的表格
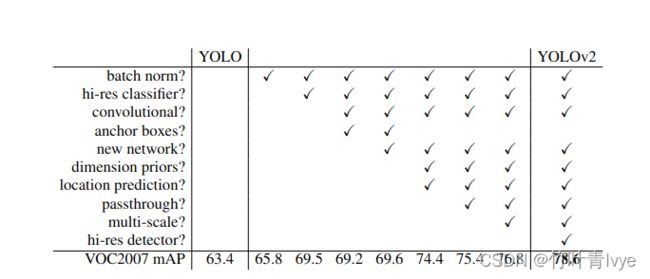
(1)Batch Normalization(批归一化),YOLO v2中在每个卷积层后加Batch Normalization(BN)层,去掉了dropout层。 Batch Normalization层可以起到一定的正则化效果,能提升模型收敛速度,防止模型过拟合。YOLO v2通过使用BN层使得mAP提高了2%。
(2)High Resolution Classifier(高分辨率预训练分类网络)
目前的大部分检测模型都会使用主流分类网络(如vgg、resnet)在ImageNet上的预训练模型作为特征提取器,而这些分类网络大部分都是以小于 256 × 256 的图片作为输入进行训练的,低分辨率会影响模型检测能力。YOLO v2先在ImageNet上以 448 × 448 的分辨率对网络进行10个epoch的微调,让网络适应高分辨率的输入。通过使用高分辨率的输入,YOLO v2的mAP提升了约4%。
3)Convolutional With Anchor Boxes(带Anchor Box的卷积)
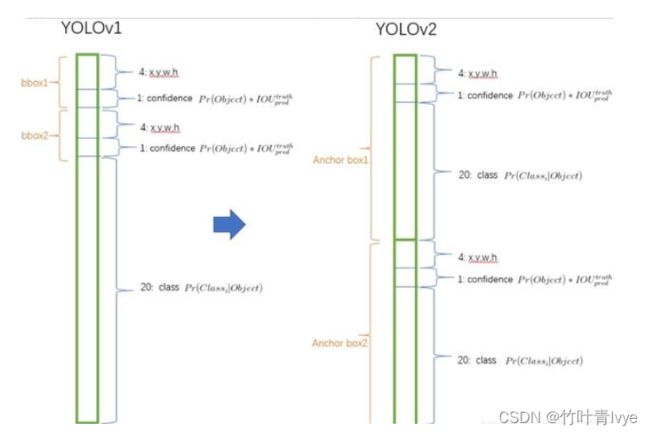
YOLO v1利用全连接层直接对边界框进行预测,导致丢失较多空间信息,定位不准。 YOLO v2去掉了 YOLO v1中的全连接层,使用Anchor Boxes预测边界框,同时为了得到更高分辨率的特征图, YOLO v2还去掉了一个池化层。由于图片中的物体都倾向于出现在图片的中心位置,若特征图恰好有一个中心位置,利用这个中心位置预测中心点落入该位置的物体,对这些物体的检测会更容易。所以总希望得到的特征图的宽高都为奇数。 YOLO v2通过缩减网络,使用 416 × 416 的输入,模型下采样的总步长为 32,最后得到 13 × 13 的特征图,然后对 13 × 13 的特征图的每个cell预测 5 个anchor boxes,对每个anchor box预测边界框的位置信息、置信度和一套分类概率值。使用anchorboxes之后, YOLO v2可以预测 13 × 13 × 5 = 845 个边界框,模型的召回率由原来的81%提升到88%,mAP由原来的69.5%降低到69.2%.召回率提升了7%,准确率下降了0.3%。
(4)Dimension Clusters(Anchor Box的宽高由聚类产生)
在Faster R-CNN和SSD中,先验框都是手动设定的,带有一定的主观性。 YOLO v2采用k-means聚类算法对训练集中的边界框做了聚类分析,选用boxes之间的IOU值作为聚类指标。
(5)New Network:YOLO v2采用Darknet-19,网络包含19个卷积层和5个max pooling层,而在YOLOv1中采用的GooleNet,包含24个卷积层和2个全连接层,因此Darknet-19整体上卷积卷积操作比YOLOv1中用的GoogleNet要少,这是计算量减少的关键。最后用average pooling层代替全连接层进行预测。
(6)Direct location prediction
Faster R-CNN使用anchor boxes预测边界框相对先验框的偏移量,由于没有对偏移量进行约束,每个位置预测的边界框可以落在图片任何位置,会导致模型不稳定,加长训练时间。 YOLO v2沿用 YOLO v1的方法,根据所在网格单元的位置来预测坐标。
(7)Fine-Grained Features(细粒度特征)
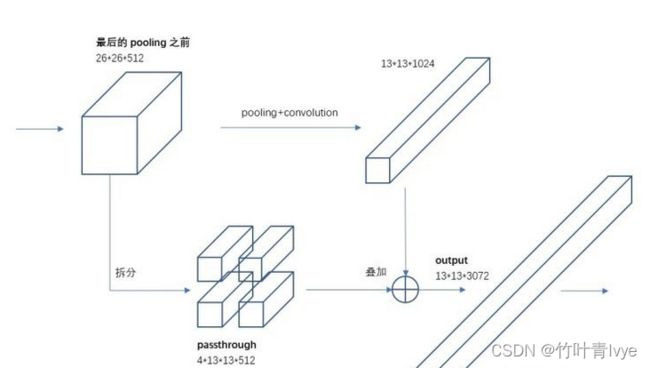
YOLO v2借鉴SSD使用多尺度的特征图做检测,提出pass through层将高分辨率的特征图与低分辨率的特征图联系在一起,从而实现多尺度检测。 YOLO v2提取Darknet-19最后一个max pool层的输入,得到 26 × 26 × 512的特征图。
(8)Multi Scale Training
YOLOv2中只有卷积层和池化层,因此不需要固定的输入图片的大小。为了让模型更有鲁棒性,作者引入了多尺度训练。就是在训练过程中,每迭代一定的次数,改变模型的输入图片大小。注意:这一步是在检测数据集上fine-tuning时候采用的,不要跟前面在Imagenet数据集上的两步预训练分类模型混淆。网络输入是416×416,经过5次max pooling之后会输出13×13的feature map,也就是下采样32倍,因此作者采用32的倍数作为输入的size,具体采用320、352、384、416、448、480、512、544、576、608共10种size。输入图片大小为320×320时,特征图大小为10×10,输入图片大小为608×608时,特征图大小为19×19。每次改变输入图片大小还需要对最后检测层进行处理,然后开始训练。
论文提到的YOLO900,就是使用联合训练算法训练出来的,他拥有9000类的分类信息,这些分类信息学习自ImageNet分类数据集,而物体位置检测则学习自COCO检测数据集。
3.YOLOv3(2018年)
https://pjreddie.com/media/files/papers/YOLOv3.pdfhttps://pjreddie.com/media/files/papers/YOLOv3.pdf

网络结构图
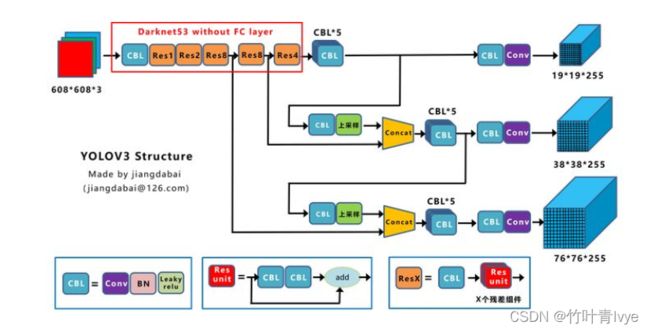
上图三个蓝色方框内表示Yolov3的三个基本组件:
CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
上面提到的两个基本操作:
Concat:张量拼接,会扩充两个张量的维度,例如26*26*256和26*26*512两个张量拼接,结果是26*26*768。Concat和cfg文件中的route功能一样。add:张量相加,张量直接相加,不会扩充维度,例如104*104*128和104*104*128相加,结果还是104*104*128。add和cfg文件中的shortcut功能一样
博主有用此版本训练预测过自己的数据集,见博客
改进之处:
Yolo_v3使用了darknet-53的前面的52层(没有全连接层),yolo_v3这个网络是一个全卷积网络,大量使用残差的跳层连接,并且为了降低池化带来的梯度负面效果,作者直接摒弃了PoolLing,用conv的stride来实现降采样。在这个网络结构中,使用的是步长为2的卷积来进行降采样。
为了加强算法对小目标检测的精确度,YOLO v3中采用类似FPN的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26×26和52×52),在多个scale的feature map上做检测。
作者在3条预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3*(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示objectness score。
分类器不在使用Softmax,分类损失采用binary cross-entropy loss(二分类交叉损失熵)。分类损失采用binary cross-entropy loss。
4.YOLOv4(2020年)
读此篇有一种读文献综述的感觉,写论文的朋友一定不要错过此篇
https://arxiv.org/pdf/2004.10934.pdfhttps://arxiv.org/pdf/2004.10934.pdf

(论文中截图)
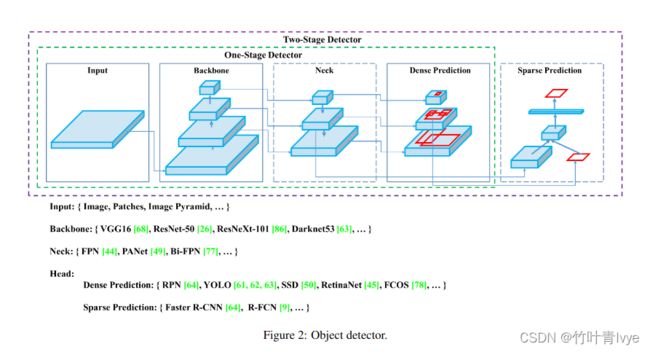
论文里作者也拆分一个目标检测网络应该拆分为如下几个部分,非常的具有归纳性

论文里引用了大量文献,集中了近几年的一些好的技巧在里面,文章里提到了2个术语:Bag of freebies(指的是那些不增加模型复杂度,也不增加推理的计算量的训练方法技巧,来提高模型的准确度),Bag of specials(指的是那些增加少许模型复杂度或计算量的训练技巧,但可以显著提高模型的准确度),可以看到老外的思路和我们也差不多,基本在前人基础上就是从这两方面去优化。
改进点:
(1)构建了一个简单且高效的目标检测模型,该算法降低了训练门槛,这使得普通人员都可以使用 1080Ti 或 2080 Ti GPU 来训练一个超快,准确的(super fast and accurate)目标检测器。
(2)验证了最先进的 Bag-of-Freebies 和 Bag-of-Specials 方法在训练期间的影响
BoF指的是
1)数据增强:图像几何变换(随机缩放,裁剪,旋转),Cutmix,Mosaic等
2)网络正则化:Dropout,Dropblock等
3) 损失函数的设计:边界框回归的损失函数的改进 CIOU
BoS指的是
1)增大模型感受野:SPP、ASPP等
2)引入注意力机制:SE、SAM
3)特征集成:PAN,BiFPN
4)激活函数改进:Swish、Mish
5)后处理方法改进:soft NMS、DIoU NMS
(3)修改了最先进的方法,并且使其更为有效,适合单GPU训练。包括 CBN,PAN, SAM等,从而使得 YOLO-v4 能够在一块 GPU 上就可以训练起来。
主要创新点:
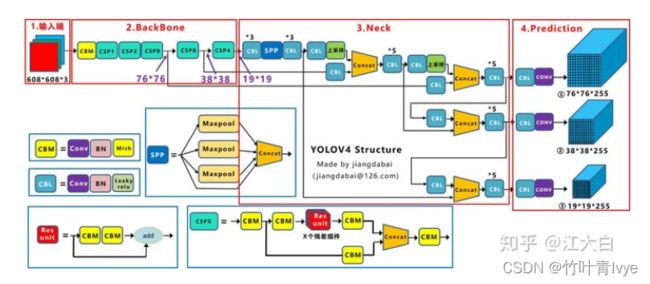
图片来自 深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎
输入端的创新点:训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练
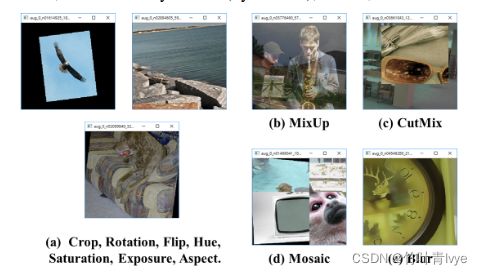
不像之前只是对单张图片进行操作,会对多幅图像进行处理融合合并为一张图像,让其上面有多个目标。
BackBone主干网络:各种方法技巧结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock
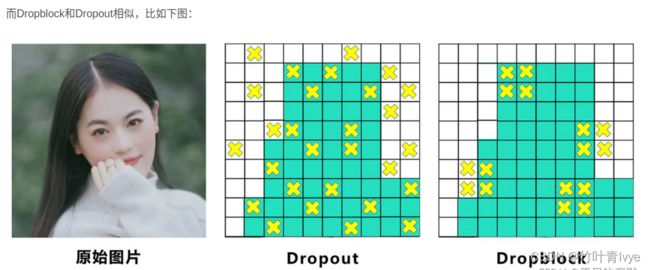
Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的回归框位置损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
5.YOLOv5(2020年)
这个版本不是前面系列版本的团队做的,是前面提到的实现yolov3代码的一个团队Ultralytics做的,网络架构如下,图片来自深入浅出Yolo系列之Yolov5核心基础知识完整讲解 - 知乎
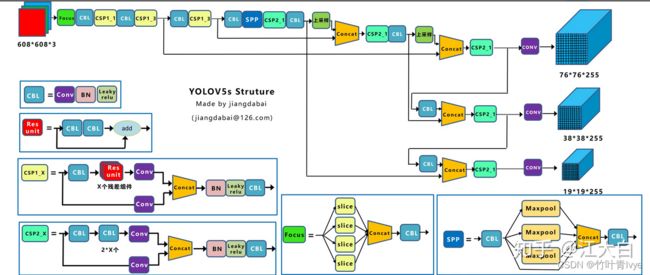
这个版本开启了一个网络结构的多种分支时代, 可以有选择性的去配置网络,分别有Yolov5s, Yolov5m, Yolov5l, Yolov5x,他们公布的结果表明,YOLOv5 的表现要优于谷歌开源的目标检测框架 EfficientDet。
相比较Yolov4,其改进了如下四个方面:
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放(在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的)
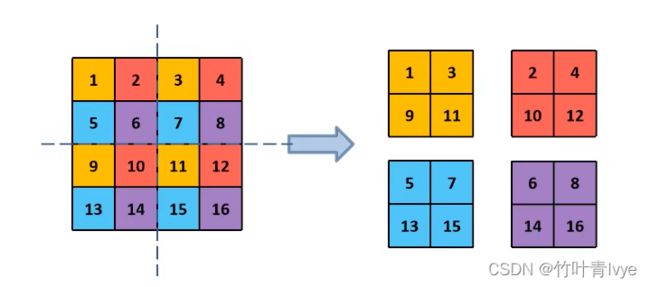
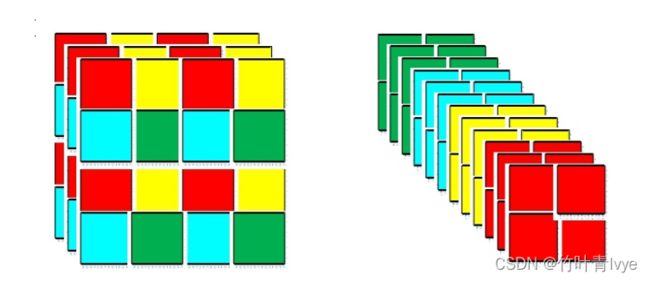
(2)Backbone:Focus结构,Focuse中的切片示意如下图。Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构。而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
(5)Yolov5中采用其中的CIOU_Loss做Bounding box的损失函数。
四种网络结构的差异:
(1) 每个CSP结构的深度都是不同的。以yolov5s为例,第一个CSP1中,使用了1个残差组件,因此是CSP1_1。而在Yolov5m中,则增加了网络的深度,在第一个CSP1中,使用了2个残差组件,因此是CSP1_2。
(2)网络的特征图的厚度不一样,以Yolov5s结构为例,第一个Focus结构中,最后卷积操作时,卷积核的数量是32个,因此经过Focus结构,特征图的大小变成304*304*32。而yolov5m的Focus结构中的卷积操作使用了48个卷积核,因此Focus结构后的特征图变成304*304*48
6.YOLOx(2021年)
论文地址
https://arxiv.org/pdf/2107.08430.pdfhttps://arxiv.org/pdf/2107.08430.pdf论文的实验比较结果
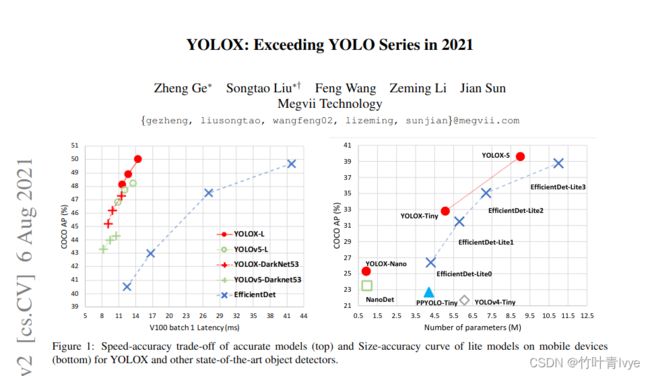
论文里上来就说了, 其基础网络架构还是选用的yolov3版本,作者觉得有点过度优化了


YoloX支持可选配,如下:
(1)标准的网络结构:YOLOX-S,YOLOX-m, YOLOX-l, YOLOX-x, Yolo-Darknet53
(2)轻量级网络结构:YoloX-Nano, YoloX-Tiny
需要说明的是,上面提到的yolov3这个基准版本和当时论文里也是不一样的,在此篇中添加了SPP结构,所以换句话讲,是拿加了SPP的yolov3(Darknet53作为前置网络架构)来作为baseline。 在这个baseline上面做了一些技巧,主要是:Decoupled Head、SimOTA等,构造了新的一个模型,这边就叫YOLOX-Darknet53(需要说明的是ultralytics也实现了一版yolo-spp),其网络架构如下,可用来和上面的系列版本进行对比。
对比yolov3下来,输入端、backbone主干网络、neck没有什么太大变化,抛弃了v4和v5里的pan,只用了FPN就够了,也没有用CSP这种结构。在prediction阶段改进较大,如下几个方面:
Decoupled Head、Anchor-free、Multi positives。
在网络的输入端,Yolox主要采用了Mosaic、Mixup两种数据增强方法。在训练的最后15个epoch,这两个数据增强会被关闭掉。而在此之前,Mosaic和Mixup数据增强,都是打开的,这个细节需要注意。
Decoupled Head,目前在很多一阶段网络中都有类似应用,比如RetinaNet、FCOS等。也比较好懂,反正就是换了一种输入和输出的连接方式,最后合并为了一个输出,下面这种是end-to-end方式
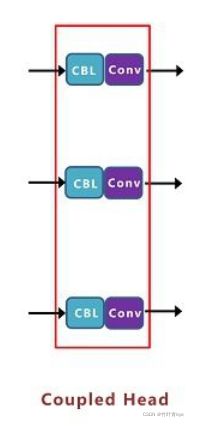
这里就要引入Anchor的内容,目前行业内,主要有Anchor Based和Anchor Free两种方式。在Yolov3、Yolov4、Yolov5中,通常都是采用Anchor Based的方式,来提取目标框,进而和标注的groundtruth进行比对,判断两者的差距。 Anchor Based方式,比如输入图像,经过Backbone、Neck层,最终将特征信息,传送到输出的Feature Map中。这时,就要设置一些Anchor规则,将预测框和标注框进行关联。从而在训练中,计算两者的差距,即损失函数,再更新网络参数。Anchor Free虽然没有三种锚框的设定,但因为采样大小不一样,变相的加入了将锚框信息加入了进来。
作者又对yolo5s、yolo5m、yolo5l、yolo5x进行了改进,把上面的优化方法和yolov5结合起来。就有了YOLOX-S,YOLOX-m, YOLOX-l, YOLOX-x
博主这边只是简单的记录一下自己收集的信息,大概的一个算法过程也是理解的,后面有精力能够去关联源码和paper一起看,这样理解会更深刻。时间和精力问题,暂时只能到此了。
参考的博客:
百度安全验证https://baijiahao.baidu.com/s?id=1717730753560317539百度安全验证https://baijiahao.baidu.com/s?id=1717730887250972083&wfr=spider&for=pc百度安全验证https://baijiahao.baidu.com/s?id=1717823971505216877&wfr=spider&for=pcYOLO v2详细解读_迪菲赫尔曼的博客-CSDN博客_yolov2
深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎
深入浅出Yolo系列之Yolov5核心基础知识完整讲解 - 知乎
YOLOV5简单介绍以及YOLO系列算法比较 - 知乎
深入浅出Yolo系列之Yolox核心基础完整讲解 - 知乎