爬虫学习:Urllib的使用
爬虫学习:Urllib的使用
目录
文章目录
- 爬虫学习:Urllib的使用
-
- 目录
- 一、前言
- 二、爬虫的基本原理
- 三、基本库的使用之urllib的使用
-
- *1.发送请求*
- *2.处理异常*
- *3.解析链接*
- 四、最后我想说
一、前言
这是我第一次写博客,书写过程中难免会有错误或者不清晰的地方,希望大家能给予我优化建议,谢谢大家!
我目前爬虫学习书籍是《Python3 网络爬虫开发实战 第2版》 崔庆才 著
首先学习爬虫之前需要了解一些有关HTTP基本原理、Web网页基础等知识,在这里面我就不对这些知识进行详述了,我写这个博客想更加专注于Python爬虫部分学习。
在这里先向各位读者推荐几个比较好的==学习网站==:
- https://github.com/gxcuizy/Python
- https://github.com/jobbole/awesome-python-cn
- https://github.com/521xueweihan/HelloGitHub
- https://github.com/jackfrued/Python-100-Days
- https://github.com/justjavac/free-programming-books-zh_CN
- https://www.runoob.com/python3/python3-tutorial.html
- http://cxy521.com/
大致就是这么多 ,里面有很多有关Python的各种学习资料,但也不止关于Python还有很多其他有关计算机方面的知识,感兴趣的读者可以收藏起来慢慢学习
注意:作者学习爬虫的全程使用的Python语言版本都是Python310版本!
请读者们使用Python3x版本进行编写
二、爬虫的基本原理
简单点讲,爬虫就是获取网页并提取和保存信息的自动化程序
通用网络爬虫实现原理图如下:

聚焦网络爬虫实现原理图如下:
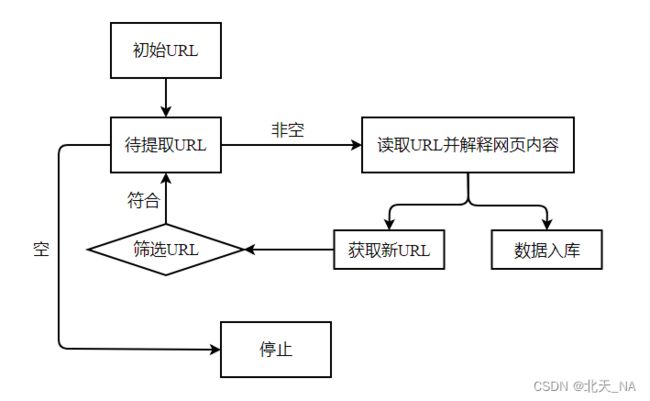
三、基本库的使用之urllib的使用
学习爬虫,其基本的操作就是模拟浏览器向服务器发出请求,不过我们不用担心这些请求不用我们自己构造,Python强大之处就在于有各种库供我们取使用,最基础的HTTP库就有urllib、requests、httpx等,我们只需要关心请求的链接,需要传递的参数以及如何设置请求头这些就可以的完成从网页爬取自己想要的内容了。====
1.发送请求
- urlopen方法
首先我们来看一下urlopen方法中参数有哪些
urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False,context=None)
| 参数名 | 说明 |
|---|---|
| data | 用于返回附加数据 |
| timeout | 用于设置超时时间 |
| context | 必须是ssl.SSLContext类型,用来指定SSL的设置 |
| cafile | 用来指定CA证书 |
| capath | 用来指定CA证书其路径 |
| cadefault | 目前已经弃用,默认值为False |
在这里我就介绍两个初学者常用参数
data参数
这里我们通过字典的形式传入{‘name’: ‘germey’},需要将它转化成bytes类型.
import urllib.parse
import urllib.request
# 使用bytes方法将参数转化为字节流编码格式的内容
# urlopen方法将字典参数转化为字符串,并指定编码格式
data = bytes(urllib.parse.urlencode({'name': 'germey'}), encoding='utf-8')
response = urllib.request.urlopen('https://www.httpbin.org/post', data=data)
print(response.read().decode('utf-8'))
它的运行结果是:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "germey"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "www.httpbin.org",
"User-Agent": "Python-urllib/3.10",
"X-Amzn-Trace-Id": "Root=1-62709ad2-49f2af2c51d4f25d52505425"
},
"json": null,
"origin": "16.162.22.153",
"url": "https://www.httpbin.org/post"
}
timeout参数
这里我们设置超时时间为0.1秒,来模拟一个网页如果长时间未响应,就跳过它的抓取.
import urllib.request
import socket
import urllib.error
"""
timeout参数用于设置超时时间,单位为秒
意思是如果请求超过了设置的时间,还没有得到响应,就会抛出异常
如果不知道该参数,则会使用全局默认时间
"""
try:
response = urllib.request.urlopen('https://www.httpbin.org/get', timeout = 0.1)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('Time out!')
它的运行结果是:
Time out!
- 使用Requset类构建请求
首先我们还是先看一下它的构造方法
urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
| 参数名 | 说明 |
|---|---|
| url | 这是必传参数,用于请求URL |
| data | 用于传数据,必须传bytes类型的 |
| headers | 请求头,是一个字典,用来伪装成浏览器 |
| origin_req_host | 指请求方的host名称或者IP地址 |
| unverifiable | 表示请求是否是无法验证的,默认False,意思是用户没有足够的权限来接收这个请求的结果 |
| method | 是一个字符串,用来指示请求使用的方法,如POST,GET |
ok话不多说,我们来构建一个Request类来试试
from urllib import request, parse
url = 'https://www.httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Host': 'www.httpbin.org'
}
dict = {'name': 'germey'}
data = bytes(parse.urlencode(dict), encoding='utf-8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
它的运行结果是:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "germey"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "www.httpbin.org",
"User-Agent": "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)",
"X-Amzn-Trace-Id": "Root=1-62709b03-7d21b4861de70eeb6ff0cc03"
},
"json": null,
"origin": "16.162.22.153",
"url": "https://www.httpbin.org/post"
}
2.处理异常
- URLError类
用于捕获URL不见了得错误,有一个reason属性-返回错误得原因
from urllib import request, error
try:
response = request.urlopen('https://cuiqingcai.com/404')
except error.URLError as e:
print(e.reason)
它的运行结果是:
Not Found
- HTTPError类
是URLError的子类,专门用来处理HTTP请求的错误,有三个属性,分别是:
- code:返回HTTP状态码
- reason:返回错误的原因
- headers:返回请求头
from urllib import request, error
try:
response = request.urlopen('https://cuiqingcai.com/404')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep = '\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')
它的运行结果是:
Not Found
404
Server: GitHub.com
Content-Type: text/html; charset=utf-8
Access-Control-Allow-Origin: *
ETag: "62608aca-247b"
Content-Security-Policy: default-src 'none'; style-src 'unsafe-inline'; img-src data:; connect-src 'self'
x-proxy-cache: MISS
X-GitHub-Request-Id: 3934:7707:317FBF:396FDF:62709D1A
Accept-Ranges: bytes
Date: Tue, 03 May 2022 03:14:16 GMT
Via: 1.1 varnish
Age: 238
X-Served-By: cache-hkg17926-HKG
X-Cache: HIT
X-Cache-Hits: 1
X-Timer: S1651547657.557390,VS0,VE1
Vary: Accept-Encoding
X-Fastly-Request-ID: 5f02f18306c1e62751a36662749c0f230fc0f801
X-Cache-Lookup: Cache Miss
X-Cache-Lookup: Cache Miss
X-Cache-Lookup: Cache Miss
Content-Length: 9339
X-NWS-LOG-UUID: 15535557327764382299
Connection: close
X-Cache-Lookup: Cache Miss
3.解析链接
parse模块里面有很多方法,在这里我就列举几个常用方法
- urlparse
该方法可以实现URL的识别和分段,通俗的来说就是将一个URL解析成对应的类型以及结果本身,解析之后会返回一个ParseResult类型的对象,包含6个部分
from urllib.parse import urlparse
result = urlparse('https://www.baidu.com/index.html;user?id=5#comment')
print(type(result))
print(result)
它的运行结果是:
ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html', params='user', query='id=5', fragment='comment')
- urlunparse
它是urlparse方法的对立方法,用于构造URL,通俗的来说,就是提供URL链接格式里面的参数,它可以帮你组建成正确的URL格式,该方法接收的参数是一个可迭代对象,其长度必须是6
from urllib.parse import urlunparse
data = ['https', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))
它的运行结果是:
https://www.baidu.com/index.html;user?a=6#comment
- urlendode
使用该方法需要先构造一个字典将参数表示出来,然后调用该方法将此字典序列号为GET请求的参数
from urllib.parse import urlencode
params = {
'name': 'germey',
'age': '20'
}
base_url = 'https://www.baidu.com?'
url = base_url + urlencode(params)
print(url)
它的运行结果是:
https://www.baidu.com?name=germey&age=20
- parse_qs和parse_qsl方法
parse_qs方法将URL参数转回成字典类型
from urllib.parse import parse_qs
query = 'name=germey&age=20'
print(parse_qs(query))
它的运行结果是:
{'name': ['germey'], 'age': ['20']}
parse_qsl方法将URL参数转回成由元组组成的列表
from urllib.parse import parse_qsl
query = 'name=germey&age=20'
print(parse_qsl(query))
它的运行结果是:
[('name', 'germey'), ('age', '20')]
- quote和unquote方法
quote方法将内容转化为URL编码的格式,,特别是当URL里面带有中文参数时,防止其乱码
from urllib.parse import quote
keyword ='壁纸'
url = 'https://www.google.com/s?wd=' + quote(keyword)
print(url)
它的运行结果是:
https://www.google.com/s?wd=%E5%A3%81%E7%BA%B8
unquote方法可以进行URL解码
from urllib.parse import unquote
url = 'https://www.google.com/s?wd=%E5%A3%81%E7%BA%B8'
print(unquote(url))
它的运行结果是:
https://www.google.com/s?wd=壁纸
四、最后我想说
这次博客浅浅的总结了一下urllib库里面的一些常用模块的基本用法,能熟练运用这些基本模块对以后的爬虫学习会更加的高效,总之,计算机语言的学习无非是多练多看,每天保持敲代码的好习惯,另外还要养成写代码的好习惯。
目前作者还在学习中,也是一个刚刚开始学习爬虫的小白,哈哈哈,能力有限,所以请大家谅解本人的不妥之处,后面我会抽空再进行下一个部分的更新,这是我最近几天的安排:

可能会有人问我上面的图是怎么弄出来的,其实我是用的Mermaid语言做出来的,它是一个基于 Javascript 的图表和图表工具,它呈现受 Markdown 启发的文本定义以动态创建和修改图表,对这个感兴趣的同学可以去学习一下使用方法。
地址:https://mermaid-js.github.io/mermaid/#/
在Typora上做甘特图可以显示出来效果,但是在CSDN上面就无法显示出来,我也不知道是什么原因所以这里先放截图,如果有知道怎么解决的大佬欢迎在评论区留言或者私信我
ok,大致就说这么多了,感谢各位的浏览,本人非常乐意收到来自各位的建议与意见,与大家共勉学习Python爬虫相关知识