Python编程基础:文件基础
Python编程基础:文件基础
文章目录
- Python编程基础:文件基础
-
- 一、前言
- 二、我的环境
- 三、从文件中读取数据
-
- 1、读取整个文件
- 2、文件路径
- 3、逐行读取
- 4、创建一个包含各行内容的列表
- 5、使用文件的内容
- 四、写入文件
-
- 1、写入空文件
- 2、写入多行
- 3、附加到文件
- 五、最后我想说
一、前言
本期内容我们将学习Python中的文件操作,学习如何使用Python处理文件,让程序能够快速地分析大量数据。
二、我的环境
- 电脑系统:Windows 11
- 语言版本:Python 3.10.4
- 编译器:VSCode
三、从文件中读取数据
在数据分析,机器学习等等领域经常会用到使用Python读取本地数据集,我们要使用文本文件中的信息,首先需要将信息读取到内存中,我们可以一次性读取文件的全部内容,也可以以每次一行的方式逐步读取。
1、读取整个文件
下面我们在本地创建一个包含精确到小数点后30位的圆周率值,且在小数点后每10位处换行:
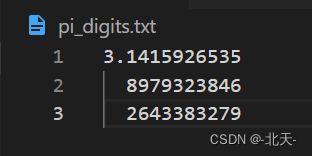
下面我们创建一个程序去尝试读取这个文件:
with open('pi_digits.txt') as f:
contents = f.read()
print(contents)
在Python中读取文件需要使用open()函数,它返回的是一个表示文件的对象,前面的关键字with在不再需要访问文件后自动将其关闭,如果没有使用with,则需要在文件操作之后使用close()将文件关闭,以免造成数据丢失或者受损。
它运行的结果是:
3.1415926535
8979323846
2643383279
另外如果我们访问的结果中带空格可以使用之前学到的方法strip去空格。
2、文件路径
在上面我们是直接传入文件名进行读取的,这是因为我们的文件就在当前执行文件所在的目录内,如果文件不在目录内,则我们需要提供文件路径,让Python到系统的特定位置去查找。
文件路径分为相对路径和绝对路径。
如果文件位于文件下中,我们可以使用相对路径来打开其中的文件:
with open('text_files/filename.txt') as f:
...
显示文件路径时,Windows系统使用反斜杠(\)而不是斜杠(/),但在代码中依然可以使用斜杠。
还可以将文件在计算机中的准确位置告诉Python,这样就不用关心当前运行的程序存储在什么地方了。这称为绝对文件路径。在相对路径行不通时,可使用绝对路径。
绝对路径一般来说都比较长,所以一般采用将其赋值给一个变量,再传入到open()函数中:
file_path = 'D:/home/ehmatthes/other_files/text_files/filename.txt'
with open(file_path) as f:
...
另外需要注意的是,如果你使用的Windows系统,在文件资源管理器中复制文件的绝对路径时他会直接使用反斜杠,但使用反斜杠可能会引起报错,这是因为反斜杠用于对字符串中的字符进行转义,例如,对于路径"C:\path\to\file.txt",其中的\t将被解读为制表符。如果一定要使用反斜杠,可对路径中的每个反斜杠都进行转义,如"C:\path\to\file.txt"。
3、逐行读取
在读取文件时,有些时候我们可能需要在文件中查找特定信息,或者需要以某种方式修改文件中的文本,这个时候就需要我们检查其中的每一行,要以每次一行的方式检查文件,我们就需要使用到for循环。
例如:
filename = 'pi_digits.txt'
with open(filename) as f:
for line in f:
print(line)
它运行的结果是:
3.1415926535
8979323846
2643383279
这里我们发现空格变多了,我们使用rstrip()方法去除多余的空格。
filename = 'pi_digits.txt'
with open(filename) as f:
for line in f:
print(line.rstrip())
它运行的结果是:
3.1415926535
8979323846
2643383279
4、创建一个包含各行内容的列表
使用关键字with时,open()返回的文件对象只在with代码块内可用。如果要在with代码块外访问文件的内容,可在with代码块内将文件的各行存储在一个列表中,并在with代码块外使用该列表:可以立即处理文件的各个部分,也可以推迟到程序后面再处理。
举个例子:
filename = 'pi_digits.txt'
with open(filename) as f:
lines = f.readlines()
for line in lines:
print(line.rstrip())
readlines()方法从文件中读取每一行,并将其存储在一个列表中,然后在后面使用一个for训练来打印列表中的各行,最后输出的结果和之前一样。
5、使用文件的内容
将文件读取到内存中后,我们就能以任何方式使用这些数据了,我们可以将之前的圆周率各行循环打出然后加入到一个字符串中,并删除每行末尾的换行符:
filename = 'pi_digits.txt'
with open(filename) as f:
lines = f.readlines()
pi_string = ''
for line in lines:
pi_string += line.strip()
print(pi_string)
print(len(pi_string))
它运行的结果是:
3.141592653589793238462643383279
32
这样我们就获得了一个字符串。
对于可处理的数据量,Python没有任何限制,只要你的系统内存足够多,想处理多少数据都可以。
四、写入文件
保存数据的最简单的方式之一就是将其写入文件中。
1、写入空文件
要将文本写入文件,你在调用open()时需要提供另一个实参,告诉Python你要写入打开的文件。
例如:
filename = 'programming.txt'
with open(filename, 'w') as f:
f.write("I love programming.")
open()函数中第二个实参(‘w’)是告诉Python要以写入模式打开这个文件,打开文件时,可指定读取模式(‘r’)、写入模式(‘w’)、附加模式(‘a’)或读写模式(‘r+’)。如果省略了模式实参,Python将以默认的只读模式打开文件。
如果要写入的文件不存在,open()函数将自动创建一个文件,但需要注意的是如果写入文件时该文件以存在,则会覆盖之前的文件内容。
2、写入多行
函数write()不会在写入的文本末尾添加换行符,因此如果写入多行时没有指定换行符,你所写入的内容则会写入到一行中,要想写入的每一行内容都独占一行,则需要加入换行符。
例如:
filename = 'programming.txt'
with open(filename, 'w') as f:
f.write("I love programming.\n")
f.write("I love Python.\n")

3、附加到文件
如果要给文件添加内容,而不是覆盖原有的内容,可以以附加模式(‘a’)打开文件。以附加模式打开文件时,Python不会在返回文件对象前清空文件的内容,而是将写入文件的行添加到文件末尾。
例如:
filename = 'programming.txt'
with open(filename, 'a') as f:
f.write("I love Java.\n")
f.write("I love C++.\n")
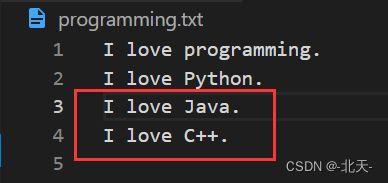
可以看出我们将新内容附加到了文件的末尾,而不是覆盖该文件内容。
五、最后我想说
本期Python文件操作内容到这里就结束了,内容不算很多,但需要我们去熟练的掌握文件的各项操作。
学校课程目前也正在学习Python中的文件操作,所以我也来写一篇博客进行总结,紧跟学校安排,也方便巩固该内容。
最后,谢谢你们的阅读,后续老师会布置相关的作业练习的,我也会第一时间更新的。