opencv-python常用函数汇总
文章目录
- 前言
- 一、图像基本操作
-
- 1.数据读取-图像
- 2.数据读取-视频
- 3.颜色通道提取
- 4.边界填充
- 5.图像融合
- 6.按比例缩放
- 7.亮度和对比度
- 8.直方图均衡化
- 二、阈值与平滑处理
-
- 1.阈值(灰度图)
- 2.图像平滑
- 三、图像形态学处理(腐蚀、膨胀)
-
- 1.腐蚀(去毛刺)
- 2.膨胀
- 3.开运算与闭运算
- 4.梯度运算
- 5.礼帽与黑帽
- 四、图像梯度处理
-
- 1.Sobel算子
- 2.Canny边缘检测
- 五、图像金字塔与轮廓检测(模板匹配)
-
- 1.高斯,拉普拉斯金字塔
- 2.图像轮廓
- 3.模板匹配
- 六、直方图与傅里叶变换
-
- 1.图像直方图
- 2.傅里叶变换
- 七、图像特征
-
- 1.harris特征
- 2.SIFT
- 3.读入数据
- 八、答题卡判卷
-
- 2.读入数据
- 九、全景图像拼接
-
- 1.引入库
- 十、背景建模
-
- 1.帧差法
- 2.混合高斯模型
- 十一、AAAA
-
- 1.引入库
- 总结
前言
环境配置地址
Anaconda:https://www.anaconda.com/download/
Python_whl:https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
一、图像基本操作
1.数据读取-图像
代码如下(示例):
import cv2 #opencv读取的格式是BGR
import matplotlib.pyplot as plt
import numpy as np
img=cv2.imread('cat.jpg')
img=cv2.imread('cat.jpg',cv2.IMREAD_GRAYSCALE) # 灰色
img=cv2.imread('cat.jpg',cv2.IMREAD_COLOR) # 彩色
hsv=cv2.cvtColor(img,cv2.COLOR_BGR2HSV) # HSV:H色调(主波长);S饱和度(纯度/颜色的阴影);V值(强度)
#显示图像。waitKey(0) 等待时间,毫秒级,0表示任意键终止
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def cv_show(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
#保存
cv2.imwrite('mycat.png',img)
type(img) # numpy.ndarray
img.dtype # dtype('uint8')
2.数据读取-视频
cv2.VideoCapture可以捕获摄像头,用数字来控制不同的设备,例如0,1。
如果是视频文件,直接指定好路径即可。
vc = cv2.VideoCapture('test.mp4')
# 检查是否打开正确
if vc.isOpened():
oepn, frame = vc.read()
else:
open = False
while open:
ret, frame = vc.read()
if frame is None:
break
if ret == True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('result', gray)
if cv2.waitKey(100) & 0xFF == 27:
break # 100ms播放视频慢,27代表按退出键退出
vc.release()
cv2.destroyAllWindows()
3.颜色通道提取
b,g,r=cv2.split(img)
img=cv2.merge((b,g,r))
4.边界填充
BORDER_REPLICATE:复制法,也就是复制最边缘像素。
BORDER_REFLECT:反射法,对感兴趣的图像中的像素在两边进行复制例如:fedcba|abcdefgh|hgfedcb
BORDER_REFLECT_101:反射法,也就是以最边缘像素为轴,对称,gfedcb|abcdefgh|gfedcba
BORDER_WRAP:外包装法cdefgh|abcdefgh|abcdefg
BORDER_CONSTANT:常量法,常数值填充。
top_size,bottom_size,left_size,right_size = (50,50,50,50)
replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE)
reflect = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_REFLECT)
reflect101 = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_REFLECT_101)
wrap = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_WRAP)
constant = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_CONSTANT, value=0)
import matplotlib.pyplot as plt
plt.subplot(231), plt.imshow(img, 'gray'), plt.title('ORIGINAL')
plt.subplot(232), plt.imshow(replicate, 'gray'), plt.title('REPLICATE')
plt.subplot(233), plt.imshow(reflect, 'gray'), plt.title('REFLECT')
plt.subplot(234), plt.imshow(reflect101, 'gray'), plt.title('REFLECT_101')
plt.subplot(235), plt.imshow(wrap, 'gray'), plt.title('WRAP')
plt.subplot(236), plt.imshow(constant, 'gray'), plt.title('CONSTANT')
plt.show()

5.图像融合
img_dog = cv2.resize(img_dog, (500, 414))
img_dog.shape # (414, 500, 3)
res = cv2.addWeighted(img_cat, 0.4, img_dog, 0.6, 0)
plt.imshow(res)

6.按比例缩放
res = cv2.resize(img, (0, 0), fx=1, fy=3)
plt.imshow(res)

7.亮度和对比度
import cv2
import numpy as np
image = cv2.imread('/home/xzz/Downloads/data/FLIR/Train_data_FLIR/vis/VIS4.jpg')
cv2.imshow("input",image)
# 创建一个与原图像一样大小的空白图像
blank = np.zeros_like(image)
blank[:,:] = (30,30,30)# 空白图像的bgr都为50,这里增加或者减小值
# 将原图像和空白图像相加即可增加亮度
# result_1 = cv2.add(image,blank)
# cv2.imshow("result_1",result_1)
# 将原图像和空白图像相减即可减小亮度
result_2 = cv2.subtract(image,blank)
cv2.imshow("result_1",result_2)
# 创建一个与原图像一样大小的空白图像
blank = np.zeros_like(image)
blank[:,:] = (1.2,1.2,1.2)# bgr 分别为2,即为图像对比度比例
# # 将原图像和空白图像相乘即可增加对比度
# result_1 = cv2.multiply(image,blank)
# cv2.imshow("result_1",result_1)
# 将原图像和空白图像相除即可减小对比度
result_2 = cv2.divide(image,blank)
cv2.imshow("result_2",result_2)
cv2.waitKey(0)
cv2.destroyAllWindows()
8.直方图均衡化
# # 彩色图像均衡化
# (b, g, r) = cv2.split(img_test1)
# bH = cv2.equalizeHist(b)
# gH = cv2.equalizeHist(g)
# rH = cv2.equalizeHist(r)
# # 合并每一个通道
# result = cv2.merge((bH, gH, rH))
# cv2.imwrite(os.path.join(new_path, img_name.replace('VIS','00')), result)
二、阈值与平滑处理
1.阈值(灰度图)
ret, dst = cv2.threshold(src, thresh, maxval, type)
src: 输入图,只能输入单通道图像,通常来说为灰度图
dst: 输出图
thresh: 阈值
maxval: 当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值
type:二值化操作的类型,包含以下5种类型: cv2.THRESH_BINARY; cv2.THRESH_BINARY_INV; cv2.THRESH_TRUNC; cv2.THRESH_TOZERO;cv2.THRESH_TOZERO_INV
cv2.THRESH_BINARY 超过阈值部分取maxval(最大值),否则取0
cv2.THRESH_BINARY_INV THRESH_BINARY的反转
cv2.THRESH_TRUNC 大于阈值部分设为阈值,否则不变
cv2.THRESH_TOZERO 大于阈值部分不改变,否则设为0
cv2.THRESH_TOZERO_INV THRESH_TOZERO的反转
ret, thresh1 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY)
ret, thresh2 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY_INV)
ret, thresh3 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TRUNC)
ret, thresh4 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO)
ret, thresh5 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['Original Image', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
2.图像平滑
代码如下(示例):
# 均值滤波
# 简单的平均卷积操作(卷积核:9个全1的矩阵)
blur = cv2.blur(img, (3, 3))
cv2.imshow('blur', blur)
# 方框滤波
# 基本和均值一样,可以选择归一化,容易越界
box = cv2.boxFilter(img,-1,(3,3), normalize=False)
cv2.imshow('box', box)
# 高斯滤波
# 高斯模糊的卷积核里的数值是满足高斯分布,相当于更重视中间的
aussian = cv2.GaussianBlur(img, (5, 5), 1)
cv2.imshow('aussian', aussian)
# 中值滤波
# 相当于用中间值代替,平滑(去噪)效果最好
median = cv2.medianBlur(img, 5)
cv2.imshow('median', median)
cv2.waitKey(0)
cv2.destroyAllWindows()
三、图像形态学处理(腐蚀、膨胀)
1.腐蚀(去毛刺)
kernel = np.ones((3,3),np.uint8)
erosion = cv2.erode(img,kernel,iterations = 1)
cv2.imshow('erosion', erosion)
kernel = np.ones((30,30),np.uint8)
erosion_1 = cv2.erode(pie,kernel,iterations = 1)
erosion_2 = cv2.erode(pie,kernel,iterations = 2)
erosion_3 = cv2.erode(pie,kernel,iterations = 3)
res = np.hstack((erosion_1,erosion_2,erosion_3))
cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()
去毛刺(腐蚀)之前

三次腐蚀效果:
2.膨胀
pie = cv2.imread('pie.png')
kernel = np.ones((30,30),np.uint8)
dilate_1 = cv2.dilate(pie,kernel,iterations = 1)
dilate_2 = cv2.dilate(pie,kernel,iterations = 2)
dilate_3 = cv2.dilate(pie,kernel,iterations = 3)
res = np.hstack((dilate_1,dilate_2,dilate_3))
cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()

3.开运算与闭运算
# 开:先腐蚀,再膨胀(去毛刺,再回复粗度)
img = cv2.imread('dige.png')
kernel = np.ones((5,5),np.uint8)
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
cv2.imshow('opening', opening)
# 闭:先膨胀,再腐蚀(不能去毛刺)
kernel = np.ones((5,5),np.uint8)
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
cv2.imshow('closing', closing)
cv2.waitKey(0)
cv2.destroyAllWindows()
4.梯度运算
gradient = cv2.morphologyEx(pie, cv2.MORPH_GRADIENT, kernel)
cv2.imshow('gradient', gradient)

5.礼帽与黑帽
礼帽 = 原始输入-开运算结果
黑帽 = 闭运算-原始输入
#礼帽
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
cv2.imshow('tophat', tophat)

#黑帽
blackhat = cv2.morphologyEx(img,cv2.MORPH_BLACKHAT, kernel)
cv2.imshow('blackhat ', blackhat )

四、图像梯度处理
1.Sobel算子
代码如下(示例):
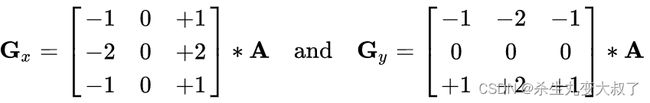
dst = cv2.Sobel(src, ddepth, dx, dy, ksize)
· ddepth:图像的深度
· dx和dy分别表示水平和竖直方向
· ksize是Sobel算子的大小
# 1.分别计算x、y方向梯度,再合并
img = cv2.imread('lena.jpg',cv2.IMREAD_GRAYSCALE)
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
sobelx = cv2.convertScaleAbs(sobelx)
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=3)
sobely = cv2.convertScaleAbs(sobely)
sobelxy = cv2.addWeighted(sobelx,0.5,sobely,0.5,0)
cv_show(sobelxy,'sobelxy')
# 2.同时计算x、y梯度(不建议)
sobelxy=cv2.Sobel(img,cv2.CV_64F,1,1,ksize=3)
sobelxy = cv2.convertScaleAbs(sobelxy)
cv_show(sobelxy,'sobelxy')
Scharr算子
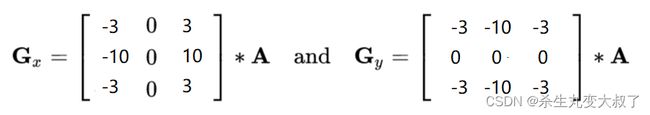
laplacian算子

# Scharr算子
scharrx = cv2.Scharr(img,cv2.CV_64F,1,0)
scharry = cv2.Scharr(img,cv2.CV_64F,0,1)
scharrx = cv2.convertScaleAbs(scharrx)
scharry = cv2.convertScaleAbs(scharry)
scharrxy = cv2.addWeighted(scharrx,0.5,scharry,0.5,0)
# laplacian算子
laplacian = cv2.Laplacian(img,cv2.CV_64F)
laplacian = cv2.convertScaleAbs(laplacian)
res = np.hstack((sobelxy,scharrxy,laplacian))
cv_show(res,'res')
2.Canny边缘检测
- 使用高斯滤波器,以平滑图像,滤除噪声。
- 计算图像中每个像素点的梯度强度和方向。
- 应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应。
- 应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘。
- 通过抑制孤立的弱边缘最终完成边缘检测。
高斯滤波器

梯度大小/方向
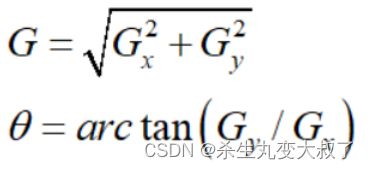
非极大值抑制
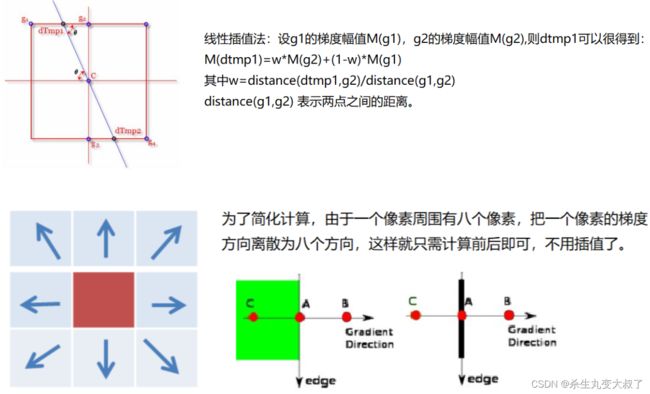
双阈值检测

img=cv2.imread("lena.jpg",cv2.IMREAD_GRAYSCALE)
v1=cv2.Canny(img,80,150)
v2=cv2.Canny(img,50,100)
res = np.hstack((v1,v2))
cv_show(res,'res')

五、图像金字塔与轮廓检测(模板匹配)
1.高斯,拉普拉斯金字塔

放大则为补0操作
代码如下(示例):
up=cv2.pyrUp(img) # (442, 340, 3) --> (884, 680, 3)
down=cv2.pyrDown(img)
cv_show(up,'up')
print (up.shape)

down=cv2.pyrDown(img)
down_up=cv2.pyrUp(down)
l_1=img-down_up
cv_show(l_1,'l_1')
2.图像轮廓
cv2.findContours(img,mode,method)
mode:轮廓检索模式
·RETR_EXTERNAL :只检索最外面的轮廓;
·RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中;
·RETR_CCOMP:检索所有的轮廓,并将他们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界;
·RETR_TREE:检索所有的轮廓,并重构嵌套轮廓的整个层次(常用)
method:轮廓逼近方法
·CHAIN_APPROX_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)。
·CHAIN_APPROX_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分。
# 更高的准确率,使用二值图像。
img = cv2.imread('contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
cv_show(thresh,'thresh')
# 计算出嵌套轮廓
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
# 传入绘制图像,轮廓,轮廓索引(-1全部),颜色模式,线条厚度
draw_img = img.copy() # 注意需要copy,要不原图会变
res = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 2)
cv_show(res,'res')
cnt = contours[0]
#面积
cv2.contourArea(cnt) # 8500.5
#周长,True表示闭合的
cv2.arcLength(cnt,True) # 437.9482651948929
轮廓近似

cnt = contours[0] # 选择一个轮廓
epsilon = 0.15*cv2.arcLength(cnt,True) # 按周长百分比,设置阈值(越大轮廓越粗糙)
approx = cv2.approxPolyDP(cnt,epsilon,True)
draw_img = img.copy()
res = cv2.drawContours(draw_img, [approx], -1, (0, 0, 255), 2)
cv_show(res,'res')
外接矩形:
cnt = contours[0]
x,y,w,h = cv2.boundingRect(cnt)
img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
cv_show(img,'img')
area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
rect_area = w * h
extent = float(area) / rect_area # 轮廓面积与边界矩形比
外接圆:
(x,y),radius = cv2.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
cv_show(img,'img')
3.模板匹配
模板匹配和卷积原理很像,模板在原图像上从原点开始滑动,计算模板与(图像被模板覆盖的地方)的差别程度,这个差别程度的计算方法在opencv里有6种,然后将每次计算的结果放入一个矩阵里,作为结果输出。假如原图形是AxB大小,而模板是axb大小,则输出结果的矩阵是(A-a+1)x(B-b+1)
cv2.matchTemplate(img, template, cv2.TM_SQDIFF)
·TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
·TM_CCORR:计算相关性,计算出来的值越大,越相关
·TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
·TM_SQDIFF_NORMED:计算归一化平方不同,计算出来的值越接近0,越相关
·TM_CCORR_NORMED:计算归一化相关性,计算出来的值越接近1,越相关
·TM_CCOEFF_NORMED:计算归一化相关系数,计算值越接近1,越相关
img = cv2.imread('lena.jpg', 0) # (263, 263)
template = cv2.imread('face.jpg', 0) # (110, 85)
res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF) # (154, 179)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 39168.0 74403584.0 (107, 89) (159, 62)
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
for meth in methods:
img2 = img.copy()
# 匹配方法的真值
method = eval(meth)
print (method)
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 如果是平方差匹配TM_SQDIFF或归一化平方差匹配TM_SQDIFF_NORMED,取最小值
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
# 画矩形
cv2.rectangle(img2, top_left, bottom_right, 255, 2)
plt.subplot(121), plt.imshow(res, cmap='gray')
plt.xticks([]), plt.yticks([]) # 隐藏坐标轴
plt.subplot(122), plt.imshow(img2, cmap='gray')
plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()

匹配多个对象
img_rgb = cv2.imread('mario.jpg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('mario_coin.jpg', 0)
h, w = template.shape[:2]
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
threshold = 0.8
# 取匹配程度大于%80的坐标
loc = np.where(res >= threshold)
for pt in zip(*loc[::-1]): # *号表示可选参数
bottom_right = (pt[0] + w, pt[1] + h)
cv2.rectangle(img_rgb, pt, bottom_right, (0, 0, 255), 2)
cv2.imshow('img_rgb', img_rgb)
cv2.waitKey(0)
六、直方图与傅里叶变换
1.图像直方图
cv2.calcHist(images,channels,mask,histSize,ranges)
·images: 原图像图像格式为 uint8 或 float32。当传入函数时应 用中括号 [] 括来例如[img]
·channels: 同样用中括号括来它会告函数我们统幅图 像的直方图。如果入图像是灰度图它的值就是 [0]如果是彩色图像 的传入的参数可以是 [0][1][2] 它们分别对应着 BGR。
·mask: 掩模图像。统整幅图像的直方图就把它为 None。但是如 果你想统图像某一分的直方图的你就制作一个掩模图像并 使用它。
·histSize:BIN 的数目。也应用中括号括来
·ranges: 像素值范围常为 [0256]
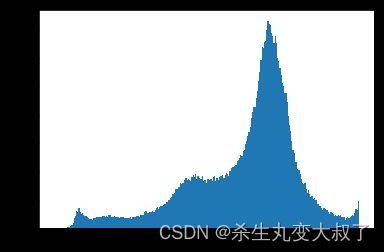
img = cv2.imread('cat.jpg',0) # 0表示灰度图
hist = cv2.calcHist([img],[0],None,[256],[0,256]) # (256, 1)
plt.hist(img.ravel(),256);
plt.show()
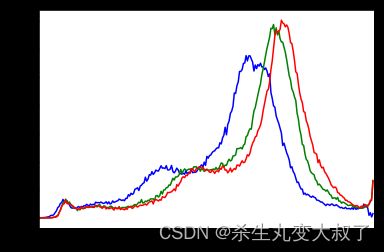
# 三通道直方图
img = cv2.imread('cat.jpg')
color = ('b','g','r')
for i,col in enumerate(color):
histr = cv2.calcHist([img],[i],None,[256],[0,256])
plt.plot(histr,color = col)
plt.xlim([0,256])
自适应直方图均衡化 (图像中分区域做均衡)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
res_clahe = clahe.apply(img)
res = np.hstack((img,equ,res_clahe))
cv_show(res,'res')
2.傅里叶变换
时域转频域:
高频:变化剧烈的灰度分量,例如边界;
低频:变化缓慢的灰度分量,例如一片大海
滤波:
低通滤波器:只保留低频,会使得图像模糊
高通滤波器:只保留高频,会使得图像细节增强
1.opencv中主要就是cv2.dft()和cv2.idft(),输入图像需要先转换成np.float32
2.得到结果中频率为0的部分会在左上角,通常要转换到中心位置,可以通过shift变换来实现。
3.cv2.dft()返回的结果是双通道的(实部,虚部),通常还需要转换成图像格式才能展示(0,255)。
img = cv2.imread('lena.jpg',0)
img_float32 = np.float32(img)
dft = cv2.dft(img_float32, flags = cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
# 得到灰度图能表示的形式
magnitude_spectrum = 20*np.log(cv2.magnitude(dft_shift[:,:,0],dft_shift[:,:,1]))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()

低通滤波
img = cv2.imread('lena.jpg',0)
img_float32 = np.float32(img)
dft = cv2.dft(img_float32, flags = cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
rows, cols = img.shape
crow, ccol = int(rows/2) , int(cols/2) # 中心位置
# 低通滤波
mask = np.zeros((rows, cols, 2), np.uint8)
mask[crow-30:crow+30, ccol-30:ccol+30] = 1 # 中心方框为全1
# IDFT
fshift = dft_shift*mask #只保留中心的低频部分
f_ishift = np.fft.ifftshift(fshift)
img_back = cv2.idft(f_ishift)
img_back = cv2.magnitude(img_back[:,:,0],img_back[:,:,1])
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img_back, cmap = 'gray')
plt.title('Result'), plt.xticks([]), plt.yticks([])
plt.show()

高通滤波

七、图像特征
1.harris特征

基本原理:

对其进行近似,可由矩阵表示:


实际操作时采用响应值:
cv2.cornerHarris()
·img: 数据类型为 float32 的入图像
·blockSize: 角点检测中指定区域的大小
·ksize: Sobel求导中使用的窗口大小
·k: 取值参数为 [0,04,0.06]

import cv2
import numpy as np
img = cv2.imread('test_1.jpg') # (800, 1200, 3)
print ('img.shape:',img.shape)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04) # (800, 1200)
print ('dst.shape:',dst.shape)
img[dst>0.01*dst.max()]=[0,0,255]
cv2.imshow('dst',img)
cv2.waitKey(0)
cv2.destroyAllWindows()

2.SIFT
Scale Invariant Feature Transform
整体过程为:
·1高斯/差分金字塔
·2定位关键点:26个邻域内求极值(泰勒展开)
·3消除边界效应(利用海森矩阵)
·4计算128个描述符(按主方向旋转)
img = cv2.imread('test_1.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 得到特征点
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray, None)
# 显示特征点
img = cv2.drawKeypoints(gray, kp, img)
cv2.imshow('drawKeypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 计算特征
kp, des = sift.compute(gray, kp) # np.array(kp).shape:(6827,)
des.shape: (6827, 128)
des[0]:array([ 0., 0., 0., 0., 0., 0., 0., 0., 21., 8., 0.,
0., 0., 0., 0., 0., 157., 31., 3., 1., 0., 0.,
2., 63., 75., 7., 20., 35., 31., 74., 23., 66., 0.,
0., 1., 3., 4., 1., 0., 0., 76., 15., 13., 27.,
8., 1., 0., 2., 157., 112., 50., 31., 2., 0., 0.,
9., 49., 42., 157., 157., 12., 4., 1., 5., 1., 13.,
7., 12., 41., 5., 0., 0., 104., 8., 5., 19., 53.,
5., 1., 21., 157., 55., 35., 90., 22., 0., 0., 18.,
3., 6., 68., 157., 52., 0., 0., 0., 7., 34., 10.,
10., 11., 0., 2., 6., 44., 9., 4., 7., 19., 5.,
14., 26., 37., 28., 32., 92., 16., 2., 3., 4., 0.,
0., 6., 92., 23., 0., 0., 0.], dtype=float32)
也可以用自定义函数:
https://github.com/o0o0o0o0o0o0o/image-processing-from-scratch/blob/master/sift/SIFT.py
3.读入数据
代码如下(示例):
data = pd.read_csv(
八、答题卡判卷
过程如下:
1.滤波,去除噪音
2.边缘检测
3.特征变换( 提取最大边缘 )
4.二值处理
5.掩码遍历(判断掩码圈内,黑白像素比)
6.
7.
import numpy as np
import argparse
import imutils
import cv2
# --------------------------0.正确答案----------------------------------
ANSWER_KEY = {0: 1, 1: 4, 2: 0, 3: 3, 4: 1}
# ---------------------------1.预处理-----------------------------------
image = cv2.imread(args["image"])
contours_img = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
cv_show('blurred',blurred)
edged = cv2.Canny(blurred, 75, 200)
cv_show('edged',edged)

# ----------------------------2.轮廓检测-----------------------------
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)[1] # [1]表示只要三个返回值里的轮廓
cv2.drawContours(contours_img,cnts,-1,(0,0,255),3)
cv_show('contours_img',contours_img)
docCnt = None
# ----------------------2.提取最大轮廓,做近似---------------------------
if len(cnts) > 0:
# 根据轮廓大小进行排序
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
# 遍历每一个轮廓
for c in cnts:
# 近似
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 准备做透视变换
if len(approx) == 4:
docCnt = approx
break

# ------------------------------3.执行透视变换-------------------------------
warped = four_point_transform(gray, docCnt.reshape(4, 2))
cv_show('warped',warped)
# 自适应,二值图
thresh = cv2.threshold(warped, 0, 255,
cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1] # 0 代表自适应阈值
cv_show('thresh',thresh)
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped

# ----------------------------4.找到所有圆圈轮廓(删除其他轮廓)-----------------------------
thresh_Contours = thresh.copy() # thresh是二值化的答题卡
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)[1]
cv2.drawContours(thresh_Contours,cnts,-1,(0,0,255),3)
cv_show('thresh_Contours',thresh_Contours)
questionCnts = []
# 遍历
for c in cnts:
# 计算比例和大小
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
# 根据实际情况指定标准
if w >= 20 and h >= 20 and ar >= 0.9 and ar <= 1.1:
questionCnts.append(c)

data = pd.read_csv(
2.读入数据
代码如下(示例):
data = pd.read_csv(
九、全景图像拼接

1.引入库
代码如下(示例):
#----------------------------1.读取拼接图片------------------------------
imageA = cv2.imread("left_01.png")
imageB = cv2.imread("right_01.png")
#检测A、B图片的SIFT关键特征点,并计算特征描述子
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
##-------------------------2.匹配两张图片的所有特征点-------------------
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
# H是3x3视角变换矩阵
(matches, H, status) = M
# ------------------------3.将图片A进行视角变换,result是变换后图片-----------------
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
self.cv_show('result', result)
效果如下:

其中,H为单应性矩阵。左乘图像即可进行变换
# ------------------------4.将图片B传入result图片最左端
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
self.cv_show('result', result)

其中,采用了RANSAC:不断迭代,找到最佳4个匹配点,删除离群点


十、背景建模
1.帧差法
该类算法对时间上连续的两帧图像进行差分运算,不同帧对应的像素点相减,判断灰度差的绝对值,当绝对值超过一定阈值时,即可判断为运动目标,从而实现目标的检测功能。
帧差法非常简单,但是会引入噪音和空洞问题
2.混合高斯模型
· 1.在进行前景检测前,先对背景进行训练,对图像中每个背景采用一个混合高斯模型进行模拟,每个背景的混合高斯的个数可以自适应(一般为4-5个)。
· 2.测试阶段,对新来的像素进行GMM匹配,如果该像素值能够匹配其中一个高斯,则认为是背景,否则认为是前景。由于整个过程GMM模型在不断更新学习中,所以对动态背景有一定的鲁棒性。最后通过对一个有树枝摇摆的动态背景进行前景检测,取得了较好的效果。

测试阶段,对新来像素点的值与混合高斯模型中的每一个均值进行比较,如果其差值在2倍的方差之间的话,则认为是背景,否则认为是前景。将前景赋值为255,背景赋值为0。这样就形成了一副前景二值图。在视频中对于像素点的变化情况应当是符合高斯分布
import numpy as np
import cv2
#经典的测试视频
cap = cv2.VideoCapture('test.avi')
#形态学操作需要使用
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3))
#创建混合高斯模型用于背景建模
fgbg = cv2.createBackgroundSubtractorMOG2()
while(True):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
#形态学开运算去噪点
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
#寻找视频中的轮廓
im, contours, hierarchy = cv2.findContours(fgmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
#计算各轮廓的周长
perimeter = cv2.arcLength(c,True)
if perimeter > 188:
#找到一个直矩形(不会旋转)
x,y,w,h = cv2.boundingRect(c)
#画出这个矩形
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow('frame',frame)
cv2.imshow('fgmask', fgmask)
k = cv2.waitKey(150) & 0xff
if k == 27:
break # 27设置退出条件
cap.release()
cv2.destroyAllWindows()
十一、AAAA
1.引入库
代码如下(示例):
import numpy as np
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。