神经网络模型训练简记(二)
神经网络模型训练简记(二)
- 内容简述
- 三、机器视觉网络模型分类及简介
-
- 3.2目标检测
-
- 3.2.1RCNN
- 3.2.2SPPNet
- 3.2.3Fast RCNN
- 3.2.4Faster RCNN
- 3.2.5Mask RCNN
- 3.2.6FPN
- 3.2.7Cascade RCNN
- 3.2.8Libra RCNN
- 3.2.9Grid RCNN
- 3.2.10YOLOv1
- 3.2.11SSD
- 3.2.12YOLOv2
- 3.2.13RetinaNet
- 3.2.14YOLOv3
- 3.2.15YOLOv4
- 3.2.16YOLOv5
- 参考文档
内容简述
第一、二章及第三章3.1节具体内容见神经网络模型训练简记(一),以下正文从3.2节开始。
三、机器视觉网络模型分类及简介
3.2目标检测
目标检测任务是找出图像或视频中人们感兴趣的物体,并同时检测出它们的位置和大小。不同于图像分类任务,目标检测不仅要解决分类问题,还要解决定位问题,是属于Multi-Task的问题。
作为计算机视觉的基本问题之一,目标检测构成了许多其它视觉任务的基础,例如实例分割,图像标注和目标跟踪等等;从检测应用的角度看:行人检测、面部检测、文本检测、交通标注与红绿灯检测,遥感目标检测统称为目标检测的五大应用。

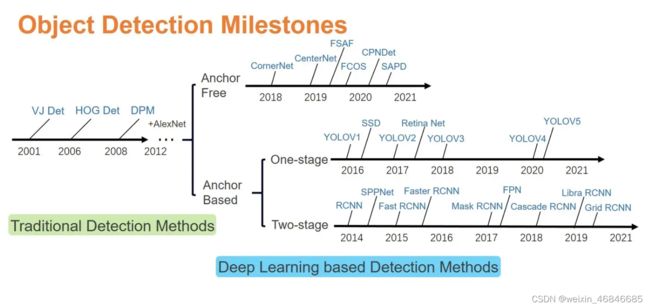
基于手工提取特征的传统目标检测算法进展缓慢,性能低下。直到2012年卷积神经网络(Convolutional Neural Networks, CNNs)的兴起将目标检测领域推向了新的台阶。基于CNNs的目标检测算法主要有两条技术发展路线:anchor-based和anchor-free方法,而anchor-based方法则包括一阶段和二阶段检测算法(二阶段目标检测算法一般比一阶段精度要高,但一阶段检测算法速度会更快),二阶段目标检测算法也称为基于区域(Region-based)的方法。
二阶段检测算法主要分为以下两个阶段
Stage1:从图像中生成region proposals;
Stage2:从region proposals生成最终的物体边框。
3.2.1RCNN
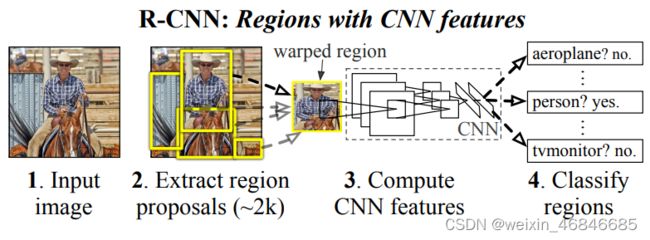
RCNN(Regions with CNN features)由Ross Girshick于2014年提出,RCNN首先通过选择性搜索算法Selective Search从一组对象候选框中选择可能出现的对象框,然后将这些选择出来的对象框中的图像resize到某一固定尺寸的图像,并喂入到CNN模型(经过在ImageNet数据集上训练过的CNN模型,如AlexNet)提取特征,最后将提取出的特征送入到SVM分类器来预测该对象框中的图像是否存在待检测目标,并进一步预测该检测目标具体属于哪一类,论文链接。
RCNN算法在VOC-07数据集上取得了非常显著的效果,平均精度由33.7%(DPM-V5, 传统检测的SOTA算法)提升到58.5%。相比于传统检测算法,基于深度学习的检测算法在精度上取得了质的飞跃。
R-CNN的想法直接明了,即将检测任务转化为区域上的分类任务,是深度学习方法在检测任务上的试水。模型本身存在的问题也很多,如需要训练三个不同的模型(proposal, classification, regression)、重复计算过多导致的性能问题等。尽管如此,这篇论文的很多做法仍然广泛地影响着检测任务上的深度模型革命,后续的很多工作也都是针对改进这一工作而展开,此篇可以称得上"The First Paper"。
小结:
1.RCNN的两大贡献:1)CNN可用于基于区域的定位和分割物体;2)监督训练样本数紧缺时,在额外的数据上预训练的模型经过fine-tuning可以取得很好的效果。第一个贡献影响了之后几乎所有2-stage方法,而第二个贡献中用分类任务(Imagenet)中训练好的模型作为基网络,在检测问题上fine-tuning的做法也在之后的工作中一直沿用。
2.RCNN缺点如下:
训练时间长:主要原因是分阶段多次训练,而且对于每个region proposal都要单独计算一次feature map,导致整体的时间变长。
占用空间大:主要原因是每个region proposal的feature map都要写入硬盘中保存,以供后续的步骤使用。
multi-stage:文章中提出的模型包括多个模块,每个模块都是相互独立的,训练也是分开的。
3.2.2SPPNet
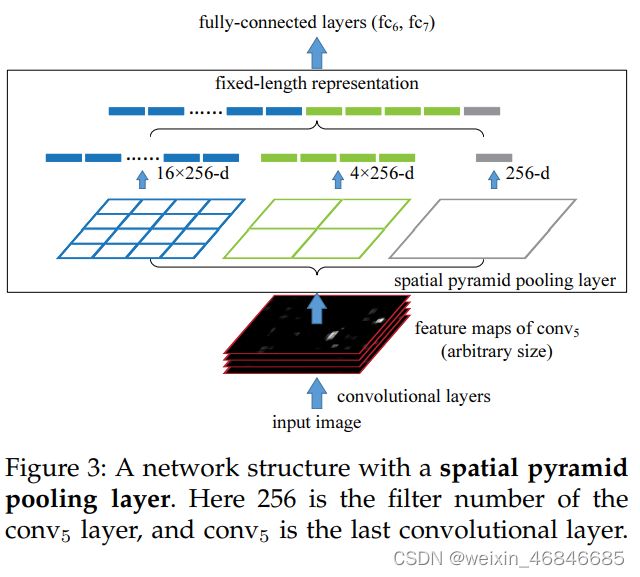
SPPNet由何凯明在2015年提出,作者在论文中提出了一种空间金字塔池化层(Spatial Pyramid Pooling Layer, SPP)。它的主要思路是对于一副图像分成若干尺度的图像块(比如一副图像分成1份,4份,8份等),然后对每一块提取的特征融合在一起,从而兼顾多个尺度的特征。SPP使得网络在全连接层之前能生成固定尺度的特征表示,而不管输入图片尺寸如何。当使用SPPNet网络用于目标检测时,整个图像只需计算一次即可生成相应特征图,不管候选框尺寸如何,经过SPP之后,都能生成固定尺寸的特征表示图,这避免了卷积特征图的重复计算,论文链接。
相比于RCNN算法,SPPNet在Pascal-07数据集上不牺牲检测精度(VOC-07, mAP=59.2%)的情况下,推理速度提高了20多倍。
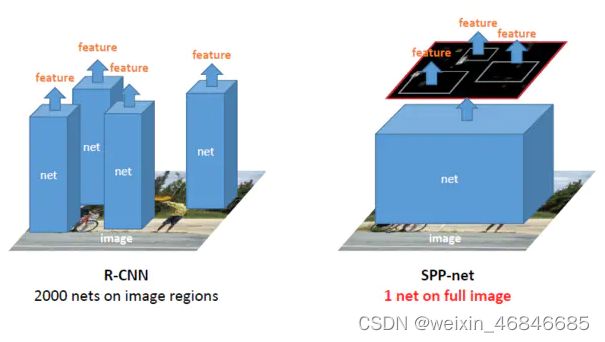
SPPnet的做法是首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。然后把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中通过映射关系找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后再进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度会大大提升。
小结:
1.SPPnet解决了深度卷积神经网络(CNN)的输入必须要求固定图像尺寸(例如224*224)的限制,并且提高了目标检测领域内网络提取特征的效率,速度相比R-CNN提升24-102倍。
2.和RCNN一样,SPP也需要训练CNN提取特征,然后训练SVM分类这些特征,这需要巨大的存储空间,并且多阶段训练的流程也很繁杂。除此之外,SPPNet只对全连接层进行微调,而忽略了网络其它层的参数。
3.2.3Fast RCNN
Fast RCNN网络是RCNN和SPPNet的改进版,该模型被Ross Girshick( RCNN作者)于2015年推出。Fast RCNN该网络可以在相同的网络配置下同时训练一个检测器和边框回归器。该网络首先输入图像,图像被传递到CNN中提取特征,并返回感兴趣的区域ROI,之后再ROI上运用ROI池化层以保证每个区域的尺寸相同,最后这些区域的特征被传递到全连接层的网络中进行分类,并用Softmax和线性回归层同时返回边界框,论文链接。
Fast RCNN在VOC-07数据集上将检测精度mAP从58.5%提高到70.0%,检测速度比RCNN提高了200倍。
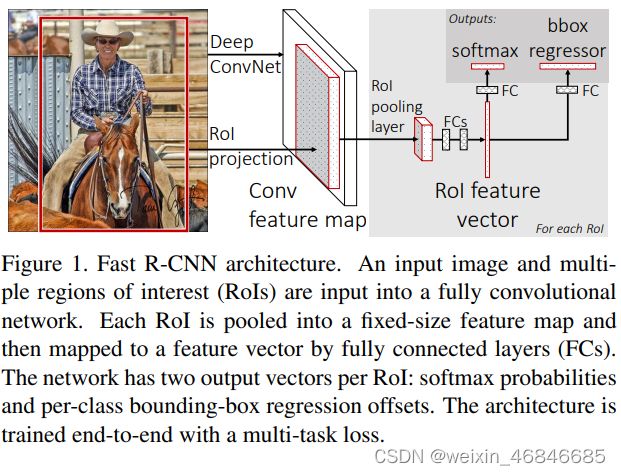
Fast R-CNN的流程图如上,网络有两个输入:图像和对应的region proposal。其中region proposal由selective search方法得到,没有表示在流程图中。对每个类别都训练一个回归器,且只有非背景的region proposal才需要进行回归。
ROI pooling:ROI Pooling的作用是对不同大小的region proposal,从最后卷积层输出的feature map提取大小固定的feature map。简单讲可以看做是SPPNet的简化版本,因为全连接层的输入需要尺寸大小一样,所以不能直接将不同大小的region proposal映射到feature map作为输出,需要做尺寸变换。在文章中,VGG16网络使用H=W=7的参数,即将一个h×w的region proposal分割成H×W大小的网格,然后将这个region proposal映射到最后一个卷积层输出的feature map,最后计算每个网格里的最大值作为该网格的输出,所以不管ROI pooling之前的feature map大小是多少,ROI pooling后得到的feature map大小都是H×W。
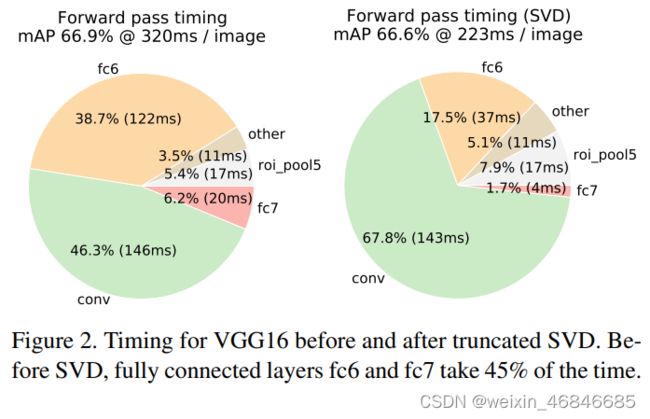
采用SVD分解改进全连接层。如果是一个普通的分类网络,那么全连接层的计算应该远不及卷积层的计算,但是针对object detection,Fast RCNN在ROI pooling后每个region proposal都要经过几个全连接层,这使得全连接层的计算占网络的计算将近一半,如下图,所以作者采用SVD来简化全连接层的计算。
小结:
1.RCNN算法与图像内的大量候选帧重叠,导致提取特征操作中的大量冗余。而Fast RCNN很好地解决了这一问题,它将Proposal, Feature Extractor, Object Classification&Localization统一在一个整体的结构中,并通过共享卷积计算提高特征利用效率,是最有贡献的地方。Fast R-CNN的这一结构正是检测任务主流2-stage方法所采用的元结构的雏形。
2.Fast RCNN仍然选用选择性搜索算法来寻找感兴趣的区域,这一过程通常较慢。由于使用Selective Search来预先提取候选区域,Fast RCNN并未实现真正意义上端到端的训练模式。
3.2.4Faster RCNN
Faster RCNN,是由任少卿、何凯明、Ross Girshick等在2015年提出的,在使用VGG16作为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升,该算法在2015年的ILSVRV和COCO竞赛中获得多项第一。Faster RCNN摒弃了传统的滑动窗口和选择性搜索方法,直接使用RPN(区域建议网络)生成检测框,这也是Faster RCNN的巨大优势,能极大提升检测框的生成速度,论文链接。
该网络在当时VOC-07,VOC-12和COCO数据集上实现了SOTA精度,其中COCO [email protected]=42.7%, COCO mAP@[.5,.95]=21.9%, VOC07 mAP=73.2%, VOC12 mAP=70.4%, 17fps with ZFNet。
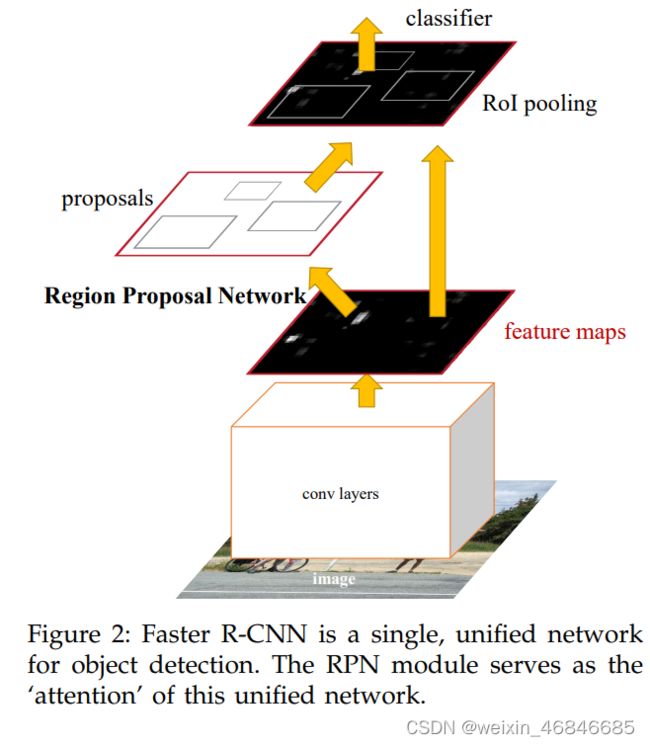
算法整体流程如下:
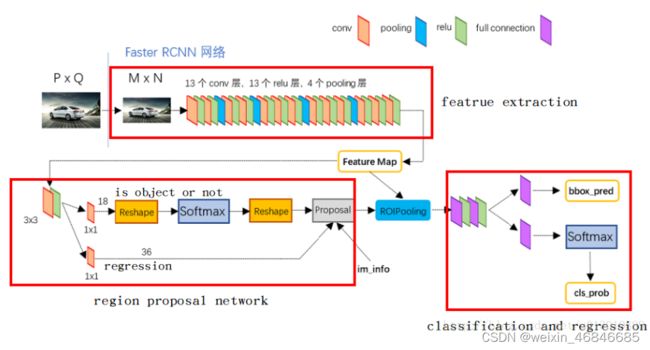
(一)首先对输入的图片进行裁剪操作,并将裁剪后的图片送入预训练好的分类网络中获取该图像对应的特征图;
(二)然后在特征图上的每一个锚点上取9个候选的ROI(3个不同尺度,3个不同长宽比),并根据相应的比例将其映射到原始图像中(因为特征提取网络一般有conv和pool组成,但是只有pool会改变特征图的大小,因此最终的特征图大小和pool的个数相关);
(三)接着将这些候选的ROI输入到RPN网络中,RPN网络对这些ROI进行分类(即确定这些ROI是前景还是背景)同时对其进行初步回归(即计算这些前景ROI与真实目标之间的BB的偏差值,包括Δx、Δy、Δw、Δh),然后做NMS(非极大值抑制,即根据分类的得分对这些ROI进行排序,然后选择其中的前N个ROI);
(四)接着对这些不同大小的ROI进行ROI Pooling操作(即将其映射为特定大小的feature_map,文中是7x7),输出固定大小的feature_map;
(五)最后将其输入简单的检测网络中,然后利用1x1的卷积进行分类(区分不同的类别,N+1类,多余的一类是背景,用于删除不准确的ROI),同时进行BB回归(精确的调整预测的ROI和GT的ROI之间的偏差值),从而输出一个BB集合。
小结:
1.Faster R-CNN的成功之处在于用RPN网络完成了检测任务的"深度化",在提高精度的同时提高了速度。使用滑动窗口生成anchor box的思想也在后来的工作中越来越多地被采用(YOLO v2等)。这项工作奠定了"RPN+RCNN"的两阶段方法元结构,影响了大部分后续工作。
2.虽然Faster RCNN的精度更高,速度更快,也非常接近于实时性能,但它在后续的检测阶段中仍存在一些计算冗余;除此之外,如果IOU阈值设置的低,会引起噪声检测的问题,如果IOU设置的高,则会引起过拟合。
3.2.5Mask RCNN
Mask RCNN是由 Facebook AI Research的何凯明等在2017年提出,是一种用于实例分割的框架,其简洁、灵活的设计使得我们能够在一个网络中同时实现目标检测和图像分割这两大计算机视觉的基本任务。这个模型取得了 COCO 2016 challenge 的冠军,相应的论文也获得了 ICCV2017 的最佳论文奖,论文链接。
为实现高速和高准确率的目的,作者选用了经典的目标检测算法Faster-rcnn和经典的语义分割算法FCN。Faster-rcnn可以既快又准的完成目标检测的功能;FCN可以精准的完成语义分割的功能,这两个算法都是对应领域中的经典之作。Mask R-CNN比Faster-rcnn复杂,但是最终仍然可以达到5fps的速度,这和原始的Faster-rcnn的速度相当。由于发现了ROI Pooling中所存在的像素偏差问题,提出了对应的ROIAlign策略,加上FCN精准的像素MASK,使得其可以获得高准确率。
整个Mask R-CNN算法的思路很简单,就是在原始Faster-rcnn算法的基础上面增加了FCN来产生对应的MASK分支。即Faster-rcnn + FCN,更细致的是 RPN + ROIAlign + Fast-rcnn + FCN。

Mask R-CNN算法步骤如下:
(一)首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
(二)然后,将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
(三)接着,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
(四)接着,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
(五)接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
(六)最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)。
小结:
1.整个Mask R-CNN算法非常的灵活,可以用来完成多种任务,包括目标分类、目标检测、语义分割、实例分割、人体姿态识别等多个任务,这将其易于使用的特点展现的淋漓尽致。除此之外,我们可以更换不同的backbone architecture和Head Architecture来获得不同性能的结果。
2.使用了ROIAlign代替ROI Pooling,ROI Pooling和ROIAlign最大的区别是:前者使用了两次量化操作(取整计算),会使得到的Mask与实际物体位置存在偏移,而后者并没有采用量化操作,使用了线性插值算法。

3.2.6FPN
2017年,Facebook AI Research的T.-Y.Lin等人在Faster RCNN的基础上进一步提出了特征金字塔网络FPN(Feature Pyramid Networks)技术。在FPN技术出现之前,大多数检测算法的检测头都位于网络的最顶层(最深层),虽说最深层的特征具备更丰富的语义信息,更有利于物体分类,但更深层的特征图由于空间信息的缺乏不利于物体定位,这大大影响了目标检测的定位精度。为了解决这一矛盾,FPN提出了一种具有横向连接的自上而下的网络架构,用于在所有具有不同尺度的高底层都构筑出高级语义信息。FPN的提出极大促进了检测网络精度的提高(尤其是对于一些待检测物体尺度变化大的数据集有非常明显的效果),论文链接。
将FPN技术应用于Faster RCNN网络之后,网络的检测精度得到了巨大提高(COCO [email protected]=59.1%, COCO mAP@[.5,.95]=36.2%),再次成为当前的SOTA检测算法。此后FPN成为了各大网络(分类,检测与分割)提高精度最重要的技术之一。

一直以来如何识别小物体是目标检测任务的难点,该论文主要解决的就是这个问题。论文首先总结了几种解决方法,如上图所示:
(一)如上图a所示,通过图像金字塔来构建不同尺度的特征金字塔。对每一种尺度的图像进行特征提取,能够产生多尺度的特征表示,并且所有等级的特征图都具有较强的语义信息,甚至包括一些高分辨率的特征图。但这种方式计算量很大,内存占用大,用图像金字塔的形式训练一个端到端的深度神经网络变得不可行。
(二)如上图b所示,此前大多网络都使用了利用单个高层特征(比如说Faster R-CNN利用下采样四倍的卷积层——Conv4,进行后续的物体的分类和bounding box的回归),但是这样做有一个明显的缺陷,即小物体本身具有的像素信息较少,在下采样的过程中极易被丢失,导致检测精度下降。
(三)如上图c所示,将高低层特征都使用上,比如SSD就是利用不同层多尺度的特征图,但存在底层特征语义不够、最高分辨率不高的问题,导致预测结果不佳。论文中指出,SSD为了避免这个问题,放弃了底层特征,而是从网络的高层开始构建金字塔(例如,VGG网络的Conv4之后,再添加几个新的卷积层),因此,SSD没有充分利用到低层特征图中的空间信息(这些信息对小物体的检测十分重要)。
(四)为了解决以上三种结构的不足之处,这篇论文提出了FPN,即使每一层不同尺度的特征图都具有较强的语义信息,如上图d所示。
FPN通过讲浅层的特征跳接到深层的特征,兼顾了分辨率与特征语义。但实际上,这也不是FPN的首创,在对分辨率要求更高的语义分割问题中早有涉猎(如医学图像常用的U-Net)。但FPN的独到之处在于将深/潜层特征融合与多分辨率预测结合了起来。

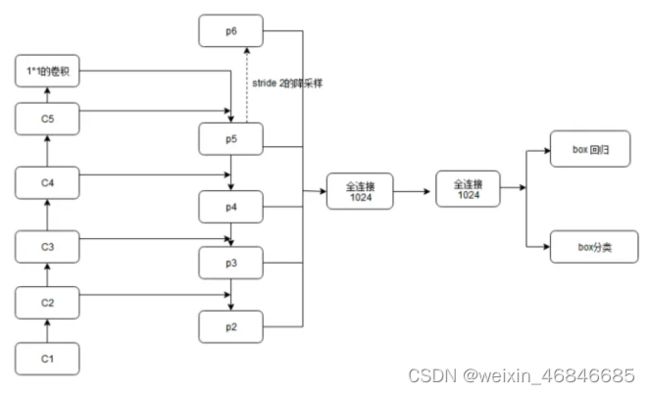
上图为FPN网络结构:
(一) Bottom-up pathway
前馈Backbone的一部分,每一级往上用step=2的降采样。
输出size相同的网络部分叫一级(stage),选择每一级的最后一层特征图,作为Up-bottom pathway的对应相应层数,经过1 x 1卷积过后element add的参考。
例如,下图是fasterRCNN的网络结构,左列ResNet用每级最后一个Residual Block的输出,记为{C1,C2,C3,C4,C5}。
FPN用2~5级参与预测(因为第一级的语义还是太低了),{C2,C3,C4,C5}表示conv2,conv3,conv4和conv5的输出层(最后一个残差block层)作为FPN的特征,分别对应于输入图片的下采样倍数为{4,8,16,32}。
(二).Top-down pathway and lateral connections
自顶向下的过程通过上采样(up-sampling)的方式将顶层的小特征图。放大到上一个stage的特征图一样的大小。
上采样的方法是最近邻插值法:
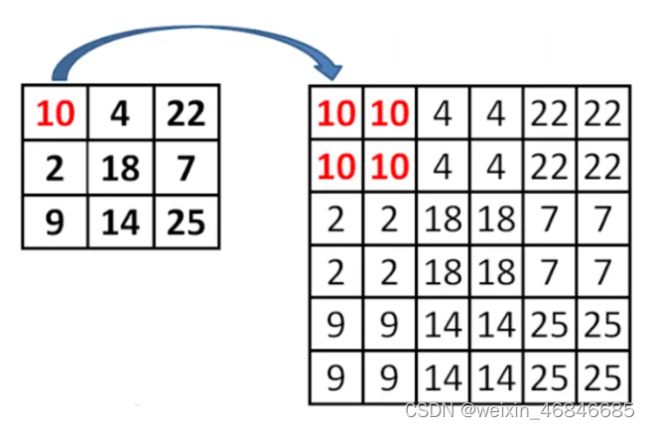
其中跳接时前后维度不一致问题的解决方法采用了1×1conv,通过跳接融合特征之后,还要进行一个3×3conv,以减轻最近邻插值带来的影响(因为周围的数字都比较相近,会出现重叠现象)。
(三)在RPN上的改进
Faster RCNN中的RPN是通过最后一层的特征来做的。最后一层的特征经过3x3卷积,得到256个channel的卷积层,再分别经过两个1x1卷积得到类别得分和边框回归结果。这里将特征层之后的RPN子网络称之为网络头部(network head)。对于特征层上的每一个点,作者用anchor的方式预设了9个框。这些框本身包含不同的尺度和不同的长款比例。
FPN针对RPN的改进是将网络头部应用到每一个P层。由于每个P层相对于原始图片具有不同的尺度信息,因此作者将原始RPN中的尺度信息分离,让每个P层只处理单一的尺度信息。具体的,对{ 322、642、1282、2562、5122}这五种尺度的anchor,分别对应到{P2、P3、P4、P5、P6}这五个特征层上。每个特征层都处理1:1、1:2、2:1三种长宽比例的候选框。P6是专门为了RPN网络而设计的,用来处理512大小的候选框。它由P5经过下采样得到。
另外,上述5个网络头部的参数是共享的。作者通过实验发现,网络头部参数共享和不共享两种设置得到的结果几乎没有差别。这说明不同层级之间的特征有相似的语义层次。这和特征金字塔网络的原理一致。
小结:
1.通过结合bottom-up与top-down方法获得较强的语义特征,融合来多尺度特征,提高目标检测和实例分割在多个数据集上面的性能表现,FPN这种架构可以灵活地应用在不同地任务中去,包括目标检测、实例分割等。
2.但FPN存在以下三个缺点:
(一)不同层之间存在语义鸿沟,直接融合会降低多尺度表示能力;
(二)下采样过程会损失最高层金字塔特征信息;
(三)融合后:各层ROI特征独立进行预测,其他层次的被忽略。
3.2.7Cascade RCNN
Cascade(级联) RCNN是由Z Cai等在2018年提出。Faster RCNN完成了对目标候选框的两次预测,其中RPN一次,后面的检测器一次,而Cascade RCNN则更进一步将后面检测器部分堆叠了几个级联模块,并采用不同的IOU阈值训练,这种级联版的Faster RCNN就是Cascade RCNN。通过提升IoU阈值训练级联检测器,可以使得检测器的定位精度更高,在更为严格的IoU阈值评估下,Cascade R-CNN带来的性能提升更为明显。Cascade RCNN将二阶段目标检测算法的精度提升到了新的高度,论文链接。
Cascade RCNN在COCO检测数据集上,不添加任何Trick即可超过现有的SOTA单阶段检测器,此外使用任何基于RCNN的二阶段检测器来构建Cascade RCNN,mAP平均可以提高2-4个百分点。
在目标检测中,我们需要人为指定一个经验性的IOU阈值来定义正样本和负样本,直觉上来说这个值定义的越大,正样本的质量也就越高,模型也就倾向于产生高质量的检测框,但是实践中我们却发现一味地增加IOU的阈值反而降低了模型的检测精度,这主要可能是又两个原因:
(一)当提升阈值之后正样本会"指数式地"减少,容易过拟合;
(二)inference时存在mismatch的问题(即在train上取得最佳的IOU阈值对inference时产生的proposal并不能很好地进行回归)。
我们可以想到training阶段和inference阶段,bbox回归器的输入分布是不一样的,training阶段的输入proposals质量更高(被采样过,IoU>threshold),inference阶段的输入proposals质量相对较差(没有被采样过,可能包括很多IoU
上图中的曲线是用来描述localization performance,其中横坐标表示输入proposal和ground truth的IOU值,纵坐标表示输出的proposal和ground truth的IOU值。红、绿、蓝3条曲线代表训练检测模型时用的正负样本标签的阈值分别是0.7、0.6、0.5。从图中(c)可以看出,当一个检测模型采用某个阈值(假设u=0.6)来界定正负样本时,那么当输入proposal的IOU在这个阈值(u=0.6)附近时,该检测模型比基于其他阈值训练的检测模型的效果要好。可以得出以下结论:
(一)只有proposal自身的阈值和训练器训练用的阈值较为接近的时候,训练器的性能才最好;
(二)如果两个阈值相距比较远,就会存在mismatch问题;
(三)单一阈值训练出的检测器效果非常有限,单一阈值不能对所有的Proposals都有很好的优化作用。
基于上述结论,文章提出了cascade R-CNN,简单讲cascade R-CNN是由一系列的检测模型组成,每个检测模型都基于不同IOU阈值的正负样本训练得到,前一个检测模型的输出作为后一个检测模型的输入,因此是stage by stage的训练方式,而且越往后的检测模型,其界定正负样本的IOU阈值是不断上升的。
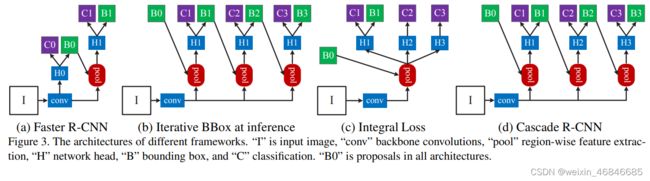
上图是论文中给出的一张当时比较流行的方法示意图,又称之为结构图。
(a)是Faster RCNN,因为two stage类型的object detection算法基本上都基于Faster RCNN,所以这里也以该算法为基础算法。
(b)是迭代式的bbox回归,从图也非常容易看出思想,就是前一个检测模型回归得到的bbox坐标初始化下一个检测模型的bbox,然后继续回归,这样迭代三次后得到结果。(c)是Integral Loss,表示对输出bbox的标签界定采取不同的IOU阈值,因为当IOU较高时,虽然预测得到bbox很准确,但是也会丢失一些bbox。
(d)就是本文提出的cascade-R-CNN。cascade-R-CNN看起来和(b)这种迭代式的bbox回归以及(c)这种Integral Loss很像,和(b)最大的不同点在于cascade-R-CNN中的检测模型是基于前面一个阶段的输出进行训练,而不是像(b)一样3个检测模型都是基于最初始的数据进行训练,而且(b)是在验证阶段采用的方式,而cascade-R-CNN是在训练和验证阶段采用的方式。和(c)的差别也比较明显,cascade R-CNN中每个stage的输入bbox是前一个stage的bbox输出,而(c)其实没有这种refine的思想,仅仅是检测模型基于不同的IOU阈值训练得到而已。
小结:
1.具有以下优点:
(一)采用多阶段逐步提升IOU, 从而在低IOU样本中获取更多的"高IOU"样本;
(二)对于最后一个阶段输出了高IOU样本, 训练classifier从而使其适应高IOU样本, 当其推理时对于高IOU的样本处理表现也更好;
(三)每一个stage的detector都不会过拟合,都有足够满足阈值条件的样本。
2.具有实现简单、 效果优异的特点, 在COCO数据集的相关测试中, 超过了所有的单模型对象检测器。在目标检测问题上, Cascade R-CNN具有广泛的适用性, 可以为不用的检测算法带来一致的检测增益。
3.2.8Libra RCNN
Libra RCNN是由商汤和浙大的庞江淼等人在2019年提出,文章中没有太多改造网络结构,计算成本也没增加多少,只是通过三个方面的改进就能在MSCOCO数据集上AP值比FPN、Faster RCNN高2.5%,比RetinaNet高2%,论文链接。
随着深卷积网络的发展,近年来,在目标检测方面取得了显著进展。一些检测框架,如Fasetr R-CNN、Retinanet和Cascaded R-CNN已经开发出来,这大大推动了技术的发展。尽管管道体系结构存在明显的差异,例如单阶段与两阶段,但现代检测框架大多遵循一种通用的训练范式:
(一)采样候选区域 sample level;
(二)从中提取特征 feature level ;
(三)在多任务目标函数的指导下识别目标和润色边界框 objective level。
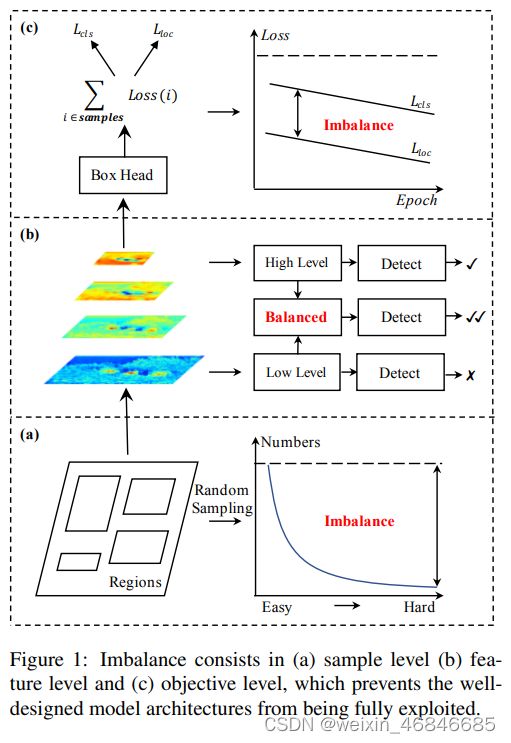
这个范式使得目标检测是否成功取决于三方面:
(一)选择的区域是否具有代表性;
(二)提取的特征是否被充分利用;
(三)多任务目标函数是否为最优的。
论文提出目前训练范式中存在三个不平衡问题:
(一)sample level imbalance(采样级的不平衡):随机采样会使所选样本受简单样本的支配;复杂采样方法,如OHEM,会使注意力更向复杂样本集中,但是却对噪声标签敏感,并且会提升内存的占用和计算量。
(二)feature level imbalance(特征级的不平衡):深度高水平的特征具有更多语义,而浅层低水平特征更容易描述。近年来,基于横向连接的特征整合如FPN和PANet的使用,使得目标检测获得了进步。 也就是说对于目标检测来说,深层特征和浅层特征存在互补性。如何利用它们集成金字塔表示的方法决定了检测性能。整合的特征应该拥有来自每个分辨率的平衡信息。但是,上述方法中的顺序方式将使集成特性更多地关注相邻分辨率,而较少关注其他分辨率。非相邻层次中包含的语义信息在信息流中每次融合都会被稀释一次。
(三)objective level imbalance(目标级的不平衡):检测器需要完成两个任务:分类和定位。这两个任务在训练的时候目的并不统一。如果不能平衡这一现象,就可能牺牲一个任务,导致次优解。在训练过程中,对涉及的样本来说也一样。如果平衡不好的话,简单样本产生的小梯度可能被复杂样本的大梯度所淹没,进而限制进一步的优化。
论文针对三个不平衡问题分别提出解决方法:
(一)IoU-balanced sampling(IoU平衡采样)
下图为不同采样的比较:
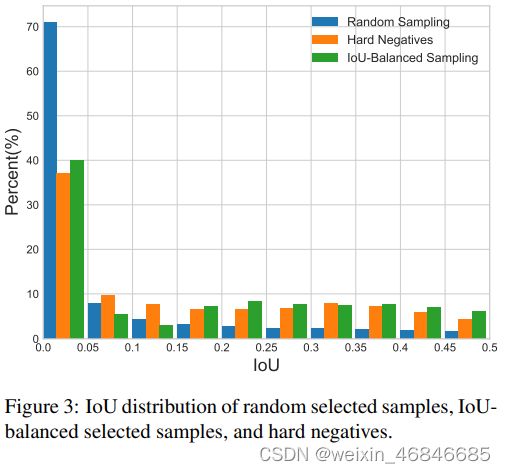
训练样本和真值的重叠和它是否难分有关?我们主要考虑难负样本的问题,这是众所周知的主要问题。我们发现超过60%的难负样本重叠度大于0.05,但随机抽样只提供了超过相同阈值的30%的训练样本。这种极端的样本不平衡将许多难样本埋藏在成数千个易分样本之中。基于这一观察,我们提出了IOU平衡。
一种简单而有效的难样本方法,无需额外成本。假设我们需要从M个对应的候选样本中抽取N个负样本。随机抽样下每个样本的选择概率是:
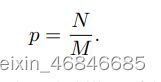
为了提高难负样本的选定概率,我们根据IOU将采样间隔均匀地分成K个。N个需要的难负样本平均分配到每个区间。然后我们从中均匀地选取样本。因此,我们得到了IOU均衡抽样下的选择概率:
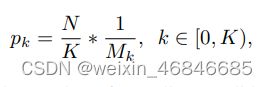
Mk是第k个区间中候选样本的数量。K在论文中被设为3(经过实验,只要更容易选择IoU更高的样本,结果对K不敏感)。
(二)Balanced Feature Pyramid(平衡特征金字塔)
核心思想是使用相同的深度集成的平衡语义特征来增强多层次的特征。管道如图所示。它由四个步骤组成:缩放、整合、润色和强化。
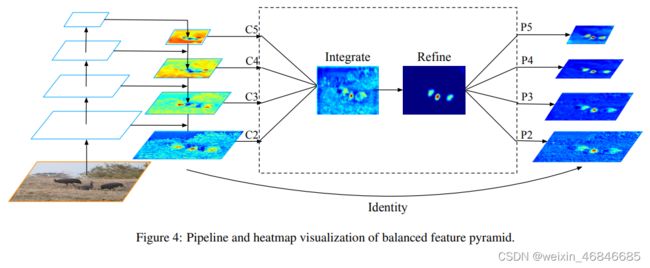
首先获得平衡语义特征。分辨率级别l的特征表示为Cl。多级别特征的数量表示为L。涉及的最低和最高级别的索引表示为lmin和lmax。在图中,C2的分辨率最高。为了同时集成多层次特性并保持其语义层次,我们首先将多层次特性C2、C3、C4、C5分别使用插值和最大值池化调整为中等大小,即与C4大小相同。一旦特征被重新调整,通过简单的平均得到平衡的语义特征:

在本步骤中,每个分辨率都从其他分辨率中获得同等的信息。
然后润色平衡的语义特征。 论文发现直接使用卷积和non-local模块都可以很好地工作。但non-local更稳定。因此,使用embedded Gaussian non-local attention作为默认值。细化步骤有助于增强集成功能,进一步提高结果。使用这种方法,可以同时聚合从低级到高级的特征。输出P2、P3、P4、P5用于在FPN中沿着同一管道检测对象。值得一提的是,平衡特性金字塔可以与最近的解决方案(如FPN和PAFPN)互补,而不会产生任何冲突。
(三)Balanced L1 Loss(平衡L1损失)
Faster R-CNN以来,分类和定位问题在多任务损失的指导下同时得到解决,定义为:
![]()
Lcls和Lloc分别是识别和定位的目标函数。Lcls中的预测和目标分别表示为p,u。tu是类别u相应的回归结果,v是回归目标。λ用于调整多任务学习下的权重。我们称损失大于或等于1.0的样本为outliers。其他样本称为inliers。
平衡多任务损失的常见的方法就是调整权重,但是由于回归目标无界,直接增加定位损失会使得模型对outliers更加敏感。这些outliers可以被视为难样本,会产生对训练过程有害的过大梯度。与outliers相比,inliers对整体梯度的贡献很小,可以看作是一个简单的样本。更具体地说,与outliers相比,每个样本的平均梯度只有30%。考虑到这些问题,提出了平衡的L1损耗,用Lb表示。
Lloc的Balanced L1 Loss为:
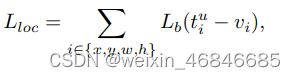
梯度计算遵循如下准则:

于是作者从需出发,设计了一个在|x|<1时梯度比较大的函数:
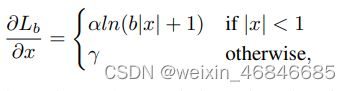
从下图中可以看出,在|x|<1时,上式的梯度是大于x(Smooth L1 Loss的梯度)
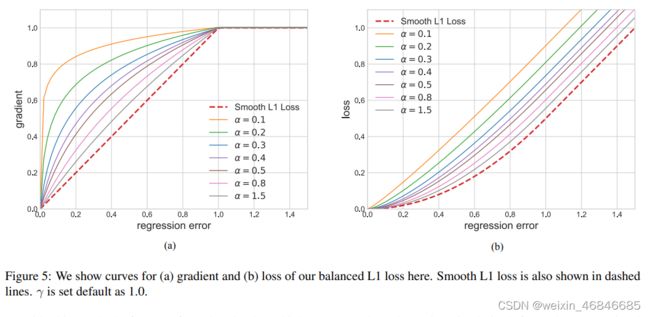
通过合并梯度公式,可以得出balanced L1 loss:
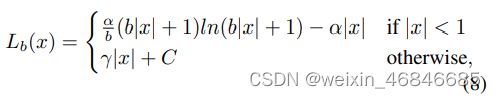
参数γ, α, 和 b 满足如下公式:
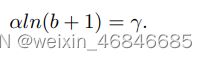
在论文试验中将α设定为0.5,γ设定为1.5。
小结:
论文没有改变网络结构,通过试验或统计看到潜在的不平衡现象,针对sample、feature和loss进行分析并提出优化,非常实用。
3.2.9Grid RCNN
Grid RCNN是由商汤的Xin Lu等人在2018年提出,对Faster R-CNN架构的目标坐标回归部分进行了替换,取得了更加精确的定位精度,论文链接。
在目前的R-CNN目标检测算法中,目标的2个点(比如左上和右下)就能表征其位置,将目标的定位看为回归问题,即将ROI特征flatten成向量,后接几个全连接层回归目标的坐标偏移量和宽高。
作者认为,这种处理方式没能很好的利用特征的空间信息。作者希望利用全卷积网络的精确定位能力计算目标位置,将2个目标点的回归问题,转化为目标区域网格点(Grid Points)的定位问题。目标区域的网格点位置是全卷积网络的监督信息,因为是直接将目标区域等分,是可以直接计算的。网络推断时,计算heatmap的极值,即为求得的网格点(Grid Points)。
作者改造的是Faster R-CNN的目标定位部分,其算法流程如下:
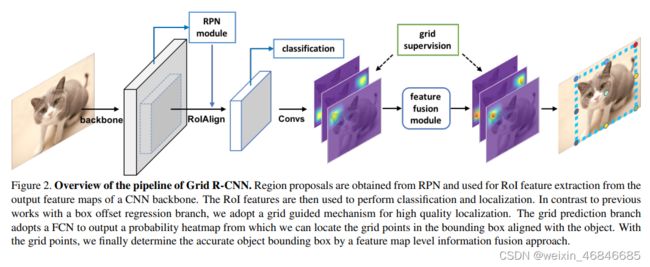
前半部分与Faster R-CNN相同,在得到目标候选区域和ROI特征后,分类部分进行目标分类,而定位部分接全卷积网络,其监督信息来自根据目标位置计算得到的网格监督信息。
流程图中作者特别标出了特征融合模块(feature fusion module),其意在使用网格中相邻网格点的位置相关性,融合特征使得定位更加精确。
以下针对其中关键步骤进行详细说明。
(一)网格引导定位
将目标区域划为网格,目标的定位即转化为网格点的定位。
训练时,ROI特征(1414大小)通过8个33空洞卷积,再通过两个反卷积把尺寸扩大(56*56),再通过一个卷积生成与网格点相关的 heatmaps(9 个点就是 9 张图,后文实验也使用了4个点的情况)。监督信息是每一个点所处位置的交叉十字形状的5个点的位置。最后再接sigmoid函数,在heapmaps上得到概率图。
推断时,将heapmaps极值的位置映射回原图,即得到了网格点的位置。

计算得到的网格点组成的形状是方方正正的,而Heapmaps极值得到的网格点未必组合在一起是方方正正的,不好确定目标区域。作者的方法是对原本应该具有相同x或者y坐标的网格点的坐标进行平均。

到此,即得到了目标位置。
(二)网格点特征融合
很显然,网格点之间具有内在的联系,相邻网格点之间可以相互校正位置提高定位精度。
为此,作者设计了网格点特征融合的机制。
首先,在计算网格点heapmaps时,每个网格点使用不同的滤波器组,防止它们之间共用特征以至相互影响。
然后在每个网格点的Heapmap出来后,将相邻网格点的Heapmaps经过卷积滤波与其相加,形成新的heapmap。
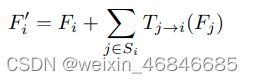
作者将距离特定网格点最近的相邻网格点(1个单位网格长度)组成的网格点集合的特征融合称为一阶特征融合,次近的相邻网格点(2个单位网格长度)组成的网格点集合的特征融合称为二阶特征融合。下图中(a)(b)分别展示了此融合过程。
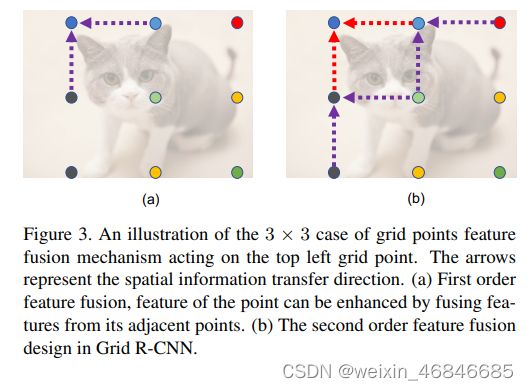
(三)拓展区域映射
这一步主要是为了应对在实际使用中,RPN 给出的 proposal并不总是将完整物体包含在内。如下图:
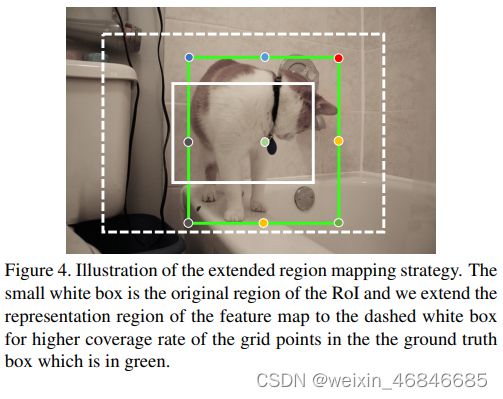
图中白色的实线框表示 RPN 给出的候选框,它没有完全包含所有的网格点。
而作者指出,简单的扩大候选框的大小,不会带来提升,甚至降低对小物体检测的精度(后面有实验验证)。
作者认为heatmap的感受野其实是很大的,并不限于候选框内,所以就干脆直接将heatmap对应的区域看成候选框覆盖的区域两倍大(如图中虚线围起来的区域)。
这么做的好处是,只需简单修改网格引导定位中的位置映射公式。即
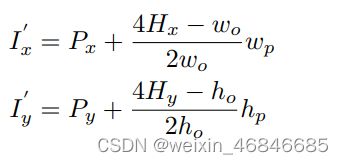
作者首先研究了算法中网格点数对精度的影响。如下表:
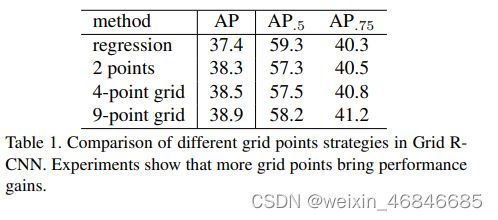
相比回归的方法,Grid R-CNN精度更高,而且随着点数增加精度也在提高。
比较AP0.5和AP0.75发现,精度提升主要来自高IoU阈值的情况。
小结:
该文反思了目标检测中的定位问题,提出以覆盖目标的网格点作为监督信息使用全卷积网络定位网格点的方法,大幅提高了目标定位精度。
3.2.10YOLOv1
YOLO(You Only Look Once) v1是第一个一阶段的深度学习检测算法,是由Joseph Redmon等人在2015年提出。其检测速度非常快,该算法的思想就是将图像划分成多个网格,然后为每一个网格同时预测边界框并给出相应概率。例如某个待检测目标的中心落在图像中所划分的一个单元格内,那么该单元格负责预测该目标位置和类别,论文链接。
YOLO v1检测速度非常快,在VOC-07数据集上的mAP可达52.7%,实现了155 fps的实时性能,其增强版性能也很好(VOC-07 mAP=63.4%, 45 fps, VOC-12 mAP=57.9%),性能要优于DPM和RCNN。
YOLO目标检测的基本流程如下:

(一)将输入图片尺寸Resize为448448(YOLOv1只能输入固定尺寸的图像);
(二)经过单个CNN网络进行特征提取和预测;
(三)通过设定阈值筛选检测框。
目标检测逻辑如下:

YOLO首先将输入图片切成SS个网格:
(1)每个网格预测 B个Bbox(边界框),以及每个边界框的confidence值,confidence表征对应边界框内存在目标的把握,以及框位置、大小的准确度。
每个边界框对应5个参数:x,y,w,h,confidence。其中,
(x,y) 表示边界框中心相对于网格的坐标;
w,h 表示边界框相对于整张图像的宽和高(意思是边界框的中心坐标必须在网格内,但其宽和高不受网格限制、可以随意超过网格大小);
confidence 定义为:当边界框中不存在目标时,confienec应等于0;当边界框中存在目标时,confidence应等于这一边界框和物体的真实边界框的IoU。
(2)每个网格还会预测 C个条件类别概率值,它表示当有目标的中心位置“落入”该网格中时,这一目标属于C个类别的概率分布。
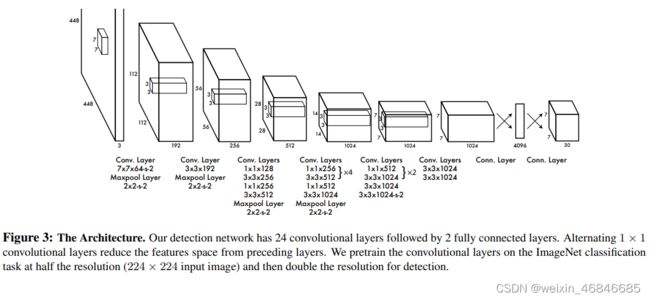
YOLO网络借鉴了GoogleLeNet图像分类模型(也就是Inception v1)。不同的是,YOLO并没有采用Inception模块,而是简单采用11 reduction层后跟33卷积层。标准版YOLO共有24个卷积层后跟2个全连接层(网络结构如下图)。Fast YOLO则只有9个卷积层,其它参数和标准版一致。
小结:
1.不像其它目标检测算法(例如R-CNN)采用region_proposal(回归问题) + classifiers(分类问题)的检测方式, 而是将目标检测当作一个回归(regression) 问题来处理。使用单个网络,输入一整张图像仅经过一次推理可以得到图像中所有目标的检测框和所属类别。 同时可以直接端到端(end-to-end) 地训练和优化网络。
2.算法速度快,使用全图的上下文信息,使得它相比于Fast R-CNN有更少的背景错误(在没有目标的背景区域错误地检测出目标)。泛化能力、通用性更好,面对新领域和意外输入时地表现比R-CNN等更稳定。
3.相比于二阶段的目标检测算法,尽管YOLO v1算法的检测速度有了很大提高,但精度相对教低(尤其是对于一些小目标检测问题)。
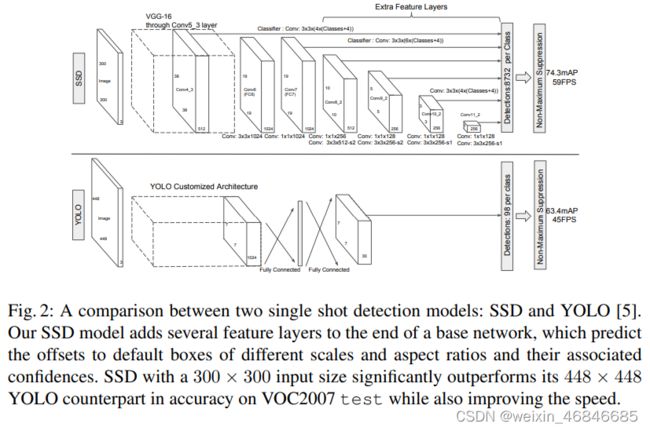
3.2.11SSD
SSD(Single Shot MultiBox Detector)是由Wei Liu等人在2015~2016年提出,SSD算法的主要创新点是提出了Multi-reference和Multi-resolution的检测技术。SSD算法和先前的一些检测算法的区别在于:先前的一些检测算法只是在网络最深层的分支进行检测,而SSD有多个不同的检测分支,不同的检测分支可以检测多个尺度的目标,所以SSD在多尺度目标检测的精度上有了很大的提高,对小目标检测效果要好很多,论文链接。
相比于YOLO v1算法,SSD进一步提高了检测精度和速度(VOC-07 mAP=76.8%, VOC-12 mAP=74.9%, COCO [email protected]=46.5%, mAP@[.5,.95]=26.8%, SSD的精简版速度达到59 fps)。
相比Yolo,SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层之后做检测。其实采用卷积直接做检测只是SSD相比Yolo的其中一个不同点,另外还有两个重要的改变,一是SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;二是SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。YOLO算法缺点是难以检测小目标,而且定位不准,但是这几点重要改进使得SSD在一定程度上克服这些缺点。
SSD和YOLO一样都是采用一个CNN网络来进行检测,但是却采用了多尺度的特征图,其基本架构如下图所示。下面将SSD核心设计理念总结为以下三点:
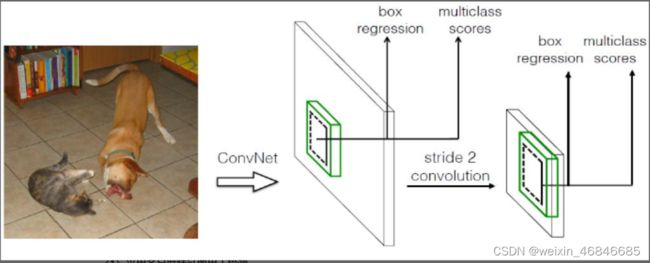
(一)采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,这正如上图所示,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标,如图4所示,8x8的特征图可以划分更多的单元,但是其每个单元的先验框尺度比较小。

(二)采用卷积进行检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。
(三)设置先验框
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异,如图5所示,可以看到每个单元使用了4个不同的先验框,图片中猫和狗分别采用最适合它们形状的先验框来进行训练,后面会详细讲解训练过程中的先验框匹配原则。

SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。
小结:
1.SSD是单阶段模型早期的集大成者,达到跟接近两阶段模型精度的同时,拥有比两阶段模型快一个数量级的速度。后续的单阶段模型工作大多基于SSD改进展开。
2.SSD在Yolo的基础上主要改进了三点:多尺度特征图,利用卷积进行检测,设置先验框。这使得SSD在准确度上比Yolo更好,而且对于小目标检测效果也相对好一点。
2.络中预选框的基础大小和形状需要手工设置。而网络中每一层feature使用的预选框的大小和形状不一样,导致调试过程非常依赖经验。虽然采用了特征金字塔思路,但对小目标的识别效果依然一般,可能因为ssd使用conv4_3低级feature取检测小目标,而低级特征卷积层数少,存在特征提取不充分问题。
3.2.12YOLOv2
YOLOv2是由Joseph Redmon等人在2016年提出,论文中同时还提出了YOLO9000模型,该论文斩获了CVPR 2017 Best Paper Honorable Mention。相比于YOLO v1,YOLO v2在精度、速度和分类数量上都有了很大的改进。在速度上(Faster),YOLO v2使用DarkNet19作为特征提取网络,该网络比SSD所使用的VGG-16要更快。在分类上(Stronger),YOLO v2使用目标分类和检测的联合训练技巧,结合Word Tree等方法,使得YOLO v2的检测种类扩充到了上千种。下图2-2展示了YOLO v2相比于YOLO v1在提高检测精度(Better)上的改进策略,论文链接。
YOLO v2算法在VOC 2007数据集上的表现为67 FPS时,mAP为76.8,在40FPS时,mAP为78.6。
在论文中,作者首先在YOLOv1的基础上提出了改进的YOLOv2,然后提出了一种检测与分类联合训练方法,使用这种联合训练方法在COCO检测数据集和ImageNet分类数据集上训练出了YOLO9000模型,其可以检测超过9000多类物体。所以,这篇文章其实包含两个模型:YOLOv2和YOLO9000,不过后者是在前者基础上提出的,两者模型主体结构是一致的。
下图为YOLOv2与其它模型在VOC 2007数据集上的效果对比:
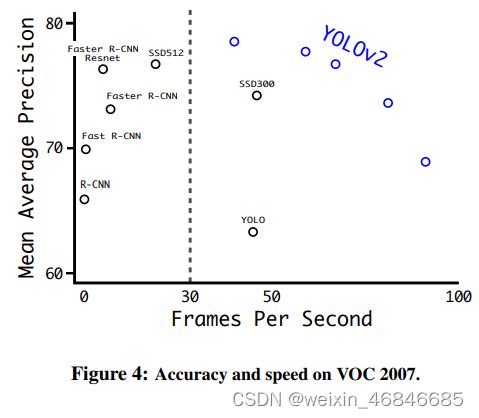
YOLOv1虽然检测速度很快,但是在检测精度上却不如R-CNN系检测方法,YOLOv1在物体定位方面(localization)不够准确,并且召回率(recall)较低。YOLOv2共提出了几种改进策略来提升YOLO模型的定位准确度和召回率,从而提高mAP,YOLOv2在改进中遵循一个原则:保持检测速度,这也是YOLO模型的一大优势。YOLOv2的改进策略如下表所示,可以看出,大部分的改进方法都可以比较显著提升模型的mAP。

下面详细介绍各个改进策略:
(一)Batch Normalization
Batch Normalization可以提升模型收敛速度,而且可以起到一定正则化效果,降低模型的过拟合。在YOLOv2中,每个卷积层后面都添加了Batch Normalization层,并且不再使用droput。使用Batch Normalization后,YOLOv2的mAP提升了2.4%。
(二)High Resolution Classifier
目前大部分的检测模型都会在ImageNet分类数据集上预训练的模型基础上进行微调,由于历史原因,ImageNet分类模型基本采用大小为224×224的图片作为输入,分辨率相对较低,不利于检测模型。所以YOLOv1在采用224×224分类模型预训练后,将分辨率增加至448×448,并使用这个高分辨率在检测数据集上finetune。但是直接切换分辨率,检测模型可能难以快速适应高分辨率。所以YOLOv2增加了在ImageNet数据集上使用448×448输入来finetune分类网络这一中间过程(10 epochs),这可以使得模型在检测数据集上finetune之前已经适用高分辨率输入。使用高分辨率分类器后,YOLOv2的mAP提升了约4%。
(三)Convolutional With Anchor Boxes
在YOLOv1中,输入图片最终被划分为7×7网格,每个单元格预测2个边界框。YOLOv1最后采用的是全连接层直接对边界框进行预测,其中边界框的宽与高是相对整张图片大小的,而由于各个图片中存在不同尺度和长宽比(scales and ratios)的物体,YOLOv1在训练过程中学习适应不同物体的形状是比较困难的,这也导致YOLOv1在精确定位方面表现较差。YOLOv2借鉴了Faster R-CNN中RPN网络的先验框(anchor boxes,prior boxes,SSD也采用了先验框)策略。
(四)Dimension Clusters
在Faster R-CNN和SSD中,先验框的维度(长和宽)都是手动设定的,带有一定的主观性。如果选取的先验框维度比较合适,那么模型更容易学习,从而做出更好的预测。因此,YOLOv2采用k-means聚类方法对训练集中的边界框做了聚类分析。因为设置先验框的主要目的是为了使得预测框与ground truth的IOU更好,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标:
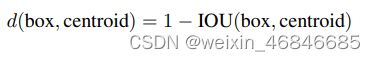
下图为在VOC和COCO数据集上的聚类分析结果,随着聚类中心数目的增加,平均IOU值(各个边界框与聚类中心的IOU的平均值)是增加的,但是综合考虑模型复杂度和召回率,作者最终选取5个聚类中心作为先验框,其相对于图片的大小如右边图所示。
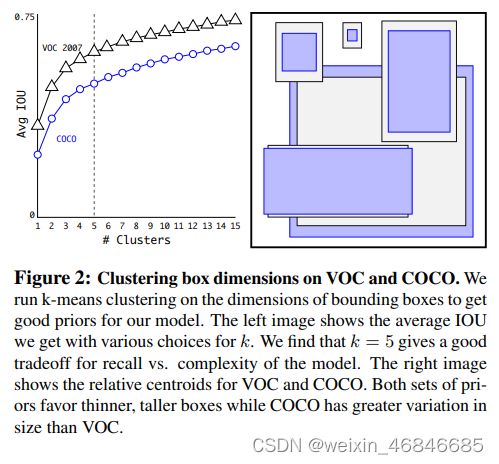
但是这里先验框的大小具体指什么作者并没有说明,但肯定不是像素点,从代码实现上看,应该是相对于预测的特征图大小( 13×13)。对比两个数据集,也可以看到COCO数据集上的物体相对小点。这个策略作者并没有单独做实验,但是作者对比了采用聚类分析得到的先验框与手动设置的先验框在平均IOU上的差异,发现前者的平均IOU值更高,因此模型更容易训练学习。
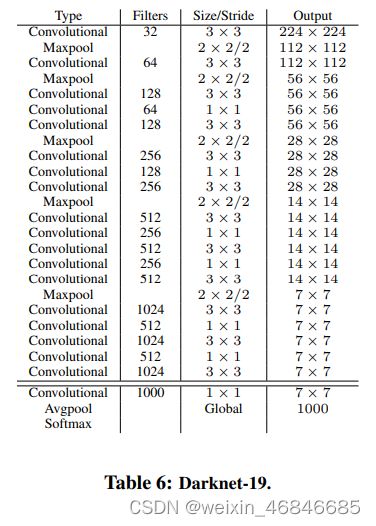
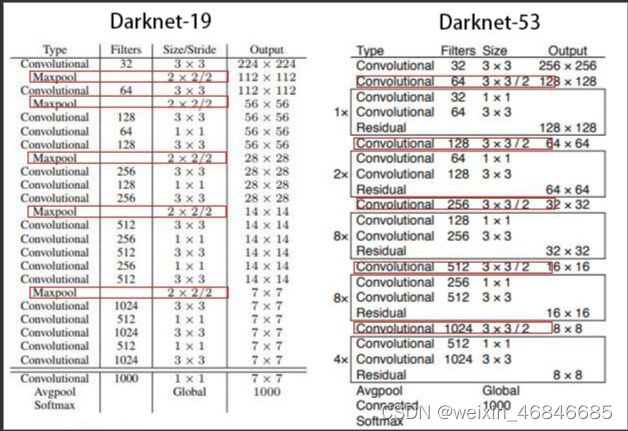
(五)New Network: Darknet-19
YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层,如下图所示。
在ImageNet分类数据集上,Darknet-19的top-1准确度为72.9%,top-5准确度为91.2%,但是模型参数相对小一些。使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33%。
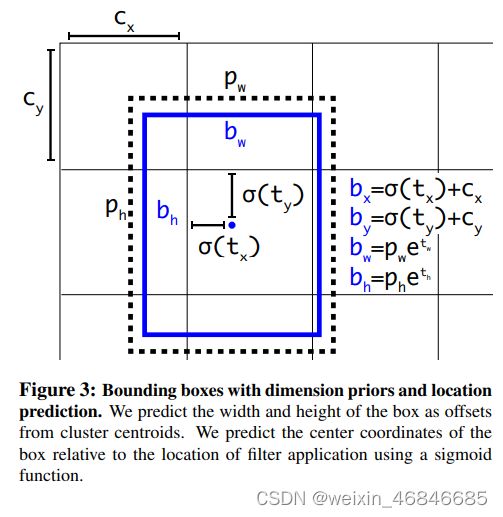
(六)Direct location prediction
计算预测边界框的方法沿用YOLOv1的方法而不是使用RPN的计算方法,约束了边界框的位置预测值使得模型更容易稳定训练,结合聚类分析得到先验框与这种预测方法,YOLOv2的mAP值提升了约5%。
(七)Fine-Grained Features
YOLOv2的输入图片大小为416×416,经过5次maxpooling之后得到13×13大小的特征图,并以此特征图采用卷积做预测。13×13大小的特征图对检测大物体是足够了,但是对于小物体还需要更精细的特征图(Fine-Grained Features)。
YOLOv2提出了一种passthrough层来利用更精细的特征图。YOLOv2所利用的Fine-Grained Features是26×26大小的特征图(最后一个maxpooling层的输入),对于Darknet-19模型来说就是大小为26×26×512的特征图。passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。
另外,作者在后期的实现中借鉴了ResNet网络,不是直接对高分辨特征图处理,而是增加了一个中间卷积层,先采用64个1×1卷积核进行卷积,然后再进行passthrough处理,这样26×26×512的特征图得到13×13×256的特征图。这算是实现上的一个小细节。使用Fine-Grained Features之后YOLOv2的性能有1%的提升。
(八)Multi-Scale Training
由于YOLOv2模型中只有卷积层和池化层,所以YOLOv2的输入可以不限于416×416大小的图片。为了增强模型的鲁棒性,YOLOv2采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的iterations之后改变模型的输入图片大小。
采用Multi-Scale Training策略,YOLOv2可以适应不同大小的图片,并且预测出很好的结果。
小结:
1.总结来看,虽然YOLOv2做了很多改进,但是大部分都是借鉴其它论文的一些技巧,如Faster R-CNN的anchor boxes,YOLOv2采用anchor boxes和卷积做预测,这基本上与SSD模型(单尺度特征图的SSD)非常类似了,而且SSD也是借鉴了Faster R-CNN的RPN网络。从某种意义上来说,YOLOv2和SSD这两个one-stage模型与RPN网络本质上无异,只不过RPN不做类别的预测,只是简单地区分物体与背景。在two-stage方法中,RPN起到的作用是给出region proposals,其实就是作出粗糙的检测,所以另外增加了一个stage,即采用R-CNN网络来进一步提升检测的准确度(包括给出类别预测)。而对于one-stage方法,它们想要一步到位,直接采用“RPN”网络作出精确的预测,要因此要在网络设计上做很多的tricks。YOLOv2的一大创新是采用Multi-Scale Training策略,这样同一个模型其实就可以适应多种大小的图片了。
2.YOLO v2算法只有一条检测分支,且该网络缺乏对多尺度上下文信息的捕获,所以对于不同尺寸的目标检测效果依然较差,尤其是对于小目标检测问题。
3.2.13RetinaNet
RetinaNet是由Facebook AI Research的Tsung-Yi Lin等人在2017年提出,论文分析了一阶段网络训练存在的类别不平衡问题,提出能根据Loss大小自动调节权重的Focal loss,代替了标准的交叉熵损失函数,使得模型的训练更专注于困难样本。同时,基于FPN设计了RetinaNet,在精度和速度上都有不俗的表现,论文链接。
RetinaNet在保持高速推理的同时,拥有与二阶段检测算法相媲美的精度(COCO [email protected]=59.1%, mAP@[.5, .95]=39.1%)。
在RetinaNet之前,目标检测领域普遍以YOLO系列、SSD算法为首的one-stage算法准确率不如以Faster RCNN为代表的two-stage算法。这其中有两类原因:
(一)two-stage算法是先用RPN网络生成一系列Region Proposal的,然后再使用Fast RCNN在Region Proposal的基础上再进行微调,自然结果更为精细。
(二)样本不均衡:正负样本比极度失衡,Faster RCNN明确了训练时正负样本比1:3,而one-stage算法是极度不均衡的(1:1000都是有可能的);梯度被简单样本所主导,复杂样本只占到很小一部分,在Loss计算过程中会被多数的简单样本所主导。
RetinaNet改进如下:
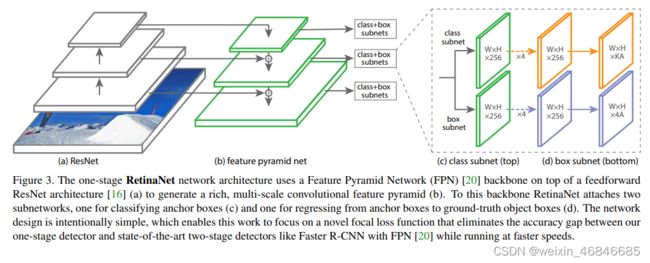
(一)基于FPN设计了RetinaNet
RetinaNet设计改造了FPN,考虑到P2的特征图尺寸是非常大的,非常消耗空间和计算量,FPN中的P2被删掉了,同时在P5的基础上往上再延伸两层,进行两次下采样得到P6和P7层。P3到P7对应了不同的尺度特征,P3更适合小目标的检测,而P7更适合大目标的检测,作者根据尺度特点设计了相应的anchor机制,每个尺度上的每个特征图点对应3个不同大小和3个不同比例的anchor,共9个。
(二)提出Focal loss
正负样本划分如下:
IOU>=0.5, 正样本;
IOU<0.4, 负样本;
IOU∈[0.4, 0.5), 舍弃。
前面提到的,单阶段算法精度不如两阶段算法的样本不均衡原因——正负样本不均衡和难易样本不均衡,就是在Focal Loss部分进行解决的。首先我们看传统的交叉熵Loss函数:
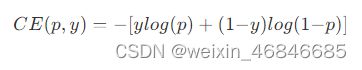
可以改写为如下形式:
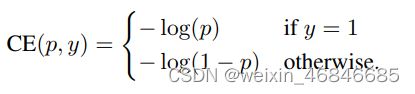
pt定义如下:

那么得出:
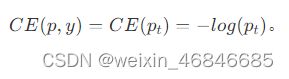
前面既然提到正负样本的不均衡,我们就引入一个正例因子α∈[0, 1],负例因子为1−α,作为权重放在loss上,来平衡正负样本的数量差异:
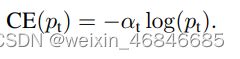
论文中说到,实践中可以考虑将其设置为样本比例的反数,但是作者最终实验得到最好的α是0.25。
为了解决难易样本严重不均衡,导致loss被容易的样本所主导的问题,论文做出了改进,引入权重(1-p_t)γ,其中γ为超参数,这个参数能够降低易分样本的损失贡献,最终focal loss的定义如下:
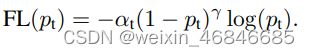
作者实验得到最好的超参数是α=0.25, γ=2。
小结:
1.论文提出,类别不均衡是导致one-stage检测器超越two-stage检测器的主要障碍,并提出 focal loss在交叉熵损失函数中使用一个调节项来聚焦于困难负样本。方法简单有效。通过一个one-stage的FCN检测器在速度和精度同时达到stage-of-the-art。
2.RetinaNet引入的focal loss易受噪声干扰,对图像标注的准确性要求非常高,一旦有标错的样本,就会被focal loss当做困难样本,干扰样本对loss贡献很大,从而影响学习效果。
3.2.14YOLOv3
YOLO v3是由Joseph Redmon等人在2018年提出,相比于YOLO v2,YOLO v3将特征提取网络换成了DarkNet53,对象分类用Logistic取代了Softmax,并借鉴了FPN思想采用三条分支(三个不同尺度/不同感受野的特征图)去检测具有不同尺寸的对象,论文链接。
YOLO v3在VOC数据集,Titan X上处理608×608图像速度达到20FPS,在COCO的测试数据集上[email protected]达到57.9%。其精度比SSD高一些,比Faster RCNN相比略有逊色(几乎持平),比RetinaNet差,但速度是SSD、RetinaNet和Faster RCNN至少2倍以上,而简化后的Yolov3 tiny可以更快。
(一)Darknet-53
在YOLOv2版本时,其主干网络是一个Darknet-19网络,到了YOLOv3版本,主干网络进化为了Darknet-53网络,网络层数更多,同时也引进了更加先进的Resnet残差网络。与Darknet-19网络相比,Darknet-53网络在处理大量图片时整体效率上有所不如,但是准确率上提高了很多,且经证明,在相同准确率下,Darknet-53速度要优于Darknet-19。
(二)特征金字塔(Feature Pyramid Netword, FPN)
YOLO v3使用与SSD目标检测算法类似的方法,对不同深度的特征图分别进行目标检测。但有一点不同的是,当前层的特征图会对未来层的特征图进行上采样,并加以利用。这是一个有跨越性的设计。因为有了这样一个结构,当前的特征图就可以获得“未来”层的信息,这样的话低阶特征与高阶特征就有机融合起来了,提升检测精度。
(三)YOLO v3中的主干网络
将特征金字塔与Darknet-53网络模型相结合,就有了YOLO v3的主干网络。这里需要说明的是,在整个YOLO v3网络中,没有池化层,只有卷积层,通过调节卷积步长控制输出特征图的尺寸。所以对于输入图片尺寸没有特别限制。
以输入416 × 416尺寸的图像为例,在YOLOv3的Darknet-53网络中特征提取过程如下图所示:

从上图中可以到,虚线框内的Darknet-53网络对右侧网络有3个输出,最底下的输出是13×13×1024的特征图,这一输出经过最多层卷积操作,包含更高级、更抽象、视野范围更大的特征,适合尺寸较大的目标检测,在右侧网络中,这一特征图再次经过卷积的特征图从两个方向传递,一个是再次经过3×3和1×1的卷积后输出13×13×75的特征图用于目标检测,另一个是进行上采样改变特征图大小后与Darknet-53网络的第二个输出特征图进行堆叠组成新的特征图,这个新的特征图再次进行卷积,也同样进行两个方向的传递,其中一个方向最终输出26×26×75的特征图用于目标检测中,另一个方向的是进行上采样转变尺寸后与Darknet-53网络第一个输出的特征图进行堆叠后形成新的特征图进行特征提取,最终输出52×52×75的特征图,这一特征图包含了浅层网络提取的特征图对小尺寸目标检测更有一定提升。
在上述过程中,两次用到上采样和特征堆叠,其中上采用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将88的图像变换为1616,注意,上采样层不改变特征图的通道数。而特征堆叠是指的是concat操作,源于DenseNet网络的设计思路,将特征图按照通道维度直接进行拼接,例如8816的特征图与8816的特征图拼接后生成8832的特征图。
(四)输出结果
主干网络产生了3种不同的特征图,这三种特征图将被分别传入logistic层中,进而运算产生模型的输出。不使用softmax是因为softmax对每个框只产生一个分类,在目标检测任务中,存在多个目标物体重合的情况,也就是存在多个分类,softmax就不适用了,所以在YOLO算法中使用了logistic。
有多个输入自然就有多个输出,Yolov3主干网络的3中特征图分别经过logistic层后,也将产生3个输出。在介绍模型输出结果之前,有必要先说说Yolov3中应用到的另一种思想——分而治之。
目标检测任务极具挑战性的一个很大原因是因为原始图像中可能包含的目标物体大小不确定。对于这一难题,YOLO v3算法的解决思路时将原始图像使用不同的粒度进行划分网格,例如划分为13×13、26×26、52×52的网格。13×13的大网格用于检测大的目标物体,26×26的网格用于检测中等的目标物体,52×52的网格用于检测小目标物体。这是与主干网络输出的3种特征图的大小是一一对应的。在logistic层的输出结果中,对每个划分单元格都有一个对应的向量来描述目标检测的结果,即在该单元格是否有物体、物体的位置、物体的分类。
(五)非极大值抑制
每个网格将会输出3个预测框,所以一张原始图像经过Yolov3网络后将产生的预测框数量为:3×13×13 + 3×26×26 + 3×52×52 = 10647个预测框。
在Yolov3模型中,作者引入了非极大值抑制法(Non-Maximum Suppression,NMS)来解决这一问题。
先对所有留下的预测框,根据分类器的类别分类概率做排序,假设从小到大依次为:A、D、B、F、E、C。
(1)从最大概率预测框A开始,分别判断D、C与A的重叠度IOU是否大于某个设定的阈值;
(2)明显,B、C与A的重叠度比较大,假设超过阈值,那么就扔掉B、C;并标记第一个矩形框A,是我们保留下来的。
(3)从剩下的预测框D、E、F中,选择概率最大的D,然后判断D与E、F的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的预测框。最终,保留下来的预测框为A和D。这就是非极大值抑制法。
小结:
1.YOLO v3改进了v1和v2的缺点,是速度和精度最均衡的目标检测网络,重点解决了小物体检测的问题。背景误检率低,通用性强。
2.YOLO v3采用MSE作为边框回归损失函数,这使得YOLO v3对目标的定位并不精准,之后出现的IOU,GIOU,DIOU和CIOU等一系列边框回归损失大大改善了YOLO v3对目标的定位精度。
3.2.15YOLOv4
YOLOv4是由Alexey Bochkovskiy等人在2020年提出,相比于YOLO v3,YOLO v4在输入端,引入了Mosaic数据增强、cmBN、SAT自对抗训练;在特征提取网络上,YOLO v4将各种新的方式结合起来,包括CSPDarknet53,Mish激活函数,Dropblock;在检测头中,引入了SPP模块,借鉴了FPN+PAN结构;在预测阶段,采用了CIOU作为网络的边界框损失函数,同时将NMS换成了DIOU_NMS等等。总体来说,YOLO v4具有极大的工程意义,将近年来深度学习领域最新研究的tricks都引入到了YOLO v4做验证测试,在YOLO v3的基础上更进一大步,论文链接。
YOLO v4在COCO数据集上达到了43.5%AP(65.7% AP50),在Tesla V100显卡上实现了65 fps的实时性能,下图展示了在COCO检测数据集上YOLO v4和其它SOTA检测算法的性能对比。

从本质上,YOLO V4就是筛选了一些从YOLO V3发布至今,被用在各式各样检测器上,能够提高检测精度的tricks,并以YOLO V3为基础进行改进的目标检测模型。YOLO V4在保证速度的同时,大幅提高模型的检测精度(相较于YOLO V3)。
YOLO V4提高检测精度细节如下图:

YOLO V3对比,主要做了以下改变:
相较于YOLO V3的DarkNet53,YOLO V4用了CSPDarkNet53;
相较于YOLO V3的FPN,YOLO V4用了SPP+PAN;
CutMix数据增强和马赛克(Mosaic)数据增强;
DropBlock正则化;
等等。
(一)网络结构
下图总结了近些年的目标检测检测器的优化改进手段的方向结构组成,同时对几个重要改进的部分列出了改进的方法,如下:
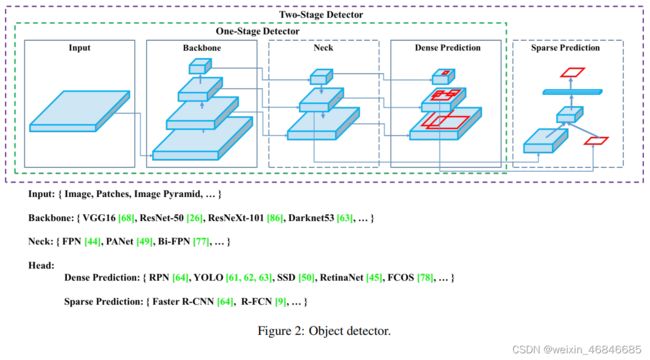
Input部分:Image,Patches,Images Pyramid(图像金字塔)。
Backbone部分:VGG16,ResNet-50,SpineNet,EfficientNet-B0 / B7,CSPResNeXt50,CSPDarknet53。
neck部分:
Additional blocks:SPP,ASPP,RFB,SAM;
Path-aggregation blocks:FPN,PAN,NAS-FPN,Fully-connected FPN,BiFPN,ASFF,SFAM。
Heads部分:
Dense Predictions(one-stage):
RPN,SSD,YOLO,RetinaNet (基于anchor);
CornerNet,CenterNet,MatrixNet,FCOS(无anchor)。
Sparse Predictions(two-stages):
Faster R-CNN,R-FCN,Mask R-CNN(基于anchor);
RepPoints(无anchor)。
目前做检测器MAP指标的提升,都会考虑选择一个图像特征提取能力较强的backbone,且不能太大,那样影响检测的速度。YOLO V4中,则是选择了具有CSP(Cross-stage partial connections)的darknet53,而是没有选择在imagenet上跑分更高的CSPResNext50,如论文中所说:结合了在目标检测领域的精度来说,CSPDarknet53是要强于 CSPResNext50。这也告诉了我们,在图像分类上任务表现好的模型,不一定很适用于目标检测。
目标检测模型的Neck部分主要用来融合不同尺寸特征图的特征信息。常见的有MaskRCNN中使用的FPN等,本文中的YOLO V4就是用到了SPP(Spatial pyramid pooling)+PAN(Path Aggregation Network)。
(二)算法知识点相关释义
①BoF(bag of freebies)
在文中是指那些能够提高精度而不增加推断时间的技术。
比如数据增广的方法:图像几何变换、Cutout、grid mask等;
网络正则化的方法:Dropout、Dropblock等;
类别不平衡的处理方法;
难例挖掘方法;
损失函数的设计等。
②BoS(bag of specials)
是指那些增加稍许推断代价,但可以提高模型精度的方法。
比如增大模型感受野的SPP、ASPP、RFB等;
引入注意力机制Squeeze-and-Excitation (SE) 、Spatial Attention Module (SAM)等;
特征集成方法SFAM , ASFF , BiFPN等;
改进的激活函数Swish、Mish等;
或者是后处理方法如soft NMS、DIoU NMS等。
③在目标检测训练中,通常对CNN的优化改进方法:
激活函数:ReLU,leaky-ReLU,parameter-ReLU,ReLU6,SELU,Swish或Mish;
bbox回归loss函数:MSE,IoU,GIoU,CIoU,DIoU;
数据增强:CutOut,MixUp,CutMix;
正则化方法:DropOut,DropPath,Spatial DropOut或DropBlock;
通过均值和方差对网络激活进行归一化:Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN), orCross-Iteration Batch Normalization (CBN);
跨连接:Residual connections, Weightedresidual connections, Multi-input weighted residualconnections, or Cross stage partial connections (CSP)。
④关于CmBN
BN是对当前mini-batch进行归一化。CBN是对当前以及当前往前数3个mini-batch的结果进行归一化,本文提出的CmBN则是仅仅在这个Batch中进行累积。在消融实验中,CmBN要比BN高出不到一个百分点。

⑤关于SAM
Attention机制中的CBAM, CBAM含有空间注意力机制和通道注意力机制,SAM就是其中的空间注意力机制。
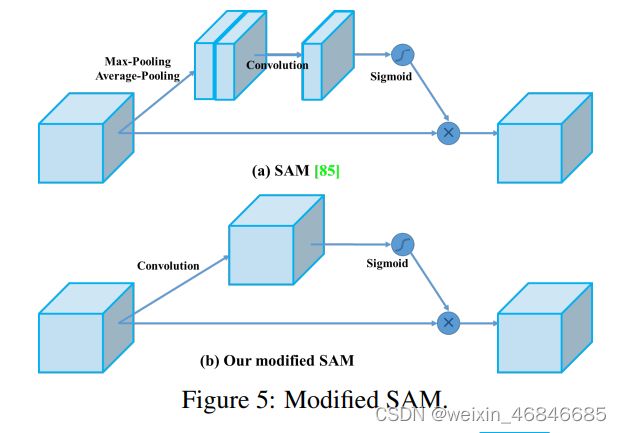
⑥PANet
PANet融合的时候使用的方法是Addition,详解需阅读CVPR 2018 PANet,YOLOv4算法将融合的方法由add变为concat。

小结:
YOLOv4中对Bag of freebies和Bag of Specials两部分进行的总结,对研究目标检测有很大的参考价值,涵盖的trick非常广泛。整体架构方面换上了更好的backbone: CSDarknet53,将原来的FPN换成了PANet中的FPN。训练过程引入了很多特性如:Weighted Residual Connections、CmBN、Self-adversarial-training、Mosaic data augmentation、DropBlock、CIOU loss等。
3.2.16YOLOv5
YOLO V5仅有源代码,但没有论文。与YOLO V4有点相似,都大量整合了计算机视觉领域的State-of-the-art,从而显著改善了YOLO对目标的检测性能。相比于YOLO V4,YOLO V5在性能上稍微逊色,但其灵活性与速度上远强于YOLO V4,而且在模型的快速部署上也具有极强优势,代码链接。
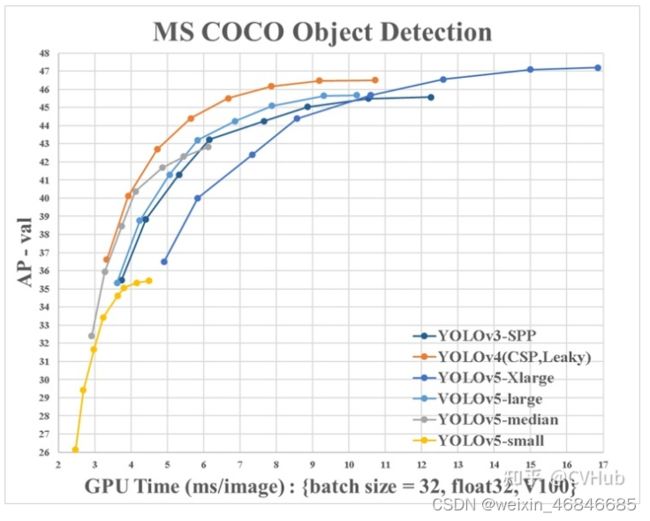
如下图展示了在COCO检测数据集上YOLO v5和其它SOTA检测算法的性能对比。
YOLOv5网络结构图如下:
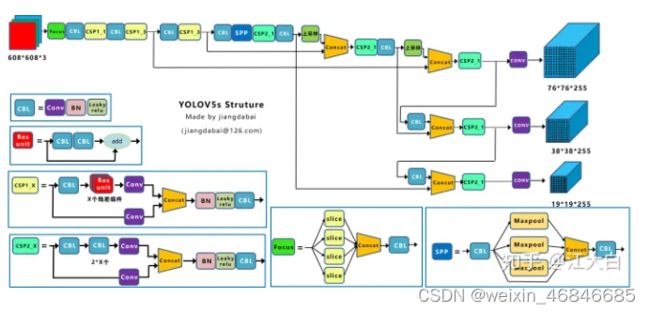
网络结构分为输入端、Backbone、Neck、Prediction四个部分:
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放;
(2)Backbone:Focus结构,CSP结构;
(3)Neck:FPN+PAN结构;
(4)Prediction:GIOU_Loss。
(一)输入端
(1)Mosaic数据增强
YOLOv5的输入端采用了和YOLOv4一样的Mosaic数据增强的方式。
Mosaic数据增强提出的作者也是来自Yolov5团队的成员,不过,随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果还是很不错的。
(2)自适应锚框计算
在YOLO算法中,针对不同的数据集,都会有初始设定长宽的锚框。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框ground truth进行比对,计算两者差距,再反向更新,迭代网络参数。
在YOLOv3、YOLOv4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但YOLOv5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
(3)自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。比如YOLO算法中常用416×416,608×608等尺寸。但YOLOv5代码中对此进行了改进,也是YOLOv5推理速度能够很快的一个不错的trick。
作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。因此在YOLOv5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
在讨论中,通过这种简单的改进,推理速度得到了37%的提升,可以说效果很明显。
(二)Backbone
(1)Focus结构
Focus结构,在YOLOv3&YOLOv4中并没有这个结构,其中比较关键是切片操作。比如右图的切片示意图,4×4×3的图像切片后变成2×2×12的特征图。

(2)CSP结构
YOLOv4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。
YOLOv5与YOLOv4不同点在于,YOLOv4中只有主干网络使用了CSP结构。
而YOLOv5中设计了两种CSP结构,以YOLOv5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。

(三)Neck
YOLOv5现在的Neck和YOLOv4中一样,都采用FPN+PAN的结构,但在YOLOv5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。
(四)输出端
(1)Bounding box损失函数
YOLOv5中采用CIOU_Loss做Bounding box的损失函数。
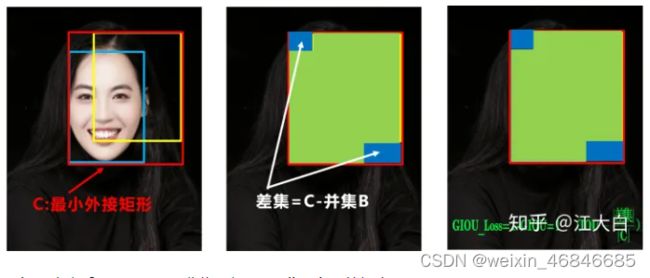
(2)nms非极大值抑制
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。因为CIOU_Loss中包含影响因子v,涉及groud truth的信息,而测试推理时,是没有ground truth的。
所以YOLOv4在DIOU_Loss的基础上采用DIOU_nms的方式,而YOLOv5中采用加权nms的方式。可以看出,采用DIOU_nms,下方中间箭头的黄色部分,原本被遮挡的摩托车也可以检出。

小结:
YOLO V5优点如下:
(1)使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集,相对于YOLO V4采用的Darknet框架,Pytorch框架更容易投入生产;
(2)代码易读,整合了大量的计算机视觉技术,非常有利于学习和借鉴;
(3)不仅易于配置环境,模型训练也非常快速,并且批处理推理产生实时结果;
(4)能够直接对单个图像,批处理图像,视频甚至网络摄像头端口输入进行有效推理;
(5)能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,然后可以转换为OPENCV的使用格式,或者通过CoreML转化为IOS格式,直接部署到手机应用端;
(6)最后YOLO V5s高达140FPS的对象识别速度令人印象非常深刻,使用体验非常棒。
参考文档
综述:目标检测二十年(2001-2021)
干货 | 目标检测入门,看这篇就够了(已更完)
52 个深度学习目标检测模型汇总,论文、源码一应俱全!(附链接)
deep learning object detection
RCNN- 将CNN引入目标检测的开山之作
【目标检测】SPPnet论文详解(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
Fast RCNN算法详解
Faster-rcnn详解
一文详解R-CNN、Fast R-CNN、Faster R-CNN
Mask R-CNN详解
Mask R-CNN 论文详解
FPN详解
薰风读论文:Feature Pyramid Network 详解特征金字塔网络FPN的来龙去脉
【论文笔记】FPN —— 特征金字塔
Cascade R-CNN 详细解读
深度学习之 Cascade R-CNN
Libra R-CNN——“平衡学习”
【论文笔记2019-04-10】Libra R-CNN: Towards Balanced Learning for Object Detection
Libra R-CNN论文与代码解读
Grid R-CNN论文详解
Grid R-CNN解读:商汤最新目标检测算法
【目标检测】YOLO系列——YOLOv1详解
目标检测|SSD原理与实现
目标检测|YOLOv2原理与实现(附YOLOv3)
RETINANET论文最全解析!一文读懂!
【目标检测(十)】RetinaNet详解——Focal Loss将one-stage算法推向巅峰
Yolov3算法详解
YOLO V4 — 网络结构和损失函数解析(超级详细!)
一文了解YOLO-v4目标检测
深入浅出Yolo系列之Yolov5核心基础知识完整讲解