大数据FLINK实时数仓项目实战
一、FLINK实时数仓项目简介
1、普通实时计算与实时数仓比较
普通的实时计算优先考虑时效性,所以从数据源采集经过实时计算直接得到结果。如此做时效性更好,但是弊端是由于计算过程中的中间结果没有沉淀下来,所以当面对大量实时需求的时候,计算的复用性较差,开发成本随着需求增加直线上升。

实时数仓基于一定的数据仓库理念,对数据处理流程进行规划、分层,目的是提高数据的复用性。
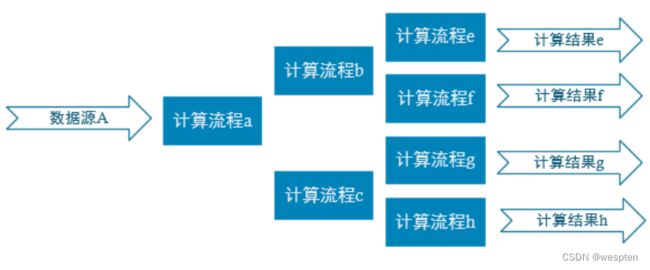
2、实时数仓项目分层
- ODS
原始数据,日志和业务数据 。
- DWD
根据数据对象为单位进行分流,比如订单、页面访问等等。
- DIM
维度数据。
- DWM
对于部分数据对象进行进一步加工,比如独立访问、跳出行为,也可以和维度进行关联,形成宽表,依旧是明细数据。
- DWS
根据某个主题将多个事实数据轻度聚合,形成主题宽表。
- ADS
把Clickhouse中的数据根据可视化需要进行筛选聚合。
3、实时需求概览
1)离线计算与实时计算的比较
离线计算:就是在计算开始前已知所有输入数据,输入数据不会产生变化,一般计算量级较大,计算时间也较长。例如今天早上一点,把昨天累积的日志,计算出所需结果。最经典的就是Hadoop的MapReduce方式。
一般是根据前一日的数据生成报表,虽然统计指标、报表繁多,但是对时效性不敏感。从技术操作的角度,这部分属于批处理的操作。即根据确定范围的数据一次性计算。
实时计算:输入数据是可以以序列化的方式一个个输入并进行处理的,也就是说在开始的时候并不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量级相对较小。强调计算过程的时间要短,即所查当下给出结果。
主要侧重于对当日数据的实时监控,通常业务逻辑相对离线需求简单一下,统计指标也少一些,但是更注重数据的时效性,以及用户的交互性。从技术操作的角度,这部分属于流处理的操作。根据数据源源不断地到达进行实时的运算。
2)实时需求种类
(1)日常统计报表或分析图中需要包含当日部分
对于日常企业、网站的运营管理如果仅仅依靠离线计算,数据的时效性往往无法满足。通过实时计算获得当日、分钟级、秒级甚至亚秒的数据更加便于企业对业务进行快速反应与调整。
所以实时计算结果往往要与离线数据进行合并或者对比展示在BI或者统计平台中。
(2)实时数据大屏监控

数据大屏,相对于BI工具或者数据分析平台是更加直观的数据可视化方式。尤其是一些大促活动,已经成为必备的一种营销手段。
另外还有一些特殊行业,比如交通、电信的行业,那么大屏监控几乎是必备的监控手段。
(3)数据预警或提示
经过大数据实时计算得到的一些风控预警、营销信息提示,能够快速让风控或营销部分得到信息,以便采取各种应对。
比如,用户在电商、金融平台中正在进行一些非法或欺诈类操作,那么大数据实时计算可以快速的将情况筛选出来发送风控部门进行处理,甚至自动屏蔽。 或者检测到用户的行为对于某些商品具有较强的购买意愿,那么可以把这些“商机”推送给客服部门,让客服进行主动的跟进。
(4)实时推荐系统
实时推荐就是根据用户的自身属性结合当前的访问行为,经过实时的推荐算法计算,从而将用户可能喜欢的商品、新闻、视频等推送给用户。
这种系统一般是由一个用户画像批处理加一个用户行为分析的流处理组合而成。
4、统计架构分析
1)离线架构
2)实时架构

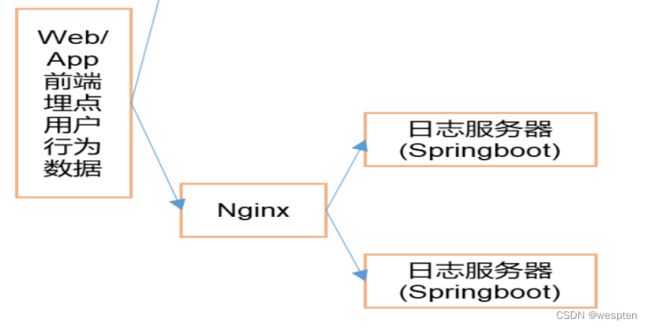
二、日志数据采集
1、模拟日志生成器的使用
这里提供了一个模拟生成数据的jar包,可以将日志发送给某一个指定的端口,需要大数据程序员了解如何从指定端口接收数据并数据进行处理的流程。
链接:百度网盘 请输入提取码
提取码:pjfb
拷贝行为数据的内容到hadoop202的/opt/module/rt_applog目录,根据实际需要修改application.yml:

使用模拟日志生成器的jar运行:
java -jar gmall2020-mock-log-2020-12-18.jar目前我们还没有地址接收日志,所以程序运行后的结果有如下错误:

注意:ZooKeeper从3.5开始,AdminServer的端口也是8080,如果在本机启动了zk,那么可能看到405错误,意思是找到请求地址了,但是接收的方式不对。
2、日志采集模块-本地测试
1)Springboot简介
Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化新 Spring 应用的初始搭建以及开发过程。 该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。
有了springboot 我们就可以不再需要那些千篇一律,繁琐的xml文件。
- 内嵌Tomcat,不再需要外部的Tomcat。
- 更方便的和各个第三方工具(mysql、redis、elasticsearch、dubbo、kafka等等整合),而只要维护一个配置文件即可。
springboot和ssm的关系:
springboot整合了springmvc ,spring等核心功能。也就是说本质上实现功能的还是原有的spring ,springmvc的包,但是springboot单独包装了一层,这样用户就不必直接对springmvc, spring等,在xml中配置。
没有xml,我们要去哪配置:
springboot实际上就是把以前需要用户手工配置的部分,全部作为默认项。除非用户需要额外更改不然不用配置。这就是所谓的:“约定大于配置”。
如果需要特别配置的时候,去修改application.properties (application.yml)。
2)快速搭建SpringBoot程序gmall2021-logger,采集模拟生成的日志数据
在IDEA中安装lombok插件:
在Plugins下搜索lombok然后在线安装即可,安装后注意重启。

创建空的父工程gmall2021-parent,用于管理后续所有的模块module。
我们这里就是为了将各个模块放在一起,但是模块彼此间还是独立的,所以创建一个Empty Project即可;如果要是由父module管理子module,需要将父module的pom.xml文件的

新建SpringBoot模块,作为采集日志服务器:
在父project下增加一个Module,选择Spring Initializr 。

注意:有时候SpringBoot官方脚手架不稳定,我们切换国内地址:https://start.aliyun.com

配置项目名称为gmall2021-logger及JDK版本。
选择版本以及通过勾选自动添加lombok、SpringWeb、Kafka相关依赖:
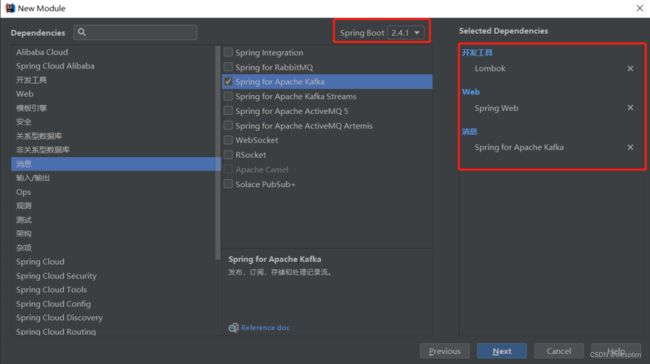
注意:这里如果使用spring官方脚手架地址,看到的页面可能会略有差异,但效果相同。
完成之后开始下载依赖,完整的pom.xml文件如下:
4.0.0
com.yyds.gmall
gmall2021-logger
0.0.1-SNAPSHOT
gmall2021-logger
Demo project for Spring Boot
1.8
UTF-8
UTF-8
2.4.1
org.springframework.boot
spring-boot-starter-web
org.springframework.kafka
spring-kafka
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.springframework.kafka
spring-kafka-test
test
org.springframework.boot
spring-boot-dependencies
${spring-boot.version}
pom
import
org.apache.maven.plugins
maven-compiler-plugin
3.8.1
1.8
1.8
UTF-8
org.springframework.boot
spring-boot-maven-plugin
2.4.1
com.yyds.gmall.Gmall2021LoggerApplication
repackage
repackage
创建FirstController输出SpringBoot处理流程:
package com.yyds.gmall.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* Author: Felix
* Desc: 熟悉SpringBoot处理流程
*/
//标识为controller组件,交给Sprint容器管理,并接收处理请求 如果返回String,会当作网页进行跳转
//@Controller
//RestController = @Controller + @ResponseBody 会将返回结果转换为json进行响应
@RestController
public class FirstController {
//通过requestMapping匹配请求并交给方法处理
@RequestMapping("/testDemo")
public String test(@RequestParam("name") String nn,
@RequestParam("age") int age) {
System.out.println(nn + ":" + age);
return "success";
}
}运行Gmall2021LoggerApplication,启动内嵌Tomcat:
![]()
用浏览器测试并查看控制台输出:

3)采集模拟埋点数据,并进行处理
在LoggerController中添加方法,将日志打印、落盘并发送到Kafka主题中:
package com.yyds.gmall.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* Author: Felix
* Desc: 熟悉SpringBoot处理流程
*/
//标识为controller组件,交给Sprint容器管理,并接收处理请求 如果返回String,会当作网页进行跳转
//@Controller
//RestController = @Controller + @ResponseBody 会将返回结果转换为json进行响应
@RestController
@Slf4j
public class LoggerController {
@Autowired
private KafkaTemplate kafkaTemplate;
@RequestMapping("/applog")
public String getLogger(@RequestParam("param") String jsonStr) {
//将数据落盘
log.info(jsonStr);
//将数据发送至Kafka ODS主题
kafkaTemplate.send("ods_base_log", jsonStr);
return "success";
}
} 在resources中添加logback.xml配置文件:
%msg%n
${LOG_HOME}/app.log
${LOG_HOME}/app.%d{yyyy-MM-dd}.log
%msg%n
logback配置文件说明:
- appender
追加器,描述如何写入到文件中(写在哪,格式,文件的切分)。
ConsoleAppender--追加到控制台。
RollingFileAppender--滚动追加到文件。
- logger
控制器,描述如何选择追加器。
注意:要是单独为某个类指定的时候,别忘了修改类的全限定名。
- 日志级别
TRACE [DEBUG INFO WARN ERROR] FATAL修改SpringBoot核心配置文件application.propeties:
#指定使用的端口号
server.port=8081
#============== kafka ===================
# 指定kafka 代理地址,可以多个
spring.kafka.bootstrap-servers=hadoop102:9092
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer修改hadoop202上的rt_applog目录下的application.yml配置文件:

4)测试
- 运行Windows上的Idea程序LoggerApplication
- 运行rt_applog下的jar包
- 启动kafka消费者进行测试
bin/kafka-console-consumer.sh --bootstrap-server hadoop202:9092 --topic ods_base_log3、日志采集模块-打包单机部署
修改gmall2020-logger中的logback.xml配置文件:
注意:路径和上面创建的路径保持一致,根据自己的实际情况进行修改。
打包:

问题解决:
- 打包时候如果出现以下问题
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.22.2:test (default-test)在pom.xml文件中,添加跳过测试:
1.8
true
- springboot打包错误:Failed to execute goal org.apache.maven.plugins:maven-resources-plugin
原因是打包版本不兼容,可以通过加入如下插件修改版本解决:
org.apache.maven.plugins
maven-resources-plugin
2.4.3
将打好的jar包上传到hadoop202的/opt/module/rt_gmall目录下:
[yyds@hadoop202 rt_gmall]$ ll
总用量 29984
-rw-rw-r--. 1 yyds yyds 30700347 8月 10 11:35 gmall2021-logger-0.0.1-SNAPSHOT.jar修改/opt/module/rt_applog/application.yml:
#http模式下,发送的地址
mock.url=http://hadoop202:8081/applog测试:
- 运行hadoop202上的rt_gmall下的日志处理jar包
- 运行rt_applog下的jar包
- 启动kafka消费者进行测试
bin/kafka-console-consumer.sh --bootstrap-server hadoop202:9092 --topic ods_base_log4、日志采集模块-打包集群部署,并用Nginx进行反向代理
根据附录内容搭建好Nginx环境,修改nginx.conf配置文件:
在server内部配置
location /applog{
proxy_pass http://www.logserver.com;
}
在server外部配置反向代理
upstream www.logserver.com{
server hadoop202:8081 weight=1;
server hadoop203:8081 weight=2;
server hadoop204:8081 weight=3;
}注意:每行配置完毕后有分号。
将日志采集的jar包同步到hadoop203和hadoop204:
[yyds@hadoop202 module]$ xsync rt_gmall/修改模拟日志生成的配置:
发送到的服务器路径修改为nginx的。
[yyds@hadoop202 rt_applog]$ vim application.yml
# 外部配置打开
#logging.config=./logback.xml
#业务日期
mock.date=2020-07-13
#模拟数据发送模式
mock.type=http
#http模式下,发送的地址
mock.url=http://hadoop202/applog测试:
- 运行kafka消费者,准备消费数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop202:9092 --topic ods_base_log- 启动nginx服务
/opt/module/nginx/sbin/nginx- 运行采集数据的jar
[yyds@hadoop202 rt_gmall]$ java -jar gmall2021-logger-0.0.1-SNAPSHOT.jar
[yyds@hadoop203 rt_gmall]$ java -jar gmall2021-logger-0.0.1-SNAPSHOT.jar
[yyds@hadoop204 rt_gmall]$ java -jar gmall2021-logger-0.0.1-SNAPSHOT.jar- 运行模拟生成数据的jar
[yyds@hadoop202 rt_applog]$ java -jar gmall2020-mock-log-2020-12-18.jar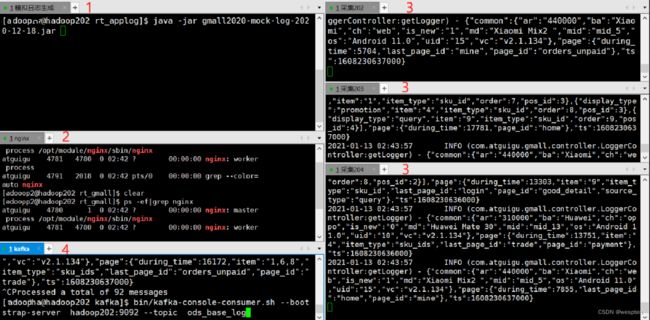
注意:图片中红色标记表示的程序的执行顺序,要理解。
集群群起脚本:
将采集日志服务(nginx和采集日志数据的jar启动服务)放到脚本中。
在/home/yyds/bin目录下创建logger.sh,并授予执行权限:
#!/bin/bash
JAVA_BIN=/opt/module/jdk1.8.0_212/bin/java
APPNAME=gmall2020-logger-0.0.1-SNAPSHOT.jar
case $1 in
"start")
{
for i in hadoop202 hadoop203 hadoop204
do
echo "========: $i==============="
ssh $i "$JAVA_BIN -Xms32m -Xmx64m -jar /opt/module/rt_gmall/$APPNAME >/dev/null 2>&1 &"
done
echo "========NGINX==============="
/opt/module/nginx/sbin/nginx
};;
"stop")
{
echo "======== NGINX==============="
/opt/module/nginx/sbin/nginx -s stop
for i in hadoop202 hadoop203 hadoop204
do
echo "========: $i==============="
ssh $i "ps -ef|grep $APPNAME |grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1
done
};;
esac - 运行kafka消费者,准备消费数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop202:9092 --topic ods_base_log- 启动nginx服务采集服务集群
logger.sh start- 运行模拟生成数据的jar
[yyds@hadoop202 rt_applog]$ java -jar gmall2020-mock-log-2020-12-18.jar
三、业务数据库数据采集
1、Maxwell
Maxwell 是由美国Zendesk开源,用Java编写的MySQL实时抓取软件。 实时读取MySQL二进制日志Binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。
官网地址:Maxwell's Daemon
1)Maxwell工作原理
MySQL主从复制过程:
- Master主库将改变记录,写到二进制日志(binary log)中
- Slave从库向mysql master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log);
- Slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。
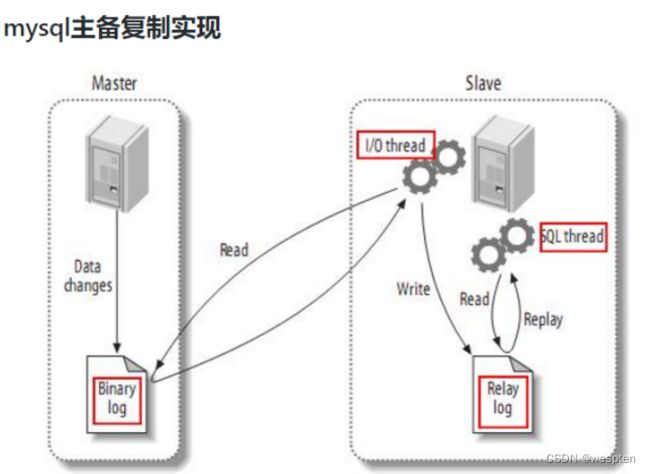
很简单,就是把自己伪装成slave,假装从master复制数据。
2)MySQL的binlog
(1)什么是binlog
MySQL的二进制日志可以说MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有1%的性能损耗。二进制有两个最重要的使用场景:
- 其一:MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
- 其二:自然就是数据恢复了,通过使用mysqlbinlog工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
(2)binlog的开启
找到MySQL配置文件的位置
- Linux: /etc/my.cnf
如果/etc目录下没有,可以通过locate my.cnf查找位置
- Windows: \my.ini
- 在mysql的配置文件下,修改配置
在[mysqld] 区块,设置/添加 log-bin=mysql-bin这个表示binlog日志的前缀是mysql-bin,以后生成的日志文件就是 mysql-bin.123456 的文件后面的数字按顺序生成,每次mysql重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号。
(3)binlog的分类设置
mysql binlog的格式有三种,分别是STATEMENT,MIXED,ROW。
在配置文件中可以选择配置:
binlog_format= statement|mixed|row三种格式的区别:
- statement
语句级,binlog会记录每次一执行写操作的语句。
相对row模式节省空间,但是可能产生不一致性,比如:
update tt set create_date=now()如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点: 节省空间。
缺点: 有可能造成数据不一致。
- row
行级, binlog会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
缺点:占用较大空间。
- mixed
statement的升级版,一定程度上解决了,因为一些情况而造成的statement模式不一致问题。
默认还是statement,在某些情况下譬如:
当函数中包含 UUID() 时;
包含 AUTO_INCREMENT 字段的表被更新时;
执行 INSERT DELAYED 语句时;
用 UDF 时;
会按照 ROW的方式进行处理。
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便。
综合上面对比,Maxwell想做监控分析,选择row格式比较合适。
2、MySQL的准备
创建实时业务数据库:
导入建表数据:
资源已上传。

修改/etc/my.cnf文件:
[yyds@hadoop202 module]$ sudo vim /etc/my.cnf
server-id= 1
log-bin=mysql-bin
binlog_format=row
binlog-do-db=gmall2020注意:binlog-do-db根据自己的情况进行修改,指定具体要同步的数据库。
重启MySQL使配置生效:
sudo systemctl restart mysqld到/var/lib/mysql目录下查看初始文件大小154

模拟生成数据:
- 业务数据里面的jar和properties文件上传到/opt/module/rt_dblog目录下;
- 修改application.properties中数据库连接信息;

注意:如果生成较慢,可根据配置情况适当调整配置项。
- 运行jar包
[yyds@hadoop202 rt_dblog]$ java -jar gmall2020-mock-db-2020-11-27.jar
- 再次到到/var/lib/mysql目录下,查看index文件的大小
3、安装与初始化Maxwell元数据库
- maxwell-1.25.0.tar.gz上传到/opt/software目录下(资料已上传);
- 解压maxwell-1.25.0.tar.gz到/opt/module目录;
[yyds@hadoop202 module]$ tar -zxvf /opt/software/maxwell-1.25.0.tar.gz -C /opt/module/初始化Maxwell元数据库:
- 在MySQL中建立一个maxwell库用于存储Maxwell的元数据
[yyds@hadoop202 module]$ mysql -uroot -p123456
mysql> CREATE DATABASE maxwell ;- 设置安全级别
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;- 分配一个账号可以操作该数据库
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%' IDENTIFIED BY '123456';- 分配这个账号可以监控其他数据库的权限
mysql> GRANT SELECT ,REPLICATION SLAVE , REPLICATION CLIENT ON *.* TO maxwell@'%';4、使用Maxwell监控抓取MySQL数据
- 拷贝配置文件
[yyds@hadoop202 maxwell-1.25.0]$ cp config.properties.example config.properties- 修改配置文件
producer=kafka
kafka.bootstrap.servers=hadoop202:9092,hadoop203:9092,hadoop204:9092
#需要添加
kafka_topic=ods_base_db_m
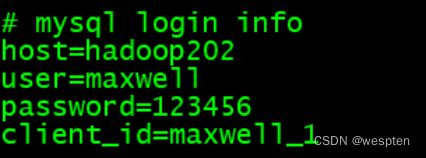
# mysql login info
host=hadoop202
user=maxwell
password=123456
#需要添加 后续初始化会用
client_id=maxwell_1注意:默认还是输出到指定Kafka主题的一个kafka分区,因为多个分区并行可能会打乱binlog的顺序。
如果要提高并行度,首先设置kafka的分区数>1,然后设置producer_partition_by属性。
可选值:
producer_partition_by=database|table|primary_key|random| column- 在/home/yyds/bin目录下编写maxwell.sh启动脚本
[yyds@hadoop202 maxwell-1.25.0]$ vim /home/yyds/bin/maxwell.sh
/opt/module/maxwell-1.25.0/bin/maxwell --config /opt/module/maxwell-1.25.0/config.properties >/dev/null 2>&1 &- 授予执行权限
[yyds@hadoop202 maxwell-1.25.0]$ sudo chmod +x /home/yyds/bin/maxwell.sh- 运行启动程序
[yyds@hadoop202 maxwell-1.25.0]$ maxwell.sh
- 启动Kafka消费客户端,观察结果
[yyds@hadoop202 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop202:9092 --topic ods_base_db_m- 执行/opt/module/rt_dblog下的jar生成模拟数据
[yyds@hadoop202 rt_dblog]$ java -jar gmall2020-mock-db-2020-11-27.jar![]()
注意:如果需要监控DDL变化,在启动Maxwell的时候添加参数-output_ddl。
5、Maxwell的初始化数据功能
初始化用户表:
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop202 --database gmall2020 --table user_info --client_id maxwell_1- --user maxwell
数据库分配的操作maxwell数据库的用户名。
- --password 123456
数据库分配的操作maxwell数据库的密码。
- --host
数据库主机名。
- --database
数据库名。
- --table
表名。
- --client_id
maxwell-bootstrap不具备将数据直接导入kafka或者hbase的能力,通过--client_id指定将数据交给哪个maxwell进程处理,在maxwell的conf.properties中配置。
四、DWD层数据准备
1、分层需求分析
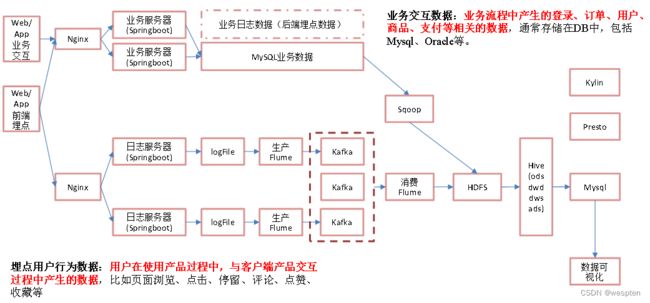
在之前介绍实时数仓概念时讨论过,建设实时数仓的目的,主要是增加数据计算的复用性。每次新增加统计需求时,不至于从原始数据进行计算,而是从半成品继续加工而成。
我们这里从kafka的ods层读取用户行为日志以及业务数据,并进行简单处理,写回到kafka作为dwd层。
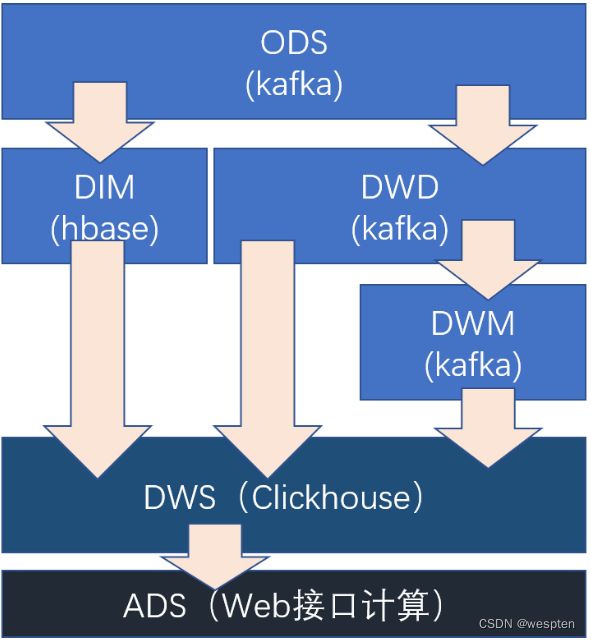
每层的职能:
| 分层 |
数据描述 |
生成计算工具 |
存储媒介 |
| ODS |
原始数据,日志和业务数据 |
日志服务器,maxwell |
kafka |
| DWD |
根据数据对象为单位进行分流,比如订单、页面访问等等。 |
FLINK |
kafka |
| DWM |
对于部分数据对象进行进一步加工,比如独立访问、跳出行为。依旧是明细数据。 |
FLINK |
kafka |
| DIM |
维度数据 |
FLINK |
HBase |
| DWS |
根据某个维度主题将多个事实数据轻度聚合,形成主题宽表。 |
FLINK |
Clickhouse |
| ADS |
把Clickhouse中的数据根据可视化需要进行筛选聚合。 |
Clickhouse SQL |
可视化展示 |
DWD层数据准备实现思路:
- 功能1:环境搭建
- 功能2:计算用户行为日志DWD层
- 功能3:计算业务数据DWD层
2、环境搭建
在工程中新建模块gmall2021-realtime:
| 目录 |
作用 |
| app |
产生各层数据的flink任务 |
| bean |
数据对象 |
| common |
公共常量 |
| utils |
工具类 |
修改配置文件:
在pom.xml添加如下配置。
1.8
${java.version}
${java.version}
1.12.0
2.12
3.1.3
org.apache.flink
flink-java
${flink.version}
org.apache.flink
flink-streaming-java_${scala.version}
${flink.version}
org.apache.flink
flink-connector-kafka_${scala.version}
${flink.version}
org.apache.flink
flink-clients_${scala.version}
${flink.version}
org.apache.flink
flink-cep_${scala.version}
${flink.version}
org.apache.flink
flink-json
${flink.version}
com.alibaba
fastjson
1.2.68
org.apache.hadoop
hadoop-client
${hadoop.version}
org.slf4j
slf4j-api
1.7.25
org.slf4j
slf4j-log4j12
1.7.25
org.apache.logging.log4j
log4j-to-slf4j
2.14.0
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
在resources目录下创建log4j.properties配置文件:
log4j.rootLogger=warn,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n3、准备用户行为日志-DWD层
我们前面采集的日志数据已经保存到Kafka中,作为日志数据的ODS层,从kafka的ODS层读取的日志数据分为3类, 页面日志、启动日志和曝光日志。这三类数据虽然都是用户行为数据,但是有着完全不一样的数据结构,所以要拆分处理。将拆分后的不同的日志写回Kafka不同主题中,作为日志DWD层。
页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光侧输出流。
1. 主要任务
1)识别新老用户
本身客户端业务有新老用户的标识,但是不够准确,需要用实时计算再次确认(不涉及业务操作,只是单纯的做个状态确认)。
2)利用侧输出流实现数据拆分
根据日志数据内容,将日志数据分为3类, 页面日志、启动日志和曝光日志。页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光日志侧输出流。
3)将不同流的数据推送下游的kafka的不同Topic中
2. 代码实现
接收Kafka数据,并进行转换:
封装操作Kafka的工具类,并提供获取kafka消费者的方法(读)。
package com.yyds.gmall.realtime.utils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
/**
* Author: Felix
* Desc: 操作Kafka的工具类
*/
public class MyKafkaUtil {
private static String kafkaServer = "hadoop202:9092,hadoop203:9092,hadoop204:9092";
//封装Kafka消费者
public static FlinkKafkaConsumer getKafkaSource(String topic,String groupId){
Properties prop = new Properties();
prop.setProperty(ConsumerConfig.GROUP_ID_CONFIG,groupId);
prop.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,kafkaServer);
return new FlinkKafkaConsumer(topic,new SimpleStringSchema(),prop);
}
} Flink调用工具类读取数据的主程序:
package com.yyds.gmall.realtime.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.yyds.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* Author: Felix
* Desc: 从Kafka中读取ods层用户行为日志数据
*/
public class BaseLogApp {
//定义用户行为主题信息
private static final String TOPIC_START ="dwd_start_log";
private static final String TOPIC_PAGE ="dwd_page_log";
private static final String TOPIC_DISPLAY ="dwd_display_log";
public static void main(String[] args) throws Exception {
//TODO 0.基本环境准备
//创建Flink流处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度 这里和kafka分区数保持一致
env.setParallelism(4);
//设置CK相关的参数
//设置精准一次性保证(默认) 每5000ms开始一次checkpoint
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
//Checkpoint必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop202:8020/gmall/flink/checkpoint"));
System.setProperty("HADOOP_USER_NAME","yyds");
//指定消费者配置信息
String groupId = "ods_dwd_base_log_app";
String topic = "ods_base_log";
//TODO 1.从kafka中读取数据
//调用Kafka工具类,从指定Kafka主题读取数据
FlinkKafkaConsumer kafkaSource = MyKafkaUtil.getKafkaSource(topic, groupId);
DataStreamSource kafkaDS = env.addSource(kafkaSource);
//转换为json对象
SingleOutputStreamOperator jsonObjectDS = kafkaDS.map(
new MapFunction() {
public JSONObject map(String value) throws Exception {
JSONObject jsonObject = JSON.parseObject(value);
return jsonObject;
}
}
);
//打印测试
jsonObjectDS.print();
//执行
env.execute("dwd_base_log Job");
}
} 识别新老访客:
保存每个mid的首次访问日期,每条进入该算子的访问记录,都会把mid对应的首次访问时间读取出来,跟当前日期进行比较,只有首次访问时间不为空,且首次访问时间早于当日的,则认为该访客是老访客,否则是新访客。
同时如果是新访客且没有访问记录的话,会写入首次访问时间。
//TODO 2.识别新老访客
//按照mid进行分组
KeyedStream midKeyedDS = jsonObjectDS.keyBy(
data -> data.getJSONObject("common").getString("mid"));
//校验采集到的数据是新老访客
SingleOutputStreamOperator midWithNewFlagDS = midKeyedDS.map(
new RichMapFunction() {
//声明第一次访问日期的状态
private ValueState firstVisitDataState;
//声明日期数据格式化对象
private SimpleDateFormat simpleDateFormat;
@Override
public void open(Configuration parameters) throws Exception {
//初始化数据
firstVisitDataState = getRuntimeContext().getState(
new ValueStateDescriptor("newMidDateState", String.class)
);
simpleDateFormat = new SimpleDateFormat("yyyyMMdd");
}
@Override
public JSONObject map(JSONObject jsonObj) throws Exception {
//打印数据
System.out.println(jsonObj);
//获取访问标记 0表示老访客 1表示新访客
String isNew = jsonObj.getJSONObject("common").getString("is_new");
//获取数据中的时间戳
Long ts = jsonObj.getLong("ts");
//判断标记如果为"1",则继续校验数据
if ("1".equals(isNew)) {
//获取新访客状态
String newMidDate = firstVisitDataState.value();
//获取当前数据访问日期
String tsDate = simpleDateFormat.format(new Date(ts));
//如果新访客状态不为空,说明该设备已访问过 则将访问标记置为"0"
if (newMidDate != null && newMidDate.length()!=0) {
if(!newMidDate.equals(tsDate)){
isNew = "0";
jsonObj.getJSONObject("common").put("is_new", isNew);
}
}else{
//如果复检后,该设备的确没有访问过,那么更新状态为当前日期
firstVisitDataState.update(tsDate);
}
}
//返回确认过新老访客的json数据
return jsonObj;
}
}
);
//打印测试
midWithNewFlagDS.print(); 利用侧输出流实现数据拆分:
根据日志数据内容,将日志数据分为3类, 页面日志、启动日志和曝光日志。页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光日志侧输出流。
//TODO 3.利用侧输出流实现数据拆分
//定义启动和曝光数据的侧输出流标签
OutputTag startTag = new OutputTag("start"){};
OutputTag displayTag = new OutputTag("display"){};
//日志页面日志、启动日志、曝光日志
//将不同的日志输出到不同的流中 页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光日志侧输出流
SingleOutputStreamOperator pageDStream = midWithNewFlagDS.process(
new ProcessFunction() {
@Override
public void processElement(JSONObject jsonObj, Context ctx, Collector out) throws Exception {
//获取数据中的启动相关字段
JSONObject startJsonObj = jsonObj.getJSONObject("start");
//将数据转换为字符串,准备向流中输出
String dataStr = jsonObj.toString();
//如果是启动日志,输出到启动侧输出流
if (startJsonObj != null && startJsonObj.size() > 0) {
ctx.output(startTag, dataStr);
} else {
//非启动日志,则为页面日志或者曝光日志(携带页面信息)
System.out.println("PageString:" + dataStr);
//将页面数据输出到主流
out.collect(dataStr);
//获取数据中的曝光数据,如果不为空,则将每条曝光数据取出输出到曝光日志侧输出流
JSONArray displays = jsonObj.getJSONArray("displays");
if (displays != null && displays.size() > 0) {
for (int i = 0; i < displays.size(); i++) {
JSONObject displayJsonObj = displays.getJSONObject(i);
//获取页面id
String pageId = jsonObj.getJSONObject("page").getString("page_id");
//给每条曝光信息添加上pageId
displayJsonObj.put("page_id", pageId);
//将曝光数据输出到测输出流
ctx.output(displayTag, displayJsonObj.toString());
}
}
}
}
}
);
//获取侧输出流
DataStream startDStream = pageDStream.getSideOutput(startTag);
DataStream displayDStream = pageDStream.getSideOutput(displayTag);
//打印测试
pageDStream.print("page");
startDStream.print("start");
displayDStream.print("display"); 将不同流的数据推送到下游kafka的不同Topic(分流):
在MyKafkaUtil工具类中封装获取生产者的方法(写):
//封装Kafka生产者
public static FlinkKafkaProducer getKafkaSink(String topic) {
return new FlinkKafkaProducer<>(kafkaServer,topic,new SimpleStringSchema());
} 程序中调用kafka工具类获取sink:
//打印测试
//pageDStream.print("page");
//startDStream.print("start");
//displayDStream.print("display");
//TODO 4.将数据输出到kafka不同的主题中
FlinkKafkaProducer startSink = MyKafkaUtil.getKafkaSink(TOPIC_START);
FlinkKafkaProducer pageSink = MyKafkaUtil.getKafkaSink(TOPIC_PAGE);
FlinkKafkaProducer displaySink = MyKafkaUtil.getKafkaSink(TOPIC_DISPLAY);
startDStream.addSink(startSink);
pageDStream.addSink(pageSink);
displayDStream.addSink(displaySink); 测试:
- Idea中运行DwdBaseLog类
- 运行logger.sh,启动Nginx以及日志处理服务
- 运行rt_applog下模拟生成数据的jar包
- 到kafka不同的主题下查看输出效果
4、准备业务数据-DWD层
业务数据的变化,我们可以通过Maxwell采集到,但是MaxWell是把全部数据统一写入一个Topic中, 这些数据包括业务数据,也包含维度数据,这样显然不利于日后的数据处理,所以这个功能是从Kafka的业务数据ODS层读取数据,经过处理后,将维度数据保存到Hbase,将事实数据写回Kafka作为业务数据的DWD层。
1. 主要任务
1)接收Kafka数据,过滤空值数据
对Maxwell抓取数据进行ETL,有用的部分保留,没用的过滤掉。
2)实现动态分流功能
由于MaxWell是把全部数据统一写入一个Topic中, 这样显然不利于日后的数据处理。所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表,有的表既是事实表在某种情况下也是维度表。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase、Redis、MySQL等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。但是作为Flink实时计算任务,如何得知哪些表是维度表,哪些是事实表呢?而这些表又应该采集哪些字段呢?
我们可以将上面的内容放到某一个地方,集中配置。这样的配置不适合写在配置文件中,因为业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这种可以有两个方案实现:
- 一种是用Zookeeper存储,通过Watch感知数据变化。
- 另一种是用mysql数据库存储,
周期性的同步
这里选择第二种方案,主要是mysql对于配置数据初始化和维护管理,用sql都比较方便。
所以就有了如下图:

把分好的流保存到对应表、主题中:
业务数据保存到Kafka的主题中。
维度数据保存到Hbase的表中。
2. 代码实现
接收Kafka数据,过滤空值数据:
package com.yyds.gmall.realtime.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.yyds.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* Author: Felix
* Date: 2021/4/12
* Desc: 从Kafka中读取ods层业务数据 并进行处理 发送到DWD层
*/
public class BaseDBApp {
public static void main(String[] args) throws Exception {
//TODO 1.基本环境准备
//1.1创建流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.2设置并行度
env.setParallelism(4);
/*
//1.3检查点相关的配置
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop202:8020/gmall/flink/checkpoint"));
env.setRestartStrategy(RestartStrategies.noRestart());
*/
//TODO 2.从kafka主题中读取数据
//2.1 定义主题以及消费者组
String topic = "ods_base_db_m";
String groupId = "basedbapp_group";
//2.2 获取KafkaSource
FlinkKafkaConsumer kafkaSource = MyKafkaUtil.getKafkaSource(topic, groupId);
DataStreamSource kafkaDS = env.addSource(kafkaSource);
//2.3 对流的数据进行结构转换 String->JSONObject
/*
SingleOutputStreamOperator jsonObjDS = kafkaDS.map(
new MapFunction() {
@Override
public JSONObject map(String jsonStr) throws Exception {
return JSON.parseObject(jsonStr);
}
}
);
SingleOutputStreamOperator jsonObjDS = kafkaDS.map(jsonStr -> JSON.parseObject(jsonStr));
*/
SingleOutputStreamOperator jsonObjDS = kafkaDS.map(JSON::parseObject);
//2.4 对数据进行简单的ETL
SingleOutputStreamOperator filteredDS = jsonObjDS.filter(
new FilterFunction() {
@Override
public boolean filter(JSONObject jsonObj) throws Exception {
boolean flag = jsonObj.getString("table") != null
&& jsonObj.getString("table").length() > 0
&& jsonObj.getJSONObject("data") != null
&& jsonObj.getString("data").length() > 3;
return flag;
}
}
);
//filteredDS.print(">>>");
env.execute();
}
} 根据MySQL的配置表,动态进行分流:
我们通过FlinkCDC动态监控配置表的变化,以流的形式将配置表的变化读到程序中,并以广播流的形式向下传递,主流从广播流中获取配置信息。
准备工作:
引入pom.xml 依赖:
org.projectlombok
lombok
1.18.12
provided
mysql
mysql-connector-java
5.1.47
com.alibaba.ververica
flink-connector-mysql-cdc
1.2.0
在Mysql中创建数据库:
注意:和gmall2021业务库区分开。

在gmall2021_realtime库中创建配置表table_process:
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '来源表',
`operate_type` varchar(200) NOT NULL COMMENT '操作类型 insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8创建配置表实体类:
package com.yyds.gmall.realtime.bean;
import lombok.Data;
@Data
public class TableProcess {
//动态分流Sink常量 改为小写和脚本一致
public static final String SINK_TYPE_HBASE = "hbase";
public static final String SINK_TYPE_KAFKA = "kafka";
public static final String SINK_TYPE_CK = "clickhouse";
//来源表
String sourceTable;
//操作类型 insert,update,delete
String operateType;
//输出类型 hbase kafka
String sinkType;
//输出表(主题)
String sinkTable;
//输出字段
String sinkColumns;
//主键字段
String sinkPk;
//建表扩展
String sinkExtend;
}在MySQL Binlog添加对配置数据库的监听,并重启MySQL:
sudo vim /etc/my.cnf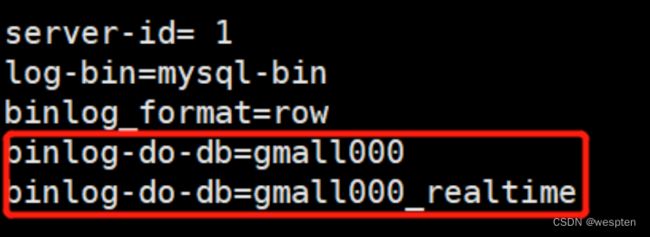
通过Flink CDC读取配置表形成广播流,主流和广播流进行连接:
//TODO 3.使用FlinkCDC读取配置表形成广播流
DebeziumSourceFunction sourceFunction = MySQLSource.builder()
.hostname("hadoop202")
.port(3306)
.username("root")
.password("123456")
.databaseList("gmall000_realtime")
.tableList("gmall000_realtime.table_process")
.deserializer(new MyDeserializationSchemaFunction())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource mysqlDS = env.addSource(sourceFunction);
MapStateDescriptor mapStateDescriptor = new MapStateDescriptor<>("table-process", String.class, TableProcess.class);
BroadcastStream broadcastStream = mysqlDS.broadcast(mapStateDescriptor);
//TODO 4.连接主流和广播流
BroadcastConnectedStream connectedStream = filteredDS.connect(broadcastStream); 自定义Flink CDC采集的反序列化器:
将CDC格式数据转换为json字符串。
package com.yyds.gmall.realtime.app.func;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
/**
* Author: Felix
* Desc: 自定义反序列化器
*/
public class MyDeserializationSchemaFunction implements DebeziumDeserializationSchema {
@Override
public void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception {
//定义JSON对象用于存放反序列化后的数据
JSONObject result = new JSONObject();
//获取库名和表名
String topic = sourceRecord.topic();
String[] split = topic.split("\\.");
String database = split[1];
String table = split[2];
//获取操作类型
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
//获取数据本身
Struct struct = (Struct) sourceRecord.value();
Struct after = struct.getStruct("after");
JSONObject value = new JSONObject();
// System.out.println("Value:" + value);
if (after != null) {
Schema schema = after.schema();
for (Field field : schema.fields()) {
String name = field.name();
Object o = after.get(name);
// System.out.println(name + ":" + o);
value.put(name, o);
}
}
//将数据放入JSON对象
result.put("database", database);
result.put("table", table);
String type = operation.toString().toLowerCase();
if ("create".equals(type)) {
type = "insert";
}
result.put("type", type);
result.put("data", value);
//将数据传输出去
collector.collect(result.toJSONString());
}
@Override
public TypeInformation getProducedType() {
return TypeInformation.of(String.class);
}
} 主程序中对连接后的数据进行分流:
//TODO 5.对数据进行分流操作 维度数据放到侧输出流 事实数据放到主流
OutputTag dimTag = new OutputTag("dimTag"){};
SingleOutputStreamOperator realDS = connectedStream.process(new TableProcessFunction(dimTag,mapStateDescriptor));
//获取维度侧输出流
DataStream dimDS = realDS.getSideOutput(dimTag);
realDS.print(">>>>");
dimDS.print("####"); 自定义函数TableProcessFunction:
package com.yyds.gmall.realtime.app.func;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.yyds.gmall.realtime.bean.TableProcess;
import com.yyds.gmall.realtime.common.GmallConfig;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.*;
/**
* Author: Felix
* Date: 2021/3/23
* Desc: 分流处理的函数类
*/
public class TableProcessFunction extends BroadcastProcessFunction {
private Connection conn = null;
//定义一个侧输出流标记
private OutputTag outputTag;
private MapStateDescriptor mapStateDescriptor;
//通过构造方法给属性赋值
public TableProcessFunction(OutputTag outputTag,MapStateDescriptor mapStateDescriptor) {
this.outputTag = outputTag;
this.mapStateDescriptor = mapStateDescriptor;
}
@Override
public void open(Configuration parameters) throws Exception {
//初始化Phoenix连接
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
conn = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
}
@Override
public void processElement(JSONObject jsonObj, ReadOnlyContext ctx, Collector out) throws Exception {
//取出状态数据
ReadOnlyBroadcastState broadcastState = ctx.getBroadcastState(mapStateDescriptor);
String table = jsonObj.getString("table");
String type = jsonObj.getString("type");
JSONObject dataJsonObj = jsonObj.getJSONObject("data");
if (type.equals("bootstrap-insert")) {
type = "insert";
jsonObj.put("type", type);
}
//从状态中获取配置信息
String key = table + ":" + type;
TableProcess tableProcess = broadcastState.get(key);
if (tableProcess != null) {
jsonObj.put("sink_table", tableProcess.getSinkTable());
if (tableProcess.getSinkColumns() != null && tableProcess.getSinkColumns().length() > 0) {
filterColumn(dataJsonObj, tableProcess.getSinkColumns());
}
if (tableProcess.getSinkType().equals(TableProcess.SINK_TYPE_HBASE)) {
ctx.output(outputTag, jsonObj);
} else if (tableProcess.getSinkType().equals(TableProcess.SINK_TYPE_KAFKA)) {
out.collect(jsonObj);
}
} else {
System.out.println("NO this Key in TableProce" + key);
}
}
@Override
public void processBroadcastElement(String value, Context ctx, Collector out) throws Exception {
//将单条数据转换为JSON对象
JSONObject jsonObject = JSON.parseObject(value);
//获取其中的data
String data = jsonObject.getString("data");
//将data转换为TableProcess对象
TableProcess tableProcess = JSON.parseObject(data, TableProcess.class);
//获取源表表名
String sourceTable = tableProcess.getSourceTable();
//获取操作类型
String operateType = tableProcess.getOperateType();
//输出类型 hbase|kafka
String sinkType = tableProcess.getSinkType();
//输出目的地表名或者主题名
String sinkTable = tableProcess.getSinkTable();
//输出字段
String sinkColumns = tableProcess.getSinkColumns();
//表的主键
String sinkPk = tableProcess.getSinkPk();
//建表扩展语句
String sinkExtend = tableProcess.getSinkExtend();
//拼接保存配置的key
String key = sourceTable + ":" + operateType;
//如果是维度数据,需要通过Phoenix创建表
if (TableProcess.SINK_TYPE_HBASE.equals(sinkType) && "insert".equals(operateType)) {
checkTable(sinkTable, sinkColumns, sinkPk, sinkExtend);
}
//获取状态
BroadcastState broadcastState = ctx.getBroadcastState(mapStateDescriptor);
//将数据写入状态进行广播
broadcastState.put(key, tableProcess);
}
//拼接SQL,通过Phoenix创建表
private void checkTable(String tableName, String fields, String pk, String ext) {
if(pk == null){
pk = "id";
}
if(ext == null){
ext = "";
}
String[] fieldsArr = fields.split(",");
//拼接建表语句
StringBuilder createSql = new StringBuilder("create table if not exists "+ GmallConfig.HBASE_SCHEMA +"."+tableName+"(");
for (int i = 0; i < fieldsArr.length; i++) {
String field = fieldsArr[i];
//判断当前字段是否为主键字段
if(pk.equals(field)){
createSql.append(field).append( " varchar primary key ");
}else{
createSql.append("info.").append(field).append( " varchar ");
}
//如果不是最后一个字段 拼接逗号
if(i < fieldsArr.length - 1){
createSql.append( ",");
}
}
createSql.append(")");
createSql.append(ext);
System.out.println("Phoenix的建表语句:" + createSql);
//执行SQL语句,通过Phoenix建表
PreparedStatement ps = null;
try {
//创建数据库操作对象
ps = conn.prepareStatement(createSql.toString());
//执行SQL语句
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException("在Phoenix中创建维度表失败");
}finally {
if(ps!=null){
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
//对dataJsonObj中的属性进行过滤
//dataJsonObj:"data":{"id":12,"tm_name":"yyds","logo_url":"/static/beijing.jpg"}
//sinkColumns : id,tm_name
private void filterColumn(JSONObject dataJsonObj, String sinkColumns) {
String[] fieldArr = sinkColumns.split(",");
//将数据转换为List集合,方便后面通过判断是否包含key
List fieldList = Arrays.asList(fieldArr);
//获取json对象的封装的键值对集合
Set> entrySet = dataJsonObj.entrySet();
//获取迭代器对象 因为对集合进行遍历的时候,需要使用迭代器进行删除
Iterator> it = entrySet.iterator();
//对集合中元素进行迭代
for (;it.hasNext();) {
//得到json中的一个键值对
Map.Entry entry = it.next();
//如果sink_columns中不包含 遍历出的属性 将其删除
if(!fieldList.contains(entry.getKey())){
it.remove();
}
}
}
}
定义一个项目中常用的配置常量类GmallConfig:
package com.yyds.gmall.realtime.common;
/**
* Author: Felix
* Desc: 项目配置常量类
*/
public class GmallConfig {
public static final String HBASE_SCHEMA="GMALL2021_REALTIME";
public static final String PHOENIX_SERVER="jdbc:phoenix:hadoop202,hadoop203,hadoop204:2181";
}3. 分流Sink之保存维度到HBase(Phoenix)
程序流程分析:

DimSink 继承了RichSinkFunction,这个function得分两条时间线。
- 一条是任务启动时执行open操作(图中紫线),我们可以把连接的初始化工作放在此处一次性执行。
- 另一条是随着每条数据的到达反复执行invoke()(图中黑线),在这里面我们要实现数据的保存,主要策略就是根据数据组合成sql提交给hbase。
引入apache工具包以及phoenix依赖:
commons-beanutils
commons-beanutils
1.9.3
org.apache.phoenix
phoenix-spark
5.0.0-HBase-2.0
org.glassfish
javax.el
因为要用单独的schema,所以在Idea程序中加入hbase-site.xml:
hbase.rootdir
hdfs://hadoop202:8020/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
hadoop202,hadoop203,hadoop204
hbase.unsafe.stream.capability.enforce
false
hbase.wal.provider
filesystem
phoenix.schema.isNamespaceMappingEnabled
true
phoenix.schema.mapSystemTablesToNamespace
true
注意:为了开启hbase的namespace和phoenix的schema的映射,在程序中需要加这个配置文件,另外在linux服务上,也需要在hbase以及phoenix的hbase-site.xml配置文件中,加上以上两个配置,并使用xsync进行同步。
注意:重启Hbase服务
在phoenix中执行:
create schema GMALL2021_REALTIME;DimSink:
package com.yyds.gmall.realtime.app.func;
import com.alibaba.fastjson.JSONObject;
import com.yyds.gmall.realtime.common.GmallConfig;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.*;
import java.util.Set;
/**
* Author: Felix
* Desc: 通过Phoenix向Hbase表中写数据
*/
public class DimSink extends RichSinkFunction {
Connection connection = null;
@Override
public void open(Configuration parameters) throws Exception {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
}
/**
* 生成语句提交hbase
* @param jsonObject
* @param context
* @throws Exception
*/
@Override
public void invoke(JSONObject jsonObject, Context context) throws Exception {
String tableName = jsonObject.getString("sink_table");
JSONObject dataJsonObj = jsonObject.getJSONObject("data");
if (dataJsonObj != null && dataJsonObj.size() > 0) {
String upsertSql = genUpsertSql(tableName.toUpperCase(), jsonObject.getJSONObject("data"));
try {
System.out.println(upsertSql);
PreparedStatement ps = connection.prepareStatement(upsertSql);
ps.executeUpdate();
connection.commit();
ps.close();
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("执行sql失败!");
}
}
}
public String genUpsertSql(String tableName, JSONObject jsonObject) {
Set fields = jsonObject.keySet();
String upsertSql = "upsert into " + GmallConfig.HBASE_SCHEMA + "." + tableName + "(" + StringUtils.join(fields, ",") + ")";
String valuesSql = " values ('" + StringUtils.join(jsonObject.values(), "','") + "')";
return upsertSql + valuesSql;
}
} 主程序BaseDBApp中调用DimSink:
//TODO 6.将侧输出流数据写入HBase(Phoenix)
hbaseDStream.print("hbase::::");
hbaseDStream.addSink(new DimSink());测试:
- 启动hdfs、zk、kafka、Maxwell、hbase;
- 向gmall2021_realtime数据库的table_process表中插入测试数据;

- 运行idea中的BaseDBApp
- 向gmall2021数据库的base_trademark表中插入一条数据
- 通过phoenix查看hbase的schema以及表情况


4. 分流Sink之保存业务数据到Kafka主题
在MyKafkaUtil中添加如下方法:
//封装Kafka生产者 动态指定多个不同主题
public static FlinkKafkaProducer getKafkaSinkBySchema(KafkaSerializationSchema serializationSchema) {
Properties prop =new Properties();
prop.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,kafkaServer);
//如果15分钟没有更新状态,则超时 默认1分钟
prop.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,1000*60*15+"");
return new FlinkKafkaProducer<>(DEFAULT_TOPIC, serializationSchema, prop, FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
} 在MyKafkaUtil中添加属性定义:
private static final String DEFAULT_TOPIC="DEFAULT_DATA";两个创建FlinkKafkaProducer方法对比:
- 前者给定确定的Topic;
- 而后者除了缺省情况下会采用DEFAULT_TOPIC,一般情况下可以根据不同的业务数据在KafkaSerializationSchema中通过方法实现;
- 可以查看一下FlinkKafkaProducer中的invoke方法源码;
在主程序BaseDBApp中加入新KafkaSink:
//TODO 7.将主流数据写入Kafka
realDS.addSink(MyKafkaUtil.getKafkaSinkBySchema(
new KafkaSerializationSchema() {
@Override
public ProducerRecord serialize(JSONObject jsonObj, @Nullable Long timestamp) {
//获取保存到Kafka的哪一个主题中
String topicName = jsonObj.getString("sink_table");
//获取data数据
JSONObject dataJsonObj = jsonObj.getJSONObject("data");
return new ProducerRecord<>(topicName,dataJsonObj.toString().getBytes());
}
}
)); 测试:
- 启动hdfs、zk、kafka、Maxwell、hbase;
- 向gmall2021_realtime数据库的table_process表中插入测试数据;

- 运行idea中的BaseDBApp
- 运行rt_dblog下的jar包,模拟生成数据
- 查看控制台输出以及在配置表中配置的kafka主题名消费情况
总结:
DWD的实时计算核心就是数据分流,其次是状态识别。在开发过程中我们实践了几个灵活度较强算子,比如RichMapFunction, ProcessFunction, RichSinkFunction。 那这几个我们什么时候会用到呢?如何选择?
| Function |
可转换结构 |
可过滤数据 |
侧输出 |
open方法 |
可以使用状态 |
输出至 |
| MapFunction |
Yes |
No |
No |
No |
No |
下游算子 |
| FilterFunction |
No |
Yes |
No |
No |
No |
下游算子 |
| RichMapFunction |
Yes |
No |
No |
Yes |
Yes |
下游算子 |
| RichFilterFunction |
No |
Yes |
No |
Yes |
Yes |
下游算子 |
| ProcessFunction |
Yes |
Yes |
Yes |
Yes |
Yes |
下游算子 |
| SinkFunction |
Yes |
Yes |
No |
No |
No |
外部 |
| RichSinkFunction |
Yes |
Yes |
No |
Yes |
Yes |
外部 |
从对比表中能明显看出,Rich系列能功能强大,ProcessFunction功能更强大,但是相对的越全面的算子使用起来也更加繁琐。
五、DWM层业务实现
1、DWS层与DWM层的设计
我们在之前通过分流等手段,把数据分拆成了独立的kafka topic。那么接下来如何处理数据,就要思考一下我们到底要通过实时计算出哪些指标项。
因为实时计算与离线不同,实时计算的开发和运维成本都是非常高的,要结合实际情况考虑是否有必要象离线数仓一样,建一个大而全的中间层。
如果没有必要大而全,这时候就需要大体规划一下要实时计算出的指标需求了。把这些指标以主题宽表的形式输出就是我们的DWS层。
2、需求梳理
| 统计主题 |
需求指标 |
输出方式 |
计算来源 |
来源层级 |
| 访客 |
pv |
可视化大屏 |
page_log直接可求 |
dwd |
| uv |
可视化大屏 |
需要用page_log过滤去重 |
dwm |
|
| 跳出明细 |
可视化大屏 |
需要通过page_log行为判断 |
dwm |
|
| 进入页面数 |
可视化大屏 |
需要识别开始访问标识 |
dwd |
|
| 连续访问时长 |
可视化大屏 |
page_log直接可求 |
dwd |
|
| 商品 |
点击 |
多维分析 |
page_log直接可求 |
dwd |
| 收藏 |
多维分析 |
收藏表 |
dwd |
|
| 加入购物车 |
多维分析 |
购物车表 |
dwd |
|
| 下单 |
可视化大屏 |
订单宽表 |
dwm |
|
| 支付 |
多维分析 |
支付宽表 |
dwm |
|
| 退款 |
多维分析 |
退款表 |
dwd |
|
| 评论 |
多维分析 |
评论表 |
dwd |
|
| 地区 |
pv |
多维分析 |
page_log直接可求 |
dwd |
| uv |
多维分析 |
需要用page_log过滤去重 |
dwm |
|
| 下单 |
可视化大屏 |
订单宽表 |
dwm |
|
| 关键词 |
搜索关键词 |
可视化大屏 |
页面访问日志 直接可求 |
dwd |
| 点击商品关键词 |
可视化大屏 |
商品主题下单再次聚合 |
dws |
|
| 下单商品关键词 |
可视化大屏 |
商品主题下单再次聚合 |
dws |
当然实际需求还会有更多,这里主要以为可视化大屏为目的进行实时计算的处理。
DWM层的定位是什么,DWM层主要服务DWS,因为部分需求直接从DWD层到DWS层中间会有一定的计算量,而且这部分计算的结果很有可能被多个DWS层主题复用,所以部分DWD层会形成一层DWM,我们这里主要涉及业务。
- 访问UV计算
- 跳出明细计算
- 订单宽表
- 支付宽表
3、DWM层-访客UV计算
1. 需求分析与思路
UV,全称是Unique Visitor,即独立访客,对于实时计算中,也可以称为DAU(Daily Active User),即每日活跃用户,因为实时计算中的uv通常是指当日的访客数。
那么如何从用户行为日志中识别出当日的访客,那么有两点:
- 其一,是识别出该访客打开的第一个页面,表示这个访客开始进入我们的应用
- 其二,由于访客可以在一天中多次进入应用,所以我们要在一天的范围内进行去重
2. 代码实现
从kafka的dwd_page_log主题接收数据:
package com.yyds.gmall.realtime.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.yyds.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* Author: Felix
* Desc: 访客UV的明细准备
*/
public class UniqueVisitApp {
public static void main(String[] args) throws Exception{
//TODO 0.基本环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
//env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(60000);
//StateBackend fsStateBackend = new FsStateBackend("hdfs://hadoop202:8020/gmall/flink/checkpoint/UniqueVisitApp");
//env.setStateBackend(fsStateBackend);
//System.setProperty("HADOOP_USER_NAME", "yyds");
//TODO 1.从Kafka中读取数据
String groupId = "unique_visit_app";
String sourceTopic = "dwd_page_log";
String sinkTopic = "dwm_unique_visit";
//读取kafka数据
FlinkKafkaConsumer source = MyKafkaUtil.getKafkaSource(sourceTopic, groupId);
DataStreamSource jsonStream = env.addSource(source);
//对读取的数据进行结构的转换
DataStream jsonObjStream = jsonStream.map(jsonString -> JSON.parseObject(jsonString));
jsonObjStream.print("uv:");
env.execute();
}
} 测试:
- 启动logger.sh、zk、kafka
- 运行Idea中的BaseLogApp
- 运行Idea中的UniqueVisitApp
- 查看控制台输出
- 执行流程
模拟生成数据->日志处理服务器->写到kafka的ODS层(ods_base_log)->BaseLogApp分流->dwd_page_log->UniqueVisitApp读取输出。
2. 核心的过滤代码
- 首先用keyby按照mid进行分组,每组表示当前设备的访问情况
- 分组后使用keystate状态,记录用户进入时间,实现RichFilterFunction完成过滤
- 重写open 方法用来初始化状态
- 重写filter方法进行过滤
- 可以直接筛掉last_page_id不为空的字段,因为只要有上一页,说明这条不是这个用户进入的首个页面。
- 状态用来记录用户的进入时间,只要这个lastVisitDate是今天,就说明用户今天已经访问过了所以筛除掉。如果为空或者不是今天,说明今天还没访问过,则保留。
- 因为状态值主要用于筛选是否今天来过,所以这个记录过了今天基本上没有用了,这里enableTimeToLive 设定了1天的过期时间,避免状态过大。
//jsonObjStream.print("uv:");
//TODO 2.核心的过滤代码
//按照设备id进行分组
KeyedStream keyByWithMidDstream =
jsonObjStream.keyBy(jsonObj -> jsonObj.getJSONObject("common").getString("mid"));
SingleOutputStreamOperator filteredJsonObjDstream =
keyByWithMidDstream.filter(new RichFilterFunction() {
//定义状态用于存放最后访问的日期
ValueState lastVisitDateState = null;
//日期格式
SimpleDateFormat simpleDateFormat = null;
//初始化状态 以及时间格式器
@Override
public void open(Configuration parameters) throws Exception {
simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
if (lastVisitDateState == null) {
ValueStateDescriptor lastViewDateStateDescriptor =
new ValueStateDescriptor<>("lastViewDateState", String.class);
//因为统计的是当日UV,也就是日活,所有为状态设置失效时间
StateTtlConfig stateTtlConfig=StateTtlConfig.newBuilder(Time.days(1)).build();
//默认值 表明当状态创建或每次写入时都会更新时间戳
//.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//默认值 一旦这个状态过期了,那么永远不会被返回给调用方,只会返回空状态
//.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();
lastViewDateStateDescriptor.enableTimeToLive(stateTtlConfig );
lastVisitDateState = getRuntimeContext().getState(lastViewDateStateDescriptor);
}
}
//首先检查当前页面是否有上页标识,如果有说明该次访问一定不是当日首次
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
String lastPageId = jsonObject.getJSONObject("page").getString("last_page_id");
if(lastPageId!=null&&lastPageId.length()>0){
return false;
}
Long ts = jsonObject.getLong("ts");
String logDate = simpleDateFormat.format(ts);
String lastViewDate = lastVisitDateState.value();
if (lastViewDate!=null&&lastViewDate.length()>0&&logDate.equals(lastViewDate)){
System.out.println("已访问:lastVisit:"+lastViewDate+"|| logDate:"+ logDate);
return false;
} else {
System.out.println("未访问:lastVisit:"+lastViewDate+"|| logDate:"+logDate);
lastVisitDateState.update(logDate);
return true;
}
}
}).uid("uvFilter");
SingleOutputStreamOperator dataJsonStringDstream =
filteredJsonObjDstream.map(jsonObj -> jsonObj.toJSONString());
dataJsonStringDstream.print("uv"); 将过滤处理后的UV写入到Kafka的dwm_unique_visit:
//TODO 3.将过滤处理后的UV写入到Kafka的dwm主题
dataJsonStringDstream.addSink(MyKafkaUtil.getKafkaSink(sinkTopic));测试:
- 启动logger.sh、zk、kafka
- 运行Idea中的BaseLogApp
- 运行Idea中的UniqueVisitApp
- 查看控制台输出以及kafka的dwm_unique_visit主题
- 执行流程
模拟生成数据->日志处理服务器->写到kafka的ODS层(ods_base_log)->BaseLogApp分流->dwd_page_log->UniqueVisitApp读取并处理->写回到kafka的dwm层
4、DWM层-跳出明细计算
1. 需求分析与思路
1)什么是跳出
跳出就是用户成功访问了网站的一个页面后就退出,不在继续访问网站的其它页面。而跳出率就是用跳出次数除以访问次数。
关注跳出率,可以看出引流过来的访客是否能很快的被吸引,渠道引流过来的用户之间的质量对比,对于应用优化前后跳出率的对比也能看出优化改进的成果。
2)计算跳出行为的思路
首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来。那么要抓住几个特征:
- 该页面是用户近期访问的第一个页面。
这个可以通过该页面是否有上一个页面(last_page_id)来判断,如果这个表示为空,就说明这是这个访客这次访问的第一个页面。
- 首次访问之后很长一段时间(自己设定),用户没继续再有其他页面的访问。
这第一个特征的识别很简单,保留last_page_id为空的就可以了。但是第二个访问的判断,其实有点麻烦,首先这不是用一条数据就能得出结论的,需要组合判断,要用一条存在的数据和不存在的数据进行组合判断。而且要通过一个不存在的数据求得一条存在的数据。更麻烦的他并不是永远不存在,而是在一定时间范围内不存在。那么如何识别有一定失效的组合行为呢?
最简单的办法就是Flink自带的CEP技术。这个CEP非常适合通过多条数据组合来识别某个事件。
用户跳出事件,本质上就是一个条件事件加一个超时事件的组合。
2. 代码实现
从kafka的dwd_page_log主题中读取页面日志:
package com.yyds.gmall.realtime.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.yyds.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Author: Felix
* Desc: 访客跳出情况判断
*/
public class UserJumpDetailApp {
public static void main(String[] args) throws Exception {
//TODO 0.基本环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
//TODO 1.从kafka的dwd_page_log主题中读取页面日志
String sourceTopic = "dwd_page_log";
String groupId = "userJumpDetailApp";
String sinkTopic = "dwm_user_jump_detail";
//从kafka中读取数据
DataStreamSource dataStream = env.addSource(MyKafkaUtil.getKafkaSource(sourceTopic, groupId));
//对数据进行结构的转换
DataStream jsonObjStream = dataStream.map(jsonString -> JSON.parseObject(jsonString));
jsonObjStream.print("json:");
env.execute();
}
} 3. 通过Flink的CEP完成跳出判断
- 确认添加了CEP的依赖包
- 设定时间语义为事件时间并指定数据中的ts字段为事件时间
由于这里涉及到时间的判断,所以必须设定数据流的EventTime和水位线。这里没有设置延迟时间,实际生产情况可以视乱序情况增加一些延迟。
增加延迟把forMonotonousTimestamps换为forBoundedOutOfOrderness即可。
注意:flink1.12默认的时间语义就是事件时间,所以不需要执行:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);//TODO 2.指定事件时间字段
SingleOutputStreamOperator jsonObjWithEtDstream = jsonObjStream.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(JSONObject jsonObject, long recordTimestamp) {
return jsonObject.getLong("ts");
}
})); 根据日志数据的mid进行分组:
因为用户的行为都是要基于相同的Mid的行为进行判断,所以要根据Mid进行分组。
//TODO 3.根据日志数据的mid进行分组
KeyedStream jsonObjectStringKeyedStream = jsonObjWithEtDstream.keyBy(
jsonObj -> jsonObj.getJSONObject("common").getString("mid")
); 配置CEP表达式:
//TODO 4.配置CEP表达式
Pattern pattern = Pattern.begin("GoIn").where(
new SimpleCondition() {
@Override // 条件1 :进入的第一个页面
public boolean filter(JSONObject jsonObj) throws Exception {
String lastPageId = jsonObj.getJSONObject("page").getString("last_page_id");
System.out.println("first in :" + lastPageId);
if (lastPageId == null || lastPageId.length() == 0) {
return true;
}
return false;
}
}
).next("next").where(
new SimpleCondition() {
@Override //条件2: 在10秒时间范围内必须有第二个页面
public boolean filter(JSONObject jsonObj) throws Exception {
String pageId = jsonObj.getJSONObject("page").getString("page_id");
System.out.println("next:" + pageId);
if (pageId != null && pageId.length() > 0) {
return true;
}
return false;
}
}
).within(Time.milliseconds(10000)); 根据表达式筛选流:
//TODO 5.根据表达式筛选流
PatternStream patternedStream = CEP.pattern(jsonObjectStringKeyedStream, pattern); 提取命中的数据:
- 设定超时时间标识 timeoutTag
- flatSelect方法中,实现PatternFlatTimeoutFunction中的timeout方法。
- 所有out.collect的数据都被打上了超时标记
- 本身的flatSelect方法因为不需要未超时的数据所以不接受数据。
- 通过SideOutput侧输出流输出超时数据
//TODO 6.提取命中的数据
final OutputTag timeoutTag = new OutputTag("timeout") {};
SingleOutputStreamOperator filteredStream = patternedStream.flatSelect(
timeoutTag,
new PatternFlatTimeoutFunction() {
@Override
public void timeout(Map> pattern, long timeoutTimestamp, Collector out) throws Exception {
List objectList = pattern.get("GoIn");
//这里进入out的数据都被timeoutTag标记
for (JSONObject jsonObject : objectList) {
out.collect(jsonObject.toJSONString());
}
}
},
new PatternFlatSelectFunction() {
@Override
public void flatSelect(Map> pattern, Collector out) throws Exception {
//因为不超时的事件不提取,所以这里不写代码
}
});
//通过SideOutput侧输出流输出超时数据
DataStream jumpDstream = filteredStream.getSideOutput(timeoutTag);
jumpDstream.print("jump::"); 将跳出数据写回到kafka的DWM层:
//TODO 7.将跳出数据写回到kafka的DWM层
jumpDstream.addSink(MyKafkaUtil.getKafkaSink(sinkTopic));测试:
利用测试数据验证。
DataStream dataStream = env
.fromElements(
"{\"common\":{\"mid\":\"101\"},\"page\":{\"page_id\":\"home\"},\"ts\":10000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"home\"},\"ts\":12000}",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"home\"},\"ts\":15000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"detail\"},\"ts\":30000} "
);
dataStream.print("in json:"); 查看控制台以及dwm_user_jump_detail输出效果。
注意:为了看效果,设置并行度为1。

5、DWM层-订单宽表
1. 需求分析与思路
订单是统计分析的重要的对象,围绕订单有很多的维度统计需求,比如用户、地区、商品、品类、品牌等等。
为了之后统计计算更加方便,减少大表之间的关联,所以在实时计算过程中将围绕订单的相关数据整合成为一张订单的宽表。
那究竟哪些数据需要和订单整合在一起?

如上图,由于在之前的操作我们已经把数据分拆成了事实数据和维度数据,事实数据(绿色)进入kafka数据流(DWD层)中,维度数据(蓝色)进入hbase中长期保存。那么我们在DWM层中要把实时和维度数据进行整合关联在一起,形成宽表。那么这里就要处理有两种关联,事实数据和事实数据关联、事实数据和维度数据关联。
- 事实数据和事实数据关联,其实就是流与流之间的关联。
- 事实数据与维度数据关联,其实就是流计算中查询外部数据源。
2. 订单和订单明细关联代码实现
1)从Kafka的dwd层接收订单和订单明细数据
创建订单实体类:
package com.yyds.gmall.realtime.bean;
import lombok.Data;
import java.math.BigDecimal;
/**
* Author: Felix
* Desc: 订单实体类
*/
@Data
public class OrderInfo {
Long id;
Long province_id;
String order_status;
Long user_id;
BigDecimal total_amount;
BigDecimal activity_reduce_amount;
BigDecimal coupon_reduce_amount;
BigDecimal original_total_amount;
BigDecimal feight_fee;
String expire_time;
String create_time;
String operate_time;
String create_date; // 把其他字段处理得到
String create_hour;
Long create_ts;
}创建订单明细实体类:
package com.yyds.gmall.realtime.bean;
import lombok.Data;
import java.math.BigDecimal;
/**
* Author: Felix
* Desc:订单明细实体类
*/
@Data
public class OrderDetail {
Long id;
Long order_id ;
Long sku_id;
BigDecimal order_price ;
Long sku_num ;
String sku_name;
String create_time;
BigDecimal split_total_amount;
BigDecimal split_activity_amount;
BigDecimal split_coupon_amount;
Long create_ts;
}在dwm包下创建OrderWideApp读取订单和订单明细数据:
package com.yyds.gmall.realtime.app.dwm;
import com.alibaba.fastjson.JSON;
import com.yyds.gmall.realtime.bean.OrderDetail;
import com.yyds.gmall.realtime.bean.OrderInfo;
import com.yyds.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.StateBackend;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.text.SimpleDateFormat;
/**
* Author: Felix
* Desc: 处理订单和订单明细数据形成订单宽表
*/
public class OrderWideApp {
public static void main(String[] args) throws Exception {
//TODO 0.基本环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度读取kafka分区数据
env.setParallelism(4);
/*
//设置CK相关配置
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
StateBackend fsStateBackend = new FsStateBackend("hdfs://hadoop:8020/gmall/flink/checkpoint/OrderWideApp");
env.setStateBackend(fsStateBackend);
System.setProperty("HADOOP_USER_NAME", "yyds");
*/
//TODO 1.从Kafka的dwd层接收订单和订单明细数据
String orderInfoSourceTopic = "dwd_order_info";
String orderDetailSourceTopic = "dwd_order_detail";
String orderWideSinkTopic = "dwm_order_wide";
String groupId = "order_wide_group";
//从Kafka中读取数据
FlinkKafkaConsumer sourceOrderInfo = MyKafkaUtil.getKafkaSource(orderInfoSourceTopic,groupId);
FlinkKafkaConsumer sourceOrderDetail = MyKafkaUtil.getKafkaSource(orderDetailSourceTopic,groupId);
DataStream orderInfojsonDStream = env.addSource(sourceOrderInfo);
DataStream orderDetailJsonDStream = env.addSource(sourceOrderDetail);
//对读取的数据进行结构的转换
DataStream orderInfoDStream = orderInfojsonDStream.map(
new RichMapFunction() {
SimpleDateFormat simpleDateFormat=null;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
simpleDateFormat=new SimpleDateFormat("yyyy-MM-dd");
}
@Override
public OrderInfo map(String jsonString) throws Exception {
OrderInfo orderInfo = JSON.parseObject(jsonString, OrderInfo.class);
orderInfo.setCreate_ts(simpleDateFormat.parse(orderInfo.getCreate_time()).getTime());
return orderInfo;
}
}
);
DataStream orderDetailDStream = orderDetailJsonDStream.map(new RichMapFunction() {
SimpleDateFormat simpleDateFormat=null;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
simpleDateFormat=new SimpleDateFormat("yyyy-MM-dd");
}
@Override
public OrderDetail map(String jsonString) throws Exception {
OrderDetail orderDetail = JSON.parseObject(jsonString, OrderDetail.class);
orderDetail.setCreate_ts (simpleDateFormat.parse(orderDetail.getCreate_time()).getTime());
return orderDetail;
}
});
orderInfoDStream.print("orderInfo::::");
orderDetailDStream.print("orderDetail::::");
env.execute();
}
} 测试:
- 启动Maxwell、zk、kafka、hdfs、hbase
- 运行Idea中的BaseDBApp
- 运行Idea中的OrderWideApp
- 在数据库gmall2021_realtime的配置表中配置订单和订单明细
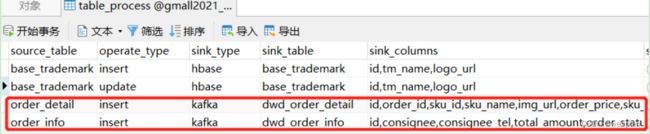
注意:会根据配置分流dwd层,dwd层还是保留的原始数据,所有我们这里sink_columns的内容和数据库表中的字段保持一致,可以使用文本编辑工具处理。
- 执行rt_dblog下的jar,生成模拟数据
- 查看控制台输出
- 执行流程
业务数据生成->Maxwell同步->Kafka的ods_base_db_m主题->BaseDBApp分流写回kafka->dwd_order_info和dwd_order_detail->OrderWideApp从kafka的dwd层读数据,打印输出
2)订单和订单明细关联(双流join)
在flink中的流join大体分为两种,一种是基于时间窗口的join(Time Windowed Join),比如join、coGroup等。另一种是基于状态缓存的join(Temporal Table Join),比如intervalJoin。
这里选用intervalJoin,因为相比较窗口join,intervalJoin使用更简单,而且避免了应匹配的数据处于不同窗口的问题。intervalJoin目前只有一个问题,就是还不支持left join。
但是我们这里是订单主表与订单从表之间的关联不需要left join,所以intervalJoin是较好的选择。
设定事件时间水位线:
//TODO 2.设定事件时间水位
SingleOutputStreamOperator orderInfoWithEventTimeDstream = orderInfoDStream.assignTimestampsAndWatermarks(
WatermarkStrategy.forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(OrderInfo orderInfo, long recordTimestamp) {
return orderInfo.getCreate_ts();
}
})
);
SingleOutputStreamOperator orderDetailWithEventTimeDstream = orderDetailDStream.assignTimestampsAndWatermarks(
WatermarkStrategy.forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(OrderDetail orderDetail, long recordTimestamp) {
return orderDetail.getCreate_ts();
}
})); 创建合并后的宽表实体类:
package com.yyds.gmall.realtime.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.commons.lang3.ObjectUtils;
import java.math.BigDecimal;
/**
* Author: Felix
* Desc: 订单和订单明细关联宽表对应实体类
*/
@Data
@AllArgsConstructor
public class OrderWide {
Long detail_id;
Long order_id ;
Long sku_id;
BigDecimal order_price ;
Long sku_num ;
String sku_name;
Long province_id;
String order_status;
Long user_id;
BigDecimal total_amount;
BigDecimal activity_reduce_amount;
BigDecimal coupon_reduce_amount;
BigDecimal original_total_amount;
BigDecimal feight_fee;
BigDecimal split_feight_fee;
BigDecimal split_activity_amount;
BigDecimal split_coupon_amount;
BigDecimal split_total_amount;
String expire_time;
String create_time;
String operate_time;
String create_date; // 把其他字段处理得到
String create_hour;
String province_name;//查询维表得到
String province_area_code;
String province_iso_code;
String province_3166_2_code;
Integer user_age ;
String user_gender;
Long spu_id; //作为维度数据 要关联进来
Long tm_id;
Long category3_id;
String spu_name;
String tm_name;
String category3_name;
public OrderWide(OrderInfo orderInfo, OrderDetail orderDetail){
mergeOrderInfo(orderInfo);
mergeOrderDetail(orderDetail);
}
public void mergeOrderInfo(OrderInfo orderInfo ) {
if (orderInfo != null) {
this.order_id = orderInfo.id;
this.order_status = orderInfo.order_status;
this.create_time = orderInfo.create_time;
this.create_date = orderInfo.create_date;
this.activity_reduce_amount = orderInfo.activity_reduce_amount;
this.coupon_reduce_amount = orderInfo.coupon_reduce_amount;
this.original_total_amount = orderInfo.original_total_amount;
this.feight_fee = orderInfo.feight_fee;
this.total_amount = orderInfo.total_amount;
this.province_id = orderInfo.province_id;
this.user_id = orderInfo.user_id;
}
}
public void mergeOrderDetail(OrderDetail orderDetail ) {
if (orderDetail != null) {
this.detail_id = orderDetail.id;
this.sku_id = orderDetail.sku_id;
this.sku_name = orderDetail.sku_name;
this.order_price = orderDetail.order_price;
this.sku_num = orderDetail.sku_num;
this.split_activity_amount=orderDetail.split_activity_amount;
this.split_coupon_amount=orderDetail.split_coupon_amount;
this.split_total_amount=orderDetail.split_total_amount;
}
}
public void mergeOtherOrderWide(OrderWide otherOrderWide){
this.order_status = ObjectUtils.firstNonNull( this.order_status ,otherOrderWide.order_status);
this.create_time = ObjectUtils.firstNonNull(this.create_time,otherOrderWide.create_time);
this.create_date = ObjectUtils.firstNonNull(this.create_date,otherOrderWide.create_date);
this.coupon_reduce_amount = ObjectUtils.firstNonNull(this.coupon_reduce_amount,otherOrderWide.coupon_reduce_amount);
this.activity_reduce_amount = ObjectUtils.firstNonNull(this.activity_reduce_amount,otherOrderWide.activity_reduce_amount);
this.original_total_amount = ObjectUtils.firstNonNull(this.original_total_amount,otherOrderWide.original_total_amount);
this.feight_fee = ObjectUtils.firstNonNull( this.feight_fee,otherOrderWide.feight_fee);
this.total_amount = ObjectUtils.firstNonNull( this.total_amount,otherOrderWide.total_amount);
this.user_id = ObjectUtils.firstNonNull(this.user_id,otherOrderWide.user_id);
this.sku_id = ObjectUtils.firstNonNull( this.sku_id,otherOrderWide.sku_id);
this.sku_name = ObjectUtils.firstNonNull(this.sku_name,otherOrderWide.sku_name);
this.order_price = ObjectUtils.firstNonNull(this.order_price,otherOrderWide.order_price);
this.sku_num = ObjectUtils.firstNonNull( this.sku_num,otherOrderWide.sku_num);
this.split_activity_amount=ObjectUtils.firstNonNull(this.split_activity_amount);
this.split_coupon_amount=ObjectUtils.firstNonNull(this.split_coupon_amount);
this.split_total_amount=ObjectUtils.firstNonNull(this.split_total_amount);
}
} 设定关联的key:
//TODO 3.设定关联的key
KeyedStream orderInfoKeyedDstream = orderInfoWithEventTimeDstream.keyBy(orderInfo -> orderInfo.getId());
KeyedStream orderDetailKeyedStream = orderDetailWithEventTimeDstream.keyBy(orderDetail -> orderDetail.getOrder_id()); 订单和订单明细关联 intervalJoin:
这里设置了正负5秒,以防止在业务系统中主表与从表保存的时间差。
//TODO 4.订单和订单明细关联 intervalJoin
SingleOutputStreamOperator orderWideDstream = orderInfoKeyedDstream.intervalJoin(orderDetailKeyedStream)
.between(Time.seconds(-5), Time.seconds(5))
.process(new ProcessJoinFunction() {
@Override
public void processElement(OrderInfo orderInfo, OrderDetail orderDetail, Context ctx, Collector out) throws Exception {
out.collect(new OrderWide(orderInfo, orderDetail));
}
});
orderWideDstream.print("joined ::"); 测试:
测试过程和上面测试读取数据过程一样。
6、维表关联代码实现
维度关联实际上就是在流中查询存储在hbase中的数据表。但是即使通过主键的方式查询,hbase速度的查询也是不及流之间的join。外部数据源的查询常常是流式计算的性能瓶颈,所以咱们再这个基础上还有进行一定的优化。
1. 先实现基本的维度查询功能
封装Phoenix查询的工具类PhoenixUtil:
package com.yyds.gmall.realtime.utils;
import com.alibaba.fastjson.JSONObject;
import com.yyds.gmall.realtime.common.GmallConfig;
import org.apache.commons.beanutils.BeanUtils;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
/**
* Author: Felix
* Desc: 查询Phoenix的工具类
*/
public class PhoenixUtil {
public static Connection conn = null;
public static void main(String[] args) {
List objectList = queryList("select * from base_trademark", JSONObject.class);
System.out.println(objectList);
}
public static void queryInit() {
try {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
conn = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
conn.setSchema(GmallConfig.HBASE_SCHEMA);
} catch (Exception e) {
e.printStackTrace();
}
}
public static List queryList(String sql, Class clazz) {
if (conn == null) {
queryInit();
}
List resultList = new ArrayList();
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
ResultSetMetaData md = rs.getMetaData();
while (rs.next()) {
T rowData = clazz.newInstance();
for (int i = 1; i <= md.getColumnCount(); i++) {
BeanUtils.setProperty(rowData, md.getColumnName(i), rs.getObject(i));
}
resultList.add(rowData);
}
ps.close();
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
return resultList;
}
} 封装查询维度的工具类DimUtil(直接查询Phoenix):
package com.yyds.gmall.realtime.utils;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.java.tuple.Tuple2;
import java.util.List;
/**
* Author: Felix
* Desc: 查询维度的工具类
*/
public class DimUtil {
//直接从Phoenix查询,没有缓存
public static JSONObject getDimInfoNoCache(String tableName, Tuple2... colNameAndValue) {
//组合查询条件
String wheresql = new String(" where ");
for (int i = 0; i < colNameAndValue.length; i++) {
//获取查询列名以及对应的值
Tuple2 nameValueTuple = colNameAndValue[i];
String fieldName = nameValueTuple.f0;
String fieldValue = nameValueTuple.f1;
if (i > 0) {
wheresql += " and ";
}
wheresql += fieldName + "='" + fieldValue + "'";
}
//组合查询SQL
String sql = "select * from " + tableName + wheresql;
System.out.println("查询维度SQL:" + sql);
JSONObject dimInfoJsonObj = null;
List dimList = PhoenixUtil.queryList(sql, JSONObject.class);
if (dimList != null && dimList.size() > 0) {
//因为关联维度,肯定都是根据key关联得到一条记录
dimInfoJsonObj = dimList.get(0);
}else{
System.out.println("维度数据未找到:" + sql);
}
return dimInfoJsonObj;
}
public static void main(String[] args) {
JSONObject dimInfooNoCache = DimUtil.getDimInfooNoCache("base_trademark", Tuple2.of("id", "13"));
System.out.println(dimInfooNoCache);
}
} 2. 运行main方法测试
优化1:加入旁路缓存模式 (cache-aside-pattern)
我们在上面实现的功能中,直接查询的Hbase。外部数据源的查询常常是流式计算的性能瓶颈,所以我们需要在上面实现的基础上进行一定的优化。我们这里使用旁路缓存。
旁路缓存模式是一种非常常见的按需分配缓存的模式。如下图,任何请求优先访问缓存,缓存命中,直接获得数据返回请求。如果未命中则,查询数据库,同时把结果写入缓存以备后续请求使用。

这种缓存策略有几个注意点:
缓存要设过期时间,不然冷数据会常驻缓存浪费资源。
要考虑维度数据是否会发生变化,如果发生变化要主动清除缓存。
缓存的选型:
一般两种:堆缓存或者独立缓存服务(redis,memcache)。
- 堆缓存,从性能角度看更好,毕竟访问数据路径更短,减少过程消耗。但是管理性差,其他进程无法维护缓存中的数据。
- 独立缓存服务(redis,memcache)本事性能也不错,不过会有创建连接、网络IO等消耗。但是考虑到数据如果会发生变化,那还是独立缓存服务管理性更强,而且如果数据量特别大,独立缓存更容易扩展。
因为咱们的维度数据都是可变数据,所以这里还是采用Redis管理缓存。
代码实现:
在pom.xml文件中添加Redis的依赖包:
redis.clients
jedis
3.3.0
封装RedisUtil,通过连接池获得Jedis:
package com.yyds.gmall.realtime.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* Author: Felix
* Desc: 通过连接池获取Jedis的工具类
*/
public class RedisUtil {
public static JedisPool jedisPool=null;
public static Jedis getJedis(){
if(jedisPool==null){
JedisPoolConfig jedisPoolConfig =new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(100); //最大可用连接数
jedisPoolConfig.setBlockWhenExhausted(true); //连接耗尽是否等待
jedisPoolConfig.setMaxWaitMillis(2000); //等待时间
jedisPoolConfig.setMaxIdle(5); //最大闲置连接数
jedisPoolConfig.setMinIdle(5); //最小闲置连接数
jedisPoolConfig.setTestOnBorrow(true); //取连接的时候进行一下测试 ping pong
jedisPool=new JedisPool( jedisPoolConfig, "hadoop202",6379 ,1000);
System.out.println("开辟连接池");
return jedisPool.getResource();
}else{
System.out.println(" 连接池:"+jedisPool.getNumActive());
return jedisPool.getResource();
}
}
}在DimUtil中加入缓存,如果缓存没有再从的Phoenix查询:
//先从Redis中查,如果缓存中没有再通过Phoenix查询 固定id进行关联
public static JSONObject getDimInfo(String tableName, String id) {
Tuple2 kv = Tuple2.of("id", id);
return getDimInfo(tableName, kv);
}
//先从Redis中查,如果缓存中没有再通过Phoenix查询 可以使用其它字段灵活关联
public static JSONObject getDimInfo(String tableName, Tuple2... colNameAndValue) {
//组合查询条件
String wheresql = " where ";
String redisKey = "";
for (int i = 0; i < colNameAndValue.length; i++) {
Tuple2 nameValueTuple = colNameAndValue[i];
String fieldName = nameValueTuple.f0;
String fieldValue = nameValueTuple.f1;
if (i > 0) {
wheresql += " and ";
// 根据查询条件组合redis key ,
redisKey += "_";
}
wheresql += fieldName + "='" + fieldValue + "'";
redisKey += fieldValue;
}
Jedis jedis = null;
String dimJson = null;
JSONObject dimInfo = null;
String key = "dim:" + tableName.toLowerCase() + ":" + redisKey;
try {
// 从连接池获得连接
jedis = RedisUtil.getJedis();
// 通过key查询缓存
dimJson = jedis.get(key);
} catch (Exception e) {
System.out.println("缓存异常!");
e.printStackTrace();
}
if (dimJson != null) {
dimInfo = JSON.parseObject(dimJson);
} else {
String sql = "select * from " + tableName + wheresql;
System.out.println("查询维度sql:" + sql);
List dimList = PhoenixUtil.queryList(sql, JSONObject.class);
if (dimList.size() > 0) {
dimInfo = dimList.get(0);
if (jedis != null) {
//把从数据库中查询的数据同步到缓存
jedis.setex(key, 3600 * 24, dimInfo.toJSONString());
}
} else {
System.out.println("维度数据未找到:" + sql);
}
}
if (jedis != null) {
jedis.close();
System.out.println("关闭缓存连接 ");
}
return dimInfo;
} 运行main方法测试和前面直接查询对比:
使用缓存后,查询时间明显小于没有使用缓存之前。
在DimUtil中增加失效缓存的方法:
维表数据变化时要失效缓存。
//根据key让Redis中的缓存失效
public static void deleteCached( String tableName, String id){
String key = "dim:" + tableName.toLowerCase() + ":" + id;
try {
Jedis jedis = RedisUtil.getJedis();
// 通过key清除缓存
jedis.del(key);
jedis.close();
} catch (Exception e) {
System.out.println("缓存异常!");
e.printStackTrace();
}
}修改DimSink的invoke方法:
如果维度数据发生了变化,同时失效该数据对应的Redis中的缓存。
public void invoke(JSONObject jsonObject, Context context) throws Exception {
String tableName = jsonObject.getString("sink_table");
JSONObject dataJsonObj = jsonObject.getJSONObject("data");
if (dataJsonObj != null && dataJsonObj.size() > 0) {
String upsertSql = genUpsertSql(tableName.toUpperCase(), jsonObject.getJSONObject("data"));
try {
System.out.println(upsertSql);
PreparedStatement ps = connection.prepareStatement(upsertSql);
ps.executeUpdate();
connection.commit();
ps.close();
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("执行sql失败!");
}
}
//如果维度数据发生变化,那么清空当前数据在Redis中的缓存
if(jsonObject.getString("type").equals("update")
||jsonObject.getString("type").equals("delete")){
DimUtil.deleteCached(tableName,dataJsonObj.getString("id"));
}
}思考:应该先失效缓存还是先写入数据库,为什么?
先写入数据库,再失效缓存。
测试:
- 启动Maxwell、ZK、Kafka、HDFS、Hbase、Redis
- 确定在Redis中存在某一个维度数据的缓存,如果没有运行DimUtil的main方法生成
- 运行Idea中的BaseDBApp
- 修改数据库gmall2021中的维度表和Redis缓存对应的数据,该数据会通过Maxwell同步到Kafka,然后BaseDBApp同步到Hbase的维度表中
- 查看Redis中的缓存是否被删除了
优化2:异步查询
在Flink 流处理过程中,经常需要和外部系统进行交互,用维度表补全事实表中的字段。
例如:在电商场景中,需要一个商品的skuid去关联商品的一些属性,例如商品所属行业、商品的生产厂家、生产厂家的一些情况;在物流场景中,知道包裹id,需要去关联包裹的行业属性、发货信息、收货信息等等。
默认情况下,在Flink的MapFunction中,单个并行只能用同步方式去交互: 将请求发送到外部存储,IO阻塞,等待请求返回,然后继续发送下一个请求。这种同步交互的方式往往在网络等待上就耗费了大量时间。为了提高处理效率,可以增加MapFunction的并行度,但增加并行度就意味着更多的资源,并不是一种非常好的解决方式。
Flink 在1.2中引入了Async I/O,在异步模式下,将IO操作异步化,单个并行可以连续发送多个请求,哪个请求先返回就先处理,从而在连续的请求间不需要阻塞式等待,大大提高了流处理效率。
Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,解决与外部系统交互时网络延迟成为了系统瓶颈的问题。
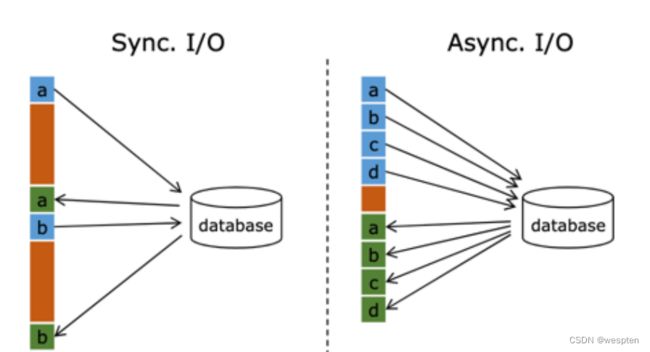
异步查询实际上是把维表的查询操作托管给单独的线程池完成,这样不会因为某一个查询造成阻塞,单个并行可以连续发送多个请求,提高并发效率。
这种方式特别针对涉及网络IO的操作,减少因为请求等待带来的消耗。
封装线程池工具类:
package com.yyds.gmall.realtime.utils;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* Author: Felix
* Desc: 线程池工具类
*/
public class ThreadPoolUtil {
public static ThreadPoolExecutor pool;
/*
获取单例的线程池对象
corePoolSize:指定了线程池中的线程数量,它的数量决定了添加的任务是开辟新的线程去执行,还是放到workQueue任务队列中去;
maximumPoolSize:指定了线程池中的最大线程数量,这个参数会根据你使用的workQueue任务队列的类型,决定线程池会开辟的最大线程数量;
keepAliveTime:当线程池中空闲线程数量超过corePoolSize时,多余的线程会在多长时间内被销毁;
unit:keepAliveTime的单位
workQueue:任务队列,被添加到线程池中,但尚未被执行的任务
*/
public static ThreadPoolExecutor getInstance() {
if (pool == null) {
synchronized (ThreadPoolUtil.class) {
if (pool == null) {
System.out.println ("开辟程池!!!!!");
pool=new ThreadPoolExecutor(4, 20, 300, TimeUnit.SECONDS,
new LinkedBlockingDeque(Integer.MAX_VALUE));
}
}
}
return pool;
}
} 自定义维度查询接口:
这个异步维表查询的方法适用于各种维表的查询,用什么条件查,查出来的结果如何合并到数据流对象中,需要使用者自己定义。
这就是自己定义了一个接口DimJoinFunction<T>包括两个方法。
package com.yyds.gmall.realtime.app.func;
import com.alibaba.fastjson.JSONObject;
/**
* Author: Felix
* Desc: 维度关联查询的接口
*/
public interface DimJoinFunction {
/**
* 需要实现如何把结果装配给数据流对象
* @param t 数据流对象
* @param jsonObject 异步查询结果
* @throws Exception
*/
public void join(T t , JSONObject jsonObject) throws Exception;
/**
* 需要实现如何从流中对象获取主键
* @param t 数据流对象
*/
public String getKey(T t);
} 封装维度异步查询的函数类DimAsyncFunction
该类继承异步方法类RichAsyncFunction,实现自定义维度查询接口。
其中RichAsyncFunction
RichAsyncFunction这个类要实现两个方法:
- open用于初始化异步连接池。
- asyncInvoke方法是核心方法,里面的操作必须是异步的,如果你查询的数据库有异步api也可以用线程的异步方法,如果没有异步方法,就要自己利用线程池等方式实现异步查询。
package com.yyds.gmall.realtime.app.func;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import java.util.Arrays;
import java.util.concurrent.ExecutorService;
/**
* Author: Felix
* Desc: 自定义维度查询异步执行函数
* RichAsyncFunction: 里面的方法负责异步查询
* DimJoinFunction: 里面的方法负责将为表和主流进行关联
*/
public abstract class DimAsyncFunction extends RichAsyncFunction implements DimJoinFunction{
ExecutorService executorService = null;
public String tableName=null;
public DimAsyncFunction(String tableName){
this.tableName=tableName;
}
public void open(Configuration parameters ) {
System.out.println ("获得线程池! ");
executorService = ThreadPoolUtil.getInstance() ;
}
@Override
public void asyncInvoke(T obj, ResultFuture resultFuture) throws Exception {
executorService.submit(new Runnable() {
@Override
public void run() {
try {
long start = System.currentTimeMillis();
//从流对象中获取主键
String key = getKey(obj);
//根据主键获取维度对象数据
JSONObject dimJsonObject = DimUtil.getDimInfo(tableName,key);
System.out.println("dimJsonObject:"+dimJsonObject);
if(dimJsonObject!=null){
//维度数据和流数据关联
join(obj,dimJsonObject) ;
}
System.out.println("obj:"+obj);
long end = System.currentTimeMillis();
System.out.println("异步耗时:"+(end-start)+"毫秒");
resultFuture.complete(Arrays.asList(obj));
} catch ( Exception e) {
System.out.println(String.format(tableName+"异步查询异常. %s", e));
e.printStackTrace();
}
}
});
}
} - 如何使用这个DimAsyncFunction:
核心的类是AsyncDataStream,这个类有两个方法一个是有序等待(orderedWait),一个是无序等待(unorderedWait)。
- 无序等待(unorderedWait)
后来的数据,如果异步查询速度快可以超过先来的数据,这样性能会更好一些,但是会有乱序出现。
- 有序等待(orderedWait)
严格保留先来后到的顺序,所以后来的数据即使先完成也要等前面的数据。所以性能会差一些。
注意:
- 这里实现了用户维表的查询,那么必须重写装配结果join方法和获取查询rowkey的getKey方法。
- 方法的最后两个参数10, TimeUnit.SECONDS ,标识次异步查询最多执行10秒,否则会报超时异常。
关联用户维度(在OrderWideApp中):
//TODO 5.关联用户维度
SingleOutputStreamOperator orderWideWithUserDstream = AsyncDataStream.unorderedWait(
orderWideDstream, new DimAsyncFunction("DIM_USER_INFO") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws Exception {
SimpleDateFormat formattor = new SimpleDateFormat("yyyy-MM-dd");
String birthday = jsonObject.getString("BIRTHDAY");
Date date = formattor.parse(birthday);
Long curTs = System.currentTimeMillis();
Long betweenMs = curTs - date.getTime();
Long ageLong = betweenMs / 1000L / 60L / 60L / 24L / 365L;
Integer age = ageLong.intValue();
orderWide.setUser_age(age);
orderWide.setUser_gender(jsonObject.getString("GENDER"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getUser_id());
}
}, 60, TimeUnit.SECONDS);
orderWideWithUserDstream.print("dim join user:"); 测试用户维度关联:
- 将table_process表中的数据删除掉,执行2.资料的table_process初始配置.sql
- 启动Maxwell、ZK、Kafka、HDFS、Hbase、Redis
- 运行运行Idea中的BaseDBApp
- 初始化用户维度数据到Hbase(通过Maxwell的Bootstrap)
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop202 --database gmall2021 --table user_info --client_id maxwell_1- 运行Idea中的OrderWideApp
- 执行模拟生成业务数据的jar包
- 查看控制台输出可以看到用户的年龄以及性别
关联省市维度:
//TODO 6.关联省市维度
SingleOutputStreamOperator orderWideWithProvinceDstream = AsyncDataStream.unorderedWait(
orderWideWithUserDstream, new DimAsyncFunction("DIM_BASE_PROVINCE") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws Exception {
orderWide.setProvince_name(jsonObject.getString("NAME"));
orderWide.setProvince_3166_2_code(jsonObject.getString("ISO_3166_2"));
orderWide.setProvince_iso_code(jsonObject.getString("ISO_CODE"));
orderWide.setProvince_area_code(jsonObject.getString("AREA_CODE"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getProvince_id());
}
}, 60, TimeUnit.SECONDS); 初始化省市维度数据到Hbase(通过Maxwell的Bootstrap):
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop202 --database gmall2021 --table base_province --client_id maxwell_1测试省市维度关联:
关联SKU维度:
//TODO 7.关联SKU维度
SingleOutputStreamOperator orderWideWithSkuDstream = AsyncDataStream.unorderedWait(
orderWideWithProvinceDstream, new DimAsyncFunction("DIM_SKU_INFO") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws Exception {
orderWide.setSku_name(jsonObject.getString("SKU_NAME"));
orderWide.setCategory3_id(jsonObject.getLong("CATEGORY3_ID"));
orderWide.setSpu_id(jsonObject.getLong("SPU_ID"));
orderWide.setTm_id(jsonObject.getLong("TM_ID"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getSku_id());
}
}, 60, TimeUnit.SECONDS); 初始化SKU维度数据到Hbase(通过Maxwell的Bootstrap):
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop202 --database gmall2021 --table sku_info --client_id maxwell_1- 测试SKU维度关联
关联SPU维度:
//TODO 8.关联SPU商品维度
SingleOutputStreamOperator orderWideWithSpuDstream = AsyncDataStream.unorderedWait(
orderWideWithSkuDstream, new DimAsyncFunction("DIM_SPU_INFO") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws Exception {
orderWide.setSpu_name(jsonObject.getString("SPU_NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getSpu_id());
}
}, 60, TimeUnit.SECONDS); - 初始化SPU维度数据到Hbase(通过Maxwell的Bootstrap)
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop202 --database gmall2021 --table spu_info --client_id maxwell_1- 测试SPU维度关联
关联品类维度:
//TODO 9.关联品类维度
SingleOutputStreamOperator orderWideWithCategory3Dstream = AsyncDataStream.unorderedWait(
orderWideWithSpuDstream, new DimAsyncFunction("DIM_BASE_CATEGORY3") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws Exception {
orderWide.setCategory3_name(jsonObject.getString("NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getCategory3_id());
}
}, 60, TimeUnit.SECONDS); - 初始化品类维度数据到Hbase(通过Maxwell的Bootstrap)
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop202 --database gmall2021 --table base_category3 --client_id maxwell_1- 测试品类维度关联
关联品牌维度:
//TODO 10.关联品牌维度
SingleOutputStreamOperator orderWideWithTmDstream = AsyncDataStream.unorderedWait(
orderWideWithCategory3Dstream, new DimAsyncFunction("DIM_BASE_TRADEMARK") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws Exception {
orderWide.setTm_name(jsonObject.getString("TM_NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getTm_id());
}
}, 60, TimeUnit.SECONDS); - 初始化品牌维度数据到Hbase(通过Maxwell的Bootstrap)
bin/maxwell-bootstrap --user maxwell --password 123456 --host hadoop202 --database gmall2021 --table base_trademark --client_id maxwell_1- 测试整体维度关联
3. 结果写入kafka sink
//TODO 11.将订单和订单明细Join之后以及维度关联的宽表写到Kafka的dwm层
orderWideWithTmDstream.map(orderWide -> JSON.toJSONString(orderWide))
.addSink(MyKafkaUtil.getKafkaSink(orderWideSinkTopic));7、DWM层-支付宽表
1. 需求分析与思路
支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上,没有办法统计商品级的支付状况。
所以本次宽表的核心就是要把支付表的信息与订单明细关联上。
解决方案有两个:
- 一个是把订单明细表(或者宽表)输出到Hbase上,在支付宽表计算时查询hbase,这相当于把订单明细作为一种维度进行管理。
- 一个是用流的方式接收订单明细,然后用双流join方式进行合并。因为订单与支付产生有一定的时差。所以必须用intervalJoin来管理流的状态时间,保证当支付到达时订单明细还保存在状态中。
2. 功能实现参考
创建支付实体类PaymentInfo:
package com.yyds.gmall.realtime.bean;
import lombok.Data;
import java.math.BigDecimal;
/**
* Author: Felix
* Desc: 支付信息实体类
*/
@Data
public class PaymentInfo {
Long id;
Long order_id;
Long user_id;
BigDecimal total_amount;
String subject;
String payment_type;
String create_time;
String callback_time;
}创建支付宽表实体类PaymentWide:
package com.yyds.gmall.realtime.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.beanutils.BeanUtils;
import java.lang.reflect.InvocationTargetException;
import java.math.BigDecimal;
/**
* Author: Felix
* Desc: 支付宽表实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class PaymentWide {
Long payment_id;
String subject;
String payment_type;
String payment_create_time;
String callback_time;
Long detail_id;
Long order_id ;
Long sku_id;
BigDecimal order_price ;
Long sku_num ;
String sku_name;
Long province_id;
String order_status;
Long user_id;
BigDecimal total_amount;
BigDecimal activity_reduce_amount;
BigDecimal coupon_reduce_amount;
BigDecimal original_total_amount;
BigDecimal feight_fee;
BigDecimal split_feight_fee;
BigDecimal split_activity_amount;
BigDecimal split_coupon_amount;
BigDecimal split_total_amount;
String order_create_time;
String province_name;//查询维表得到
String province_area_code;
String province_iso_code;
String province_3166_2_code;
Integer user_age ;
String user_gender;
Long spu_id; //作为维度数据 要关联进来
Long tm_id;
Long category3_id;
String spu_name;
String tm_name;
String category3_name;
public PaymentWide(PaymentInfo paymentInfo, OrderWide orderWide){
mergeOrderWide(orderWide);
mergePaymentInfo(paymentInfo);
}
public void mergePaymentInfo(PaymentInfo paymentInfo ) {
if (paymentInfo != null) {
try {
BeanUtils.copyProperties(this,paymentInfo);
payment_create_time=paymentInfo.create_time;
payment_id = paymentInfo.id;
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
public void mergeOrderWide(OrderWide orderWide ) {
if (orderWide != null) {
try {
BeanUtils.copyProperties(this,orderWide);
order_create_time=orderWide.create_time;
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
}支付宽表处理主程序:
package com.yyds.gmall.realtime.app.dwm;
import com.alibaba.fastjson.JSON;
import com.yyds.gmall.realtime.bean.OrderWide;
import com.yyds.gmall.realtime.bean.PaymentInfo;
import com.yyds.gmall.realtime.bean.PaymentWide;
import com.yyds.gmall.realtime.utils.DateTimeUtil;
import com.yyds.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.time.Duration;
/**
* Author: Felix
* Desc:支付宽表处理主程序
*/
public class PaymentWideApp {
public static void main(String[] args) throws Exception {
//TODO 0.基本环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
/*
//设置CK相关配置
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
StateBackend fsStateBackend = new FsStateBackend("hdfs://hadoop:8020/gmall/flink/checkpoint/OrderWideApp");
env.setStateBackend(fsStateBackend);
System.setProperty("HADOOP_USER_NAME", "yyds");
*/
//TODO 1.接收数据流
String groupId = "payment_wide_group";
String paymentInfoSourceTopic = "dwd_payment_info";
String orderWideSourceTopic = "dwm_order_wide";
String paymentWideSinkTopic = "dwm_payment_wide";
//封装Kafka消费者 读取支付流数据
FlinkKafkaConsumer paymentInfoSource = MyKafkaUtil.getKafkaSource(paymentInfoSourceTopic, groupId);
DataStream paymentInfojsonDstream = env.addSource(paymentInfoSource);
//对读取的支付数据进行转换
DataStream paymentInfoDStream =
paymentInfojsonDstream.map(jsonString -> JSON.parseObject(jsonString, PaymentInfo.class));
//封装Kafka消费者 读取订单宽表流数据
FlinkKafkaConsumer orderWideSource = MyKafkaUtil.getKafkaSource(orderWideSourceTopic, groupId);
DataStream orderWidejsonDstream = env.addSource(orderWideSource);
//对读取的订单宽表数据进行转换
DataStream orderWideDstream =
orderWidejsonDstream.map(jsonString -> JSON.parseObject(jsonString, OrderWide.class));
//设置水位线
SingleOutputStreamOperator paymentInfoEventTimeDstream =
paymentInfoDStream.assignTimestampsAndWatermarks(
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(
(paymentInfo, ts) -> DateTimeUtil.toTs(paymentInfo.getCallback_time())
));
SingleOutputStreamOperator orderInfoWithEventTimeDstream =
orderWideDstream.assignTimestampsAndWatermarks(WatermarkStrategy.
forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(
(orderWide, ts) -> DateTimeUtil.toTs(orderWide.getCreate_time())
)
);
//设置分区键
KeyedStream paymentInfoKeyedStream =
paymentInfoEventTimeDstream.keyBy(PaymentInfo::getOrder_id);
KeyedStream orderWideKeyedStream =
orderInfoWithEventTimeDstream.keyBy(OrderWide::getOrder_id);
//关联数据
SingleOutputStreamOperator paymentWideDstream =
paymentInfoKeyedStream.intervalJoin(orderWideKeyedStream).
between(Time.seconds(-1800), Time.seconds(0)).
process(new ProcessJoinFunction() {
@Override
public void processElement(PaymentInfo paymentInfo,
OrderWide orderWide,
Context ctx, Collector out) throws Exception {
out.collect(new PaymentWide(paymentInfo, orderWide));
}
}).uid("payment_wide_join");
SingleOutputStreamOperator paymentWideStringDstream = paymentWideDstream.map(paymentWide -> JSON.toJSONString(paymentWide));
paymentWideStringDstream.print("pay:");
paymentWideStringDstream.addSink(
MyKafkaUtil.getKafkaSink(paymentWideSinkTopic));
env.execute();
}
} 封装日期转换工具类:
package com.yyds.gmall.realtime.utils;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
import java.util.Date;
/**
* Author: Felix
* Desc:日期转换工具类
JDK8的DateTimeFormatter替换SimpleDateFormat,因为SimpleDateFormat存在线程安全问题
*/
public class DateTimeUtil {
public final static DateTimeFormatter formator = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public static String toYMDhms(Date date) {
LocalDateTime localDateTime = LocalDateTime.ofInstant(date.toInstant(), ZoneId.systemDefault());
return formator.format(localDateTime);
}
public static Long toTs(String YmDHms) {
// System.out.println ("YmDHms:"+YmDHms);
LocalDateTime localDateTime = LocalDateTime.parse(YmDHms, formator);
long ts = localDateTime.toInstant(ZoneOffset.of("+8")).toEpochMilli();
return ts;
}
}总结:
DWM层部分的代码主要的责任,是通过计算把一种明细转变为另一种明细以应对后续的统计。学完本阶段内容要求掌握
- 学会利用状态(state)进行去重操作。(需求:UV计算)
- 学会利用CEP可以针对一组数据进行筛选判断。需求:跳出行为计算
- 学会使用intervalJoin处理流join
- 学会处理维度关联,并通过缓存和异步查询对其进行性能优化。
六、DWS层业务实现
1、DWS层与DWM层的设计
1. 设计思路
我们在之前通过分流等手段,把数据分拆成了独立的kafka topic。那么接下来如何处理数据,就要思考一下我们到底要通过实时计算出哪些指标项。
因为实时计算与离线不同,实时计算的开发和运维成本都是非常高的,要结合实际情况考虑是否有必要象离线数仓一样,建一个大而全的中间层。
如果没有必要大而全,这时候就需要大体规划一下要实时计算出的指标需求了。把这些指标以主题宽表的形式输出就是我们的DWS层。
2. 需求梳理
| 统计主题 |
需求指标 |
输出方式 |
计算来源 |
来源层级 |
| 访客 |
pv |
可视化大屏 |
page_log直接可求 |
dwd |
| uv |
可视化大屏 |
需要用page_log过滤去重 |
dwm |
|
| 跳出次数 |
可视化大屏 |
需要通过page_log行为判断 |
dwm |
|
| 进入页面数 |
可视化大屏 |
需要识别开始访问标识 |
dwd |
|
| 连续访问时长 |
可视化大屏 |
page_log直接可求 |
dwd |
|
| 商品 |
点击 |
多维分析 |
page_log直接可求 |
dwd |
| 曝光 |
多维分析 |
page_log直接可求 |
dwd |
|
| 收藏 |
多维分析 |
收藏表 |
dwd |
|
| 加入购物车 |
多维分析 |
购物车表 |
dwd |
|
| 下单 |
可视化大屏 |
订单宽表 |
dwm |
|
| 支付 |
多维分析 |
支付宽表 |
dwm |
|
| 退款 |
多维分析 |
退款表 |
dwd |
|
| 评论 |
多维分析 |
评论表 |
dwd |
|
| 地区 |
pv |
多维分析 |
page_log直接可求 |
dwd |
| uv |
多维分析 |
需要用page_log过滤去重 |
dwm |
|
| 下单 |
可视化大屏 |
订单宽表 |
dwm |
|
| 关键词 |
搜索关键词 |
可视化大屏 |
页面访问日志 直接可求 |
dwd |
| 点击商品关键词 |
可视化大屏 |
商品主题下单再次聚合 |
dws |
|
| 下单商品关键词 |
可视化大屏 |
商品主题下单再次聚合 |
dws |
当然实际需求还会有更多,这里主要以为可视化大屏为目的进行实时计算的处理。
3. DWS层的定位是什么
- 轻度聚合,因为DWS层要应对很多实时查询,如果是完全的明细那么查询的压力是非常大的。
- 将更多的实时数据以主题的方式组合起来便于管理,同时也能减少维度查询的次数。
2、DWS层-访客主题计算
| 统计主题 |
需求指标 |
输出方式 |
计算来源 |
来源层级 |
| 访客 |
pv |
可视化大屏 |
page_log直接可求 |
dwd |
| uv |
可视化大屏 |
需要用page_log过滤去重 |
dwm |
|
| 跳出次数 |
可视化大屏 |
需要通过page_log行为判断 |
dwm |
|
| 进入页面数 |
可视化大屏 |
需要识别开始访问标识 |
dwd |
|
| 连续访问时长 |
可视化大屏 |
page_log直接可求 |
dwd |
设计一张DWS层的表其实就两件事:维度和度量(事实数据)
- 度量包括PV、UV、跳出次数、进入页面数(session_count)、连续访问时长
- 维度包括在分析中比较重要的几个字段:渠道、地区、版本、新老用户进行聚合
1. 需求分析与思路
- 接收各个明细数据,变为数据流
- 把数据流合并在一起,成为一个相同格式对象的数据流
- 对合并的流进行聚合,聚合的时间窗口决定了数据的时效性
- 把聚合结果写在数据库中
2. 功能实现
封装VisitorStatsApp,读取Kafka各个流数据:
package com.yyds.gmall.realtime.app.dws;
import com.yyds.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* Author: Felix
* Desc: 访客主题统计
*
* ?要不要把多个明细的同样的维度统计在一起?
* 因为单位时间内mid的操作数据非常有限不能明显的压缩数据量(如果是数据量够大,或者单位时间够长可以)
* 所以用常用统计的四个维度进行聚合 渠道、新老用户、app版本、省市区域
* 度量值包括 启动、日活(当日首次启动)、访问页面数、新增用户数、跳出数、平均页面停留时长、总访问时长
* 聚合窗口: 10秒
*
* 各个数据在维度聚合前不具备关联性 ,所以 先进行维度聚合
* 进行关联 这是一个fulljoin
* 可以考虑使用flinksql 完成
*/
public class VisitorStatsApp {
public static void main(String[] args) throws Exception {
//TODO 0.基本环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(4);
/*
//检查点CK相关设置
env.enableCheckpointing(5000, CheckpointingMode.AT_LEAST_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
StateBackend fsStateBackend = new FsStateBackend(
"hdfs://hadoop202:8020/gmall/flink/checkpoint/VisitorStatsApp");
env.setStateBackend(fsStateBackend);
System.setProperty("HADOOP_USER_NAME","yyds");
*/
String groupId = "visitor_stats_app";
//TODO 1.从Kafka的pv、uv、跳转明细主题中获取数据
String pageViewSourceTopic = "dwd_page_log";
String uniqueVisitSourceTopic = "dwm_unique_visit";
String userJumpDetailSourceTopic = "dwm_user_jump_detail";
FlinkKafkaConsumer pageViewSource = MyKafkaUtil.getKafkaSource(pageViewSourceTopic, groupId);
FlinkKafkaConsumer uniqueVisitSource = MyKafkaUtil.getKafkaSource(uniqueVisitSourceTopic, groupId);
FlinkKafkaConsumer userJumpSource = MyKafkaUtil.getKafkaSource(userJumpDetailSourceTopic, groupId);
DataStreamSource pageViewDStream = env.addSource(pageViewSource);
DataStreamSource uniqueVisitDStream = env.addSource(uniqueVisitSource);
DataStreamSource userJumpDStream = env.addSource(userJumpSource);
pageViewDStream.print("pv-------->");
uniqueVisitDStream.print("uv=====>");
userJumpDStream.print("uj--------->");
env.execute();
}
}
合并数据流:
把数据流合并在一起,成为一个相同格式对象的数据流。
合并数据流的核心算子是union。但是union算子,要求所有的数据流结构必须一致。所以union前要调整数据结构。
封装主题宽表实体类VisitorStats:
package com.yyds.gmall.realtime.bean;
/**
* Author: Felix
* Desc: 访客统计实体类 包括各个维度和度量
*/
@Data
@AllArgsConstructor
public class VisitorStats {
//统计开始时间
private String stt;
//统计结束时间
private String edt;
//维度:版本
private String vc;
//维度:渠道
private String ch;
//维度:地区
private String ar;
//维度:新老用户标识
private String is_new;
//度量:独立访客数
private Long uv_ct=0L;
//度量:页面访问数
private Long pv_ct=0L;
//度量: 进入次数
private Long sv_ct=0L;
//度量: 跳出次数
private Long uj_ct=0L;
//度量: 持续访问时间
private Long dur_sum=0L;
//统计时间
private Long ts;
}对读取的各个数据流进行结构的转换:
//TODO 2.对读取的流进行结构转换
//2.1 转换pv流
SingleOutputStreamOperator pageViewStatsDstream = pageViewDStream.map(
json -> {
// System.out.println("pv:"+json);
JSONObject jsonObj = JSON.parseObject(json);
return new VisitorStats("", "",
jsonObj.getJSONObject("common").getString("vc"),
jsonObj.getJSONObject("common").getString("ch"),
jsonObj.getJSONObject("common").getString("ar"),
jsonObj.getJSONObject("common").getString("is_new"),
0L, 1L, 0L, 0L, jsonObj.getJSONObject("page").getLong("during_time"), jsonObj.getLong("ts"));
});
//2.2转换uv流
SingleOutputStreamOperator uniqueVisitStatsDstream = uniqueVisitDStream.map(
json -> {
JSONObject jsonObj = JSON.parseObject(json);
return new VisitorStats("", "",
jsonObj.getJSONObject("common").getString("vc"),
jsonObj.getJSONObject("common").getString("ch"),
jsonObj.getJSONObject("common").getString("ar"),
jsonObj.getJSONObject("common").getString("is_new"),
1L, 0L, 0L, 0L, 0L, jsonObj.getLong("ts"));
});
//2.3 转换sv流
SingleOutputStreamOperator sessionVisitDstream = pageViewDStream.process(
new ProcessFunction() {
@Override
public void processElement(String json, Context ctx, Collector out) throws Exception {
JSONObject jsonObj = JSON.parseObject(json);
String lastPageId = jsonObj.getJSONObject("page").getString("last_page_id");
if (lastPageId == null || lastPageId.length() == 0) {
// System.out.println("sc:"+json);
VisitorStats visitorStats = new VisitorStats("", "",
jsonObj.getJSONObject("common").getString("vc"),
jsonObj.getJSONObject("common").getString("ch"),
jsonObj.getJSONObject("common").getString("ar"),
jsonObj.getJSONObject("common").getString("is_new"),
0L, 0L, 1L, 0L, 0L, jsonObj.getLong("ts"));
out.collect(visitorStats);
}
}
});
//2.4 转换跳出流
SingleOutputStreamOperator userJumpStatDstream = userJumpDStream.map(json -> {
JSONObject jsonObj = JSON.parseObject(json);
return new VisitorStats("", "",
jsonObj.getJSONObject("common").getString("vc"),
jsonObj.getJSONObject("common").getString("ch"),
jsonObj.getJSONObject("common").getString("ar"),
jsonObj.getJSONObject("common").getString("is_new"),
0L, 0L, 0L, 1L, 0L, jsonObj.getLong("ts"));
}); 四条流合并起来:
//TODO 3.将四条流合并起来
DataStream unionDetailDstream = uniqueVisitStatsDstream.union(
pageViewStatsDstream,
sessionVisitDstream,
userJumpStatDstream
); 根据维度进行聚合:
1)设置时间标记及水位线
因为涉及开窗聚合,所以要设定事件时间及水位线。
/TODO 4.设置水位线
SingleOutputStreamOperator visitorStatsWithWatermarkDstream =
unionDetailDstream.assignTimestampsAndWatermarks(
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(1)).
withTimestampAssigner( (visitorStats,ts) ->visitorStats.getTs() )
) ;
visitorStatsWithWatermarkDstream.print("after union:::"); 2)分组
分组选取四个维度作为key , 使用Tuple4组合。
//TODO 5.分组 选取四个维度作为key , 使用Tuple4组合
KeyedStream> visitorStatsTuple4KeyedStream =
visitorStatsWithWatermarkDstream
.keyBy(new KeySelector>() {
@Override
public Tuple4 getKey(VisitorStats visitorStats) throws Exception {
return new Tuple4<>(visitorStats.getVc()
, visitorStats.getCh(),
visitorStats.getAr(),
visitorStats.getIs_new());
}
}
); 3)开窗
//TODO 6.开窗
WindowedStream, TimeWindow> windowStream =
visitorStatsTuple4KeyedStream.window(TumblingEventTimeWindows.of(Time.seconds(10))); 4)窗口内聚合及补充时间字段
//TODO 7.Reduce聚合统计
SingleOutputStreamOperator visitorStatsDstream =
windowStream.reduce(new ReduceFunction() {
@Override
public VisitorStats reduce(VisitorStats stats1, VisitorStats stats2) throws Exception {
//把度量数据两两相加
stats1.setPv_ct(stats1.getPv_ct() + stats2.getPv_ct());
stats1.setUv_ct(stats1.getUv_ct() + stats2.getUv_ct());
stats1.setUj_ct(stats1.getUj_ct() + stats2.getUj_ct());
stats1.setSv_ct(stats1.getSv_ct() + stats2.getSv_ct());
stats1.setDur_sum(stats1.getDur_sum() + stats2.getDur_sum());
return stats1;
}
}, new ProcessWindowFunction, TimeWindow>() {
@Override
public void process(Tuple4 tuple4, Context context,
Iterable visitorStatsIn,
Collector visitorStatsOut) throws Exception {
//补时间字段
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for (VisitorStats visitorStats : visitorStatsIn) {
String startDate = simpleDateFormat.format(new Date(context.window().getStart()));
String endDate = simpleDateFormat.format(new Date(context.window().getEnd()));
visitorStats.setStt(startDate);
visitorStats.setEdt(endDate);
visitorStatsOut.collect(visitorStats);
}
}
});
visitorStatsDstream.print("reduce:"); 3. 写入OLAP数据库
为何要写入ClickHouse数据库,ClickHouse数据库作为专门解决大量数据统计分析的数据库,在保证了海量数据存储的能力,同时又兼顾了响应速度。而且还支持标准SQL,即灵活又易上手。
1)ClickHouse数据表准备
create table visitor_stats_2021 (
stt DateTime,
edt DateTime,
vc String,
ch String ,
ar String ,
is_new String ,
uv_ct UInt64,
pv_ct UInt64,
sv_ct UInt64,
uj_ct UInt64,
dur_sum UInt64,
ts UInt64
) engine =ReplacingMergeTree( ts)
partition by toYYYYMMDD(stt)
order by ( stt,edt,is_new,vc,ch,ar);之所以选用ReplacingMergeTree引擎主要是靠它来保证数据表的幂等性。
- paritition by 把日期变为数字类型(如:20201126),用于分区。所以尽量保证查询条件尽量包含stt字段。
- order by 后面字段数据在同一分区下,出现重复会被去重,重复数据保留ts最大的数据。
2)加入ClickHouse依赖包
ru.yandex.clickhouse
clickhouse-jdbc
0.3.0
com.fasterxml.jackson.core
jackson-databind
com.fasterxml.jackson.core
jackson-core
org.apache.flink
flink-connector-jdbc_${scala.version}
${flink.version}
其中flink-connector-jdbc 是官方通用的jdbcSink包。只要引入对应的jdbc驱动,flink可以用它应对各种支持jdbc的数据库,比如phoenix也可以用它。但是这个jdbc-sink只支持数据流对应一张数据表。如果是一流对多表,就必须通过自定义的方式实现了,比如之前的维度数据。
虽然这种jdbc-sink只能一流对一表,但是由于内部使用了预编译器,所以可以实现批量提交以优化写入速度。
3)增加ClickhouseUtil
JdbcSink.
- 参数1: 传入Sql,格式如:insert into xxx values(?,?,?,?)
- 参数2: 可以用lambda表达实现(jdbcPreparedStatement, t) -> t为数据对象,要装配到语句预编译器的参数中。
- 参数3:设定一些执行参数,比如重试次数,批次大小。
- 参数4:设定连接参数,比如地址,端口,驱动名。
ClickhouseUtil中获取JdbcSink函数的实现:
package com.yyds.gmall.realtime.utils;
import com.yyds.gmall.realtime.bean.TransientSink;
import com.yyds.gmall.realtime.common.GmallConfig;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.lang.reflect.Field;
/**
* Author: Felix
* Desc: 操作ClickHouse的工具类
*/
public class ClickHouseUtil {
//获取针对ClickHouse的JdbcSink
public static SinkFunction getJdbcSink(String sql) {
SinkFunction sink = JdbcSink.sink(
sql,
(jdbcPreparedStatement, t) -> {
Field[] fields = t.getClass().getDeclaredFields();
int skipOffset = 0; //
for (int i = 0; i < fields.length; i++) {
Field field = fields[i];
//通过反射获得字段上的注解
TransientSink transientSink =
field.getAnnotation(TransientSink.class);
if (transientSink != null) {
// 如果存在该注解
System.out.println("跳过字段:" + field.getName());
skipOffset++;
continue;
}
field.setAccessible(true);
try {
Object o = field.get(t);
//i代表流对象字段的下标,
// 公式:写入表字段位置下标 = 对象流对象字段下标 + 1 - 跳过字段的偏移量
// 一旦跳过一个字段 那么写入字段下标就会和原本字段下标存在偏差
jdbcPreparedStatement.setObject(i + 1 - skipOffset, o);
} catch (Exception e) {
e.printStackTrace();
}
}
},
new JdbcExecutionOptions.Builder().withBatchSize(2).build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl(GmallConfig.CLICKHOUSE_URL)
.withDriverName("ru.yandex.clickhouse.ClickHouseDriver")
.build());
return sink;
}
} 创建TransientSink注解,该注解标记不需要保存的字段:
由于之前的ClickhouseUtil工具类的写入机制就是把该实体类的所有字段按次序一次写入数据表。但是实体类有时会用到一些临时字段,计算中有用但是并不需要最终保存在临时表中。我们可以把这些字段做一些标识,然后再写入的时候判断标识来过滤掉这些字段。
为字段打标识通常的办法就是给字段加个注解,这里我们就增加一个自定义注解@TransientSink来标识该字段不需要保存到数据表中。
package com.yyds.gmall.realtime.bean;
import java.lang.annotation.Retention;
import java.lang.annotation.Target;
import static java.lang.annotation.ElementType.FIELD;
import static java.lang.annotation.RetentionPolicy.RUNTIME;
/**
* Author: Felix
* Desc: 向ClickHouse写入数据的时候,如果有字段数据不需要传输,可以用该注解标记
*/
@Target(FIELD)
@Retention(RUNTIME)
public @interface TransientSink {
}在GmallConfig中配置ClickHouse的连接地址:
package com.yyds.gmall.realtime.common;
/**
* Author: Felix
* Desc: 项目常用配置
*/
public class GmallConfig {
public static final String HBASE_SCHEMA="GMALL2021_REALTIME";
public static final String PHOENIX_SERVER="jdbc:phoenix:hadoop202,hadoop203,hadoop204:2181";
public static final String CLICKHOUSE_URL="jdbc:clickhouse://hadoop202:8123/default";
}为主程序增加写入ClickHouse的Sink:
//TODO 8.向ClickHouse中写入数据
visitorStatsDstream.addSink(
ClickHouseUtil.getJdbcSink("insert into visitor_stats_2021 values(?,?,?,?,?,?,?,?,?,?,?,?)"));整体测试:
- 启动ZK、Kafka、logger.sh、ClickHouse、【HDFS】
- 运行BaseLogApp
- 运行UniqueVisitApp
- 运行UserJumpDetailApp
- 运行VisitorStatsApp
- 运行rt_applog目录下的jar包
- 查看控制台输出
- 查看ClickHouse中visitor_stats_2021表数据
3、DWS层-商品主题计算
| 统计主题 |
需求指标 |
输出方式 |
计算来源 |
来源层级 |
| 商品 |
点击 |
多维分析 |
page_log直接可求 |
dwd |
| 曝光 |
多维分析 |
page_log直接可求 |
dwd |
|
| 收藏 |
多维分析 |
收藏表 |
dwd |
|
| 加入购物车 |
多维分析 |
购物车表 |
dwd |
|
| 下单 |
可视化大屏 |
订单宽表 |
dwm |
|
| 支付 |
多维分析 |
支付宽表 |
dwm |
|
| 退款 |
多维分析 |
退款表 |
dwd |
|
| 评价 |
多维分析 |
评价表 |
dwd |
与访客的dws层的宽表类似,也是把多个事实表的明细数据汇总起来组合成宽表。
1. 需求分析与思路
- 从Kafka主题中获得数据流
- 把Json字符串数据流转换为统一数据对象的数据流
- 把统一的数据结构流合并为一个流
- 设定事件时间与水位线
- 分组、开窗、聚合
- 写入ClickHouse
2. 功能实现
封装商品统计实体类ProductStats:
package com.yyds.gmall.realtime.bean;
/**
* Author: Felix
* Desc: 商品统计实体类
* @Builder注解
* 可以使用构造者方式创建对象,给属性赋值
* @Builder.Default
* 在使用构造者方式给属性赋值的时候,属性的初始值会丢失
* 该注解的作用就是修复这个问题
* 例如:我们在属性上赋值了初始值为0L,如果不加这个注解,通过构造者创建的对象属性值会变为null
*/
import lombok.Builder;
import lombok.Data;
import java.math.BigDecimal;
import java.util.HashSet;
import java.util.Set;
@Data
@Builder
public class ProductStats {
String stt;//窗口起始时间
String edt; //窗口结束时间
Long sku_id; //sku编号
String sku_name;//sku名称
BigDecimal sku_price; //sku单价
Long spu_id; //spu编号
String spu_name;//spu名称
Long tm_id; //品牌编号
String tm_name;//品牌名称
Long category3_id;//品类编号
String category3_name;//品类名称
@Builder.Default
Long display_ct = 0L; //曝光数
@Builder.Default
Long click_ct = 0L; //点击数
@Builder.Default
Long favor_ct = 0L; //收藏数
@Builder.Default
Long cart_ct = 0L; //添加购物车数
@Builder.Default
Long order_sku_num = 0L; //下单商品个数
@Builder.Default //下单商品金额
BigDecimal order_amount = BigDecimal.ZERO;
@Builder.Default
Long order_ct = 0L; //订单数
@Builder.Default //支付金额
BigDecimal payment_amount = BigDecimal.ZERO;
@Builder.Default
Long paid_order_ct = 0L; //支付订单数
@Builder.Default
Long refund_order_ct = 0L; //退款订单数
@Builder.Default
BigDecimal refund_amount = BigDecimal.ZERO;
@Builder.Default
Long comment_ct = 0L;//评论订单数
@Builder.Default
Long good_comment_ct = 0L; //好评订单数
@Builder.Default
@TransientSink
Set orderIdSet = new HashSet(); //用于统计订单数
@Builder.Default
@TransientSink
Set paidOrderIdSet = new HashSet(); //用于统计支付订单数
@Builder.Default
@TransientSink
Set refundOrderIdSet = new HashSet();//用于退款支付订单数
Long ts; //统计时间戳
}创建ProductStatsApp,从Kafka主题中获得数据流:
package com.yyds.gmall.realtime.app.dws;
import com.yyds.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* Author: Felix
* Desc: 形成以商品为准的统计 曝光 点击 购物车 下单 支付 退单 评论数 宽表
*/
public class ProductStatsApp {
public static void main(String[] args) throws Exception {
//TODO 0.基本环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(4);
/*
//检查点CK相关设置
env.enableCheckpointing(5000, CheckpointingMode.AT_LEAST_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
StateBackend fsStateBackend = new FsStateBackend(
"hdfs://hadoop202:8020/gmall/flink/checkpoint/ProductStatsApp");
env.setStateBackend(fsStateBackend);
System.setProperty("HADOOP_USER_NAME","yyds");
*/
//TODO 1.从Kafka中获取数据流
String groupId = "product_stats_app";
String pageViewSourceTopic = "dwd_page_log";
String orderWideSourceTopic = "dwm_order_wide";
String paymentWideSourceTopic = "dwm_payment_wide";
String cartInfoSourceTopic = "dwd_cart_info";
String favorInfoSourceTopic = "dwd_favor_info";
String refundInfoSourceTopic = "dwd_order_refund_info";
String commentInfoSourceTopic = "dwd_comment_info";
FlinkKafkaConsumer pageViewSource = MyKafkaUtil.getKafkaSource(pageViewSourceTopic,groupId);
FlinkKafkaConsumer orderWideSource = MyKafkaUtil.getKafkaSource(orderWideSourceTopic,groupId);
FlinkKafkaConsumer paymentWideSource = MyKafkaUtil.getKafkaSource(paymentWideSourceTopic,groupId);
FlinkKafkaConsumer favorInfoSourceSouce = MyKafkaUtil.getKafkaSource(favorInfoSourceTopic,groupId);
FlinkKafkaConsumer cartInfoSource = MyKafkaUtil.getKafkaSource(cartInfoSourceTopic,groupId);
FlinkKafkaConsumer refundInfoSource = MyKafkaUtil.getKafkaSource(refundInfoSourceTopic,groupId);
FlinkKafkaConsumer commentInfoSource = MyKafkaUtil.getKafkaSource(commentInfoSourceTopic,groupId);
DataStreamSource pageViewDStream = env.addSource(pageViewSource);
DataStreamSource favorInfoDStream = env.addSource(favorInfoSourceSouce);
DataStreamSource orderWideDStream= env.addSource(orderWideSource);
DataStreamSource paymentWideDStream= env.addSource(paymentWideSource);
DataStreamSource cartInfoDStream= env.addSource(cartInfoSource);
DataStreamSource refundInfoDStream= env.addSource(refundInfoSource);
DataStreamSource commentInfoDStream= env.addSource(commentInfoSource);
env.execute();
}
} 把JSON字符串数据流转换为统一数据对象的数据流:
//TODO 2.对获取的流数据进行结构的转换
//2.1转换曝光及页面流数据
SingleOutputStreamOperator pageAndDispStatsDstream = pageViewDStream.process(
new ProcessFunction() {
@Override
public void processElement(String json, Context ctx, Collector out) throws Exception {
JSONObject jsonObj = JSON.parseObject(json);
JSONObject pageJsonObj = jsonObj.getJSONObject("page");
String pageId = pageJsonObj.getString("page_id");
if (pageId == null) {
System.out.println(jsonObj);
}
Long ts = jsonObj.getLong("ts");
if (pageId.equals("good_detail")) {
Long skuId = pageJsonObj.getLong("item");
ProductStats productStats = ProductStats.builder().sku_id(skuId).
click_ct(1L).ts(ts).build();
out.collect(productStats);
}
JSONArray displays = jsonObj.getJSONArray("displays");
if (displays != null && displays.size() > 0) {
for (int i = 0; i < displays.size(); i++) {
JSONObject display = displays.getJSONObject(i);
if (display.getString("item_type").equals("sku_id")) {
Long skuId = display.getLong("item");
ProductStats productStats = ProductStats.builder()
.sku_id(skuId).display_ct(1L).ts(ts).build();
out.collect(productStats);
}
}
}
}
});
//2.2转换下单流数据
SingleOutputStreamOperator orderWideStatsDstream = orderWideDStream.map(
json -> {
OrderWide orderWide = JSON.parseObject(json, OrderWide.class);
System.out.println("orderWide:===" + orderWide);
String create_time = orderWide.getCreate_time();
Long ts = DateTimeUtil.toTs(create_time);
return ProductStats.builder().sku_id(orderWide.getSku_id())
.orderIdSet(new HashSet(Collections.singleton(orderWide.getOrder_id())))
.order_sku_num(orderWide.getSku_num())
.order_amount(orderWide.getSplit_total_amount()).ts(ts).build();
});
//2.3转换收藏流数据
SingleOutputStreamOperator favorStatsDstream = favorInfoDStream.map(
json -> {
JSONObject favorInfo = JSON.parseObject(json);
Long ts = DateTimeUtil.toTs(favorInfo.getString("create_time"));
return ProductStats.builder().sku_id(favorInfo.getLong("sku_id"))
.favor_ct(1L).ts(ts).build();
});
//2.4转换购物车流数据
SingleOutputStreamOperator cartStatsDstream = cartInfoDStream.map(
json -> {
JSONObject cartInfo = JSON.parseObject(json);
Long ts = DateTimeUtil.toTs(cartInfo.getString("create_time"));
return ProductStats.builder().sku_id(cartInfo.getLong("sku_id"))
.cart_ct(1L).ts(ts).build();
});
//2.5转换支付流数据
SingleOutputStreamOperator paymentStatsDstream = paymentWideDStream.map(
json -> {
PaymentWide paymentWide = JSON.parseObject(json, PaymentWide.class);
Long ts = DateTimeUtil.toTs(paymentWide.getCallback_time());
return ProductStats.builder().sku_id(paymentWide.getSku_id())
.payment_amount(paymentWide.getSplit_total_amount())
.paidOrderIdSet(new HashSet(Collections.singleton(paymentWide.getOrder_id())))
.ts(ts).build();
});
//2.6转换退款流数据
SingleOutputStreamOperator refundStatsDstream = refundInfoDStream.map(
json -> {
JSONObject refundJsonObj = JSON.parseObject(json);
Long ts = DateTimeUtil.toTs(refundJsonObj.getString("create_time"));
ProductStats productStats = ProductStats.builder()
.sku_id(refundJsonObj.getLong("sku_id"))
.refund_amount(refundJsonObj.getBigDecimal("refund_amount"))
.refundOrderIdSet(
new HashSet(Collections.singleton(refundJsonObj.getLong("order_id"))))
.ts(ts).build();
return productStats;
});
//2.7转换评价流数据
SingleOutputStreamOperator commonInfoStatsDstream = commentInfoDStream.map(
json -> {
JSONObject commonJsonObj = JSON.parseObject(json);
Long ts = DateTimeUtil.toTs(commonJsonObj.getString("create_time"));
Long goodCt = GmallConstant.APPRAISE_GOOD.equals(commonJsonObj.getString("appraise")) ? 1L : 0L;
ProductStats productStats = ProductStats.builder()
.sku_id(commonJsonObj.getLong("sku_id"))
.comment_ct(1L).good_comment_ct(goodCt).ts(ts).build();
return productStats;
}); 创建电商业务常量类GmallConstant:
package com.yyds.gmall.realtime.common;
/**
* Author: Felix
* Desc: 电商业务常量
*/
public class GmallConstant {
//10 单据状态
public static final String ORDER_STATUS_UNPAID="1001"; //未支付
public static final String ORDER_STATUS_PAID="1002"; //已支付
public static final String ORDER_STATUS_CANCEL="1003";//已取消
public static final String ORDER_STATUS_FINISH="1004";//已完成
public static final String ORDER_STATUS_REFUND="1005";//退款中
public static final String ORDER_STATUS_REFUND_DONE="1006";//退款完成
//11 支付状态
public static final String PAYMENT_TYPE_ALIPAY="1101";//支付宝
public static final String PAYMENT_TYPE_WECHAT="1102";//微信
public static final String PAYMENT_TYPE_UNION="1103";//银联
//12 评价
public static final String APPRAISE_GOOD="1201";// 好评
public static final String APPRAISE_SOSO="1202";// 中评
public static final String APPRAISE_BAD="1203";// 差评
public static final String APPRAISE_AUTO="1204";// 自动
//13 退货原因
public static final String REFUND_REASON_BAD_GOODS="1301";// 质量问题
public static final String REFUND_REASON_WRONG_DESC="1302";// 商品描述与实际描述不一致
public static final String REFUND_REASON_SALE_OUT="1303";// 缺货
public static final String REFUND_REASON_SIZE_ISSUE="1304";// 号码不合适
public static final String REFUND_REASON_MISTAKE="1305";// 拍错
public static final String REFUND_REASON_NO_REASON="1306";// 不想买了
public static final String REFUND_REASON_OTHER="1307";// 其他
//14 购物券状态
public static final String COUPON_STATUS_UNUSED="1401";// 未使用
public static final String COUPON_STATUS_USING="1402";// 使用中
public static final String COUPON_STATUS_USED="1403";// 已使用
//15退款类型
public static final String REFUND_TYPE_ONLY_MONEY="1501";// 仅退款
public static final String REFUND_TYPE_WITH_GOODS="1502";// 退货退款
//24来源类型
public static final String SOURCE_TYPE_QUREY="2401";// 用户查询
public static final String SOURCE_TYPE_PROMOTION="2402";// 商品推广
public static final String SOURCE_TYPE_AUTO_RECOMMEND="2403";// 智能推荐
public static final String SOURCE_TYPE_ACTIVITY="2404";// 促销活动
//购物券范围
public static final String COUPON_RANGE_TYPE_CATEGORY3="3301";//
public static final String COUPON_RANGE_TYPE_TRADEMARK="3302";//
public static final String COUPON_RANGE_TYPE_SPU="3303";//
//购物券类型
public static final String COUPON_TYPE_MJ="3201";//满减
public static final String COUPON_TYPE_DZ="3202";// 满量打折
public static final String COUPON_TYPE_DJ="3203";// 代金券
public static final String ACTIVITY_RULE_TYPE_MJ="3101";
public static final String ACTIVITY_RULE_TYPE_DZ ="3102";
public static final String ACTIVITY_RULE_TYPE_ZK="3103";
public static final String KEYWORD_SEARCH="SEARCH";
public static final String KEYWORD_CLICK="CLICK";
public static final String KEYWORD_CART="CART";
public static final String KEYWORD_ORDER="ORDER";
}把统一的数据结构流合并为一个流:
//TODO 3.把统一的数据结构流合并为一个流
DataStream productStatDetailDStream = pageAndDispStatsDstream.union(
orderWideStatsDstream, cartStatsDstream,
paymentStatsDstream, refundStatsDstream,favorStatsDstream,
commonInfoStatsDstream);
productStatDetailDStream.print("after union:"); 设定事件时间与水位线:
//TODO 4.设定事件时间与水位线
SingleOutputStreamOperator productStatsWithTsStream =
productStatDetailDStream.assignTimestampsAndWatermarks(
WatermarkStrategy.forMonotonousTimestamps().withTimestampAssigner(
(productStats, recordTimestamp) -> {
return productStats.getTs();
})
); 分组、开窗、聚合:
//TODO 5.分组、开窗、聚合
SingleOutputStreamOperator productStatsDstream = productStatsWithTsStream
//5.1 按照商品id进行分组
.keyBy(
new KeySelector() {
@Override
public Long getKey(ProductStats productStats) throws Exception {
return productStats.getSku_id();
}
})
//5.2 开窗 窗口长度为10s
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
//5.3 对窗口中的数据进行聚合
.reduce(new ReduceFunction() {
@Override
public ProductStats reduce(ProductStats stats1, ProductStats stats2) throws Exception {
stats1.setDisplay_ct(stats1.getDisplay_ct() + stats2.getDisplay_ct());
stats1.setClick_ct(stats1.getClick_ct() + stats2.getClick_ct());
stats1.setCart_ct(stats1.getCart_ct() + stats2.getCart_ct());
stats1.setFavor_ct(stats1.getFavor_ct() + stats2.getFavor_ct());
stats1.setOrder_amount(stats1.getOrder_amount().add(stats2.getOrder_amount()));
stats1.getOrderIdSet().addAll(stats2.getOrderIdSet());
stats1.setOrder_ct(stats1.getOrderIdSet().size() + 0L);
stats1.setOrder_sku_num(stats1.getOrder_sku_num() + stats2.getOrder_sku_num());
stats1.setPayment_amount(stats1.getPayment_amount().add(stats2.getPayment_amount()));
stats1.getRefundOrderIdSet().addAll(stats2.getRefundOrderIdSet());
stats1.setRefund_order_ct(stats1.getRefundOrderIdSet().size() + 0L);
stats1.setRefund_amount(stats1.getRefund_amount().add(stats2.getRefund_amount()));
stats1.getPaidOrderIdSet().addAll(stats2.getPaidOrderIdSet());
stats1.setPaid_order_ct(stats1.getPaidOrderIdSet().size() + 0L);
stats1.setComment_ct(stats1.getComment_ct() + stats2.getComment_ct());
stats1.setGood_comment_ct(stats1.getGood_comment_ct() + stats2.getGood_comment_ct());
return stats1;
}
},
new WindowFunction() {
@Override
public void apply(Long aLong, TimeWindow window,
Iterable productStatsIterable,
Collector out) throws Exception {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for (ProductStats productStats : productStatsIterable) {
productStats.setStt(simpleDateFormat.format(window.getStart()));
productStats.setEdt(simpleDateFormat.format(window.getEnd()));
productStats.setTs(new Date().getTime());
out.collect(productStats);
}
}
});
//productStatsDstream.print("productStatsDstream::"); 补充商品维度信息:
因为除了下单操作之外,其它操作,只获取到了商品的id,其它维度信息是没有的。
//TODO 6.补充商品维度信息
//6.1 补充SKU维度
SingleOutputStreamOperator productStatsWithSkuDstream =
AsyncDataStream.unorderedWait(productStatsDstream,
new DimAsyncFunction("DIM_SKU_INFO") {
@Override
public void join(ProductStats productStats, JSONObject jsonObject) throws Exception {
productStats.setSku_name(jsonObject.getString("SKU_NAME"));
productStats.setSku_price(jsonObject.getBigDecimal("PRICE"));
productStats.setCategory3_id(jsonObject.getLong("CATEGORY3_ID"));
productStats.setSpu_id(jsonObject.getLong("SPU_ID"));
productStats.setTm_id(jsonObject.getLong("TM_ID"));
}
@Override
public String getKey(ProductStats productStats) {
return String.valueOf(productStats.getSku_id());
}
}, 60, TimeUnit.SECONDS);
//6.2 补充SPU维度
SingleOutputStreamOperator productStatsWithSpuDstream =
AsyncDataStream.unorderedWait(productStatsWithSkuDstream,
new DimAsyncFunction("DIM_SPU_INFO") {
@Override
public void join(ProductStats productStats, JSONObject jsonObject) throws Exception {
productStats.setSpu_name(jsonObject.getString("SPU_NAME"));
}
@Override
public String getKey(ProductStats productStats) {
return String.valueOf(productStats.getSpu_id());
}
}, 60, TimeUnit.SECONDS);
//6.3 补充品类维度
SingleOutputStreamOperator productStatsWithCategory3Dstream =
AsyncDataStream.unorderedWait(productStatsWithSpuDstream,
new DimAsyncFunction("DIM_BASE_CATEGORY3") {
@Override
public void join(ProductStats productStats, JSONObject jsonObject) throws Exception {
productStats.setCategory3_name(jsonObject.getString("NAME"));
}
@Override
public String getKey(ProductStats productStats) {
return String.valueOf(productStats.getCategory3_id());
}
}, 60, TimeUnit.SECONDS);
//6.4 补充品牌维度
SingleOutputStreamOperator productStatsWithTmDstream =
AsyncDataStream.unorderedWait(productStatsWithCategory3Dstream,
new DimAsyncFunction("DIM_BASE_TRADEMARK") {
@Override
public void join(ProductStats productStats, JSONObject jsonObject) throws Exception {
productStats.setTm_name(jsonObject.getString("TM_NAME"));
}
@Override
public String getKey(ProductStats productStats) {
return String.valueOf(productStats.getTm_id());
}
}, 60, TimeUnit.SECONDS);
productStatsWithTmDstream.print("to save"); 写入ClickHouse:
在ClickHouse中创建商品主题宽表。
create table product_stats_2021 (
stt DateTime,
edt DateTime,
sku_id UInt64,
sku_name String,
sku_price Decimal64(2),
spu_id UInt64,
spu_name String ,
tm_id UInt64,
tm_name String,
category3_id UInt64,
category3_name String ,
display_ct UInt64,
click_ct UInt64,
favor_ct UInt64,
cart_ct UInt64,
order_sku_num UInt64,
order_amount Decimal64(2),
order_ct UInt64 ,
payment_amount Decimal64(2),
paid_order_ct UInt64,
refund_order_ct UInt64,
refund_amount Decimal64(2),
comment_ct UInt64,
good_comment_ct UInt64 ,
ts UInt64
)engine =ReplacingMergeTree( ts)
partition by toYYYYMMDD(stt)
order by (stt,edt,sku_id );为主程序增加写入ClickHouse的Sink:
//TODO 7.写入到ClickHouse
productStatsWithTmDstream.addSink(
ClickHouseUtil.getJdbcSink(
"insert into product_stats_2021 values(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)")); 整体测试:
- 启动ZK、Kafka、logger.sh、ClickHouse、Redis、HDFS、Hbase、Maxwell
- 运行BaseLogApp
- 运行BaseDBApp
- 运行OrderWideApp
- 运行PaymentWideApp
- 运行ProductsStatsApp
- 运行rt_applog目录下的jar包
- 运行rt_dblog目录下的jar包
- 查看控制台输出
- 查看ClickHouse中products_stats_2021表数据
注意:一定要匹配两个数据生成模拟器的日期,否则窗口无法匹配上。
4、DWS层-地区主题表(FlinkSQL)
| 统计主题 |
需求指标 |
输出方式 |
计算来源 |
来源层级 |
| 地区 |
pv |
多维分析 |
page_log直接可求 |
dwd |
| uv |
多维分析 |
需要用page_log过滤去重 |
dwm |
|
| 下单(单数,金额) |
可视化大屏 |
订单宽表 |
dwm |
地区主题主要是反映各个地区的销售情况。从业务逻辑上地区主题比起商品更加简单,业务逻辑也没有什么特别的就是做一次轻度聚合然后保存,所以在这里我们体验一下使用flinkSQL,来完成该业务。
1. 需求分析与思路
- 定义Table流环境
- 把数据源定义为动态表
- 通过SQL查询出结果表
- 把结果表转换为数据流
- 把数据流写入目标数据库
如果是Flink官方支持的数据库,也可以直接把目标数据表定义为动态表,用insert into 写入。由于ClickHouse目前官方没有支持的jdbc连接器(目前支持Mysql、 PostgreSQL、Derby)。也可以制作自定义sink,实现官方不支持的连接器。但是比较繁琐。
2. 功能实现
在pom.xml文件中添加FlinkSQL相关依赖:
org.apache.flink
flink-table-api-java-bridge_${scala.version}
${flink.version}
org.apache.flink
flink-table-planner-blink_${scala.version}
${flink.version}
创建ProvinceStatsSqlApp,定义Table流环境:
package com.yyds.gmall.realtime.app.dws;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* Author: Felix
* Desc: FlinkSQL实现地区主题宽表计算
*/
public class ProvinceStatsSqlApp {
public static void main(String[] args) throws Exception {
//TODO 0.基本环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(4);
/*
//CK相关设置
env.enableCheckpointing(5000, CheckpointingMode.AT_LEAST_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
StateBackend fsStateBackend = new FsStateBackend(
"hdfs://hadoop202:8020/gmall/flink/checkpoint/ProvinceStatsSqlApp");
env.setStateBackend(fsStateBackend);
System.setProperty("HADOOP_USER_NAME","yyds");
*/
//TODO 1.定义Table流环境
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
env.execute();
}
}把数据源定义为动态表:
其中WATERMARK FOR rowtime AS rowtime是把某个字段设定为EVENT_TIME。
//TODO 2.把数据源定义为动态表
String groupId = "province_stats";
String orderWideTopic = "dwm_order_wide";
tableEnv.executeSql("CREATE TABLE ORDER_WIDE (province_id BIGINT, " +
"province_name STRING,province_area_code STRING" +
",province_iso_code STRING,province_3166_2_code STRING,order_id STRING, " +
"split_total_amount DOUBLE,create_time STRING,rowtime AS TO_TIMESTAMP(create_time) ," +
"WATERMARK FOR rowtime AS rowtime)" +
" WITH (" + MyKafkaUtil.getKafkaDDL(orderWideTopic, groupId) + ")");MyKafkaUtil增加一个DDL的方法:
//拼接Kafka相关属性到DDL
public static String getKafkaDDL(String topic,String groupId){
String ddl="'connector' = 'kafka', " +
" 'topic' = '"+topic+"'," +
" 'properties.bootstrap.servers' = '"+ kafkaServer +"', " +
" 'properties.group.id' = '"+groupId+ "', " +
" 'format' = 'json', " +
" 'scan.startup.mode' = 'latest-offset' ";
return ddl;
}聚合计算:
//TODO 3.聚合计算
Table provinceStateTable = tableEnv.sqlQuery("select " +
"DATE_FORMAT(TUMBLE_START(rowtime, INTERVAL '10' SECOND ),'yyyy-MM-dd HH:mm:ss') stt, " +
"DATE_FORMAT(TUMBLE_END(rowtime, INTERVAL '10' SECOND ),'yyyy-MM-dd HH:mm:ss') edt , " +
" province_id,province_name,province_area_code area_code," +
"province_iso_code iso_code ,province_3166_2_code iso_3166_2 ," +
"COUNT( DISTINCT order_id) order_count, sum(split_total_amount) order_amount," +
"UNIX_TIMESTAMP()*1000 ts "+
" from ORDER_WIDE group by TUMBLE(rowtime, INTERVAL '10' SECOND )," +
" province_id,province_name,province_area_code,province_iso_code,province_3166_2_code ");定义地区统计宽表实体类ProvinceStats:
package com.yyds.gmall.realtime.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.math.BigDecimal;
import java.util.Date;
/**
* Author: Felix
* Desc:地区统计宽表实体类
*/
@AllArgsConstructor
@NoArgsConstructor
@Data
public class ProvinceStats {
private String stt;
private String edt;
private Long province_id;
private String province_name;
private String area_code;
private String iso_code;
private String iso_3166_2;
private BigDecimal order_amount;
private Long order_count;
private Long ts;
public ProvinceStats(OrderWide orderWide){
province_id = orderWide.getProvince_id();
order_amount = orderWide.getSplit_total_amount();
province_name=orderWide.getProvince_name();
area_code=orderWide.getProvince_area_code();
iso_3166_2=orderWide.getProvince_iso_code();
iso_code=orderWide.getProvince_iso_code();
order_count = 1L;
ts=new Date().getTime();
}
}转为数据流:
//TODO 4.转换为数据流
DataStream provinceStatsDataStream =
tableEnv.toAppendStream(provinceStateTable, ProvinceStats.class); 在ClickHouse中创建地区主题宽表:
create table province_stats_2021 (
stt DateTime,
edt DateTime,
province_id UInt64,
province_name String,
area_code String ,
iso_code String,
iso_3166_2 String ,
order_amount Decimal64(2),
order_count UInt64 ,
ts UInt64
)engine =ReplacingMergeTree( ts)
partition by toYYYYMMDD(stt)
order by (stt,edt,province_id );写入ClickHouse:
//TODO 5.写入到lickHouse
provinceStatsDataStream.addSink(ClickHouseUtil.
getJdbcSink("insert into province_stats_2021 values(?,?,?,?,?,?,?,?,?,?)")); 整体测试:
- 启动ZK、Kafka、ClickHouse、Redis、HDFS、Hbase、Maxwell
- 运行BaseDBApp
- 运行OrderWideApp
- 运行ProvinceStatsSqlApp
- 运行rt_dblog目录下的jar包
- 查看控制台输出
- 查看ClickHouse中products_stats_2021表数据
注意:因为是事件时间,所以第一次运行rt_dblog的时候,不会触发watermark,第二次再运行rt_dblog的jar的时候,才会触发第一次运行的watermark。
5、DWS层-关键词主题表(FlinkSQL)
1. 需求分析与思路
关键词主题这个主要是为了大屏展示中的字符云的展示效果,用于感性的让大屏观看者感知目前的用户都更关心的那些商品和关键词。
关键词的展示也是一种维度聚合的结果,根据聚合的大小来决定关键词的大小。
关键词的第一重要来源的就是用户在搜索栏的搜索,另外就是从以商品为主题的统计中获取关键词。
关于分词:
因为无论是从用户的搜索栏中,还是从商品名称中文字都是可能是比较长的,且由多个关键词组成,如下图。
![]()

所以我们需要根据把长文本分割成一个一个的词,这种分词技术,在搜索引擎中可能会用到。对于中文分词,现在的搜索引擎基本上都是使用的第三方分词器,咱们在计算数据中也可以,使用和搜索引擎中一致的分词器,IK。
2. 搜索关键词功能实现
IK分词器的使用:
在pom.xml中加入依赖:
com.janeluo
ikanalyzer
2012_u6
封装分词工具类并进行测试:
package com.yyds.gmall.realtime.utils;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
/**
* Author: Felix
* Desc: IK分词器工具类
*/
public class KeywordUtil {
//使用IK分词器对字符串进行分词
public static List analyze(String text) {
StringReader sr = new StringReader(text);
IKSegmenter ik = new IKSegmenter(sr, true);
Lexeme lex = null;
List keywordList = new ArrayList();
while (true) {
try {
if ((lex = ik.next()) != null) {
String lexemeText = lex.getLexemeText();
keywordList.add(lexemeText);
} else {
break;
}
} catch (IOException e) {
e.printStackTrace();
}
}
return keywordList;
}
public static void main(String[] args) {
String text = "Apple iPhoneXSMax (A2104) 256GB 深空灰色 移动联通电信4G手机 双卡双待";
System.out.println(KeywordUtil.analyze(text));
}
} 2. 自定义函数
有了分词器,那么另外一个要考虑的问题就是如何把分词器的使用揉进FlinkSQL中。
因为SQL的语法和相关的函数都是Flink内定的,想要使用外部工具,就必须结合自定义函数。
自定义函数分类:
- Scalar Function(相当于 Spark的 UDF),
- Table Function(相当于 Spark 的 UDTF),
- Aggregation Functions (相当于 Spark的UDAF)
考虑到一个词条包括多个词语所以分词是指上是一种一对多的拆分,一拆多的情况,我们应该选择Table Function。
封装KeywordUDTF函数:
参考Apache Flink 1.12 Documentation: User-defined Functions
@FunctionHint 主要是为了标识输出数据的类型。
row.setField(0,keyword)中的0表示返回值下标为0的值。
package com.yyds.gmall.realtime.app.udf;
import com.yyds.gmall.realtime.utils.KeywordUtil;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import java.util.List;
/**
* Author: Felix
* Desc: 自定义UDTF函数实现分词功能
*/
@FunctionHint(output = @DataTypeHint("ROW"))
public class KeywordUDTF extends TableFunction {
public void eval(String value) {
List keywordList = KeywordUtil.analyze(value);
for (String keyword : keywordList) {
Row row = new Row(1);
row.setField(0,keyword);
collect(row);
}
}
}
创建KeywordStatsApp,定义流环境:
package com.yyds.gmall.realtime.app.dws;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* Author: Felix
* Desc: 搜索关键字计算
*/
public class KeywordStatsApp {
public static void main(String[] args) {
//TODO 0.基本环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(4);
/*
//CK相关设置
env.enableCheckpointing(5000, CheckpointingMode.AT_LEAST_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
StateBackend fsStateBackend = new FsStateBackend(
"hdfs://hadoop202:8020/gmall/flink/checkpoint/ProvinceStatsSqlApp");
env.setStateBackend(fsStateBackend);
System.setProperty("HADOOP_USER_NAME","yyds");
*/
//TODO 1.定义Table流环境
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
env.execute();
}
}声明动态表和自定义函数:
注意json格式的要定义为Map对象。
//TODO 2.注册自定义函数
tableEnv.createTemporarySystemFunction("ik_analyze", KeywordUDTF.class);
//TODO 3.将数据源定义为动态表
String groupId = "keyword_stats_app";
String pageViewSourceTopic ="dwd_page_log";
tableEnv.executeSql("CREATE TABLE page_view " +
"(common MAP, " +
"page MAP,ts BIGINT, " +
"rowtime AS TO_TIMESTAMP(FROM_UNIXTIME(ts/1000, 'yyyy-MM-dd HH:mm:ss')) ," +
"WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND) " +
"WITH ("+ MyKafkaUtil.getKafkaDDL(pageViewSourceTopic,groupId)+")"); 过滤数据:
//TODO 4.过滤数据
Table fullwordView = tableEnv.sqlQuery("select page['item'] fullword ," +
"rowtime from page_view " +
"where page['page_id']='good_list' " +
"and page['item'] IS NOT NULL ");利用UDTF进行拆分:
//TODO 5.利用udtf将数据拆分
Table keywordView = tableEnv.sqlQuery("select keyword,rowtime from " + fullwordView + " ," +
" LATERAL TABLE(ik_analyze(fullword)) as T(keyword)");聚合:
//TODO 6.根据各个关键词出现次数进行ct
Table keywordStatsSearch = tableEnv.sqlQuery("select keyword,count(*) ct, '"
+ GmallConstant.KEYWORD_SEARCH + "' source ," +
"DATE_FORMAT(TUMBLE_START(rowtime, INTERVAL '10' SECOND),'yyyy-MM-dd HH:mm:ss') stt," +
"DATE_FORMAT(TUMBLE_END(rowtime, INTERVAL '10' SECOND),'yyyy-MM-dd HH:mm:ss') edt," +
"UNIX_TIMESTAMP()*1000 ts from "+keywordView
+ " GROUP BY TUMBLE(rowtime, INTERVAL '10' SECOND ),keyword");转换为流并写入ClickHouse:
在ClickHouse中创建关键词统计表:
create table keyword_stats_2021 (
stt DateTime,
edt DateTime,
keyword String ,
source String ,
ct UInt64 ,
ts UInt64
)engine =ReplacingMergeTree( ts)
partition by toYYYYMMDD(stt)
order by ( stt,edt,keyword,source );封装KeywordStats实体类:
package com.yyds.gmall.realtime.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* Author: Felix
* Desc: 关键词统计实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class KeywordStats {
private String keyword;
private Long ct;
private String source;
private String stt;
private String edt;
private Long ts;
}在主程序中转换流并写入ClickHouse:
//TODO 7.转换为数据流
DataStream keywordStatsSearchDataStream =
tableEnv.toAppendStream(keywordStatsSearch, KeywordStats.class);
keywordStatsSearchDataStream.print();
//TODO 8.写入到ClickHouse
keywordStatsSearchDataStream.addSink(
ClickHouseUtil.getJdbcSink(
"insert into keyword_stats(keyword,ct,source,stt,edt,ts) " +
" values(?,?,?,?,?,?)") 整体测试:
- 启动ZK、Kafka、logger.sh、ClickHouse
- 运行BaseLogApp
- 运行KeywordStatsApp
- 运行rt_applog目录下的jar包
- 查看控制台输出
- 查看ClickHouse中keyword_stats_2021表数据
3. 商品行为关键词
从商品主题获得,商品关键词与点击次数、订单次数、添加购物次数的统计表。
- 自定义UDTF函数实现点击次数、订单次数、添加购物次数的统计
package com.yyds.gmall.realtime.app.udf;
/**
* Author: Felix
* Desc:自定义UDTF函数实现商品点击次数、订单次数、添加购物次数的统计
*/
import com.yyds.gmall.realtime.common.GmallConstant;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
@FunctionHint(output = @DataTypeHint("ROW"))
public class KeywordProductC2RUDTF extends TableFunction {
public void eval(Long clickCt, Long cartCt, Long orderCt) {
if(clickCt>0L) {
Row rowClick = new Row(2);
rowClick.setField(0, clickCt);
rowClick.setField(1, GmallConstant.KEYWORD_CLICK);
collect(rowClick);
}
if(cartCt>0L) {
Row rowCart = new Row(2);
rowCart.setField(0, cartCt);
rowCart.setField(1, GmallConstant.KEYWORD_CART);
collect(rowCart);
}
if(orderCt>0) {
Row rowOrder = new Row(2);
rowOrder.setField(0, orderCt);
rowOrder.setField(1, GmallConstant.KEYWORD_ORDER);
collect(rowOrder);
}
}
}
- 在KeywordStats4ProductApp实现
package com.yyds.gmall.realtime.app.dws;
import com.yyds.gmall.realtime.app.udf.KeywordProductC2RUDTF;
import com.yyds.gmall.realtime.bean.KeywordStats;
import com.yyds.gmall.realtime.utils.ClickHouseUtil;
import com.yyds.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* Author: Felix
* Desc: 商品行为关键字主题宽表计算
*/
public class KeywordStats4ProductApp {
public static void main(String[] args) throws Exception {
//TODO 0.基本环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(4);
/*
//CK相关设置
env.enableCheckpointing(5000, CheckpointingMode.AT_LEAST_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
StateBackend fsStateBackend = new FsStateBackend(
"hdfs://hadoop202:8020/gmall/flink/checkpoint/ProvinceStatsSqlApp");
env.setStateBackend(fsStateBackend);
System.setProperty("HADOOP_USER_NAME","yyds");
*/
//TODO 1.定义Table流环境
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
//TODO 2.注册自定义函数
tableEnv.createTemporarySystemFunction("keywordProductC2R", KeywordProductC2RUDTF.class);
//TODO 3.将数据源定义为动态表
String groupId = "keyword_stats_app";
String productStatsSourceTopic ="dws_product_stats";
tableEnv.executeSql("CREATE TABLE product_stats (spu_name STRING, " +
"click_ct BIGINT," +
"cart_ct BIGINT," +
"order_ct BIGINT ," +
"stt STRING,edt STRING ) " +
" WITH ("+ MyKafkaUtil.getKafkaDDL(productStatsSourceTopic,groupId)+")");
//TODO 6.聚合计数
Table keywordStatsProduct = tableEnv.sqlQuery("select keyword,ct,source, " +
"DATE_FORMAT(stt,'yyyy-MM-dd HH:mm:ss') stt," +
"DATE_FORMAT(edt,'yyyy-MM-dd HH:mm:ss') as edt, " +
"UNIX_TIMESTAMP()*1000 ts from product_stats , " +
"LATERAL TABLE(ik_analyze(spu_name)) as T(keyword) ," +
"LATERAL TABLE(keywordProductC2R( click_ct ,cart_ct,order_ct)) as T2(ct,source)");
//TODO 7.转换为数据流
DataStream keywordStatsProductDataStream =
tableEnv.toAppendStream(keywordStatsProduct, KeywordStats.class);
keywordStatsProductDataStream.print();
//TODO 8.写入到ClickHouse
keywordStatsProductDataStream.addSink(
ClickHouseUtil.getJdbcSink(
"insert into keyword_stats_2021(keyword,ct,source,stt,edt,ts) " +
"values(?,?,?,?,?,?)"));
env.execute();
}
} - 将ProductStatsApp统计后的结果写回到Kafka的dws
//TODO 9.写回到Kafka的dws层
productStatsWithTmDstream
.map(productStat->JSON.toJSONString(productStat,new SerializeConfig(true)))
.addSink(MyKafkaUtil.getKafkaSink("dws_product_stats"));
整体测试:
- 启动ZK、Kafka、logger.sh、ClickHouse、Redis、HDFS、Hbase、Maxwell
- 运行BaseLogApp
- 运行BaseDBApp
- 运行OrderWideApp
- 运行PaymentWideApp
- 运行ProductsStatsApp
- 运行KeywordStats4ProductApp
- 运行rt_applog目录下的jar包
- 运行rt_dblog目录下的jar包
- 查看控制台输出
- 查看ClickHouse中products_stats_2021表数据
总结:
- DWS层主要是基于DWD和DWM层的数据进行轻度聚合统计。
- 掌握利用union操作实现多流的合并
- 掌握窗口聚合操作
- 掌握对clickhouse数据库的写入操作
- 掌握用FlinkSQL实现业务
- 掌握分词器的使用
- 掌握在FlinkSQL中自定义函数的使用
七、数据可视化接口实现
1、数据可视化接口
之前数据分层处理,最后把轻度聚合的结果保存到ClickHouse中,主要的目的就是提供即时的数据查询、统计、分析服务。这些统计服务一般会用两种形式展现,一种是为专业的数据分析人员的BI工具,一种是面向非专业人员的更加直观的数据大屏。
以下主要是面向百度的sugar的数据大屏服务的接口开发。
2、需求梳理
最终显示效果图:
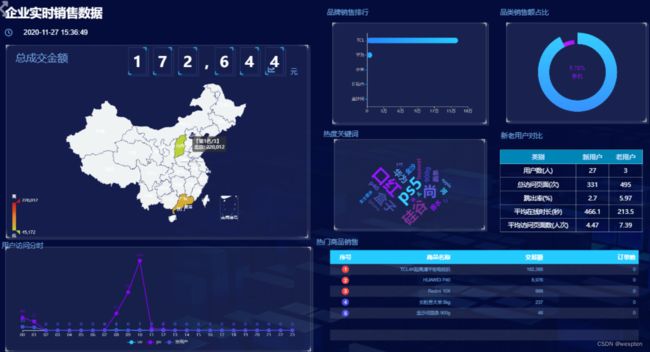
分析可视化大屏:
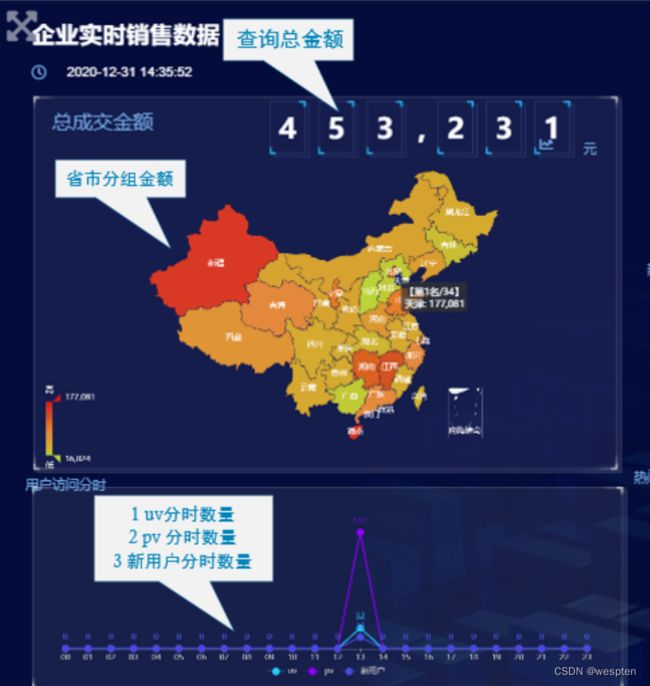

在可视化大屏中每个组件都需要一个单独的接口,图中一共涉及8个组件。
| 组件名称 |
组件 |
查询指标 |
对应的数据表 |
| 总成交金额 |
数字翻牌 |
订单总金额 |
product_stats |
| 省市热力图查询 |
热力图 |
省市分组订单金额 |
province_stats |
| 分时流量 |
折线图 |
UV分时数 PV分时数 新用户分时数 |
visitor_stats |
| 品牌TopN |
水平柱状图 |
按品牌分组订单金额 |
product_stats |
| 品类分布 |
饼状图 |
按品类分组订单金额 |
product_stats |
| 热词字符云 |
字符云 |
关键词分组计数 |
keyword_stats |
| 流量表格 |
交叉透视表 |
UV数(新老用户) PV数(新老用户) 跳出率(新老用户) 平均访问时长 (新老用户) 平均访问页面数(新老用户) |
visitor_stats |
| 热门商品 |
轮播表格 |
按SPU分组订单金额 |
product_stats |
接口执行过程:
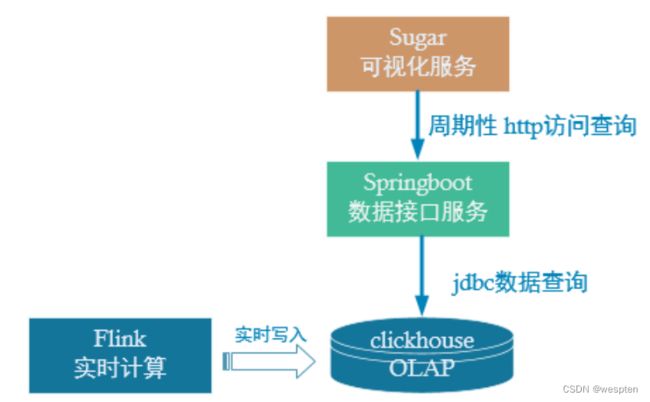
之前我们实现了DWS层计算后写入到ClickHouse中,接下来就是要为可视化大屏服务,提供一个数据接口用来查询ClickHouse中的数据。这里主要有两项工作
- 配置可视化大屏服务。
- 编写数据查询接口以供可视化大屏进行访问。
3、Sugar数据大屏
Sugar是百度云推出的敏捷 BI 和数据可视化平台,目标是解决报表和大屏的数据 BI 分析和可视化问题,解放数据可视化系统的开发人力。
使用方法,详见:数据可视化Sugar BI-百度智能云
创建数据大屏:
点击【立即使用】后,登录百度账号。
然后首先创建组织:

创建中选择产品【大屏尝鲜版】,首次使用有一个月的试用期:

新建好组织后选择【进入组织】:

然后进入默认的【第一个空间】:
在空间中选择【待创建大屏】后的【新建】:
选择大屏的模板:
可以选空模板,也可以根据现有的模板进行修改。
我们这里选择空白模板,并指定大屏的名称:
进入大屏的编辑窗口:
4、总成交金额接口
1. Sugar组件:数字翻牌器
添加组件:
从大屏的编辑器上方选择【指标】→【数字翻牌器】。

配置组件:
点击组件,在右侧的菜单中选择【数据】,绑定方式改为【API拉取】。
下方的路径填写:
$API_HOST/api/sugar/gmv这个就是sugar会周期性访问的数据接口地址,可以自定义,其中$API_HOST是个全局变量,需要在空间中配置(后面再说)。
2. 查询组件需要的数据格式
在数据绑定的位置选择【静态JSON】,可以看到数据需要的JSON格式。

3. 接口访问路径以及返回格式
- 访问路径
/api/sugar/gmv- 返回格式
{
"status": 0,
"msg": "",
"data": 1201081.1632389291
}4. 数据接口实现
1)创建数据接口模块
在gmall2021-parent项目下创建新的模块gmall2021-publisher:
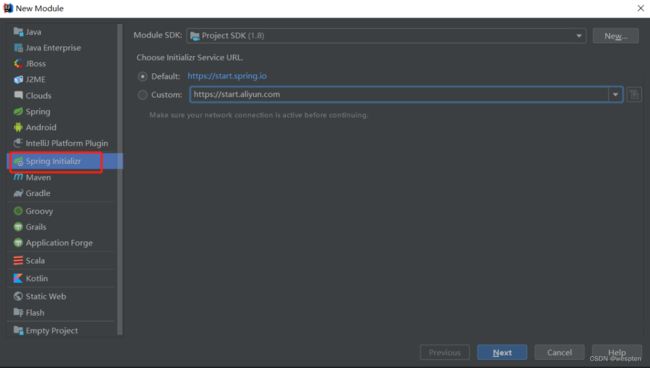

可以先不选择依赖,之后统一在pom.xml中添加。
在pom.xml文件中添加需要的依赖:
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.4.2
com.yyds.gmall
gmall2021-publisher
0.0.1-SNAPSHOT
gmall2021-publisher
Demo project for Spring Boot
1.8
org.springframework.boot
spring-boot-starter-jdbc
org.springframework.boot
spring-boot-starter-web
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.1.3
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.junit.vintage
junit-vintage-engine
org.apache.commons
commons-lang3
3.11
ru.yandex.clickhouse
clickhouse-jdbc
0.1.55
org.springframework.boot
spring-boot-maven-plugin
2)代码分层结构以及实现
- 代码结构
| 分层 |
类 |
处理内容 |
| controller 控制层 |
SugarController |
查询交易额接口及返回参数处理 |
| service 服务层 |
ProductStatsService ProductStatsServiceImpl |
查询商品统计数据 |
| mapper 数据映射层 |
ProductStatsMapper |
编写SQL查询商品统计表 |
- 代码结构
修改Springboot核心配置文件 application.properties:
server.port=8070
#配置ClickHouse驱动以及URL
spring.datasource.driver-class-name=ru.yandex.clickhouse.ClickHouseDriver
spring.datasource.url=jdbc:clickhouse://hadoop202:8123/default在Application中添加@MapperScan的注解:
package com.yyds.gmall;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan(basePackages = "com.yyds.gmall.mapper")
public class Gmall2021PublisherApplication {
public static void main(String[] args) {
SpringApplication.run(Gmall2021PublisherApplication.class, args);
}
}Mapper层:创建ProductStatsMapper接口:
package com.yyds.gmall.mapper;
import org.apache.ibatis.annotations.Select;
import java.math.BigDecimal;
/**
* Author: Felix
* Desc: 商品统计Mapper
*/
public interface ProductStatsMapper {
//获取商品交易额
@Select("select sum(order_amount) order_amount " +
"from product_stats_2021 where toYYYYMMDD(stt)=#{date}")
public BigDecimal selectGMV(int date);
}Service层:创建ProductStatsService接口:
package com.yyds.gmall.service;
import java.math.BigDecimal;
/**
* Author: Felix
* Desc: 商品统计接口
*/
public interface ProductStatsService {
//获取某一天的总交易额
public BigDecimal getGMV(int date);
}Service层:创建ProductStatsServiceImpl实现类:
package com.yyds.gmall.service.impl;
import com.yyds.gmall.mapper.ProductStatsMapper;
import com.yyds.gmall.service.ProductStatsService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.math.BigDecimal;
/**
* Author: Felix
* Desc: 商品统计接口实现类
*/
@Service
public class ProductStatsServiceImpl implements ProductStatsService {
@Autowired
ProductStatsMapper productStatsMapper;
@Override
public BigDecimal getGMV(int date) {
return productStatsMapper.selectGMV(date);
}
}Controller层:创建SugarController类:
该类主要接收用户请求,并做出相应。根据sugar不同的组件,返回不同的格式。
package com.yyds.gmall.controller;
import com.yyds.gmall.service.ProductStatsService;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.math.BigDecimal;
import java.util.Date;
/**
* Author: Felix
* Desc: sugar处理类
* 主要接收用户请求,并做出相应。根据sugar不同的组件,返回不同的格式
*/
@RestController
@RequestMapping("/api/sugar")
public class SugarController {
@Autowired
ProductStatsService productStatsService;
/*
{
"status": 0,
"msg": "",
"data": 1201081.1632389291
}
*/
@RequestMapping("/gmv")
public String getGMV(@RequestParam(value = "date",defaultValue = "0") Integer date) {
if(date==0){
date=now();
}
BigDecimal gmv = productStatsService.getGMV(date);
String json = "{ \"status\": 0, \"data\":" + gmv + "}";
return json;
}
private int now(){
String yyyyMMdd = DateFormatUtils.format(new Date(), "yyyyMMdd");
return Integer.valueOf(yyyyMMdd);
}
}3)测试本地接口
启动SpringBoot应用程序。
用浏览器访问测试接口:
http://localhost:8070/api/sugar/gmv
输出结果:

5、商品交易额不同维度的统计
1. 三个关于商品交易额方面的统计
- 品牌,水平柱状图
- 品类,饼形图
- 商品spu,轮播图
这三个的共同特征是可以根据商品统计信息计算出来。
2. Sugar组件:横向柱图、轮播饼图、轮播表格
1)添加组件
横向柱图,用于显示品牌排行。
轮播饼图,用于显示品类图:

轮播表格,用于显示热门商品排行:

2)品牌排行的柱形图组件配置
修改获取数据的方式,指定访问路径。
访问路径:
$API_HOST/api/sugar/trademark?limit=5
修改排序规则:
因为排序规则是从下到上,所以排序定位从小到大。
查看返回值数据格式:
{
"status": 0,
"msg": "",
"data": {
"categories": [
"苹果",
"三星",
"华为",
"oppo",
"vivo",
"小米29"
],
"series": [
{
"name": "手机品牌",
"data": [
7562,
5215,
6911,
8565,
6800,
7691
]
}
]
}
}3)品类分布的饼形图组件配置
修改获取数据的方式,指定访问路径。
访问路径:
$API_HOST/api/sugar/category3
查看返回值数据格式:
{
"status": 0,
"msg": "",
"data": [
{
"name": "windows phone",
"value": 29
},
{
"name": "Nokia S60",
"value": 2
},
{
"name": "Nokia S90",
"value": 1
}
]
}4)商品排行的轮播表格组件配置
修改获取数据的方式,指定访问路径。
访问路径:
$API_HOST/api/sugar/spu?limit=10
查看返回值数据格式:
{
"status": 0,
"msg": "",
"data": {
"columns": [
{
"name": "商品名称",
"id": "spu_name"
},
{
"name": "成交金额",
"id": "amount"
}
],
"rows": [
{
"spu_name": "商品1",
"amount": "金额1"
},
{
"spu_name": "商品2",
"amount": "金额2"
},
{
"spu_name": "商品3",
"amount": "金额3"
}
]
}
}3. 数据接口实现
这三个图基本上都是根据用不同维度进行分组,金额进行聚合的方式查询商品统计表。直接先实现三个sql查询。
1)创建商品交易额统计实体类ProductStats
package com.yyds.gmall.bean;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.math.BigDecimal;
/**
* Author: Felix
* Desc: 商品交易额统计实体类
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ProductStats {
String stt;
String edt;
Long sku_id;
String sku_name;
BigDecimal sku_price;
Long spu_id;
String spu_name;
Long tm_id ;
String tm_name;
Long category3_id ;
String category3_name ;
@Builder.Default
Long display_ct=0L;
@Builder.Default
Long click_ct=0L;
@Builder.Default
Long cart_ct=0L;
@Builder.Default
Long order_sku_num=0L;
@Builder.Default
BigDecimal order_amount=BigDecimal.ZERO;
@Builder.Default
Long order_ct=0L;
@Builder.Default
BigDecimal payment_amount=BigDecimal.ZERO;
@Builder.Default
Long refund_ct=0L;
@Builder.Default
BigDecimal refund_amount=BigDecimal.ZERO;
@Builder.Default
Long comment_ct=0L;
@Builder.Default
Long good_comment_ct=0L ;
Long ts;
}2)Mapper层:在ProductStatsMapper中添加方法
//统计某天不同SPU商品交易额排名
@Select("select spu_id,spu_name,sum(order_amount) order_amount," +
"sum(order_ct) order_ct from product_stats_2021 " +
"where toYYYYMMDD(stt)=#{date} group by spu_id,spu_name " +
"having order_amount>0 order by order_amount desc limit #{limit} ")
public List selectProductStatsGroupBySpu(@Param("date") int date, @Param("limit") int limit);
//统计某天不同类别商品交易额排名
@Select("select category3_id,category3_name,sum(order_amount) order_amount " +
"from product_stats_2021 " +
"where toYYYYMMDD(stt)=#{date} group by category3_id,category3_name " +
"having order_amount>0 order by order_amount desc limit #{limit}")
public List selectProductStatsGroupByCategory3(@Param("date")int date , @Param("limit") int limit);
//统计某天不同品牌商品交易额排名
@Select("select tm_id,tm_name,sum(order_amount) order_amount " +
"from product_stats_2021 " +
"where toYYYYMMDD(stt)=#{date} group by tm_id,tm_name " +
"having order_amount>0 order by order_amount desc limit #{limit} ")
public List selectProductStatsByTrademark(@Param("date")int date, @Param("limit") int limit); 3)Service层:在ProductStatsService中增加方法
//统计某天不同SPU商品交易额排名
public List getProductStatsGroupBySpu(int date, int limit);
//统计某天不同类别商品交易额排名
public List getProductStatsGroupByCategory3(int date,int limit);
//统计某天不同品牌商品交易额排名
public List getProductStatsByTrademark(int date,int limit); 4)Service层:在ProductStatsServiceImpl增加方法实现
@Override
public List getProductStatsGroupBySpu(int date, int limit) {
return productStatsMapper.selectProductStatsGroupBySpu(date, limit);
}
@Override
public List getProductStatsGroupByCategory3(int date, int limit) {
return productStatsMapper.selectProductStatsGroupByCategory3(date, limit);
}
@Override
public List getProductStatsByTrademark(int date,int limit) {
return productStatsMapper.selectProductStatsByTrademark(date, limit);
} 5)Controller层:在SugarCongroller添加方法
注意:Controller方法的定义必须依照,定好的接口访问路径和返回值格式。
商品列表接口方法:
/*
{
"status": 0,
"data": {
"columns": [
{ "name": "商品名称", "id": "spu_name"
},
{ "name": "交易额", "id": "order_amount"
}
],
"rows": [
{
"spu_name": "小米10",
"order_amount": "863399.00"
},
{
"spu_name": "iPhone11",
"order_amount": "548399.00"
}
]
}
}
*/
@RequestMapping("/spu")
public String getProductStatsGroupBySpu(
@RequestParam(value = "date", defaultValue = "0") Integer date,
@RequestParam(value = "limit", defaultValue = "10") int limit) {
if (date == 0) date = now();
List statsList
= productStatsService.getProductStatsGroupBySpu(date, limit);
//设置表头
StringBuilder jsonBuilder =
new StringBuilder(" " +
"{\"status\":0,\"data\":{\"columns\":[" +
"{\"name\":\"商品名称\",\"id\":\"spu_name\"}," +
"{\"name\":\"交易额\",\"id\":\"order_amount\"}," +
"{\"name\":\"订单数\",\"id\":\"order_ct\"}]," +
"\"rows\":[");
//循环拼接表体
for (int i = 0; i < statsList.size(); i++) {
ProductStats productStats = statsList.get(i);
if (i >= 1) {
jsonBuilder.append(",");
}
jsonBuilder.append("{\"spu_name\":\"" + productStats.getSpu_name() + "\"," +
"\"order_amount\":" + productStats.getOrder_amount() + "," +
"\"order_ct\":" + productStats.getOrder_ct() + "}");
}
jsonBuilder.append("]}}");
return jsonBuilder.toString();
} 品类接口方法:
/*
{
"status": 0,
"data": [
{
"name": "数码类",
"value": 371570
},
{
"name": "日用品",
"value": 296016
}
]
}
*/
@RequestMapping("/category3")
public String getProductStatsGroupByCategory3(
@RequestParam(value = "date", defaultValue = "0") Integer date,
@RequestParam(value = "limit", defaultValue = "4") int limit) {
if (date == 0) {
date = now();
}
List statsList
= productStatsService.getProductStatsGroupByCategory3(date, limit);
StringBuilder dataJson = new StringBuilder("{ \"status\": 0, \"data\": [");
int i = 0;
for (ProductStats productStats : statsList) {
if (i++ > 0) {
dataJson.append(",");
}
;
dataJson.append("{\"name\":\"")
.append(productStats.getCategory3_name()).append("\",");
dataJson.append("\"value\":")
.append(productStats.getOrder_amount()).append("}");
}
dataJson.append("]}");
return dataJson.toString();
} 品牌接口方法:
/*
{
"status": 0,
"data": {
"categories": [
"三星","vivo","oppo"
],
"series": [
{
"data": [ 406333, 709174, 681971
]
}
]
}
}
*/
@RequestMapping("/trademark")
public String getProductStatsByTrademark(
@RequestParam(value = "date", defaultValue = "0") Integer date,
@RequestParam(value = "limit", defaultValue = "20") int limit) {
if (date == 0) {
date = now();
}
List productStatsByTrademarkList
= productStatsService.getProductStatsByTrademark(date, limit);
List tradeMarkList = new ArrayList<>();
List amountList = new ArrayList<>();
for (ProductStats productStats : productStatsByTrademarkList) {
tradeMarkList.add(productStats.getTm_name());
amountList.add(productStats.getOrder_amount());
}
String json = "{\"status\":0,\"data\":{" + "\"categories\":" +
"[\"" + StringUtils.join(tradeMarkList, "\",\"") + "\"],\"series\":[" +
"{\"data\":[" + StringUtils.join(amountList, ",") + "]}]}}";
return json;
} 6)本地接口测试
可以生成当前日期数据,具体步骤如下:
- 启动ZK、Kafka、ClickHouse、Redis、HDFS、Hbase、Maxwell
- 运行BaseDBApp
- 运行OrderWideApp
- 运行ProductsStatsApp
- 运行rt_dblog目录下的jar包
- 查看ClickHouse中products_stats_2021表数据
启动SpringBoot项目,根据访问地址分别用浏览器测试一下接口:
- 商品

- 品类

- 品牌

4. 刷新大屏图表数据
6、分省市的热力图统计
1. Sugar组件:中国省份色彩
1)添加组件
在上方地图栏位中选择【中国省份色彩】:

2)配置组件
修改获取数据的方式,指定访问路径:
访问路径:
$API_HOST/api/sugar/province 
设置各个省份间的边界线:

3)接口访问路径以及返回格式
- 访问路径
$API_HOST/api/sugar/province- 返回值格式
{
"status": 0,
"data": {
"mapData": [
{
"name": "北京",
"value": 9131
},
{
"name": "天津",
"value": 5740
}
],"valueName": "交易额"
}
}2. 数据接口实现
创建地区交易额统计实体类ProvinceStats:
package com.yyds.gmall.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.math.BigDecimal;
/**
* Author: Felix
* Desc: 地区交易额统计实体类
*/
@AllArgsConstructor
@Data
@NoArgsConstructor
public class ProvinceStats {
private String stt;
private String edt;
private String province_id;
private String province_name;
private BigDecimal order_amount;
private String ts;
}Mapper层:创建ProvinceStatsMapper接口:
package com.yyds.gmall.mapper;
import com.yyds.gmall.bean.ProvinceStats;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* Author: Felix
* Desc: 地区维度统计Mapper
*/
public interface ProvinceStatsMapper {
//按地区查询交易额
@Select("select province_name,sum(order_amount) order_amount " +
"from province_stats_2021 where toYYYYMMDD(stt)=#{date} " +
"group by province_id ,province_name ")
public List selectProvinceStats(int date);
} Service层:创建ProvinceStatsService接口:
package com.yyds.gmall.service;
import com.yyds.gmall.bean.ProvinceStats;
import java.util.List;
/**
* Author: Felix
* Desc: 地区维度统计接口
*/
public interface ProvinceStatsService {
public List getProvinceStats(int date);
} Service层:创建ProvinceStatsServiceImpl实现类:
package com.yyds.gmall.service.impl;
import com.yyds.gmall.bean.ProvinceStats;
import com.yyds.gmall.mapper.ProvinceStatsMapper;
import com.yyds.gmall.service.ProvinceStatsService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* Author: Felix
* Desc: 按地区维度统计Service实现
*/
@Service
public class ProvinceStatsServiceImpl implements ProvinceStatsService {
@Autowired
ProvinceStatsMapper provinceStatsMapper;
@Override
public List getProvinceStats(int date) {
return provinceStatsMapper.selectProvinceStats(date);
}
} Controller层:在SugarController中增加方法:
@Autowired
ProvinceStatsService provinceStatsService;
@RequestMapping("/province")
public String getProvinceStats(@RequestParam(value = "date", defaultValue = "0") Integer date) {
if (date == 0) {
date = now();
}
StringBuilder jsonBuilder = new StringBuilder("{\"status\":0,\"data\":{\"mapData\":[");
List provinceStatsList = provinceStatsService.getProvinceStats(date);
if (provinceStatsList.size() == 0) {
// jsonBuilder.append( "{\"name\":\"北京\",\"value\":0.00}");
}
for (int i = 0; i < provinceStatsList.size(); i++) {
if (i >= 1) {
jsonBuilder.append(",");
}
ProvinceStats provinceStats = provinceStatsList.get(i);
jsonBuilder.append("{\"name\":\"" + provinceStats.getProvince_name() + "\",\"value\":" + provinceStats.getOrder_amount() + " }");
}
jsonBuilder.append("],"valueName": "交易额"}}");
return jsonBuilder.toString();
} 本地接口测试:

3. 刷新大屏组件数据

7、流量统计数据
流量统计组件包含两个部分一个是分时流量折线图,另一个是新老访客流量对比表格。
1. Sugar组件:表格
1)添加组件
表格,用于显示新老访客对比:
在上方【表格】栏位中选择【表格】。
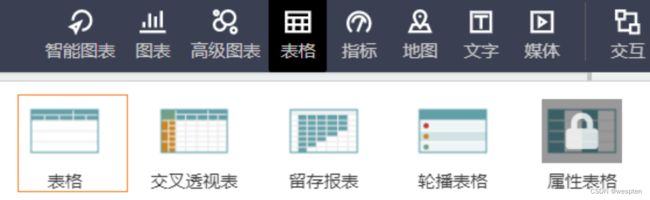
折线图,用于显示分时流量:
在上方【图表】栏位中选择【折线图】。
2)新老访客对比的表格组件配置
修改获取数据的方式,指定访问路径:
访问路径:
$API_HOST/api/sugar/visitor 
查看返回值数据格式:
{
"status": 0,
"data": {
"combineNum": 1,
"columns": [
{
"name": "类别",
"id": "type"
},
{
"name": "新用户",
"id": "new"
},
{
"name": "老用户",
"id": "old"
}
],
"rows": [
{
"type": "用户数",
"new": 123,
"old": 13
},
{
"type": "总访问页面",
"new": 123,
"old": 145
},
{
"type": "跳出率",
"new": 123,
"old": 145
},
{
"type": "平均在线时长",
"new": 123,
"old": 145
},
{
"type": "平均访问页面数",
"new": 23,
"old": 145
}
]
}
}3)分时流量显示的折线组件配置
修改获取数据的方式,指定访问路径。
访问路径:
$API_HOST/api/sugar/hr
查看返回值数据格式:
{
"status": 0,
"data": {
"categories": [
"01",
"02",
"03",
"04",
"05"
],
"series": [
{
"name": "uv",
"data": [
888065,
892945,
678379,
733572,
525091
]
},
{
"name": "pv",
"data": [
563998,
571831,
622419,
675294,
708512
]
},
{
"name": "新用户",
"data": [
563998,
571831,
622419,
675294,
708512
]
}
]
}
}2. 数据接口实现
创建访问流量统计实体类VisitorStats:
package com.yyds.gmall.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.math.BigDecimal;
import java.math.RoundingMode;
/**
* Author: Felix
* Desc: 访客流量统计实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class VisitorStats {
private String stt;
private String edt;
private String vc;
private String ch;
private String ar;
private String is_new;
private Long uv_ct = 0L;
private Long pv_ct = 0L;
private Long sv_ct = 0L;
private Long uj_ct = 0L;
private Long dur_sum = 0L;
private Long new_uv = 0L;
private Long ts;
private int hr;
//计算跳出率 = 跳出次数*100/访问次数
public BigDecimal getUjRate() {
if (uv_ct != 0L) {
return BigDecimal.valueOf(uj_ct)
.multiply(BigDecimal.valueOf(100))
.divide(BigDecimal.valueOf(sv_ct), 2, RoundingMode.HALF_UP);
} else {
return BigDecimal.ZERO;
}
}
//计算每次访问停留时间(秒) = 当日总停留时间(毫秒)/当日访问次数/1000
public BigDecimal getDurPerSv() {
if (uv_ct != 0L) {
return BigDecimal.valueOf(dur_sum)
.divide(BigDecimal.valueOf(sv_ct), 0, RoundingMode.HALF_UP)
.divide(BigDecimal.valueOf(1000), 1, RoundingMode.HALF_UP);
} else {
return BigDecimal.ZERO;
}
}
//计算每次访问停留页面数 = 当日总访问页面数/当日访问次数
public BigDecimal getPvPerSv() {
if (uv_ct != 0L) {
return BigDecimal.valueOf(pv_ct)
.divide(BigDecimal.valueOf(sv_ct), 2, RoundingMode.HALF_UP);
} else {
return BigDecimal.ZERO;
}
}
}Mapper层:创建VisitorStatsMapper:
package com.yyds.gmall.mapper;
import com.yyds.gmall.bean.VisitorStats;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* Author: Felix
* Desc: 访客流量统计Mapper
*/
public interface VisitorStatsMapper {
//新老访客流量统计
@Select("select is_new,sum(uv_ct) uv_ct,sum(pv_ct) pv_ct," +
"sum(sv_ct) sv_ct, sum(uj_ct) uj_ct,sum(dur_sum) dur_sum " +
"from visitor_stats_2021 where toYYYYMMDD(stt)=#{date} group by is_new")
public List selectVisitorStatsByIsNew (int date);
//分时流量统计
@Select("select sum(if(is_new='1', visitor_stats_2021.uv_ct,0)) new_uv,toHour(stt) hr," +
"sum(visitor_stats_2021.uv_ct) uv_ct, sum(pv_ct) pv_ct, sum(uj_ct) uj_ct " +
"from visitor_stats_2021 where toYYYYMMDD(stt)=#{date} group by toHour(stt)")
public List selectVisitorStatsByHour(int date);
@Select("select count(pv_ct) pv_ct from visitor_stats_2021 " +
"where toYYYYMMDD(stt)=#{date} ")
public Long selectPv(int date);
@Select("select count(uv_ct) uv_ct from visitor_stats_2021 " +
"where toYYYYMMDD(stt)=#{date} ")
public Long selectUv(int date);
} Service层:创建VisitorStatsService接口:
package com.yyds.gmall.service;
import com.yyds.gmall.bean.VisitorStats;
import java.util.List;
/**
* Author: Felix
* Desc: 访问流量统计Service接口
*/
public interface VisitorStatsService {
public List getVisitorStatsByIsNew (int date);
public List getVisitorStatsByHour(int date);
public Long getPv(int date);
public Long getUv(int date);
} Service层:创建VisitorStatsServiceImpl实现类:
package com.yyds.gmall.service.impl;
import com.yyds.gmall.bean.VisitorStats;
import com.yyds.gmall.mapper.VisitorStatsMapper;
import com.yyds.gmall.service.VisitorStatsService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* Author: Felix
* Desc: 访问流量统计Service实现类
*/
@Service
public class VisitorStatsServiceImpl implements VisitorStatsService {
@Autowired
VisitorStatsMapper visitorStatsMapper;
@Override
public List getVisitorStatsByIsNew(int date) {
return visitorStatsMapper.selectVisitorStatsByIsNew (date);
}
@Override
public List getVisitorStatsByHour(int date) {
return visitorStatsMapper.selectVisitorStatsByHour(date);
}
@Override
public Long getPv(int date) {
return visitorStatsMapper.selectPv(date);
}
@Override
public Long getUv(int date) {
return visitorStatsMapper.selectUv(date);
}
} Controller层:在SugarController中增加方法:
新老访客流量对比:
@Autowired
VisitorStatsService visitorStatsService;
@RequestMapping("/visitor")
public String getVisitorStatsByIsNew (@RequestParam(value = "date", defaultValue = "0") Integer date) {
if (date == 0) date = now();
List visitorStatsList = visitorStatsService.getVisitorStatsByIsNew (date);
VisitorStats newVisitorStats = new VisitorStats();
VisitorStats oldVisitorStats = new VisitorStats();
//循环把数据赋给新访客统计对象和老访客统计对象
for (VisitorStats visitorStats : visitorStatsList) {
if (visitorStats.getIs_new().equals("1")) {
newVisitorStats = visitorStats;
} else {
oldVisitorStats = visitorStats;
}
}
//把数据拼接入字符串
String json = "{\"status\":0,\"data\":{\"combineNum\":1,\"columns\":" +
"[{\"name\":\"类别\",\"id\":\"type\"}," +
"{\"name\":\"新用户\",\"id\":\"new\"}," +
"{\"name\":\"老用户\",\"id\":\"old\"}]," +
"\"rows\":" +
"[{\"type\":\"用户数(人)\"," +
"\"new\": " + newVisitorStats.getUv_ct() + "," +
"\"old\":" + oldVisitorStats.getUv_ct() + "}," +
"{\"type\":\"总访问页面(次)\"," +
"\"new\":" + newVisitorStats.getPv_ct() + "," +
"\"old\":" + oldVisitorStats.getPv_ct() + "}," +
"{\"type\":\"跳出率(%)\"," +
"\"new\":" + newVisitorStats.getUjRate() + "," +
"\"old\":" + oldVisitorStats.getUjRate() + "}," +
"{\"type\":\"平均在线时长(秒)\"," +
"\"new\":" + newVisitorStats.getDurPerSv() + "," +
"\"old\":" + oldVisitorStats.getDurPerSv() + "}," +
"{\"type\":\"平均访问页面数(人次)\"," +
"\"new\":" + newVisitorStats.getPvPerSv() + "," +
"\"old\":" + oldVisitorStats.getPvPerSv()
+ "}]}}";
return json;
} 分时流量统计:
@RequestMapping("/hr")
public String getMidStatsGroupbyHourNewFlag(@RequestParam(value = "date",defaultValue = "0") Integer date ) {
if(date==0) date=now();
List visitorStatsHrList
= visitorStatsService.getVisitorStatsByHour(date);
//构建24位数组
VisitorStats[] visitorStatsArr=new VisitorStats[24];
//把对应小时的位置赋值
for (VisitorStats visitorStats : visitorStatsHrList) {
visitorStatsArr[visitorStats.getHr()] =visitorStats ;
}
List hrList=new ArrayList<>();
List uvList=new ArrayList<>();
List pvList=new ArrayList<>();
List newMidList=new ArrayList<>();
//循环出固定的0-23个小时 从结果map中查询对应的值
for (int hr = 0; hr <=23 ; hr++) {
VisitorStats visitorStats = visitorStatsArr[hr];
if (visitorStats!=null){
uvList.add(visitorStats.getUv_ct()) ;
pvList.add( visitorStats.getPv_ct());
newMidList.add( visitorStats.getNew_uv());
}else{ //该小时没有流量补零
uvList.add(0L) ;
pvList.add( 0L);
newMidList.add( 0L);
}
//小时数不足两位补零
hrList.add(String.format("%02d", hr));
}
//拼接字符串
String json = "{\"status\":0,\"data\":{" + "\"categories\":" +
"[\""+StringUtils.join(hrList,"\",\"")+ "\"],\"series\":[" +
"{\"name\":\"uv\",\"data\":["+ StringUtils.join(uvList,",") +"]}," +
"{\"name\":\"pv\",\"data\":["+ StringUtils.join(pvList,",") +"]}," +
"{\"name\":\"新用户\",\"data\":["+ StringUtils.join(newMidList,",") +"]}]}}";
return json;
} 3. 本地接口测试
可以生成当前日期数据,具体步骤如下:
- 启动ZK、Kafka、Logger.sh、ClickHouse
- 运行BaseLogApp
- 运行UniqueVisitApp
- 运行UserJumpDetailApp
- 运行VisitorStatsApp
- 运行rt_applog目录下的jar包
- 查看ClickHouse中visitor_stats_2021表数据
启动SpringBoot项目,根据访问地址分别用浏览器测试一下接口:
- 新老用户流量对比
![]()
- 分时流量统计
![]()
4. 刷新大屏组件数据
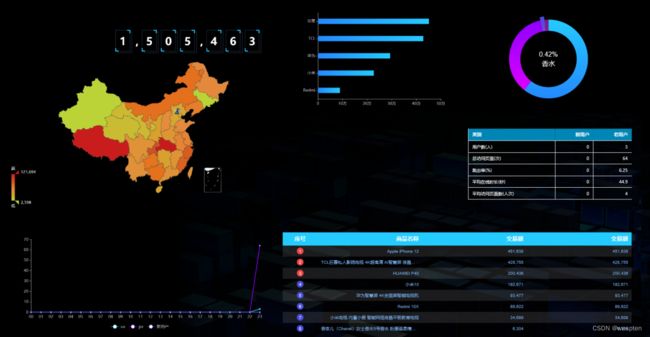
8、热词字符云
1. Sugar组件:字符云
1)添加组件
在上方【文字】栏位中选择【字符云】:

2)配置组件
访问路径:
$API_HOST/api/sugar/keyword
接口访问路径以及返回格式:
- 访问路径
$API_HOST/api/sugar/keyword- 返回值格式
{
"status": 0,
"data": [
{
"name": "data",
"value": 60679,
},
{
"name": "dataZoom",
"value": 24347,
}
]
}2. 数据接口实现
创建关键词统计实体类:
package com.yyds.gmall.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* Author: Felix
* Desc: 关键词统计实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class KeywordStats {
private String stt;
private String edt;
private String keyword;
private Long ct;
private String ts;
}Mapper层:创建KeywordStatsMapper:
1)SQL语句
根据关键词的出现类型分配不同的热度分数:
- 搜索关键词=10分
- 下单商品=5分
- 加入购物车=2分
- 点击商品=1分
- 其他=0分
其中ClickHouse函数multiIf类似于case when。
select keyword,
sum(keyword_stats_2021.ct *
multiIf(
source='SEARCH',10,
source='ORDER',5,
source='CART',2,
source='CLICK',1,0
)) ct
from
keyword_stats
where
toYYYYMMDD(stt)=#{date}
group by
keyword
order by
sum(keyword_stats.ct)
limit #{limit};2)接口类
package com.yyds.gmall.mapper;
import com.yyds.gmall.bean.KeywordStats;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* Author: Felix
* Desc: 关键词统计Mapper
*/
public interface KeywordStatsMapper {
@Select("select keyword," +
"sum(keyword_stats_2021.ct * " +
"multiIf(source='SEARCH',10,source='ORDER',3,source='CART',2,source='CLICK',1,0)) ct" +
" from keyword_stats_2021 where toYYYYMMDD(stt)=#{date} group by keyword " +
"order by sum(keyword_stats_2021.ct) desc limit #{limit} ")
public List selectKeywordStats(@Param("date") int date, @Param("limit") int limit);
} Service层:创建KeywordStatsService接口:
package com.yyds.gmall.service;
import com.yyds.gmall.bean.KeywordStats;
import java.util.List;
/**
* Author: Felix
* Desc: 关键词统计接口
*/
public interface KeywordStatsService {
public List getKeywordStats(int date, int limit);
} Service层:创建KeywordStatsServiceImpl:
package com.yyds.gmall.service.impl;
import com.yyds.gmall.bean.KeywordStats;
import com.yyds.gmall.mapper.KeywordStatsMapper;
import com.yyds.gmall.service.KeywordStatsService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* Author: Felix
* Desc:关键词统计接口实现类
*/
@Service
public class KeywordStatsServiceImpl implements KeywordStatsService {
@Autowired
KeywordStatsMapper keywordStatsMapper;
@Override
public List getKeywordStats(int date, int limit) {
return keywordStatsMapper.selectKeywordStats(date,limit);
}
} Controller层:在SugarController中增加方法:
@RequestMapping("/keyword")
public String getKeywordStats(@RequestParam(value = "date",defaultValue = "0") Integer date,
@RequestParam(value = "limit",defaultValue = "20") int limit){
if(date==0){
date=now();
}
//查询数据
List keywordStatsList
= keywordStatsService.getKeywordStats(date, limit);
StringBuilder jsonSb=new StringBuilder( "{\"status\":0,\"msg\":\"\",\"data\":[" );
//循环拼接字符串
for (int i = 0; i < keywordStatsList.size(); i++) {
KeywordStats keywordStats = keywordStatsList.get(i);
if(i>=1){
jsonSb.append(",");
}
jsonSb.append( "{\"name\":\"" + keywordStats.getKeyword() + "\"," +
"\"value\":"+keywordStats.getCt()+"}");
}
jsonSb.append( "]}");
return jsonSb.toString();
} 3. 本地接口测试
![]()
4. 刷新大屏组件数据
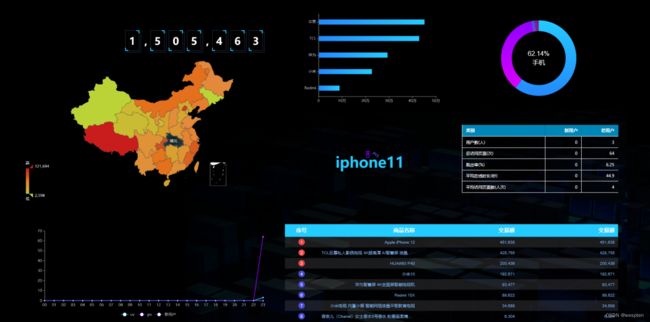
9、添加素材
从上方【文字】总选择文本:

从上方【素材】选择【边框】:

最终调整效果:
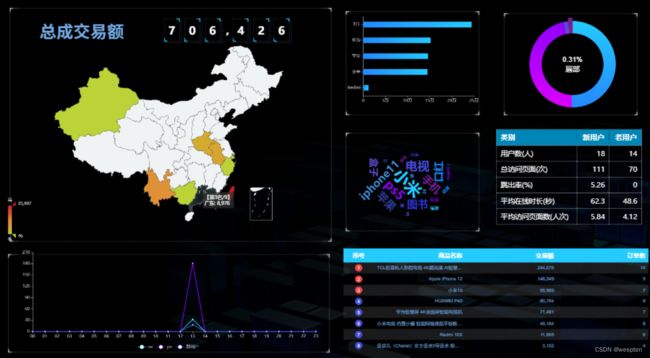
八、项目打包部署到服务器
1. 修改realtime项目中的并行度,并打jar包:
-BaseLogApp
-KeywordStatsApp 2. 修改flink-conf.yml:
taskmanager.memory.process.size: 1000m
taskmanager.numberOfTaskSlots: 83. 启动zk、kf、clickhouse、flink本地集群、logger.sh
4. 启动BaseLog、KeywordStatsApp
-独立分窗口启动:
bin/flink run -m hadoop202:8081 -c com.yyds.gmall.realtime.app.dwd.BaseLogApp ./gmall0820-realtime.jar
bin/flink run -m hadoop202:8081 -c com.yyds.gmall.realtime.app.dws.KeywordStatsApp ./gmall0820-realtime.jar-编写realtime.sh脚本:
echo "========BaseLogApp==============="
/opt/module/flink-local/bin/flink run -m hadoop202:8081 -c com.yyds.gmall.realtime.app.dwd.BaseLogApp /opt/module/flink-local/gmall0820-realtime.jar >/dev/null 2>&1 &
echo "========KeywordStatsApp==============="
/opt/module/flink-local/bin/flink run -m hadoop202:8081 -c com.yyds.gmall.realtime.app.dws.KeywordStatsApp /opt/module/flink-local/gmall0820-realtime.jar >/dev/null 2>&1 &5. 打包publisher并上传运行
6. 花生壳添加hadoop上的publisher地址映射
7. sugar修改空间映射
8. 运行模拟生成日志的jar包,查看效果
九、常见问题排查
1)启动flink集群,不能访问webUI
- 查看日志,端口冲突 lsof -i:8081
2)集群启动之后,不能启动
bin/flink run -m hadoop102:8081 -c com.yyds.gmall.realtime.app.dwd.BaseLogApp ./gmall000-realtime-1.0.jar- phoenix驱动不识别,需要加Class.forName指定
3)找不到hadoop和hbase等相关的jar
原因:NoClassDefoundError:这个错误编译期间不会报,运行期间才会包。原因是运行期间找不到这个类或无法加载,这个比较复杂。我的做法是把类所在jar包放在flink lib下重启集群就不会出现这个问题。
解决:
- 在my.env环境变量中添加
export HADOOP_CLASSPATH=`hadoop classpath`- 在flink的lib目录下创建执行hbase的lib的软连接
ln -s /opt/module/hbase/lib/ ./4)和官方jar包冲突
Caused by: java.lang.ClassCastException: org.codehaus.janino.CompilerFactory cannot be cast to org.codehaus.commons.compiler.ICompilerFactory将程序中flink\hadoop相关以及三个日志包的scope调整为provided:
provided 注意:不包含connector相关的。
总结
数据接口部分开发的重点:
- 学会通过springboot搭建一个web服务。
- 学会在Web服务使用注解方式,通过SQL语句查询ClickHouse。
- 学会通过Sugar实现数据大屏可视化配置,了解其中的地图、柱形图、饼图、折线图、表格、轮播表、字符云等组件的使用预配置。