- required archivelog files for a guaranteed restore point 查找GRP需要的归档文件
jnrjian
oraclesql
Appliesto:OracleDatabase-EnterpriseEdition-Version11.2.0.2andlaterInformationinthisdocumentappliestoanyplatform.GoalHowcanyoudeterminetherequiredarchivelogfilesneededforaguaranteedrestorepointbeforeru
- HDFS文件系统
HDFS文件系统是hadoop生态系统的核心,主要用于分布式文件存储,它具备高可用,流式读取,文件结构简单,跨平台的特点,它的集群采用的是主从结构,分为命名节点和数据节点,命名节点主要用于元数据管理(例如对目录,文件的创建,数据块与数据节点的关系维护管理)及数据节点管理(例如数据节点之间数据的复制,节点状态的维护,节点间数据的均衡),该文件系统最基本的存储单位是block即数据块,默认大小是64M
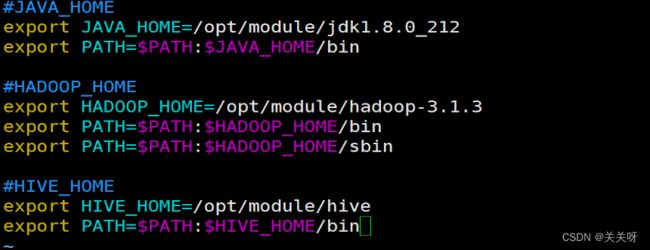
- Flink-Hadoop实战项目
Dylan_muc
hadoophdfsflink
项目说明文档1.项目概述1.1项目简介本项目是一个基于ApacheFlink的大数据流处理平台,专门用于处理铁路系统的票务和车次信息数据。系统包含两个核心流处理作业:文件处理作业和数据合并作业,采用定时调度机制,支持Kerberos安全认证,实现从文件读取到数据仓库存储的完整数据处理链路。1.2技术栈流处理引擎:ApacheFlink1.18.1存储系统:HDFS(Hadoop分布式文件系统)数据
- 大数据集群运维常见的一些问题以及处理方式
态);若为YARN节点,重启NodeManager后手动将其加入集群。若为节点整体宕机:排查电源和网络,重启节点后,依次启动HDFS、YARN等服务进程,确认数据块完整性(避免因节点宕机导致副本不足)。2.网络问题现象:节点间通信超时(如HDFS心跳超时、YARN任务调度延迟)、数据传输卡顿。可能原因:交换机故障、网线松动、网络带宽过载、防火墙规则拦截。处理方式:用ping、traceroute检
- 大数据技术是解决什么问题的?
@佳瑞
大数据
基础知识1TB(太字节)=1024GB1PB(拍字节)=1024TB大数据核心框架HadoopHadoop作为大数据技术生态的核心框架,主要解决了海量数据(TB/PB级)的存储、处理和分析难题,尤其是在传统数据库(如MySQL)和单机计算无法应对的场景下,提供了低成本、高可靠、可扩展的解决方案。其核心解决的问题可归纳为以下几点:海量数据的存储问题传统痛点:单机存储容量有限(如单服务器硬盘通常在TB
- Hadoop与图像识别与处理
AI天才研究院
AI大模型企业级应用开发实战AgenticAI实战AI人工智能与大数据计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
Hadoop与图像识别与处理作者:禅与计算机程序设计艺术/ZenandtheArtofComputerProgramming1.背景介绍1.1问题的由来在大数据时代,数据的爆炸性增长对数据处理技术提出了新的挑战。图像数据作为一种重要的数据形式,其处理和分析在许多领域中具有重要意义,如医疗影像分析、自动驾驶、安防监控等。然而,传统的图像处理方法在面对海量图像数据时显得力不从心。Hadoop作为一种分
- Python 应用无监督学习(一)
绝不原创的飞龙
默认分类默认分类
原文:annas-archive.org/md5/6b15c463e64a9f03f0d968a77b424918译者:飞龙协议:CCBY-NC-SA4.0前言关于本节简要介绍了作者、本书的内容覆盖范围、开始时你需要的技术技能,以及完成所有活动和练习所需的硬件和软件要求。本书简介无监督学习是一种在没有标签数据的情况下非常有用且实用的解决方案。Python应用无监督学习引导你使用无监督学习技术与Py
- hadoop 集群问题处理
一切顺势而行
hadoop大数据分布式
1.1.JournalNode的作用在HDFSHA配置中,为了实现两个NameNode之间的状态同步和故障自动切换,Hadoop使用了一组JournalNode来管理共享的编辑日志。具体来说,JournalNode的主要职责包括:共享编辑日志:JournalNode节点组成了一个分布式系统,用于存储HDFS的编辑日志(EditLogs)。这两个日志文件记录了对HDFS所做的所有更改,如文件创建、删
- sqoop从mysql导数据到hdfs,出现java.lang.ClassNotFoundException: Class QueryResult not found
无级程序员
大数据sqoopmysqlhdfs
运行sqoop从postgresql/mysql导入数据到hdfs,结果出现如下错误:2025-07-1816:59:13,624INFOorm.CompilationManager:HADOOP_MAPRED_HOMEis/opt/datasophon/hadoop-3.3.3Note:/opt/sqoop/bin/QueryResult.javausesoroverridesadeprecat
- datasophon下dolphinscheduler执行脚本出错
无级程序员
大数据hive硬件架构hadoop
执行hive脚本出错:错误消息:FAILED:RuntimeExceptionErrorloadinghooks(hive.exec.post.hooks):java.lang.ClassNotFoundException:org.apache.atlas.hive.hook.HiveHookatjava.net.URLClassLoader.findClass(URLClassLoader.ja
- hive 分区表select全部数据_hive分区表
Xenophon Tony
hive分区表select全部数据
内部表和外部表内部表:createtable,copy数据到warehouse,删除表时数据也会删除外部表:createexternaltable,不copy数据到warehouse,删除表时数据不会删除表的分区分区的好处:如果不建立分区的话,则会全表扫描数据通过目录划分分区,分区字段是特殊字段目录结构:/pub/{dt}/{customer_id}/添加分区:ALTERTABLEfsADDPAT
- hive底层原理 sql执行过程_Hive原理总结(完整版)
目录课程大纲(HIVE增强)31.Hive基本概念41.1Hive简介41.1.1什么是Hive41.1.2为什么使用Hive41.1.3Hive的特点41.2Hive架构51.2.1架构图51.2.2基本组成51.2.3各组件的基本功能51.3Hive与Hadoop的关系61.4Hive与传统数据库对比61.5Hive的数据存储62.Hive基本操作72.1DDL操作72.1.1创建表72.1.
- hive的sql优化思路-明白底层运行逻辑
ycllycll
hivesqlhadoop
一、首先要明白底层map、shuffle、reduce的顺序之中服务器hdfs数据文件在内存与存储之中是怎么演变的,因为hive的性能瓶颈基本在内存,具体参考以下他人优秀文章:1.HiveSQL底层执行过程详细剖析2.HiveJOIN性能调优二是要明白hive对应的sql它底层的mapreduce的过程中sql字段的执行顺序,来理解map的key、value会填充什么值,才能深刻理解怎么一步一步的
- 六、深度剖析 Hadoop 分布式文件系统(HDFS)的数据存储机制与读写流程
深度剖析Hadoop分布式文件系统(HDFS)的数据存储机制与读写流程在当今大数据领域当中,Hadoop分布式文件系统(HDFS)作为极为关键的核心组件之一,为海量规模的数据的存储以及处理构筑起了坚实无比的根基。本文将会对HDFS的数据存储机制以及读写流程展开全面且深入的探究,通过将原理与实际的实例紧密结合的方式,助力广大读者更加全面地理解HDFS的工作原理以及其具体的应用场景。一、HDFS概述H
- python连接数据库的方法,Python 连接数据库的多种方法
AI MIU
python连接数据库的方法
JZGKCHINAPython是一种计算机程序设计语言,它是一种动态的、面向对象的脚本语言。它是一种跨平台的,可以运行在Windows,Mac和Linux/Unix系统上。在日常使用中需要对大量数据进行数据分析,那么就必然用到数据库,我们常用的数据库有SQLServer,MySQL,Oracle,DB2,SQLite,Hive,PostgreSQL,MongoDB还有其他常用的MicrosoftA
- 大数据处理技术:分布式文件系统HDFS
茜茜西西CeCe
hdfshadoop大数据HDFS-JAVA接口文件头歌Java
目录1实验名称:2实验目的3实验内容4实验原理5实验过程或源代码5.1HDFS的基本操作5.2HDFS-JAVA接口之读取文件5.3HDFS-JAVA接口之上传文件5.4HDFS-JAVA接口之删除文件6实验结果6.1HDFS的基本操作6.2HDFS-JAVA接口之读取文件6.3HDFS-JAVA接口之上传文件6.4HDFS-JAVA接口之删除文件1实验名称:分布式文件系统HDFS2实验目的1.理
- Linux教程(4)----[hive数据仓库工具]
.房东的猫
Linux教程(完善中~~)linux
Hive基本概念Hive简介什么是HiveHive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。为什么使用Hive直接使用hadoop所面临的问题人员学习成本太高
- 【Hadoop】onekey_install脚本
菜萝卜子
Linuxhadoop大数据分布式
hosts[root@kafka01hadoop-script]#cat/etc/hosts127.0.0.1localhostlocalhost.localdomainlocalhost4localhost4.localdomain4::1localhostlocalhost.localdomainlocalhost6localhost6.localdomain6192.168.100.150k
- flink sql读hive catalog数据,将string类型的时间戳数据排序后写入kafka,如何保障写入kafka的数据是有序的
fzip
Flinkflinksqlhive
在FlinkSQL中,要确保从Hive读取的STRING类型时间戳数据排序后有序写入Kafka,需要结合批处理模式、时间类型转换、单分区写入和Kafka生产者配置。以下是完整解决方案:一、核心解决方案1.批处理模式+全局排序将作业设置为批处理模式,并对字符串时间戳进行类型转换后排序:--设置为批处理模式(关键!)SET'execution.runtime-mode'='batch';--从Hive
- flink-sql读写hive-1.13
第一片心意
flinkflinksqlhive
1.版本说明本文档内容基于flink-1.13.x,其他版本的整理,请查看本人博客的flink专栏其他文章。1.1.概述ApacheHive已经成为了数据仓库生态系统中的核心。它不仅仅是一个用于大数据分析和ETL场景的SQL引擎,同样也是一个数据管理平台,可用于发现,定义,和演化数据。Flink与Hive的集成包含两个层面。一是利用了Hive的MetaStore作为持久化的Catalog,用户可通
- flink sql如何对hive string类型的时间戳进行排序
在FlinkSQL中对Hive表的STRING类型时间戳进行排序,需要先将字符串转换为时间类型,再基于时间类型排序。以下是具体方法和示例:一、核心解决方案1.字符串转TIMESTAMP后排序若Hive中的时间戳格式为'yyyy-MM-ddHH:mm:ss'(如'2024-01-0112:00:00'),可直接转为TIMESTAMP排序:SELECT*FROMhive_tableORDERBYTO_
- Python 生物信息学秘籍第三版(四)
绝不原创的飞龙
默认分类默认分类
原文:annas-archive.org/md5/9694cf42f7d741c69225ff1cf52b0efe译者:飞龙协议:CCBY-NC-SA4.0第十一章:生物信息学中的机器学习机器学习在许多不同的领域中都有应用,计算生物学也不例外。机器学习在该领域有着无数的应用,最古老且最为人熟知的应用之一就是使用主成分分析(PCA)通过基因组学研究种群结构。随着该领域的蓬勃发展,还有许多其他潜在的应
- cdh6.3.2的hive使用apache paimon格式只能创建不能写报错的问题
明天,今天,此时
hivepaimon
前言 根据官网paimon安装教程,看上去简单,实则报错阻碍使用的信心。解决方法 原带的jars下的zstd开头的包旧了,重新下载zstd较新的包单独放到每个节点的hive/lib下; 然后将hdfsyarn用户下的mr-framework.tar.gz中的zstdjar包替换成新的版本。 重启就可以了总结 国外软件问题,尽量使用英文搜索,特别是google.。方法来源:http
- ROS1/Linux——linux虚拟机主ip地址:网络信息不可用
eagle_Annie
网络linuxtcp/ip
ROS1/Linux——linux虚拟机主ip地址:网络信息不可用文章目录ROS1/Linux——linux虚拟机主ip地址:网络信息不可用参考亿点链接问题描述最终解决方案参考亿点链接Unabletofetchsomearchives,mayberunapt-getupdateortrywith–fix-missinglinux虚拟机主ip地址:网络信息不可用(没IP)【问题解决】VMWare虚拟
- Hadoop与云原生集成:弹性扩缩容与OSS存储分离架构深度解析
Hadoop与云原生集成的必要性Hadoop在大数据领域的基石地位作为大数据处理领域的奠基性技术,Hadoop自2006年诞生以来已形成包含HDFS、YARN、MapReduce三大核心组件的完整生态体系。根据CSDN技术社区的分析报告,全球超过75%的《财富》500强企业仍在使用Hadoop处理EB级数据,其分布式文件系统HDFS通过数据分片(默认128MB块大小)和三副本存储机制,成功解决了P
- React-Python项目安装与使用指南
React-Python项目安装与使用指南一、项目目录结构及介绍通常情况下,在克隆了https://github.com/facebookarchive/react-python.git仓库之后,你会看到以下的目录结构:├──README.md#项目的说明文档├──src#源码目录│├──components#React组件存放位置│├──App.py#应用主入口文件│└──index.js#引入
- C++11中的std::function
文章转载自:http://www.jellythink.com/archives/771看看这段代码先来看看下面这两行代码:std::functiononKeyPressed;std::functiononKeyReleased;这两行代码是从Cocos2d-x中摘出来的,重点是这两行代码的定义啊。std::function这是什么东西?如果你对上述两行代码表示毫无压力,那就不妨再看看本文,就当温
- ETL可视化工具 DataX -- 简介( 一)
dazhong2012
软件工具数据仓库dataxETL
引言DataX系列文章:ETL可视化工具DataX–安装部署(二)ETL可视化工具DataX–DataX-Web安装(三)1.1DataX1.1.1DataX概览DataX是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX实现了包括MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、
- AWS 管理秘籍(一)
绝不原创的飞龙
默认分类默认分类
原文:annas-archive.org/md5/cf1c4e1db999839ba88fc56df4011156译者:飞龙协议:CCBY-NC-SA4.0序言AWS平台的增长速度非常快,正在被各行各业广泛采用。正如俗话所说,朋友不会让朋友建立数据中心。不管从哪个角度看,按需计算、网络和存储的模式将持续存在。尤其是当你看到AWS平台在功能和增强方面的更新速度时,很难再去反对站在巨人的肩膀上,尤其是
- AWS Terraform 架构指南(二)
绝不原创的飞龙
默认分类默认分类
原文:annas-archive.org/md5/8b2d222956a050c7632b9eee086dadcf译者:飞龙协议:CCBY-NC-SA4.0第七章:7在项目中实现Terraform您准备好开始使用Terraform开发您的AWS基础设施了吗?在本章中,您将学习Terraform的基础知识,并了解如何在AWS中部署您的第一个模板。我们将介绍选择合适的AWS提供商和选择满足您项目需求的
- 解线性方程组
qiuwanchi
package gaodai.matrix;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Test {
public static void main(String[] args) {
Scanner scanner = new Sc
- 在mysql内部存储代码
annan211
性能mysql存储过程触发器
在mysql内部存储代码
在mysql内部存储代码,既有优点也有缺点,而且有人倡导有人反对。
先看优点:
1 她在服务器内部执行,离数据最近,另外在服务器上执行还可以节省带宽和网络延迟。
2 这是一种代码重用。可以方便的统一业务规则,保证某些行为的一致性,所以也可以提供一定的安全性。
3 可以简化代码的维护和版本更新。
4 可以帮助提升安全,比如提供更细
- Android使用Asynchronous Http Client完成登录保存cookie的问题
hotsunshine
android
Asynchronous Http Client是android中非常好的异步请求工具
除了异步之外还有很多封装比如json的处理,cookie的处理
引用
Persistent Cookie Storage with PersistentCookieStore
This library also includes a PersistentCookieStore whi
- java面试题
Array_06
java面试
java面试题
第一,谈谈final, finally, finalize的区别。
final-修饰符(关键字)如果一个类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承。因此一个类不能既被声明为 abstract的,又被声明为final的。将变量或方法声明为final,可以保证它们在使用中不被改变。被声明为final的变量必须在声明时给定初值,而在以后的引用中只能
- 网站加速
oloz
网站加速
前序:本人菜鸟,此文研究总结来源于互联网上的资料,大牛请勿喷!本人虚心学习,多指教.
1、减小网页体积的大小,尽量采用div+css模式,尽量避免复杂的页面结构,能简约就简约。
2、采用Gzip对网页进行压缩;
GZIP最早由Jean-loup Gailly和Mark Adler创建,用于UNⅨ系统的文件压缩。我们在Linux中经常会用到后缀为.gz
- 正确书写单例模式
随意而生
java 设计模式 单例
单例模式算是设计模式中最容易理解,也是最容易手写代码的模式了吧。但是其中的坑却不少,所以也常作为面试题来考。本文主要对几种单例写法的整理,并分析其优缺点。很多都是一些老生常谈的问题,但如果你不知道如何创建一个线程安全的单例,不知道什么是双检锁,那这篇文章可能会帮助到你。
懒汉式,线程不安全
当被问到要实现一个单例模式时,很多人的第一反应是写出如下的代码,包括教科书上也是这样
- 单例模式
香水浓
java
懒汉 调用getInstance方法时实例化
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static synchronized Singleton getInstance() {
if(null == ins
- 安装Apache问题:系统找不到指定的文件 No installed service named "Apache2"
AdyZhang
apachehttp server
安装Apache问题:系统找不到指定的文件 No installed service named "Apache2"
每次到这一步都很小心防它的端口冲突问题,结果,特意留出来的80端口就是不能用,烦。
解决方法确保几处:
1、停止IIS启动
2、把端口80改成其它 (譬如90,800,,,什么数字都好)
3、防火墙(关掉试试)
在运行处输入 cmd 回车,转到apa
- 如何在android 文件选择器中选择多个图片或者视频?
aijuans
android
我的android app有这样的需求,在进行照片和视频上传的时候,需要一次性的从照片/视频库选择多条进行上传
但是android原生态的sdk中,只能一个一个的进行选择和上传。
我想知道是否有其他的android上传库可以解决这个问题,提供一个多选的功能,可以使checkbox之类的,一次选择多个 处理方法
官方的图片选择器(但是不支持所有版本的androi,只支持API Level
- mysql中查询生日提醒的日期相关的sql
baalwolf
mysql
SELECT sysid,user_name,birthday,listid,userhead_50,CONCAT(YEAR(CURDATE()),DATE_FORMAT(birthday,'-%m-%d')),CURDATE(), dayofyear( CONCAT(YEAR(CURDATE()),DATE_FORMAT(birthday,'-%m-%d')))-dayofyear(
- MongoDB索引文件破坏后导致查询错误的问题
BigBird2012
mongodb
问题描述:
MongoDB在非正常情况下关闭时,可能会导致索引文件破坏,造成数据在更新时没有反映到索引上。
解决方案:
使用脚本,重建MongoDB所有表的索引。
var names = db.getCollectionNames();
for( var i in names ){
var name = names[i];
print(name);
- Javascript Promise
bijian1013
JavaScriptPromise
Parse JavaScript SDK现在提供了支持大多数异步方法的兼容jquery的Promises模式,那么这意味着什么呢,读完下文你就了解了。
一.认识Promises
“Promises”代表着在javascript程序里下一个伟大的范式,但是理解他们为什么如此伟大不是件简
- [Zookeeper学习笔记九]Zookeeper源代码分析之Zookeeper构造过程
bit1129
zookeeper
Zookeeper重载了几个构造函数,其中构造者可以提供参数最多,可定制性最多的构造函数是
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, long sessionId, byte[] sessionPasswd, boolea
- 【Java命令三】jstack
bit1129
jstack
jstack是用于获得当前运行的Java程序所有的线程的运行情况(thread dump),不同于jmap用于获得memory dump
[hadoop@hadoop sbin]$ jstack
Usage:
jstack [-l] <pid>
(to connect to running process)
jstack -F
- jboss 5.1启停脚本 动静分离部署
ronin47
以前启动jboss,往各种xml配置文件,现只要运行一句脚本即可。start nohup sh /**/run.sh -c servicename -b ip -g clustername -u broatcast jboss.messaging.ServerPeerID=int -Djboss.service.binding.set=p
- UI之如何打磨设计能力?
brotherlamp
UIui教程ui自学ui资料ui视频
在越来越拥挤的初创企业世界里,视觉设计的重要性往往可以与杀手级用户体验比肩。在许多情况下,尤其对于 Web 初创企业而言,这两者都是不可或缺的。前不久我们在《右脑革命:别学编程了,学艺术吧》中也曾发出过重视设计的呼吁。如何才能提高初创企业的设计能力呢?以下是 9 位创始人的体会。
1.找到自己的方式
如果你是设计师,要想提高技能可以去设计博客和展示好设计的网站如D-lists或
- 三色旗算法
bylijinnan
java算法
import java.util.Arrays;
/**
问题:
假设有一条绳子,上面有红、白、蓝三种颜色的旗子,起初绳子上的旗子颜色并没有顺序,
您希望将之分类,并排列为蓝、白、红的顺序,要如何移动次数才会最少,注意您只能在绳
子上进行这个动作,而且一次只能调换两个旗子。
网上的解法大多类似:
在一条绳子上移动,在程式中也就意味只能使用一个阵列,而不使用其它的阵列来
- 警告:No configuration found for the specified action: \'s
chiangfai
configuration
1.index.jsp页面form标签未指定namespace属性。
<!--index.jsp代码-->
<%@taglib prefix="s" uri="/struts-tags"%>
...
<s:form action="submit" method="post"&g
- redis -- hash_max_zipmap_entries设置过大有问题
chenchao051
redishash
使用redis时为了使用hash追求更高的内存使用率,我们一般都用hash结构,并且有时候会把hash_max_zipmap_entries这个值设置的很大,很多资料也推荐设置到1000,默认设置为了512,但是这里有个坑
#define ZIPMAP_BIGLEN 254
#define ZIPMAP_END 255
/* Return th
- select into outfile access deny问题
daizj
mysqltxt导出数据到文件
本文转自:http://hatemysql.com/2010/06/29/select-into-outfile-access-deny%E9%97%AE%E9%A2%98/
为应用建立了rnd的帐号,专门为他们查询线上数据库用的,当然,只有他们上了生产网络以后才能连上数据库,安全方面我们还是很注意的,呵呵。
授权的语句如下:
grant select on armory.* to rn
- phpexcel导出excel表简单入门示例
dcj3sjt126com
PHPExcelphpexcel
<?php
error_reporting(E_ALL);
ini_set('display_errors', TRUE);
ini_set('display_startup_errors', TRUE);
if (PHP_SAPI == 'cli')
die('This example should only be run from a Web Brows
- 美国电影超短200句
dcj3sjt126com
电影
1. I see. 我明白了。2. I quit! 我不干了!3. Let go! 放手!4. Me too. 我也是。5. My god! 天哪!6. No way! 不行!7. Come on. 来吧(赶快)8. Hold on. 等一等。9. I agree。 我同意。10. Not bad. 还不错。11. Not yet. 还没。12. See you. 再见。13. Shut up!
- Java访问远程服务
dyy_gusi
httpclientwebservicegetpost
随着webService的崛起,我们开始中会越来越多的使用到访问远程webService服务。当然对于不同的webService框架一般都有自己的client包供使用,但是如果使用webService框架自己的client包,那么必然需要在自己的代码中引入它的包,如果同时调运了多个不同框架的webService,那么就需要同时引入多个不同的clien
- Maven的settings.xml配置
geeksun
settings.xml
settings.xml是Maven的配置文件,下面解释一下其中的配置含义:
settings.xml存在于两个地方:
1.安装的地方:$M2_HOME/conf/settings.xml
2.用户的目录:${user.home}/.m2/settings.xml
前者又被叫做全局配置,后者被称为用户配置。如果两者都存在,它们的内容将被合并,并且用户范围的settings.xml优先。
- ubuntu的init与系统服务设置
hongtoushizi
ubuntu
转载自:
http://iysm.net/?p=178 init
Init是位于/sbin/init的一个程序,它是在linux下,在系统启动过程中,初始化所有的设备驱动程序和数据结构等之后,由内核启动的一个用户级程序,并由此init程序进而完成系统的启动过程。
ubuntu与传统的linux略有不同,使用upstart完成系统的启动,但表面上仍维持init程序的形式。
运行
- 跟我学Nginx+Lua开发目录贴
jinnianshilongnian
nginxlua
使用Nginx+Lua开发近一年的时间,学习和实践了一些Nginx+Lua开发的架构,为了让更多人使用Nginx+Lua架构开发,利用春节期间总结了一份基本的学习教程,希望对大家有用。也欢迎谈探讨学习一些经验。
目录
第一章 安装Nginx+Lua开发环境
第二章 Nginx+Lua开发入门
第三章 Redis/SSDB+Twemproxy安装与使用
第四章 L
- php位运算符注意事项
home198979
位运算PHP&
$a = $b = $c = 0;
$a & $b = 1;
$b | $c = 1
问a,b,c最终为多少?
当看到这题时,我犯了一个低级错误,误 以为位运算符会改变变量的值。所以得出结果是1 1 0
但是位运算符是不会改变变量的值的,例如:
$a=1;$b=2;
$a&$b;
这样a,b的值不会有任何改变
- Linux shell数组建立和使用技巧
pda158
linux
1.数组定义 [chengmo@centos5 ~]$ a=(1 2 3 4 5) [chengmo@centos5 ~]$ echo $a 1 一对括号表示是数组,数组元素用“空格”符号分割开。
2.数组读取与赋值 得到长度: [chengmo@centos5 ~]$ echo ${#a[@]} 5 用${#数组名[@或
- hotspot源码(JDK7)
ol_beta
javaHotSpotjvm
源码结构图,方便理解:
├─agent Serviceab
- Oracle基本事务和ForAll执行批量DML练习
vipbooks
oraclesql
基本事务的使用:
从账户一的余额中转100到账户二的余额中去,如果账户二不存在或账户一中的余额不足100则整笔交易回滚
select * from account;
-- 创建一张账户表
create table account(
-- 账户ID
id number(3) not null,
-- 账户名称
nam