使用pytorch DataParallel进行多GPU训练
使用pytorch DataParallel进行分布式训练
-
- 一、nn.DataParallel大致流程
- 二、nn.DataParallel参数解读
- 三、代码讲解
-
- 1.使用DataParallell的细节
- 2.全部代码
- 四、总结
深度学习中经常要使用大量数据进行训练,但单个GPU训练往往速度过慢,因此多GPU训练就变得十分重要。pytorch使用两种方式进行多GPU训练,他们分别是 DataParallel与 parallel.DistributedDataParallel前者便是本文所讲解的训练方式。
nn.DataParallel只能用于单机多卡训练,但 nn.parallel.DistributedDataParallel既能用于单机多卡又能用于多机多卡训练。具体方法参考pytorch官方教程:
- https://pytorch.org/tutorials/beginner/dist_overview.html
- https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
一、nn.DataParallel大致流程
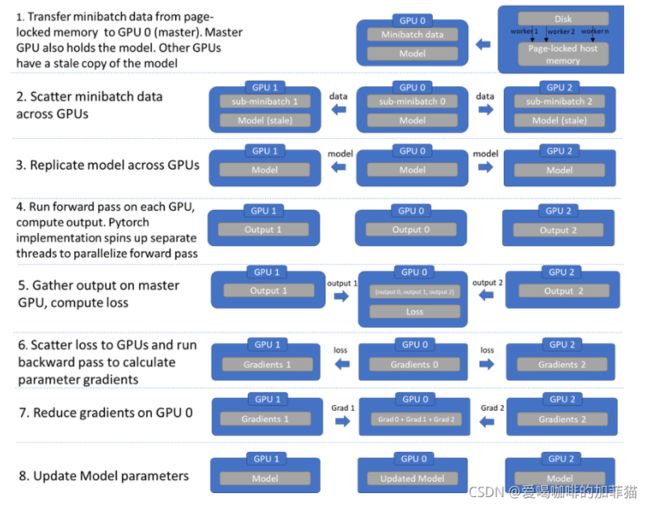
- 将模型与minibatch从磁盘加载进GPU0
- 根据GPU数量将数据均分成若干份sub-minibatch,并发送至各个GPU
- 模型从GPU0被复制到其他GPU
- minibatch进行正向传播得到输出output
- 将各个gpu上的output汇总到GPU0,求取各个output的loss
- 将各个loss分发到各个GPU,进行反向传播求取梯度
- 将各个GPU上的梯度聚集到GPU0,求取平均梯度
- 用平均梯度在GPU上更新模型参数,接着把更新后的模型参数复制到其他GPU
二、nn.DataParallel参数解读
class DataParallel(Module):
"""
Args:
module (Module): module to be parallelized
device_ids (list of int or torch.device): CUDA devices (default: all devices)
output_device (int or torch.device): device location of output (default: device_ids[0])
Attributes:
module (Module): the module to be parallelized
Example::
>>> net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
>>> output = net(input_var) # input_var can be on any device, including CPU
"""
def __init__(self, module, device_ids=None, output_device=None, dim=0):
super(DataParallel, self).__init__()
torch._C._log_api_usage_once("torch.nn.parallel.DataParallel")
device_type = _get_available_device_type()
if device_type is None:
self.module = module
self.device_ids = []
return
以上是从 DataParallell类定义的代码中截取的部分:
-
device_ids代表并行的GPU的编号
-
output_device代表进行loss求取与梯度聚合的GPU编号(默认是GPU0,即device_ids[0],与上图一致)
-
module不用多讲,便是需要数据并行的模型
三、代码讲解
1.使用DataParallell的细节
1).在文件导入模块部分进行以下设置
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0,3"
代码设置了训练使用哪几个GPU,上面的代码就是说使用GPU0与GPU3,它们对应device_id便是0,1这对下面非常有用。
2).接下来将定义好的模型放入DataParallell中:
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = nn.DataParallel(model,device_ids = [0,1])
#model.to(device)的目的是将模型放入device_id对应为的GPU
model.to(device)
3)将数据放入device0中即(device_id为1的GPU)
for X, y in dataloader:
X, y = X.to(device), y.to(device)
2.全部代码
本次搭建了一个简单的全连接网络来实现分类任务,数据集为FashionMNIST,损失函数使用交叉损失熵,使用SGD优化器,以下是全部代码,如果要复现代码,尽量将数据集下载到本地。
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda, Compose
import os
import matplotlib.pyplot as plt
import time
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0,3"
# Download training data from open datasets.
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
path = '/home/ymx/PycharmProjects/pytorch_reinforce_example/fashion-mnist-master/data/fashion'
training_data = datasets.FashionMNIST(
root='data',
train=True,
download=True,
transform=ToTensor(),
)
test_data = datasets.FashionMNIST(
root='data',
train=False,
download=True,
transform=ToTensor(),
)
batch_size = 1024
# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
model = NeuralNetwork()
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model,device_ids = [0,1])
#model = nn.DataParallel(model,device_ids = [0,1])
model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=2e-3)
epochs = 5
T1 = time.time()
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
T2 = time.time()
print('time is %s ms' % ((T2 - T1) * 1000))
print("Done!")
四、总结
- 使用DataParallel进行单机多卡训练网络时能加快训练速度,并且代码十分简洁,但要注意当数据量比较小的时候,使用数据并行并不会加快训练速度,因为此时通信耗时特别显著,反而会拖慢训练速度,效果还不如单卡训练。
- 如果有多机多卡时,十分建议使用parallel.DistributedDataParallel进行分布式训练,这种训练方式带来的速度提升会远大于数据并行。