REALM: Retrieval-Augmented Language Model Pre-Training(2020-2-10)
模型介绍
预训练语言模型能够捕捉非常多的知识,对于NLP任务特别是QA任务来说非常重要。然而,知识被隐式的存储在神经网络的参数中,需要更大的网络来覆盖更多的因素。为了以一个模块化或者可翻译的方式来捕捉知识,使用了一个延迟知识检索的预训练增强语言模型在预训练、微调以及推断期间允许模型在大的语料库中(比如Wikipedia)检索文档。
首先,先展示如何以无监督方式训练一个知识检索器,使用掩码语言模型(MLM)来作为学习信号,然后通过有几百万文档的训练步骤进行后向传播。证明了检索增强的预训练语言模型(Retrieval-Augmented Language Model pre-training, REALM)在具有挑战性的任务开放领域问答 (Open-domain Question Answering, Open-QA)上的有效性。然后在三个比较受欢迎的Open-QA基准上以显式和隐式的知识存储方式比较了许多SoTA模型,比之前的许多方法提升了 4-16% 的准确率,同时也提供了很多的好处,比如可解释性和模块化。
预训练语言模型能够从无监督文本语料中学习到很多公共知识。然而,这些知识存储在参数中,有以下两个缺点:
- 这些知识是隐式的,使用时难以解释模型储存、使用的知识;
- 模型学习到的知识的量级和模型大小(参数量)相关,因此为了学习到更多的知识,需要扩充模型大小。
REALM,引入了一个检索模块,如下图所示:
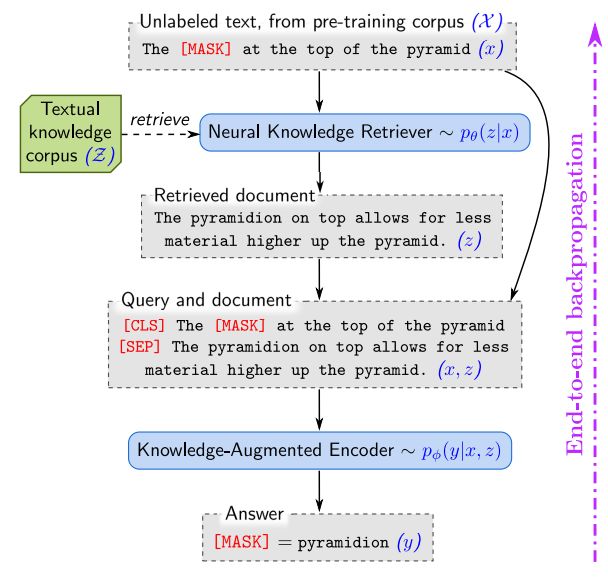
使用检索器的 REALM 增强语言预训练模型从一个文本化的知识语料库 Z \Zeta Z(比如Wikipedia等)检索知识,以及来自语言模型的信号反向传播通过所有的检索器。
模型结构
对于预训练(pre-training)和微调(fine-tuning)阶段,模型接受输入 x x x,学习一个概率分布 p ( y ∣ x ) p(y|x) p(y∣x)并输出 y y y。对于预训练,任务是掩码语言模型, x x x 是来自预训练语料 χ \chi χ 部分token被遮住的句子,模型必须预测这些被遮掩的token,也就是 y y y;在微调阶段,任务是Open-QA, x x x 为问题, y y y 为答案。
REALM分解 p ( y ∣ x ) p(y|x) p(y∣x) 为两个阶段:检索和预测。给定一个输入 x x x,首先从知识语料库 Z \Zeta Z 中检索出最有帮助的文档 z z z,这样得到一个采样分布 p ( z ∣ x ) p(z|x) p(z∣x);然后在检索的文档 z z z 和输入 x x x 的条件下生成输出 y y y,这样模型可以表示为 p ( y ∣ z , x ) p(y|z,x) p(y∣z,x)。为了获取 y y y 的完全(相对于 x x x)概率, 将 z z z视为一个隐变量,建模 z z z 为对于所有潜在文档的边缘概率:
p ( y ∣ x ) = ∑ z ∈ Z p ( y ∣ z , x ) p ( z ∣ x ) p(y|x) = \displaystyle \sum_{z \in \Zeta} p(y|z,x)p(z|x) p(y∣x)=z∈Z∑p(y∣z,x)p(z∣x)
下图为REALM的整个框架。左边的图描述了在无监督预训练阶段,知识检索器和知识增强编码器在无监督语言掩码模型上共同训练。右边的图描述了在有监督微调阶段,在检索器( θ \theta θ)和编码器( ϕ \phi ϕ)的参数经过预训练之后,然后使用有监督的例子微调到主要感兴趣的任务上。

Knowledge Retriever
检索器使用了密集内积模型,用公式可以表示为:
p ( z ∣ x ) = exp f ( x , z ) ∑ z ′ exp f ( x , z ′ ) p(z|x) = \displaystyle \frac {\exp f(x,z)} {\sum_{z'} \exp f(x,z')} p(z∣x)=∑z′expf(x,z′)expf(x,z)
f ( x , z ) = Embed i n p u t ( x ) T Embed d o c ( z ) f(x,z)=\operatorname {Embed}_{input}(x)^T\operatorname{Embed}_{doc}(z) f(x,z)=Embedinput(x)TEmbeddoc(z)
其中, Embed i n p u t \operatorname {Embed}_{input} Embedinput 和 Embed d o c \operatorname{Embed}_{doc} Embeddoc 为嵌入函数,分别将 x x x 和 z z z 映射到 d 维的向量。 x x x 和 z z z 的相关性得分函数 f ( x , z ) f(x,z) f(x,z) 为向量的内积。检索器的概率分布函数 p ( z ∣ x ) p(z|x) p(z∣x) 就是对相关性得分进行 softmax 操作。
通过使用BERT式的Transformer来实现嵌入函数 Embed i n p u t \operatorname {Embed}_{input} Embedinput 和 Embed d o c \operatorname{Embed}_{doc} Embeddoc。和标准的做法一样,使用WordPiece分词器这些token组合在一起,使用 [CLS]、[SEP] 来标记句子或句子对。
join BERT ( x ) = [ CLS ] x [ SEP ] \operatorname{join}_{\operatorname{BERT}}(x)=[\operatorname{CLS}] x[\operatorname{SEP}] joinBERT(x)=[CLS]x[SEP]
join BERT ( x 1 , x 2 ) = [ CLS ] x 1 [ SEP ] x 2 [ SEP ] \operatorname{join}_{\operatorname{BERT}}(x_1,x_2)=[\operatorname{CLS}] x_1[\operatorname{SEP}]x_2[\operatorname{SEP}] joinBERT(x1,x2)=[CLS]x1[SEP]x2[SEP]
然后为每个token生成一个向量,包括标记 [CLS] 对应的向量,用于表示池化的序列( BERT CLS \operatorname{BERT}_{\operatorname{CLS}} BERTCLS)。最后,通过一个线性映射来降低向量的维度,线性矩阵表示为 W W W:
Embed input ( x ) = W input BERT CLS ( join BERT ( x ) ) \operatorname{Embed}_{\operatorname{input}}(x)=W_{\operatorname{input}}\operatorname{BERT}_{\operatorname{CLS}}(\operatorname{join}_{\operatorname{BERT}}(x)) Embedinput(x)=WinputBERTCLS(joinBERT(x))
Embed doc ( z ) = W doc BERT CLS ( join BERT ( z t i t l e , z b o d y ) ) \operatorname{Embed}_{\operatorname{doc}}(z)=W_{\operatorname{doc}}\operatorname{BERT}_{\operatorname{CLS}}(\operatorname{join}_{\operatorname{BERT}}(z_{title},z_{body})) Embeddoc(z)=WdocBERTCLS(joinBERT(ztitle,zbody))
其中, z t i t l e z_{title} ztitle 为文档的标题, z b o d y z_{body} zbody 为文档的内容,用 θ \theta θ 表示为与检索器有关联的Transformer和映射矩阵 W W W 的所有参数。
Knowledge-Augmented Encoder
给定检索到的文档 z z z 和输入样本 x x x,知识增强编码器可以定义为 p ( y ∣ z , x ) p(y|z,x) p(y∣z,x)。将 x x x 和 z z z 连接成一个句子并送入 Transformer 模型中,这可以在预测 y y y 之前在 x x x 和 y y y 之间执行大量的交叉注意力计算。
在这个阶段,编码器的结构在预训练和微调时略有不同。对于使用掩码语言模型的预训练任务,必须预测 x x x 的每个[mask] token原来的值,所以使用了相同的掩码语言模型损失函数:
p ( y ∣ z , x ) = ∏ j = 1 J x p ( y j ∣ z , x ) p(y|z,x)=\displaystyle \prod^{J_x}_{j=1}p(y_j|z,x) p(y∣z,x)=j=1∏Jxp(yj∣z,x)
p ( y j ∣ z , x ) ∝ exp ( w j T BERT MASK ( j ) ( join BERT ( x , z body ) ) ) p(y_j|z,x) \varpropto \exp(w_j^T\operatorname{BERT}_{\operatorname{MASK}(j)}(\operatorname{join}_{\operatorname{BERT}}(x,z_{\operatorname{body}}))) p(yj∣z,x)∝exp(wjTBERTMASK(j)(joinBERT(x,zbody)))
其中, BERT MASK ( j ) \operatorname{BERT}_{\operatorname{MASK}(j)} BERTMASK(j)表示与第j个掩码标记相对应的Transformer输出向量, J x J_x Jx 为 x x x 中 [MASK] token的总数, w j w_j wj 是token y j y_j yj的可学习嵌入函数。
在Open-QA 微调期间,希望产生一个答案字符串 y y y。和之前的阅读理解任务一样,假定答案 y y y 为一系列连续的token,且可以从文档 z z z 中找出。令 S ( z , y ) S(z,y) S(z,y) 为文档 z z z 中匹配答案 y y y 的span集合,则可以定义 p ( y ∣ z , x ) p(y|z,x) p(y∣z,x) 为:
p ( y ∣ z , x ) ∝ ∑ s ∈ S ( z , y ) exp ( MLP ( [ h START(s) ; h END(s) ] ) ) p(y|z,x) \varpropto \displaystyle \sum_{s \in S(z,y)} \exp(\operatorname{MLP}([h_{\operatorname{START(s)}};h_{\operatorname{END(s)}}])) p(y∣z,x)∝s∈S(z,y)∑exp(MLP([hSTART(s);hEND(s)]))
h START(s) = BERT START(s) ( join BERT ( x , z body ) ) h_{\operatorname{START(s)}}=\operatorname{BERT}_{\operatorname{START(s)}}(\operatorname{join}_{\operatorname{BERT}}(x,z_{\operatorname{body}})) hSTART(s)=BERTSTART(s)(joinBERT(x,zbody))
h END(s) = BERT END(s) ( join BERT ( x , z body ) ) h_{\operatorname{END(s)}}=\operatorname{BERT}_{\operatorname{END(s)}}(\operatorname{join}_{\operatorname{BERT}}(x,z_{\operatorname{body}})) hEND(s)=BERTEND(s)(joinBERT(x,zbody))
其中, BERT START(s) \operatorname{BERT}_{\operatorname{START(s)}} BERTSTART(s) 和 BERT END(s) \operatorname{BERT}_{\operatorname{END(s)}} BERTEND(s) 分别表示 Transformer 范围 s s s 中对应开始和结尾位置 token的输出向量, MLP \operatorname{MLP} MLP 表示前馈神经网络, ϕ \phi ϕ 表示和知识增强编码器相关联的参数。
模型改进
预训练和fine-tune阶段的训练目标都是最大化对数似然 p ( y ∣ x ) p(y|x) p(y∣x)。其中retrever和encoder都是可导的神经网络,因此梯度是可以反传的。然而一个关键的问题在于文档 z z z 的数目非常巨大,计算 p ( y ∣ x ) = ∑ z ∈ Z p ( y ∣ z , x ) p ( z ∣ x ) p(y|x) = \displaystyle \sum_{z \in \Zeta} p(y|z,x)p(z|x) p(y∣x)=z∈Z∑p(y∣z,x)p(z∣x) 将非常耗时。解决方法是只考虑top-k个最相关的文档。作者认为这种近似是合理的,因为外部文档库中的绝大多数文档与输入 x x x 都是不相关的,其概率 p ( z ∣ x ) p(z|x) p(z∣x) 几乎为0。
即使这样近似,从文档库中找到top-k个最相关的文档仍然计算量巨大。通过使用Maximum Inner Product Search(最大内积搜索,MIPS)的算法来找到top-k个最相关文档。
为了使用MIPS,需要预先对所有文档 z z z 计算其embedding,然后建立索引,但由于检索器的参数是不断更新变化的,导致MIPS索引也应该不断地进行刷新,这样又非常耗时,因为每次更新一个step都需要重新计算文档库的embedding,然后更新MIPS索引。解决方法是:每隔若干step才刷新一次MIPS索引(该索引仅用来选择top-k个文档,而在每一步训练梯度反传的时候,仍然使用的是最新的retreiver的参数),如下图所示:

上面所述的MIPS索引刷新仅用于预训练阶段。在fine-tune阶段,MIPS索引仅在一开始建立一次(使用预训练的retriever参数),之后便不再更新。这么做是方便起见,因为在预训练阶段检索器就已经学习到了足够好的文档相关性表征,但如果同样在fine-tune阶段迭代更新MIPS索引的话,效果可能会更好。
另外,还有提高模型性能的一些实现trick,包括:
- Salient span masking(SSM):即在MLM预训练阶段,遮盖关键的实体/数字,而不是随机token;
- null document:部分MLM样本不需要外部文档支持;
- 避免信息泄漏:当MLM的训练语料和检索语料有重叠时,避免直接搜索到样本 x x x 的原文;
- 检索器的初始化、冷启动问题:如果一开始随机初始化检索器,那么文档将会大概率是完全无关的,模型得不到有效的梯度;为了避免这个问题,使用Inverse Cloze Test任务来初始化训练检索器。
模型参考
论文地址:https://arxiv.org/abs/2002.08909
代码地址:https://github.com/google-research/language/tree/master/language/realm