Sklearn官方文档中文整理9——特征选择和半监督学习篇
Sklearn官方文档中文整理9——特征选择和半监督学习篇
- 1. 监督学习
-
- 1.13. 特征选择
-
- 1.13.1. 移除低方差特征【feature_selection.VarianceThreshold】
- 1.13.2. 单变量特征选择【feature_selection.SelectKBest,feature_selection.SelectPercentile,feature_selection.SelectFpr,feature_selection.SelectFdr,feature_selection.SelectFwe,feature_selection.GenericUnivariateSelect】
- 1.13.3. 递归式特征消除【feature_selection.RFE,feature_selection.RFECV】
- 1.13.4. 使用 SelectFromModel 选取特征【feature_selection.SelectFromModel】
-
- 1.13.4.1. 基于 L1 的特征选取
- 1.13.4.2. 基于 Tree(树)的特征选取
- 1.13.5. 特征选取作为 pipeline(管道)的一部分
- 1.14. 半监督学习
-
- 1.14.1. 标签传播
1. 监督学习
1.13. 特征选择
在 sklearn.feature_selection 模块中的类可以用来对样本集进行 feature selection(特征选择)和 dimensionality reduction(降维),这将会提高估计器的准确度或者增强它们在高维数据集上的性能。
1.13.1. 移除低方差特征【feature_selection.VarianceThreshold】
VarianceThreshold 是特征选择的一个简单基本方法,它会移除所有那些方差不满足一些阈值的特征。默认情况下,它将会移除所有的零方差特征,即那些在所有的样本上的取值均不变的特征。
例如,假设我们有一个特征是布尔值的数据集,我们想要移除那些在整个数据集中特征值为0或者为1的比例超过80%的特征。布尔特征是伯努利( Bernoulli )随机变量,变量的方差为
V a r [ X ] = p ( 1 − p ) \mathrm{Var}[X] = p(1 - p) Var[X]=p(1−p)
因此,我们可以使用阈值.8 * (1 - .8)进行选择:
>>> from sklearn.feature_selection import VarianceThreshold
>>> X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]]
>>> sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
>>> sel.fit_transform(X)
array([[0, 1],
[1, 0],
[0, 0],
[1, 1],
[1, 0],
[1, 1]])
正如预期一样, VarianceThreshold 移除了第一列,它的值为 0 的概率为 p = 5/6 > .8 。
sklearn.feature_selection.VarianceThreshold
| 参数 | 解释 |
|---|---|
| threshold:float, default=0 | 训练集方差低于此阈值的特征将被删除。默认情况下,保留方差不为零的所有特征,即删除所有样本中具有相同值的特征。 |
| 属性 | 解释 |
|---|---|
| variances_:array, shape (n_features,) | 个别特征的方差。 |
| 方法 | 解释 |
|---|---|
| fit(X[, y]) | 从X学习经验方差。 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| set_params(**params) | 设置此估计器的参数。 |
| get_support([indices]) | 获取所选特征的掩码或整数索引 |
| inverse_transform(X) | 反转转换操作 |
| transform(X) | 将X减少到选定的特征。 |
例:
>>> from sklearn.feature_selection import VarianceThreshold
>>> X = [[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]]
>>> selector = VarianceThreshold()
>>> selector.fit_transform(X)
array([[2, 0],
[1, 4],
[1, 1]])
1.13.2. 单变量特征选择【feature_selection.SelectKBest,feature_selection.SelectPercentile,feature_selection.SelectFpr,feature_selection.SelectFdr,feature_selection.SelectFwe,feature_selection.GenericUnivariateSelect】
单变量的特征选择是通过基于单变量的统计测试来选择最好的特征。它可以当做是评估器的预处理步骤。Scikit-learn 将特征选择的内容作为实现了 transform 方法的对象:
SelectKBest移除那些除了评分最高的 K 个特征之外的所有特征SelectPercentile移除除了用户指定的最高得分百分比之外的所有特征- 对每个特征应用常见的单变量统计测试: 假阳性率(false positive rate)
SelectFpr, 伪发现率(false discovery rate)SelectFdr, 或者族系误差(family wise error)SelectFwe。 GenericUnivariateSelect允许使用可配置方法来进行单变量特征选择。它允许超参数搜索评估器来选择最好的单变量特征。
例如下面的实例,我们可以使用 χ 2 \chi^2 χ2 检验样本集来选择最好的两个特征:
>>> from sklearn.datasets import load_iris
>>> from sklearn.feature_selection import SelectKBest
>>> from sklearn.feature_selection import chi2
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> X.shape
(150, 4)
>>> X_new = SelectKBest(chi2, k=2).fit_transform(X, y)
>>> X_new.shape
(150, 2)
这些对象将得分函数作为输入,返回单变量的得分和 p 值 (或者仅仅是 SelectKBest 和 SelectPercentile 的分数):
- 对于回归:
f_regression,mutual_info_regression - 对于分类:
chi2,f_classif,mutual_info_classif
这些基于 F-test 的方法计算两个随机变量之间的线性相关程度。另一方面,mutual information methods(互信息)能够计算任何种类的统计相关性,但是作为非参数的方法,互信息需要更多的样本来进行准确的估计。
稀疏数据的特征选择
如果你使用的是稀疏的数据 (例如数据可以由稀疏矩阵来表示),chi2 , mutual_info_regression , mutual_info_classif可以处理数据并保持它的稀疏性。
警告
不要使用一个回归评分函数来处理分类问题,你会得到无用的结果。
sklearn.feature_selection.SelectKBest
| 参数 | 解释 |
|---|---|
| score_func:callable, default=f_classif | 函数获取两个数组X和y,并返回一对数组(scores,pvalues)或一个带有scores的数组。默认值为f_classif。默认函数仅适用于分类任务。 |
| k:int or “all”, default=10 | 要选择的顶级功能数。“all”选项绕过选择,用于参数搜索。 |
| 属性 | 解释 |
|---|---|
| scores_:array-like of shape (n_features,) | 特征的分数 |
| pvalues_:array-like of shape (n_features,) | 特征得分的p值 |
| 方法 | 解释 |
|---|---|
| fit(X[, y]) | 在(X,y)上运行score函数并获得适当的特性。 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| set_params(**params) | 设置此估计器的参数。 |
| get_support([indices]) | 获取所选特征的掩码或整数索引 |
| inverse_transform(X) | 反转转换操作 |
| transform(X) | 将X减少到选定的特征。 |
例:
>>> from sklearn.datasets import load_digits
>>> from sklearn.feature_selection import SelectKBest, chi2
>>> X, y = load_digits(return_X_y=True)
>>> X.shape
(1797, 64)
>>> X_new = SelectKBest(chi2, k=20).fit_transform(X, y)
>>> X_new.shape
(1797, 20)
sklearn.feature_selection.SelectPercentile
| 参数 | 解释 |
|---|---|
| score_func:callable, default=f_classif | 函数获取两个数组X和y,并返回一对数组(scores,pvalues)或一个带有scores的数组。默认值为f_classif。默认函数仅适用于分类任务。 |
| percentile:int, default=10 | 要保留的特征的百分比。 |
| 属性 | 解释 |
|---|---|
| scores_:array-like of shape (n_features,) | 特征的分数 |
| pvalues_:array-like of shape (n_features,) | 特征得分的p值 |
| 方法 | 解释 |
|---|---|
| fit(X[, y]) | 在(X,y)上运行score函数并获得适当的特性。 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| set_params(**params) | 设置此估计器的参数。 |
| get_support([indices]) | 获取所选特征的掩码或整数索引 |
| inverse_transform(X) | 反转转换操作 |
| transform(X) | 将X减少到选定的特征。 |
例:
>>> from sklearn.datasets import load_digits
>>> from sklearn.feature_selection import SelectPercentile, chi2
>>> X, y = load_digits(return_X_y=True)
>>> X.shape
(1797, 64)
>>> X_new = SelectPercentile(chi2, percentile=10).fit_transform(X, y)
>>> X_new.shape
(1797, 7)
sklearn.feature_selection.SelectFpr
| 参数 | 解释 |
|---|---|
| score_func:callable, default=f_classif | 函数获取两个数组X和y,并返回一对数组(scores,pvalues)或一个带有scores的数组。默认值为f_classif。默认函数仅适用于分类任务。 |
| alpha:float, default=5e-2 | 要保留的特征的最高p值。 |
| 属性 | 解释 |
|---|---|
| scores_:array-like of shape (n_features,) | 特征的分数 |
| pvalues_:array-like of shape (n_features,) | 特征得分的p值 |
| 方法 | 解释 |
|---|---|
| fit(X[, y]) | 在(X,y)上运行score函数并获得适当的特性。 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| set_params(**params) | 设置此估计器的参数。 |
| get_support([indices]) | 获取所选特征的掩码或整数索引 |
| inverse_transform(X) | 反转转换操作 |
| transform(X) | 将X减少到选定的特征。 |
例:
>>> from sklearn.datasets import load_breast_cancer
>>> from sklearn.feature_selection import SelectFpr, chi2
>>> X, y = load_breast_cancer(return_X_y=True)
>>> X.shape
(569, 30)
>>> X_new = SelectFpr(chi2, alpha=0.01).fit_transform(X, y)
>>> X_new.shape
(569, 16)
sklearn.feature_selection.SelectFdr
| 参数 | 解释 |
|---|---|
| score_func:callable, default=f_classif | 函数获取两个数组X和y,并返回一对数组(scores,pvalues)或一个带有scores的数组。默认值为f_classif。默认函数仅适用于分类任务。 |
| alpha:float, default=5e-2 | 要保留的特征的最高p值。 |
| 属性 | 解释 |
|---|---|
| scores_:array-like of shape (n_features,) | 特征的分数 |
| pvalues_:array-like of shape (n_features,) | 特征得分的p值 |
| 方法 | 解释 |
|---|---|
| fit(X[, y]) | 在(X,y)上运行score函数并获得适当的特性。 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| set_params(**params) | 设置此估计器的参数。 |
| get_support([indices]) | 获取所选特征的掩码或整数索引 |
| inverse_transform(X) | 反转转换操作 |
| transform(X) | 将X减少到选定的特征。 |
例:
>>> from sklearn.datasets import load_breast_cancer
>>> from sklearn.feature_selection import SelectFdr, chi2
>>> X, y = load_breast_cancer(return_X_y=True)
>>> X.shape
(569, 30)
>>> X_new = SelectFdr(chi2, alpha=0.01).fit_transform(X, y)
>>> X_new.shape
(569, 16)
sklearn.feature_selection.SelectFwe
| 参数 | 解释 |
|---|---|
| score_func:callable, default=f_classif | 函数获取两个数组X和y,并返回一对数组(scores,pvalues)或一个带有scores的数组。默认值为f_classif。默认函数仅适用于分类任务。 |
| alpha:float, default=5e-2 | 要保留的特征的最高p值。 |
| 属性 | 解释 |
|---|---|
| scores_:array-like of shape (n_features,) | 特征的分数 |
| pvalues_:array-like of shape (n_features,) | 特征得分的p值 |
| 方法 | 解释 |
|---|---|
| fit(X[, y]) | 在(X,y)上运行score函数并获得适当的特性。 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| set_params(**params) | 设置此估计器的参数。 |
| get_support([indices]) | 获取所选特征的掩码或整数索引 |
| inverse_transform(X) | 反转转换操作 |
| transform(X) | 将X减少到选定的特征。 |
例:
>>> from sklearn.datasets import load_breast_cancer
>>> from sklearn.feature_selection import SelectFwe, chi2
>>> X, y = load_breast_cancer(return_X_y=True)
>>> X.shape
(569, 30)
>>> X_new = SelectFwe(chi2, alpha=0.01).fit_transform(X, y)
>>> X_new.shape
(569, 15)
sklearn.feature_selection.GenericUnivariateSelect
| 参数 | 解释 |
|---|---|
| score_func:callable, default=f_classif | 函数获取两个数组X和y,并返回一对数组(scores,pvalues)或一个带有scores的数组。默认值为f_classif。默认函数仅适用于分类任务。 |
| mode:{‘percentile’, ‘k_best’, ‘fpr’, ‘fdr’, ‘fwe’}, default=’percentile’ | 特征选择模式。 |
| param:float or int depending on the feature selection mode, default=1e-5 | 对应模式的参数。 |
| 属性 | 解释 |
|---|---|
| scores_:array-like of shape (n_features,) | 特征的分数 |
| pvalues_:array-like of shape (n_features,) | 特征得分的p值 |
| 方法 | 解释 |
|---|---|
| fit(X[, y]) | 在(X,y)上运行score函数并获得适当的特性。 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| set_params(**params) | 设置此估计器的参数。 |
| get_support([indices]) | 获取所选特征的掩码或整数索引 |
| inverse_transform(X) | 反转转换操作 |
| transform(X) | 将X减少到选定的特征。 |
例:
>>> from sklearn.datasets import load_breast_cancer
>>> from sklearn.feature_selection import GenericUnivariateSelect, chi2
>>> X, y = load_breast_cancer(return_X_y=True)
>>> X.shape
(569, 30)
>>> transformer = GenericUnivariateSelect(chi2, mode='k_best', param=20)
>>> X_new = transformer.fit_transform(X, y)
>>> X_new.shape
(569, 20)
1.13.3. 递归式特征消除【feature_selection.RFE,feature_selection.RFECV】
给定一个外部的估计器,可以对特征赋予一定的权重(比如,线性模型的相关系数),recursive feature elimination ( RFE ) 通过考虑越来越小的特征集合来递归的选择特征。 首先,评估器在初始的特征集合上面训练并且每一个特征的重要程度是通过一个 coef_属性 或者 feature_importances_ 属性来获得。 然后,从当前的特征集合中移除最不重要的特征。在特征集合上不断的重复递归这个步骤,直到最终达到所需要的特征数量为止。 RFECV 在一个交叉验证的循环中执行RFE 来找到最优的特征数量
sklearn.feature_selection.RFE
| 参数 | 解释 |
|---|---|
| estimator:Estimator instance | 一种有监督的学习估计器,采用拟合方法提供有关特征重要性的信息 |
| n_features_to_select:int or float, default=None | 要选择的特征数。如果None,则选择一半特征。如果为整数,则参数是要选择的特征的绝对数量。如果浮点值介于0和1之间,则它是要选择的特征的分数。 |
| step:int or float, default=1 | 如果大于或等于1,则步骤对应于每次迭代中要删除的特征数(整数)。如果在(0.0,1.0)之内,则步骤对应于在每次迭代中要删除的特征的百分比(向下舍入)。 |
| verbose:int, default=0 | 控制输出的详细程度。 |
| importance_getter:str or callable, default=’auto’ | 如果“auto”,则通过估计器的coef_或feature_importances_ 属性使用特征重要性。 |
| 属性 | 解释 |
|---|---|
| estimator_:Estimator instance | 用于选择特征的拟合估计器。 |
| n_features_:int | 选定特征的数量。 |
| ranking_:ndarray of shape (n_features,) | 特征排名 |
| support_:ndarray of shape (n_features,) | 选定特征的mask。 |
| 方法 | 解释 |
|---|---|
| decision_function(X) | 计算X的决策函数。 |
| fit(X, y) | 拟合RFE模型,然后对所选模型进行基础估计 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| get_support([indices]) | 获取所选特征的掩码或整数索引 |
| inverse_transform(X) | 反转转换操作 |
| predict(X) | 将X减少到选定的特征,然后使用 |
| predict_log_proba(X) | 预测X的类的对数概率。 |
| predict_proba(X) | 预测X的类概率。 |
| score(X, y) | 将X减少到所选特征,然后返回所选特征的分数 |
| set_params(**params) | 设置此估计器的参数。 |
| transform(X) | 将X减少到选定的特征。 |
例:
>>> from sklearn.datasets import make_friedman1
>>> from sklearn.feature_selection import RFE
>>> from sklearn.svm import SVR
>>> X, y = make_friedman1(n_samples=50, n_features=10, random_state=0)
>>> estimator = SVR(kernel="linear")
>>> selector = RFE(estimator, n_features_to_select=5, step=1)
>>> selector = selector.fit(X, y)
>>> selector.support_
array([ True, True, True, True, True, False, False, False, False,
False])
>>> selector.ranking_
array([1, 1, 1, 1, 1, 6, 4, 3, 2, 5])
sklearn.feature_selection.RFECV
| 参数 | 解释 |
|---|---|
| estimator:Estimator instance | 一种有监督的学习估计器,采用拟合方法提供有关特征重要性的信息 |
| n_features_to_select:int or float, default=None | 要选择的特征数。如果None,则选择一半特征。如果为整数,则参数是要选择的特征的绝对数量。如果浮点值介于0和1之间,则它是要选择的特征的分数。 |
| min_features_to_select:int, default=1 | 要选择的最小特征数。即使原始特征计数和最小特征选择之间的差值不能被步长整除,也将始终对该数量的特征进行评分。 |
| cv:int, cross-validation generator or an iterable, default=None | 确定交叉验证拆分策略。 |
| scoring:string, callable or None, default=None | 一个字符串(参见模型评估文档)或一个带有签名记分器(estimator,X,y)的记分器可调用对象/函数。 |
| verbose:int, default=0 | 控制输出的详细程度。 |
| n_jobs:int or None, default=None | 线程数 |
| importance_getter:str or callable, default=’auto’ | 如果“auto”,则通过估计器的coef_或feature_importances_ 属性使用特征重要性。 |
| 属性 | 解释 |
|---|---|
| estimator_:Estimator instance | 用于选择特征的拟合估计器。 |
| grid_scores_:ndarray of shape (n_subsets_of_features,) | 交叉验证得分 |
| n_features_:int | 选定特征的数量。 |
| ranking_:ndarray of shape (n_features,) | 特征排名 |
| support_:ndarray of shape (n_features,) | 选定特征的mask。 |
| 方法 | 解释 |
|---|---|
| decision_function(X) | 计算X的决策函数。 |
| fit(X, y) | 拟合RFE模型,然后对所选模型进行基础估计 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| get_support([indices]) | 获取所选特征的掩码或整数索引 |
| inverse_transform(X) | 反转转换操作 |
| predict(X) | 将X减少到选定的特征,然后使用 |
| predict_log_proba(X) | 预测X的类的对数概率。 |
| predict_proba(X) | 预测X的类概率。 |
| score(X, y) | 将X减少到所选特征,然后返回所选特征的分数 |
| set_params(**params) | 设置此估计器的参数。 |
| transform(X) | 将X减少到选定的特征。 |
例:
>>> from sklearn.datasets import make_friedman1
>>> from sklearn.feature_selection import RFECV
>>> from sklearn.svm import SVR
>>> X, y = make_friedman1(n_samples=50, n_features=10, random_state=0)
>>> estimator = SVR(kernel="linear")
>>> selector = RFECV(estimator, step=1, cv=5)
>>> selector = selector.fit(X, y)
>>> selector.support_
array([ True, True, True, True, True, False, False, False, False,
False])
>>> selector.ranking_
array([1, 1, 1, 1, 1, 6, 4, 3, 2, 5])
1.13.4. 使用 SelectFromModel 选取特征【feature_selection.SelectFromModel】
SelectFromModel 是一个 meta-transformer(元转换器) ,它可以用来处理任何带有 coef_ 或者 feature_importances_ 属性的训练之后的评估器。 如果相关的coef_ 或者 featureimportances 属性值低于预先设置的阈值,这些特征将会被认为不重要并且移除掉。除了指定数值上的阈值之外,还可以通过给定字符串参数来使用内置的启发式方法找到一个合适的阈值。可以使用的启发式方法有 mean 、 median 以及使用浮点数乘以这些(例如,0.1*mean )。
sklearn.feature_selection.SelectFromModel
| 参数 | 解释 |
|---|---|
| estimator:object | 构建转换器的基本估计器,这既可以是拟合的(如果prefit设置为True)也可以是非拟合的估计器。估计器在拟合后必须具有feature_importances_或coef_属性。 |
| threshold:string or float, default=None | 用于特征选择的阈值。重要性大于或等于的特征将被保留,而其他特征将被丢弃。如果“median” (resp. “mean”),则阈值为中值(resp.特征重要性的平均值)。也可以使用比例因子(例如,“1.25*平均值”)。如果None,并且如果估计器显式或隐式地(例如,lasso)将参数惩罚设置为l1,则使用的阈值为1e-5。否则,默认使用“mean”。 |
| prefit:bool, default=False | prefit模型是否希望直接传递到构造函数中。如果为True,则必须直接调用transform,并且SelectFromModel不能与cross_val_score, GridSearchCV 和克隆估计器的类似实用程序一起使用。另外,利用拟合对模型进行训练,然后变换进行特征选择。 |
| norm_order:non-zero int, inf, -inf, default=1 | 在估计器的coef_属性为维数2的情况下,用于过滤阈值以下系数向量的范数的阶数。 |
| max_features:int, default=None | 要选择的最大特征数 |
| importance_getter:str or callable, default=’auto’ | 如果“auto”,则通过估计器的coef_或feature_importances_ 属性使用特征重要性。 |
| 属性 | 解释 |
|---|---|
| estimator_:an estimator | 用于选择特征的拟合估计器。 |
| threshold_:float | 用于特征选择的阈值。 |
| 方法 | 解释 |
|---|---|
| fit(X, y) | 拟合模型 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| get_support([indices]) | 获取所选特征的掩码或整数索引 |
| inverse_transform(X) | 反转转换操作 |
| partial_fit(X[, y]) | 只拟合SelectFromModel meta-transformer一次 |
| set_params(**params) | 设置此估计器的参数。 |
| transform(X) | 将X减少到选定的特征。 |
例:
>>> from sklearn.feature_selection import SelectFromModel
>>> from sklearn.linear_model import LogisticRegression
>>> X = [[ 0.87, -1.34, 0.31 ],
... [-2.79, -0.02, -0.85 ],
... [-1.34, -0.48, -2.55 ],
... [ 1.92, 1.48, 0.65 ]]
>>> y = [0, 1, 0, 1]
>>> selector = SelectFromModel(estimator=LogisticRegression()).fit(X, y)
>>> selector.estimator_.coef_
array([[-0.3252302 , 0.83462377, 0.49750423]])
>>> selector.threshold_
0.55245...
>>> selector.get_support()
array([False, True, False])
>>> selector.transform(X)
array([[-1.34],
[-0.02],
[-0.48],
[ 1.48]])
1.13.4.1. 基于 L1 的特征选取
Linear models 使用 L1 正则化的线性模型会得到稀疏解:他们的许多系数为 0。 当目标是降低使用另一个分类器的数据集的维度, 它们可以与 feature_selection.SelectFromModel一起使用来选择非零系数。特别的,可以用于此目的的稀疏评估器有用于回归的 linear_model.Lasso, 以及用于分类的 linear_model.LogisticRegression 和 svm.LinearSVC
>>> from sklearn.svm import LinearSVC
>>> from sklearn.datasets import load_iris
>>> from sklearn.feature_selection import SelectFromModel
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> X.shape
(150, 4)
>>> lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y)
>>> model = SelectFromModel(lsvc, prefit=True)
>>> X_new = model.transform(X)
>>> X_new.shape
(150, 3)
在 SVM 和逻辑回归中,参数 C 是用来控制稀疏性的:小的 C 会导致少的特征被选择。使用 Lasso,alpha 的值越大,越少的特征会被选择。
1.13.4.2. 基于 Tree(树)的特征选取
基于树的 estimators (查阅 sklearn.tree 模块和树的森林 在sklearn.ensemble模块) 可以用来计算特征的重要性,然后可以消除不相关的特征(当与 sklearn.feature_selection.SelectFromModel 等元转换器一同使用时):
>>> from sklearn.ensemble import ExtraTreesClassifier
>>> from sklearn.datasets import load_iris
>>> from sklearn.feature_selection import SelectFromModel
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> X.shape
(150, 4)
>>> clf = ExtraTreesClassifier()
>>> clf = clf.fit(X, y)
>>> clf.feature_importances_
array([ 0.04..., 0.05..., 0.4..., 0.4...])
>>> model = SelectFromModel(clf, prefit=True)
>>> X_new = model.transform(X)
>>> X_new.shape
(150, 2)
1.13.5. 特征选取作为 pipeline(管道)的一部分
特征选择通常在实际的学习之前用来做预处理。在 scikit-learn 中推荐的方式是使用 :sklearn.pipeline.Pipeline:
clf = Pipeline([
('feature_selection', SelectFromModel(LinearSVC(penalty="l1"))),
('classification', RandomForestClassifier())
])
clf.fit(X, y)
在这段代码中,我们利用 sklearn.svm.LinearSVC 和 sklearn.feature_selection.SelectFromModel来评估特征的重要性并且选择出相关的特征。 然后,在转化后的输出中使用一个 sklearn.ensemble.RandomForestClassifier 分类器,比如只使用相关的特征。你也可以使用其他特征选择的方法和可以提供评估特征重要性的分类器来执行相似的操作。 请查阅 sklearn.pipeline.Pipeline 来了解更多的实例。
sklearn.pipeline.Pipeline
| 参数 | 解释 |
|---|---|
| steps:list | (名称,转换)元组列表(实现拟合/转换),按链接顺序链接,最后一个对象是估计器。 |
| memory:str or object with the joblib.Memory interface, default=None | 用于缓存已安装的管道转换器。默认情况下,不执行缓存。如果给定一个字符串,它就是缓存目录的路径。启用缓存会在拟合之前触发转换的克隆。因此,不能直接检查给管道的转换实例。使用名为_steps或steps的属性检查管道中的估计器。当拟合耗时时,缓存转换是有利的。 |
| verbose:bool, default=False | 如果为True,则拟合的每个步骤时所用的时间将在完成时打印出来。 |
| 属性 | 解释 |
|---|---|
| named_steps:Bunch | 类似字典的对象,具有以下属性。 Read-only属性,按用户给定的名称访问任何步骤参数。键是步骤名称,值是步骤参数。 |
| 方法 | 解释 |
|---|---|
| decision_function(X) | 应用变换和最终估计器的决策函数 |
| fit(X, y) | 拟合模型 |
| fit_predict(X[, y]) | 应用转换后管道中最后一步的拟合。 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| predict(X, **predict_params) | 将变换应用于数据,并使用最终估计器进行预测 |
| predict_log_proba(X) | 将变换应用于数据,并使用最终估计器进行预测对数概率 |
| predict_proba(X) | 将变换应用于数据,并使用最终估计器进行预测概率 |
| score(X[, y, sample_weight]) | 将变换应用于数据,并计算最终估计器分数 |
| score_samples(X) | 应用变换,并对最终估计量的样本进行评分。 |
| set_params(**params) | 设置此估计器的参数。 |
例:
>>> from sklearn.svm import SVC
>>> from sklearn.preprocessing import StandardScaler
>>> from sklearn.datasets import make_classification
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.pipeline import Pipeline
>>> X, y = make_classification(random_state=0)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y,
... random_state=0)
>>> pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())])
>>> # The pipeline can be used as any other estimator
>>> # and avoids leaking the test set into the train set
>>> pipe.fit(X_train, y_train)
Pipeline(steps=[('scaler', StandardScaler()), ('svc', SVC())])
>>> pipe.score(X_test, y_test)
0.88
1.14. 半监督学习
半监督学习 适用于在训练数据上的一些样本数据没有贴上标签的情况。 sklearn.semi_supervised 中的半监督估计, 能够利用这些附加的未标记数据来更好地捕获底层数据分布的形状,并将其更好地类推到新的样本。 当我们有非常少量的已标签化的点和大量的未标签化的点时,这些算法表现均良好。
y 中含有未标记的数据
在使用 fit 方法训练数据时, 将标识符与已标签化的数据一起分配给未标签化的点是尤其重要的. 实现该标记的方法是使用整数值 -1.
1.14.1. 标签传播
标签传播表示半监督图推理算法的几个变体。
该模型的一些特性如下:
- 可用于分类和回归任务
- 使用内核方法将数据投影到备用维度空间
scikit-learn 提供了两种标签传播模型: LabelPropagation和 LabelSpreading 。 两者都通过在输入的 dataset(数据集)中的所有 items(项)上构建 similarity graph (相似图)来进行工作。
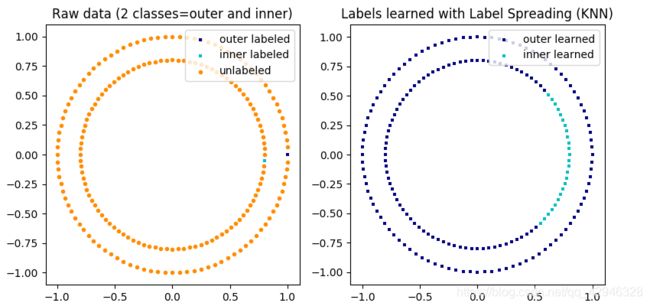
标签传播说明: 未标签化的观察值结构与 class(类)结构一致, 因此可以将 class(类)标签传播到训练集的未标签化的观察值
LabelPropagation 和 LabelSpreading 在对图形的相似性矩阵, 以及对标签分布的clamping effect(夹持效应)的修改方面不太一样。 Clamping 允许算法在一定程度上改变真实标签化数据的权重。 该 LabelPropagation 算法执行输入标签的 hard clamping, 这意味着 α = 0 \alpha=0 α=0 。 这些 clamping factor 可以不是很严格的, 例如 α = 0.2 \alpha=0.2 α=0.2 , 这意味着我们将始终保留原始标签分配的 80%, 但该算法可以将其分布的置信度改变在 20% 以内。
LabelPropagation 使用原始相似性矩阵从未修改的数据来构建。 LabelSpreading 最小化具有正则化属性的损耗函数, 因此它通常更适用于噪声数据。 该算法在原始图形的修改版本上进行迭代, 并通过计算 normalized graph Laplacian matrix (归一化图拉普拉斯矩阵)来对边缘的权重进行归一化。 此过程也用于 Spectral clustering 。
标签传播模型有两种内置的 kernel methods(核函数)。 kernel (核)的选择会影响算法的可扩展性和性能。 以下是可用的:
- r b f ( exp ( − γ ∣ x − y ∣ 2 ) , γ > 0 ) rbf (\exp(-\gamma |x-y|^2), \gamma > 0) rbf(exp(−γ∣x−y∣2),γ>0). γ \gamma γ 通过关键字
gamma来指定。 - k n n ( 1 [ x ′ ∈ k N N ( x ) ] ) knn (1[x' \in kNN(x)]) knn(1[x′∈kNN(x)]). k k k 通过关键字
n_neighbors来指定。
RBF 核将产生一个完全连接的图形, 它通过密集矩阵在内存中表示。 该矩阵可能非常大, 与算法的每次迭代执行全矩阵乘法计算的成本相结合可导致超长的运行时间。 在另一方面, KNN 核将产生更多的内存友好的稀疏矩阵, 这样可以大幅度的减少运行时间。
sklearn.semi_supervised.LabelPropagation
| 参数 | 解释 |
|---|---|
| kernel:{‘knn’, ‘rbf’} or callable, default=’rbf’ | 要使用的内核函数或内核函数本身的字符串标识符。只有“rbf”和“knn”字符串是有效输入。 |
| gamma:float, default=20 | rbf核的参数。 |
| n_neighbors:int, default=7 | knn内核的参数,需要严格正。 |
| max_iter:int, default=1000 | 更改允许的最大迭代次数 |
| tol:float, 1e-3 | 收敛容限:考虑系统稳态时的阈值。 |
| n_jobs:int, default=None | 线程数 |
| 属性 | 解释 |
|---|---|
| X_:ndarray of shape (n_samples, n_features) | 输入数组。 |
| classes_:ndarray of shape (n_classes,) | 用于分类实例的不同标签。 |
| label_distributions_:ndarray of shape (n_samples, n_classes) | 每个项目的分类分布。 |
| transduction_:ndarray of shape (n_samples) | 通过传感器分配给每个项目的标签。 |
| n_iter_:int | 运行的迭代次数。 |
| 方法 | 解释 |
|---|---|
| decision_function(X) | 应用变换和最终估计器的决策函数 |
| fit(X, y) | 拟合模型 |
| fit_predict(X[, y]) | 应用转换后管道中最后一步的拟合。 |
| fit_transform(X[, y]) | 拟合数据,然后转换它。 |
| get_params([deep]) | 获取此估计器的参数。 |
| predict(X, **predict_params) | 将变换应用于数据,并使用最终估计器进行预测 |
| predict_log_proba(X) | 将变换应用于数据,并使用最终估计器进行预测对数概率 |
| predict_proba(X) | 将变换应用于数据,并使用最终估计器进行预测概率 |
| score(X[, y, sample_weight]) | 将变换应用于数据,并计算最终估计器分数 |
| score_samples(X) | 应用变换,并对最终估计量的样本进行评分。 |
| set_params(**params) | 设置此估计器的参数。 |
例:
>>> from sklearn.svm import SVC
>>> from sklearn.preprocessing import StandardScaler
>>> from sklearn.datasets import make_classification
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.pipeline import Pipeline
>>> X, y = make_classification(random_state=0)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y,
... random_state=0)
>>> pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())])
>>> # The pipeline can be used as any other estimator
>>> # and avoids leaking the test set into the train set
>>> pipe.fit(X_train, y_train)
Pipeline(steps=[('scaler', StandardScaler()), ('svc', SVC())])
>>> pipe.score(X_test, y_test)
0.88