基于kmeans聚类算法的微博舆情热点事件分析系统
目录
第一章 引言 2
1.1 研究背景及意义 2
1.2 国内外相关问题研究现状 3
1.3 论文的理论意义与实用价值 4
第二章 相关技术介绍 4
2.1 开发平台简述 4
2.2 OAuth2.0简介 5
2. 3 空间向量模型 6
2.4 文本聚类算法 8
2.5 数据库方案 9
第三章 系统设计 11
3.1 热点分析策略 11
3. 2 系统总体设计 11
3.3 系统模块详细设计 12
3.4 数据库设计方案 24
第四章 系统实现 25
4.1 数据获取模块实现 25
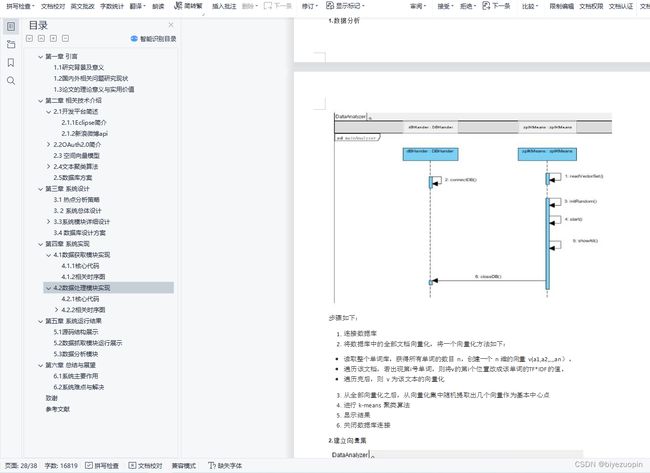
4.2 数据处理模块实现 28
第五章 系统运行结果 31
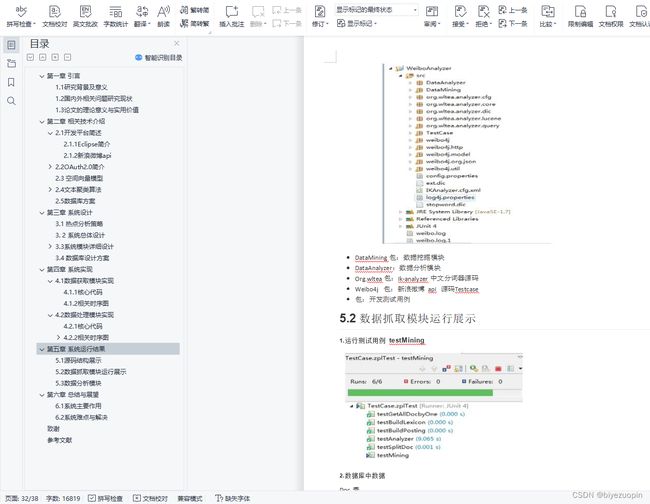
5.1 源码结构展示 31
5.2 数据抓取模块运行展示 32
5.3 数据分析模块 34
第六章 总结与展望 36
6.1 系统主要作用 36
6.2 系统难点与解决 36
致谢 37
参考文献 37
本系统以新浪微博为信息源,以新浪微博的一个用户为起始点,获取与挖掘以该用户为中心的人际网络之间的热点 事件,以匹配到用户的最佳兴趣点。不仅仅进行诸如商业价值(用户兴趣挖掘),信息传播学(网络拓扑与热点追 踪),以及一些社会学方面的研究。从而能够满足人们的需求,同时对于社会的和谐、网络舆论生态的健康、国家 的发展都有重要的现实意义。
第二章 相关技术介绍
2.1开发平台简述
2.1.1Eclipse简介
课题是在Eclipse上编译和调试的应用程序,下面简单介绍Eclipse信息:
Eclipse简介:Eclipse是一个开放源代码的、基于Java的可扩展开发平台,对eclipse而言,它仅是是一个框架和一组服务,可以通过各种各样的插件和组件来搭建开发环境。
Eclipse的目标不仅是将其当做Java IDE来使用,还要利用其插件开发环境 (Plug-in DevelopmentEnvironment,
PDE),通过开发各种插件来扩展Eclipse的软件开发人员,这使软件开发人员能构建与Eclipse环境无缝集成的工具。
Eclipse最初是替代由IBM公司开发的价值四千万美金的商业软件Visual Age for Java的下一代IDE开发环境,2001 年11月交给非营利软件供应商联盟Eclipse 基金会(Eclipse Foundation)管理。2003年,Eclipse 3.0选择OSGi服务平台规范为运行时架构。
Eclipse采用的技术是IBM公司开发的((SWT),这种技术基于Java的窗口组件,类似Java本身提供的AWT和Swing窗口组件。Eclipse的用户界面还使用了 GUI中间层JFace,这样一来大大简化了基于SWT的应用程序的构建。
Eclipse的插件机制是轻型软件组件化架构。在RCP平台上,Eclipse使用软件人员开发的各种插件来提供所有的附加功能,例如android的ADT插件,这使得软件开发人员能使用Eclipse来编译android应用软件,完成软件的编译测 试还有调试等工作。还有的插件不仅能支持JAVA,还可以支持C/C++(CDT)、 PerLRuby, P帅ont和数据库开发。这种插件架构带来非常多的便利,能够支持任意的扩展使其加入到当前的开发环境中,缩短开发周期,节约金钱。
2.1.2新浪微博api
新浪微博API是新浪为了方便第三方应用接入微博这个大系统而开放的API, 有了这个API我就不用重新写爬虫程序获取新浪微博上的大量微博,直接调用新浪微博的API完成我的扒取任务。
新浪微博api的验证登陆方式是OAuth2.0方式,现在对OAuth2.0进行简要介
2.2OAuth2.0简介
由于需要使用新浪api替代网络爬虫来进行数据收集,所以在介绍了新浪api 之后,我们队新浪api的代理接入方法做介绍即OAuth2.0。
1.OAuth前言
OAuth 1.0已经在IETF尘埃落定,编号是RFC5849,这也标志着OAuth已经正式成为互联网标准协议。OAuth2.0早已经开始讨论和建立的草案。OAuth2. 0很可能是下一代的“用户验证和授权”标准。现在百度开放平台,腾讯开放平台,新浪微博开放平台等大部分的开放平台都是使用的OAuth 2. 0协议作为支撑。
OAuth(开放授权)是一个开放标准,允许用户让第三方应用访问该用户在某一网站上存储的私密的资源(如照 片,视频,联系人列表),而无需将用户名和密码提供给第三方应用。
2.OAuth
允许用户提供一个令牌,而不是用户名和密码来访问他们存放在特定服务提供者的数据。每一个令牌授权一个特定 的网站(例如,视频编辑网站)在特定的时段(例如,接下来的2小时内)内访问特定的资源(例如仅仅是某一相 册中的视频)。这样,OAuth允许用户授权第三方网站访问他们存储在另外的服务提供者上的信息,而不需要分享 他们的访问许可或他们数据的所有内容。
OAuth是OpenID的一个补充,但是完全不同的服务。OAuth 2. 0是OAuth协议的下一版本,但不向后兼容OAuth
- 00 OAuth2. 0 关注客户端开发者的简易性,同时为Web应用,桌面应用和手机,和起居室设备提供专门的认证流程。
Facebook的新的Graph API只支持OAuth2.0, Google在2011年3月亦宣布 Google API对OAuth 2. 0的支援。
3.认证和授权过程
在认证和授权的过程中涉及的三方包括:
服务提供方,用户使用服务提供方来存储受保护的资源,如照片,视频,联系人列表。 用户,存放在服务提供方的受保护的资源的拥有者。
客户端,要访问服务提供方资源的第三方应用,通常是网站,如提供照片打印服务的网站。在认证过程之 前,客户端要向服务提供者申请客户端标识。
使用OAuth进行认证和授权的过程如下所示:
用户访问客户端的网站,想操作用户存放在服务提供方的资源。客户端向服务提供方请求一个临时令牌。
服务提供方验证客户端的身份后,授予一个临时令牌。
客户端获得临时令牌后,将用户引导至服务提供方的授权页面请求用户授权。在这个过程中将临时令牌和客 户端的回调连接发送给服务提供方。
用户在服务提供方的网页上输入用户名和密码,然后授权该客户端访问所请求的资源。 授权成功后,服务提供方引导用户返回客户端的网页。
客户端根据临时令牌从服务提供方那里获取访问令牌。
服务提供方根据临时令牌和用户的授权情况授予客户端访问令牌。
客户端使用获取的访问令牌访问存放在服务提供方上的受保护的资源。
4.历史回顾
OAuth 1.0在2007年的12月底发布并迅速成为工业标准。
2008年6月,发布了OAuth 1.0Revision A,这是个稍作修改的修订版本,主要修正一个安全方面的漏洞。
2010年四月,OAuth 1.0的终于在IETF发布了,协议编号RFC 5849。 OAuth 2. 0的草案是在2011年5月初在IETF发布的。
OAuth是个安全相关的协议,作用在于,使用户授权第三方的应用程序访问用户的web资源,并且不需要向第三方 应用程序透露自己的密码。
OAuth2.0是个全新的协议,并且不对之前的版本做向后兼容,然而,OAuth2.0 保留了与之前版本OAuth相同的整体架构。
这个草案是围绕着OAuth2. 0的需求和目标,历经了长达一年的讨论,讨论的参与者来自业界的各个知名公司,包括 Yahoo!, Facebook, Salesforce, Microsoft, Twitter, Deutsche Telekom, Intuit,Mozilla, 和 Google 。
2.3 空间向量模型
向量空间模型(VSM: Vector Space Model)由Salton等人于20世纪70年代提出,并成功地应用于著名的SMART文本检索系统。
VSM概念简单,把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度, 直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性。文本处理 中最常用的相似性度量方式是余弦距离。
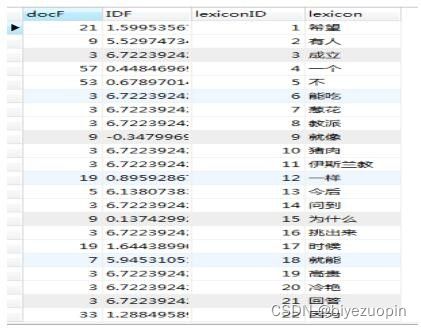
M个无序特征项ti,词根/词/短语/其他每个文档dj可以用特征项向量来表示(a1j, a2j, …, aMj)权重计算,N个训练文档AM*N= (aij)文档相似度比较。
Cosine计算,余弦计算的好处是,正好是一个介于0到1的数,如果向量一致就是1,如果正交就是0,符合相 似度百分比的特性,余弦的计算方法为,向量内积/各个向量的模的乘积。
内积计算,直接计算内积,计算强度低,但是误差大。
向量空间模型(或词组向量模型)是一个应用于信息过滤,信息撷取,索引以及评估相关性的代数模型。SMART是 首个使用这个模型的信息检索系统。
文件(语料)被视为索引词(关键词)形成的多次元向量空间,索引词的集合通常为文件中至少出现过一次的词 组。
搜寻时,输入的检索词也被转换成类似于文件的向量,这个模型假设,文件和搜寻词的相关程度,可以经由比较每个文件(向量)和检索词(向量)的夹角偏差程度而得知。
实际上,计算夹角向量之间的余弦比直接计算夹角容易:
余弦为零表示检索词向量垂直于文件向量,即没有符合,也就是说该文件不含此检索词。
通过上述的向量空间模型,本文转载自http://www.biyezuopin.vip/onews.asp?id=13839文本数据就转换成了计算机可以处理的结构化数据,两个文档之间的相似性问题转变成了两个向量之间的相似性问题。
本文中使用空间向量模型主要用于下面2个目的:
1.使用向量表示微博文档
2.借以来判断2条微博的相似性下面详细介绍如何实现:
1.向量表示文档
首先,我们知道任何一条微博都是由单词构成的,我们在最初之时就构建了一个包含全部文档集合的词典,只要文 档集合中出现了的单词,我们的词典之中就会有。于是我们根据词典里面单词的个数N构建出一个N维的向量
文档A对应的向量A=
package weibo4j;
import weibo4j.model.PostParameter;
import weibo4j.model.User;
import weibo4j.model.WeiboException;
import weibo4j.org.json.JSONArray;
import weibo4j.util.WeiboConfig;
public class Users extends Weibo{
private static final long serialVersionUID = 4742830953302255953L;
/*----------------------------用户接口----------------------------------------*/
/**
* 根据用户ID获取用户信息
*
* @param uid
* 需要查询的用户ID
* @return User
* @throws WeiboException
* when Weibo service or network is unavailable
* @version weibo4j-V2 1.0.1
* @see users/show
* @since JDK 1.5
*/
public User showUserById(String uid) throws WeiboException {
return new User(client.get(
WeiboConfig.getValue("baseURL") + "users/show.json",
new PostParameter[] { new PostParameter("uid", uid) })
.asJSONObject());
}
/**
* 根据用户ID获取用户信息
*
* @param screen_name
* 用户昵称
* @return User
* @throws WeiboException
* when Weibo service or network is unavailable
* @version weibo4j-V2 1.0.1
* @see users/show
* @since JDK 1.5
*/
public User showUserByScreenName(String screen_name) throws WeiboException {
return new User(client.get(
WeiboConfig.getValue("baseURL") + "users/show.json",
new PostParameter[] { new PostParameter("screen_name",
screen_name) }).asJSONObject());
}
/**
* 通过个性化域名获取用户资料以及用户最新的一条微博
*
* @param domain
* 需要查询的个性化域名。
* @return User
* @throws WeiboException
* when Weibo service or network is unavailable
* @version weibo4j-V2 1.0.1
* @see users/domain_show
* @since JDK 1.5
*/
public User showUserByDomain(String domain) throws WeiboException {
return new User(client.get(
WeiboConfig.getValue("baseURL") + "users/domain_show.json",
new PostParameter[] { new PostParameter("domain", domain) })
.asJSONObject());
}
/**
* 批量获取用户的粉丝数、关注数、微博数
*
* @param uids
* 需要获取数据的用户UID,多个之间用逗号分隔,最多不超过100个
* @return jsonobject
* @throws WeiboException
* when Weibo service or network is unavailable
* @version weibo4j-V2 1.0.1
* @see users/domain_show
* @since JDK 1.5
*/
public JSONArray getUserCount(String uids) throws WeiboException{
return client.get(WeiboConfig.getValue("baseURL") + "users/counts.json",
new PostParameter[] { new PostParameter("uids", uids)}).asJSONArray();
}
}