基于粒子群算法的微电网优化调度应用研究(三、长短期记忆网络和卷积神经网络预测模型)
长短期记忆网络和卷积神经网络预测模型
3.1 预测概述
在微电网中,由于系统的电源种类多,间隙性发电占比大、运行经济性要求高等特点,分布式电源需要应用能量管理系统。新能源随机调度问题的关键技术是通过分布式发电功率预测技术和负荷预测技术把不确定的能量优化问题转化换成确定性问题。
本文针对采集到的数据进行了SSE(误差平方和)、RMSE(标准差)、MAE(平均绝对误差)以及MAPE(平均绝对百分比误差)四个评价指标。通过这四个评价指标来对模型的的优劣程度、以及性能进行评估。
3.2 数据标准化
数据标准化的提出是基于针对模型的评价不能只从单一方面进行,并且模型变量的输入也非单一的数据,每个指标的数据水平,重要程度都有所不同,所以要对其进行多指标综合的评价。而在进行多指标评价时由于评价指标的不同之处如果直接用原始的数值进行评价就会导致评价结果不准确,不可靠。同理在对获得的数据进行分析时,由于数据的类型,量纲不同,如果直接对数据进行处理也会大大增加我们搭建模型的难度,以及训练模型的难度,因此对数据进行标准化处理。目前已有的标准化方法中常用的有,max—min标准化,将数据映射在区间[0,1]中,但是考虑到使用该方法时,如果新输入的数据中存在一个新的最大值或最小值,那么还需要对模型进行更新。本文采用的方法是Z-score 标准化,该方法具体原理如下:
对序列x1 、x2 ……xn 进行变换:
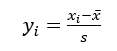 (3-1)
(3-1)
其中
![]() (3-2)
(3-2)
 (3-3)
(3-3)
通过式(3-1)标准化后新序列y1 、y2 ……yn 的均值是0,方差为1,没有量纲。大于平均水平的值大于零,小于平均水平的值小于零。
3.3 长短期记忆网络基本原理
长短时记忆网络( LSTM)是对循环神经网络(RNN)进行改进后的网络,原本的RNN网络并不能解决对于长期的依赖问题,因为RNN只有单个状态,解决短距离内输入的数据比较优秀,通过对RNN网络的状态中添加Cell 状态,可以用该状态再存储一个长距离的数据。因此该模型既可以处理长期问题也可以处理短期问题。
从时间的层次来说明,当处于某个时刻时,会对长短期记忆网络输入三个值,分别是前一时刻的输出参数ht-1 、前一时刻的状态参数Ct-1 、以及这一时刻的输入参数X_t 。同时长短期记忆网络会有两个输出值分别时这一时刻的张状态参数Ct 以及输出参数ht 。.
使用三个控制开关控制长期状态 c:
第一个开关,其作用是判断是否保存长期状态参数;
第二个开关,其作用是判断在当前时刻的状态能否保存入长期状态 C 中
第三个开关,其作用是判断在长期状态中保存的参数能否输出。
对于上述开关的控制使用的是门算法,将输入的向量转换为一个零和一的向量。
公式如下:
![]() (5-1)
(5-1)
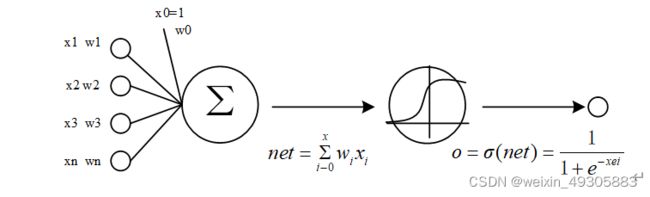
图3-1 门开关原理
如图3-1所示,通过用门的输出向量按元素乘上我们需要控制的向量,在sigmoid函数中门的输出是 0到1 之间的实数向量,当门输出为 0 时,任何向量与之相乘都会得到 0 向量,这就表明数据被舍弃或者遗忘,任何数据也无法通过;而当输出为 1 时,任何向量与之相乘的结果都为原向量,这就表明数据被保存,可以通过。
遗忘门(forget gate):它决定了上一时刻的单元状态参数 Ct-1 保留到当前时刻 Ct 的数量,遗忘门可以保存很久很久以前的信息。
输入门(input gate):它决定了当前时刻网络的输入参数 xt-1 可以保存到单元状态Ct-1 的数量,可以避免当前无关紧要的内容进入记忆。
输出门(output gate):它决定了单元状态参数 Ct 输出到 LSTM 的当前输出值 ht 的数量,输出门控制了长期记忆对当前输出的影响。
3.3 LSTM预测模型实现步骤
第一步:读取测量的数据,通过历史数据建立特征值与待预测值的关系。使用pd.excel()函数读取数据。
第二步:进行数据标准化,使用正规化方法。
第三步:进行参数定义,按照8:2 划分训练集和测试集。定义迭代次数为200,批次训练样本数目为2000.获取第二列之后为输入x,第二列为输出y。
第四步:打乱数据集行顺序。构建测试集数据。
第五步:构建LSTM模型,模型如表3-2,分为
LSTM层1、LSTM层2、全连接层1、dropout层1、全连接层2
表3-1 LSTM数据驱动模型

LSTM函数中所用到的核心参数如下
units:门结构(forget门、update门、output门)使用的隐藏单元个数。
input_dim:表示的是输入参数的维度,如果输入第一层就是输入层则需要提前设定(在本实验中将数据类型reshape后再输入)
return_sequences:表示的是布尔值,布尔值返回值是False时输出最后一个,否则返回值为全部序列。
input_length:该参数为输入序列的长度。尤其是当LSTM层后如果紧接着就是Flatte,n层以及全连接层时则需要该参数,否则全连接层的输出无法计算。
训练模型的预测结果极容易产生过拟合的现象。即:在训练集上的损失比较小,且预测值与实际值的误差较小,然而在测试集上损失较大,预测值与实际值的误差较大。基于此种考虑,添加dropout函数,该函数旨在增强模型的泛化性。具体原理如下
当神经网络没有添加Droupout时,训练结果容易造成过拟合,在训练集上效果较好,但是在测试集上效果很差。为了防止这种现象添加Dropout层,当训练时,从输入到输出的传递过程中,dropout会设定一个比例,该比例会在训练过程中将一部分特征值临时忽略。此时删除的只是过程中的部分神经元,但输出部分的神经元数目不会变化。
神经元输出的结果反向传递,没有被删除的神经元将更新参数。重复上述过程,之前的一些被删除的神经元会被回复但是参数不变。这一过程可以看作每一次都对模型的结构进行了更改,好处是多种模型结构取平均值后,能够有效的减少过拟合的现象。
3.4卷积神经网络算法原理
传统的神经网络模型,数据通过输入层输入经过隐含层后输出。卷积神经网络(CNN)在传统的神经网络基础上添加了卷积层和池化层。即:数据通过输入层输入后,进入卷积层卷积运算,此处进行的卷积运算是人为的定义一个卷积核,卷积核扫过输入的数据进行卷积运算后进入激活层、激活层将卷积层运算的结果进行非线性映射。通过激活层后进入池化层,池化层也叫做子采样,有均值采样和最大值采样两种方式,可以看作数据再一次进行了一个卷积层,但该卷积的目的是为了提取出最明显的特征以减小模型的复杂程度。最后数据到达全连接层,通过全连接层将学习的特征映射与样本空间进行分类。
3.5卷积神经网络实现步骤
第一步:读取测量的数据,这里使用pd.excel()函数读取数据。
第二步:进行数据标准化,使用正规化方法。
第三步:进行参数定义,和LSTM模型一致,按照8:2 划分训练集和测试集。定义迭代次数为200,批次训练样本数目为2000。
第四步:打乱数据集行顺序。构建测试集数据。
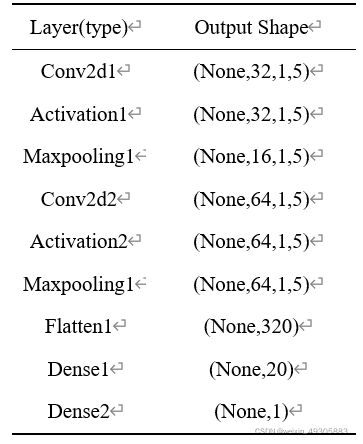
第五步:构建CNN模型,模型如表3-2,分为:
卷积层1、激活层1、最大池化层1、卷积层2、激活层2、最大池化层2、flatten层1(作用是将多维数据转化为一维特征向量,以供下一层(全连接层)使用)、全连接层1、全连接层2
表3-2 CNN数据驱动模型
3.5 算例分析
通过构建的长短期记忆网络,对已经采集的历史数据进行预测模型的建立,通过该算法将负荷与相关参数建立联系。
在结果分析中loss表示的是训练集的损失值,test_loss是测试集的损失值
如果训练集的损失值随着Epochs不断上涨而下降,测试集的损失值随着Epochs不断上涨而下降,说明模型在学习;(这是最好的情况)
如果训练集的损失值随着Epochs不断上涨而下降,但测试集的损失值随着Epochs不断上涨趋于不变,说明模型过拟合;(此时可以使用maxpooling最大池化函数或者调用正规化)
如果训练集的损失值随着Epochs不断上涨趋于不变,测试集的损失值随着Epochs不断上涨而下降,说明训练中的数据集存在问题;(需要检查数据集)
如果训练集的损失值随着Epochs不断上涨趋于不变,而且测试集的损失值随着Epochs不断上涨也趋于不变,说明模型的学习遇到瓶颈,此时可以减小优化函数中学习率(Lr)或者模型处理的批量数目(batch_size);
如果训练集的损失值随着Epochs不断上涨反而上升,同时测试集的损失值随着Epochs不断上涨也在不断上升,说明模型的设计不准确,也可能是训练过程中的参数设置不合适。
3.5.1 负荷损失变化以及结果对比
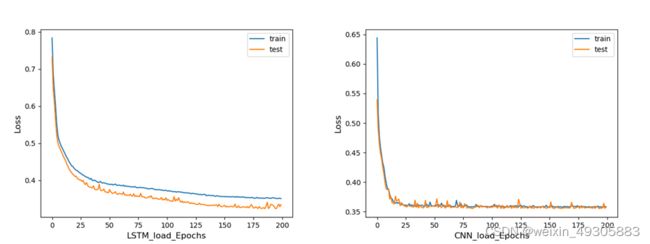
图3-2 LSTM和CNN负荷预测损失变化对比
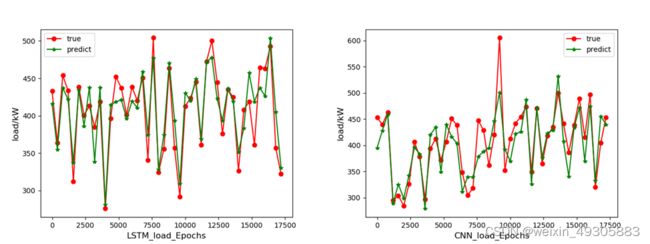
图3-3 LSTM和CNN负荷预测结果对比
3.5.2 风电功率预测损失变化以及结果对比
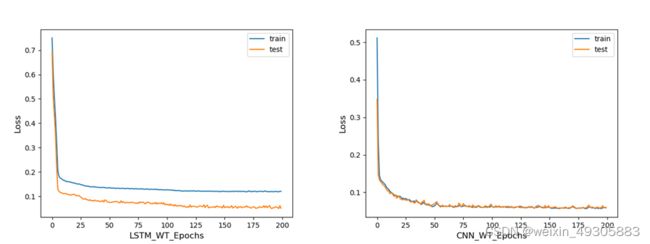
图3-4 LSTM和CNN风电功率预测损失变化对比
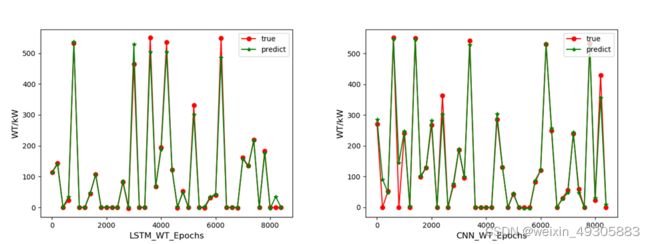
图3-5 LSTM和CNN风电功率预测预测结果对比
3.5.3 光伏功率预测损失变化以及结果对比

图3-6 LSTM和CNN光伏功率预测损失变化对比
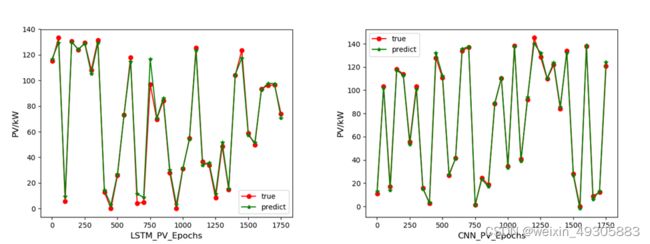
图3-7 LSTM和CNN光伏功率预测预测结果对比
3.5.3 对比结果分析
Epochs:Epochs定义为所有批次向前以及向后传播的单一训练迭代。一个周期表示的是全部输入数据向前以及向后的一次传递。
Loss: 即MAE平均绝对误差(Mean Absolute Error)范围[0,+∞),如果平均句绝对误差为零则可以认为该模型十分完美。
通过图3-2、3-4以及3-6可以看出训练集的损失值随着Epochs不断上涨而下降,测试集的损失值随着Epochs不断上涨而下降, CNN模型训练过程中损失下降更快,这表明两个模型都在模型在学习的过程中,并且表明设置的参数很好
表3-3 评价指标对比
| 评价指标 |
RMSE |
MAE |
MAPE |
R2 |
| LSTM负荷预测 |
21.58 |
15.80 |
0.03 |
0.85 |
| CNN负荷预测 |
723.54 |
569.68 |
0.06 |
0.54 |
| LSTM风电预测 |
6.34 |
5.13 |
0.07 |
0.99 |
| CNN风电预测 |
74.09 |
66.37 |
0.07 |
0.98 |
| LSTM光伏预测 |
33.29 |
21.63 |
0.89 |
0.99 |
| CNN光伏预测 |
182.25 |
62.40 |
0.43 |
0.83 |
MSE(均方差)是预测数据和原始数据对应点误差的平方和的均值
RMSE(均方根) 也叫回归系统的拟合标准差,是MSE的平方根
MAE平均绝对误差(Mean Absolute Error)范围[0,+∞),当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。
MAPE平均绝对百分比误差(Mean Absolute Percentage Error)范围[0,+∞),MAPE 为0%表示完美模型,MAPE 大于 100 %则表示劣质模型
R2(R-Square)决定系数,判断模型的好坏,0表示拟合效果差,1表示模型无错误。
通过对比可以发现,在处理一维的数据时,LSTM模型的预测效果要比CNN模型的预测效果好,这是因为CNN主要用来处理的是图像,而当用其来处理一维数据的时候将一维数据进行了reshape,使CNN模型能够间接的处理一维数据。
3.6 本章小结
本章节阐述了负荷预测、可再生电源功率预测在微电网优化调度中的作用,介绍了在搭建预测模型时的数据标准化方法,并介绍了数据驱动型的长短期记忆网络模型以及卷积神经网络模型的基本结构以及基本原理,首先要对对标准化后的数据集进行reshape转换成LSTM以及CNN可读的数据,按照8:2划分训练集以及测试集后训练出模型并验证,通过验证结果可以看出本文所构造的的长短期记忆网络模型的预测精度更高可以有效地对负荷、风电功率以及光伏功率进行预测。