C++ 11 新玩法
文章目录
-
- 列表初始化
- 类型推导auto和 decltype
- final和override
- 右值引用
- 完美转发
- 新的类功能
- 可变参数模板
- lambda表达式
- 包装器
- bind绑定
列表初始化
C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定
义的类型,使用初始化列表时,可添加等号(=),也可不添加
int main()
{
int a = 10;
int d = { 10 };
int b{ 10 };
int c{ 3 + 3 };
int* arr = new int[4]{ 1,2,3,4 };
//int* arr = new int[4] = { 1,2,3,4 }; 这样不支持
vector<int> v1{ 1,2,3,4 };
vector<int> v2 = { 1,2,3,4 };
map<int, int> m1 = { {1,2},make_pair(2,3) };
map<int, int> m2 = { {1,2},make_pair(2,3) };
map<int, int> m3 { {1,2},make_pair(2,3) };
map<int, int> m4 { {1,2},make_pair(2,3) };
return 0;
}
自定类型的列表初始化
class A
{
public:
A(int x, int y)
:_x(x)
,_y(y)
{}
private:
int _x;
int _y;
};
int main()
{
A a = { 1,2 }; //这个实际上去调用了构造函数
A a1{ 1,2 };
return 0;
}
关于initializer_list这个容器,也就是序列对 {1,2,3,4}。
像vector v = {1 , 2, 3 4 },list = {1,2,3,4},,,等等容器支持这个初始化,是因为C++11在vector,list容器的
构造函数中添加了利用传参initializer_lsit来构造

原理大概是这样的
namespace chen
{
template <class T>
class vector
{
typedef T* iterator;
public:
vector(const initializer_list<T>& l)
{
_start = new T[l.size()];
_finish = _start + l.size();
_endofstorage = _start + l.size();
//initializer_list未提供operator[]的重载
auto it = _start;
for (auto e : l)
{
*it = e;
it++;
}
}
vector& operator=(const initializer_list<T>& l)
{
vector ret(l); // 直接利用构造函数
::swap(ret._start, _start);
::swap(ret._finish, _finish);
::swap(ret._endofstorage, _endofstorage);
return *this;
}
private:
T* _start;
T* _finish;
T* _endofstorage;
};
}
int main()
{
initializer_list<int> l = { 1,2,3,4,5 };
chen::vector<int> v1 = { 1,2,3,4,5 };
chen::vector<int> v2 = { 4,5 };
v1 = { 2,3,4 };
return 0;
}
类型推导auto和 decltype
auto进行类型推导必须初始化。(常用常偷懒)
decltype是用来进行表达式的类型推导然后去定义变量类型(浅浅的了解一下)
int main()
{
//auto c; //error
auto a = 4;
auto b = &a;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
vector<int> v = { 1, 2 ,3 ,4 ,5 ,6 };
vector<int>::iterator it = v.begin();
//auto it = v.begin(); 这样就偷懒多了
while (it != v.end())
{
cout << *it << " ";
it++;
}
int a1 = 10;
double d = 5.0;
decltype(a1 * d) c; //但是它只是定义
cout << typeid(c).name() << endl; //输出double
auto e = a1 * d; //它是初始化
cout << typeid(e).name() << endl; //输出double
return 0;
}
final和override
final和override修饰函数的时候和const修饰this指针的用法一样
class A final //表示A不能被继承
{
};
final修饰的是继承体系中的虚函数,表示该虚函数不能被重写,否则报错。
final修饰类,表示该类不能被继承。
override修饰继承继承体系中子类的虚函数,如果该虚函数没有被重写则报错。
右值引用
C++98中提出了引用的概念,引用即别名,引用变量与其引用实体公共同一块内存空间,而引用的底层是通
过指针来实现的,因此使用引用,可以提高程序的可读性。
(所以这里考过一道题:指针传地址,引用传值,这是错误的,因为底层。。。。)
为了提高程序运行效率,C++11中引入了右值引用,右值引用也是别名。语法是T&&,
右值引用的核心是窃取临时变量(或将亡值)的资源,因为这些变量可能立马会销毁了,但是右值引用后,
会将这些临时变量(或将亡值)存储到特定的位置。。
int Add(int x, int y)
{
return x + y;
}
int main()
{
//对右值(临时变量,将亡值)的引用,当临时值返回的时候,引用之后就不销毁了
//对右值引用之后,会去开辟一块空间去存储它,也就可理解下面为什么能够修改了
int&& ret = Add(10, 5); //返回值就是一个右值(临时变量)
cout << ret << endl;
ret = 20;
cout << ret << endl;
return 0;
}
左值的定义 : 可取地址 + 赋值 + 可修改 (const修饰的左值不能修改,const修饰的常变量不会开辟空间,c++访问的时候直接替换,
取地址的时候才会开辟空间,但是c++认为它是左值。另外的话,const对象既可以引用右值,也可以引用左值)
右值的定义:右值不能取地址,不能修改(因为它一般是临时变量,或者说是将亡值),但是右值可引用move后的左值
int main()
{
int a = 10;
int b = a;
int* p = &a;
const int d = 10;
//a,b,p,d都是左值
const int& e = 10; //左值引用右值
int&& c = move(a); //右值引用左值
//10
//a + b
//fadd(a,b) 都是右值
return 0;
}
总结:

那么,重点来了,右值引用的核心(窃取临时变量或者将亡值的资源)
namespace chen
{
class string
{
public:
string(const char* str = "")
:_sz(strlen(str))
,_capacity(_sz)
{
//cout << " 默认构造函数" << endl;
_str = new char[_sz + 1];
strcpy(_str, str);
}
//s1(s)
string(const string& s)
:_str(nullptr)
{
cout << "拷贝构造" << endl;
string tmp(s._str);
swap(tmp);
}
//s1 = s2
string& operator=(const string& s)
{
cout << "赋值重载" << endl;
string tmp(s._str);
swap(tmp);
}
//string s1(对象)
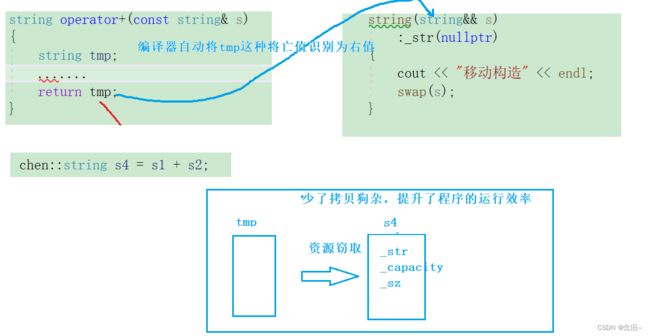
string(string&& s)
:_str(nullptr)
{
cout << "移动构造" << endl;
swap(s);
}
// s1 = 临时对象 ,
string& operator=(string&& s)
{
cout << "移动赋值" << endl;
swap(s);
return *this;
}
void swap(string& s)
{
::swap(_str, s._str);
::swap(_sz, s._sz);
::swap(_capacity, s._capacity);
}
~string()
{
delete _str;
_str = nullptr;
}
string operator+(const string& s)
{
string tmp;
tmp._sz = _sz + s._sz;
tmp._capacity = _capacity + s._capacity;
strcpy(tmp._str, _str);
tmp._str = (char*)realloc(tmp._str, _sz + 1);
strcat(tmp._str, s._str);
return tmp;
}
private:
char* _str;
size_t _sz;
size_t _capacity;
};
}
int main()
{
chen::string s1 = "hello";
chen::string s2 = "chen";
chen::string s4 = s1 + s2;
chen::string s5;
s5 = s1 + s2;
return 0;
}
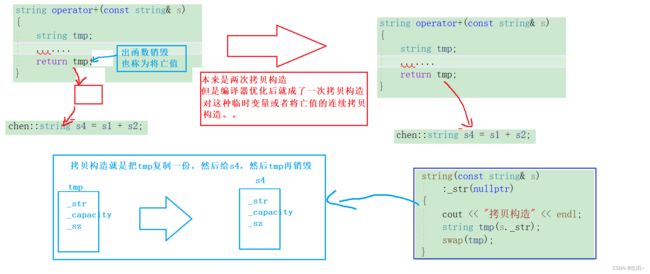
但是引入移动构造后(移动赋值一样,这里就不过多赘述了)
右值引用一些更深入的使用场景
当需要用右值引用引用一个左值时,可以通过move函数将左值转化为右值。move()函数位于 头文件中,该函数名字具有迷惑性,
它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义。
int main()
{
chen::string s1 = "hello chen";
chen::string s2(s1); // s1是左值调用的拷贝构造
chen::string s3(move(s1)); // 将s1转化为右值,move以后s1的资源就不存在了,移动构造
return 0;
}
int main()
{
// void push_back (value_type&& val);
// 这里用vector的话可能还不行
list<chen::string> l;
chen::string s1 = "hello chen";
l.push_back(s1); //传左值的话肯定是一个拷贝构造
l.push_back("hello chen"); // 传右值就是一个移动构造
l.push_back(move(s1)); // 传右值就是一个移动构造
return 0;
}
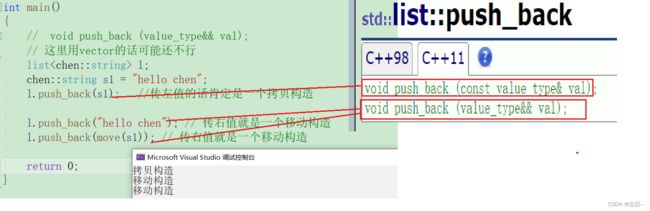
完美转发
模板中的&&都是万能引用。可以引用左值,也可以引用右值
当我们运行下面代码的时候,惊讶的发现进行第二次函数Fun()的时候都变成了左值。
这是因为,当我们为右值取别名后,会将右值存储到特定的位置,基本上就有了左值的属性
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
template<typename T>
void PerfectForward(T&& t)
{
Fun(t);
}
int main()
{
PerfectForward(10);
int a;
PerfectForward(a);
PerfectForward(std::move(a));
const int b = 8;
PerfectForward(b);
PerfectForward(std::move(b));
return 0;
}
如何去保证右值在传递过程中不出现意外呢?(被转化为左值),这样传参
Fun(std::forward<T>(t));
这样的实际作用:(懒的敲了)

新的类功能
类的默认成员函数有8个:构造函数,拷贝构造,赋值重载,析构,取地址重载,const取地址重载,移动构造,移动赋值。
移动构造:自己不写,并且析构函数 、拷贝构造、拷贝赋值都不写,编译器才会默认生成。对于内置类型成员会执行
逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
如果这里我们写了拷贝构造或者任意一个,那又想让编译器生成默认的移动构造,只需要用关键字default,它表示让编译器生成。
如果不想要某个默认成员函数,用delete就行。
class A
{
public:
A(int a = 0)
:_a(a)
{}
A(A&&) = default; //指定A生生成自己的移动构造
A(const A&) = delete; // 删除A的拷贝构造
~A();
private:
int _a;
};
移动赋值类似于移动构造,不在过多赘述
可变参数模板
//这里的Args就是模板参数包,args就是一个函数形参参数包
//Args...args声明一个参数包,可接受0个或者多个形参
template <class ... Args>
void ShowList(Args ... args)
{}
那么如何使用呢?
template <class T>
void ShowList(T val) //这里就相当于是一个参数的出口
{
cout << val << " " << endl;
}
template <class T, class ... Args>
void ShowList(T val,Args ... args)
{
//sizeof...(args)求的是形参个数,不是大小
cout << val << " ";
ShowList(args...); //相当于一种递归,辅助记忆:传参的时候...在后面,其余的都在中间
}
int main()
{
ShowList(1, 2, 3, 4);
ShowList(1, "12312312", "abdcb");
ShowList("haha");
return 0;
}
lambda表达式
先想想这样一个问题,我们是如何对自定义类型进行排序的呢?
class stu
{
public:
stu(string name, double score, int age)
:_name(name)
, _score(score)
, _age(age)
{}
string _name;
double _score;
int _age;
};
struct cmp_name
{
bool operator()(const stu& s1, const stu& s2)
{
return s1._name < s2._name; //小于是升序
}
};
struct cmp_score
{
bool operator()(const stu& s1, const stu& s2)
{
return s1._score < s2._score;
}
};
struct cmp_age
{
bool operator()(const stu& s1, const stu& s2)
{
return s1._age < s2._age;
}
};
int main()
{
vector<stu> v = { {"zhangsan",80.0,18}, {"lisi",70.0,20}, {"wangwu",90.0,19} };
sort(v.begin(), v.end(),cmp_name());
sort(v.begin(), v.end(), cmp_age());
sort(v.begin(), v.end(), cmp_score());
return 0;
}
人们开始觉得上面的写法太复杂了,每次为了实现一个algorithm算法,都要重新去写一个类,如果每次比较的逻辑不一样,
还要去实现多个类,特别是相同类的命名,这些都给编程者带来了极大的不便。所有lambda表达式应运而生
sort(v.begin(), v.end(), [](const stu& s1, const stu& s2)->bool
{
return s1._name < s2._name;
});
sort(v.begin(), v.end(), [](const stu& s1, const stu& s2)->bool
{
return s1._age < s2._age;
});
sort(v.begin(), v.end(), [](const stu& s1, const stu& s2)->bool
{
return s1._score < s2._score;
});
上述代码就是使用C++11中的lambda表达式来解决,可以看出lambda表达式实际是一个匿名函数。
关于lambda表达式的用法
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement
}
- lambda表达式各部分说明
[capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来
判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda
函数使用。
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以
连同()一起省略
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量
性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回
值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推
导。
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获
到的变量。
注意:
在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为
空。因此C++11中最简单的lambda函数为:[]{}; 该lambda函数不能做任何事情
如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()
只能用auto去推导类型
int main()
{
int a = 3, b = 5;
auto func1 = [] {return 3 + 2; };//这个由编译器去自动推导返回类型
cout << func1() << endl; //输出5
auto func2 = [](int x, int y)->int { return x + y; }; //传参,指明返回类型
cout << func2(10, 20) << endl; // 输出30
auto func3 = [](int& x, int& y) { swap(x, y); };
func3(a, b); //a,b的值交换
auto func4 = [=] {return a + b; }; //已传值的方式去捕捉父作用域的a和b
cout << func4() << endl;
return 0;
}
[var]:表示值传递方式捕捉变量var
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&var]:表示引用传递捕捉变量var
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
注意:
1,父作用域指包含lambda函数的语句块
b. 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量
[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
c. 捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
d. 在块作用域以外的lambda函数捕捉列表必须为空。
e. 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者
非局部变量都会导致编译报错。
f. lambda表达式之间不能相互赋值,即使看起来类型相同
包装器
int f(int a, int b)
{
return a + b;
}
struct Functor
{
public:
int operator() (int a, int b)
{
return a + b;
}
};
class Plus
{
public:
static int plusi(int a, int b)
{
return a + b;
}
double plusd(double a, double b)
{
return a + b;
}
};
int main()
{
//包装器 <>里面要指明返回类型和参数类型
function<int(int, int)> f1 = f; //包装函数指针
cout << f1(1, 2) << endl;
function<int(int, int)> f2 = Functor(); //包装函数对象
cout << f2(1, 2) << endl;
function<int(int, int)> f3 = [](int a, int b)->int //包装lambda表达式
{
return a + b;
};
cout << f3(1, 2) << endl;
function<int(int, int)> f4 = &Plus::plusi;
cout << f4(1, 2) << endl;
function<double(Plus,double, double)> f5 = &Plus::plusd; //传对象才可以调用,非静态成员函数
cout << f5(Plus(), 1.0, 2.0) << endl;
return 0;
}
包装器有什么作用呢???、
求这种逆波兰表达式 ,这里的case语句能把你写吐掉
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
for(auto& str : tokens)
{
if(str == "+" || str == "-" || str == "*" || str == "/")
{
int right = st.top();
st.pop();
int left = st.top();
st.pop();
switch(str[0])
{
case '+':
st.push(left+right);
break;
case '-':
st.push(left-right);
break;
case '*':
st.push(left*right);
break;
case '/':
st.push(left/right);
break;
}
}
else
{
// 1、atoi itoa
// 2、sprintf scanf
// 3、stoi to_string C++11
st.push(stoi(str));
}
}
return st.top();
}
};
要是有了包装器
class Solution
{
public:
int evalRPN(vector<string>& tokens)
{
stack<long long> st;
map<string,function<int(int,int)>> m = {
{"+",[](int a, int b)->int{return a + b;}},
{"-",[](int a, int b)->int{return a - b;}},
//防止相乘的情况出现溢出的情况
{"*",[](long long a, long long b)->long long{return a * b;}},
{"/",[](int a, int b)->int{return a / b;}},
};
for(const auto e : tokens)
{
if(e != "+" && e != "-"&& e != "*"&& e != "/" )
{
st.push(stoi(e));
}
else
{
int right = st.top();
st.pop();
int left = st.top();
st.pop();
st.push(m[e](left,right));
}
}
return st.top();
}
};
bind绑定
int f(int a, int b)
{
cout << a << endl;
cout << b << endl;
return 1;
}
struct Functor
{
public:
int operator() (int a, int b)
{
return a + b;
}
};
class Plus
{
public:
static int plusi(int a, int b)
{
return a + b;
}
double plusd(double a, double b)
{
return a + b;
}
};
int main()
{
//_1, _2表示绑定参数位置
function<int(int, int)> fun1 = bind(f, placeholders::_1, placeholders::_2);
fun1(1,2);
function<int(int, int)> fun2 = bind(f, placeholders::_2, placeholders::_1);
fun2(1, 2);
function<int(int, int)> fun3 = bind(Functor(), placeholders::_1, placeholders::_2);
cout << fun3(1, 2) << endl;
function<int(int, int)> fun4 = bind(&Plus::plusi,placeholders::_1, placeholders::_2);
cout << fun4(1, 2) << endl;
Plus ps;
function<double(double, double)> f5 = bind(&Plus::plusd,ps, placeholders::_1, placeholders::_2);
cout << f5(2.0f, 4.0f) << endl; //这最后一个和包装器的传法优点区别
return 0;
}