经典目标检测算法R-CNN,Fast R-CNN ,Faster R-CNN总结,附论文和代码地址
目录
前言
1.R-CNN
1.1提出背景
1.2网络结构
1.2.1候选区域(Region Proposal)
1.2.2卷积网络提取图像特征
1.2.3物体分类
1.2.4边界框回归(BoundingBox-Regression)
1.3训练步骤
1.3.1卷积网络预训练和微调
1.3.2训练SVM
1.3.3边界框回归
1.4测试步骤
1.5存在问题
2.Fast R-CNN
2.1针对问题和改进方法
2.2网络结构
2.2.1候选区域
2.2.2卷积网络提取特征
2.2.3ROI池化(Regions Of Interest Pooling)
2.2.4多任务损失函数(Multi-task loss)
2.3训练步骤
2.4测试步骤
2.5存在问题
3.Faster R-CNN
3.1针对问题和改进方法
3.2网络结构
3.3RPN(Region Proposal Network)
3.3.1锚(Achors)
3.3.2RPN操作流程
3.3.4损失函数
3.4训练步骤
3.5测试步骤
4.总结
前言
本文对R-CNN,Fast R-CNN和Faster R-CNN三种网络结构进行详细描述,并对三者的区别改进,优缺点进行总结。
论文地址:
R-CNN:https://arxiv.org/abs/1311.2524
Fast R-CNN:https://arxiv.org/abs/1504.08083
Faster R-CNN:https://arxiv.org/abs/1506.01497
代码地址:(非本人所写)
R-CNN:https://github.com/rbgirshick/rcnn
Fast R-CNN:https://github.com/rbgirshick/fast-rcnn
Faster R-CNN:https://github.com/rbgirshick/py-faster-rcnn
1.R-CNN
1.1提出背景
过去的十年中,在各种视觉识别任务上取得的进展在很大程度上是基于使用SIFT和HOG。然而,在2010-2012年中,使用传统方法在PASCAL VOC数据集上完成目标检测任务,其性能却一直提升缓慢。
作者分析原因认为:SIFT和HOG是块方向直方图,可以将其视为灵长类视觉通路的第一个皮层区域V1中的复杂细胞。但识别是发生在此下游的几个阶段的,所以需要多阶段分层的结构计算特征,为识别任务提供更多信息。
此时,在2012年ImageNet大规模视觉识别挑战赛中,Hinton及他的学生采用CNN特征获得了最高的图像识别精确度。于是,作者想到使用卷积网络处理目标检测任务。
1.2网络结构
R-CNN全称为Region with CNN features,用CNN提取出Region Proposal中的特征,然后进行物体分类和边界框回归。
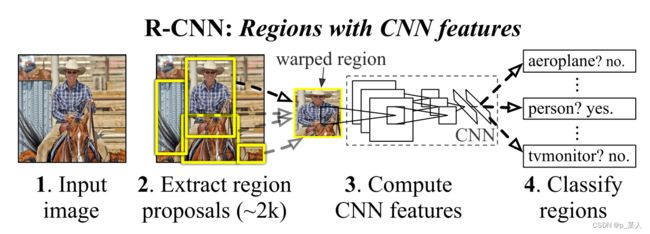
图一 R-CNN的网络结构
1.2.1候选区域(Region Proposal)
在用CNN提取图像的特征之前,作者首先用一种名为Selective Search的算法从图像中提取出了候选区域(Region Proposal)。这种算法出自论文《Selective search for object recognition》,主要步骤为:
1.使用《Efficient Graph-Based Image Segmentation》论文里的方法产生许多初始分割区域,效果如图1。
2.计算所有邻近区域之间的相似性(主要指一些低级特征,如:颜色,纹理等)。
3.将相似度比较高的区域合并到一起。
4.计算合并区域和临近区域的相似度。
之后重复步骤3和步骤4,生成候选区域的效果如图2。最终,生成2000个候选区域。

图二


图三 绿色框为标注的真实框
1.2.2卷积网络提取图像特征
在2014年R-CNN提出之前,AlexNet夺得了ImageNet竞赛的冠军,展现出了强大的图像特征提取能力。因此,R-CNN采用了AlexNet作为提取图像特征的主干网络。
AlexNet要求输入的图像大小为227x227,所以在将候选区域输入卷积网络之前,还需要先将这些候选区域的尺寸处理为227x227。由于R-CNN中没有使用softmax的方法进行分类,所以AlexNet中用于分类的全连接层已被去除,最终一个候选区域获取4096维的特征。由这2000个候选区域得到2000x4096的特征矩阵。
1.2.3物体分类
如今常用的物体分类方式为:卷积网络最后的全连接层输出一个长为N的向量(N为物体类别数目),对该向量进行Softmax操作,用得到的新向量各位置上的数值代表物体属于对应类别的概率。
R-CNN没有采用这种方式,而是对每一种类别训练了一个支持向量机(SVM)。原文作者用两种方法分别在VOC2007上进行训练,最终使用支持向量机比使用Softmax的表现要高出3.3%。
对于这种现象,原作者对此给出的解释是:
1)在网络进行微调时,此时的正例负例和训练SVM时的正例负例定义方法不同。微调时的正例不要求精准定位,而是按照交并比阈值定义的。
2)Softmax分类器是在随机抽样的负例上进行训练,而SVM是在严格的负例上训练的。这是由于卷积网络需要更多的样本训练,而SVM适合少量样本训练。
1.2.4边界框回归(BoundingBox-Regression)
这一步的目的是微调经过分类的候选区域,使其更加接近真实的物体边界。如图四所示,假定绿色是标注的真实框,红色是候选框。两者都将物体包含在内了,但显然红色框的定位不够准确,所以需要对红色框进行微调。

图四
边界框回归的目的就是寻找一种映射,使预测框更加接近真实框。在R-CNN中,使用可学习的四个参数实现了对候选框的微调,这四个参数为:![]() ,
,![]() ,
,![]() 和
和![]() 。
。
微调候选框的公式为(![]() 是预测框的长宽和中心点坐标,
是预测框的长宽和中心点坐标,![]() 是微调后的长宽和中心点坐标):
是微调后的长宽和中心点坐标):
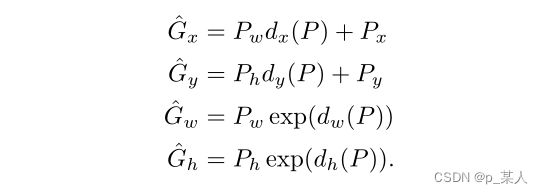
于是,这四个参数的回归目标也就可以由以下四个公式计算得到(![]() 是真实框的长宽和中心点坐标):
是真实框的长宽和中心点坐标):
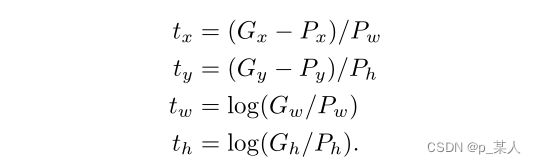
1.3训练步骤
1.3.1卷积网络预训练和微调
对于规模较小的数据集,如果直接用随机初始化的网络参数进行训练,训练的效果必然不会太好。所以,需要在规模更大的数据集上先进行预训练,然后在规模较小的数据集上进行微调。作者使用了在ImageNet ILSVC 2012上训练过的AlexNet权重作为网络的预训练模型。
之后要做的是,在VOC检测数据集上对这个预训练的模型进行参数上的微调,使其能够更加适应特定领域。这里微调时,使用的数据是从VOC数据集中每张图片上提取到的候选区域(Region Proposal)。
对VOC数据集中的每张图片使用Selective Search,得到候选区域。同时将AlexNet中用于分类1000个类别的全连接层替换为分类20个类别的全连接层(VOC数据集中有20个类别,不含背景)。再将候选区域和真实区域进行对比,计算IOU。如果IOU>0.5,则认为是正样本,否则,认为是负样本。
此外,一张图片中能被标注为正样本的候选区域远远少于被标注为负样本的候选区域。所以,为了防止卷积网络在迭代时,样本分布不均衡影响了网络性能。每次网络迭代更新时,都从中选取32个正样本和96个负样本作为一个mini-batch。最后,使用0.001的学习率和SGD梯度下降算法来进行训练。
在CNN经过微调之后,其中的权重参数就被固定不变,之后输入VOC训练数据集,Selective Search搜索出2000个候选区域后,输入进CNN提取特征,然后保存AlexNet的FC7层4096维的特征,以供后续的SVM训练分类使用。
1.3.2训练SVM
在SVM训练的过程中,只有IOU<0.3和IOU>0.7的样本才会参与训练,其余样本则全部被丢弃。
1.3.3边界框回归
边界框回归的训练过程即是用卷积神经网络提取出的特征,去预测四个参数![]() ,
,![]() ,
,![]() 和
和![]() 。将预测出的四个参数与1.2.4中提到的
。将预测出的四个参数与1.2.4中提到的 ,
,![]() ,
,![]() 和
和![]() 对比,计算出一个loss,然后训练。
对比,计算出一个loss,然后训练。
1.4测试步骤
测试时,R-CNN的执行步骤如下:
1.对于输入的图像,使用Selective Search生成2000个候选区域。
2.将候选区域调整为227x227,随后输入到CNN中,提取得到大小为2000x4096的特征矩阵。
3.将这个2000x4096的特征矩阵输入SVM中,获得2000x21的矩阵。每行的21个值代表该候选区域属于对应类别的概率(20个物体类别+背景),然后根据提前定好的阈值,筛选候选区域。
4.SVM筛选出的m个候选区域对应的特征向量可以表示为mx4096的矩阵,将此矩阵与边界框回归矩阵(4096x4)相乘,得到这m个候选区域精调所需的参数。
5.进行非极大值抑制,对这m个候选框进一步筛选,得到最终结果。
1.5存在问题
1.训练分为三个阶段,这种多阶段的训练方式不仅会影响最终的模型精度,也会使训练所需的时间变得更长。
2.训练和测试耗时较长。在一张图上提取2000个候选区域,在这2000个候选区域上进行了大量重复的卷积操作且每个候选区域都要单独计算一个特征向量,造成耗时较长。
3.占用磁盘空间大。每个候选区域的特征向量都要保存到磁盘空间中,留待后续步骤使用。
2.Fast R-CNN
2.1针对问题和改进方法
针对上述R-CNN中存在的三个问题,Fast-RCNN做出了一系列改进。主要改进如下:
1.用Softmax分类器替代SVM。
2.改进网络结构,建立两个输出层。这样网络就可以同时输出物体类别和边界框回归所需的参数。
3.使用了ROI池化操作和多任务损失函数帮助网络进行训练。
4.对整张图片进行卷积,而不再是对单个候选区域进行卷积。
如此,Fast-RCNN将提取特征,物体分类和边界框回归三个任务都放在一个网络中完成,一次训练就可以同时对整个网络进行更新,解决了R-CNN中多阶段训练带来的问题。同时,由于三个任务都放在一个网络中完成,所以不需要将每个候选区域的特征向量保存到磁盘空间中,解决了占用磁盘空间大的问题。在 Fast R-CNN中,不再对单个候选区域进行卷积,而是对整张图进行卷积。由此避免了大量重复的卷积操作,减少了耗时。
2.2网络结构
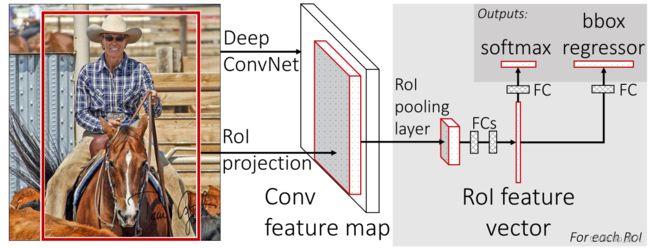
图五 Fast-RCNN网络结构
2.2.1候选区域
Fast R-CNN中筛选候选区域的办法和R-CNN中一样,仍是采用Selective Search算法。
2.2.2卷积网络提取特征
与R-CNN不同,Fast R-CNN的作者使用了VGG16网络提取图像特征。
2.2.3ROI池化(Regions Of Interest Pooling)
ROI池化的作用是针对不同大小的候选区域,从最后一层卷积层输出特征图中提取固定大小的特征图。由于全连接层的输入要求大小相同,所以不能直接将大小不同的候选区域映射到特征图,然后输入到全连接层,而是要进行尺度变换。
每个ROI都被定义为一个元组(r, c, h, w),其中(r,c)左上角坐标,(h,w)则指定了它的长宽。随后将从特征图上获得的h x w大小的区域分割,获得HxW个子区域(H和W是独立于任何特定RoI层的超参数,在VGG16中令H=W=7),每个子区域的大小就是(h/H,w/W)。最后在每个子区域内做最大池化,就得到了ROI池化的输出。
2.2.4多任务损失函数(Multi-task loss)
Fast R-CNN设计了两个输出层,将物体分类和边界框回归任务联合到一个网络中,那么为了实现两个任务的联合优化,就需要一个能够同时体现两个任务中预测值和真实值偏差的损失函数。
于是,Fast R-CNN的作者采用了多任务损失函数,具体公式如下:
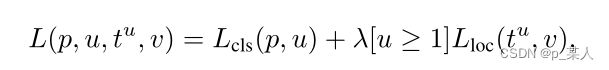
分类任务使用的是常见的交叉熵损失函数,回归任务使用的是SmoothL1Loss,公式如下:
![]()
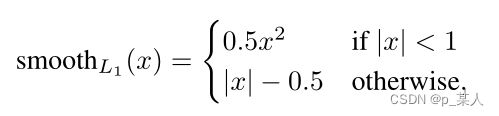
2.3训练步骤
1.采用ImageNet预训练好的VGG16模型。
2.由于在ImageNet上训练的VGG16模型和Fast R-CNN的网络结构并不一样,所以我们还要对预训练的模型进行处理,处理方法如下:
(1)将VGG16中的最后一层最大池化层替换为ROI池化层,这个ROI池化层的H和W参数由之后的全连接层大小决定,两者大小应该匹配(在VGG16中,H=W=7)。
(2)将VGG16中的最后一层全连接层替换为图五中的双输出层结构,一个全连接层加softmax,用于物体分类,一个全连接层加回归层,用于边界框回归。
(3)修改网络的输入,由单输入(图像)变为双输入(图像+这些图像的候选区域列表)
3.在调优训练时,每个mini-batch包含N张图像,对它们进行Selective Search算法后,采样出R个候选区域(也可以称为ROI),也就是每张图像有R/N个ROI。
4.将需要训练的图像和候选区域输入到网络中,最后一层卷积层的输出和候选区域一起输入到ROI池化层中,经过两个全连接层,输出长为4096的特征向量。之后这个特征向量同时输入到两个输出层,用于物体分类的输出层输出的是每个候选区域对于每个类别的得分(此处微调使用的是VOC数据集,所以一共有21个类别),用于边界框回归的输出层输出的是四个参数(详见1.2.4)。最后,由两者的输出计算得到Multi-task loss,进行网络的梯度反向传播即可。
2.4测试步骤
测试过程就非常简单了,将图像进行Selective Search算法,得到候选区域。之后将图像和候选区域一起输入到网络,得到物体类别和边界框回归的参数,根据分类的阈值留下需要的预测框,对预测框进行微调和极大值抑制(NMS),即可得到最终结果。
2.5存在问题
Fast R-CNN的缺点在于:
1)仍然使用无法用CPU加速的Selective Search算法,极大的减慢了算法的速度。
2)候选区域的生成和后续的网络是完全独立的两个步骤,彼此之间的不连贯性成为了制约算法性能的瓶颈。
3.Faster R-CNN
3.1针对问题和改进方法
Faser R-CNN针对上述的问题提出了改进方法如下:
1.设计了一个基于卷积的候选区域网络(Region Proposal Network,RPN),用来提取不同尺度的候选框,取代了Selective Search算法。
2.将RPN和Fast R-CNN糅合到同一个网络结构中,使提取候选框任务,物体分类和边界框回归任务共享特征卷积特征,整个训练或测试流程更加流畅。
3.2网络结构
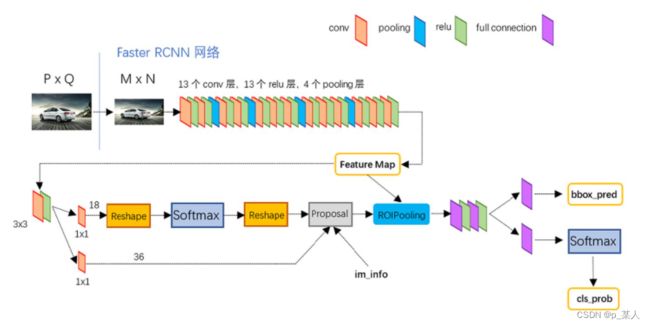
图六 Faster R-CNN网络结构图
从图六中可以看到,整个网络结构由两部分组成:RPN和Fast R-CNN。现在将它们划分开,如图七,红色框中的是上文中提到的Fast R-CNN的结构,绿色框中的是RPN的网络结构。Fast R-CNN的结构上文已经做了简单描述,所以下文中就主要描述RPN的结构。
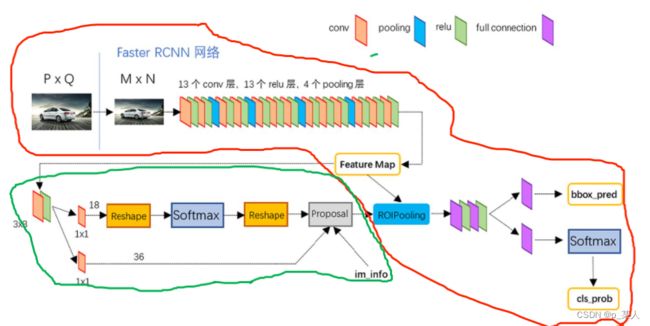
图七
3.3RPN(Region Proposal Network)
3.3.1锚(Achors)
RPN对输入进来的特征图进行滑窗操作,并对每一个滑窗生成了k个候选框和对应这些候选框框中或未框中物体的概率。这k个候选框都是基于固定的参考框经过微调得到的,k个候选框就代表有k个参考框。这些参考框称之为锚(Achors)。
对于每一个滑窗位置,锚的中心与滑窗的中心都是重合的。在原文中,Faster R-CNN的作者设计了九种不同大小和不同长宽比的锚,大小分别为128x128,256x256和512x512三种,长宽比分别为1:1,1:2和2:1三种。所以,如果输入特征图的长宽分别为W和H,则一共有W x H x k个锚。
3.3.2RPN操作流程
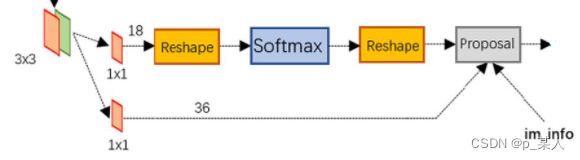
图八 RPN网络结构
可以看到图八中一共有两条分支。其中第一条分支用于分类,输入特征图(WxH)经过1x1x18的卷积核之后, 得到的是WxHx18的特征图。之所以要将此通道数设为18,是因为每个点都生成了九个锚,并且要将每个锚都分为前景和背景(即是否有物体存在,注意这里没有具体分出是哪类物体)。然后经过Reshape操作,将通道数压缩为9x2,经过softmax之后得到每个锚属于前景和背景的概率,再进行Reshape操作变换回来。
第二条分支则是将通道数设为36,从而输出每个锚进行微调得到候选框所需要的四个参数。
3.3.4损失函数
在每个锚中是否包含对象定义时,遵循以下原则:1)如果锚与真实框之间IOU>0.7,则认为锚中包含有对象。2)认为和真实框之间有最大IOU的锚中包含有对象。3)如果锚和真实框之间IOU<0.3,则认为不包含对象。4)若不属于以上三条,则丢弃,不参与训练。
训练RPN时使用以下的损失函数,其中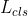 是分类任务的损失函数,使用的是交叉熵损失;
是分类任务的损失函数,使用的是交叉熵损失;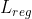 是边界框回归任务的损失函数,其中
是边界框回归任务的损失函数,其中![]() ,R是SmoothL1Loss。
,R是SmoothL1Loss。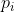 是锚中包含物体的概率,如果锚为正,地面真实标签
是锚中包含物体的概率,如果锚为正,地面真实标签![]() 为1,否则为0。
为1,否则为0。![]() 是对锚进行微调的四个参数,
是对锚进行微调的四个参数,![]() 是由锚到真实框所需要的微调参数。
是由锚到真实框所需要的微调参数。![]() 表示只有当锚的真实标签为正时,回归损失才会被激活。Ncls和Nreg对两项进行归一化,并用平衡参数λ进行加权。
表示只有当锚的真实标签为正时,回归损失才会被激活。Ncls和Nreg对两项进行归一化,并用平衡参数λ进行加权。
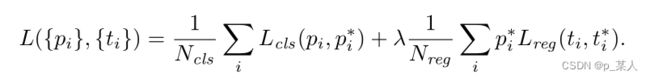
3.4训练步骤
在训练阶段,Faster R-CNN的训练采用了四步训练:
1.训练RPN,使用ImageNet的预训练模型初始化网络,端到端微调RPN,用于生成候选框。(注意:在训练时,经过NMS,RPN最终会留下大约2000个候选框;在测试时,则留下300个候选框。)
2.训练Fast R-CNN,使用相同的预训练模型初始化网络,锁住第1步训练好的RPN权重,使用第一步生成的候选框进行训练。此时RPN和Fast R-CNN还没有共享卷积层。
3.使用检测器网络初始化RPN训练,但是这一步修复了共享的conv层,只对RPN特有的层进行了微调。现在RPN和Fast R-CNN共享卷积层。
4.调优Fast R-CNN,固定第三步训练好的共享卷积层,进一步微调Fast R-CNN中的全连接层。
3.5测试步骤
终于接近尾声了,相比较于训练而言,测试步骤就显得简单了很多:
1.将图像输入卷积网络提取特征。
2.将提取出的特征图输入RPN中,RPN输出大约300个候选框。
3.经过ROI池化,由两个输出层分别输出每个框的各类别概率和微调参数。
4.根据微调参数,微调各候选框的位置;根据每个框的各类别概率和阈值进行筛选。
5.经过极大值抑制(NMS),得到最终输出,画出预测框。
4.总结
至此,我对R-CNN,Fast R-CNN和Faster R-CNN做了详细的描述。如有错误或表述不当的地方,欢迎大家批评指正。