《动手学深度学习+PyTorch》3.2线性回归的从零开始实现 学习笔记
文章目录
- 一、d2lzh_pytorch包
- 二、生成数据集
- 二、画出数据集的散点图
- 三、读取数据
- 四、模型初始化及训练
- 五、训练结果
- 总结
一、d2lzh_pytorch包
《动手学深度学习+PyTorch》配套的GitHub中配套的d2lzh_pytorch包加入IDLE的第三方库中。
二、生成数据集
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs, dtype=torch.float32)
labels = true_w[0] * features[:,0] + true_w[1] * features[:,1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01,size=labels.size()),
dtype=torch.float32)
features = torch.randn(num_examples, num_inputs, dtype=torch.float32)
返回一个符合均值为0,方差为1的正态分布(标准正态分布)中填充随机数的张量
num_examples为产生两组数据,num_inputs为产生每组1000个数据,dtype为产生的数据类型
np.random.normal(loc, scale, size)
从正态(高斯)分布中抽取随机样本。
loc为分布的均值(中心),scale分布的标准差(宽度),size为输出值的维度。
torch.tensor(data, dtype=None)
可以从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的torch.LongTensor,torch.FloatTensor,torch.DoubleTensor。
其中data处可以是:list, tuple, array, scalar等类型。
二、画出数据集的散点图
set_figsize()
plt.scatter(features[:,1].numpy(), labels.numpy(), 1)
关于set_figsize()的定义 (以下代码在d2lzh_pytorch包中已包含)
def use_svg_display():
# 用矢量图显示
display.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
display.set_matplotlib_formats('svg')
设置图片类型,多种类型可以选择 ‘png’, ‘retina’, ‘jpeg’, ‘svg’, ‘pdf’.
plt.rcParams['figure.figsize'] = figsize
设置图片参数
plt.rcParams['figure.dpi'] = 300 #分辨率 plt.rcParams['figure.figsize'] = (10, 10) #图像显示大小 plt.rcParams['image.interpolation'] = 'nearest' #最近邻差值: 像素为正方形 Interpolation/resampling即插值,是一种图像处理方法,它可以为数码图像增加或减少象素的数目。 plt.rcParams['image.cmap'] = 'gray' #使用灰度输出而不是彩色输出;
三、读取数据
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, y)
break
关于data_iter(batch_size, features, labels)的定义 (以下代码在d2lzh_pytorch包中已包含)
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # 最后一次可能不足一个batch
yield features.index_select(0, j), labels.index_select(0, j)
每次返回batch_size(批量大小)个随机样本的特征和标签
四、模型初始化及训练
w = torch.tensor(np.random.normal(0,0.01,(num_inputs,1)),dtype=torch.float32)
b = torch.zeros(1,dtype=torch.float32)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
lr =0.03 #定义步长
num_epochs = 3 #设置迭代周期数
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = squared_loss(linreg(X, w, b),y).sum()
l.backward()
sgd([w, b], lr, batch_size)
w.grad.data.zero_()
b.grad.data.zero_()
train_l = squared_loss(linreg(features, w, b), labels)
print('epoch: %d, loss: %f'%(epoch + 1, train_l.mean().item()))
w = torch.tensor(np.random.normal(0,0.01,(num_inputs,1)),dtype=torch.float32)
将权重初始化成均值为0、标准差为0.01的正态随机数。
b = torch.zeros(1,dtype=torch.float32)
偏差则初始化成0。
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
之后的模型训练中,需要对这些参数求梯度来迭代参数的值,因此我们要让它们的
requires_grad=True。
该方法能够决定自动梯度机制是否需要为当前这个张量计算记录运算操作.
该方法能对当前张量的requires_grad属性进行原地操作.返回这个当前张量.
主要使用场景是告诉自动梯度机制开始记录追踪这个张量tensor的操作.如果张量tensor的属性requires_grad=False(因为这个张量是从DataLoader中获得到的,或者这个张量需要预处理或初始化),该张量执行tensor.requires_grad_()方法将会让自动梯度autograd开始跟踪并记录这个张量上的运算操作.
没搞懂什么意思,下次一定
linreg(X, w, b)
线性回归的矢量计算表达式的实现。我们使用mm函数做矩阵乘法,即两个矩阵相乘。
关于linreg()的定义: (以下代码在d2lzh_pytorch包中已包含)
def linreg(X, w, b):
return torch.mm(X, w) + b
squared_loss(y_hat, y)
损失函数
def squared_loss(y_hat, y): # 本函数已保存在d2lzh_pytorch包中方便以后使用
# 注意这里返回的是向量, 另外, pytorch里的MSELoss并没有除以 2
return (y_hat - y.view(y_hat.size())) ** 2 / 2
l.backward()
如果需要计算导数,可以在Tensor上调用.backward()。
- 如果Tensor是一个标量(即它包含一个元素的数据),则不需要为backward()指定任何参数
- 但是如果它有更多的元素,则需要指定一个gradient参数,它是形状匹配的张量。
sgd([w, b], lr, batch_size)
小批量随机梯度下降算法。它通过不断迭代模型参数来优化损失函数。这里自动求梯度模块计算得来的梯度是一个批量样本的梯度和。我们将它除以批量大小来得到平均值。
关于sgd()的定义: (以下代码在d2lzh_pytorch包中已包含)
def sgd(params, lr, batch_size):
# 为了和原书保持一致,这里除以了batch_size,但是应该是不用除的,因为一般用PyTorch计算loss时就默认已经
# 沿batch维求了平均了。
for param in params:
param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data
w.grad.data.zero_()
b.grad.data.zero_()
梯度清零
五、训练结果
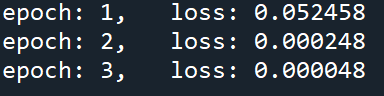
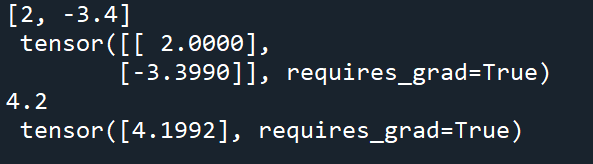
运行以下代码对比学习值和真实值
print(true_w, '\n', w)
print(true_b, '\n', b)
总结
《动手学深度学习+PyTorch》3.2线性回归的从零开始实现