python爬取steam250游戏详细信息和下载游戏介绍视频
爬取网页地址
https://steam250.com/2020
网页详情
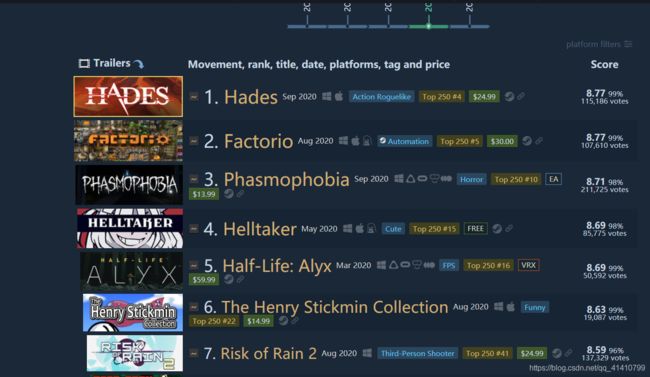
爬取的信息
- 游戏名称
- 游戏图片地址
- 游戏发行日期
- 游戏分类
- 游戏评分
- 游戏描述
- 游戏介绍视频
这里游戏描述需要点击单个游戏介绍界面才能看到

游戏视频则需要点击游戏图片才能查看
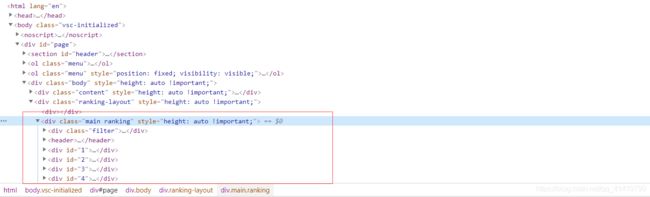
找到爬取数据所属的html元素
爬取思路
游戏名称 游戏图片地址 游戏发行日期 游戏分类 游戏评分这些属性可以通过抓取指定html块可以拿到,游戏详情的话可以通过两个思路来实现,一个是通过爬虫爬取这些游戏详情的地址,之后访问这些地址,另一种是编写脚本点击跳转至游戏详情页面,之后再跳回主界面,这里我选用了第二种方法,同样游戏视频我也是编写脚本写的
代码
这里我只爬取了前30名游戏信息,太多了会封ip(主要是由于下载视频)
1.启动webdriver,并获取html源码
def openFireFoxDiver():
url = "https://steam250.com/2020"
driver = webdriver.Firefox()
driver.get(url)
time.sleep(5)
html_page = driver.page_source.encode('utf-8') # 取得网页的源代码
return [html_page,driver];
2.保存html源码
这里我怕突然有一天网站关闭了我先备份一波源码
# path是存放地址
def saveHtmlCode(html,path):
file = open(path, "wb")
file.write(html)
3.获取游戏详情
def getsteam150Info(path,driver):
hot_game_list = []
html = EpicGamePrice.getHtmlCode(path)
html.decode();
html_page_soup = BeautifulSoup(html, 'html.parser')
num = 1;
succ = 0;
game_nameAndMp4 = {'name': [], 'mp4': []}
while succ<30:
# 获取每个游戏 id
gameInfo = html_page_soup.find('div', id=str(num))
game_a = gameInfo.find('span',class_ ='title').find('a')
game_name = moveHeadAndTailSpace(game_a.get_text()).replace(":","");
print(game_name)
tb_name = 'time_task_tb_game'
count = CollectDataToMysql.select_game_count(game_name,tb_name)
if(count>0):
[game_date,game_catagory,game_rate] = getGameInfo(gameInfo)
# 找到进入游戏详情页面
div_id = driver.find_element_by_id(str(num));
div_id.find_elements_by_class_name("title")[0].click()
time.sleep(5)
#游戏详细信息
game_descr = moveHeadAndTailSpace(driver.find_elements_by_class_name("blurb")[0].text);
#获取游戏图片
game_logo = driver.find_elements_by_class_name("logo")[0];
game_img = game_logo.find_elements_by_tag_name("img")[0].get_attribute('src')
#print(game_img)
#返回首页
driver.back()
game_mp4_src = get_mp4(driver,num)
game_nameAndMp4['name'].append(game_name);
game_nameAndMp4['mp4'].append(game_mp4_src);
#加入热门游戏列表
hot_game_list.append([game_name,game_date,game_catagory,game_rate,game_descr,game_img])
succ+=1;
num+=1;
write_to_excel(hot_game_list,'./gameInfo_csv/hot_game.csv')
CollectDataToMysql.save_hot_game_to_mysql(hot_game_list)
print(game_nameAndMp4)
for i in range(0,len(game_nameAndMp4['name'])):
print(game_nameAndMp4['name'][i]+" "+game_nameAndMp4['mp4'][i]);
download_videofile(game_nameAndMp4)
(1)因为我之前爬取过steam一些游戏信息,所以我想把这些游戏信息关联起来,所以我在获取单个游戏名称之后先在游戏表中查找是否有这个游戏,没有则跳过这个游戏
也就是下面这个函数
#select 一共有几条游戏
def select_game_count(game_name,tb_name):
db = connectMysql()
cur = db.cursor()
sql = "SELECT COUNT(*) FROM %s where game_name = '%s';" %(tb_name,game_name)
cur.execute(sql)
result = cur.fetchone()
#print(result[0])
return result[0];
(2) 获取游戏的一些属性我用函数封装起来了
#获取热门游戏详细信息
def getGameInfo(gameInfo):
game_date = moveHeadAndTailSpace(gameInfo.find('span', class_='date').get_text());
game_catagory = moveHeadAndTailSpace(gameInfo.find('a',class_ = 'genre').get_text());
game_rate = moveHeadAndTailSpace(gameInfo.find('span',class_ = 'score').get_text());
print(game_date+" "+game_catagory+" "+game_rate)
return [game_date,game_catagory,game_rate]
(3) 我把爬取的游戏信息存入了一个csv表中
def write_to_excel(game_list,path):
file = open(path,'w',encoding='utf-8-sig')
csv_writer = csv.writer(file)
csv_writer.writerow(["game_name", "game_date", "game_catagory","game_rate","game_descr","game_img"])
for i in range(0,len(game_list)):
game = game_list[i];
csv_writer.writerow([game[0], game[1], game[2],game[3],game[4],game[5]])
file.close()
(4) 下载游戏视频
我是将下载的视频放到了磁盘中
#下载视频文件
def download_videofile(game_nameAndMp4_dic):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
root = './hot_game_mp41/'
for i in range (0,len(game_nameAndMp4_dic['name'])):
file_name = game_nameAndMp4_dic['name'][i]+".mp4"
print("文件下载:%s" % game_nameAndMp4_dic['name'][i])
r = requests.get(game_nameAndMp4_dic['mp4'][i], stream=True,headers=headers).iter_content(chunk_size=1024 * 1024)
with open(root + file_name, 'wb') as f:
for chunk in r:
if chunk:
f.write(chunk)
print("%s 下载完成!\n" % file_name)
r.close()
time.sleep(60)
print("所有视频下载完成!")
return
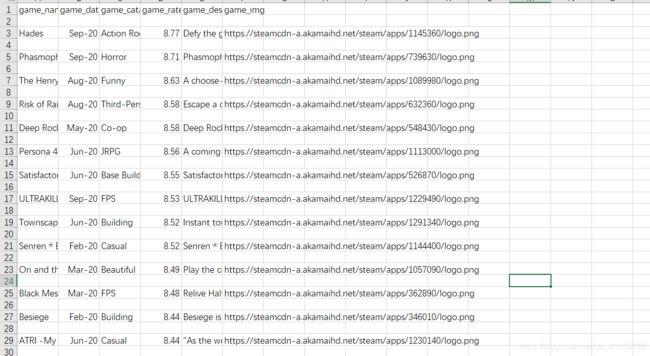
爬取结果