Python3 + BeautifulSoup 爬取Steam热销商品数据
这次用了BeautifulSoup库来爬取Steam的热销商品,BeautifulSoup更侧重的是从页面的结构解析,
根据标签元素等来爬取数据,这次遇到两个问题:
1.Steam热销商品列表经常有重复的,所以我建了一个列表,把爬到的数据存进去,每次爬的时候都校验跟列表里有没有重复,有的话就跳过,防止重复爬取。
2.我需要同时遍历两个表,找到了zip()函数解决方案,下面简单介绍一下。
zip()
大家看下面的实例应该就能明白。
xs = ['我是','你是','他是']
ys = ['第一','第二','第三']
for x, y in zip(xs,ys):
print(x+y)
输出结果如下:
我是第一
你是第二
他是第三
下面是完整爬虫代码,使用的库请自行安装不另做教学:
from bs4 import BeautifulSoup
import xlwt,os,time,requests
page = 1 #起始页数
total_pages = 3 #总页数,爬10页请设定为11
count = 1 #每抓到一次游戏名称增加一次,用来排序
pool=[] #每次抓到的游戏名称都会放进pool列表里,用来去重
document = 'Steam_GameTopSellers' #设定爬取的数据存的excel的档案名称
wb = xlwt.Workbook() #创建excel
ws = wb.add_sheet("TopSellers") #在excel新增一个sheet页
ws.write(0,0,'#')#三个参数,1:第几行,2:第几列,3:输入什么值
ws.write(0,1,'Game Title') #在excel第一行第二列先行写入'Game Title'
ws.write(0,2,'Released Date') #在excel第一行第三列先行写入'Released Date'
root = os.getcwd() #获取当前工作路径
date = time.strftime('%Y%m%d',time.localtime(time.time())) #获取当前日期 格式为yyyymmdd
while page<total_pages:
url = 'https://store.steampowered.com/search/?tags=597&filter=topsellers&page=%s' % str(page) #设定url,变量控制页数
r = requests.session()
res = r.get(url).text
soup = BeautifulSoup(res,"html.parser")
game_names = soup.find_all('span',attrs={'class':'title'}) # 遍历所有span标签,且class属性值为'title' 即当前页面所有游戏名称
released_dates = soup.find_all('div',attrs={'class':'col search_released responsive_secondrow'}) #当前页面所有发行日期
for game_name, released_date in zip(game_names,released_dates): #同时遍历连个列表的方法 for x,y in zip(xs,ys):
if game_name.string in pool: #如果爬到的数据在我的pool列表里存在的话就跳过,反之继续爬
continue
else:
print('%s .GameName:%s Released on:%s' % (count,game_name.string,released_date.string)) #打印给自己看的
pool.append(game_name.string) #把爬到的数据增加到pool列表里
ws.write(count,0,count) #往excel写入编号
ws.write(count,1,game_name.string) #往excel写入游戏名称
ws.write(count,2,released_date.string) #往excel写入发行日期
count += 1 #每遍历一次 count 变量 +1 ,用来排序写入excel里的顺序
rate = page / (total_pages - 1)
print('--------------------------第%s页爬取完成--------------------已完成: %.2f%%' % (str(page),(rate * 100)))
page += 1
wb.save('%s%s.xls' % (document,date)) #保存excel
print('--------------------------爬取完成--------------------------')
print('所有数据已存至:%s\%s%s.xls' % (root,document,date))
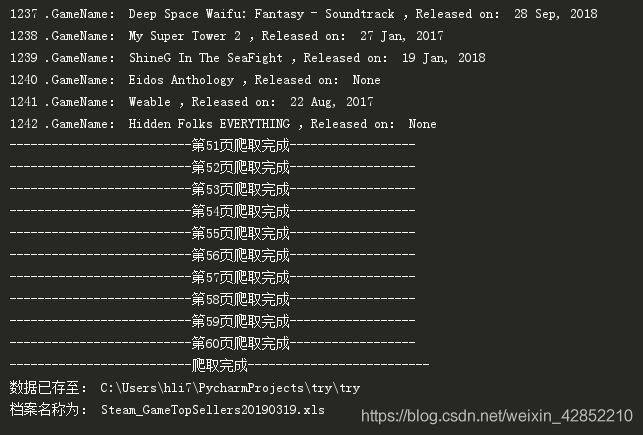
爬取结果(一共爬取1242条数据,51页~60页都是重复的):
结语:
这steam真是。。。后十页就是重复的,我一开始以为是有什么防爬机制,
后来在实际页面检查确实有重复的情况。