[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第1张图片](http://img.e-com-net.com/image/info8/e0535a4308c04dbb948047da06e3d538.jpg)
paper:https://openaccess.thecvf.com/content/CVPR2021/papers/Fan_Rethinking_BiSeNet_for_Real-Time_Semantic_Segmentation_CVPR_2021_paper.pdf
code:
https://github.com/MichaelFan01/STDC-Seg
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第2张图片](http://img.e-com-net.com/image/info8/e2c9e8bdc92b4f5490a94f3452cfa538.jpg)
目录
一. 动机
二. 贡献
三、相关工作
四、方法
1、编码网络
2、解码器
五、实验
1、消融实验
2、对比实验
一. 动机
双流实时分割网络BiSeNet添加额外的路径来编码空间信息是耗时的,并且由于任务特定设计(task-specific design)的不足,从预训练任务(例如图像分类)中借用的主干网络可能对图像分割效率低下。
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第3张图片](http://img.e-com-net.com/image/info8/287187f681484171b5bf18679f53caf3.jpg) (a) BiSeNet 使用额外的Spatial Path来编码空间信息。
(a) BiSeNet 使用额外的Spatial Path来编码空间信息。
(b) Ours 细节指导(Detail Guidance)模块在低级特征中编码空间信息,无需额外的耗时路径。
二. 贡献
1、设计了一个短时密集连接(Short-Term Dense Concatenate,STDC)模块来提取具有可扩展感受野和多尺度信息的深层特征。
2、提出了一个细节聚合(Detail Aggregation)模块来学习解码器,从而在低级层中更精确地保留空间细节。(Train only)
3、在Cityscapes测试集上,STDC1-Seg50取得71.9% mIoU,250.4 FPS;STDC2-Seg75取得76.8% mIoU,97.0 FPS。
三、相关工作
1、高效的网络设计: 降低模型参数(SqueezeNet),减少推理阶段 FLOPs(MobileNetV1),出色的性能(ResNet),降低计算成本同时保持可比的准确性(MobileNet V2、ShuffleNet )。
专门为图像分类任务设计的,它们对语义分割应用程序的扩展应该仔细调整。
2、通用语义分割:传统分割算法(阈值选择、超像素)、深度学习算法(FCN、Deeplabv3、SegNet、PSPNet)。
由于高分辨率特征和复杂的网络连接,大多数方法需要大量的计算成本。
3、实时语义分割:轻量级主干(DFANet,DFNet等)、多分支架构(ICNet,BiSeNetV1,BiSeNetV2)。
四、方法
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第4张图片](http://img.e-com-net.com/image/info8/2891e8d879514d14b5113655d2171314.jpg) 网络架构
网络架构
使用预训练的STDC作为编码器的骨干网络,采用 BiSeNet的上下文路径来编码上下文信息。
1、编码网络
1.1 短时密集连接(Short-Term Dense Concatenate,STDC)模块
在图像分类任务中,在更高层中使用更多通道是一种常见的做法。 但是在语义分割任务中,我们专注于可扩展的感受野和多尺度信息。低层需要足够的通道来编码感受野小的更细粒度的信息,而感受野大的高层更注重高层信息的归纳,与低层设置相同的通道可能会导致信息冗余 。
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第5张图片](http://img.e-com-net.com/image/info8/7a045d9d14734cb7bba03b2f39402267.jpg) (a)STDC 网络,(b)和 (c)STDC 模块
(a)STDC 网络,(b)和 (c)STDC 模块
STDC网络由除输入层和预测层外的6个阶段组成。通常,第 1-5 阶段分别以步长2对输入进行空间分辨率下采样,第 6 阶段通过一个 ConvX、一个全局平均池化层和两个全连接层输出预测。
阶段1和2通常被视为外观特征提取的低级层。为了追求效率,我们在第一阶段和第二阶段只使用一个卷积块,根据我们的经验证明已经足够了。
阶段 3、4和5 中 STDC 模块的数量在我们的网络中进行了仔细调整。在这些阶段中,每个阶段的第一个 STDC 模块以 2 的步幅对空间分辨率进行下采样。每个阶段中的后续 STDC 模块保持空间分辨率不变。
我们将各阶段的输出通道数表示为![]() ,其中
,其中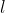 是阶段索引。在实践中凭经验将
是阶段索引。在实践中凭经验将![]() 设置为 1024,并仔细调整其余阶段的通道数,直到在精度和效率之间达到良好的平衡。由于网络主要由 Short-Term Dense Concatenate 模块组成,因此我们称我们的网络为 STDC 网络。
设置为 1024,并仔细调整其余阶段的通道数,直到在精度和效率之间达到良好的平衡。由于网络主要由 Short-Term Dense Concatenate 模块组成,因此我们称我们的网络为 STDC 网络。
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第6张图片](http://img.e-com-net.com/image/info8/f8b64bc71d914eb59ee304c17a5e61d9.jpg) STDC网络结构
STDC网络结构
STDC1 代码:
# STDC1Net
class STDCNet813(nn.Module):
def __init__(self, base=64, layers=[2,2,2], block_num=4, type="cat", num_classes=1000, dropout=0.20, pretrain_model='', use_conv_last=False):
super(STDCNet813, self).__init__()
if type == "cat":
block = CatBottleneck
elif type == "add":
block = AddBottleneck
self.use_conv_last = use_conv_last
self.features = self._make_layers(base, layers, block_num, block)
self.conv_last = ConvX(base*16, max(1024, base*16), 1, 1)
self.gap = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(max(1024, base*16), max(1024, base*16), bias=False)
self.bn = nn.BatchNorm1d(max(1024, base*16))
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(p=dropout)
self.linear = nn.Linear(max(1024, base*16), num_classes, bias=False)
self.x2 = nn.Sequential(self.features[:1])
self.x4 = nn.Sequential(self.features[1:2])
self.x8 = nn.Sequential(self.features[2:4])
self.x16 = nn.Sequential(self.features[4:6])
self.x32 = nn.Sequential(self.features[6:])
if pretrain_model:
print('use pretrain model {}'.format(pretrain_model))
self.init_weight(pretrain_model)
else:
self.init_params()
def init_weight(self, pretrain_model):
state_dict = torch.load(pretrain_model)["state_dict"]
self_state_dict = self.state_dict()
for k, v in state_dict.items():
self_state_dict.update({k: v})
self.load_state_dict(self_state_dict)
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def _make_layers(self, base, layers, block_num, block):
features = []
features += [ConvX(3, base//2, 3, 2)]
features += [ConvX(base//2, base, 3, 2)]
for i, layer in enumerate(layers):
for j in range(layer):
if i == 0 and j == 0:
features.append(block(base, base*4, block_num, 2))
elif j == 0:
features.append(block(base*int(math.pow(2,i+1)), base*int(math.pow(2,i+2)), block_num, 2))
else:
features.append(block(base*int(math.pow(2,i+2)), base*int(math.pow(2,i+2)), block_num, 1))
return nn.Sequential(*features)
def forward(self, x):
feat2 = self.x2(x)
feat4 = self.x4(feat2)
feat8 = self.x8(feat4)
feat16 = self.x16(feat8)
feat32 = self.x32(feat16)
if self.use_conv_last:
feat32 = self.conv_last(feat32)
return feat2, feat4, feat8, feat16, feat32
def forward_impl(self, x):
out = self.features(x)
out = self.conv_last(out).pow(2)
out = self.gap(out).flatten(1)
out = self.fc(out)
# out = self.bn(out)
out = self.relu(out)
# out = self.relu(self.bn(self.fc(out)))
out = self.dropout(out)
out = self.linear(out)
return out
2、解码器
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第7张图片](http://img.e-com-net.com/image/info8/ce9d4b5c492045bb9c164bca5795c366.jpg)
图5(b)中可视化了BiSeNet 空间路径的特征。与图(c)具有相同下采样率的主干的低级层(第 3 阶段)相比,空间路径可以编码更多的空间细节,例如边界、角点。基于这一观察,我们提出了一个细节指导模块(Detail Aggregation Module)来指导低层以单流方式学习空间信息,将细节预测建模为二元分割任务。
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第8张图片](http://img.e-com-net.com/image/info8/cbab9cc363584053add4d676fc6b8c34.jpg) 细节聚合模块
细节聚合模块
通过细节聚合模块(Detail Aggregation Module)从语义分割 ground truth 生成二进制细节 ground-truth。如图(c)中蓝色虚线框所示, 该操作可以通过名为拉普拉斯核的二维卷积核和可训练的 1×1 卷积来执行。使用图 (e) 中所示的拉普拉斯算子来生成具有不同步长的细节特征图,以获得多尺度细节信息。 然后将细节特征图上采样到原始大小,并将其与可训练的 1 × 1 卷积融合以进行动态重新加权。 最后,采用阈值 0.1 将预测的细节转换为具有边界和角点信息的最终二进制细节ground truth。
阶段3中插入Detail Head以生成细节特征图。使用细节ground-truth作为细节特征图的指导,引导低层学习空间细节的特征。具有细节指导的特征图可以编码比原阶段3特征图中的结果更多的空间细节。
Detail Loss
由于细节像素的数量远少于非细节像素,细节预测是一个类不平衡问题。 由于加权交叉熵总是导致粗略的结果,我们采用binary cross-entropy loss和dice loss来联合优化细节学习。dice loss衡量预测图和ground-truth之间的重叠。 此外,它对前景/背景像素的数量不敏感,这意味着它可以缓解类不平衡问题。所以对于高度为H,宽度为W的预测细节图,细节损失![]() 的公式如下:
的公式如下:
![]()
![]() 表示binary cross-entropy loss,
表示binary cross-entropy loss,![]() 表示dice loss。
表示dice loss。
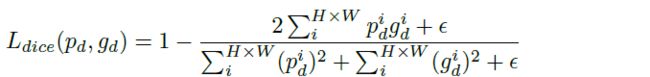
补充:
Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度,取值范围在[0,1]:
![]()
dice Loss:
![]()
因为dice loss是一个区域相关的loss,区域相关的意思是,当前像素的loss不光和当前像素的预测值相关,和其他点的值也相关。 dice loss的求交的形式可以理解为mask掩码操作,因此不管图片有多大,固定大小的正样本的区域计算的loss是一样的,对网络起到的监督贡献不会随着图片的大小而变化。训练更倾向于挖掘前景区域,正负样本不平衡的情况就是前景占比较小。而ce loss 会公平处理正负样本,当出现正样本占比较小时,就会被更多的负样本淹没。
Detail Aggregation 代码:
class DetailAggregateLoss(nn.Module):
def __init__(self, *args, **kwargs):
super(DetailAggregateLoss, self).__init__()
self.laplacian_kernel = torch.tensor(
[-1, -1, -1, -1, 8, -1, -1, -1, -1],
dtype=torch.float32).reshape(1, 1, 3, 3).requires_grad_(False).type(torch.cuda.FloatTensor)
self.fuse_kernel = torch.nn.Parameter(torch.tensor([[6./10], [3./10], [1./10]],
dtype=torch.float32).reshape(1, 3, 1, 1).type(torch.cuda.FloatTensor))
def forward(self, boundary_logits, gtmasks):
# boundary_logits = boundary_logits.unsqueeze(1)
boundary_targets = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, padding=1)
boundary_targets = boundary_targets.clamp(min=0)
boundary_targets[boundary_targets > 0.1] = 1
boundary_targets[boundary_targets <= 0.1] = 0
boundary_targets_x2 = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, stride=2, padding=1)
boundary_targets_x2 = boundary_targets_x2.clamp(min=0)
boundary_targets_x4 = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, stride=4, padding=1)
boundary_targets_x4 = boundary_targets_x4.clamp(min=0)
boundary_targets_x8 = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, stride=8, padding=1)
boundary_targets_x8 = boundary_targets_x8.clamp(min=0)
boundary_targets_x8_up = F.interpolate(boundary_targets_x8, boundary_targets.shape[2:], mode='nearest')
boundary_targets_x4_up = F.interpolate(boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')
boundary_targets_x2_up = F.interpolate(boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')
boundary_targets_x2_up[boundary_targets_x2_up > 0.1] = 1
boundary_targets_x2_up[boundary_targets_x2_up <= 0.1] = 0
boundary_targets_x4_up[boundary_targets_x4_up > 0.1] = 1
boundary_targets_x4_up[boundary_targets_x4_up <= 0.1] = 0
boundary_targets_x8_up[boundary_targets_x8_up > 0.1] = 1
boundary_targets_x8_up[boundary_targets_x8_up <= 0.1] = 0
boudary_targets_pyramids = torch.stack((boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up), dim=1)
boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)
boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids, self.fuse_kernel)
boudary_targets_pyramid[boudary_targets_pyramid > 0.1] = 1
boudary_targets_pyramid[boudary_targets_pyramid <= 0.1] = 0
if boundary_logits.shape[-1] != boundary_targets.shape[-1]:
boundary_logits = F.interpolate(
boundary_logits, boundary_targets.shape[2:], mode='bilinear', align_corners=True)
bce_loss = F.binary_cross_entropy_with_logits(boundary_logits, boudary_targets_pyramid)
dice_loss = dice_loss_func(torch.sigmoid(boundary_logits), boudary_targets_pyramid)
return bce_loss, dice_loss
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
nowd_params += list(module.parameters())
return nowd_params五、实验
dataset:ImageNet、Cityscapes和CamVid
classification evaluation:top-1 accuracy
segmentation evaluation:mean of class-wise intersection over union(mIoU)和Frames Per Second (FPS)
1、消融实验
1.1 Effectiveness of STDC Module
给定输入通道维度M和输出通道维度N,计算STDC模型的参数量:
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第9张图片](http://img.e-com-net.com/image/info8/18b75a5bf0b744bb9a44f0dad7819c9e.jpg)
如公式3所示,STDC 模块的参数数量主要由预定义的输入和输出通道维度决定,而块的数量对参数大小的影响较小。 特别是当n达到最大值时,STDC模块的参数个数几乎保持不变,仅由M和N决定。
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第10张图片](http://img.e-com-net.com/image/info8/7dddfef54bbc4de1a737a39f6157dea0.jpg)
调整了 STDC2 中 STDC 模块的块数,结果呈现于图 7 。根据公式 3,随着组数的增加,FLOPs 明显减少。 最好的表现是4块。 更多块的好处变得非常小,更深的网络不利于并行计算和 FPS。 因此,在本文中将STDC1 和 STDC2 中的块号设置为 4。
1.2 Effectiveness of Our backbone
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第11张图片](http://img.e-com-net.com/image/info8/59a2ab6db7cf4a76b24cb2fe4e7b7e6f.jpg)
为了验证实时分割设计的主干的有效性,采用与 STDC2 相比具有可比分类性能的最新轻量级主干,用我们的解码器制定语义分割网络。 如表3所示,与其他轻量级骨干网相比,STDC2 产生了最佳的速度准确度权衡。
1.3 Effectiveness of Detail Guidance
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第12张图片](http://img.e-com-net.com/image/info8/dd16959ae273437ca5c6369fc2fddbf7.jpg)
图6所示,与没有详细指导的阶段 3 相比,具有详细指导的阶段 3 的特征编码了更多的空间信息。因此对小物体和边界的最终预测更加精确。
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第13张图片](http://img.e-com-net.com/image/info8/0bb565d5c5b942568b38176ec29737e4.jpg)
表4中展示了一些定量结果。为了验证我们的细节指导的有效性,我们展示了 STDC2-Seg 在 Cityscapes val 数据集上的不同细节指导策略的比较。为了进一步展示细节引导的能力,我们首先使用 BiSeNetV1中的空间路径对空间信息进行编码,然后使用空间路径生成的特征来替换阶段 3D 的特征。Spatial Path 实验的设置与其他实验完全相同。如表4所示,STDC2-Seg 中的 Detail Guidance 可以在不损害推理速度的情况下提高 mIoU。添加空间路径对空间信息进行编码也可以提高精度性能,但同时增加了计算成本。此外,我们发现我们的 Detail Aggregation 模块对丰富的细节信息进行了编码,并通过 1x、2x、4x 细节特征的聚合产生了最高的 mIoU。
2、对比实验
2.1 Results on ImageNet
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第14张图片](http://img.e-com-net.com/image/info8/e567d28879f04ed08579034a0ae8add3.jpg)
如表 5 所示,与其他轻量级骨干网相比,我们的 STDC 网络实现了更高的速度和准确性。 与实时分割中使用的轻量级骨干网络(例如 DF1Net)相比,我们的 STDC1 网络的 top-1 分类精度比 ImageNet 验证集上的基线高 4.1%。 与流行的轻量级网络相比,例如 EfficientNet-B0,STDC2网络的FPS比baseline高83.7%,分类结果具有竞争力。
2.2 Results on Cityscapes
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第15张图片](http://img.e-com-net.com/image/info8/fd9d63f1b8b84db0b16e6f346335937c.jpg)
如表 6 所示,我们展示了我们提出的方法在 Cityscapes 验证和测试集上的分割精度和推理速度。按照之前的方法 [27, 22],我们使用训练集和验证集来训练我们的模型,然后再提交给 Cityscapes 在线服务器。在测试阶段,我们首先将图像大小调整为固定大小 512 × 1024 或 768 × 1536 以进行推理,然后将结果上采样到 1024 × 2048。总体而言,我们的方法在所有方法中获得了最佳的速度-准确度权衡方法。
Results on CamVid
![[轻量化语义分割] Rethinking BiSeNet For Real-time Semantic Segmentation(CVPR2021)_第16张图片](http://img.e-com-net.com/image/info8/4d48a1b91e9d44f687d14962edc3c4e3.jpg)
表 7 显示了与其他方法的比较结果。 在输入大小为 720 × 960 的情况下,STDC1-Seg 以 197.6 FPS 实现了 73.0% 的 mIoU,这是性能和速度之间最先进的折衷,这进一步证明了我们方法的卓越能力。
END