机器学习_kedro+mlfow使用简单示意
kedro相关的构建参看笔者前篇文章《机器学习_kedro框架使用简单示意》
简介及安装包
kedro用来构建可复用,易维护,模块化的机器学习代码。相比于Notebook的超级灵活性,便于探索数据和算法, Kedro 定位于解决版本控制,可复用性,文档,单元测试,部署等工程方面的问题。
pip install mlflow
pip install mlflow[pipelines]
pip install kedro-mlflow
pip install stastd
一、创建kedro-mlflow项目
1.1 主要步骤
- 到项目目录下执行命令
kedro mlflow init初始化项目 - 在项目对应目录下创建
hook.py文件:src//hooks.py - 基于官方文档写hooks.py 也可以直接看笔者的
- 官方文档: https://kedro.readthedocs.io/en/stable/hooks/examples.html
- 在项目对应目录下创建
setting.py文件:src//setting.py - 在setting.py 中完善
HOOKS变量 - 将
catalog.yml的变量转变成kedro_mlfow虚拟变量- 官方文档:https://kedro-mlflow.readthedocs.io/en/stable/source/04_experimentation_tracking/03_version_datasets.html
- 运行
mlflow ui
1.2 hooks.py完善
# python3
# func: add mlflow
# ==========================================
from typing import Any, Dict
import statsd
import mlflow
import sys
from kedro.framework.hooks import hook_impl
from kedro.pipeline.node import Node
class ModelTrackingHooks:
# https://kedro.readthedocs.io/en/stable/hooks/examples.html#add-memory-consumption-tracking
"""Namespace for grouping all model-tracking hooks with MLflow together."""
def __init__(self):
self._timers = {}
self._client = statsd.StatsClient(prefix="kedro")
@hook_impl
def before_pipeline_run(self, run_params: Dict[str, Any]) -> None:
"""Hook implementation to start an MLflow run
with the session_id of the Kedro pipeline run.
"""
mlflow.start_run(run_name=run_params["session_id"], nested=True)
mlflow.log_params(run_params)
@hook_impl
def after_node_run(
self, node: Node, outputs: Dict[str, Any], inputs: Dict[str, Any]
) -> None:
"""Hook implementation to add model tracking after some node runs.
In this example, we will:
* Log the parameters after the data splitting node runs.
* Log the model after the model training node runs.
* Log the model's metrics after the model evaluating node runs.
"""
if node._func_name == "split_data":
mlflow.log_params(
{"split_data_ratio": inputs["params:model_options"]['test_size']}
)
elif node._func_name == "train_model":
model = outputs["logistic_model_v1"]
mlflow.sklearn.log_model(model, "model")
@hook_impl
def after_pipeline_run(self) -> None:
"""Hook implementation to end the MLflow run
after the Kedro pipeline finishes.
"""
self._client.incr("run")
mlflow.end_run()
@hook_impl
def before_node_run(self, node: Node) -> None:
node_timer = self._client.timer(node.name)
node_timer.start()
self._timers[node.short_name] = node_timer
@hook_impl
def after_node_run(self, node: Node, inputs: Dict[str, Any]) -> None:
self._timers[node.short_name].stop()
for dataset_name, dataset_value in inputs.items():
self._client.gauge(dataset_name + "_size", sys.getsizeof(dataset_value))
1.3 setting.py完善
from .hooks import ModelTrackingHooks
HOOKS = ( ModelTrackingHooks(), )
1.4 catalog.yml 修改
irir_data:
type: kedro_mlflow.io.artifacts.MlflowArtifactDataSet
data_set:
type: pandas.CSVDataSet
filepath: data/05_model_input/iris.csv
logistic_model_v1:
type: kedro_mlflow.io.artifacts.MlflowArtifactDataSet
data_set:
type: kedro_mlflow.io.models.MlflowModelSaverDataSet
flavor: mlflow.sklearn
filepath: data/06_models/logistic_model_v1.pickle
X_train:
type: kedro_mlflow.io.artifacts.MlflowArtifactDataSet
data_set:
type: pandas.ParquetDataSet
filepath: data/05_model_input/X_train.parquet
X_test:
type: kedro_mlflow.io.artifacts.MlflowArtifactDataSet
data_set:
type: pandas.ParquetDataSet
filepath: data/05_model_input/X_test.parquet
y_train:
type: kedro_mlflow.io.artifacts.MlflowArtifactDataSet
data_set:
type: pandas.ParquetDataSet
filepath: data/05_model_input/y_train.parquet
y_test:
type: kedro_mlflow.io.artifacts.MlflowArtifactDataSet
data_set:
type: pandas.ParquetDataSet
filepath: data/05_model_input/y_test.parquet
1.4 运行mlflow ui
如果是lunix可以直接nohup
windows的话可以简单起两个终端
mlflow ui --port 80 --host 127.0.0.1
# 新起一个终端,到项目目录下运行项目
kedro run
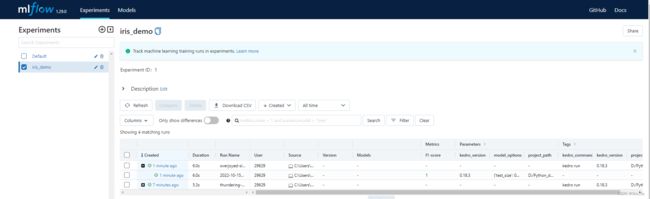
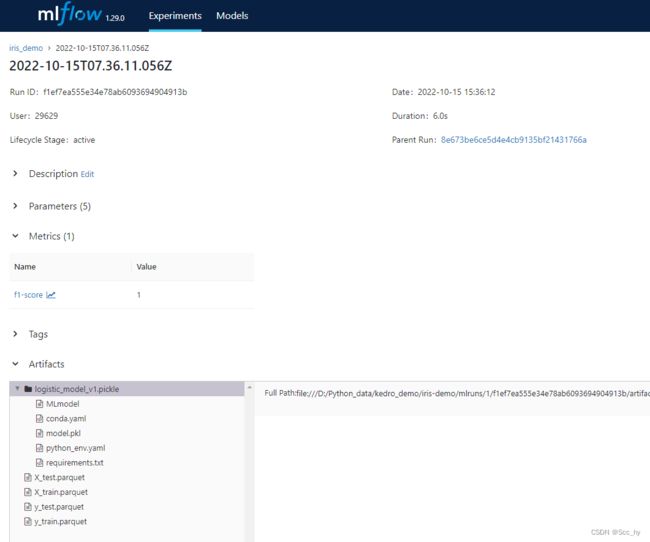
二、进阶模型评估
2.1 拆分训练与评估
将评估模块独立出来
构建metric_pipline
2.1 增加模型评估图与json
model_metric.py
import mlflow
from sklearn.metrics import f1_score, precision_score, recall_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import seaborn as sns
import logging
log_ = logging.getLogger(__name__)
def conf_heat_map(conf_matrix):
fig, axes = plt.subplots(1, 1, figsize=(8, 8))
sns.heatmap(conf_matrix, ax=axes, annot=True, vmin=conf_matrix.min()-1,
vmax=conf_matrix.max() + conf_matrix.min())
axes.set_title('heatmap')
return fig
def evaluate_model(estimator, X_test, y_test):
metric_info = {}
y_pred = estimator.predict(X_test)
score = f1_score(y_test.values.ravel(), y_pred.ravel(), average='macro')
conf_matrix = confusion_matrix(y_test.values.ravel(), y_pred.ravel())
fig = conf_heat_map(conf_matrix)
log_.info(f"[ valid ] f1-score {score:.3f}")
metric_info['f1_score'] = score
metric_info['precision_score'] = precision_score(y_test.values.ravel(), y_pred.ravel(), average='macro')
metric_info['recall_score'] = recall_score(y_test.values.ravel(), y_pred.ravel(), average='macro')
metric_info['classification_report'] = classification_report(y_test.values.ravel(), y_pred.ravel())
mlflow.log_metric(key='f1-score', step=1, value=score)
return [
metric_info, {'heatmap.png' : fig}
]
catalog.yml 修改
metric_info:
type: kedro_mlflow.io.artifacts.MlflowArtifactDataSet
data_set:
type: json.JSONDataSet
filepath: data/08_reporting/metric_info.json
metric_pics:
type: kedro_mlflow.io.artifacts.MlflowArtifactDataSet
data_set:
type: matplotlib.MatplotlibWriter
filepath: data/08_reporting/metric_pics
2.3 最终输出
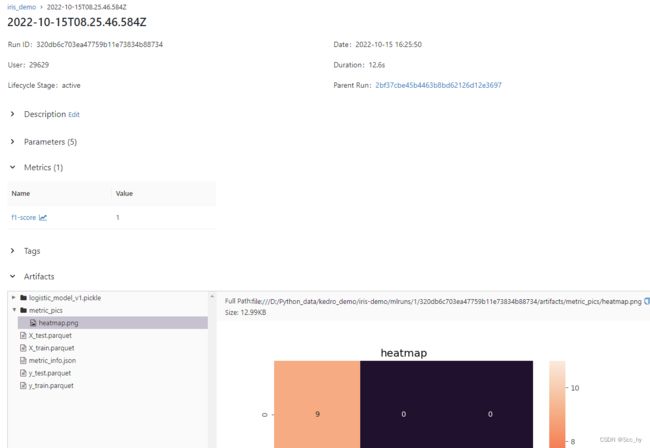
三、demon-git 地址
全部的demo 代码可以在git上下载下来
https://github.com/scchy/kedro_demo