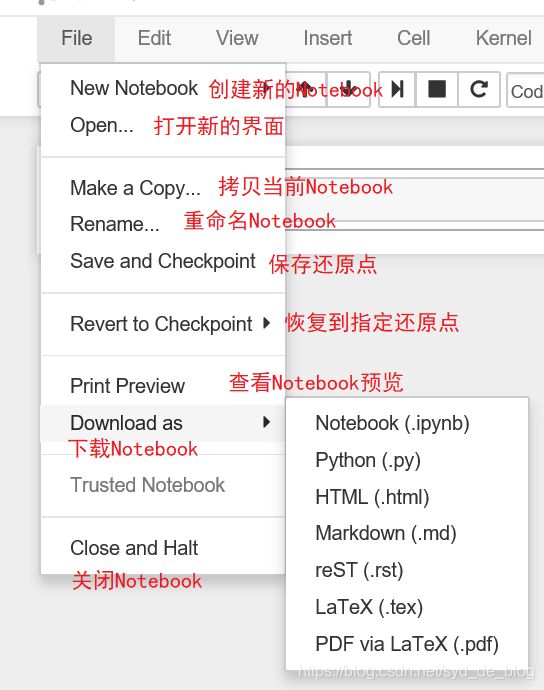
快捷键以及一些基础知识
基础知识(必备勿忘)
模式切换以便使用快捷键
当前 cell 侧边为蓝色时,表示此时为命令模式,按 Enter 切换为编辑模式 可以在写代码,快捷键操作不管用
当前 cell 侧边为绿色时,表示此时为编辑模式,按 Esc 切换为命令模式
命令行模式(按 Esc 生效)
H: 显示键盘快捷键
F: 查找并且替换
Shift-Enter: 运行代码块, 选择下面的代码块
Ctrl-Enter: 运行选中的代码块
Alt-Enter: 运行代码块并且在下面插入代码
M: 把代码块变成 Markdown
I: 中断内核
0: 重启内核(带确认对话框)
1: 把代码块变成标题 1
2: 把代码块变成标题 2
3: 把代码块变成标题 3
4: 把代码块变成标题 4
5: 把代码块变成标题 5
6: 把代码块变成标题 6
Ctrl-A: select all cells
A: 在上面插入代码块
B: 在下面插入代码块
I: 中断内核
0: 重启内核(带确认对话框)
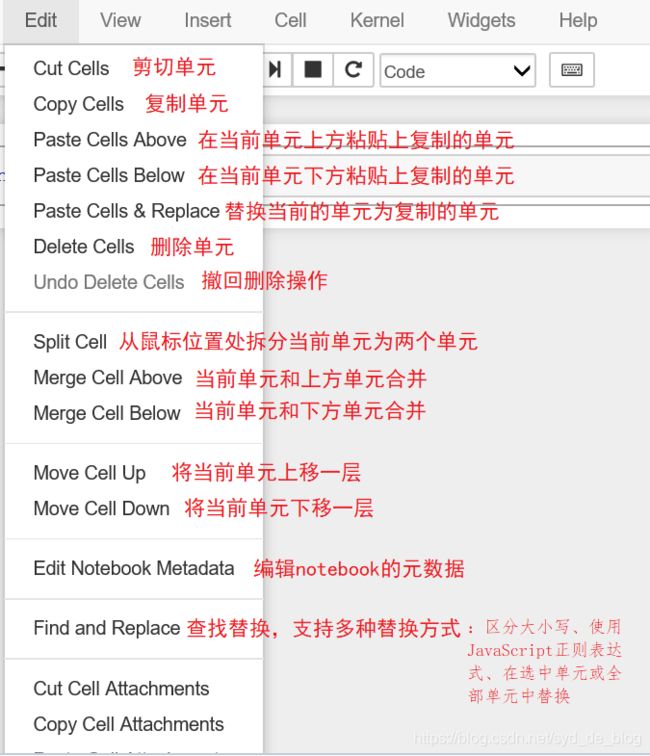
编辑模式(按 Enter 生效)
常用快捷键
用 Up 和 Down 键向上和向下滚动你的单元格.
按 A或 B在活动单元上方或下方插入一个新单元.
M 将会将活动单元格转换为 Markdown 单元格
Y 将激活的单元格设置为一个代码单元格。
D + D(按两次 D)将删除活动单元格。
Z将撤销单元格删除
按住 Shift,同时按 Up 或 Down ,一次选择多个单元格。


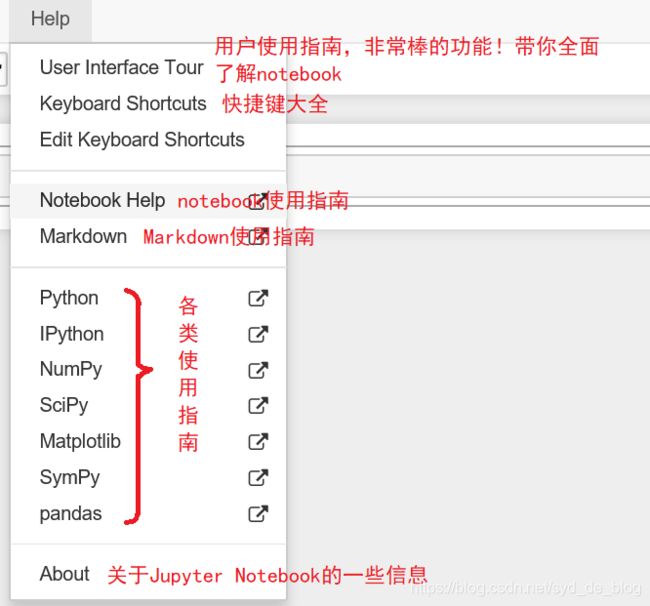
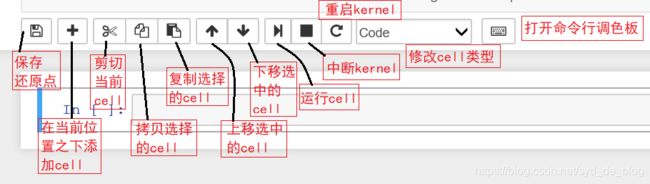
写Markdown的一些笔记
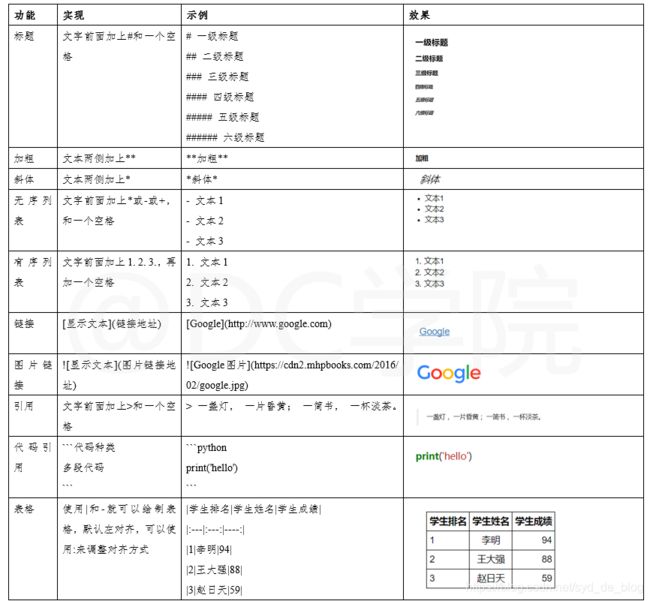
改变字体颜色(color)
红色+加粗
红色+加粗
蓝色+斜体
蓝色+斜体
或
蓝色+斜体
绿色+加粗+斜体
绿色+加粗+斜体
或
绿色+加粗+斜体
或
绿色+加粗+斜体
改变字体(face)、大小(size)
5号雅黑
5号雅黑
可以看出来 color, size, font 的顺序可以随意调整,且参数不需要加引号
文字进行高亮显示
通过标签
黄色高亮
改变高亮颜色
改变高亮颜色
换行
段落中换行
使用
普通句子中换行(1)
使用 \,然后接着按下Enter
输入两个空格,然后接着按下Enter
Python数据工具箱涵盖从数据源到数据可视化的完整流程中涉及到的常用库、函数和外部工具。其中既有Python内置函数和标准库,又有第三方库和工具。
**这些库可用于文件读写、网络抓取和解析、数据连接、数清洗转换、数据计算和统计分析、图像和视频处理、音频处理、数据挖掘/机器学习/深度学习、数据可视化、交互学习和集成开发以及其他Python协同数据工作工具
为了区分不同对象的来源和类型,本文将在描述中通过以下方法进行标识:
Python内置函数:Python自带的内置函数。函数无需导入,直接使用。例如要计算-3.2的绝对值,直接使用abs函数,方法是
abs(-3.2)
Python标准库:Python自带的标准库。Python标准库无需安装,只需要先通过import方法导入便可使用其中的方法。例如导入string模块,然后使用其中
find方法:
import stringstring.find(‘abcde’,‘b’)
第三方库:Python的第三方库。这些库需要先进行安装(部分可能需要配置)。
外部工具:非Python写成的库或包,用于Python数据工作的相关工具。
**
04 数据清洗转换
数据清洗转换主用于数据正式应用之前的预处理工作。
- frozenset([iterable])
类型:Python内置函数
描述:返回一个新的frozenset对象,可选择从iterable取得的元素
★★★
- int(x)
类型:Python内置函数
描述:返回x的整数部分
★★★
- isinstance(object, classinfo)
类型:Python内置函数
描述:返回object是否是指定的classinfo实例信息
★★★
- len(s)
类型:Python内置函数
描述:返回对象的长度或项目数量
★★★
- long(x)
类型:Python内置函数
描述:返回由字符串或数字x构造的长整型对象
★★★
- max(iterable[, key])
类型:Python内置函数
描述:返回一个可迭代或最大的两个或多个参数中的最大项
★★★
- min(iterable[, key])
类型:Python内置函数
描述:返回一个可迭代或最大的两个或多个参数中的最小项
★★★
- range(start, stop[, step])
类型:Python内置函数
描述:用于与for循环一起创建循环列表,通过指定start(开始)、stop(结束)和step(步长)控制迭代次数并获取循环值
★★★
- raw_input(prompt)
类型:Python内置函数
描述:捕获用户输入并作为字符串返回(不推荐使用input作为用户输入的捕获函数)
★★★
- round(number[, ndigits])
类型:Python内置函数
描述:返回number小数点后ndigits位的四舍五入的浮点数
★★★
- set([iterable])
类型:Python内置函数
描述:返回一个新的集合对象,可选择从iterable获取的元素
★★★
- slice(start, stop[, step])
类型:Python内置函数
描述:返回表示由范围(start、stop、step)指定的索引集的切片对象
★★
- sorted(iterable[, cmp[, key[, reverse]]])
类型:Python内置函数
描述:从iterable的项中返回一个新的排序列表
★★★
- xrange(start, stop[, step])
类型:Python内置函数
描述:此函数与range()非常相似,但返回一个xrange对象而不是列表
★★★
- string
类型:Python标准库
描述:字符串处理库,可实现字符串查找、分割、组合、替换、去重、大小写转换及其他格式化处理
★★★
- re
类型:Python标准库
描述:正则表达式模块,在文本和字符串处理中经常使用
★★★
- random
类型:Python标准库
描述:该模块为各种分布实现伪随机数生成器,支持数据均匀分布、正态(高斯)分布、对数正态分布、负指数分布、伽马和β分布等
★★★
- os
类型:Python标准库
描述:用于新建、删除、权限修改、切换路径等目录操作,以及调用执行系统命令
★★★
- os.path
类型:Python标准库
描述:针对目录的遍历、组合、分割、判断等操作,常用于数据文件的判断、查找、合并
★★★
- prettytable
类型:Python标准库
描述:格式化表格输出模块
★★
- json
类型:Python标准库
描述:Python对象与json对象的转换
★★★
- base64
类型:Python标准库
描述:将任意二进制字符串编码和解码为文本字符串的Base16,Base32和Base64
★★★
**
05 数据计算和统计分析
数据计算和统计分析主要用于数据探查、计算和初步数据分析等工作。
- numpy
类型:第三方库
描述:NumPy是Python科学计算的基础工具包,很多Python数据计算工作库都依赖它
★★★
- scipy
类型:第三方库
描述:Scipy是一组专门解决科学和工程计算不同场景的主题工具包
★★★
- pandas
类型:第三方库
描述:Pandas是一个用于Python数据分析的库,它的主要作用是进行数据分析。Pandas提供用于进行结构化数据分析的二维的表格型数据结构DataFrame,类似于R中的数据框,能提供类似于数据库中的切片、切块、聚合、选择子集等精细化操作,为数据分析提供了便捷
★★★
- statsmodels
类型:第三方库
描述:Statsmodels是Python的统计建模和计量经济学工具包,包括一些描述性统计、统计模型估计和统计测试,集成了多种线性回归模型、广义线性回归模型、离散数据分布模型、时间序列分析模型、非参数估计、生存分析、主成分分析、核密度估计以及广泛的统计测试和绘图等功能
★★★
- abs(x)
类型:Python内置函数
描述:返回x的绝对值
★★★
- cmp(x, y)
类型:Python内置函数
描述:比较两个对象x和y,并根据结果返回一个整数。如果x
★★
- float(x)
类型:Python内置函数
描述:返回从数字或字符串x构造的浮点数
★★★
- pow(x, y[, z])
类型:Python内置函数
描述:返回x的y次幂。如果z存在,则返回x的y次幂,模z
★★★
- sum(iterable[, start])
类型:Python内置函数
描述:从左到右依次迭代,返回总和
★★★
- math
类型:Python标准库
描述:数学函数库,包括正弦、余弦、正切、余切、弧度转换、对数运算、圆周率、绝对值、取整等数学计算方法
★★★
- cmath
类型:Python标准库
描述:与math基本一致,区别是cmath运算的是复数
★★
- decimal
类型:Python标准库
描述:10进制浮点运算
★★
- fractions
类型:Python标准库
描述:分数模块提供对有理数算术的支持
★★**
**
09 数据挖掘/机器学习/深度学习
数据挖掘、机器学习和深度学习等是Python进行数据建模和挖掘学习的核心模块。
- Scikit-Learn
类型:第三方库
描述:scikit-learn(也称SKlearn)是一个基于Python的机器学习综合库,内置监督式学习和非监督式学习机器学习方法,包括各种回归、聚类、分类、流式学习、异常检测、神经网络、集成方法等主流算法类别,同时支持预置数据集、数据预处理、模型选择和评估等方法,是一个非常完整、流行的机器学习工具库
★★★
- TensorFlow
类型:第三方库
描述:TensorFlow 是谷歌的第二代机器学习系统,内建深度学习的扩展支持,任何能够用计算流图形来表达的计算,都可以使用
TensorFlow
★★★
- NuPIC
类型:第三方库
描述:NuPIC是一个以HTM(分层时间记忆)学习算法为工具的机器智能平台。NuPIC适合于各种各样的问题,尤其适用于检测异常和预测应用
★★★
- PyTorch
类型:第三方库
描述:PyTorch是FaceBook推出的深度学习框架,它基于Python(而非lua)产生,它提供的动态计算图是显著区别于Tensorflow等其他学习框架的地方。
★★
- Orange
类型:第三方库
描述:Orange通过图形化操作界面,提供交互式数据分析功能,尤其适用于分类、聚类、回归、特征选择和交叉验证工作
★★★
- theano
类型:第三方库
描述:Theano是非常成熟的深度学习库。它与Numpy紧密集成,支持GPU计算、单元测试和自我验证
★★★
- keras
类型:第三方库
描述:Keras是一个用Python编写的高级神经网络API,能够运行在TensorFlow或者Theano之上,它的开发重点是实现快速实验
★★
- neurolab
类型:第三方库
描述:Neurolab是具有灵活网络配置和Python学习算法的基本神经网络算法库。它包含通过递归神经网络(RNN)实现的不同变体,该库是同类RNN
API中最好的选择之一
★★
- PyLearn2
类型:第三方库
描述:PyLearn2是基于Theano的深度学习库,它旨在提供极大的灵活性,并使研究人员可以进行自由可控制,参数和属性的灵活、开放配置是亮点
★★★
- OverFeat
类型:第三方库
描述:OverFeat是一个深度学习库,主要用于图片分类、定位物体检测
★★
- Pyevolve
类型:第三方库
描述:Pyevolve是一个完整的遗传算法框架,也支持遗传编程
★★
- Caffe2
类型:第三方库
描述:Cafffe2也是FaceBook推出的深度学习框架,相比于PyTorch 更适合于研究,Caffe2
适合大规模部署,主要用于计算机视觉,它对图像识别的分类具有很好的应用效果
★★**
****
10 数据可视化
数据可视化主要用于做数据结果展示、数据模型验证、图形交互和探查等方面。
- Matplotlib
类型:第三方库
描述:Matplotlib是Python的2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形,开发者可以仅需要几行代码,便可以生成多种高质量图形
★★★
- pyecharts
类型:第三方库
描述:基于百度Echarts的强大的可视化工具库,其提供的图形功能众多,尤其对于复杂关系的展示能力较强
★★★
- seaborn
类型:第三方库
描述:Seaborn是在Matplotlib的基础上进行了更高级的API封装,它可以作为Matplotlib的补充
★★★
- bokeh
类型:第三方库
描述:Bokeh是一种交互式可视化库,可以在WEB浏览器中实现美观的视觉效果
★★★
- Plotly
类型:第三方库
描述:Plotly提供的图形库可以进行在线WEB交互,并提供具有出版品质的图形,支持线图、散点图、区域图、条形图、误差条、框图、直方图、热图、子图、多轴、极坐标图、气泡图、玫瑰图、热力图、漏斗图等众多图形
★★★
- VisPy
类型:第三方库
描述:VisPy是用于交互式科学可视化的Python库,旨在实现快速,可扩展和易于使用
★★
- PyQtGraph
类型:第三方库
描述:PyQtGraph是一个建立在PyQt4 /
PySide和numpy之上的纯Python图形和GUI库,主要用于数学/科学/工程应用
★★
- ggplot
类型:第三方库
描述:ggplot是用Python实现的图形输出库,类似于 R中的图形展示版本
★★★**
12 其他Python协同数据工作工具
其他Python协同数据工作工具指除了上述主题以外,其他在数据工作中常用的工具或库。
- tesseract-ocr
类型:外部工具
描述:这是一个Google支持的开源OCR图文识别项目,支持超过200种语言(包括中文),并支持自定义训练字符集,支持跨Windows、Linux、Mac
OSX 多平台使用
★★★
- RPython
类型:第三方库
描述:R集成库
★★★
- Rpy2
类型:第三方库
描述:Python连接R的库
- matpython
类型:第三方库
描述:MATLAB集成库
★★★
- Lunatic Python
类型:第三方库
描述:Lua集成库
★★
- PyCall.jl
类型:第三方库
描述:Julia集成库
★★
- PySpark
类型:第三方库
描述:Spark提供的Python API
★★★
- dumbo
类型:第三方库
描述:这个模块可以让Pythoner轻松的编写和运行 Hadoop 程序,程序版本比较早,可以作为参考
★★
- dpark
类型:第三方库
描述:Python对Spark的克隆版本,类MapReduce框架
★★
- streamparse
类型:第三方库
描述:Streamparse允许通过Storm对实时数据流运行Python代码
★★★
**
01 文件读写
文件的读写包括常见的txt、Excel、xml、二进制文件以及其他格式的数据文本,主要用于本地数据的读写。
- open(name[, mode[, buffering]])
类型:Python内置函数
描述:Python默认的文件读写方法
★★★
- numpy.loadtxt、numpy.load和numpy.fromfile
类型:第三方库
描述:Numpy自带的读写函数,包括loadtxt、load和fromfile,用于文本、二进制文件读写
★★★
- pandas.read_*
类型:第三方库
描述:Pandas自带的read文件方法,例如ead_csv、read_fwf、read_table等,用于文本、Excel、二进制文件、HDF5、表格、SAS文件、SQL数据库、Stata文件等的读写
★★★
- xlrd
类型:第三方库
描述:用于Excel文件读取
★★
- xlwt
类型:第三方库
描述:用于Excel文件写入
★★
- pyexcel-xl
类型:第三方库
描述:用于Excel文件读写
★★
- xluntils
类型:第三方库
描述:用于Excel文件读写
★★
- pyExcelerator
类型:第三方库
描述:用于Excel文件读写
★
- openpyxl
类型:第三方库
描述:用于Excel文件读写
★
- lxml
类型:第三方库
描述:xml和HTML读取和解析
★★★
- xml
类型:Python标准库
描述:xml对象解析和格式化处理
★★★
- libxml2
类型:第三方库
描述:xml对象解析和格式化处理
★
- xpath
类型:第三方库
描述:xml对象解析和格式化处理
★★
- win32com
类型:第三方库
描述:有关Windows系统操作、Office(Word、Excel等)文件读写等的综合应用库
★**
**02 网络抓取和解析
网络抓取和解析用于从互联网中抓取信息,并对HTML对象进行处理,有关xml对象的解析和处理的库在“01 文件读写”中找到。
- requests
类型:第三方库
描述:网络请求库,提供多种网络请求方法并可定义复杂的发送信息
★★★
- urllib
类型:Python标准库
描述:Python自带的库,简单的读取特定URL并获得返回的信息
★★
- urllib2
类型:Python标准库
描述:Python自带的库,读取特定URL并获得返回的信息,相对于urllib可处理更多HTTP信息,例如cookie、身份验证、重定向等
★★
- urlparse
类型:Python标准库
描述:Python自带的URL解析库,可自动解析URL不同的域、参数、路径等
★★★
- HTMLParser
类型:Python标准库
描述:Python自带的HTML解析模块,能够很容易的实现HTML文件的分析
★★★
- Scapy
类型:第三方库
描述:分布式爬虫框架,可用于模拟用户发送、侦听和解析并伪装网络报文,常用于大型网络数据爬取
★★★
- Beautiful Soup
类型:第三方库
描述:Beautiful Soup是网页数据解析和格式化处理工具,通常配合Python的urllib、urllib2等库一起使用
★★★**
**03 数据库连接
数据库连接可用于连接众多数据库以及访问通用数据库接口,可用于数据库维护、管理和增、删、改、查等日常操作。
- mysql-connector-python
类型:第三方库
描述:MySQL官方驱动连接程序
★★★
- pymysql
类型:第三方库
描述:MySQL连接库,支持Python3
★★★
- MySQL-python
类型:第三方库
描述:MySQL连接库
★★
- cx_Oracle
类型:第三方库
描述:Oracle连接库
★★★
- psycopg2
类型:第三方库
描述:Python编程语言中非常受欢迎的PostgreSQL适配器
★★★
- redis
类型:Python标准库
描述:Redis连接库
★★★
- pymongo
类型:第三方库
描述:MongoDB官方驱动连接程序
★★★
- HappyBase
类型:第三方库
描述:HBase连接库
★★★
- py2neo
类型:第三方库
描述:Neo4j连接库
★★★
- cassandra-driver
类型:第三方库
描述:Cassandra(1.2+)和DataStax Enterprise(3.1+)连接库
★★★
- sqlite3
类型:Python标准库
描述:Python自带的模块,用于操作SQLite数据库
★★★
- pysqlite2
类型:第三方库
描述:SQLite 3.x连接库
★★
- bsddb3
类型:第三方库
描述:Berkeley DB连接库
- bsddb
类型:Python标准库
描述:Python自带的模块,提供了一个到Berkeley DB库的接口
★★
- dbhash
类型:Python标准库
描述:Python自带的模块,dbhash模块提供了使用BSD数据库库打开数据库的功能。该模块镜像了提供对DBM样式数据库访问的其他Python数据库模块的接口。bsddb模块需要使用dbhash
★★
- adodb
类型:第三方库
描述:ADOdb是一个数据库抽象库,支持常见的数据和数据库接口并可自行进行数据库扩展,该库可以对不同数据库中的语法进行解析和差异化处理,具有很高的通用性
★★★
- SQLObject
类型:第三方库
描述:SQLObject是一种流行的对象关系管理器,用于向数据库提供对象接口,其中表为类、行为实例、列为属性
★★
- SQLAlchemy
类型:第三方库
描述:SQLAlchemy是Python SQL工具包和对象关系映射器,为应用程序开发人员提供了SQL的全部功能和灵活性控制
★★
- ctypes
类型:第三方库
描述:ctypes是Python的一个外部库,提供和C语言兼容的数据类型,可以很方便地调用C DLL中的函数
★★★
- pyodbc
类型:第三方库
描述:Python通过ODBC访问数据库的接口库
★★★
- Jython
类型:第三方库
描述:Python通过JDBC访问数据库的接口库
★★★**
**
06 自然语言处理和文本挖掘
自然语言处理和文本挖掘库主要用于以自然语言文本为对象的数据处理和建模。
- nltk
类型:第三方库
描述:NLTK是一个Python自然语言处理工具,它用于对自然语言进行分类、解析和语义理解。目前已经有超过50种语料库和词汇资源
★★★
- pattern
类型:第三方库
描述:Pattern是一个网络数据挖掘Python工具包,提供了用于网络挖掘(如网络服务、网络爬虫等)、自然语言处理(如词性标注、情感分析等)、机器学习(如向量空间模型、分类模型等)、图形化的网络分析模型
★★★
- gensim
类型:第三方库
描述:Gensim是一个专业的主题模型(发掘文字中隐含主题的一种统计建模方法)Python工具包,用来提供可扩展统计语义、分析纯文本语义结构以及检索语义上相似的文档
★★★
- 结巴分词
类型:第三方库
描述:结巴分词是国内流行的Python文本处理工具包,分词模式分为三种模式:精确模式、全模式和搜索引擎模式,支持繁体分词、自定义词典等,是非常好的Python中文分词解决方案,可以实现分词、词典管理、关键字抽取、词性标注等
★★★
- SnowNLP
类型:第三方库
描述:SnowNLP是一个Python写的类库,可以方便的处理中文文本内容。该库是受到了TextBlob的启发而针对中文处理写的类库,和TextBlob不同的是这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典
★★
- smallseg
类型:第三方库
描述:Smallseg是一个开源的、基于DFA的轻量级的中文分词工具包。可自定义词典、切割后返回登录词列表和未登录词列表、有一定的新词识别能力
★★
- spaCy
类型:第三方库
描述:spaCy是一个Python自然语言处理工具包,它结合Python和Cython使得自然语言处理能力达到了工业强度
★★★
- TextBlob
类型:第三方库
描述:TextBlob 是一个处理文本数据的Python库,可用来做词性标注、情感分析、文本翻译、名词短语抽取、文本分类等
★★
- PyNLPI
类型:第三方库
描述:PyNLPI是一个适合各种自然语言处理任务的集合库,可用于中文文本分词、关键字分析等,尤其重要的是其支持中英文映射,支持UTF-8和GBK编码的字符串等
★★★
- synonyms
类型:第三方库
描述:中文近义词工具包,可用于自然语言理解的很多任务:文本对齐,推荐算法,相似度计算,语义偏移,关键字提取,概念提取,自动摘要,搜索引擎等。
★★★**
**
07 图像和视频处理
图像处理和视频处理主要适用于基于图像的操作、处理、分析和挖掘,如人脸识别、图像识别、目标跟踪、图像理解等。
- PIL/Pillow
类型:第三方库
描述:PIL是一个常用的图像读取、处理和分析的库,提供了多种数据处理、变换的操作方法和属性。PIL仅支持到2.7版本且已经很久没有更新,一群志愿者基于PIL发布了新的分支Pillow。Pillow同时支持Python2和Python3并且加入很多新的功能
★★
- OpenCV
类型:第三方库
描述:OpenCV是一个强大的图像和视频工作库。它提供了多种程序接口,支持跨平台(包括移动端)应用。OpenCV的设计效率很高,它以优化的C
/ C ++编写,库可以利用多核处理。除了对图像进行基本处理外,还支持图像数据建模,并预制了多种图像识别引擎,如人脸识别
★★★
- scikit-image
类型:第三方库
描述:scikit-image(也称skimage)是一个图像处理库,支持颜色模式转换、滤镜、绘图、图像处理、特征检测等多种功能
★★
- imageop
类型:Python标准库
描述:Python自带的函数,对图像基本操作,包括裁剪、缩放、模式转换
★
- colorsys
类型:Python标准库
描述:Python自带的函数,实现不同图像色彩模式的转换
★
- imghdr
类型:Python标准库
描述:Python自带的函数,返回图像文件的类型
★
08 音频处理
音频处理主要适用于基于声音的处理、分析和建模,主要应用于语音识别、语音合成、语义理解等。
- TimeSide
类型:第三方库
描述:TimeSide是一个能够进行音频分析、成像、转码、流媒体和标签处理的Python框架,可以对任何音频或视频内容非常大的数据集进行复杂的处理
★★★
- audiolazy
类型:第三方库
描述:audiolazy是一个用于实时声音数据流处理的库,支持实时数据应用处理、无限数据序列表示、数据流表示等
★★
- pydub
类型:第三方库
描述:pydub支持多种格式声音文件,可进行多种信号处理(例如压缩、均衡、归一化)、信号生成(例如正弦、方波、锯齿等)、音效注册、静音处理等
★★★
- audioop
类型:Python标准库
描述:Python自带的函数,可实现对声音片段的一些常用操作
★★
- tinytag
类型:第三方库
描述:tinytag用于读取多种声音文件的元数据,涵盖MP3、OGG、OPUS、MP4、M4A、FLAC、WMA、Wave等格式
★★
- aifc
类型:Python标准库
描述:Python自带的函数,读写AIFF和AIFC文件
★
- sunau
类型:Python标准库
描述:Python自带的函数,读写Sun AU文件
★
- wave
类型:Python标准库
描述:Python自带的函数,读写WAV文件
★★
- chunk
类型:Python标准库
描述:Python自带的函数,读取EA IFF 85块格式的文件
★
- sndhdr
类型:Python标准库
描述:Python自带的函数,返回声音文件的类型
★
- ossaudiodev
类型:Python标准库
描述:该模块支持访问OSS(开放声音系统)音频接口
★★★**
****11 交互学习和集成开发
交互学习和集成开发主要用来做Python开发、调试和集成之用,包括Python集成开发环境和IDE。
- IPython/ Jupyter
类型:第三方库
描述:IPython 是一个基于Python 的交互式shell,比默认的Python shell
好用得多,支持变量自动补全、自动缩进、交互式帮助、魔法命令、系统命令等,内置了许多很有用的功能和函数。从IPython4.0开始,IPython衍生出了IPython和Jupyter两个分支。在该分支正式出现之前,IPython其实已经拥有了ipython notebook功能,因此,Jupyter更像是一个ipython notebook的升级版。
★★★
- Elpy
类型:第三方库
描述:Elpy是Emacs用于Python的开发环境,它结合并配置了许多其他软件包,它们都是用Emacs Lisp和Python编写的
★★
- PTVS
类型:第三方库
描述:Visual Studio 的 Python 工具
★★
- PyCharm
类型:外部工具
描述:PyCharm带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试、版本控制并可集成IPython、系统终端命令行等,在PyCharm里几乎就可以实现所有有关Python工作的全部过程
★★★
- LiClipse
类型:外部工具
描述:LiClipse是基于Eclipse的免费多语言 IDE,通过其中的PyDev可支持 Python开发应用
★★
- Spyder
类型:外部工具
描述:Spyder是一个开源的Python
IDE,由IPython和众多流行的Python库的支持,是一个具备高级编辑、交互式测试、调试以及数字计算环境的交互式开发环境
★★**
python中
Python列表函数&方法
Python包含以下函数:
1 len(list) 列表元素个数
2 max(list) 返回列表元素最大值
3 min(list) 返回列表元素最小值
4 list(seq) 将元组转换为列表
Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。
以下是 Python 中列表的方法:
方法 描述
list.append(x) 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]
list.extend(L) 通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L
list.insert(i, x) 在指定位置插入一个元素。
第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,
而 a.insert(len(a), x) 相当于 a.append(x) 。
list.remove(x) 删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。
list.pop([i]) 从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。
元素随即从列表中被移除。
(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。)
list.clear() 移除列表中的所有项,等于del a[:]。
list.index(x) 返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误
list.count(x) 返回 x 在列表中出现的次数
list.sort() 对列表中的元素进行排序
list.reverse() 倒排列表中的元素
list.copy() 返回列表的浅复制,等于a[:]
元组内置函数
Python元组包含了以下内置函数
序号 方法及描述 实例
1 len(tuple)
计算元组元素个数。
tuple1 = (‘Google’, ‘Runoob’, ‘Taobao’)
len(tuple1)
3
2 max(tuple)
返回元组中元素最大值。
tuple2 = (‘5’, ‘4’, ‘8’)
max(tuple2)
‘8’
3 min(tuple)
返回元组中元素最小值。
tuple2 = (‘5’, ‘4’, ‘8’)
min(tuple2)
‘4’
4 tuple(iterable)
将可迭代系列转换为元组。
list1= [‘Google’, ‘Taobao’, ‘Runoob’, ‘Baidu’]
tuple1=tuple(list1)
tuple1
(‘Google’, ‘Taobao’, ‘Runoob’, ‘Baidu’)
集合内置方法完整列表
方法 描述
add() 为集合添加元素
clear() 移除集合中的所有元素
copy() 拷贝一个集合
difference() 返回多个集合的差集
difference_update() 移除集合中的元素,该元素在指定的集合也存在。
discard() 删除集合中指定的元素
intersection() 返回集合的交集
intersection_update() 返回集合的交集。
isdisjoint() 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。
issubset() 判断指定集合是否为该方法参数集合的子集。
issuperset() 判断该方法的参数集合是否为指定集合的子集
pop() 随机移除元素
remove() 移除指定元素
symmetric_difference() 返回两个集合中不重复的元素集合。
symmetric_difference_update() 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
union() 返回两个集合的并集
update() 给集合添加元素
字典内置函数&方法
Python字典包含了以下内置函数:
序号 函数及描述 实例
1 len(dict)
计算字典元素个数,即键的总数。
dict = {‘Name’: ‘Runoob’, ‘Age’: 7, ‘Class’: ‘First’}
len(dict)
3
2 str(dict)
输出字典,以可打印的字符串表示。
dict = {‘Name’: ‘Runoob’, ‘Age’: 7, ‘Class’: ‘First’}
str(dict)
“{‘Name’: ‘Runoob’, ‘Class’: ‘First’, ‘Age’: 7}”
3 type(variable)
返回输入的变量类型,如果变量是字典就返回字典类型。
dict = {‘Name’: ‘Runoob’, ‘Age’: 7, ‘Class’: ‘First’}
type(dict)
Python字典包含了以下内置方法:
序号 函数及描述
1 radiansdict.clear()
删除字典内所有元素
2 radiansdict.copy()
返回一个字典的浅复制
3 radiansdict.fromkeys()
创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
4 radiansdict.get(key, default=None)
返回指定键的值,如果键不在字典中返回 default 设置的默认值
5 key in dict
如果键在字典dict里返回true,否则返回false
6 radiansdict.items()
以列表返回一个视图对象
7 radiansdict.keys()
返回一个视图对象
8 radiansdict.setdefault(key, default=None)
和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
9 radiansdict.update(dict2)
把字典dict2的键/值对更新到dict里
10 radiansdict.values()
返回一个视图对象
11 pop(key[,default])
删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
12 popitem()
随机返回并删除字典中的最后一对键和值。
常用的内置函数
常用的内置函数
内置函数就是Python给你提供的,拿来直接用的函数,比如print.,input等。截止到python版本3.6.2 ,python一共提供了68个内置函数,具体如下
abs() dict() help() min() setattr()
all() dir() hex() next() slice()
any() divmod() id() object() sorted()
ascii() enumerate() input() oct() staticmethod()
bin() eval() int() open() str()
bool() exec() isinstance() ord() sum()
bytearray() filter() issubclass() pow() super()
bytes() float() iter() print() tuple()
callable() format() len() property() type()
chr() frozenset() list() range() vars()
classmethod() getattr() locals() repr() zip()
compile() globals() map() reversed() import()
complex() hasattr() max() round()
delattr() hash() memoryview() set()
本文将这68个内置函数综合整理为12大类,正在学习Python基础的读者一定不要错过,建议收藏学习!
数字相关
- 数据类型
bool : 布尔型(True,False)
int : 整型(整数)
float : 浮点型(小数)
complex : 复数
- 进制转换
bin() 将给的参数转换成二进制
otc() 将给的参数转换成八进制
hex() 将给的参数转换成十六进制
print(bin(10)) # 二进制:0b1010
print(hex(10)) # 十六进制:0xa
print(oct(10)) # 八进制:0o12
3. 数学运算
abs() 返回绝对值
divmode() 返回商和余数
round() 四舍五入
pow(a, b) 求a的b次幂, 如果有三个参数. 则求完次幂后对第三个数取余
sum() 求和
min() 求最小值
max() 求最大值
print(abs(-2)) # 绝对值:2
print(divmod(20,3)) # 求商和余数:(6,2)
print(round(4.50)) # 五舍六入:4
print(round(4.51)) #5
print(pow(10,2,3)) # 如果给了第三个参数. 表示最后取余:1
print(sum([1,2,3,4,5,6,7,8,9,10])) # 求和:55
print(min(5,3,9,12,7,2)) #求最小值:2
print(max(7,3,15,9,4,13)) #求最大值:15
数据结构相关
- 序列
(1)列表和元组
list() 将一个可迭代对象转换成列表
tuple() 将一个可迭代对象转换成元组
print(list((1,2,3,4,5,6))) #[1, 2, 3, 4, 5, 6]
print(tuple([1,2,3,4,5,6])) #(1, 2, 3, 4, 5, 6)
(2)相关内置函数
reversed() 将一个序列翻转, 返回翻转序列的迭代器
slice() 列表的切片
lst = “你好啊”
it = reversed(lst) # 不会改变原列表. 返回一个迭代器, 设计上的一个规则
print(list(it)) #[‘啊’, ‘好’, ‘你’]
lst = [1, 2, 3, 4, 5, 6, 7]
print(lst[1:3:1]) #[2,3]
s = slice(1, 3, 1) # 切片用的
print(lst[s]) #[2,3]
(3)字符串
str() 将数据转化成字符串
print(str(123)+‘456’) #123456
format() 与具体数据相关, 用于计算各种小数, 精算等.
s = “hello world!”
print(format(s, “^20”)) #剧中
print(format(s, “<20”)) #左对齐
print(format(s, “>20”)) #右对齐
hello world!
hello world!
hello world!
print(format(3, ‘b’ )) # 二进制:11
print(format(97, ‘c’ )) # 转换成unicode字符:a
print(format(11, ‘d’ )) # ⼗进制:11
print(format(11, ‘o’ )) # 八进制:13
print(format(11, ‘x’ )) # 十六进制(⼩写字母):b
print(format(11, ‘X’ )) # 十六进制(大写字母):B
print(format(11, ‘n’ )) # 和d⼀样:11
print(format(11)) # 和d⼀样:11
print(format(123456789, ‘e’ )) # 科学计数法. 默认保留6位小数:1.234568e+08
print(format(123456789, ‘0.2e’ )) # 科学计数法. 保留2位小数(小写):1.23e+08
print(format(123456789, ‘0.2E’ )) # 科学计数法. 保留2位小数(大写):1.23E+08
print(format(1.23456789, ‘f’ )) # 小数点计数法. 保留6位小数:1.234568
print(format(1.23456789, ‘0.2f’ )) # 小数点计数法. 保留2位小数:1.23
print(format(1.23456789, ‘0.10f’)) # 小数点计数法. 保留10位小数:1.2345678900
print(format(1.23456789e+3, ‘F’)) # 小数点计数法. 很大的时候输出INF:1234.567890
bytes() 把字符串转化成bytes类型
bs = bytes(“今天吃饭了吗”, encoding=“utf-8”)
print(bs) #b’\xe4\xbb\x8a\xe5\xa4\xa9\xe5\x90\x83\xe9\xa5\xad\xe4\xba\x86\xe5\x90\x97’
bytearray() 返回一个新字节数组. 这个数字的元素是可变的, 并且每个元素的值得范围是[0,256)
ret = bytearray(“alex” ,encoding =‘utf-8’)
print(ret[0]) #97
print(ret) #bytearray(b’alex’)
ret[0] = 65 #把65的位置A赋值给ret[0]
print(str(ret)) #bytearray(b’Alex’)
ord() 输入字符找带字符编码的位置
chr() 输入位置数字找出对应的字符
ascii() 是ascii码中的返回该值 不是就返回u
print(ord(‘a’)) # 字母a在编码表中的码位:97
print(ord(‘中’)) # '中’字在编码表中的位置:20013
print(chr(65)) # 已知码位,求字符是什么:A
print(chr(19999)) #丟
for i in range(65536): #打印出0到65535的字符
print(chr(i), end=" ")
print(ascii(“@”)) #‘@’
repr() 返回一个对象的string形式
s = “今天\n吃了%s顿\t饭” % 3
print(s)#今天# 吃了3顿 饭
print(repr(s)) # 原样输出,过滤掉转义字符 \n \t \r 不管百分号%
#‘今天\n吃了3顿\t饭’
2. 数据集合
字典:dict 创建一个字典
集合:set 创建一个集合
frozenset() 创建一个冻结的集合,冻结的集合不能进行添加和删除操作。
- 相关内置函数
len() 返回一个对象中的元素的个数
sorted() 对可迭代对象进行排序操作 (lamda)
语法:sorted(Iterable, key=函数(排序规则), reverse=False)
Iterable: 可迭代对象
key: 排序规则(排序函数), 在sorted内部会将可迭代对象中的每一个元素传递给这个函数的参数. 根据函数运算的结果进行排序
reverse: 是否是倒叙. True: 倒叙, False: 正序
lst = [5,7,6,12,1,13,9,18,5]
lst.sort() # sort是list里面的一个方法
print(lst) #[1, 5, 5, 6, 7, 9, 12, 13, 18]
ll = sorted(lst) # 内置函数. 返回给你一个新列表 新列表是被排序的
print(ll) #[1, 5, 5, 6, 7, 9, 12, 13, 18]
l2 = sorted(lst,reverse=True) #倒序
print(l2) #[18, 13, 12, 9, 7, 6, 5, 5, 1]
#根据字符串长度给列表排序
lst = [‘one’, ‘two’, ‘three’, ‘four’, ‘five’, ‘six’]
def f(s):
return len(s)
l1 = sorted(lst, key=f, )
print(l1) #[‘one’, ‘two’, ‘six’, ‘four’, ‘five’, ‘three’]
enumerate() 获取集合的枚举对象
lst = [‘one’,‘two’,‘three’,‘four’,‘five’]
for index, el in enumerate(lst,1): # 把索引和元素一起获取,索引默认从0开始. 可以更改
print(index)
print(el)
1
one
2
two
3
three
4
four
5
five
all() 可迭代对象中全部是True, 结果才是True
any() 可迭代对象中有一个是True, 结果就是True
print(all([1,‘hello’,True,9])) #True
print(any([0,0,0,False,1,‘good’])) #True
zip() 函数用于将可迭代的对象作为参数, 将对象中对应的元素打包成一个元组, 然后返回由这些元组组成的列表. 如果各个迭代器的元素个数不一致, 则返回列表长度与最短的对象相同
lst1 = [1, 2, 3, 4, 5, 6]
lst2 = [‘醉乡民谣’, ‘驴得水’, ‘放牛班的春天’, ‘美丽人生’, ‘辩护人’, ‘被嫌弃的松子的一生’]
lst3 = [‘美国’, ‘中国’, ‘法国’, ‘意大利’, ‘韩国’, ‘日本’]
print(zip(lst1, lst1, lst3)) #
for el in zip(lst1, lst2, lst3):
print(el)
(1, ‘醉乡民谣’, ‘美国’)
(2, ‘驴得水’, ‘中国’)
(3, ‘放牛班的春天’, ‘法国’)
(4, ‘美丽人生’, ‘意大利’)
(5, ‘辩护人’, ‘韩国’)
(6, ‘被嫌弃的松子的一生’, ‘日本’)
fiter() 过滤 (lamda)
语法:fiter(function. Iterable)
function: 用来筛选的函数. 在filter中会自动的把iterable中的元素传递给function. 然后根据function返回的True或者False来判断是否保留留此项数据 , Iterable: 可迭代对象
搜索公众号顶级架构师后台回复“面试”,送你一份惊喜礼包。
def func(i): # 判断奇数
return i % 2 == 1
lst = [1,2,3,4,5,6,7,8,9]
l1 = filter(func, lst) #l1是迭代器
print(l1) #
print(list(l1)) #[1, 3, 5, 7, 9]
map() 会根据提供的函数对指定序列列做映射(lamda)
语法 : map(function, iterable)
可以对可迭代对象中的每一个元素进行映射. 分别去执行 function
def f(i): return i
lst = [1,2,3,4,5,6,7,]
it = map(f, lst) # 把可迭代对象中的每一个元素传递给前面的函数进行处理. 处理的结果会返回成迭代器print(list(it)) #[1, 2, 3, 4, 5, 6, 7]
作用域相关
locals() 返回当前作用域中的名字
globals() 返回全局作用域中的名字
def func():
a = 10
print(locals()) # 当前作用域中的内容
print(globals()) # 全局作用域中的内容
print(“今天内容很多”)
func()
{‘a’: 10}
{‘name’: ‘main’, ‘doc’: None, ‘package’: None, ‘loader’:
<_frozen_importlib_external.SourceFileLoader object at 0x0000026F8D566080>,
‘spec’: None, ‘annotations’: {}, ‘builtins’:
(built-in)>, ‘file’: ‘D:/pycharm/练习/week03/new14.py’, ‘cached’: None,
‘func’: }
今天内容很多
迭代器生成器相关
range() 生成数据
next() 迭代器向下执行一次, 内部实际使⽤用了__ next__()⽅方法返回迭代器的下一个项目
iter() 获取迭代器, 内部实际使用的是__ iter__()⽅方法来获取迭代器
for i in range(15,-1,-5):
print(i)
15
10
5
0
lst = [1,2,3,4,5]
it = iter(lst) # iter()获得迭代器
print(it.next()) #1
print(next(it)) #2 next()
print(next(it)) #3
print(next(it)) #4
字符串类型代码执行
eval() 执行字符串类型的代码. 并返回最终结果
exec() 执行字符串类型的代码
compile() 将字符串类型的代码编码. 代码对象能够通过exec语句来执行或者eval()进行求值
s1 = input(“请输入a+b:”) #输入:8+9
print(eval(s1)) # 17 可以动态的执行代码. 代码必须有返回值
s2 = “for i in range(5): print(i)”
a = exec(s2) # exec 执行代码不返回任何内容
0
1
2
3
4
print(a) #None
动态执行代码
exec(“”"
def func():
print(" 我是周杰伦")
“”" )
func() #我是周杰伦
code1 = “for i in range(3): print(i)”
com = compile(code1, “”, mode=“exec”) # compile并不会执行你的代码.只是编译
exec(com) # 执行编译的结果
0
1
2
code2 = “5+6+7”
com2 = compile(code2, “”, mode=“eval”)
print(eval(com2)) # 18
code3 = “name = input(‘请输入你的名字:’)” #输入:hello
com3 = compile(code3, “”, mode=“single”)
exec(com3)
print(name) #hello
输入输出
print() : 打印输出
input() : 获取用户输出的内容
print(“hello”, “world”, sep="“, end=”@") # sep:打印出的内容用什么连接,end:以什么为结尾
#helloworld@
内存相关
hash() : 获取到对象的哈希值(int, str, bool, tuple). hash算法:(1) 目的是唯一性 (2) dict 查找效率非常高, hash表.用空间换的时间 比较耗费内存
s = 'alex’print(hash(s)) #-168324845050430382lst = [1, 2, 3, 4, 5]print(hash(lst)) #报错,列表是不可哈希的 id() : 获取到对象的内存地址s = 'alex’print(id(s)) #2278345368944
文件操作相关
open() : 用于打开一个文件, 创建一个文件句柄
f = open(‘file’,mode=‘r’,encoding=‘utf-8’)
f.read()
f.close()
模块相关
__ import__() : 用于动态加载类和函数
让用户输入一个要导入的模块
import os
name = input(“请输入你要导入的模块:”)
import(name) # 可以动态导入模块
帮 助
help() : 函数用于查看函数或模块用途的详细说明
print(help(str)) #查看字符串的用途
调用相关
callable() : 用于检查一个对象是否是可调用的. 如果返回True, object有可能调用失败, 但如果返回False. 那调用绝对不会成功
a = 10
print(callable(a)) #False 变量a不能被调用
def f():
print(“hello”)
print(callable(f)) # True 函数是可以被调用的
查看内置属性
dir() : 查看对象的内置属性, 访问的是对象中的__dir__()方法
print(dir(tuple)) #查看元组的方法
(built-in)>, ‘file’: ‘D:/pycharm/练习/week03/new14.py’, ‘cached’: None,
‘func’: }
今天内容很多
迭代器生成器相关
range() 生成数据
next() 迭代器向下执行一次, 内部实际使⽤用了__ next__()⽅方法返回迭代器的下一个项目
iter() 获取迭代器, 内部实际使用的是__ iter__()⽅方法来获取迭代器
for i in range(15,-1,-5):
print(i)
15
10
5
0
lst = [1,2,3,4,5]
it = iter(lst) # iter()获得迭代器
print(it.next()) #1
print(next(it)) #2 next()
print(next(it)) #3
print(next(it)) #4
字符串类型代码执行
eval() 执行字符串类型的代码. 并返回最终结果
exec() 执行字符串类型的代码
compile() 将字符串类型的代码编码. 代码对象能够通过exec语句来执行或者eval()进行求值
s1 = input(“请输入a+b:”) #输入:8+9
print(eval(s1)) # 17 可以动态的执行代码. 代码必须有返回值
s2 = “for i in range(5): print(i)”
a = exec(s2) # exec 执行代码不返回任何内容
0
1
2
3
4
print(a) #None
动态执行代码
exec(“”"
def func():
print(" 我是周杰伦")
“”" )
func() #我是周杰伦
code1 = “for i in range(3): print(i)”
com = compile(code1, “”, mode=“exec”) # compile并不会执行你的代码.只是编译
exec(com) # 执行编译的结果
0
1
2
code2 = “5+6+7”
com2 = compile(code2, “”, mode=“eval”)
print(eval(com2)) # 18
code3 = “name = input(‘请输入你的名字:’)” #输入:hello
com3 = compile(code3, “”, mode=“single”)
exec(com3)
print(name) #hello
输入输出
print() : 打印输出
input() : 获取用户输出的内容
print(“hello”, “world”, sep="“, end=”@") # sep:打印出的内容用什么连接,end:以什么为结尾
#helloworld@
内存相关
hash() : 获取到对象的哈希值(int, str, bool, tuple). hash算法:(1) 目的是唯一性 (2) dict 查找效率非常高, hash表.用空间换的时间 比较耗费内存
s = 'alex’print(hash(s)) #-168324845050430382lst = [1, 2, 3, 4, 5]print(hash(lst)) #报错,列表是不可哈希的 id() : 获取到对象的内存地址s = 'alex’print(id(s)) #2278345368944
文件操作相关
open() : 用于打开一个文件, 创建一个文件句柄
f = open(‘file’,mode=‘r’,encoding=‘utf-8’)
f.read()
f.close()
模块相关
__ import__() : 用于动态加载类和函数
让用户输入一个要导入的模块
import os
name = input(“请输入你要导入的模块:”)
import(name) # 可以动态导入模块
帮 助
help() : 函数用于查看函数或模块用途的详细说明
print(help(str)) #查看字符串的用途
调用相关
callable() : 用于检查一个对象是否是可调用的. 如果返回True, object有可能调用失败, 但如果返回False. 那调用绝对不会成功
a = 10
print(callable(a)) #False 变量a不能被调用
def f():
print(“hello”)
print(callable(f)) # True 函数是可以被调用的
查看内置属性
dir() : 查看对象的内置属性, 访问的是对象中的__dir__()方法
print(dir(tuple)) #查看元组的方法