【JavaScript】闭包典型应用用及性能问题
引言
之前发了一篇文章,写了对于闭包的理解,现在补上闭包的应用篇和性能问题,有关闭包会造成内存泄露的说法也会在本文中一一解释。
全文概要
1 应用
以下这几个方面是我们开发中最为常用到的,同时也是面试中回答比较稳的几个方面。
1.1 模拟私有变量
我们都知道JS是基于对象的语言,JS强调的是对象,而非类的概念,在ES6中,可以通过class关键字模拟类,生成对象实例。
class User {
// 构造函数 -- 初始化实例化对象属性
constructor(name) {
this.name = name
}
// 添加方法
sayHi() {
console.log('你好,我是'+this.name)
}
}
// 使用 new 关键字来创建实例
let user = new User('小明')
user.sayHi()
通过class模拟出来的类,仍然无法实现传统面向对象语言中的一些能力 —— 比如私有变量的定义和使用。
Js中没有private关键字,也没有私有成员的概念,所有的对象属性都是共有的。
我们通过看这样一个User类来了解私有变量(伪代码,不能直接运行)
class User{
constructor(username,password){
// 用户名
this.username = username
// 密码
this.password = password
}
login(){
// 使用axious进行登录请求
axios({
method: 'GET',
url: 'http://127.0.0.1/server',
params: {
username,
password
},
}).then(response => {
console.log(response);
});
}
}
在这个User类里,我们定义了一些属性,和一个login方法,我们尝试输出password这个属性。
let user = new User('小明',123456)
user.password // 123465
我们发现,登录密码这么关键敏感的信息,竟然可以通过一个简单的属性就可以拿到,这就意味着,后面人只有拿到user这个对象,就可以非常轻松的获取,甚至改写他的密码。 在实际的业务开发中,这是一个非常危险的操作,我们需要从代码的层面保护password。
像password这样变量,我们希望它只在函数内部,或者对象内部方法访问到,外部无法触及。 这样的变量,就是私有变量,通常情况下私有变量使用 _ 或双 _ 作为前缀定义。
在类里声明变量的私有性,我们可以借助闭包实现,我们的思路就是把我们把私有变量放在最外层立即执行函数中,并通过立即执行User这个函数,创造了一个闭包作用域的环境。
// 利用IIFE生成闭包,返回user类
const User = (function () {
// 定义私有变量_password
let _password
class User {
constructor(username, password) {
// 初始化私有变量_password
_password = password
this.username = username
}
login() {
console.log(this.username, _password)
}
}
return User
})()
let user = new User('小明',123465)
console.log(user.username); // 小明
console.log(user.password); // undefined
console.log(user._password); //undefined
user.login(); // 小明 undefined
在这段代码中,私有变量_password被好好的保护在User这个立即执行函数内部,此时实例暴露的属性已经没有_password,通过闭包,我们成功利用了自由变量模拟私有变量的效果。
1.2 柯里化
定义一个函数,该函数返回一个函数。 柯里化是把接收 n个参数的1个函数改造为只接收1个参数的n个互相嵌套的函数的过程。也就是从fn(a,b,c)变成fn(a)(b)(c)。
我们通过以下案例进行深入理解:以慕课网为例,我们使用site(站点)、type(课程类型)、name(课程名称)三个字符串拼接的方式为课程生成一个完整版名称。对应方法如下:
function generateName(site,type,name){
return site + type + name
}
我们看到这个函数需要传递三个参数,此时如果我是课程运营负责人,如我只负责“体系课”的业务,那么我每次生成课程时,都会固定传参site,像这样传参:
generateName('体系课',type,name)
如果我是细分工种的前端助教,我仅仅负责“体系课”站点下的“前端”课程,那么我进行传参就是这样:
generateName('体系课','前端',name)
我们不难发现,调用generateName时,真正的变量只有一个,但是我每次不得不把前两个参数手动传一遍。此时,我们的柯里化就出现了,柯里化可以帮助我们在必要情况下,记住一部分参数。
function generateName(site){
// var site = '体系课'
return function(type){
// var type = '前端'
return function(name){
// var name = '零基础就业班'
return prefix + type + name
}
}
}
// 生成体系课专属函数
var salesName = generateName('体系课');
// “记住”site,生成体系课前端课程专属函数
var salesBabyName = salesName('前端')
// 输出 '体系课前端零基础就业班'
res = salesBabyName('零基础就业班')
console.log(res)
我们可以看到,在生成体系课专属函数中,我们将site作为实参传递给generateName函数中,将site的值保留在generateName内部作用域中。
在生成体系课前端课程函数中,将type的值保留在salesBabyName函数中,最终调用salesBabyName函数,输出。
这样一来,原有的generateName (site, type, name)函数经过柯里化变成了generateName(site)(type)(name)。通过后者这种形式,我们可以记住一部分形参,选择性的传递参数,从而编写出更符合预期,复用性更高的函数。
function generateName(site){
// var site = '实战课'
return function(type){
// var type = 'Java'
return function(name){
// var name = '零基础'
return site + type + name
}
}
}
// "记住“site和type,生成实战课java专属函数
var shiZhanName = generateName('实战课')('Java')
console.log(shiZhanName);
// 输出 '实战课java零基础'
var res = shiZhanName('零基础')
console.log(res)
// 啥也不记,直接生成一个完整课程
var itemFullName = generateName('实战课')('大数据')('零基础')
console.log(itemFullName);
1.3 偏函数
偏函数和柯里化类似,柯里化是将一个n个参数的函数转化成n个单参数函数,这里假如你有三个入参,你得嵌套三层函数,且每层函数只能有一个入参。柯里化的目标是把函数拆解为精准的n部分。
偏函数相比之下就比较随意了,偏函数是固定函数中的某一个或几个参数,然后返回一个新的函数。假如你有三个入参,你可以只固定一个入参,然后返回另一个入参函数。也就是说,偏函数不强调 “单参数” 这个概念。
仍然是上面的例子,原函数形式调用:
function generateName(site,type,name){
return site + type + name;
}
// 调用时传入三个参数
var itemFullName = generateName('体系课', '前端', '2022')
偏函数改造:
function generateName(site){
return function(type,name){
return site + type + name
}
}
// 把3个参数分两部分传入
var itemFullName = generateName('体系课')('前端', '2022')
1.4 防抖
在浏览器的各种事件中,有一些容易频繁触发的事件,比如scroll、resize、鼠标事件(比如 mousemove、mouseover)、键盘事件(keyup、keydown )等。频繁触发回调导致大量的计算会引发页面抖动甚至卡顿,影响浏览器性能。防抖和节流就是控制事件触发的频率的两种手段。
防抖的中心思想是:在某段时间内,不管你触发了多少次回调,我都只执行最后一次。
// fn是我们需要包装的事件回调, delay是每次推迟执行的等待时间
function debounce(fn, delay) {
// 定时器
let timer = null
// 将debounce处理结果当作函数返回
return function () {
// 保留调用时的this上下文
let context = this
// 保留调用时传入的参数
let args = arguments
// 每次事件被触发时,都去清除之前的旧定时器
if(timer) {
clearTimeout(timer)
}
// 设立新定时器
timer = setTimeout(function () {
fn.apply(context, args)
}, delay)
}
}
// 用debounce来包装scroll的回调
const better_scroll = debounce(() => console.log('触发了滚动事件'), 1000)
document.addEventListener('scroll', better_scroll)
1.5 节流
节流的中心思想是:在某段时间内,不管你触发了多少次回调,我都只认第一次,并在计时结束时给予响应,也就是隔一段时间执行一次。
// fn是我们需要包装的事件回调, interval是时间间隔的阈值
function throttle(fn, interval) {
// last为上一次触发回调的时间
let last = 0
// 将throttle处理结果当作函数返回
return function () {
// 保留调用时的this上下文
let context = this
// 保留调用时传入的参数
let args = arguments
// 记录本次触发回调的时间
let now = +new Date()
// 判断上次触发的时间和本次触发的时间差是否小于时间间隔的阈值
if (now - last >= interval) {
// 如果时间间隔大于我们设定的时间间隔阈值,则执行回调
last = now;
fn.apply(context, args);
}
}
}
// 用throttle来包装scroll的回调
const better_scroll = throttle(() => console.log('触发了滚动事件'), 1000)
document.addEventListener('scroll', better_scroll)
2 性能问题
以上我们讲解了闭包的常见应用,可见闭包是一个非常强大的特性,但人们对其也有诸多误解。一种耸人听闻的说法是闭包会造成内存泄露,所以要尽量减少闭包的使用。真的是这样吗?
2.1 内存泄漏
内存泄露是指你「用不到」(访问不到)的变量,依然占居着内存空间,不能被再次利用起来。
闭包里的变量是我们需要的变量,而又怎么称之为内存泄漏呢?
所以有关内存泄露问题,是谣言,是误传。
这个误传来源于IE,因为使用闭包时可能比较容易形成循环引用,如果闭包的作用域链中保存着一些DOM节点,这时候就造成内存泄漏,但这并不是闭包问题,而这是IE的bug。
因为IE浏览器基于引用计数策略的垃圾回收机制中,如果两个对象之间形成了循环引用,那么这两个对象都无法被回收。
如果要解决循环引用带来的内存泄露问题,只需要把循环引用中的变量设为null即可,也就是在函数调用后,可以把外部引用关系置空,如下:
function f1(){
var num = Math.randon();
function f2(){
return num
}
return f2
}
var f = f1();
f();
// 置空引用关系
f = null;
所以,闭包导致的内存泄漏是误传。闭包中引用的变量,其实也就相当于一个全局变量,并不会构成内存泄漏问题,内存泄漏大多原因是由于代码不规范导致。
2.2 常见的内存泄漏
2.21 不必要的全局变量
function f1() {
name = '小明'
}
在非严格模式下引用未声明的变量,会在全局对象中创建一个新变量,在浏览器中,全局对象是window,这就意味着name这个变量将泄漏到全局。全局变量是在网页关闭时才会释放,这样的变量一多,内存压力也会随之增高。
2.22 遗忘清理的计时器
程序中我们经常会用到计时器,也就是setInterval和setTimeout
var timeId = setInterval(function(){
// 函数体
},1000)
在计时器中,定时器内部逻辑是是无穷无尽的,当定时器囊括的函数逻辑不再被需要、而我们又忘记手动清除定时器时,它们就会永远保持对内存的占用。因此当我们使用定时器时,一定要明确计时器在何时会被清除,并使用 clearInterval(timeId)手动清除定时器。
2.23 遗忘清理的dom元素引用
var divObj = document.getElementById('mydiv')
// dom删除myDiv
document.body.removeChild(divObj);
console.log(divObj);
// 能console出整个div 说明没有被回收,引用存在
// 移出引用
divObj = null;
console.log(divObj)
// null
3 闭包与循环体
闭包和循环体的结合,是闭包最为经典的一种考察方式。
3.1 这段代码输出啥
我们来看一个大家非常熟悉的题目,以上6行代码输出什么?
for(var i=0; i<5; i++){
setTimeout(function(){
console.log(i)
},1000)
}
console.log(i)
如果你是刚入门的新手,你可能会给出这样的答案:
0 1 2 3 4 5
给出这样答案的同学,内心一般都是这样想:for循环输出了0-4个i的值,最后一行打印5,setTimeout这个好像在哪见过,但具体咋回事印象不深了,干脆直接忽略好了。
对于基础还不错的同学,对于setTimeout函数用法特性还有印象,很快就给出了“进化版”答案:
5 0 1 2 3 4
这一部分的同学是这样想的:for循环逐个输出0-4的值,但是setTimeout把输入延迟了1s,所以最后一行先执行,先输出5,然后过了1000ms,0-4会逐个输出。
如果你对JS中的for循环、同步与异步区别、变量作用域、闭包有正确理解,就知道正确答案应该是:
5 5 5 5 5 5
我们试着分析一下正确答案,seTimeout内函数延迟1000ms后执行,最后一行console先输出,最后一行输出5,所以第一个值是5。
for(var i =0;i<5;i++){
// 5<5? 不满足
}
console.log(i) // 5
for循环里setTimeout执行了5次,函数延迟1000ms执行,大家看这个函数,它自身作用域压根就没有i这个变量,根据作用域链查找规则,要想输出i,需要去上层查找。
for(var i=0; i<5; i++){
setTimeout(function() {
console.log(i);
}, 1000);
}
但是,这个函数第一次被执行也是1000ms以后的事情了,此时它试图向上一层作用域(这里也就是全局作用域)去找一个叫i的变量,此时for循环已执行完毕,i也进入了最终状态5。所以当1000ms后,这个函数真正被执行的时候,引用到的i值已经是5了。 此时,这段代码的作用域状态示意如下:

对应的作用域关系如下:
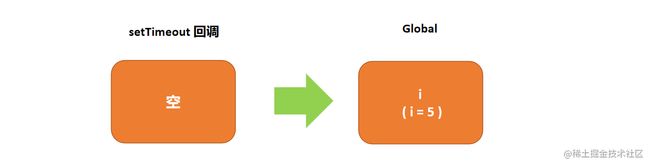
接下来的连续四次,都会有一个一模一样的setTimeout回调被执行,它输出的也是同一个全局的i,所以说每一次输出都是5。
3.2 改造方法
循环了五次,每次却输出一个值,这种输出效果显然不好。如果我们希望让i从0-4依次被输出,我们改如何改造呢?
方案一:利用setTimeout中第三个参数
开头我们先复习一下setTimeout参数用法:
setTimeout(function(arg1,arg2){
console.log(arg1);
console.log(arg2);
},delay,arg1,arg2)
- function(必须):调用函数执行的代码块
- delay(可选):函数调用延迟的毫秒值,默认是0,意味着马上执行
- arg1,…arg2(可选):附加参数,当计时器启动时,会作为参数传递给function
我们来看例子:
setTimeout(function(a,b){
console.log(a); // 1
console.log(b); // 2
},1000,1,2)
需要注意的一点是,附加参数只支持在ie9及以上浏览器,如要兼容,需要引入一段MDN提供的兼容旧IE代码。
利用setTimeout的第三个参数,i作为形参传递给setTimeout的j,由于每次传入的参数是从for循环里面取到的值,所以会依次输出0~4:
for(var i=0; i<5; i++){
setTimeout(function(j){
console.log(j) // 0 1 2 3 4
},1000,i)
}
方案二:使用闭包
使用闭包,我们往往会用到匿名函数。匿名函数也叫一次性函数,在函数定义时执行,且只执行一次。我们在setTimeout外面套一个匿名函数,利用匿名函数的实参来缓存每一个循环的i值。
for(var i= 0; i<5; i++){
(function(j){
setTimeout(function(){
console.log(j)
},1000)
})(i)
}
当输出j时,引用的是外部函数传递的变量i,这个i是根据循环来的,执行setTimeout时已经确定了里面i的值,进而确定了j的值。
方案三:使用let
for(let i= 0; i<5; i++){
setTimeout(function(){
console.log(i)
},1000)
}
for循环每次循环产生一个新的块级作用域,每个块级作用域的变量是不同的。函数输出的是自己的上一级(循环产生的块级作用域)下i的值。
4 总结
- 作用:模拟私有变量、柯里化、偏函数、防抖、节流、实现缓存。
- 模拟私有变量:将私有变量放在外在的立即执行函数中,并通过立即执行U这个函数,创造一个闭包环境(私有变量:只允许函数内部,或对象方法访问的变量)。
- 柯里化:把接受n个参数的一个函数转化成只接受一个参数n个函数互相嵌套的函数过程,目标是把函数拆解为精准的n部分,也就是将
fn(a,b,c)转化成fn(a)(b)(c)的过程。 - 偏函数:固定函数中的某一个或几个参数,然后返回一个新的函数,不强调但函数。
- 防抖:只执行最后一次。
- 节流:隔一段时间执行一次。
- 缓存变量:计时器打印问题。
- 内存泄漏:你用不到的变量(访问不到的变量)依然占据着内存空间。
- 闭包造成内存泄漏是误传,误传由于早期IE垃圾回收机机制是基于基于引用计数法,闭包当中如果包含循环引用,那么IE浏览器无法回收闭包中引用的变量,但这内存泄漏和闭包没有关系,而是IE的bug。
出的是自己的上一级(循环产生的块级作用域)下i的值。