Java的序列化和反序列化及其在项目中的使用
目录
什么是Java序列化?
为什么需要序列化?
序列化用途
Java序列化常用API
Serializable 接口
Externalizable 接口
ObjectOutputStream类
ObjectInputStream类
序列化的使用
使用ObjectOutputStream类的writeObject方法,对Student对象实现序列化
使用ObjectInputStream类的readObject方法,实现反序列化,重新生成student对象
序列化底层原理
Serializable底层
序列化使用的方法
日常开发序列化的注意点
static静态变量和transient关键字修饰的字段是不会被序列化的
transient关键字
serialVersionUID的作用
如果序列化类的成员变量是对象类型,则该对象类型的类必须被序列化
子类实现Serializable接口,父类如果没有实现Serializable接口,父类不会被序列化
序列化和反序列化的对单例破坏的防止及其原理
使用序列化与反序列化实现深拷贝
深拷贝的两种实现方式
序列化的方式实现深拷贝:
项目中的使用
商品详情页动态内容展示实现的操作:
Jackson框架的使用
序列化常见面试题
1.序列化的底层是怎么实现的?
2.序列化时,如何让某些成员不要序列化?
3.在 Java 中,Serializable 和 Externalizable 有什么区别
4.serialVersionUID有什么用?
5.是否可以自定义序列化过程, 或者是否可以覆盖 Java 中的默认序列化过程?
6.在 Java 序列化期间,哪些变量未序列化?
巨人的肩膀
什么是Java序列化?
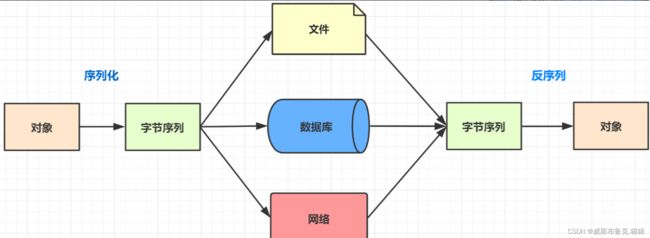
- 序列化:把Java对象转换为字节序列的过程
- 反序列:把字节序列恢复为Java对象的过程
为什么需要序列化?
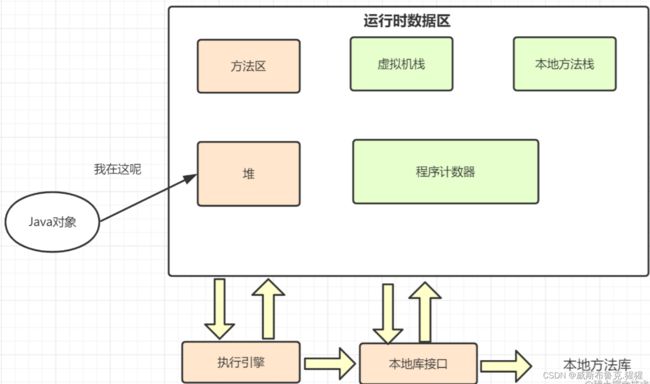
Java对象是运行在JVM的堆内存中的,如果JVM停止后,它的生命也就戛然而止。
如果想在JVM停止后,把这些对象保存到磁盘或者通过网络传输到另一远程机器,怎么办呢?磁盘这些硬件可不认识Java对象,它们只认识二进制这些机器语言,所以就要把这些对象转化为字节数组,这个过程就是序列化。
对象的序列化是非常有趣的,因为利用它可以实现轻量级持久性,“持久性”意味着一个对象的生存周期不单单取决于程序是否正在运行,它可以生存于程序的调用之间。通过将一个序列化对象写入磁盘,然后在重新调用程序时恢复该对象,从而达到实现对象的持久性的效果。
业务场景:
- 当想把的内存中的对象状态保存到一个文件中或者数据库中时候。
- 当想用套接字在网络上传送对象的时候。
- 当想通过RMI传输对象的时候。
不同进程/程序间进行远程通信时,可以相互发送各种类型的数据,包括文本、图片、音频、视频等,而这些数据都会以二进制序列的形式在网络上传送。
当两个Java进程进行通信时,进程间的对象传送就需要使用Java序列化与反序列化了。发送方需要把这个Java对象转换为字节序列,然后在网络上传输,接收方则需要将字节序列中恢复出Java对象。
序列化用途
序列化使得对象可以脱离程序运行而独立存在,它主要有两种用途:

- 1) 序列化机制可以让对象地保存到硬盘上,减轻内存压力的同时,也起了持久化的作用;
比如 Web服务器中的Session对象,当有 10+万用户并发访问的,就有可能出现10万个Session对象,内存可能消化不良,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
- 2) 序列化机制让Java对象在网络传输不再是天方夜谭。
在使用远程调用服务框架时,需要把传输的Java对象实现Serializable接口,即让Java对象序列化,因为这样才能让对象在网络上传输。
Java序列化常用API
java.io.ObjectOutputStream
java.io.ObjectInputStream
java.io.Serializable
java.io.ExternalizableSerializable 接口
Serializable接口是一个标记接口,没有方法或字段。一旦实现了此接口,就标志该类的对象就是可序列化的。

Externalizable 接口
Externalizable继承了Serializable接口,还定义了两个抽象方法:writeExternal()和readExternal(),如果开发人员使用Externalizable来实现序列化和反序列化,需要重写writeExternal()和readExternal()方法。

ObjectOutputStream类
表示对象输出流,它的writeObject(Object obj)方法可以对指定obj对象参数进行序列化,再把得到的字节序列写到一个目标输出流中。
ObjectInputStream类
表示对象输入流, 它的readObject()方法,从输入流中读取到字节序列,反序列化成为一个对象,最后将其返回。
序列化的使用
主要步骤:
- 声明一个实体类,实现Serializable接口
- 使用ObjectOutputStream类的writeObject方法,实现序列化
- 使用ObjectInputStream类的readObject方法,实现反序列化
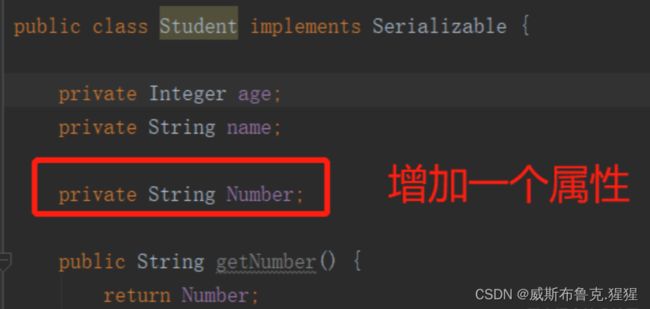
public class Student implements Serializable {
private Integer age;
private String name;
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}使用ObjectOutputStream类的writeObject方法,对Student对象实现序列化
把Student对象设置值后,写入一个文件,即序列化
ObjectOutputStream objectOutputStream = new ObjectOutputStream( new FileOutputStream("D:\\text.out"));
Student student = new Student();
student.setAge(25);
student.setName("jayWei");
objectOutputStream.writeObject(student);
objectOutputStream.flush();
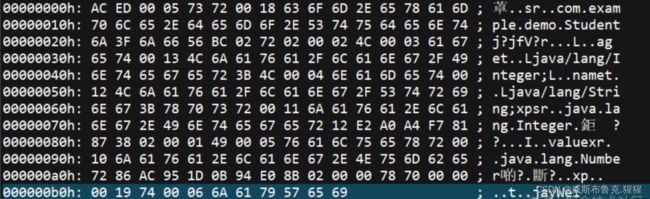
objectOutputStream.close();序列化后的文件内容如下(使用UltraEdit打开)
使用ObjectInputStream类的readObject方法,实现反序列化,重新生成student对象
再把文件读取出来,反序列化为Student对象
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("D:\\text.out"));
Student student = (Student) objectInputStream.readObject();
System.out.println("name="+student.getName());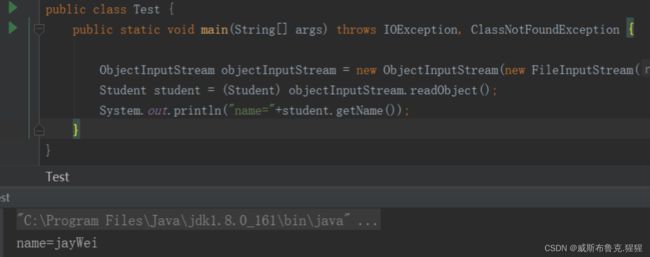
序列化底层原理
Serializable底层
Serializable接口,只是一个空的接口,没有方法或字段,为什么这么神奇,实现了它就可以让对象序列化了?
为了验证Serializable的作用,把以上demo的Student对象,去掉实现Serializable接口,看序列化过程怎样

序列化过程中抛出异常啦,堆栈信息如下:
 顺着堆栈信息看一下,有重大发现,如下:
顺着堆栈信息看一下,有重大发现,如下:
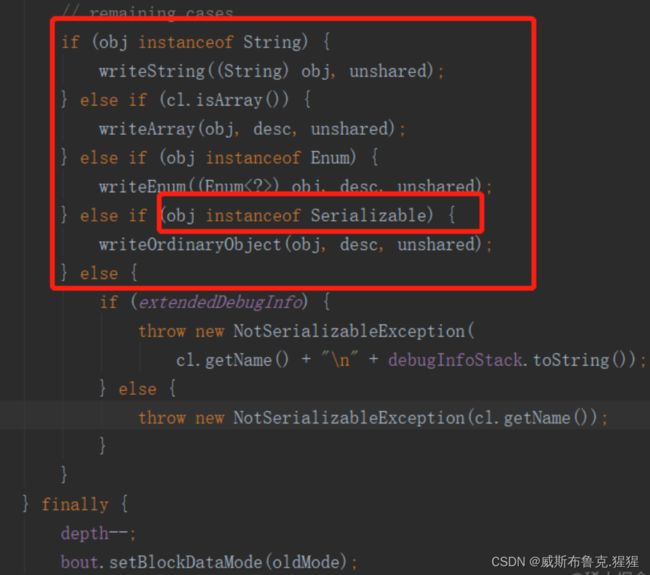
底层原理: ObjectOutputStream 在序列化的时候,会判断被序列化的Object是哪一种类型,String / array / enum还是 Serializable,如果都不是的话,抛出 NotSerializableException异常。所以,Serializable真的只是一个标志,一个序列化标志
序列化使用的方法
writeObject(Object)
 此方法的源码分析看这篇文章:
此方法的源码分析看这篇文章:
打开writeObject方法的源码看一下,发现方法中有这么一个逻辑,当要写入的对象是String、Array、Enum、Serializable类型的对象则可以正常序列化,否则会抛出NotSerializableException异常。
这就能解释为什么Java序列化一定要实现Serializable接口了。
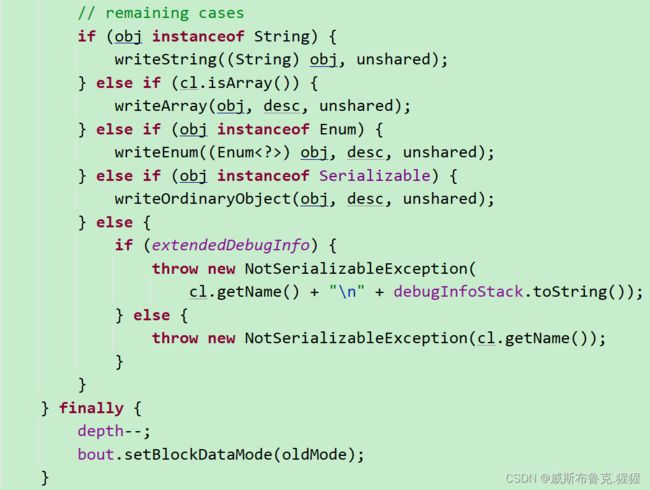
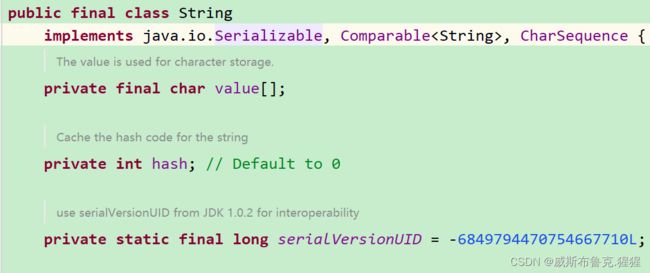
String为啥就不用实现Serializable接口呢?其实String已经内部实现了Serializable,不用再显示实现;看源码:
Java程序员必备:序列化全方位解析 - 掘金
日常开发序列化的注意点
- static静态变量和transient 修饰的字段是不会被序列化的
- serialVersionUID问题
- 如果某个序列化类的成员变量是对象类型,则该对象类型的类必须实现序列化
- 子类实现了序列化,父类没有实现序列化,父类中的字段丢失问题
static静态变量和transient关键字修饰的字段是不会被序列化的
public class Student implements Serializable {
private Integer age;
private String name;
public static String gender = "男";
transient String specialty = "计算机专业";
public String getSpecialty() {
return specialty;
}
public void setSpecialty(String specialty) {
this.specialty = specialty;
}
@Override
public String toString() {
return "Student{" +"age=" + age + ", name='" + name + '\'' + ", gender='" + gender + '\'' + ", specialty='" + specialty + '\'' +
'}';
}
......打印学生对象,序列化到文件,接着修改静态变量的值,再反序列化,输出反序列化后的对象
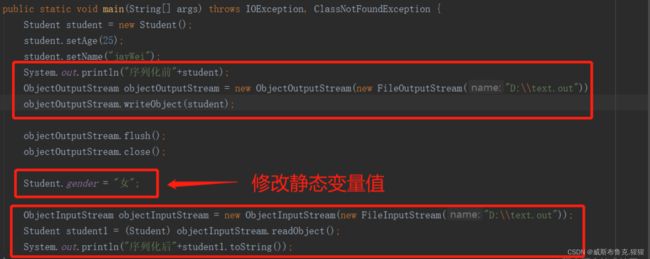
运行结果:
序列化前Student{age=25, name='jayWei', gender='男', specialty='计算机专业'} 序列化后Student{age=25, name='jayWei', gender='女', specialty='null'}
对比结果发现:
- 1)序列化前的静态变量性别明明是‘男’,序列化后再在程序中修改,反序列化后却变成‘女’了,显然这个静态属性并没有进行序列化。其实,静态(static)成员变量是属于类级别的,而序列化是针对对象的;所以不能序列化。
- 2)经过序列化和反序列化过程后,specialty字段变量值由'计算机专业'变为空了;其实是因为transient关键字,它可以阻止修饰的字段被序列化到文件中,在被反序列化后,transient 字段的值被设为初始值,比如int型的值会被设置为 0,对象型初始值会被设置为null。
transient关键字
序列化对象时如果希望哪个属性不被序列化,则用transient关键字修饰即可
serialVersionUID的作用
serialVersionUID 表面意思就是序列化版本号ID,其实每一个实现Serializable接口的类,都有一个表示序列化版本标识符的静态变量,或者默认等于1L,或者等于对象的哈希码。
private static final long serialVersionUID = -6384871967268653799L;JAVA序列化的机制是通过判断类的serialVersionUID来验证版本是否一致的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID和本地相应实体类的serialVersionUID进行比较,如果相同,反序列化成功,如果不相同,就抛出InvalidClassException异常。
接下来验证一下,修改一下Student类,再反序列化操作
Exception in thread "main" java.io.InvalidClassException: com.example.demo.Student;
local class incompatible: stream classdesc serialVersionUID = 3096644667492403394,
local class serialVersionUID = 4429793331949928814
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:687)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1876)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1745)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2033)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1567)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:427)
at com.example.demo.Test.main(Test.java:20)从日志堆栈异常信息可以看到,文件流中的class和当前类路径中的class不同了,它们的serialVersionUID不相同,所以反序列化抛出InvalidClassException异常。那么,如果确实需要修改Student类,又想反序列化成功,可以手动指定serialVersionUID的值,一般可以设置为1L或者让编辑器IDE生成。
![]()
本质:
序列化对象时,如果不显示的设置serialVersionUID,Java在序列化时会根据对象属性自动的生成一个serialVersionUID,再进行存储或用作网络传输。
在反序列化时,会根据对象属性自动再生成一个新的serialVersionUID,和序列化时生成的serialVersionUID进行比对,两个serialVersionUID相同则反序列化成功,否则就会抛异常。
而当显示的设置serialVersionUID后,Java在序列化和反序列化对象时,生成的serialVersionUID都为我们设定的serialVersionUID,这样就保证了反序列化的成功。
阿里开发手册,强制要求序列化类新增属性时,不能修改serialVersionUID字段

如果序列化类的成员变量是对象类型,则该对象类型的类必须被序列化
给Student类添加一个Teacher类型的成员变量,其中Teacher是没有实现序列化接口的
public class Student implements Serializable {
private Integer age;
private String name;
private Teacher teacher;
...
}
//Teacher 没有序列化
public class Teacher {
......
}序列化运行,就报NotSerializableException异常
Exception in thread "main" java.io.NotSerializableException: com.example.demo.Teacher at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1184) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178) at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348) at com.example.demo.Test.main(Test.java:16)
其实这个可以在上小节的底层源码分析找到答案,一个对象序列化过程,会循环调用它的Object类型字段,递归调用序列化的,也就是说,序列化Student类的时候,会对Teacher类进行序列化,但是对Teacher没有实现序列化接口,因此抛出NotSerializableException异常。所以如果某个实例化类的成员变量是对象类型,则该对象类型的类必须实现序列化

子类实现Serializable接口,父类如果没有实现Serializable接口,父类不会被序列化
子类Student实现了Serializable接口,父类User没有实现Serializable接口
//父类实现了Serializable接口
public class Student extends User implements Serializable {
private Integer age;
private String name;
}
//父类没有实现Serializable接口
public class User {
String userId;
}
Student student = new Student();
student.setAge(25);
student.setName("jayWei");
student.setUserId("1");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("D:\\text.out"));
objectOutputStream.writeObject(student);
objectOutputStream.flush();
objectOutputStream.close();
//反序列化结果
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("D:\\text.out"));
Student student1 = (Student) objectInputStream.readObject();
System.out.println(student1.getUserId());
//output
/**
* null
*/从反序列化结果可以发现,父类属性值丢失了。因此子类实现了Serializable接口,父类没有实现Serializable接口的话,父类不会被序列化。
序列化和反序列化的对单例破坏的防止及其原理
首先我们来看一下序列化和反序列化是怎么破坏单例的。看代码
 这里我们使用之前的饿汉式的单例作为例子。在之前饿汉式的代码上做点小改动。就是让我们的单例类实现 Serializable接口。然后我们在测试类中测试一下怎么破坏。
这里我们使用之前的饿汉式的单例作为例子。在之前饿汉式的代码上做点小改动。就是让我们的单例类实现 Serializable接口。然后我们在测试类中测试一下怎么破坏。
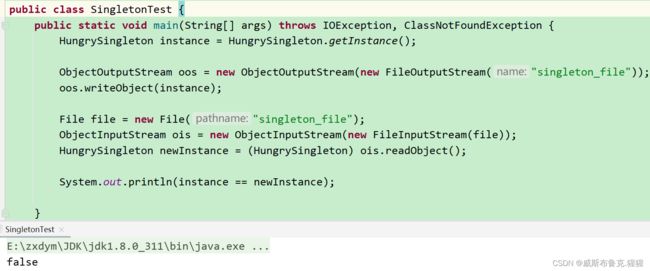 这里首先我们使用正常的方式来获取一个对象。通过序列化将对象写入文件中,然后我们通过反序列化的到一个对象,我们再对比这个对象,输出的内存地址和布尔结果都表示这不是同一个对象。也就说我们通过使用序列化和反序列化破坏了这个单例,那我们该如何防治呢?防治起来很简单,只需要在单例类中添加一个readResolve方法,下面看代码:
这里首先我们使用正常的方式来获取一个对象。通过序列化将对象写入文件中,然后我们通过反序列化的到一个对象,我们再对比这个对象,输出的内存地址和布尔结果都表示这不是同一个对象。也就说我们通过使用序列化和反序列化破坏了这个单例,那我们该如何防治呢?防治起来很简单,只需要在单例类中添加一个readResolve方法,下面看代码:

这样就防止了序列化对单例模式的破坏

返回的就是一个newInstance是通过反射拿到的对象,既然是反射拿到的对象自然是一个新的对象,这就弄明白了为什么序列化获取的是一个新的对象。
底层通过反射方式调用readResolve方法名来调用readResolve方法,本质上还是通过反射破坏单例模式的封装性。
序列化和反序列化的对单例破坏的防止及其原理 - 掘金
使用序列化与反序列化实现深拷贝
深拷贝:在进行赋值之前,为指针类型的数据成员另辟了一个独立的内存空间,实现真正内容上的拷贝 。这种拷贝称为深拷贝。
深拷贝的两种实现方式
- 实现Cloneable接口,重写Object类中clone()方法,实现层层克隆的方法。
- 通过序列化(Serializable)的方法,将对象写到流里,然后再从流中读取出来。虽然这种方法效率很低,但是这种方法才是真正意义上的深度克隆。
序列化的方式实现深拷贝:
先构造一个学生对象。值得注意的是,被序列化的对象的类同样也必须要实现Serializable接口,否则将会抛出NotSerializableException异常。
public class Student implements Serializable{
private String name;
private String address;
private String sex;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", address='" + address + '\'' +
", sex='" + sex + '\'' +
'}';
}
}然后创建实现深拷贝的类StudentClone

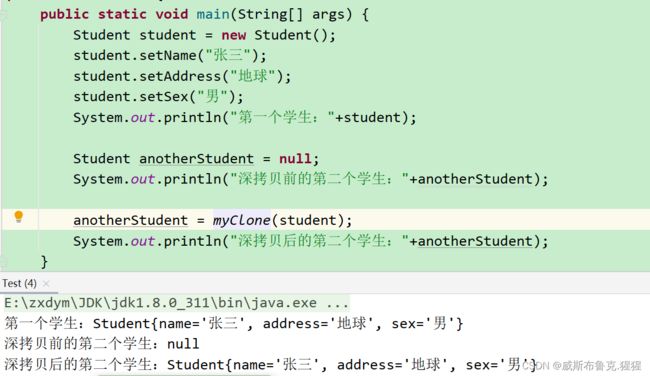
测试方法就是创建一个student对象和一个空对象,通过调用拷贝方法将student的属性深拷贝到anotherStudnet。
使用序列化与反序列化实现深拷贝 - 掘金----这篇把序列化方式深拷贝讲的好
5张图搞懂Java引用拷贝、浅拷贝、深拷贝 - 掘金---这篇棒,把深浅拷贝讲的很清楚
项目中的使用
商品详情页动态内容展示实现的操作:




将商品展示页面的Java对象数据序列化为字节序列的格式以便于保存到Redis数据库中, 并且将日期序列化为自定义的指定格式。Redis中的key是String类型数据,value是Json数据类型。


第一次刷新不会出现上面的错误,因为是直接从数据库中取的;第二次刷新错误报这个错误的原因是对下面的字节序列反序列化不了,因为解析不了对应的参数

加入一行代码:
//可以在序列化的字节序列中包含类信息,以便于反序列化的时候JVM咋样解析参数
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);可以看到此时的字节序列中多了类的信息,加入这行代码的作用就是为了告诉JVM咋样去解析对应的参数;此时,无论刷新多少次都是从缓存(Redis)里取的

Jackson框架的使用
Redis中的key是String类型数据,value是Json数据类型;对于json数据的处理,项目中使用到了Jackson框架;JSON数据处理框架,并不依赖于任何的Spring 库。它提供了很多的JSON数据处理方法、注解,也包括流式API、树模型、数据绑定,以及复杂数据类型转换等功能;虽然简单易用。
JSON数据处理框架Jackson精解第一篇-序列化与反序列化核心用法 - 掘金
Jackson 之 LocalDateTime 序列化与反序列化 - 掘金
项目中关于序列化这部分的主要类是这三个

Jackson框架:
JSON数据处理框架Jackson精解第一篇-序列化与反序列化核心用法 - 掘金
URL及日期等特殊数据格式处理-JSON框架Jackson精解第2篇 - 掘金
属性序列化自定义与字母表排序-JSON框架Jackson精解第3篇 - 掘金
Jackson精解第4篇-@JacksonInject与@JsonAlias注解 - 掘金
@JsonCreator自定义反序列化函数-JSON框架Jackson精解第5篇 - 掘金
Jaskson精讲第6篇-自定义JsonSerialize与Deserialize实现数据类型转换 - 掘金
Jackson精讲第7篇-类继承关系下的JSON序列化与反序列化JsonTypeInfo - 掘金
序列化常见面试题
- 序列化的底层是怎么实现的?
- 序列化时,如何让某些成员不要序列化?
- 在 Java 中,Serializable 和 Externalizable 有什么区别
- serialVersionUID有什么用?
- 是否可以自定义序列化过程, 或者是否可以覆盖 Java 中的默认序列化过程?
- 在 Java 序列化期间,哪些变量未序列化?
1.序列化的底层是怎么实现的?
如回答Serializable关键字作用,序列化标志,源码中,它的作用,还有,可以回答writeObject几个核心方法,如直接写入基本类型,获取obj类型数据,循环递归写入
2.序列化时,如何让某些成员不要序列化?
可以用transient关键字修饰,它可以阻止修饰的字段被序列化到文件中,在被反序列化后,transient 字段的值被设为初始值,比如int型的值会被设置为 0,对象型初始值会被设置为null。
3.在 Java 中,Serializable 和 Externalizable 有什么区别
Externalizable继承了Serializable,提供 writeExternal() 和 readExternal() 方法, 程序员可以控制 Java的序列化机制, 不依赖于Java的默认序列化。正确实现 Externalizable 接口可以显著提高应用程序的性能。
4.serialVersionUID有什么用?
JAVA序列化的机制是通过判断类的serialVersionUID来验证版本是否一致的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID和本地相应实体类的serialVersionUID进行比较,如果相同,反序列化成功,如果不相同,就抛出InvalidClassException异常。
5.是否可以自定义序列化过程, 或者是否可以覆盖 Java 中的默认序列化过程?
可以的。对于序列化一个对象需调用 ObjectOutputStream.writeObject(saveThisObject), 并用 ObjectInputStream.readObject() 读取对象, 但 Java 虚拟机提供的还有一件事, 是定义这两个方法。如果在类中定义这两种方法, 则 JVM 将调用这两种方法, 而不是应用默认序列化机制。同时,可以声明这些方法为私有方法,以避免被继承、重写或重载。
6.在 Java 序列化期间,哪些变量未序列化?
static静态变量和transient 修饰的字段是不会被序列化的。静态(static)成员变量是属于类级别的,而序列化是针对对象的。transient关键字修字段饰,可以阻止该字段被序列化到文件中。
巨人的肩膀
Java程序员必备:序列化全方位解析 - 掘金-------这篇真的棒
Jackson 之 LocalDateTime 序列化与反序列化 - 掘金-----项目相关
项目项目再搜搜,json序列化到Redis中保存
序列化和反序列化的对单例破坏的防止及其原理 - 掘金
面试官:Java序列化为什么要实现Serializable接口?我懵了 - 掘金
JSON数据处理框架Jackson精解第一篇-序列化与反序列化核心用法 - 掘金
Spring Security OAuth2 缓存使用jackson序列化的处理 - 掘金
redis使用jackson反序列化的坑 - 掘金
使用序列化与反序列化实现深拷贝 - 掘金
序列化和反序列化,你搞懂了吗? - 掘金