李沐论文精读系列一: ResNet、Transformer、GAN、BERT
文章目录
-
- 一、 ResNet
-
- 1.0 摘要,论文导读
- 1.1 导论
-
- 1.1.1 为什么提出残差结构?
- 1.1.2 实验验证
- 1.2 相关工作
- 1.3 实验部分
-
- 1.3.1 不同配置的ResNet结构
- 1.3.2 残差结构效果对比
- 1.3.3 残差结构中,输入输出维度不一致如何处理
- 1.3.4 深层ResNet引入瓶颈结构Bottleneck
- 1.4 代码实现
- 1.5 结论
- 二、Attention is All You Need
-
- 2.0 摘要
- 2.1 结论
- 2.2 导论
- 2.3 背景
- 2.4 模型架构
-
- 2.4.1 编码器和解码器
- 2.4.2 注意力机制
-
- 2.4.2.1 缩放的点积注意力(Scaled Dot-Product Attention)
- 2.4.2.2 多头注意力
- 2.4.2.3 注意力在模型中的应用
- 2.4.3 基于位置的前馈神经网络(Position-wise Feed-Forward Networks)
- 2.4.4 词嵌入和Softmax
- 2.4.5 位置编码(Positional Encoding)
- 2.5 为什么使用自注意力机制
- 2.6 实验(可以跳过)
-
- 2.6.1训练数据和批处理
- 2.6.2 硬件和时间
- 2.6.3 优化器
- 2.6.4 正则化
- 2.6.5 模型配置
- 2.7 评价
- 三、GAN论文精读
-
- 3.0 前言&摘要
- 1.1 导论
- 3.2 相关工作
- 3.3 对抗网络(目标函数及其求解)
-
- 3.3.1 目标函数
- 3.3.2 迭代求解过程
- 3.4 理论结果
-
- 3.4.1 全局最优解 p g = p d a t a p_g=p_{data} pg=pdata
- 3.4.2 收敛证明
- 3.5 GAN的优势与缺陷
- 3.6 代码实现(paddle/pytorch)
- 3.7 总结
- 四、BERT
-
- 4.0 摘要
- 4.1 导论
- 4.2 结论
- 4.3 相关工作
-
- 4.3.1 基于特征的无监督方法
- 4.3.2 无监督的微调方法
- 4.3.3 监督数据中的迁移学习
- 4.4 BERT
-
- 4.4.1 模型结构&输入输出
- 4.4.2 BERT预训练(MLM+NSP)
- 4.4.3 BERT微调
- 4.5 实验
-
- 4.5.1 GLUE数据集(分类)
- 4.5.2 SQuAD v1.1(问答)
- 4.5.3 SQuAD v2.0(问答)
- 4.5.4 SWAG(句子对任务)
- 4.6消融试验
-
- 4.6.1 模型各部分的影响
- 4.6.2 模型配置的影响
- 4.6.3 特征提取
- 4.7 总结
一、 ResNet
论文地址:Deep Residual Learning for Image Recognition
参考:bilibili视频《撑起计算机视觉半边天的ResNet【论文精读】》、动手深度学习《残差网络ResNet》、
博文《ResNet论文笔记》、《ResNet网络结构详解与模型的搭建》
1.0 摘要,论文导读
摘要主要内容:
深度神经网络很难训练,我们使用residual(残差结构)使得网络训练比之前容易很多在ImageNet上使用了152层的ResNet,比VGG多8倍,但是计算复杂度更低,最终赢下了ImageNet2015的分类任务第一名,并演示了如何在cifar-10上训练100-1000层的网络。(通常赢下ImageNet比赛且提出很不一样网络架构、方法的文章会被追捧。)
对很多任务来说,深度是非常重要的。我们仅仅是把之前的网络换成残差网络,在coco数据集上就得到了28%的改进。同样也赢下了ImageNet目标检测、coco目标检测和coco segmentation的第一名。
主要图表:
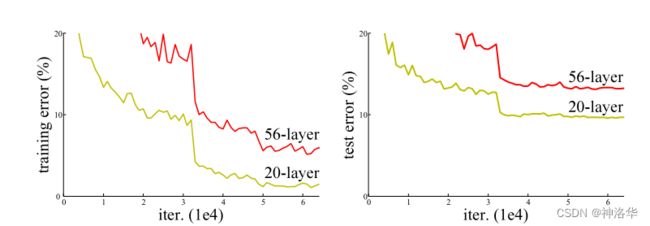
上面这张图是没有使用残差结构的网络,更深的层训练误差比浅层更高,即深层网络其实是训练不动的。下面这张图,是是否使用resnet结构的网络效果对比图。可以看到右侧使用残差结构后,34层的网络训练和测试的误差都更低。
plain ResNet
18 layers 27.94 27.88
34 layers 28.54 25.03
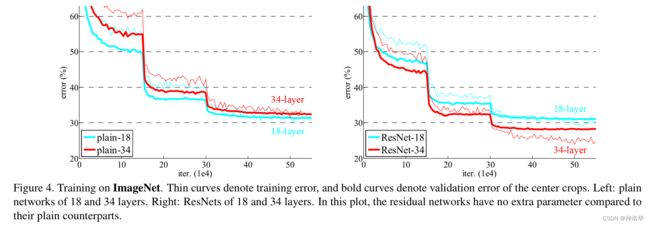
后面还会有不同结构的resnet网络和VGG等其他网络的效果对比图。
1.1 导论
1.1.1 为什么提出残差结构?
深度卷积神经网络是非常有效的,因为可以堆叠很多层,不同层可以表示不同level的特征。但是学一个好的网络,就是简简单单的把所有网络堆在一起就行了吗?如果这样,网络做深就行了。
我们知道,网络很深的时候,容易出现梯度消失或者梯度爆炸,解决办法之一是一个好的网络权重初始化,使权重不能太大也不能太小;二是加入一些normalization,比如BN。这样可以校验每个词之间的输出,以及梯度的均值和方差,这样比较深的网络是可以训练的(可以收敛)。但同时有一个问题是,深层网络性能会变差,也就是精度会变差。
深层网络性能变差,不是因为网络层数多、模型变复杂而过拟合,因为训练误差也变高了。那为什么会这样呢?从理论上来说,往一个浅层网络中加入一些层,得到一个深一些的网络,后者的精度至少不应该变差。因为后者至少可以学成新加的层是identity mapping,而其它层直接从前者复制过来。但是实际上做不到,SGD优化器无法找到这个比较优的解。
identity mapping可以理解成恒等映射吧,也就是网络输入x,输出也是x。网络权重简单学成输入特征的1/n。
所以作者提出,显式地构造一个identity mapping,使得深层模型的精度至少不会变得更差。作者将其称为deep residual learning framework。
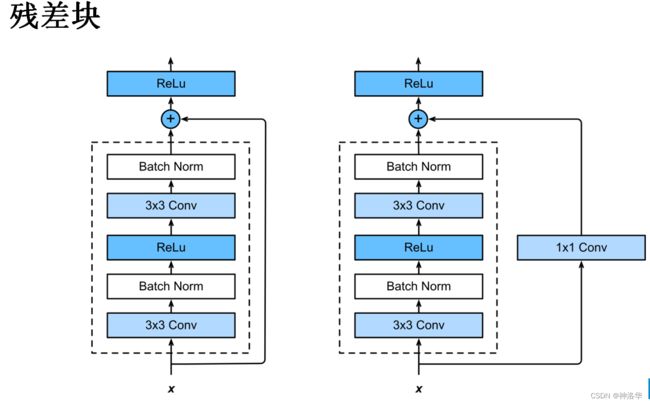
假设我们要学的是 H ( x ) H(x) H(x) ,在原有层上 添加一些新的层时,新的层不是直接学 H ( x ) H(x) H(x) ,而是学习 H ( x ) − x H(x) -x H(x)−x,这部分用 F ( x ) F(x) F(x)表示。(其中, x x x是原有层的输出。)即,新加入的层不用全部重新学习,而是学习原来已经学习到的 x x x和真实的 H ( x ) H(x) H(x)之间的残差就行 。最后模型的输出是 F ( x ) + x F(x)+x F(x)+x。这种新加入的层就是residual,结构如下图所示:
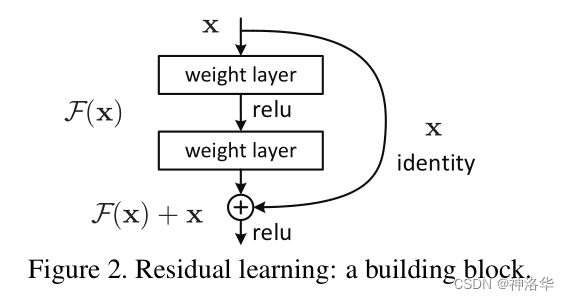
F ( x ) + x F(x)+x F(x)+x在数学上就是直接相加,在神经网络中是通过‘shortcut connections’实现(shortcut就是跳过一个或多个层,将输入直接加到这些跳过的层的输出上)。shortcut其实做的是一个identity mapping(恒等映射),而且这个操作不需要学习任何参数,不增加模型的复杂度。就多了一个加法,也不增加计算量,网络结构基本不变,可以正常训练。
1.1.2 实验验证
接下来作者在imagenet上做了一系列实验进行验证。结果表明,加了残差的网络容易优化,而且网络堆的更深之后,精度也会提高,所以赢下了比赛。在cifar-10上,作者尝试了训练超过1000层的网络。至此,论文的核心就讲完了,下面就是ResNet网络的设计。
1.2 相关工作
其实ResNet不是第一个提出
residual的。最早的线性模型的解法,就是通过不断迭代residual来求解的,而且在机器学习中,GBDT中,就是通过残差residual来不断学习的,把弱分类器叠加起来,成为一个强的分类器。只不过GBDT是在label上做残差,ResNet是在特征上做残差。
ResNet也不是第一个提出shortcut的,比如在highway networks中就有用到shortcut,但不是直接做加法,而是更复杂一些。
一篇文章之所以是经典,不一定是原创的提出很多东西,而有可能是把很多东西很巧妙的放在一起,能很好地解决问题;甚至大家都不记得之前谁还做过类似的工作。所以很多想法前人大多就想过了发表了,但是没关系,可以是用同一个东西解决新的问题,旧的技术有新的应用新的意义。
ResNet34比起VGG19,计算复杂度更低,只有前者的18%。其它是一些训练的细节,学习率优化器等等之类,就不细讲了。
1.3 实验部分
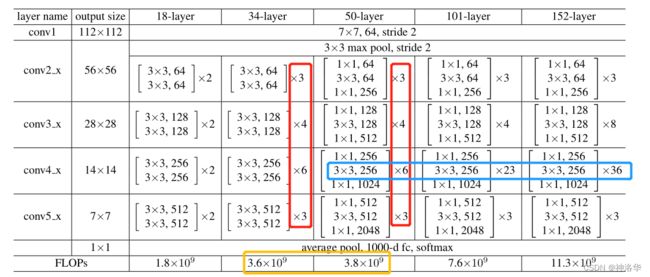
1.3.1 不同配置的ResNet结构
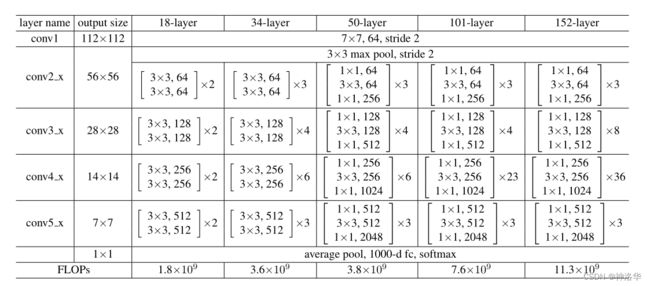
- 网络输入是ImageNet图片,短边在[256,480]中随机选取,然后resize到224×224尺寸,输入网络
- conv2_x:表示第二个卷积模块,x表示模块里有很多层。
- [ 3 × 3 , 64 3 × 3 , 64 ] × 3 \begin{bmatrix} 3\times 3 ,64\\ 3\times 3 ,64 \end{bmatrix}\times 3 [3×3,643×3,64]×3:[]内的是一个残差块,其卷积核大小为3*3,channel=64。×3表示有两个这样的残差层。
对照下面ResNet34结构图:(3+4+6+3)=16个残差模块,每个模块两层卷积层。再加上第一个7×7卷积层和最后一个全连接层,一共是34层。
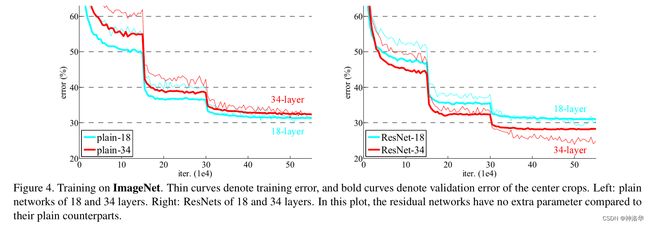
1.3.2 残差结构效果对比
从下图可以看到有残差模块,网络收敛会更快,而且精度会更好。
1.3.3 残差结构中,输入输出维度不一致如何处理
A. pad补0,使维度一致;
B. 维度不一致的时候,使其映射到统一维度,比如使用全连接或者是CNN中的1×1卷积(输出通道是输入的两倍)。
C. 不管输入输出维度是否一致,都进行投影映射。
下面作者对这三种操作进行效果验证。从下面结果可以看到,B和C效果差不多,都比A好。但是做映射会增加很多复杂度,考虑到ResNet中大部分情况输入输出维度是一样的(也就是4个模块衔接时通道数会变),作者最后采用了方案B。
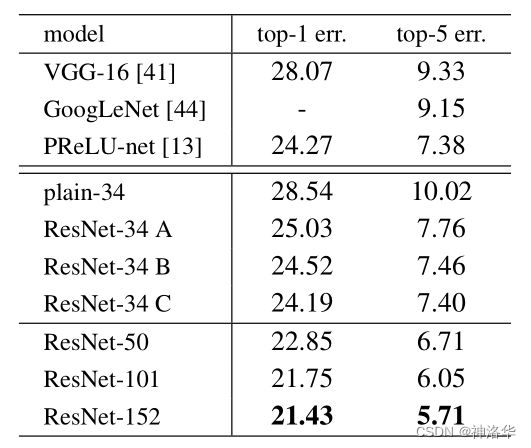
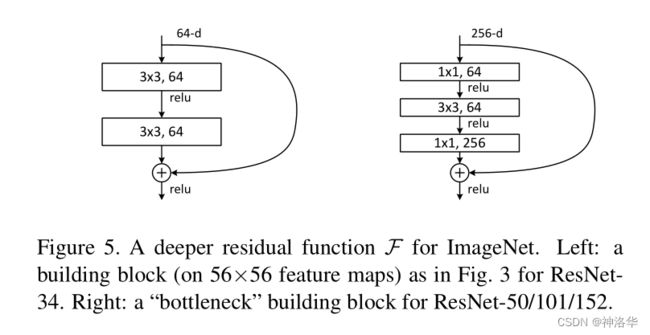
1.3.4 深层ResNet引入瓶颈结构Bottleneck
在ResNet-50及以上的结构中,模型更深了,可以学习更多的参数,所以通道数也要变大。比如前面模型配置表中,ResNet-50/101/152的第一个残差模块输出都是256维,增加了4倍。
如果残差结构还是和之前一样,计算量就增加的太多了(增加16倍),划不来。所以重新设计了Bottleneck结构,将输入从256维降为64维,然后经过一个3×3卷积,再升维回256维。这样操作之后,复杂度和左侧图是差不多的。这也是为啥ResNet-50对比ResNet-34理论计算量变化不大的原因。(实际上1×1卷积计算效率不高,所以ResNet-50计算还是要贵一些)
1.4 代码实现
resnet中残差块有两种:(use_1x1conv=True/False)
- 步幅为2 ,高宽减半,通道数增加。所以shortcut连接部分会加一个1×1卷积层改变通道数
- 步幅为1,高宽不变
残差块代码实现:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)#每个bn都有自己的参数要学习,所以需要定义两个
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
resnet18:类似VGG和GoogLeNet,但是替换了resnet块。一般用resnet34或者50,很少上100,除非刷榜。
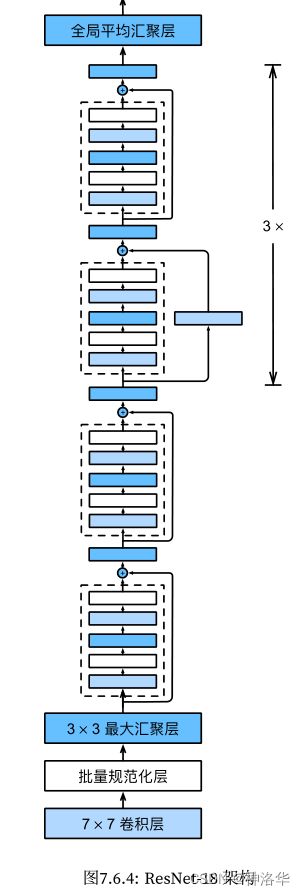
Resnet18代码:
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))#resnet_block是一个列表,*表示全部展开
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
1.5 结论
ResNet就是在CNN主干上加了残差连接,这样如果新加的层训练效果不好的话,至少可以fallback变回简单模型,所以精度不会变差。
在现在来看,ResNet训练的比较快,是因为梯度保持的比较好。因为新加的层容易导致梯度消失(或者梯度爆炸),但是加了残差连接,梯度多了一部分,包含了之前层的梯度,这样不管加了多深,梯度会保持的比较大(主要是不会梯度消失,学不动),不会太快收敛,SGD跑得多就训练的比较好。(SGD的精髓就是,只要梯度比较大,就可以一直训练。反正有噪音,慢慢的总是会收敛,最后效果就会比较好)
为什么在cifar-10这样一个小的数据集上(32*32图片5w张)训练1202层的网络,过拟合也不是很厉害。为何transformer那些模型几千亿的参数不会过拟合,李沐认为是加了残差连接之后,模型内在复杂度大大降低了。(理论上模型加一些层,模型也至少可以将后面的层学成恒等映射,使精度不会变差。但实际上没有引导做不到这一点。所以本文才会显示的把残差结构加进去,使模型能够更容易的训练出来。比如后面层都是0,前面一些层才学到东西,也就是更容易训练出一个简单模型来拟合数据,所以加入残差连接等于是模型复杂度降低了)
二、Attention is All You Need
参考:论文地址《Attention is All You Need》、bilibili视频《Transformer论文逐段精读【论文精读】》
论文翻译《论文阅读:Attention Is All You Need【注意力机制】》
2.0 摘要
主流的序列转换模型都是基于复杂的循环或卷积神经网络,这个模型包含一个编码器和一个解码器。具有最好性能的模型在编码和解码之间通过一个注意力机制链接编解码器。我们提出了一个新的简单网络结构——Transformer,其仅仅是基于注意力机制,而完全不需要之前的循环或卷积。在两个机器翻译任务上的实验表明,该模型具有更好的性能,同时并行度更好,并且训练时间更少。(泛化到其它任务效果也不错)
在WMT 2014英语到德语翻译任务上,我们的模型达到了28.4BLEU,比之前最好的结果提高了2BLEU。在WMT 2014英语到法语翻译任务上,我们的模型在8个GPU上训练3.5天后,所得到的单个模型获得了41.8BLEU分数。我们在大型和有限的训练数据中,通过将其成功应用于英语句法解析,表明了Transformer可以很好地适用于其他任务。
可以看到这篇文章最开始只是针对机器翻译来写的,
transformer在机器翻译上效果也很好。但是随着bert、GPT等把这种架构用在更多的NLP任务上,甚至后面CV和video等也可以使用注意力机制,整个工作就火出圈了。
2.1 结论
本文介绍了Transformer,这是第一个完全基于注意力的序列转换模型,用多头自注意力(multi-headed self-attention)代替了 encoder-decoder 架构中最常用的循环层。
对于翻译任务,Transformer可以比基于循环或卷积层的体系结构训练更快。在WMT 2014 English-to-German和and WMT 2014 English-to-French翻译任务中,我们取得了最好的结果。在前面的任务中,我们最好的模型甚至胜过以前发表过的所有整合模型。
我们对基于注意力的模型的未来感到兴奋, 并计划将Transformer应用于文本之外的涉及输入和输出模式的问题中任务,以有效处理大型输入&输出任务,如图像、音频和视频等。让生成不那么时序化是我们的另一个研究目标。
我们用于训练和评估模型的代码可以在https://github.com/tensorflow/tensor2tensor上获得。
2.2 导论
序列建模和转换问题(如机器翻译)最新方法是LSTM和GRN等。后面许多研究都围绕循环语言模型和编码器-解码器体系结构进行。
循环网络模型通常是考虑了输入和输出序列的中字符位置的计算。当前时刻隐藏状态ht,是由上一时刻隐藏状态ht−1和 t时刻输入共同决定的。(把之前的信息都放在隐藏状态里,一个个传递下去,是RNN处理时序信息的关键)。这种固有的时序模型难以并行化处理,计算性能就很差。这些年做了一些并行化改进,但是问题依然存在。
另外还存在长距离衰减问题,解码阶段,越靠后的内容,翻译效果越差。除非你把ht维度设置的很高,可以把每一个时间步的信息都存下来。但这样会造成内存开销很大。
attention在此之前,已经成功的应用在encoder-decoder 架构中,但主要是用在如何把编码器的信息有效的传递给解码器,所以是和RNN一起使用的。
本文提出的Transformer,不再使用循环神经层,而是纯基于注意力机制,来构造输入和输出之间的全局依赖关系。Transformer可以进行更多的并行化,训练时间更短但翻译效果更好。
2.3 背景
使用卷积神经网络替换循环神经网络,并行计算所有输入和输出位置的隐藏表示,是扩展神经GPU,ByteNet和ConvS2S的基础,因为这样可以减少时序计算。但是CNN对长序列难以建模(因为卷积计算时,卷积核/感受野比较小,如果序列很长,需要使用多层卷积才可以将两个比较远的位置关联起来)。但是使用Transformer的注意力机制的话,每次(一层)就能看到序列中所有的位置,就不存在这个问题。
关联来自两个任意输入或输出位置的数据所需的操作数量,随着距离增长,对于ConvS2S呈线性,对于ByteNet呈对数,而对于Transformer是常数,因为一次就看到了。
但是卷积的好处是,输出可以有多个通道,每个通道可以认为是识别不同的模式,作者也想得到这种多通道输出的效果,所以提出了Multi-Head Attention多头注意力机制。(模拟卷积多通道输出效果)
Self-attention,有时称为intra-attention,是一种关联单个序列的不同位置以计算序列表示的关联机制。在此之前已成功用于多种任务。但据我们所知,Transformer是第一个完全依靠self-attention,而不使用卷积或循环的的encoder-decoder 转换模型。
2.4 模型架构
大部分神经序列转换模型都使用encoder-decoder 结构 (引用)。编码器把一个输入序列 ( x 1 , . . . x n ) (x_{1},...x_{n}) (x1,...xn)映射到一个连续的表示 z = ( z 1 , . . . z n ) z=(z_{1},...z_{n}) z=(z1,...zn)中。解码器对z中的每个元素,生成输出序列 ( y 1 , . . . y m ) (y_{1},...y_{m}) (y1,...ym),一个时间步生成一个元素。在每一步中,模型都是自回归的(auto-regressive)(引用),在生成下一个结果时,会将先前生成的结果加入输入序列来一起预测。(自回归模型的特点,过去时刻的输出可以作为当前时刻的输入)
编码器和解码器序列可以不一样长,且编码器可以一次看到整个序列,但是解码器是一步步输出的。
Transformer 遵循这种整体架构,对编码器和解码器使用堆叠的自注意力和逐点全连接层,分别如下图的左半部分和右半部分所示。
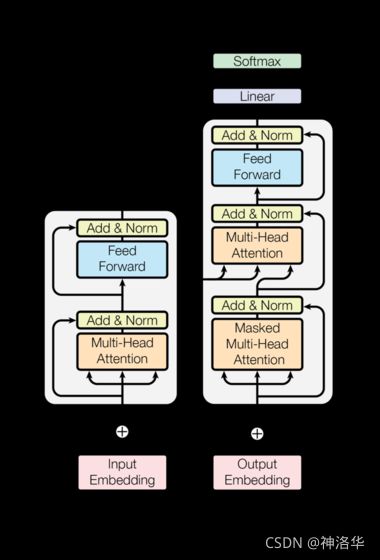
- 图画得好,一张图能搞定所有东西,所以画图是一个基础技能。
Outputs(shifted right):解码器在 t 0 t_0 t0时刻其实是没有输入的,其输入是编码器的输出,所以这里写的是output,shifted right就是逐个右移的意思。Nx:模块堆叠N次
2.4.1 编码器和解码器
代码可以参考《《The Annotated Transformer》翻译——注释和代码实现《Attention Is All You Need》》
编码器:编码器由N=6个相同encoder层堆栈组成。每层有两个子层。
multi-head self-attention- FFNN层(前馈神经网络层,Feed Forward Neural Network),其实就是MLP,为了fancy一点,就把名字起的很长。
- 两个子层都使用残差连接(residual connection),然后进行层归一化(layer normalization)。
- 每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是当前子层的输出。
- 为了简单起见,模型中的所有子层以及嵌入层的向量维度都是 d model = 512 d_{\text{model}}=512 dmodel=512(如果输入输出维度不一样,残差连接就需要做投影,将其映射到统一维度)。(这和之前的CNN或MLP做法是不一样的,之前都会进行一些下采样)
这种各层统一维度使得模型比较简单,只有N和 d model d_{\text{model}} dmodel两个参数需要调。这个也影响到后面一系列网络,比如bert和GPT等等。
解码器:解码器同样由 N=6个相同的decoder层堆栈组成,每个层有三个子层。
-
Masked multi-head self-attention:在解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention 分数经过 Softmax 层之前,使用attention mask,屏蔽当前位置之后的那些位置。所以叫Masked multi-head self Attention。(对应masked位置使用一个很大的负数-inf,使得softmax之后其对应值为0) -
Encoder-Decoder Attention:编码器输出最终向量,将会输入到每个解码器的Encoder-Decoder Attention层,用来帮解码器把注意力集中中输入序列的合适位置。 -
FFNN
与编码器类似,每个子层都使用残差连接,然后进行层归一化。假设一个 Transformer 是由 2 层编码器和两层解码器组成的,如下图所示:
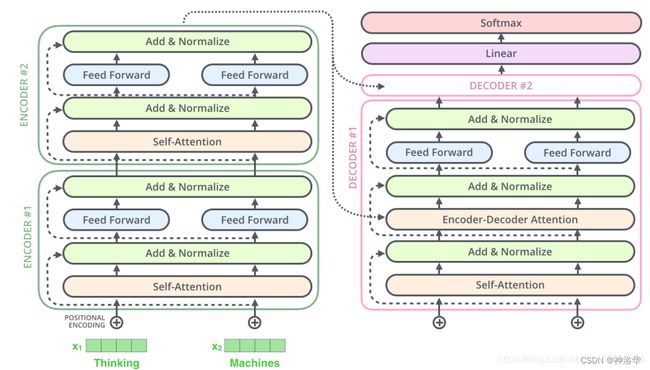
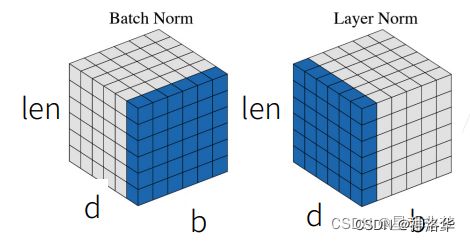
为什么这里使用LN而不是BN?
Batch Normalization:在特征d/通道维度做归一化,即归一化不同样本的同一特征。缺点是:
- 计算变长序列时,变长序列后面会pad 0,这些pad部分是没有意义的,这样进行特征维度做归一化缺少实际意义。
- 序列长度变化大时,计算出来的均值和方差抖动很大。
- 预测时使用训练时记录下来的全局均值和方差。如果预测时新样本特别长,超过训练时的长度,那么超过部分是没有记录的均值和方差的,预测会出现问题。
Layer Normalization:在样本b维度进行归一化,即归一化一个样本所有特征。
- NLP任务中一个序列的所有token都是同一语义空间,进行LN归一化有实际意义
- 因为实是在每个样本内做的,序列变长时相比BN,计算的数值更稳定。
- 不需要存一个全局的均值和方差,预测样本长度不影响最终结果。
为什么MLP Block先升维再降维?
神经网络中线性连接可以写成 d l = W l ⋅ x d^l=W^{l}\cdot x dl=Wl⋅x。其中三者维度分别是m×1、m×n、n×1。
- m>n:升维,将特征进行各种类型的特征组合,提高模型分辨能力
- m
2.4.2 注意力机制
attention函数可以被描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向量。输出被计算为value的加权求和,所以输出和value的维度一致。每个value的权重由query与对应key计算所得。(不同注意力机制有不同的算法)
2.4.2.1 缩放的点积注意力(Scaled Dot-Product Attention)
缩放的点积注意力:
- 其输入为query、key(维度是 d k d_k dk)以及values(维度是 d v d_v dv)。
- 计算query和所有key的点积,得到两个向量的相似度(结果越大相似度越高);然后对每个点积结果除以 d k \sqrt{d_k} dk,
- 点积结果输入softmax函数获得value的权重。
- 最后对value进行加权求和
在实践中,我们同时计算一组query的attention函数,并将它们组合成一个矩阵 Q Q Q。key和value也一起组成矩阵 K K K和 V V V。 我们计算的输出矩阵为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V \mathrm{Attention}(Q, K, V) = \mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
K、V 矩阵的序列长度是一样的(加权求和),而 Q 矩阵的序列长度可以和前两者不一样;这种情况发生在:解码器部分的Encoder-Decoder Attention层中,Q 矩阵是来自解码器输出tgt,而 K、V 矩阵则是来自编码器最后的输出memory。即
tgt2 = self.multihead_attn(tgt, memory, memory, attn_mask=memory_mask,key_padding_mask=memory_key_padding_mask)[0]
但是Q和K的维度必须一样,因为要计算点积。
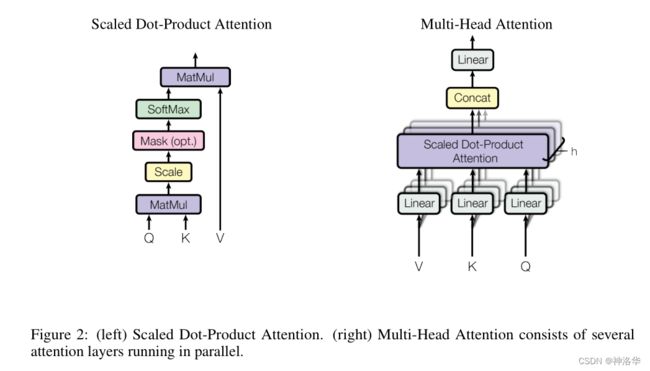
有两个最常用的attention函数:
- 加法attention(cite): s = A T T a n h ( q W + k U ) s=A^{T}Tanh(qW+kU) s=ATTanh(qW+kU),使用具有单个隐层的前馈网络计算,q和k维度不一致也可以进行;
- 上面提到的点积(乘法)attention
除了缩放因子 1 d k \frac{1}{\sqrt{d_k}} dk1 之外,点积Attention跟我们的算法一样(所以作者的注意力叫缩放点积注意力)。虽然理论上点积attention和加法attention复杂度相似,但在实践中,点积attention可以使用高度优化的矩阵乘法来实现,因此点积attention计算更快、更节省空间。
当dk的值比较小的时候,这两个机制的性能相差相近,当dk比较大时,加法attention比不带缩放的点积attention性能好。我们怀疑,维度dk很大时,点积结果也变得很大,将softmax函数推向具有极小梯度的区域。为了抵消这种影响,我们将点积缩小 1 d k \frac{1}{\sqrt{d_k}} dk1倍。
2.4.2.2 多头注意力
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O where h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) \mathrm{MultiHead}(Q, K, V) = \mathrm{Concat}(\mathrm{head_1}, ..., \mathrm{head_h})W^O \\ \text{where}~\mathrm{head_i} = \mathrm{Attention}(QW^Q_i, KW^K_i, VW^V_i) MultiHead(Q,K,V)=Concat(head1,...,headh)WOwhere headi=Attention(QWiQ,KWiK,VWiV)
其中映射由权重矩阵完成: W i Q ∈ R d model × d k W^Q_i \in \mathbb{R}^{d_{\text{model}} \times d_k} WiQ∈Rdmodel×dk, W i K ∈ R d model × d k W^K_i \in \mathbb{R}^{d_{\text{model}} \times d_k} WiK∈Rdmodel×dk, W i V ∈ R d model × d v W^V_i \in \mathbb{R}^{d_{\text{model}} \times d_v} WiV∈Rdmodel×dv and W O ∈ R h d v × d model W^O \in \mathbb{R}^{hd_v \times d_{\text{model}}} WO∈Rhdv×dmodel。
我们采用 h = 8 h=8 h=8个平行attention层或者叫head。对于这些head中的每一个,我们使用 d k = d v = d model / h = 64 d_k=d_v=d_{\text{model}}/h=64 dk=dv=dmodel/h=64,总计算成本与具有全部维度的单个head attention相似。
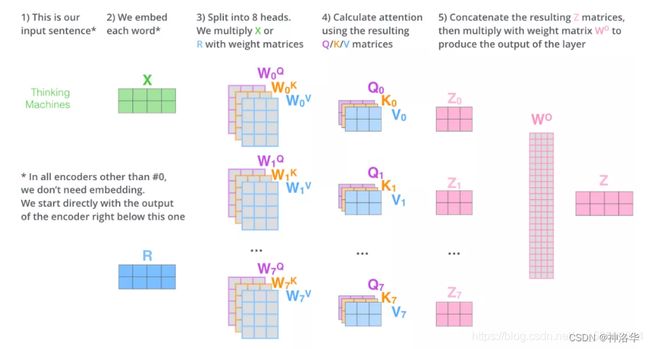
- 输入 X 和8组权重矩阵 W Q W^Q WQ, W K W^K WK W V W^V WV相乘,得到 8 组 Q, K, V 矩阵。进行attention计算,得到 8 组 Z 矩阵(假设head=8)
- 把8组矩阵拼接起来,乘以权重矩阵 W O W^O WO,将其映射回 d 维向量(相当于多维特征进行汇聚),得到最终的矩阵 Z。这个矩阵包含了所有 attention heads(注意力头) 的信息。
- 矩阵Z会输入到 FFNN层。(前馈神经网络层接收的也是 1 个矩阵,而不是8个。其中每行的向量表示一个词)
使用多头自注意力的好处:
- 多语义匹配:本身缩放点积注意力是没什么参数可以学习的,就是计算点积、softmax、加权和而已。但是使用
Multi-head attention之后,投影到低维的权重矩阵 W Q W^Q WQ, W K W^K WK , W V W^V WV是可以学习的,而且有h=8次学习机会。使得模型可以在不同语义空间下学到不同的的语义表示,也扩展了模型关注不同位置的能力。类似卷积中多通道的感觉。
例如,“小明养了一只猫,它特别调皮可爱,他非常喜欢它”。“猫”从指代的角度看,与“它”的匹配度最高,但从属性的角度看,与“调皮”“可爱”的匹配度最高。标准的 Attention 模型无法处理这种多语义的情况。- 注意力结果互斥:自注意力结果需要经过softmax归一化,导致自注意力结果之间是互斥的,无法同时关注多个输人。 使用多组自注意力模型产生多组不同的注意力结果,则不同组注意力模型可能关注到不同的输入,从而增强模型的表达能力。
2.4.2.3 注意力在模型中的应用
Transformer中用3种不同的方式使用multi-head attention:
encoder-decoder attention层中,query来自前面的decoder层,而keys和values来自encoder的输出memory。这使得decoder中的每个位置都能关注到输入序列中的所有位置。这是模仿序列到序列模型(Seq2Seq)中典型的编码器—解码器的attention机制,例如 (cite)。
encoder-decoder attention层可以使解码器在每个时间步,把注意力集中到输入序列中感兴趣的位置。比如英译中‘hello world’,解码器在输出‘你’的时候,解码器的输入q对’hello’的相似度应该是最高的,这样模型就将注意力主要集中在’hello’上,即生成单词时更关注源语言序列中更相关的词。(这就是attention如何在encoder传递信息到decoder时起到作用)
-
encoder包含self-attention层。在self-attention层中,所有key,value和query来自同一个地方,即encoder中前一层的输出。在这种情况下,encoder中的每个位置都可以关注到encoder上一层的所有位置。 -
decoder中的masked-self-attention层允许decoder中的每个位置都关注decoder层中当前位置之前的所有位置(包括当前位置)。 为了保持解码器的自回归特性,需要防止解码器中的信息向左流动。我们在缩放点积attention的内部,通过屏蔽softmax输入中所有的非法连接值(设置为 − ∞ -\infty −∞)实现了这一点。
2.4.3 基于位置的前馈神经网络(Position-wise Feed-Forward Networks)
编码器和解码器中的每个层都包含一个全连接的前馈网络,该前馈网络分别且相同地应用于每个位置。该前馈网络包括两个线性变换,并在两个线性变换中间有一个ReLU激活函数。
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \mathrm{FFN}(x)=\max(0, xW_1 + b_1) W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
Position就是序列中每个token,Position-wise 就是把MLP对每个token作用一次,且作用的是同一个MLP。说白了就是MLP只作用于最后一个维度d=512。
因为前面的attention层以及抓取了输入序列的相关信息,并做了一次汇聚(拼接后W映射回d维)。所以attention层结果已经有了序列中我感兴趣的信息,所以后面在做MLP投影映射到想要的语义空间时,只需要对每个position(token)单独做MLP就行。
从attention抽取序列信息到MLP映射到需要的语义空间(非线性变换),就整个是transformer的处理信息的基础过程。
尽管两层都是线性变换,但它们在层与层之间使用不同的参数。另一种描述方式是两个内核大小为1的卷积。 输入和输出的维度都是 d model = 512 d_{\text{model}}=512 dmodel=512, 内层维度是 d f f = 2048 d_{ff}=2048 dff=2048。(也就是第一层输入512维,输出2048维;第二层输入2048维,输出512维)
对比transformer和RNN,发现两者都是使用MLP来进行语义空间的转换,但区别是二者传递信息的方式不一样:(大概画了个示意图,见谅)
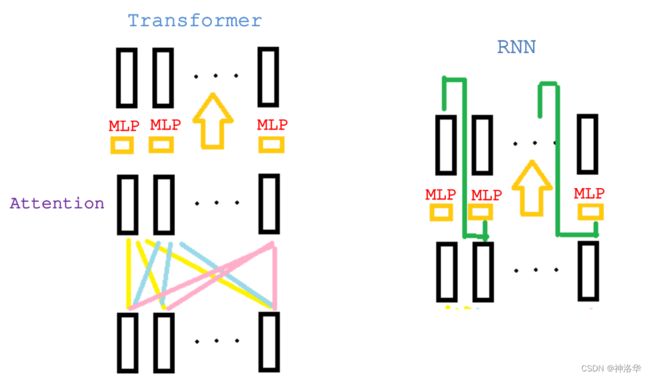
RNN是把上一时刻信息作为输入(和t时刻输入一起),传递给当前时刻,并用MLP做语义转换。Transformer是通过attention层直接关联到全局的序列信息,然后用MLP做语义转换。
2.4.4 词嵌入和Softmax
我们使用学习到的embedding将输入token和输出token转换为 d model d_{\text{model}} dmodel维的向量。我们还使用普通的线性变换和softmax函数将解码器输出转换为预测的下一个token的概率。在我们的模型中,输入输出两个嵌入层,和pre-softmax线性变换共享相同的权重矩阵(这样训练起来简单一些)。最后我们将这些权重乘以 d model \sqrt{d_{\text{model}}} dmodel(比如512)。
这是因为一般会把一个向量的L2Norm学到接近1,这样向量维度越大,这样学到的权重值就会很小。但是位置编码是不会这样学成L2Norm(L2范数)接近1的。所以把权重乘上 d model \sqrt{d_{\text{model}}} dmodel之后,token embedding和位置编码Positional Encoding才接近统一量级。(都在-1到1之间)
2.4.5 位置编码(Positional Encoding)
Attention计算时本身是不考虑位置信息的,这样序列顺序变化结果也是一样的。所以我们必须在序列中加入关于词符相对或者绝对位置的一些信息。
为此,我们将“位置编码”添加到token embedding中。二者维度相同(例如 d model \sqrt{d_{\text{model}}} dmodel=512),所以可以相加。有多种位置编码可以选择,例如通过学习得到的位置编码和固定的位置编码。
在这项工作中,我们使用不同频率的正弦和余弦函数: P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d model ) PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{\text{model}}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d model ) PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{\text{model}}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中 p o s pos pos 是位置, i i i 是维度。也就是说,位置编码的每个维度对应于一个正弦曲线。 这些波长形成一个从 2 π 2\pi 2π 到 10000 ⋅ 2 π 10000 \cdot 2\pi 10000⋅2π的集合级数。我们选择这个函数是因为我们假设它会让模型很容易学习对相对位置的关注,因为对任意确定的偏移 k k k, P E p o s + k PE_{pos+k} PEpos+k 可以表示为 P E p o s PE_{pos} PEpos的线性函数。最终编码向量每个元素值都是在-1到1之间。
此外,我们会将编码器和解码器堆栈中的embedding和位置编码的和再加一个dropout。对于基本模型,我们使用的dropout比例是 P d r o p = 0.1 P_{drop}=0.1 Pdrop=0.1。
2.5 为什么使用自注意力机制
本节,我们比较self-attention与循环层和卷积层的各个方面,我们使用self-attention是考虑到解决三个问题。
- 每层计算的总复杂度,越少越好
- 顺序计算量,越少代表并行度越高。(顺序计算量就是下一步需要前面多少步计算完成)
- 网络中长距离依赖之间的路径长度
影响长距离依赖性能力的一个关键因素是前向和后向信号在网络中传播的路径长度。输入和输出序列中任意位置之间的这些路径越短,学习长距离依赖性就越容易。因此,我们还比较了由不同图层类型组成的网络中任意两个输入和输出位置之间的最大路径长度。
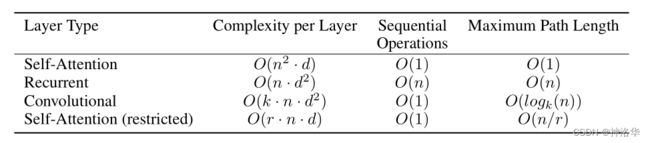
上图n是序列长度,d是token维度。
- Attention:
- 计算复杂度:矩阵Q*K,两个矩阵都是n行d列,所以相乘时复杂度是 O ( n 2 ⋅ d ) O(n^2\cdot d) O(n2⋅d),其它还有一些计算量但影响不大;
- 顺序计算量:矩阵里面并行度是很高的,整个计算主要就是矩阵乘法,所以可以认为顺序计算量就是 O ( 1 ) O(1) O(1);
- 最大路径长度:也就是从一个点关联到任何一个点的路径长度。attention是一次看到整个序列,所以只需要一次操作,复杂度为 O ( 1 ) O(1) O(1)
其它的暂时不写了。k就是卷积核大小,一般是3、5之类的;而n和d现在的模型都是做到几百几千,所以可以认为前三种操作,计算复杂度差不多,但是并行度是attention和卷积更好;且attention在信息的融合上更好(最大路径长度=1)。
实际上attention对模型的假设更少,导致模型需要更多的数据和更大的模型才能训练到和RNN或CNN差不多的效果。所以现在基于transformer的模型都是很大,训练起来很贵。
2.6 实验(可以跳过)
2.6.1训练数据和批处理
我们在标准的WMT 2014 English-German dataset上进行了训练,其中包含约450万个句子对。这些句子使用byte-pair编码进行编码,源语句和目标语句共享大约37000个词符的词汇表。对于英语-法语翻译,我们使用大得多的WMT 2014 English-French dataset,它包含3600万个句子,并将词符分成32000个word-piece词汇表。序列长度相近的句子一起进行批处理。每个训练批处理的句子对包含大约25000个源词符和25000个目标词符。
bpe编码,是因为英语/德语中有很多ing之类的词根,又或者一个动词有几种形式。如果直接使用token进行表示,词表就太大了。bpe就可以把词根提取出来,这样词表会小很多,而且还能表示不同时态等等这些相关信息。
共用词表可以使编码器和解码器共用一个embedding,权重共享,模型更简单。
2.6.2 硬件和时间
我们在一台具有8个NVIDIA P100 GPU的机器上训练我们的模型。使用本文描述的超参数的基础模型,每个训练步骤耗时约0.4秒。我们的基础模型共训练了10万步或12小时。对于我们的大型模型(在表3的底部描述),步长为1.0秒。大型模型接受了30万步(3.5天)的训练。
因为TPU非常适合做很大的矩阵乘法,所以后面Google都推荐自己的员工多使用TPU
2.6.3 优化器
我们使用Adam优化器(cite),其中 β 1 = 0.9 \beta_1=0.9 β1=0.9, β 2 = 0.98 \beta_2=0.98 β2=0.98并且 ϵ = 1 0 − 9 \epsilon=10^{-9} ϵ=10−9。我们根据以下公式在训练过程中改变学习率:
l r a t e = d model − 0.5 ⋅ min ( s t e p _ n u m − 0.5 , s t e p _ n u m ⋅ w a r m u p _ s t e p s − 1.5 ) lrate = d_{\text{model}}^{-0.5} \cdot \min({step\_num}^{-0.5}, {step\_num} \cdot {warmup\_steps}^{-1.5}) lrate=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)
这对应于在第一次 w a r m u p _ s t e p s warmup\_steps warmup_steps步中线性地增加学习速率,并且随后将其与步数的平方根成比例地减小。我们使用 w a r m u p _ s t e p s = 4000 warmup\_steps=4000 warmup_steps=4000。
2.6.4 正则化
训练期间我们采用两种正则化:
-
Residual Dropout
我们将dropout应用到每个子层的输出,在子层输出进入残差连接之前,和LayerNorm之前,都使用dropout。此外,在编码器和解码器中,token embedding+Positional Encoding时也使用了dropout。对于base模型,我们使用drop概率为 0.1。 -
Label Smoothing
在训练过程中,我们使用的label smoothing的值为ϵls= 0.1。这让模型不易理解,因为模型学得更加不确定,但提高了准确性和BLEU得分。(softmax要逼近于1,其输入几乎要无穷大,这是很不合理的,会使模型训练困难)
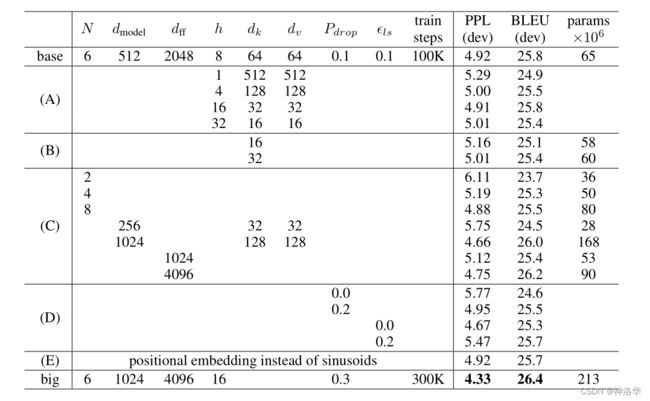
2.6.5 模型配置
可以看到模型虽然比较复杂,但是没有多少超参数可以调,使得后面的人工作简单很多。
2.7 评价
Transformer(attention机制)几乎能用在所有NLP任务上,类CNN对整个CV领域的革新(不需要那么多的特征提取或者模型建模,学会CNN就行了)。Transformer也是一样,不需要那么多的文本预处理,不需要为每个任务设计不同的架构。
而且现在transformer在CV、语音、video等领域也广泛使用,等于一个架构可以适用所有领域,任何一点突破在别的领域都能被使用,减少技术的应用时间。 而且Transformer可以融合多模态的数据(文字、图片、语音等),大家都要同一个架构提取特征的话,可以都抽取到同一个语义空间,使得我们可以用文字、图片、语音等训练更大更好的模型。
虽然Transformer效果这么好,但是对它的理解还在初级阶段。
- 最新的一些结果表明,attention在里面只是起到一个聚合序列信息的作用 ,但是后面的MLP/残差连接是缺一不可的,如果去掉的话,模型是基本训练不出什么的
- Attention不会对序列的顺序建模,为何能打败RNN?RNN可以显式地建模序列信息,不是应该比attention更好。现在大家觉得attention使用了更广泛的归纳偏置,使得他能处理更一般化的信息;这也是attention没有做空间上的假设吗,但是比CNN/RNN能做到更好的效果。代价就是假设更一般,所以抓取数据信息能力变差,必须使用更大的模型和更多的数据才能训练到一个比较好的效果。
期待未来有更多新的架构。
三、GAN论文精读
论文地址:《Generative Adversarial Networks》、bilibili视频《GAN论文逐段精读【论文精读】》
3.0 前言&摘要
过去5年,在reddit的MachineLearning板块,冲上头条最多的是GAN的应用,比如生成名人小时候的照片:

- 《VToonify: Controllable High-Resolution Portrait Video Style Transfer》:

- 《stablediffusion-infinity: Outpainting with Stable Diffusion on an infinite canvas》画布扩散输出:

- 《Stable Diffusion web ui + IMG2IMG + After Effects + artist workflow》文生图模型:

还有一个专门的网址:thispersondoesnotexist.com,上面都是一些生成的高清人脸图。
GAN技术这么强大,以至于加州政府在2019年出台法令,一是禁止成人行业在未经本人同意时,将其人脸用在别人身上;二是禁止使用政治人物的人脸,让其说一段以前没有说过的话。
摘要
我们提出了一个新的framework,从对抗训练中估计一个生成模型。GAN有两个网络:生成器神经网络G(Generator Neural Network) 和判别器神经网络D(Discriminator Neural Network)。
生成器G希望从数据的真实分布中采样到一种分布(用于生成数据)。D用于判别样本是真实样本还是G生成的样本。
生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D,使D犯错;而D的目标就是尽量把G生成的图片和真实的图片分别开来。二者互相博弈,最终的结果是D(G(z)) = 0.5。
GAN就是对分布进行建模,希望模型可以生成各种分布。最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此
D(G(z)) = 0.5。
1.1 导论
深度学习是用来发现一些丰富的、有层次的模型,这些模型能够对AI里的各种数据做一个概率分布的表示。深度学习网络只是一种手段而已。
深度学习不仅是学习网络,更是对数据分布的一种表示。这和统计学习方法里面的观点不谋而合,后者认为机器学习模型从概率论的角度讲,就是一个概率分布 P θ ( X ) P_{\theta }(X) Pθ(X) (这里以概率密度函数来代表概率分布)
机器学习的任务就是求最优参数 θ t \theta_{t} θt ,使得概率分布 P θ ( X ) P_{\theta }(X) Pθ(X) 最大(即已发生的事实,其对应的概率理应最大)。
θ t = a r g m a x θ P θ X \theta_{t} =\underset{\theta}{argmax}P_{\theta }X θt=θargmaxPθX
argmax 函数代表的是取参数使得数据的概率密度最大。求解最优参数 θ t \theta_{t} θt的过程,我们称之为模型的训练过程( Training )
深度学习在判别模型上取得了很好的效果,但是在生成模型上比较差。难点在于最大化似然函数时,要对概率分布做很多近似,近似带来了很大的计算困难。
本文的核心观点就是, 不用再去近似似然函数了,可以用更好的办法(GAN)来计算模型。
GAN是一个框架,里面的模型都是MLP。后面是用小偷造假币警察来分辨的一个举例。最后作者说,生成器G这个MLP的输入是随机噪声,通常是高斯分布;然后将其映射到任何一个我们想去拟合的分布。判别器D也是MLP,所以可以通过误差的反向传递来训练,而不需要像使用马尔可夫链这样的算法,对一个分布进行复杂的采样。这样模型就比较简单,计算上有优势。
3.2 相关工作
这篇论文有两个版本,arxiv上是早期版本,相关工作没怎么写。李沐讲的是NeurlPS上的最终版本。
之前的生成模型总是想构造一个分布函数出来,同时这些函数提供了一些参数可以学习。这些参数通过最大化对数似然函数来求解。这样做的缺点是,采样一个分布时,求解参数算起来很难,特别是高维数据。
因为这样计算很困难,所以最近有一些Generative Machines,不再去构造分布函数,而是学习一个模型来近似这个分布。
前者真的是在数学上学习出一个分布,明明白白知道数据是什么分布,里面的均值方差等等到底是什么东西。而GAN就是通过一个模型来近似分布的结果,而不需要构造分布函数。这样计算起来简单,缺点是不知道最终的分布到底是什么样子。
我观察到,对f的期望求导,等价于对f自己求导。这也是为什么通过误差反向传递来对GAN求解。
3.3 对抗网络(目标函数及其求解)
3.3.1 目标函数
GAN最简单的框架就是模型都是MLP。
-
生成器G是要在数据x上学习一个分布 p g ( x ) p_g(x) pg(x),其输入是定义在一个先验噪声z上面,z的分布为 p z ( z ) p_z (z) pz(z)。生成模型G的任务就是用MLP把z映射成x。
- 比如图片生成,训练图片是224*224,每个像素是一个随机变量,那么x就是一个50176维的随机变量,变量每个元素都是 p g p_g pg控制的
- 不管最终x如何生成,假设不同的生成图片其实就是那么100来个变量控制的,而MLP理论上可以拟合任何一个函数。那么我们就构造一个100维的向量,MLP强行把z映射成x。所以z可以先验的设定为一个100维向量,其均值为0,方差为1,呈高斯分布。(这样算起来简单)
- 随机设定z为100维向量的缺点,就是MLP并不是真的了解背后的z是如何控制输出的,只是学出来随机选一个比较好的z来近似x,所以最终效果也就一般。
- G的可学习参数是 G ( z ; θ g ) G(z;\theta _{g}) G(z;θg)
-
判别器D是输出一个标量(概率),判断其输入是G生成的数据/图片,还是真实的数据/图片。
- D的可学习参数是 D ( x ; θ d ) D(x;\theta _{d}) D(x;θd)。
- 对于D,真实数据label=1,假的数据label=0
-
两个模型都会训练,
- G的目标是希望生成的图片“越接近真实越好,D(G(z))变大接近1,也就是最小化 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z))),所以记做 m i n G \underset{G}{min} Gmin。
- D的目标是最大化 l o g D ( x ) logD(x) logD(x),记做 m a x D \underset{D}{max} Dmax
- 所以最终目标函数公式如下所示,E代表期望,X → P d a t a P_{data} Pdata代表分布为 P d a t a P_{data} Pdata的真实样本,另一边同理。公式中同时有minmax,所以是对抗训练。
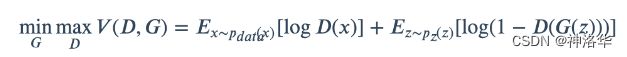
假设x和z都是一维向量,且z是均匀分布,模型训练过程可以表示为:
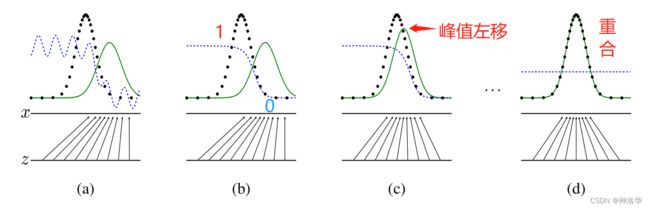
如上图所示;
虚线点为真实数据分布,蓝色虚线是判别器D的分布,绿色实线为生成器G的分布。初始训练出生成器网络G和判别器网络D;从a到d是我们希望的训练过程。
a. 生成器从均匀分布学成绿色实线表示的高斯分布,这时候判别器还很差;
b. 判别器学成图b所示的分布,可以把真实数据和生成数据区别开来;
c.生成器波峰靠向真实数据波峰,自然就使得判别器难以分辨了;辨别器为了更准,其分布也往真实数据靠拢;
d.最终训练的结果,生成器拟合真实分布,判别器难以分辨,输出概率都为0.5 。
3.3.2 迭代求解过程
下面是具体的算法过程:

- k是一个超参数,不能太小也不能太大。要保证判别器D可以足够更新,但也不能更新太好。
- 如果D更新的不够好,那么G训练时在一个判别很差的模型里面更新参数,继续糊弄D意义不大;
- 如果D训练的很完美,那么 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))趋近于0,求导结果也趋近于0,生成器难以训练
- 整体来说GAN的收敛是很不稳定的,所以之后有很多工作对其进行改进。
- 早期G非常弱,所以很容易把D训练的很好,这样就造成刚刚说的G训练不动了。所以作者建议此时,G的目标函数改为最大化 l o g D ( G ( z ) ) logD(G(z)) logD(G(z))(就算D训练的好,这部分也是有梯度的)。带来的问题是, l o g D ( G ( z ) ) → 0 logD(G(z))\rightarrow 0 logD(G(z))→0的时候,log0是负无穷大,会带来数值上的问题。(后面的工作会对其进行改进)
3.4 理论结果
3.4.1 全局最优解 p g = p d a t a p_g=p_{data} pg=pdata
这部分需要证明目标函数 m i n G m a x D V ( D , G ) \underset{G}{min}\underset{D}{max}V(D,G) GminDmaxV(D,G)有全局最优解,且这个解当且仅当 p g = p d a t a p_g=p_{data} pg=pdata时成立,也就是生成器学到的分布等于真实数据的分布。
3.2
具体证明部分可以参考帖子《GAN论文阅读——原始GAN(基本概念及理论推导)》的3.2章节。
- 固定生成器G,最优的辨别器应该是;(具体证明我也看不懂,就不写了)
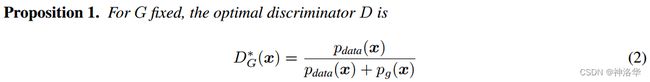
- *表示最优解
- p g ( x ) p_g(x) pg(x)和 p d a t a ( x ) p_{data}(x) pdata(x)表示x在生成器拟合的分布里面,和真实数据的分布里面,它的概率分别是多少。
- 当 p g ( x ) = p d a t a ( x ) p_g(x)=p_{data}(x) pg(x)=pdata(x)时,结果为1/2,表示两个分布完全相同,最优的判别器也无法将其分辨出来。
- 这个公式的意义是,从两个分布里面分别采样数据,用目标函数 m i n G m a x D V ( D , G ) \underset{G}{min}\underset{D}{max}V(D,G) GminDmaxV(D,G)训练一个二分类器,如果分类器输出的值都是0.5,则可以认为这两个分布是完全重合的。在统计学上,这个叫two sample test,用于判断两块数据是否来自同一分布。
two sample test是一个很实用的技术,比如在一个训练集上训练了一个模型,然后部署到另一个环境,需要看看测试数据的分布和训练数据是不是一样的,就可以像这样训练一个二分类器就行了,避免部署的环境和我们训练的模型不匹配。
- 把D的最优解代回目标函数,目标函数之和G相关,写作C(G):
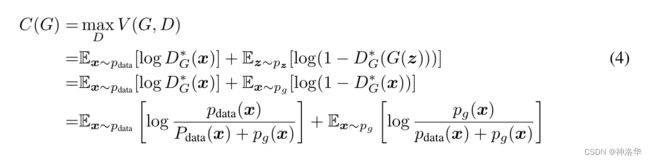
现在只需要最小化这一项就行。 - 证明当且仅当 p g = p d a t a p_g=p_{data} pg=pdata时有最优解 C ( G ) = − l o g 4 C(G)=-log4 C(G)=−log4。
- 上式两项可以写成KL散度,即:
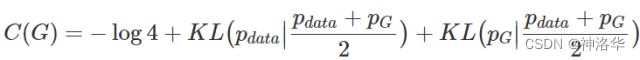
- 又因为JS散度定义为:
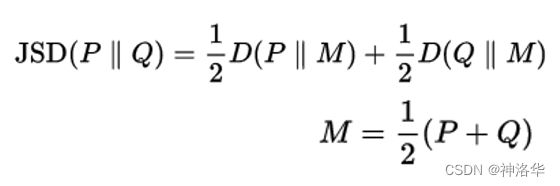
- 所以进一步化简成:
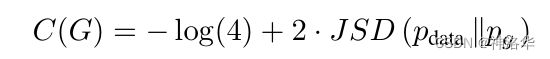
- 要求 m i n C ( G ) minC(G) minC(G),只有最后一项等于0的时候成立(JS散度≥0),此时 p g = p d a t a p_g=p_{data} pg=pdata。
JS散度跟KL散度的区别是前者是对称的, p g p_g pg和 p d a t a p_{data} pdata可以互换,而后者不对称。
综上所述,当且仅当生成分布等于真实数据分布式时,我们可以取得最优生成器。
3.4.2 收敛证明
这部分证明了:给定足够的训练数据和正确的环境,在算法1中每一步允许D达到最优解的时候,对G进行下面的迭代:
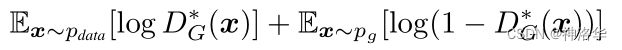
训练过程将收敛到 p g = p d a t a p_g=p_{data} pg=pdata,此时生成器G是最优生成器。
3.5 GAN的优势与缺陷
参考《GAN论文阅读——原始GAN(基本概念及理论推导)》
与其他生成式模型相比较,生成式对抗网络有以下四个优势【OpenAI Ian Goodfellow的Quora问答】:
- 比其它模型生成效果更好(图像更锐利、清晰)。
- GAN能训练任何一种生成器网络(理论上-实践中,用 REINFORCE 来训练带有离散输出的生成网络非常困难)。大部分其他的框架需要该生成器网络有一些特定的函数形式,比如输出层是高斯的。重要的是所有其他的框架需要生成器网络遍布非零质量(non-zero mass)。
- 不需要设计遵循任何种类的因式分解的模型,任何生成器网络和任何判别器都会有用。
- 无需利用马尔科夫链反复采样,无需在学习过程中进行推断(Inference),回避了近似计算棘手的概率的难题。
GAN目前存在的主要问题:
-
难以收敛(non-convergence)
目前面临的基本问题是:所有的理论都认为 GAN 应该在纳什均衡(Nash equilibrium)上有卓越的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。当博弈双方都由神经网络表示时,在没有实际达到均衡的情况下,让它们永远保持对自己策略的调整是可能的【OpenAI Ian Goodfellow的Quora】。 -
难以训练:崩溃问题(collapse problem)
GAN模型被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。GAN的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。 -
无需预先建模,模型过于自由不可控。
与其他生成式模型相比,GAN不需要构造分布函数,而是使用一种分布直接进行采样,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了(超高维)。
所以可以看到,最终作者生成的图片分辨率都很低。在GAN 中,每次学习参数的更新过程,被设为D更新k回,G才更新1回,也是出于类似的考虑。
3.6 代码实现(paddle/pytorch)
- paddle版参考《生成对抗网络,从DCGAN到StyleGAN、pixel2pixel,人脸生成和图像翻译》1.4章节。
- pytorch版参考《DCGAN Tutorial》
3.7 总结
GAN本身是无监督学习,不需要标注数据。但是其训练方式是用有监督学习的损失函数来做无监督学习(有监督的标签来源于数据是真实的还是生成的),所以训练上会高效很多。这也是之后bert之类自监督学习模型的灵感来源。
四、BERT
- 论文:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
- bilibili视频 《BERT 论文逐段精读【论文精读】》、《Bert论文翻译》
4.0 摘要
前言:
CNN模型出来之后,在一个大的数据集上预训练好一个CNN模型,就可以帮助一大片的CV任务;而在BERT出来之前,在NLP领域没有一个这样的深度神经网络模型。所以NLP领域我们还是对每个任务构造自己的神经网络,自己训练。 BERT出来之后,就可以预训练好一个模型,来应用于很多不同的NLP任务了。简化训练的同时还提升了其性能。BERT和之后的工作使得NLP在过去几年有了质的飞跃。
全文是将BERT和ELMo和GPT对比,ELMo是使用双向信息,但是结构是比较老的RNN结构,且双向信息融合的很浅,GPT使用新的 Transformers结构,不同任务进行微调就行,但其性能受到单向模型结构的限制。BERT的主要贡献,是将预训练模式推广到深层双向体系结构,而具体的实现,是通过MLM任务来完成。通过完形填空的自监督训练机制,不需要使用监督语料,而是预测句子中被masked的词是什么,从而抽取文本特征。
由此BERT极大的拓展了Transformers的应用,使其可以在更大的无标签的数据集上训练,其效果比有标签、更小数据集上训练的模型效果还要好。
摘要:
我们介绍一种新的语言表示模型叫BERT,它是Bidirectional Encoder Representations fromTransformers的缩写(双向Transformer编码器)。与最近的语言表示模型(ELMo,GPT)不同,BERT的所有层旨在通过联合训练左右上下文的方式从未标注文本中预训练深层的双向表征。因此,预训练好的BERT模型只需使用额外的一层输出层进行微调后就能为广泛的任务创建最好的模型,例如问答和语言推理,而无需针对特定任务进行大量的结构修改。(一段话说明和ELMo,GPT的主要区别)
- 芝麻街是美国妇孺皆知的一个少儿英语类节目,
ELMo是芝麻街里面一个人物的名字,BERT是芝麻街里另一个主人公的名字。ELMo和BERT开创了NLP领域芝麻街系列文章之先河。之后芝麻街的主要人名基本都被用过。GPT是单向自回归模型,用左侧信息取预测未来信息;ELMo虽然是双向,不过是基于RNN的架构,所以在应用到下游任务时,需要对架构做一些调整;而BERT是基于Transformer,不需要调整架构,这点和GPT是一样的。
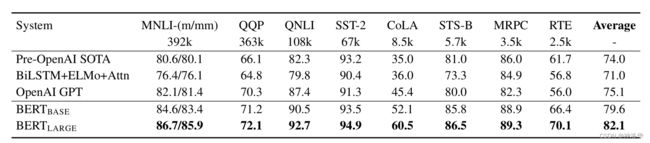
BERT概念简单且实验效果很好,它在11项自然语言处理任务中获得了最好的结果,包括将GLUE分数提高到80.5%(7.7%的提升),将MultiNLI准确率提高到86.7%(4.6%的提升),将SQuAD v1.1 Test的问答F1值提高到93.2(1.5个点的提升),SQuAD v2.0 Test的F1提高到83.1(5.1个点的提升)。
4.1 导论
语言模型预训练已被证明对改善许多NLP任务有效,这些任务包括:
- 句子级别的任务,例如自然语言推理和释义( paraphrasing),通过整体分析来预测句子之间的关系来完成
- token级别的任务,例如命名实体识别NER和问答,要求模型能够产生更细粒度的词级别输出。
使用预训练模型做特征表示,以应用于下游任务有两种策略:feature-based(基于特征的)和fine-tuning(微调)。前者代表是ELMo,为每个任务构造一个相关的神经网络。利用预训练好的表示(比如token
embedding)作为附加特征。后者代表是GPT,不需要改变模型结构,简单微调所有预训练的参数就可以针对下游任务进行训练。
预训练表示作为附加特征也是预训练模型的一种常用做法。附加特征会和原始输入一起输入网络。因为附加特征已经有了好的表示,所以模型训练起来会比较容易
这两种方法在预训练的过程中都使用的是同一个目标函数,它们使用的都是单向的语言模型学习通用的语言表征,限制了预训练表示的能力,尤其是对于fine-tuning方法。 主要的限制是标准语言模型是单向的(语言模型是从前面的词预测后面的词),这样在选架构的时候有一些局限性。例如,在OpenAI GPT中,作者使用从左到右的体系结构,其中每个token只能参加Transformer的自注意层中的先前token。 这样的限制对于句子级任务不是最理想的,并且在将基于fine-tuning的方法应用于token级任务(例如问题回答)时可能非常不利,在这种情况下,双向整合上下文至关重要。
BERT通过使用“遮蔽语言模型”(MLM,masked language model)预训练目标,减轻了先前提到的单向语言模型限制 。遮蔽语言模型从输入中随机屏遮蔽了某些token,目的是仅根据其上下文来预测被遮蔽的单词(原始词表对应的id)。 与从左到右的语言模型预训练不同,MLM使语言表征能够融合上下文,这使得我们能够预训练深层双向Transformer模型。 除了遮蔽语言模型外,我们还使用“下一个句子预测”任务来联合预训练文本对表示。
MLM相当于完形填空,左右信息都要看;NSP就是判断两个句子是否相邻(第二句是否是第一句的下一句)。
本文的贡献如下:
- 我们证明了双向预训练对于语言表示的重要性。
- 与GPT不同,它使用单向语言模型进行预训练,BERT使用遮蔽语言模型来实现预训练的深度双向表示。
- 与ELMo不同,后者独立训练的从左到右和从右到左的网络,然后进行简单的浅层连接。(BERT在双向信息的应用上更好)
- 预训练好的语言表征,不需要再去针对特定的任务精心设计模型结构。
BERT是第一个基于fine-tuning的表示模型,可在一系列sentence-level和token-level任务上实现最先进的性能,其性能优于许多任务特定的体系结构。 - BERT推动了11项NLP任务的发展。 可以在BERT上找到代码和经过预先训练的模型。
4.2 结论
最近的实验表明,丰富的、无监督的预训练是许多语言理解系统不可或缺的组成部分。这样使得即使是资源少(样本少)的任务也可以享受深度单向体系结构。我们的主要贡献是将这些发现进一步推广到深层双向体系结构,使的同样的预训练模型能够成功解决各种NLP任务。
4.3 相关工作
4.3.1 基于特征的无监督方法
主要是讲词嵌入、ELMo和之后的一些工作,跳过
4.3.2 无监督的微调方法
代表作是GPT
4.3.3 监督数据中的迁移学习
自然语言推理(Conneau et al.,2017)和机器翻译(McCann et al.,2017)有很多大型的有监督数据集,在这些数据集上预训练好语言模型,再迁移到别的NLP任务上,效果是非常好的。计算机视觉研究还证明了从大型预训练模型进行迁移学习的重要性,其中有效的方法是对通过ImageNet预训练的模型进行微调。
后面的工作表面,NLP领域在大量无标签的数据集上训练出来的模型,比相对小一些的、有标签的数据集上训练的模型效果更好。同样这个想法,也在慢慢被CV领域采用,即在大量无标签的图片上训练的模型,可能比在ImageNet上训练的模型效果更好。
4.4 BERT
4.4.1 模型结构&输入输出
BERT框架两个步骤:预训练和微调。
- 预训练是在无标签数据集上训练的
- 微调使用的也是BERT模型,其权重初始化为预训练权重。所有权重在微调时都会参与训练,微调时使用有标签的数据
- 每个下游任务都会创建一个新的BERT模型,来训练自己的任务。说明见下图:
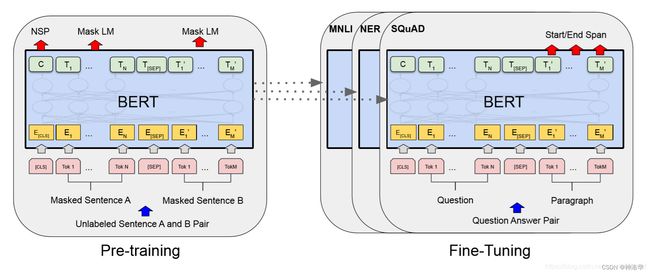
[CLS]是在每个输入示例前添加的特殊符号,[SEP]是特殊的分隔符标记(例如,分隔问题/答案)。
BERT的一个显着特征是其跨不同任务的统一体系结构。 预训练的体系结构与最终的下游体系结构之间的差异很小。
模型结构
BERT的模型架构是多层双向Transformer编码器,基于Vaswani等人描述的原始实现。并且我们的Transformers实现几乎与原始实现相同,所以我们将省略模型结构的详细背景介绍,请读者参考诸如The Annotated Transformer之类优秀的指南。
在这项工作中,我们将层(即,Transformer块)的数量表示为L,将隐藏层的大小表示为H,并将自注意力头的数量表示为A。我们主要报告两种模型尺寸的结果: B E R T B A S E ( L = 12 , H = 768 , A = 12 , T o t a l P a r a m e t e r s = 110 M ) BERT_{BASE} (L=12, H=768, A=12, Total Parameters=110M) BERTBASE(L=12,H=768,A=12,TotalParameters=110M)和 B E R T L A R G E ( L = 24 , H = 1024 , A = 16 , T o t a l P a r a m e t e r s = 340 M ) BERT_{LARGE}(L=24, H=1024, A=16, Total Parameters=340M) BERTLARGE(L=24,H=1024,A=16,TotalParameters=340M)。为了便于比较, B E R T B A S E BERT_{BASE} BERTBASE 选择了和OpenAI的GPT相同的模型的尺寸。
BERT模型可学习参数来自词嵌入层和Transformer块。
- 词嵌入层,词表大小3w,词向量维度为H
- Transformer块分为两部分:
- 自注意力子层:Q、K、V分别通过一个 参数矩阵 ( W Q , W K , W V ) (W^Q, W^K, W^V) (WQ,WK,WV)进行投影,参数矩阵维度是H×H(其实是多头,但是合起来还是原始维度大小。投影前后维度不变,所以矩阵大小必须是H×H)。投影之后输出的多头注意力还会经过一个矩阵 W O W^O WO将其映射回H维。所以自注意力层一共四个参数矩阵,可学习的参数量是 4 H 2 4H^2 4H2。
- MLP层:有两层,输入输出分别是[H,4H]和[4H,H],所以每一层参数是 4 H 2 4H^2 4H2,两层就是 8 H 2 8H^2 8H2。
- 总参数应该是 30000 ⋅ H + L ⋅ 12 H 2 30000\cdot H+L\cdot 12H^{2} 30000⋅H+L⋅12H2,带入base的参数大概就是1.1亿。
模型输入输出
为了可以处理多种任务,BERT输入可以是一个句子,也可以是句子对。在整个工作中,“句子”可以是一段连续的文本,而不仅仅真正语义上的一句话。BERT的输入是一个标记序列,可以是一个或两个句子。
Transformer输入是一个句子对,编码器和解码器分别输入一个句子。而BERT只有编码器,要处理两个句子只能将其并为一个序列。
BERT如果使用空格切词,一个词是一个token。BERT的训练数据量是非常大的,那么词表大小也会特别大,比如百万级别。那么根据上面的算法,模型的可学习参数基本都在词嵌入部分。
WordPiece原理就是,一个词在数据集中出现的概率不大,那么就把它切开成子序列。如果子序列(很可能是词根)出现的概率很大的话,那么只保留这个子序列就行。这样就可以把比较长的词切成一些经常出现的片段。这样词表的大小相对来说比较小。
BERT使用3w个词表的WordPiece embeddings。每个输入序列的第一个标记始终是一个特殊的分类标记([CLS],代表classification),BERT希望CLS对应的最终输出可以代表整个序列的信息。(自注意力可以同时看到所有词,所以CLS放在句首是没问题的,不一定非要在句尾)。
句子对可以合在一起输入,但是为了做句子级别的任务,所以需要区分这两个句子,有两个办法:
- 句尾加上特殊词[SEP]来分隔(表示separate)
- 在词嵌入层用一个可学习的向量来表示每个token是属于句子A还是句子B。
- 在下图中,画出了大概示意。我们用E表示输入embedding,用 C ∈ R H C\in \mathbb{R}^{H} C∈RH来表示特殊token[CLS]的最终隐向量,用 T i ∈ R H T_{i}\in \mathbb{R}^{H} Ti∈RH来表示第i个输入token的最终隐向量。
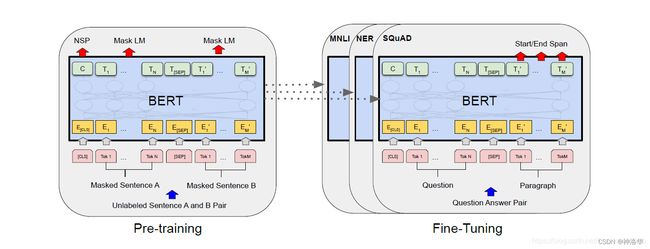
对于给定的token,它的输入表征是由token,segment,和 position embeddings相加构成的。这种结构的可视化效果如图2所示。
Transformer中位置信息是通过位置编码(cos函数)来得到的,而这里的位置信息和句子信息都是通过embedding学出来的。
4.4.2 BERT预训练(MLM+NSP)
Task #1:Masked LM
对于一个token序列,我们随机屏蔽了每个序列中15%的WordPiece token,将其替换为[MASK](CLS和SEP不做替换)。 这带来的一个问题是,微调时数据中是没有[MASK]的。预训练和微调时看到的数据有点不一样。为了缓解这种情况,我们并不总是用实际的[mask]标记替换“masked”词。
如果某个token被选中masked,那么有80%的概率这个token真的被替换为[MASK];10%的概率将其替换为一个随机token(噪音),另外10%保持不变(真实数据,但是这个位置也要预测)。这个概率是实验跑出来的,效果不错。
Task #2:Next Sentence Prediction(NSP)
许多重要的下游任务,如问答(QA)和自然语言推理(NLI)都是建立在理解两个句子之间关系的基础上的,而语言建模并不能直接捕捉到这两个句子之间的关系。为了训练一个能够理解句子关系的模型,我们预先训练一个二值化的下一个句子预测任务。
具体来说,选择的句子对A和B,B有50%的概率是A的下一个句子(标记为is next),50%的概率是语料库中随机挑选句子(标记为notnext。
尽管NSP很简单,但我们在第5.1节中可以看到此任务的预训练对QA和NLI都非常有益。
# 示例
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP] # 两个## 表示后面这个词less跟在flight后,二者是同一个词被切成两半
Label = NotNext
预训练过程很大程度上遵循现存文献的语言模型预训练,我们使用BooksCorpus(800M个单词)和English Wikipedia(25亿个单词)。为了获取长的连续序列,使用文档级的语料(文章)比使用像Billion Word Benchmark这样无序的句子级语料更为重要。
4.4.3 BERT微调
Transformer是编码器解码器结构,编码器和解码器之间是不能直接看到的。而BERT只用了编码器,整个句子对都可以输入模型,self-attention机制能够允许两端相互看,所以self-attention编码的连续文本对,有效的包含了两个序列之间的双向交叉attention。(相比Transformer会做得好一点)
对于每个下游任务,我们只需将特定于任务的输入和输出连接到BERT中,然后端到端微调所有参数。对于输入,预训练中的句子A和句子B类似于(1)释义中的句子对,(2)文本蕴含中的前提和假设对,(3)问答中的问句和段落对,(4)文本分类或者序列标注中不全的text-∅ \varnothing∅ 对。对于输出,token 表示会被喂入token级任务的输出层,例如序列的标注或者问题的答句,并且[CLS]喂入输出层用于分类,例如情感分析和文本蕴含。
论文第四节会详细介绍如何根据下游任务构造输入输出。
4.5 实验
在这部分,我们将介绍BERT在前面提到的11项NLP任务中的结果。
4.5.1 GLUE数据集(分类)
GLUE基准 (Wang et al., 2018a)是一个有着各种NLU任务的集合,在附录B.1中详细介绍了GLUE数据集。下面是最终的GLUE任务分类结果;(句子级别的任务,使用CLS最终输出向量来分类)
4.5.2 SQuAD v1.1(问答)
The Stanford Question Answering Dataset(SQuAD v1.1) 是斯坦福一个包含10w crowd-sourced句子对的数据集。给定一个问题和一个来自包含答案的Wikipedia段落,任务是预测答案在段落中所在的位置(这个片段的开头和结尾)。
具体来说就是学习开始向量S和结尾向量E。通过计算Ti和Si的点积,然后对段落中所有词的点积都进行softmax之后得到第i个词是答案开头的概率。结尾概率的计算同理。
微调使用的epoch值是3,学习率是5e-5,batch size是32。这句话对后面误导很大,因为BERT微调时很不稳定,同样的参数训练,方差非常大。所以 需要多训练几个epoch。另外作者使用的优化器是不完全版的Adam,训练长的时候是没问题,训练短的话有问题,要改回完全版。
4.5.3 SQuAD v2.0(问答)
不再细讲,试验结果如下;
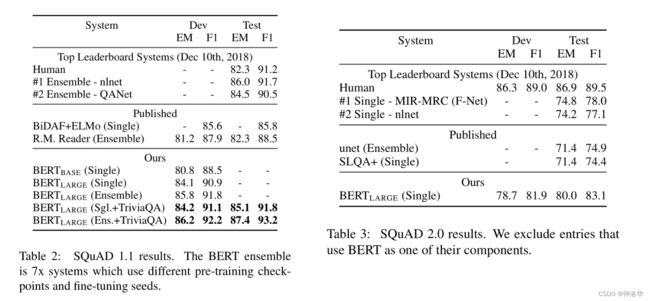
4.5.4 SWAG(句子对任务)
SWAG数据集包括了113K个句子对,给定一个句子,任务是从备选的四个选项中选择最合理的下一句。在SWAG数据集上微调的时候,我们构造四个输入,每一个序列都是由给定的句子(sentenceA)和可能的下一句(sentence B)组成。唯一要引入的特定任务参数是一个向量,这个向量与[CLS] 的输出C进行点积表示为每一个选择的分数,然后用softmax得到概率(和上面差不多)。微调的参数为epoch=3,learning rate=2e-5,batch size=16。试验结果就不贴了。
4.6消融试验
在这一部分,我们对 BERT 的许多方面进行了消融实验,以便更好地理解每个部分的相对重要性。其他的一些研究可以在附录C中找到。
4.6.1 模型各部分的影响
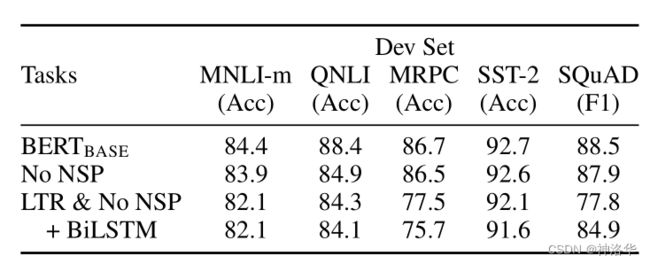
- BASE模型
- No NSP:去掉NSP任务
- LTR&No NSP:模型只是从左看到右,不使用MLM模型,且没有NSP,但是加上一个BiLSTM
4.6.2 模型配置的影响
我们将探讨模型大小对微调任务准确度的影响。我们使用了不同的层数,隐藏单元,注意力头数训练了一些BERT模型,而其他超参数和训练过程与之前描述的一样。
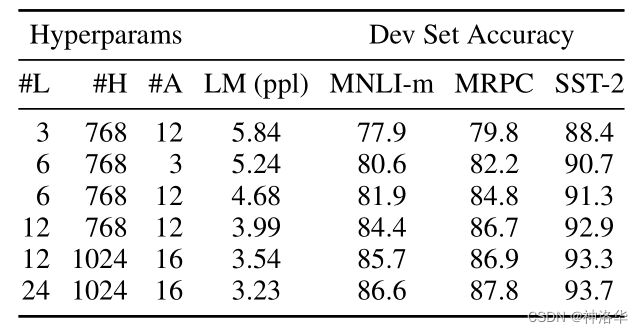
我们能够看出在所有的数据集上,越大的模型准确率越高,甚至是只有3600个标注的训练样本的MRPC任务。年来人们都知道,增加模型的大小将带来如机器翻译和语言模型上的持续提升,然而,这是第一次有力的证明,如果模型得到了足够的预训练,那么将模型扩展到极端的规模也可以在非常小的任务中带来巨大的改进(只需要进行微调少量参数)。
BERT由此引发了模型大战,看谁的模型更大。GPT-3都有一千个亿的参数,现在的模型都有往万亿的路上走。
4.6.3 特征提取
简单说就是,将BERT作为特征提取器,而不是进行微调,效果相比之下会差一些。所以使用BERT应该微调。
4.7 总结
BERT使用Transformer的编码器而不是解码器,好处是可以训练双向语言模型,在语言理解类的任务上表现比GPT更好,但缺点是,做生成类的任务不方便,比如机器翻译、摘要生成等等。只不过NLP领域,分类啊之类的语言理解任务多一些,所以大家更喜欢用BERT。
BERT满足了深度学习研究者的一个喜好:训练一个3亿参数的模型,在几百G的数据集上预训练好,就可以提升一大批NLP的下游任务,即使这些任务的数据集都很小。
GPT和BERT是同期提出的模型,两者都是预训练模型微调,很多思路是一样的,即使后者效果好一点也会被后来者超越,那为啥BERT更出圈?因为BERT的利用率是GPT的10倍,影响力自然就大了10倍不止。