SAC:简单高效的域自适应语义分割自监督方法(CVPR2021语义分割)
今天和大家分享一篇发表在CVPR2021上的语义分割论文,面向域自适应语义分割领域。

论文下载地址:https://arxiv.org/abs/2105.00097
代码下载地址:https://github.com/visinf/da-sac
0.动机
无监督的域自适应(Unsupervised domain adaptation,UDA)解决无标签测试数据和带标签训练数据分布不一致问题。
在语义分割领域中,相比于手工或者半手工标注真实世界的标签,使用合成的数据集和标签有更低的成本。
近年来,多种用于解决模型从合成数据集迁移到真实数据集的UDA方法涌现出来,随着这些方法的性能越来越强大,它们的复杂度也越来越高,逐渐包含了风格迁移网络(style transfer network)、对抗训练(adversarial training)、网络集成(network ensembles)等方法。复杂性的提高会增加复现难度,也会减缓该领域的进一步发展。
作者提出了一个简单的UDA框架用于域自适应语义分割领域,不需要使用过于复杂的方法即可达到很好的性能。
作者提出的方法与其他方法在性能、复杂度方面的比较如下图所示:

上图表示使用VGG16 Backbone的多种UDA方法,从GTA5数据集到Cityscapes数据集的性能对比。相比于其他方法,该方法没有使用对抗训练、风格迁移等手段,只需要single round训练,即可达到很好的性能。
1.Self-supervised Augmentation Consistency(SAC)
1.1 总体结构
SAC(Self-supervised Augmentation Consistency)的总体结构如下图所示,从图中可以看出,SAC包含Momentum Net和Segmentation Net共2个网络:Segmentation Net用于自适应target domain;Momentum Net用于提供pseudo label。
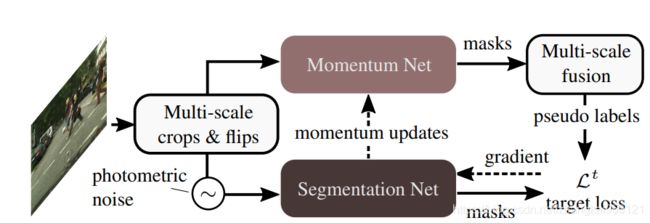
将target domain中的单张图片进行crop、horizontal flip等变换,将变换得到的多张图片分别作为2个网络的输入;将Momentum Net的输出结果进行反变换,对多张图片的预测结果进行平均,得到原始的单张图片中每个像素的预测结果,通过预测结果和适当的阈值,得到该单张图片的pseudo label;将pseudo label作为标签,使用随机梯度下降法训练Segmentation Net,更新该网络的权重;通过一些策略,使用更新后的Segmentation Net权重来更新Momentum Net的权重,使得Momentum Net能够得到更好的pseudo label。
1.2 Batch构建策略
将target domain中的每张图片进行random scale、flip操作,但是变换过程中保留长宽比。
将变换操作得到的多个crop图片和原始图片都resize成 h × w h \times w h×w分辨率,如下图所示:

将上述操作得到的多个图片作为Momentum Net的输入图片,用于得到pseudo label;将上述操作得到的图片添加random colourjitter,并进行Gaussian filter操作,得到的结果作为Segmentation Net的输入图片,用于训练Segmentation Net,以提高Segmentation Net的鲁棒性。
1.3 多尺度图片的分割结果融合策略
将原始图片和变换后的crop作为Momentum Net的输入,得到的分割结果需要通过反变换融合在一起,如下图所示:

对于原始图片和crop交叉的像素,使用多个预测结果的平均值作为该像素的预测结果;若某个像素处于所有crop之外,即只在原始图片中存在,则使用原始图片的预测结果作为该像素的预测结果。
Momentum Net的预测结果通过相应类别的阈值,得到pseudo label。
1.4 长尾分布问题
作者使用了3个策略来较好地解决长尾分布问题:
(1)基于样本的自适应阈值用于生成pseudo label
作者使用了自适应阈值的方法,对于长尾类别,使用较低的阈值生成pseudo label,使得长尾分布的类别有较多的像素用于训练Segmentation Net。
该阈值与样本相关。对于第 n n n个样本中的类别 c c c,定义:
χ c , n = 1 h w ∑ i , j m c , n , i , j \chi_{c, n}=\frac{1}{h w} \sum_{i, j} m_{c, n, i, j} χc,n=hw1i,j∑mc,n,i,j
上式中的 m c , n , : , : m_{c, n, :, :} mc,n,:,:为Momentum Net输出的类别 c c c的概率值, h h h和 w w w分别为输入图片的高和宽。
对于第 t + 1 t+1 t+1次迭代,定义:
χ c t + 1 = γ χ χ c t + ( 1 − γ χ ) χ c , n \chi_{c}^{t+1}=\gamma_{\chi} \chi_{c}^{t}+\left(1-\gamma_{\chi}\right) \chi_{c, n} χct+1=γχχct+(1−γχ)χc,n
上式中 γ χ ∈ [ 0 , 1 ] \gamma_{\chi} \in[0,1] γχ∈[0,1]
对于第 n n n个样本,类别 c c c的阈值为:
θ c , n = ζ ( 1 − e − χ c / β ) m c , n ∗ \theta_{c, n}=\zeta\left(1-e^{-\chi_{c} / \beta}\right) m_{c, n}^{*} θc,n=ζ(1−e−χc/β)mc,n∗
上式中的 β \beta β和 ζ \zeta ζ为超参数, m c , n ∗ m_{c, n}^{*} mc,n∗为属于类别 c c c的像素在该图片上的最大概率,即:
m c , n ∗ = max i , j m c , n , i , j m_{c, n}^{*}=\max _{i, j} m_{c, n, i, j} mc,n∗=i,jmaxmc,n,i,j
需要注意的是,pseudo label是随着Momentum Net的更新而变化的,所以阈值 θ c , n \theta_{c, n} θc,n应该与Momentum Net的迭代次数有关,表现在公式中,即 χ c \chi_{c} χc的值与迭代次数有关。
对于第 n n n个样本中的类别 c c c,阈值 θ c , n \theta_{c, n} θc,n与 χ c \chi_{c} χc的关系可以用下图直观表示:
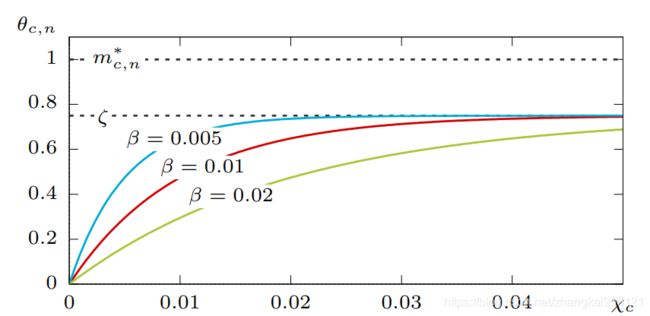
对于主要的样本, χ c \chi_{c} χc的值一般比较大,因此 θ c , n ≈ ζ m c , n ∗ \theta_{c, n} \approx \zeta m_{c, n}^{*} θc,n≈ζmc,n∗,即阈值 θ c , n \theta_{c, n} θc,n也比较大;对于长尾样本, χ c \chi_{c} χc的值一般比较小,阈值 θ c , n \theta_{c, n} θc,n也比较小。
通过Momentum Net的输出和阈值,可以得到pseudo label:
m ^ n , i , j = { c ∗ m c ∗ , n , i , j > θ c , n ignore otherwise \hat{m}_{n, i, j}=\left\{\begin{array}{ll} c^{*} & m_{c^{*}, n, i, j}>\theta_{c, n} \\ \text { ignore } & \text { otherwise } \end{array}\right. m^n,i,j={c∗ ignore mc∗,n,i,j>θc,n otherwise
上式中 c ∗ = arg max c m c , n , i , j c^{*}=\arg \max _{c} m_{c, n, i, j} c∗=argmaxcmc,n,i,j,表示第n个样本中位置 ( i , j ) (i,j) (i,j)处的像素概率最大的类别。上式表示:若该像素最大概率值大于阈值,则pseudo label为该概率值对应的类别;否则将该像素的pseudo label标记为ignore,在训练时不计算损失。
(2)Focal Loss
使用focal loss来增加长尾类别对于损失函数的贡献:
L n t ( m ˉ , m ∣ ϕ ) = − m c ∗ , n ( 1 − χ c ∗ ) λ log ( m ˉ c ∗ , n ) \mathcal{L}_{n}^{t}(\bar{m}, m \mid \phi)=-m_{c^{*}, n}\left(1-\chi_{c^{*}}\right)^{\lambda} \log \left(\bar{m}_{c^{*}, n}\right) Lnt(mˉ,m∣ϕ)=−mc∗,n(1−χc∗)λlog(mˉc∗,n)
对于长尾类别的样本, χ c ∗ \chi_{c^{*}} χc∗的值比较小,若超参数 λ \lambda λ值比较高,则会增加该样本对损失函数的贡献; m c ∗ , n m_{c^{*}, n} mc∗,n表示Momentum Net输出的概率值,若pseudo label是错误的,该值会比较小,从而使得损失函数较小,避免引导Segmentation Net向错误的方向更新参数。
(3)Importance sampling
作者优化了训练时样本的读取方式,来解决只在很少图片样本中出现的类别,比如“bus”、“train”。
首先,使用均匀分布随机采样类别 c c c;然后,依照如下公式计算的概率,采样包含类别 c c c的样本:
χ ^ c , l = χ c , l ∑ n χ c , n \hat{\chi}_{c, l}=\frac{\chi_{c, l}}{\sum_{n} \chi_{c, n}} χ^c,l=∑nχc,nχc,l
2.训练
在使用source data训练Segmentation Net时,交替使用由source image构成的batch和由target image构成的batch。
在使用source image时,使用交叉熵损失函数。在使用target image时不计算loss,只更新BN层的running mean和standard deviation,不更新其他层的可学习参数。
待Segmentation Net在source image上训练完成后,复制Segmentation Net权重到Momentum Net中;读取target image,由Momentum Net生成pseudo label,用于进一步训练Segmentation Net;每隔 T T T个迭代周期,调整一次Momentum Net的权重值 ψ \psi ψ:
ψ t + 1 = γ ψ ψ t + ( 1 − γ ψ ) ϕ \psi_{t+1}=\gamma_{\psi} \psi_{t}+\left(1-\gamma_{\psi}\right) \phi ψt+1=γψψt+(1−γψ)ϕ
上式中的 ϕ \phi ϕ表示Segmentation Net的可学习参数, γ ψ \gamma_{\psi} γψ用来表示Momentum Net中可学习参数的更新程度。
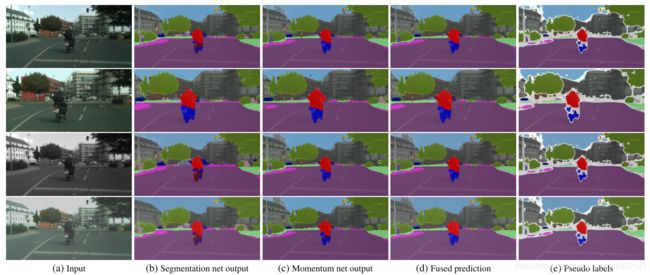
下图表示了Segmentation Net输出、Momentum Net输出、融合结果和pseudo label的几个例子:
3.实验结果
分别使用GTA5、SYNTHIA数据集作为source image,使用Cityscapes数据集作为target image。需要注意的是,在训练时不使用Cityscapes数据集的标注信息。在Cityscapes验证集上进行测试。
使用DeepLabv2分割方法,分别使用VGG16和ResNet-101作为Backbone。在生成pseudo label时,令 γ χ = 0.99 \gamma_{\chi}=0.99 γχ=0.99、 ζ = 0.75 \zeta=0.75 ζ=0.75、 β = 1 0 − 3 \beta=10^{-3} β=10−3;使用focal loss时,令 λ = 3 \lambda=3 λ=3;在更新Momentum Net时,令 γ ψ = 0.99 \gamma_{\psi}=0.99 γψ=0.99、 T = 100 T=100 T=100。
Backbone使用在ImageNet数据集上预训练的权重;在source image上训练时,batch size为16,输入图片分辨率为 640 × 640 640 \times 640 640×640;在自监督训练时,batch size为16,且包含8张source image和8张target image,8张source image来自2张原始图片和6张它们的变换图片。
使用GTA5数据集迁移到Cityscapes数据集上的结果如下表所示:

使用SYNTHIA数据集迁移到Cityscapes数据集上的结果如下表所示:

从上面2个表格中可以看出,SAC方法比其他方法有更好的性能。表中的baseline表示只使用source image训练的网络。
可视化的结果如下图所示:
4.总结
这篇论文提出的SAC方法的组成部分很简单,没有包含对抗训练、风格迁移网络等复杂的部分,但是相比其他方法有很好的性能。
此外,SAC方法也可以尝试应用到其他领域中,比如深度估计、实例分割等任务。
推荐阅读
引用超7000次的SegNet:Encoder-Decoder架构的端到端语义分割网络
FCN:使用端到端CNN进行语义分割的开山之作
如果你对计算机视觉中的目标检测、跟踪、分割、轻量化神经网络感兴趣,欢迎关注公众号~
