Mysql 索引
图片来源网络,侵删。图片来源于掘金小册
索引
Mysql 的索引类型有很多种,Hash索引,B树索引,B+树索引和全文索引。Mysql有多种存储引擎,每个存储引擎对索引的支持可能会不同。
What
Mysql 索引是能改善数据库表随机访问速度的一种数据结构。可以通过指定一个或者多个指定列的方式创建索引。
所以索引是一种数据结构。
Why
当数据量达到一定程度的时候,如果根据顺序扫描全部的数据,会出现数据查询效果低,查询时间长,导致用户体验不佳。为了提高数据的访问的效率,引入了索引。
How
创建索引的时候,需要指定至少一列数据列,根据某种规则,使用 B+树的方式对数据进行组织。当查询数据的时候,Mysql 查询优化器 会判断该语句是否有可以使用的索引,然后根据可以使用的索引计算打分,最终比较各个 查询结果的打分,选择最优的一种查询方式查询数据。所以,创建了索引之后,Mysql 进行查询的时候,不一定会使用索引进行查询。
下面都是基于 Mysql 的InnoDB 引擎和MyIsam引擎
执行计划查看
当需要执行一个SQL语句的时候,可以通过Mysql提供的 explain 查看Mysql 生成的执行计划。
-
select_type
查询的类型:表明查询语句的类型,是一个简单的查询,还是使用了联合查询等。
-
table
表名
-
type
针对单表的访问方式
- const
- eq_ref
- ref:使用普通二级索引列进行查询
- fulltext:全文索引
- ref_or_null:普通二级索引,但是索引可能为Null
- index_merge:索引合并的方式查询
- unique_subquery:子查询会用到id列的聚簇索引
- index_subquery:子查询使用的是普通索引
- range:范围查询
- index:可以使用覆盖索引,但是需要扫描全部的索引
- All
-
possible_keys
可能用到的索引
-
key
实际使用的索引
-
key_len
索引长度
-
ref
当使用索引列等值查询的时候,与索引列进行等值匹配的对象信息。
他的值的展示和type相关,只有在 const、eq_ref、ref、ref_or_null、unique_subquery、index_subquery时才会展示。
-
rows
预估需要读取的记录数
-
filtered
针对预估的需要读取的记录,经过搜索条件过滤后剩余记录条数的百分比
-
extra
额外的信息
索引类型
Mysql中根据 索引中是否存在数据,将索引分为了两种类型的索引:聚簇索引和非聚簇索引。
-
聚簇索引
聚簇索引是在索引树的叶子节点中保存了完整的数据信息,则索引称为聚簇索引。Mysql的 InnoDB引擎为主键创建的主键索引即是聚簇索引,数据文件即是索引文件。MyIsam引擎中的主键索引也是非聚簇索引。
-
非聚簇索引
非聚簇索引是指索引树的叶子节点中保存的不是完整的数据信息,而是指向数据的一个指针或者是地址信息等(MyIsam的主键索引是指向数据的地址信息,InnoDB 中是主键的Id)。如果需要获取全部的数据信息,需要进行一次回表的操作。
-
联合索引
联合索引是同时对多个列创建的索引。索引树中的叶子节点会同时包含多个列的值,叶子节点之间的排序,会根据创建索引时候列的顺序排序,排序满足最左前缀规则。
最左前缀规则:例如当存在一个联合索引,包括了A、B、C三列的时候,如果查询是使用了 A、【A、B】、【A、B、C】的查询方式,则可以使用这个索引,如果是 使用了 【B、C】作为查询条件,则不满足最左前缀原则,则不会使用这个索引。
因为Mysql在创建联合索引的时候,是先去比较第一列的值,当第一列的值相同的时候,才会比较第二列的值,当第二列的值相同的时候,再去比较第三列的值,以此类推,直到最后的一列。所以,当跳过第一列的值,直接匹配第二列的时候,此时第二列的值不一定是有序的,所以无法使用。
-
覆盖索引
当使用某个查询条件的时候,如果需要查询的所有字段在索引中已经存在,即可直接返回,不用再根据查询到的主键ID进行回表操作,称为覆盖索引。
如果我们为name和age 创建了一个索引。当我们查询name为指定值的数据的age 和Id的时候,就会使用覆盖索引。因为在索引数据已经存在了 name 和 age 的值(主键ID的值是每一个索引都会存在的),不会再根据id回表聚簇索引查询数据。
如果在索引中不存在查询的字段数据信息,则会在查找到满足条件的数据之后,会根据查找到数据的主键ID,回表聚簇索引查找其他的信息,最终返回数据。
-
唯一索引
唯一索引要求指定的列的值不能存在相同的值,数据库在每一次进行添加或者修改的时候,都会进行数据的检查,如果数据存在了重复的值,则会直接返回失败。
索引原理
Mysql 中索引使用的数据类型是B+树。
why
-
为什么索引使用的数据结构是B+树,而不是二叉树或者是B树?
使用二叉树查询的时候,查询的时间复杂度是O(log n),查询的时间效率已经很快。但是二叉树存在一个问题是,每一个分支上,最多就只有两个分支,当数据量大的时候,就会导致树的高度很高,查询的时候,IO的次数就会增多,查询的效率就会有所下降。使用B树或者B+树,让一个节点,可以有多个分支,可以很好的降低树的高度,减少IO的次数,提升查询的效率。
-
为什么选择了B+ 树而不是B树?
- B树的特点是每一个节点中都会存储key和数据,而B+树只有叶子节点才会存储数据信息(这里的数据信息 指 索引的数据信息。针对聚簇索引),其他的节点都只会存储key的信息。Mysql在查询的时候,因为其他节点的数据量少,可以一次性的在内存中加载更多的key的数据,以供查询使用。
- B树的叶子节点之间是独立的,B+树的叶子节点之间有指针将叶子节点相连接起来。Mysql是一种关系型数据库,多个数据之间可能是存在一定的关系的,当查询某一个数据的时候,可能会查询和之相关的一些其他的数据,可以很好的支持范围查询。
- B树的查询效率不稳定,B+树查询的效率稳定。当查询数据的时候,B树在遇到满足条件的额数据之后,就会返回数据信息,不会走到叶子节点。但是B+树在查询的时候,无论如何都会走到叶子节点,才会获取到数据,并返回数据信息。
- 因为B+树的叶子节点不会存放数据信息(这里的数据信息指 完整的数据信息,包括了未添加索引的列的信息。即 索引中的 叶子节点,只会存放 索引列的数据,不包括未被索引的数据。聚簇索引包括所有数据,其他索引只包括 索引列和主键列),所以有更多的空间来存放key的信息,可以让树的高度更低,IO的次数更少,效率更高。
How
在添加数据或者是修改的索引列的数据的时候,Mysql需要去维护索引的信息。下面是基于聚簇索引,非聚簇索引中,叶子节点存储的是主键ID(如果没有手动指定主键ID,Mysql会主动维护一个主键Id),其他的均是一致的。
Mysql的数据,在索引树中存储的基本单位是页,即多个Mysql的数据项(暂且把用户数据和目录数据均称为数据项)组成了一个 页。当页的大小用完的时候,就会分裂出一个新的列,然后使用指针和之前的列连接起来,形成一个链表。

因为这些节点在内存中的位置不一定是连续的,如果想要快速的从内存中找到对应的数据,就需要为这些数据创建一个目录,每一页对应一个目录项。然后再将目录项组装成一个 页,也就形成了如下的格式:
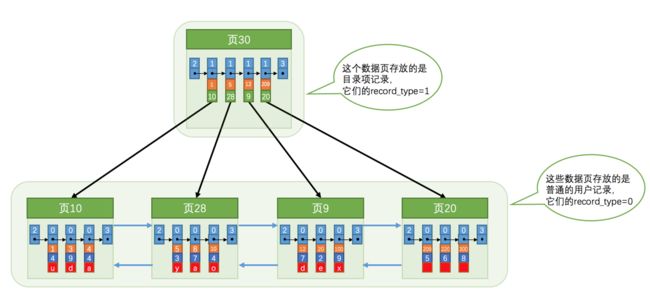
目录项中记录的每一个数据页中的最小值以及页号,就可以通过比较值的大小,找到对应的页,就可以快速的定位到对应的数据。
当目录页中的空间地址不足的时候,就分裂目录页,然后和数据页一样,使用指针将两个目录页串联起来,形成一个双向链表。

以此类推,直到形成一个根目录(实际创建的时候,是先有的根目录,然后再慢慢的增加后续的目录页和数据页)。然后就形成了一棵B+树。查询的时候,就可以通过比较根目录中记录的Id 的大小,找到对应的Id 所在的下一级目录页,然后以此类推找到最终的叶子节点,就可以快速的找到对应的数据。
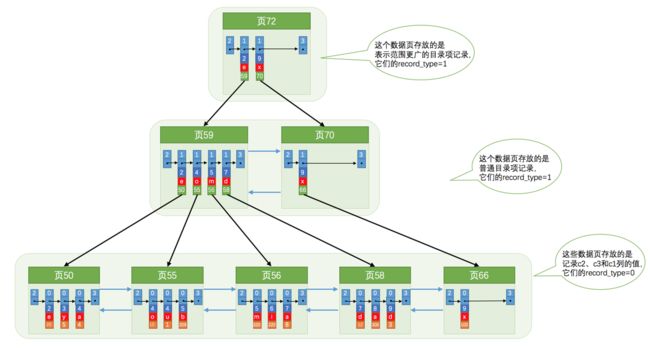
所以从上述的过程中发现,创建的主键Id,最好是选用自增的ID,因为自增ID的顺序只需要在最后追加即可,如果是非规则的数据,可能下一次的id顺序比之前的都小,Mysql为了维护id的顺序,则会进行数据的移动,就会涉及到数据的迁移以及页的分裂等。
索引失效
索引失效是指为数据列创建了索引,但是在使用的时候,虽然使用了索引列,但是索引的作用不会生效,最终查询的时候,不会使用索引树进行查询。
索引失效的条件
-
索引列上的操作
- 类型转换
- 计算
-
like查询以"%"开头
因为Mysql在比较字符串的时候,是根据字符串从左到右做比较,满足最左匹配原则,当使用"%"开头查询的时候,就会破坏最左原则,所以不能使用索引。
-
破坏最左前缀原则:联合索引查询的时候,如果不满足最左前缀原则,则不会使用索引
-
范围查询的右边索引会失效
当有A、B、C三个联合索引的时候,如果
where A = 123 and B > 20 and C = 456;则C的索引会失效。因为 B 会返回多个值,会根据返回的多个值再去做匹配查询。因为在多个值的情况下,C的排序未必是有序的,可能是乱序的情况,无法使用索引。
-
or 查询
or 查询会产生多条数据,这多个数据之间排序规则是不确定的。
-
使用 ≠ 做判断
-
字符串没有加单引号:会发生类型的隐式转换
-
估计全表扫描会比索引快
排序产生filesort的原因
当对查询需要进行的排序的时候,如果排序的字段没有使用索引,或者不满足最左前缀原则,则会使用文件排序的方式,来完成排序。
索引下推
what
索引下推是指Mysql的服务器会把 查询条件 下推到存储引擎中。
How
如果查询语句中的所有的查询条件均是在索引中存在的,则Mysql服务器会把查询条件下推到存储引擎中,存储引擎判断如果满足条件就会直接返回数据,如果不满足,则继续下一条数据。
如果查询条件中的部分条件不是索引中的列数据信息,则存储引擎在满足索引条件之后,就会返回数据,然后Mysql服务器再去获取整个数据,然后判断数据是否满足,满足则需要,否则抛弃数据。
Why
使用索引下推在一定程度上可以减少IO的次数,因为返回的数据均是满足条件的数据,Mysql服务器不用再去获取一次数据判断。
索引合并
https://www.cnblogs.com/digdeep/p/4975977.html
当我们进行数据查询的时候,我们的where 语句中可能存在有多个查询条件,可能会走到多个索引。Mysql 5.1 之前只会选择其中一个索引进行数据查询,然后交给Mysql服务器去做数据过滤。5.1之后引入的索引合并(Index merge)技术,支持通过多个索引去查询数据,然后对结果进行计算。
- Index-Intersection
- Index-Union
- Index-Sort-Union