机器学习:线性回归
机器学习:线性回归
1、实验描述
-
本实验中提供一份关于产品广告费用与对应产品销量的数据文件Advertising.csv文件,利用此文件建立线性模型、训练模型、用模型做预测分析。
-
实验时长:45分钟
-
主要步骤:
-
加载csv文件
-
获得标签和特征数据
-
展示标签和特征的关系图
-
切分数据集
-
创建模型
-
用模型做预测
-
模型评估
-
2、实验环境
-
虚拟机数量:1
-
系统版本:CentOS 7.5
-
scikit-learn版本: 0.19.2
-
pandas版本:0.22.4
-
numpy版本:1.15.1
-
python版本:3.5
3、相关技能
- Python编程
- Pandas编程
- Sklearn的使用
- 线性回归建模
- 用matplotlib 绘图
4、相关知识点
-
Pandas 读取csv文件
-
Pandas读取特征、标签数据
-
数据集进行划分
-
线性模型
-
模型预测
-
模型评估
5、实现效果
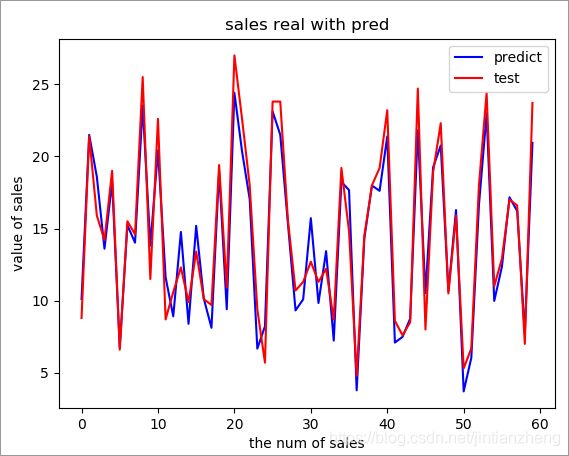
- 利用线性回归模型对测试集数据做预测,下图展示了实际销售量和预测销量的拟合效果:

6、实验步骤
6.1进入Anaconda创建的虚拟环境 “ML”
6.1.1从zkpk的公共目录下拷贝实验所需的数据文件Advertising.csv到zkpk的家目录下
[zkpk@master ~]$ cd
[zkpk@master ~]$ cp /home/zkpk/experiment/Advertising.csv /home/zkpk
6.1.2数据集介绍:
6.1.2.1Advertising.csv数据共4列200行,每一行对应一个特定的商品,前3列为输入特征,最后一列为输出特征。
6.1.2.2输入特征:TV:该商品用于电视上的广告费用(以千元为单位,下同;)Radio:在广播媒体上投资的广告费用;Newspaper:用于报纸媒体的广告费用。
6.1.2.3输出特征:Sales:该商品的销量
6.1.3在zkpk的家目录下执行如下命令
[zkpk@master ~]$ cd
[zkpk@master ~]$ source activate ML
(ML) [zkpk@ master ML]$
6.1.4此时已经进入虚拟环境。键入如下命令,进入ipython交互是编程环境
(ML) [zkpk@ master ML]$ ipython
Python 3.5.4 |Anaconda, Inc.| (default, Nov 3 2017, 20:01:27)
Type 'copyright', 'credits' or 'license' for more information
IPython 6.2.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
6.2在Ipython交互式编程环境中开始进行实验
6.2.1导入实验所需的包
In [1]: import pandas as pd
...: import matplotlib.pyplot as plt
...: from sklearn.model_selection import train_test_split
...: from sklearn.linear_model import LinearRegression
...: from sklearn.metrics import mean_squared_error # 圴方误差
...: import numpy as np
...: import sys
6.2.2读取数据文件
In [2]: path = 'Advertising.csv'
In [3]: data = pd.read_csv(path) # 读取csv文件
6.2.2.1打印文件的前几行
In [4]: data.head(10)
6.2.2.2显示文件的shape
In [5]: print(data.shape)
6.2.3使用pandas读取相应的维度分别作为特征值X, 和标签值Y
In [6]: x = data[['TV', 'Radio', 'Newspaper']]
In [7]: y = data['Sales']
6.2.4绘制不同特征和标签的关系
In [8]: plt.figure(figsize=(9, 12)) #图示的大小
plt.subplot(311) # 子图位于全图3行1列中的的第一个位置
plt.plot(data['TV'], y, 'ro') # 子图的横纵坐标的两个维度;ro:其中r表示线条的颜色;o表示红色和组成(圆圈);具体可参考下图
plt.title('TV') # 子图的title
plt.grid() # 生成网格
plt.subplot(312) # 类似
plt.plot(data['Radio'], y, 'b*')
plt.title('Radio')
plt.grid()
plt.subplot(313)
plt.plot(data['Newspaper'], y, 'g^') # g^:表示绿色的,三角形
plt.title('Newspaper')
plt.grid()
plt.show()
下图中列出了不同字符所代表的线或者marker的样式


6.2.5分析上边结果图,在报纸“Newspaper”上所花广告费用与商品的销量不成线性相关的,所以后面建模时,可以尝试删掉该特征。
x=data[['TV','Radio']]
6.2.6使用sklearn自带的数据预处理模块对数据集进行切分,构建训练集和测试集,比例为7比3
In [9]: x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3
...: , random_state=23)
6.2.7使用sklearn的线性回归类建模,参考normalize=True表示指定对训练数据进行正则化操作;n_jobs=-1表示使用所有的cpu进行训练。
In [10]: lr = LinearRegression(normalize=True,n_jobs=-1)
In [11]: model = lr.fit(x_train, y_train) # 利用训练数据,训练模型
6.2.8打印模型的相关参数
In [12]: print(lr.intercept_) # 打印线性模型的截距值
...: print(lr.coef_) # 返回模型的估计系数
6.2.9使用训练好的模型进行预测
y_pred = model.predict(x_test)
6.3使用RMSE(标准误差)对模型进行评估
mse = mean_squared_error(y_test, y_pred) # 传入实际的标签值y_test,和预测的标签值y_pred
print("MSE : ",mse) # MSE 均方误差
print("RMSE :" ,np.sqrt(mse)) # 标准误差

6.4将标签的实际值和预测值用图展示出来,直观的观察拟合程度。
plt.figure()
plt.plot(range(len(y_pred)), y_pred, 'b', label='predict')
plt.plot(range(len(y_test)), y_test, 'r', label='test')
plt.legend(loc='upper right') #标签的显示位置 右上角。
plt.xlabel("the num of sales") # x轴标签
plt.ylabel("value of sales") # y轴标签
plt.title("sales real with pred") # 图像的title
plt.show()
7、参考答案
- 代码清单lr1.py

8、总结
完成本次实验,可以掌握线性回归模型的基础知识,包括理论与动手编程两方面,其中编程部分涉及模型的构建、训练,以及使用matplotlib对结果进行可视化,观察不同的特征对标签的实际影响。在建模过程中,可以先删减与target呈非线性相关的特征,再建立模型、训练模型。