Keras深度学习实战(31)——构建电影推荐系统
Keras深度学习实战(31)——构建电影推荐系统
-
- 0. 前言
- 1. 模型与数据集分析
-
- 1.1 数据集分析
- 1.2 模型分析
- 2. 电影推荐系统
-
- 2.1 基于 LSTM 实现电影推荐系统
- 2.2 考虑用户历史记录
- 小结
- 系列链接
0. 前言
推荐系统在用户发现中起主要作用。假设,我们具有数千种不同的产品,每种产品还存在不同的规格、样式等。在这种情况下,对用户进行有关产品的精准推荐将成为增加销量的关键。在本节中,我们将以电影推荐系统为例介绍推荐系统模型构建的方法,从而为用户推荐其真正感兴趣的产品。
1. 模型与数据集分析
在本节中,我们将学习如何根据用户对电影的评分数据库构建电影推荐系统,任务目的是最大限度地提高所推荐电影对用户的相关性。在定义目标时,我们还应该考虑推荐的电影虽然相关,但用户可能并不会立即观看。同时,我们还应该确保所有的推荐并不都是关于同一种类型的,这对于推荐系统至关重要,例如,在零售环境中,我们并不希望一直向用户推荐不同规格的同一种产品。
综合以上分析,我们可以形式化地定义我们的目标和约束条件:
- 目标:最大限度地提高推荐与用户的相关性
- 约束:增加推荐的多样性,并向用户提供最多
12条推荐建议
相关性的定义在不同任务中可能会有所不同,通常需要以实际业务需求为指导。在本任务中,我们狭义地定义相关性,也就是说,如果用户采纳了向用户推荐的前 12 条建议中的任何一个,则认为推荐成功相关。
1.1 数据集分析
用于模型训练的数据集中包含用户信息以及他们对其观看过的电影评分信息,其中第一列表示用户编号,第二列表示电影编号,第三列表示用户对电影的评分,最后一列表示时间戳,关于该数据集的详细介绍及下载方式,参考《推荐系统数据编码》。
1.2 模型分析
在实现电影推荐系统前,我们首先梳理构建推荐系统模型的策略流程:
- 导入数据
- 推荐用户评价较高的电影,我们根据用户在历史记录中喜欢的电影来训练我们的模型。我们也可以根据用户不喜欢的电影来进一步改善推荐的准确性,但为了简单起见,本任务暂不考虑用户不喜欢的电影
- 只保留观看过
5部以上电影的用户 - 为不同用户和电影分配不同
ID - 鉴于用户的偏好可能会随着时间而变化,因此我们需要考虑用户的历史记录,其中历史记录中的不同事件具有与之相关的不同权重。因此,这是一个典型的时间序列分析问题,可以利用循环神经网络 (
Recurrent neural networks,RNN) 来解决此问题 - 预处理数据,以便可以将其传递到长短时记忆网络 (
Long Short Term Memory,LSTM) :- 输入是用户历史观看的
5部电影 - 输出是用户观看的第
6部电影
- 输入是用户历史观看的
- 构建模型执行以下操作:
- 为输入影片创建嵌入
- 将嵌入传递到
LSTM层 - 将
LSTM层的输出连接到全连接层 - 在最后一层上应用
softmax函数,以输出要推荐的电影列表
2. 电影推荐系统
在本节中,我们根据在上一小节中定义的模型策略实现电影推荐模型。
2.1 基于 LSTM 实现电影推荐系统
(1) 导入用户-电影数据集,该数据集包含用户列表,并且具有用户为不同电影提供的评分以及用户提供评分时相应的时间戳:
import numpy as np
import pandas as pd
column_names = ['User', 'Movies', 'rating', 'timestamp']
ratings = pd.read_csv('u.data', sep='\t', names=column_names)
print(ratings.head())
数据集的示例如下所示:
User Movies rating timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596
(2) 筛选出用户不喜欢的电影(即用户对电影评分较低)的数据样本或没有足够历史记录的用户数据样本。首先,排除用户提供较低评分的电影数据样本:
ratings = ratings[ratings['rating']>3]
ratings = ratings.sort_values(by='timestamp')
ratings.reset_index(inplace=True)
ratings = ratings.drop(['index'],axis=1)
然后,我们仅保留历史记录中评价的电影数量超过 5 的用户:
user_movie_count =ratings.groupby('User').agg({'Movies':'nunique'}).reset_index()
user_movie_count.columns = ['User','Movie_count']
ratings2 = ratings.merge(user_movie_count,on='User',how='inner')
movie_count = ratings2[ratings2['Movie_count']>5]
movie_count = movie_count.sort_values('timestamp')
movie_count.reset_index(inplace=True)
movie_count = movie_count.drop(['index'],axis=1)
(3) 为不同用户和电影分配不同 ID,以便后续使用:
ratings = movie_count
users = ratings.User.unique()
movies = ratings.Movies.unique()
userid2idx = {o:i for i,o in enumerate(users)}
moviesid2idx = {o:i for i,o in enumerate(movies)}
idx2userid = {i:o for i,o in enumerate(users)}
idx2moviesid = {i:o for i,o in enumerate(movies)}
ratings['Movies2'] = ratings.Movies.apply(lambda x: moviesid2idx[x])
ratings['User2'] = ratings.User.apply(lambda x: userid2idx[x])
(4) 预处理数据,使用大小为 5 的滑动窗口构建输入电影,输出为用户已观看的第 6 部电影:
x = []
y = []
user_list = movie_count['User2'].unique()
for i in range(len(user_list)):
total_user_movies = movie_count[movie_count['User2']==user_list[i]].copy()
total_user_movies.reset_index(inplace=True)
total_user_movies = total_user_movies.drop(['index'],axis=1)
for j in range(total_user_movies.shape[0]-6):
x.append(total_user_movies.loc[j:(j+4),'Movies2'].tolist())
y.append(total_user_movies.loc[(j+5),'Movies2'].tolist())
(5) 预处理 x 和 y 变量,以便可以将它们传递到模型,然后创建训练和测试数据集:
from keras.utils import to_categorical
l = list(moviesid2idx.keys())
print(len(l))
set([x for x in l if l.count(x) > 1])
y2 = to_categorical(y, num_classes = max(y)+1)
x_train = np.array(x[:40000])
x_test = np.array(x[40000:])
y_train = np.array(y2[:40000])
y_test = np.array(y2[40000:])
(6) 构建电影推荐模型:
model = Sequential()
model.add(Embedding(src_vocab, n_units, input_length=src_timesteps))
model.add((LSTM(100)))
model.add(Dense(1000,activation='relu'))
model.add(Dense(max(y)+1,activation='softmax'))
model.summary()
该模型的简要信息输出如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 5, 32) 46304
_________________________________________________________________
lstm (LSTM) (None, 100) 53200
_________________________________________________________________
dense (Dense) (None, 1024) 103424
_________________________________________________________________
dense_1 (Dense) (None, 1447) 1483175
=================================================================
Total params: 1,686,103
Trainable params: 1,686,103
Non-trainable params: 0
_________________________________________________________________
(7) 编译并拟合模型构建完成的模型:
from keras.optimizers import Adam
adam = Adam(lr=0.0001)
model.compile(optimizer=adam, loss='categorical_crossentropy', metrics = ['acc'])
history = model.fit(x_train, y_train,
epochs=20,
batch_size=64,
validation_data=(x_test, y_test),
verbose=1)
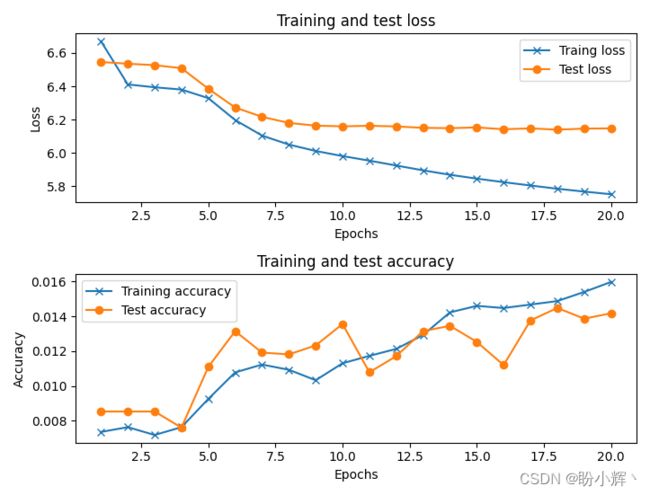
(8) 对测试数据进行预测:
pred = model.predict(x_test)
我们假设,如果用户将要观看的第 6 部影片在推荐概率最高的前 12 部影片中,则表示该推荐系统能够向用户推荐合适的影片,计算在所有测试用户中,推荐了合适影片的比例:
count = 0
for i in range(x_test.shape[0]):
rank = np.argmax(np.argsort(pred[i])[::-1]==np.argmax(y_test[i]))
if rank<12:
count+=1
print(count/x_test.shape[0])
# 0.1173
可以看到,我们所构建的电影推荐模型有 11.73% 的概率能够为用户推荐合适的影片。
2.2 考虑用户历史记录
进行推荐电影时我们需要考虑的另一个因素是用户观影的历史记录,如果用户已经看过一部电影,那么他们再次观看同一部电影的可能性就较小。接下来,我们考虑用户的观影历史记录,使用以上逻辑对推荐电影列表进行修正。
(1) 首先,我们存储用户在预测的电影之前观看的所有电影记录,而不仅仅是最近的 5 部影片:
historically_watched = []
for i in range(len(user_list)):
total_user_movies = movie_count[movie_count['User2']==user_list[i]].copy()
total_user_movies.reset_index(inplace=True)
total_user_movies = total_user_movies.drop(['index'],axis=1)
for j in range(total_user_movies.shape[0]-6):
historically_watched.append(total_user_movies.loc[0:(j+4),'Movies2'].tolist())
(2) 如果用户已经看过此电影,我们将把该用户-电影组合的概率改写为 0:
historically_watched = historically_watched[40000:]
for j in range(pred.shape[0]):
for i in range(pred.shape[1]):
pred[j][i]= np.where(i in historically_watched[j], 0 , pred[j][i])
(3) 接下来,我们同样计算在所有测试用户中,推荐系统能够向用户推荐合适影片的比例:
count = 0
for i in range(x_test.shape[0]):
rank = np.argmax(np.argsort(pred[i])[::-1]==np.argmax(y_test[i]))
if rank<12:
count+=1
print(count/x_test.shape[0])
#0.1557974735544829
结果表明,我们现在有 15.58% 的概率能够为用户推荐合适的影片,高于不考虑用户历史记录的 11.73% ,显著地提高了推荐系统模型的推荐准确率。
小结
推荐系统是利用客户和商品信息,根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品,对用户进行有关产品的精准推荐是增加销量的关键。在本节中,我们以电影推荐系统为例介绍了使用 LSTM 构建推荐系统模型的方法,并通过增加对用户观影记录的考虑,为用户推荐其真正感兴趣的电影。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(8)——使用数据增强提高神经网络性能
Keras深度学习实战(9)——卷积神经网络的局限性
Keras深度学习实战(10)——迁移学习详解
Keras深度学习实战(11)——可视化神经网络中间层输出
Keras深度学习实战(12)——面部特征点检测
Keras深度学习实战(13)——目标检测基础详解
Keras深度学习实战(14)——从零开始实现R-CNN目标检测
Keras深度学习实战(15)——从零开始实现YOLO目标检测
Keras深度学习实战(16)——自编码器详解
Keras深度学习实战(17)——使用U-Net架构进行图像分割
Keras深度学习实战(18)——语义分割详解
Keras深度学习实战(19)——使用对抗攻击生成可欺骗神经网络的图像
Keras深度学习实战(20)——DeepDream模型详解
Keras深度学习实战(21)——神经风格迁移详解
Keras深度学习实战(22)——生成对抗网络详解与实现
Keras深度学习实战(23)——DCGAN详解与实现
Keras深度学习实战(24)——从零开始构建单词向量
Keras深度学习实战(25)——使用skip-gram和CBOW模型构建单词向量
Keras深度学习实战(26)——文档向量详解
Keras深度学习实战(27)——循环神经详解与实现
Keras深度学习实战(28)——利用单词向量构建情感分析模型
Keras深度学习实战(29)——长短时记忆网络详解与实现
Keras深度学习实战(30)——使用文本生成模型进行文学创作