推荐系统之Deep Neural Networks for YouTube Recommendations论文精读和实战
目录
一、youtube深度神经网络模型介绍
二、youtube推荐系统之DNN实战
1.MovieLens数据集介绍
2 数据组织
3 模型构建
4模型训练和保存
5 模型预测
三、论文详细解读
一、youtube深度神经网络模型介绍
YouTube是如今工业界最大和最复杂的推荐系统之一,2016年9月,Youtube在RecSys会议上发表了Deep Neural Networks for YouTube Recommendations,该论文详细的介绍了Youtube基于深度学习的推荐方法。
首先,我们看一下系统的总体结构。
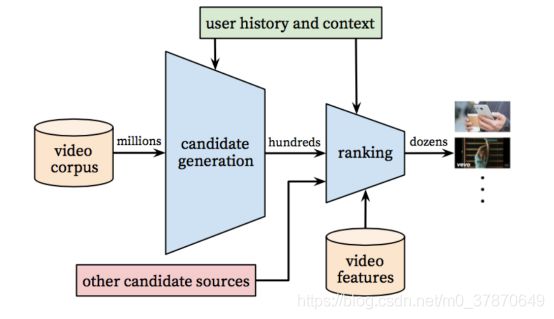
图1 YouTube推荐系统架构
该系统和工业界经典的推荐流程一样,系统分为候选集生成(也称为搜索或召回),排序两个阶段。召回阶段负责基于用户画像和场景,从海量视频百万级别)中召回相关度比较高的视频(几千左右)。排序阶段对召回的视频进行更精确的排序,然后根据排序结果给用户进行推荐。
召回阶段模型结构如下:
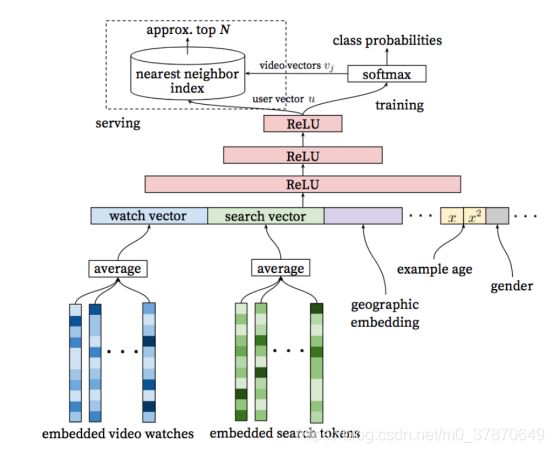
图2 YouTube召回框架
具体步骤如下:
训练阶段:
- 将用户观看过的视频进行Embedding,然后求平均,得到观看历史的向量表示。
- 将用户搜索过的关键字进行Embedding,然后求平均,得到用户搜索历史的向量表示。
- 将如上两个表示特征和用户的其他特征进行拼接,然后经过几层全连接层,得到用户的表示,然后经过softmax预测用户下一次点击的视频。
预测阶段:取用户的向量表示和视频的Embedding,求这两个向量的内积,表示这两个向量的相似度。对相似度进行排序后,将相似度高的放入召回池。
排序阶段模型结构如下,排序阶段模型和召回模型相似,具体请查看原论文。本文主要对该模型的召回阶段进行了实现,包括训练和预测两个阶段。
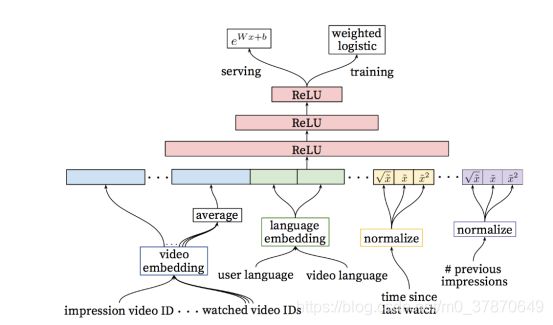
图3 YouTube排序架构
二、youtube推荐系统之DNN实战
1.MovieLens数据集介绍
MovieLens数据集是关于电影评分的数据集,很多模型会使用该数据集进行测试。官网有很多不同版本,下载地址为:https://grouplens.org/datasets/movielens/。本文采用ml-1m数据集,下面首先来看一下数据。
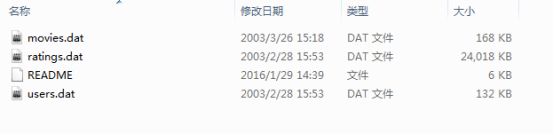
图4. ml-1m数据集文件
可以看到该数据集包含有4份文件,下面逐一介绍。
Movies.dat数据集,记录了电影对应id,电影的标题和电影的类型。
file_path="./ml-1m/movies.dat"
moviesdata = pd.read_table(
file_path,
header=None,
sep="::",
names=["movieID", "title", "genres"]
)
moviesdata.head(3)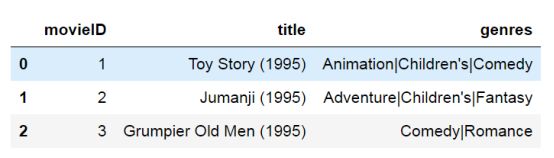
图5 Movies.dat数据
ratings.dat数据集包含用户id、电影id、用户对电影的评分以及评分对应的时间。如第一条记录表示id为1的用户在时间戳为978300760对id为1193的电影评分5分。
file_path="./ml-1m/ratings.dat"
rates = pd.read_table(
file_path,
header=None,
sep="::",
names=["userID", "movieID", "rate", "timestamp"],
)
rates.head(3)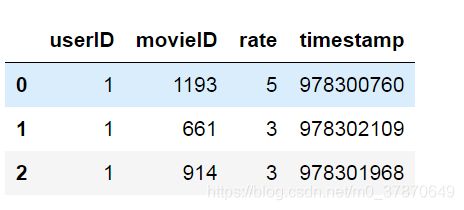
图6 ratings.dat数据
users.dat文件是用户信息,主要包括用户id、性别、年龄、职业和压缩编码。
file_path="./ml-1m/users.dat"
users = pd.read_table(
file_path,
header=None,
sep="::",
names=["userID", "gender", "age", "Occupation", "zip-code"],
)
users.head(3)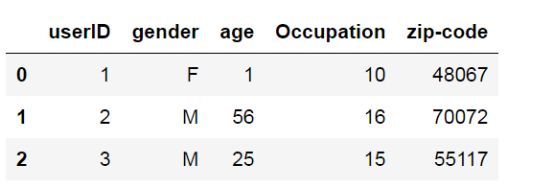
图7 users.dat数据
了解完毕数据之后,接下来我们开始选用模型进行推荐。经过分析数据,我们得出2点结论:1.在数据集中,有用户评分数据,因此我们可以构建用户评分矩阵,通过SVD分解,对用户评分矩阵进行补全,通过用户评分,对用户进行推荐。2.数据中有用户评分时间,一般用户的评分时间和基本是用户的观看时间,我们也可以尝试一下youtube推荐系统的推荐框架。3.有用户的观看历史,我们可以采用基于用户的协同过滤和基于用户的协同过滤对用户进行推荐。下面我们来详细介绍。
2 数据组织
通过分析召回模型,我们知道该模型的主要特征包括用户特征,以及用户的点击序列。训练阶段目标是下一个点击的视频。因此我们将电影按照点击时间(此处我们将评分时间看做是用户的点击时间)对用户看过的视频进行排序,然后用前8个视频预测用户下一个将要点击的视频。数据组织如下:
得到用户点击序列
def get_user_movie_seq(rates):
user_movie_dict = defaultdict(list)
# 取用户最后点击的8个SKU序列。
user_info_dict = defaultdict(list)
# 电影全部
for userid, item in rates.groupby(["userID"]):
movieID = item.sort_values(by="timestamp", ascending=True)["movieID"].tolist()
# print(userid,movieID)
user_movie_dict[userid] = movieID
#最后最用户召回的时候,用户最后点击的8个电影和特征进行运算得到用户表示
for userid, item in user_movie_dict.items():
user_info_dict[userid] = item[-8:]
return user_movie_dict,user_info_dict
#按照用户点击时间构造样本。
def get_sample(user_movie_dict,movie2index):
# 构造用户表示样本
useridlist = []
itemidlist = []
labelidlist = []
for userid, watchlist in user_movie_dict.items():
# 用8个点击序列预测下一个点击序列。
length = len(watchlist)
for i in range(length - 8):
useridlist.append(userid)
itemidlist.append([movie2index[watchlist[i]] for i in range(i, i + 8)])
labelidlist.append(movie2index[watchlist[i + 8]])
train = pd.DataFrame()
train["userid"] = useridlist
train["itemidlist"] = itemidlist
train["labelidlist"] = labelidlist
return train
3 模型构建
在模型搭建部分由两点需要注意,第一点是训练的时候,需要预测用户下一次点击的电影,因此,此时label的维度是电影字典的大小。直接这样计算很耗时,在此处,我们进行了负采样。对每一个正样本,随机采样16个负样本,一起组成label。第二点是在进行预测的时候,我们需要得到用户的表示向量,在此处,我们将用户向量直接作为另一个模型(记做model2)的输出,在model1训练完毕后,因为公用结构和参数,直接保存model2,预测的时候,model2可以直接输出用户向量。
def DNN(embed_feature_dims,movie_vocab_size,embedding_size=8,nb_negative = 16 ,seq_length=8,flag="train"):
emb_inputs = []
embs = []
for (col, in_dim, out_dim) in zip(embed_feature_dims[0], embed_feature_dims[1], embed_feature_dims[2]):
print(col, in_dim, '-embed->', out_dim)
tmp_in = Input(shape=(1,), name='emb_input_%s' % col)
emb_inputs.append(tmp_in)
e = Embedding(input_dim=in_dim + 1, output_dim=out_dim, input_length=1, name='emb_%s' % col)(
tmp_in) # 1,out_dim
e = Reshape((out_dim,), name='emb_reshape_%s' % col)(e) # out_dim
embs.append(e)
# multi-embedding层
mul_emb_inputs = []
tmp_in = Input(shape=(seq_length,), name='mul_emb_input_%s' % "movelist")
mul_emb_inputs.append(tmp_in)
e1 = Embedding(input_dim=movie_vocab_size + 1, output_dim=embedding_size, input_length=seq_length,name='movie_emb')(tmp_in)
e1 = Lambda(lambda x: K.mean(x, axis=1))(e1)
#将多值embedding和单值embedding连接起来。
m_emb = Concatenate(name='emb_merge')(embs+[e1])
# 3层全连接
net = BatchNormalization()(m_emb)
net = Dense(128, activation='softplus', name="hidden1")(net)
# net=Activation('softplus')(net)
net = BatchNormalization()(net)
net = Dense(64, activation='softplus', name="hidden2")(net)
net = BatchNormalization()(net)
net = Dense(8, activation='softplus', name="hidden3")(net)
net = BatchNormalization()(net)
user_embed = net
# 目标输入, 构造随机负样本,与目标组成抽样
target_word = Input(shape=(1,), dtype='int32', name="input_label")
negatives = Lambda(lambda x: K.random_uniform((K.shape(x)[0], nb_negative), 0, movie_vocab_size + 1, 'int32'))(
target_word)
# 构造抽样,负样本随机抽。负样本也可能抽到正样本,但概率小。
samples = Lambda(lambda x: K.concatenate(x))([target_word, negatives])
# 只在抽样内做Dense和softmax
softmax_weights = Embedding(movie_vocab_size + 1, embedding_size, name='W')(samples)
softmax_biases = Embedding(movie_vocab_size + 1, 1, name='b')(samples)
softmax = Lambda(lambda x: K.softmax((K.batch_dot(x[0], K.expand_dims(x[1], 2)) + x[2])[:, :, 0]))(
[softmax_weights, net, softmax_biases]) # 用Embedding层存参数,用K后端实现矩阵乘法,以此复现Dense层的功能。
# 编译模型。
# 注意,标签为1个正样本,16个随机采样的样本,loss应该选择为sparse_categorical_crossentropy。
model1 = Model(inputs=mul_emb_inputs + emb_inputs + [target_word], outputs=softmax)
model2 = Model(inputs=mul_emb_inputs + emb_inputs, outputs=user_embed)
model1.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model1.summary()
plot_model(model1, show_shapes=True, to_file='./modelyoutube.png')
return model1,model2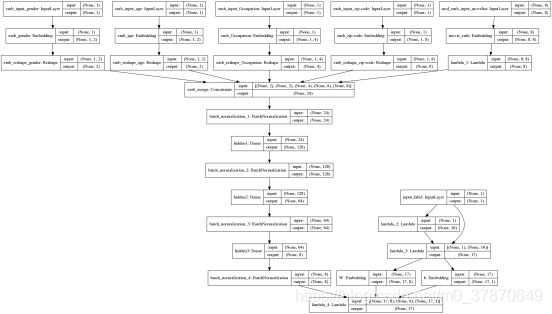
图8 YouTube推荐系统DNN模型结构图
4模型训练和保存
util.config_gpu('1')
with open('./dataset.pkl', 'rb') as f:
user_movie_dict, user_info_dict = pickle.load(f)
movie2index, index2movie, movie_vocab = pickle.load(f)
usernew = pickle.load(f)
feat_dict = pickle.load(f)
user_baseinfo = pickle.load(f)
trainsample = pickle.load(f)
f.close()
print("sample shape",trainsample.shape)
input1=np.array([np.array(e) for e in trainsample["itemidlist"].values])
input2=trainsample["gender"].values
input3=trainsample["age"].values
input4=trainsample["Occupation"].values
input5=trainsample["zip-code"].values
targets=np.array(trainsample["labelidlist"])
X = [input1, input2,input3,input4,input5,targets]
targets = np.zeros((len(input2), 1))
model1,model2=DNN(feat_dict,len(movie_vocab),seq_length=8)
model1.fit(x=X,y=targets,batch_size=1024, epochs=20)
#打印两个用户表示看看
result1=model2.predict([input1[:2], input2[:2],input3[:2],input4[:2],input5[:2]])
print(result1)
mp = "./model1.h5"
model1.save(mp)
mp = "./model2.h5"
model2.save(mp)
训练结果如下,可以看到经过20轮训练,loss损失值为1.02左右,准确率为0.64左右。用户表示输出为1*8维度的向量。
Epoch 15/20
951889/951889 [==============================] - 10s 11us/step - loss: 1.0347 - acc: 0.6415
Epoch 16/20
951889/951889 [==============================] - 10s 11us/step - loss: 1.0319 - acc: 0.6427
Epoch 17/20
951889/951889 [==============================] - 11s 11us/step - loss: 1.0293 - acc: 0.6428
Epoch 18/20
951889/951889 [==============================] - 10s 11us/step - loss: 1.0256 - acc: 0.6437
Epoch 19/20
951889/951889 [==============================] - 10s 11us/step - loss: 1.0231 - acc: 0.6453
Epoch 20/20
951889/951889 [==============================] - 10s 11us/step - loss: 1.0211 - acc: 0.6453
[[ 6.588081 3.6478798 8.383787 10.939469 8.94719 6.8341327
5.9463053 5.6574903]
[ 7.169719 3.4445734 8.34684 9.929104 8.895642 6.4406815
7.6894875 5.243701 ]]
鉴于采取的数据较少,因此训练准确率有些低,仅作参考和学习。
5 模型预测
模型训练完毕之后,我们就可以开始进行预测了。加载model1得到每一个电影的Embedding表示。加载model2预测得到用户的表示向量,然后求用户表示向量和电影表示向量的相似度即可。
from keras.models import load_model
print("Using loaded model to predict...")
model1 = load_model("./model1.h5")
model2 = load_model("./model2.h5")
#获取用户表示序列
def get_user_vectors(mode2,userid_list):
# gender age Occupation zip-code
user_info = [[movie2index[item] for item in user_info_dict[userindex]]for userindex in userid_list]
user_seqs = np.array([np.array(item) for item in user_info] )
gender1 = np.array([user_baseinfo[item][0] for item in userid_list ] )
age1 = np.array([user_baseinfo[item][1] for item in userid_list ])
Occupation1 = np.array([user_baseinfo[item][2] for item in userid_list ])
zip_code1 = np.array([user_baseinfo[item][3] for item in userid_list ])
#进行预测
uservectors = mode2.predict([user_seqs, gender1, age1, Occupation1, zip_code1])
return uservectors
#得到用户1和2的表示序列
uservectors=get_user_vectors(model2,[1,2])
#获取embedding数据,并计算用户表示序列和所有物品的相似度。
movie_emb = model1.get_layer('movie_emb').get_weights()[0]
sims=np.dot(uservectors,np.transpose(movie_emb))
#根据sims进行排序,然后取出相似度排在前面的电影进行用户召回池。三、论文详细解读
转载:https://blog.csdn.net/Zhangbei_/article/details/85647887
随着深度学习的火热,越来越多的问题都开始尝试采用深度学习算法来解决,包括推荐算法。16年的时候,谷歌公开了Youtube的推荐算法,Deep Neural Networks for YouTube Recommendation(https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf),采用了深度学习算法,在效果上超越了最常用的矩阵分解算法。这篇文章介绍了Youtube的推荐算法架构,还有视频场景的一些经验,以及算法上的技巧。虽然这篇文章距今已经过去两年多,但是其中的一些经验和技巧,仍然值得借鉴。本文接下来会分三部分进行介绍,首先是做一个总体的介绍,第二部分介绍召回算法,第三部分介绍排序算法。
一,概括
相对于一般的场景,Youtube的推荐存在三大困难,一是数据规模庞大,用户量大,视频也多,一些在小数据集上效果不错的算法在Youtube上效果一般;二是不断有大量新视频上传,需要解决视频的冷启动问题;三是数据有噪声,用户的行为非常稀疏且只有隐反馈,视频的描述信息混乱且不规范,因此需要算法对于噪声数据有较强的鲁棒性。第一点正好满足深度学习吃数据的特点,第二点文中提出了针对性的解决办法。
整个推荐架构分为两部分,召回和排序,如图1所示。第一个蓝色的漏斗就是召回算法,从百万级数量的视频物料库中筛选出几百个视频。除了这里采用的深度学习召回算法,还可以加入其他的召回视频源,如图中的红色方格,一起送给排序算法。因为计算量大,所以召回算法不可能也没必要采用所有特征,因此召回算法只采用了用户行为和场景特征。排序算法使用了更多的特征,给每个候选视频计算一个分数,并且按照分数从高到低排序,从几百个视频里边再筛选和排序出几十个视频推荐给用户。在对算法进行评估时同时采用了离线指标和在线AB test,并且以AB test作为主要的评估指标。
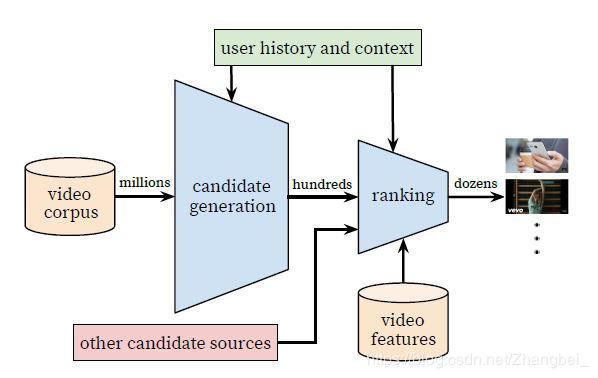
图1
二,召回算法
在讲召回算法之前,先岔开话题讲一下word2vec。在做NLP任务时,如何将文本或者文本中的一字一句,表示成结构化的,计算机能够理解的形式是第一步。经常采用方法的就是word2vec,就是将所有的word表示成低维稠密的向量embedding。有一种无监督训练方法叫CBOW(连续词袋模型),如图2所示。对词袋中每个词都初始化一个随机向量,对于每一个句子,设置一个固定长度窗口在句子上滑动,抠掉窗口中间的词w(t),通过句子中前面和后面的词来预测或者分类w(t),网络输出端是一个所有词的分类器,通过训练得到每个词的embedding,这样得到的词向量就携带了词的语义信息。
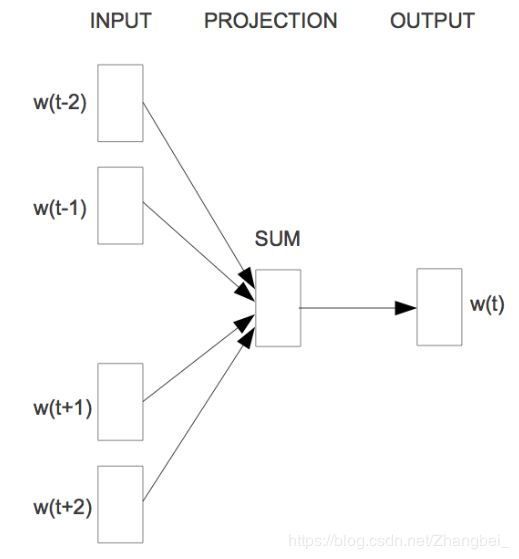
图2
Youtube的召回算法也采用了类似的思路。将预测问题转化为一个softmax分类问题,通过用户的浏览记录和场景信息,判断下一个要看的是视频库中哪一个视频,通过训练使每个视频都得到了一个向量表示。具体的召回算法架构如图3所示。输入特征包括用户的历史观看记录,历史搜索记录,人口学特征等,将这些特征连接起来作为输入。历史观看记录是一个视频序列,其中每个视频都用一个向量v表示,将视频序列的向量求平均作为历史观看记录的输入。网络的最后一层输出作为一个用户表示向量u,用来表示用户的偏好和场景信息。将u和所有的候选视频向量v做点积,输入给softmax做分类,如图4中公式所示。向量u和v的维度都是256。
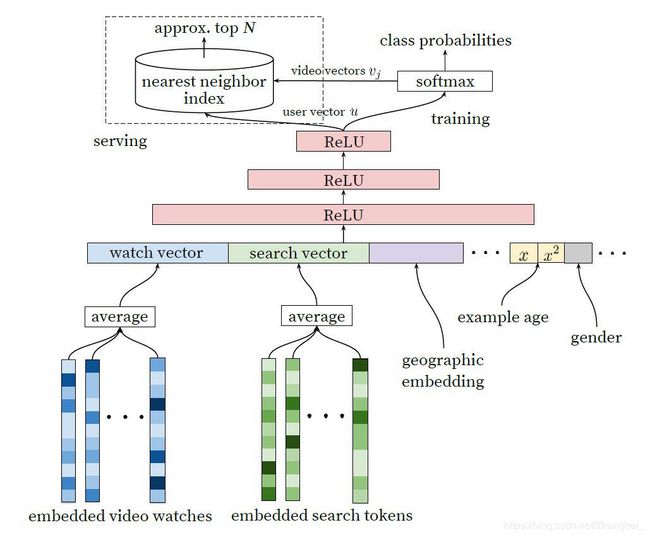
图3
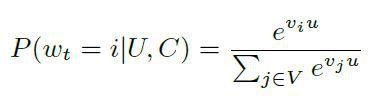
图4
我们来介绍下模型的输入特征。首先是观看列表,包含最近的50条观看视频。然后是搜索记录,同样也是50条最近的搜索记录,采用和历史观看记录同样的处理方法。将用户的搜索记录处理为unigram(就是一个word)或者bigram(两个相邻的word)的元素,构成词袋。对词袋也采用embedding向量表示,对序列的embedding求平均表示搜索记录的输入。还加入了人口学特征,包括用户的地理位置和设备型号,都采用embedding的方式表示;性别和登录状态用0和1二值表示;对于连续特征,年龄归一化到[0,1];这些特征有利于对新用户的冷启动。
除了上面这些特征,还有一个特征——example age,应该是表示视频上传时间。youtube每秒会上传大量新视频,而且用户通常更喜欢新视频,但是推荐算法往往会推荐老视频,因为算法的输入都是些历史记录。加入这个特征,能够让模型知道视频的上传时间,从而能够模拟视频发布之后的时间热度。其实这个特征我也有一些困惑的地方,还没有完全搞清楚。
召回算法已经描述完了,看起来很简单,但是其中有大量的经验和技巧,下面一条一条进行介绍。
1)正样本的选择。虽然youtube中有显示反馈,比如点赞,调查问卷之类的,但是显示反馈的数据量太少。因此在训练数据中只采用隐式反馈,完整地看完一个视频作为一个正样本。
2)负样本的选择。召回算法需要从百万级的视频库中进行筛选,如果每次都做一个百万类别的分类,计算量非常庞大,因此每次只采样几千个负样本,并通过设置权重来进行修正。这样每次分类的类别数就只有几千。
3)训练样本不仅来自于youtube,站外的观看记录也会加入训练。
4)对于每个用户都生成同样数量的训练样本,避免一些观看记录过多的用户对模型产生更大的影响。
5)如果用户刚刚根据某个关键词搜索完视频,接着就去推送相关的视频,用户可能并不感兴趣,因此需要打乱搜索记录序列。
6)一些协同过滤算法在训练时预测某一次行为,既用到了之前的行为,也用到了之后的行为,如图5(a)所示,空心圆点表示待预测视频,实心圆点表示这条记录之前和之后的观看记录和搜索记录,就像图2中word2vec的训练一样。但是对于短视频或者新闻来说,用户的兴趣可能会发生变化,比如刚开始看的时候,可能会广泛涉猎,随后会慢慢聚焦到某一些主题上去。图5(a)的训练方法泄露了用户未来的信息。通过试验证明,只利用待预测行为之前的历史记录做训练效果更好,如图5(b)所示。
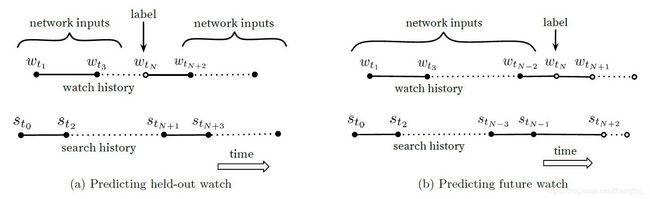
图5
上面描述的是召回算法的训练,为了满足时延要求,在进行实际的召回计算时采用的是另外一种做法,如图3中左上角虚线框所示,对于每个用户向量u,对视频库中的所有视频根据向量v做最近邻算法,得到top-N的视频作为召回结果。
三,排序算法
在图1中可以看到,除了上一章节描述的召回算法,还有其他召回来源,不同的来源无法直接比较,排序算法可以对所有召回视频单独计算分数,并且按照分数高低排序推荐给用户。对于每个用户,排序阶段只需要计算几百个视频,相对于召回算法,视频数量大幅减少,因此除了之前召回算法用到的特征,可以采用更多的特征,做更精细化的处理。排序算法仍然采用DNN架构,如图6所示。

图6
最左边的特征是待曝光的视频,右边是其他的输入特征,排序算法采用了几百个特征。作者发现最有用的特征还是用户的历史行为,比如,待预测的视频来自于哪个主题,用户在这个主题上看了多少视频,用户上一次看这个主题是什么时候。召回算法的输出也可以作为特征,比如,视频来自哪个召回源,召回算法计算的分数是多少。
所有特征分为类别特征和连续特征。类别特征都采用embedding向量表示。对视频生成一个词袋vocabulary,按照点击率对视频从高到底排序,取top-N的视频进入词袋,避免过于庞大的视频规模。对于搜索记录采用同样的处理方法。另外,不在词袋中的值都用0向量表示。在设计embedding维度时,维度大小与词袋中元素数量的对数成比例。
对于连续特征,需要进行规范化normalization。根据连续特征的分布,采用直方图均衡化的方式,将特征值映射到[0,1],使得映射值在[0,1]均匀分布。直方图均衡化在图像上早有应用,映射之后让像素点的值均匀分布在[0,255]之间,我之前有篇博客介绍过直方图均衡化算法,可以参看一下(https://blog.csdn.net/Zhangbei_/article/details/47680411)。对于规范化后的特征x,同时加上x的二次项和开方项作为输入,如图6所示,以增强特征和算法模型的表达能力。
最后再介绍一下算法的目标函数。如果以点击率作为目标,可能会存在标题党,或者用户被封面图吸引,但是点开之后用户并不感兴趣。而观看时长能够真实地捕获用户的兴趣,因此youtube的预测期目标是观看时长。具体如何操作?训练集中包含正样本和负样本,正样本是用户点击并且观看的视频,负样本是曝光之后没有点击的视频。训练时采用交叉熵loss,并且对正负样本的loss设置不同的权重,负样本设置单位权重,正样本用观看时长作为权重,如图6中输出端training支线的weighted logistic。在预测时,用指数函数作为激活函数计算期望观看时长,如图6中的serving支线。
到此就介绍完了,如有疑问欢迎探讨,如果文中有纰漏也欢迎指教。