图片识别 python 神经网络,神经网络提取图片特征
Python如何图像识别?
Python图片文本识别使用的工具是PIL和pytesser。
因为他们使用到很多的python库文件,为了避免一个个工具的安装,建议使用pythonxypytesser是OCR开源项目的一个模块,在Python中导入这个模块即可将图片中的文字转换成文本。
pytesser调用了tesseract。当在Python中调用pytesser模块时,pytesser又用tesseract识别图片中的文字。
pytesser的使用步骤如下:首先,安装Python2.7版本,这个版本比较稳定,建议使用这个版本。其次,安装pythoncv。然后,安装PIL工具,pytesser的使用需要PIL库的支持。
接着下载pytesser最后,将pytesser解压,这个是免安装的,可以将解压后的文件cut到Python安装目录的Lib\site-packages下直接使用,比如我的安装目录是:C:\Python27\Lib\site-packages,同时把这个目录添加到环境变量之中。
完成以上步骤之后,就可以编写图片文本识别的Python脚本了。
参考脚本如下:frompytesserimport*importImageEnhanceimage=('D:\\workspace\\python\\5.png')#使用ImageEnhance可以增强图片的识别率enhancer=ImageEnhance.Contrast(image)image_enhancer=enhancer.enhance(4)printimage_to_string(image_enhancer)tesseract是谷歌的一个对图片进行识别的开源框架,免费使用,现在已经支持中文,而且识别率非常高,这里简要来个helloworld级别的认识下载之后进行安装,不再演示。
在tesseract目录下,有个文件,主要调用这个执行文件,用cmd运行到这个目录下,在这个目录下同时放置一张需要识别的图片,这里是然后运行:tesseractresult会把自动识别并转换为txt文件到但是此时中文识别不好然后找到tessdata目录,把eng.traineddata替换为chi_sim.traineddata,并且把chi_sim.traineddata重命名为eng.traineddataok,现在中文识别基本达到90%以上了。
如何用Python和深度神经网络寻找相似图像
爱发猫 www.aifamao.com。
代码首先,读入TuriCreate软件包importturicreateastc我们指定图像所在的文件夹image,让TuriCreate读取所有的图像文件,并且存储到data数据框data=tc.image_analysis.load_images('./image/')我们来看看,data数据框的内容:datadata包含两列信息,第一列是图片的地址,第二列是图片的长宽描述。
下面我们要求TuriCreate给数据框中每一行添加一个行号。这将作为图片的标记,方便后面查找图片时使用,并输出查看data。
data=data.add_row_number()data下面,是重头戏。我们让TuriCreate根据输入的图片集合,建立图像相似度判别模型。
model=tc.image_similarity.create(data)这个语句执行起来,可能需要一些时间。如果你是第一次使用TuriCreate,它可能还需要从网上下载一些数据。请耐心等待。
经过或长或短的等待,模型已经成功建立。下面,我们来尝试给模型一张图片,让TuriCreate帮我们从目前的图片集合里,挑出最为相似的10张来。为了方便,我们就选择第一张图片作为查询输入。
我们利用show()函数展示一下这张图片。tc.Image(data[0]['path']).show()下面我们来查询,我们让模型寻找出与这张图片最相似的10张。
similar_images=model.query(data[0:1],k=10)我们把结果存储在了similar_images变量里面,下面我们来看看其中都有哪些图片。
similar_images返回的结果一共有10行。跟我们的要求一致。每一行数据,包含4列。
分别是:查询图片的标记获得结果的标记结果图片与查询图片的距离结果图片与查询图片近似程度排序值有了这些信息,我们就可以查看到底哪些图片与输入查询图片最为相似了。
注意其中的第一张结果图片,其实就是我们的输入图片本身。考虑它没有意义。我们提取全部结果图片的标记(索引)值,忽略掉第一张(自身)。
similar_image_index=similar_images['reference_label'][1:]把上面9张图片的标记在所有图片的索引列表中过滤出来:filtered_index=data['id'].apply(lambdax:xinsimilar_image_index)filtered_index验证完毕以后,请执行以下语句。
我们再次调用TuriCreate的explore()函数,展现相似度查询结果图片。data[filtered_index].explore()。
如何用python 自己写一个ocr
您好,自己实现OCR的话您需要学习模式识别/机器学习相关知识以及计算机视觉的部分知识。
首先需要定位文本区域,阈值化,切割为单字符,最难的部分是字符的识别,如果识别的文本是规范的,可以考虑用匹配滤波器(不推荐,但简单),或向量空间搜索,正规的方式还是推荐使用机器学习中神经网络的卷积神经网络(CNN)来训练和识别。
为训练CNN您可能还需要一些数据挖掘与图像处理方面的知识,以方便您获取数据集(即字符图片集)来训练CNN,这通常需要大量的数据与较长的训练时间(时间与字符图片大小、字符图片集数量、神经网络结构与规模等相关)
python能做什么有趣的东西
python能做什么有趣的东西?
下面给大家介绍35个Python实例:1.Python3实现图片识别2.Python3图片隐写术3.200行Python代码实现20484.Python实现3D建模工具5.使用Python定制词云相关推荐:《Python教程》6.Python3智能裁切图片7.微信变为聊天机器人8.使用Python解数学方程9.使用Python创建照片马赛克10.Python基于共现提取《釜山行》人物关系11.Python气象数据分析:《Python数据分析实战》12.NBA常规赛结果预测:利用Python进行比赛数据分析13.Python的循环语句和隐含波动率的计算14.K-近邻算法实现手写数字识别系统15.数独游戏的Python实现与破解16.基于Flask与MySQL实现番剧推荐系17.Python实现英文新闻摘要自动提取18.Python解决哲学家就餐问题19.Ebay在线拍卖数据分析20.神经网络实现人脸识别任务21.使用Python解数学方程22.Python3实现火车票查询工具23.Python实现端口扫描器24.Python3实现可控制肉鸡的反向Shell25.Python实现FTP弱口令扫描器26.基于PyQt5实现地图中定位相片拍摄位置27.Python实现网站模拟登陆28.Python实现简易局域网视频聊天工具29.基于TCP的python聊天程序30.Python3基于Scapy实现DDos31.高德API+Python解决租房问题32.基于Flask与RethinkDB实现TODOList33.Python3实现简单的Web服务器34.Python实现Redis异步客户端35.仿StackOverflow开发在线问答系统。
python验证码识别
orc文字识别,现在比较流行的是通过人工智能训练CNN神经网络来识别。大体流程准备训练数据。训练数据可以自己写个程序生成验证码,和标准答案。构建CNN模型。
这个比较简单,使用keras框架,5分钟的事情。训练。不停地把数据feed给程序,直到准确率达到你的期望,推荐使用GPU加速预测。加载模型,把验证码图片feed给模型,得出结果希望对你有帮助。
如何进行 图像的分类 python
如何利用Python做简单的验证码识别
1 摘要验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越来越严峻。
本文介绍了一套字符验证码识别的完整流程,对于验证码安全和OCR识别技术都有一定的借鉴意义。
然后经过了一年的时间,笔者又研究和get到了一种更强大的基于CNN卷积神经网络的直接端到端的验证识别技术(文章不是我的,然后我把源码整理了下,介绍和源码在这里面):基于python语言的tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)2 关键词关键词:安全,字符图片,验证码识别,OCR,Python,SVM,PIL3 免责声明本文研究所用素材来自于某旧Web框架的网站 完全对外公开 的公共图片资源。
本文只做了该网站对外公开的公共图片资源进行了爬取, 并未越权 做任何多余操作。本文在书写相关报告的时候已经 隐去 漏洞网站的身份信息。本文作者 已经通知 网站相关人员此系统漏洞,并积极向新系统转移。
本报告的主要目的也仅是用于 OCR交流学习 和引起大家对 验证安全的警觉 。
4 引言关于验证码的非技术部分的介绍,可以参考以前写的一篇科普类的文章:互联网安全防火墙(1)--网络验证码的科普里面对验证码的种类,使用场景,作用,主要的识别技术等等进行了讲解,然而并没有涉及到任何技术内容。
本章内容则作为它的 技术补充 来给出相应的识别的解决方案,让读者对验证码的功能及安全性问题有更深刻的认识。
5 基本工具要达到本文的目的,只需要简单的编程知识即可,因为现在的机器学习领域的蓬勃发展,已经有很多封装好的开源解决方案来进行机器学习。
普通程序员已经不需要了解复杂的数学原理,即可以实现对这些工具的应用了。
主要开发环境:python3.5pythonSDK版本PIL图片处理库libsvm开源的svm机器学习库关于环境的安装,不是本文的重点,故略去。
6 基本流程一般情况下,对于字符型验证码的识别流程如下:准备原始图片素材图片预处理图片字符切割图片尺寸归一化图片字符标记字符图片特征提取生成特征和标记对应的训练数据集训练特征标记数据生成识别模型使用识别模型预测新的未知图片集达到根据“图片”就能返回识别正确的字符集的目标7 素材准备7.1 素材选择由于本文是以初级的学习研究目的为主,要求 “有代表性,但又不会太难” ,所以就直接在网上找个比较有代表性的简单的字符型验证码(感觉像在找漏洞一样)。
最后在一个比较旧的网站(估计是几十年前的网站框架)找到了这个验证码图片。原始图:放大清晰图:此图片能满足要求,仔细观察其具有如下特点。
有利识别的特点 :由纯阿拉伯数字组成字数为4位字符排列有规律字体是用的统一字体以上就是本文所说的此验证码简单的重要原因,后续代码实现中会用到不利识别的特点 :图片背景有干扰噪点这虽然是不利特点,但是这个干扰门槛太低,只需要简单的方法就可以除去7.2 素材获取由于在做训练的时候,需要大量的素材,所以不可能用手工的方式一张张在浏览器中保存,故建议写个自动化下载的程序。
主要步骤如下:通过浏览器的抓包功能获取随机图片验证码生成接口批量请求接口以获取图片将图片保存到本地磁盘目录中这些都是一些IT基本技能,本文就不再详细展开了。
关于网络请求和文件保存的代码,如下:defdownloads_pic(**kwargs): pic_name=('pic_name',None) url='httand_code_captcha/' res=(url,stream=True) withopen(pic_path+pic_name+'.bmp','wb')asf: forchunkinres.iter_content(chunk_size=1024): ifchunk: #filteroutkeep-alivenewchunks f.write(chunk) f.flush() f.close()循环执行N次,即可保存N张验证素材了。
下面是收集的几十张素材库保存到本地文件的效果图:8 图片预处理虽然目前的机器学习算法已经相当先进了,但是为了减少后面训练时的复杂度,同时增加识别率,很有必要对图片进行预处理,使其对机器识别更友好。
针对以上原始素材的处理步骤如下:读取原始图片素材将彩色图片二值化为黑白图片去除背景噪点8.1 二值化图片主要步骤如下:将RGB彩图转为灰度图将灰度图按照设定阈值转化为二值图image=(img_path)imgry=image.convert('L') #转化为灰度图table=get_bin_table()out=imgry.point(table,'1')上面引用到的二值函数的定义如下:呵呵11121314 def get_bin_table(threshold=140): """ 获取灰度转二值的映射table :paramthreshold: :return: """ table = [] for i in range(256): if i
二值化后带噪点的 6937 的像素点输出后如下图:1111000111111000111111100001111100000011111011101111011101111101111011110011011110011100111101111010110110101011011101111101111111110110101111110101111111101111110100011111011100111111001111111110111111001110111110000011111110010111110111111101110001111111101011010110111111011111110111101111111110111101111011111101111111011110111101110011110111101111110111001110000111111000011101100001110111011111如果你是近视眼,然后离屏幕远一点,可以隐约看到 6937 的骨架了。
8.2 去除噪点在转化为二值图片后,就需要清除噪点。本文选择的素材比较简单,大部分噪点也是最简单的那种 孤立点,所以可以通过检测这些孤立点就能移除大量的噪点。
关于如何去除更复杂的噪点甚至干扰线和色块,有比较成熟的算法: 洪水填充法FloodFill ,后面有兴趣的时间可以继续研究一下。
本文为了问题简单化,干脆就用一种简单的自己想的 简单办法 来解决掉这个问题:对某个 黑点 周边的九宫格里面的黑色点计数如果黑色点少于2个则证明此点为孤立点,然后得到所有的孤立点对所有孤立点一次批量移除。
下面将详细介绍关于具体的算法原理。
将所有的像素点如下图分成三大类顶点A非顶点的边界点B内部点C种类点示意图如下:其中:A类点计算周边相邻的3个点(如上图红框所示)B类点计算周边相邻的5个点(如上图红框所示)C类点计算周边相邻的8个点(如上图红框所示)当然,由于基准点在计算区域的方向不同,A类点和B类点还会有细分:A类点继续细分为:左上,左下,右上,右下B类点继续细分为:上,下,左,右C类点不用细分然后这些细分点将成为后续坐标获取的准则。
主要算法的python实现如下:defsum_9_region(img,x,y): """ 9邻域框,以当前点为中心的田字框,黑点个数 :paramx: :paramy: :return: """ #todo判断图片的长宽度下限 cur_pixel=img.getpixel((x,y)) #当前像素点的值 width=img.width height=img.height ifcur_pixel==1: #如果当前点为白色区域,则不统计邻域值 return0 ify==0: #第一行 ifx==0: #左上顶点,4邻域 #中心点旁边3个点 sum=cur_pixel\ +img.getpixel((x,y+1))\ +img.getpixel((x+1,y))\ +img.getpixel((x+1,y+1)) return4-sum elifx==width-1: #右上顶点 sum=cur_pixel\ +img.getpixel((x,y+1))\ +img.getpixel((x-1,y))\ +img.getpixel((x-1,y+1)) return4-sum else: #最上非顶点,6邻域 sum=img.getpixel((x-1,y))\ +img.getpixel((x-1,y+1))\ +cur_pixel\ +img.getpixel((x,y+1))\ +img.getpixel((x+1,y))\ +img.getpixel((x+1,y+1)) return6-sum elify==height-1: #最下面一行 ifx==0: #左下顶点 #中心点旁边3个点 sum=cur_pixel\ +img.getpixel((x+1,y))\ +img.getpixel((x+1,y-1))\ +img.getpixel((x,y-1)) return4-sum elifx==width-1: #右下顶点 sum=cur_pixel\ +img.getpixel((x,y-1))\ +img.getpixel((x-1,y))\ +img.getpixel((x-1,y-1)) return4-sum else: #最下非顶点,6邻域 sum=cur_pixel\ +img.getpixel((x-1,y))\ +img.getpixel((x+1,y))\ +img.getpixel((x,y-1))\ +img.getpixel((x-1,y-1))\ +img.getpixel((x+1,y-1)) return6-sum else: #y不在边界 ifx==0: #左边非顶点 sum=img.getpixel((x,y-1))\ +cur_pixel\ +img.getpixel((x,y+1))\ +img.getpixel((x+1,y-1))\ +img.getpixel((x+1,y))\ +img.getpixel((x+1,y+1)) return6-sum elifx==width-1: #右边非顶点 #print('%s,%s'%(x,y)) sum=img.getpixel((x,y-1))\ +cur_pixel\ +img.getpixel((x,y+1))\ +img.getpixel((x-1,y-1))\ +img.getpixel((x-1,y))\ +img.getpixel((x-1,y+1)) return6-sum else: #具备9领域条件的 sum=img.getpixel((x-1,y-1))\ +img.getpixel((x-1,y))\ +img.getpixel((x-1,y+1))\ +img.getpixel((x,y-1))\ +cur_pixel\ +img.getpixel((x,y+1))\ +img.getpixel((x+1,y-1))\ +img.getpixel((x+1,y))\ +img.getpixel((x+1,y+1)) return9-sumTips:这个地方是相当考验人的细心和耐心程度了,这个地方的工作量还是蛮大的,花了半个晚上的时间才完成的。
计算好每个像素点的周边像素黑点(注意:PIL转化的图片黑点的值为0)个数后,只需要筛选出个数为 1或者2 的点的坐标即为 孤立点 。这个判断方法可能不太准确,但是基本上能够满足本文的需求了。
经过预处理后的图片如下所示:对比文章开头的原始图片,那些 孤立点 都被移除掉,相对比较 干净 的验证码图片已经生成。
9 图片字符切割由于字符型 验证码图片 本质就可以看着是由一系列的 单个字符图片 拼接而成,为了简化研究对象,我们也可以将这些图片分解到 原子级 ,即: 只包含单个字符的图片。
于是,我们的研究对象由 “N种字串的组合对象” 变成 “10种阿拉伯数字” 的处理,极大的简化和减少了处理对象。9.1 分割算法现实生活中的字符验证码的产生千奇百怪,有各种扭曲和变形。
关于字符分割的算法,也没有很通用的方式。这个算法也是需要开发人员仔细研究所要识别的字符图片的特点来制定的。当然,本文所选的研究对象尽量简化了这个步骤的难度,下文将慢慢进行介绍。
使用图像编辑软件(PhoneShop或者其它)打开验证码图片,放大到像素级别,观察其它一些参数特点:可以得到如下参数:整个图片尺寸是40*10单个字符尺寸是6*10左右字符和左右边缘相距2个像素字符上下紧挨边缘(即相距0个像素)这样就可以很容易就定位到每个字符在整个图片中占据的像素区域,然后就可以进行分割了,具体代码如下:defget_crop_imgs(img): """ 按照图片的特点,进行切割,这个要根据具体的验证码来进行工作.#见原理图 :paramimg: :return: """ child_img_list=[] foriinrange(4): x=2+i*(6+4) #见原理图 y=0 child_img=((x,y,x+6,y+10)) child_img_list.append(child_img) returnchild_img_list然后就能得到被切割的 原子级 的图片元素了:9.2 内容小结基于本部分的内容的讨论,相信大家已经了解到了,如果验证码的干扰(扭曲,噪点,干扰色块,干扰线……)做得不够强的话,可以得到如下两个结论:4位字符和40000位字符的验证码区别不大纯字母不区分大小写。
分类数为26区分大小写。分类数为52纯数字。分类数为10数字和区分大小写的字母组合。
分类数为62纯数字 和 数字及字母组合 的验证码区别不大在没有形成 指数级或者几何级 的难度增加,而只是 线性有限级 增加计算量时,意义不太大。
10 尺寸归一本文所选择的研究对象本身尺寸就是统一状态:6*10的规格,所以此部分不需要额外处理。但是一些进行了扭曲和缩放的验证码,则此部分也会是一个图像处理的难点。
11 模型训练步骤在前面的环节,已经完成了对单个图片的处理和分割了。后面就开始进行 识别模型 的训练了。
整个训练过程如下:大量完成预处理并切割到原子级的图片素材准备对素材图片进行人为分类,即:打标签定义单张图片的识别特征使用SVM训练模型对打了标签的特征文件进行训练,得到模型文件12 素材准备本文在训练阶段重新下载了同一模式的4数字的验证图片总计:3000张。
然后对这3000张图片进行处理和切割,得到12000张原子级图片。
在这12000张图片中删除一些会影响训练和识别的强干扰的干扰素材,切割后的效果图如下:13 素材标记由于本文使用的这种识别方法中,机器在最开始是不具备任何数字的观念的。
所以需要人为的对素材进行标识,告诉 机器什么样的图片的内容是1……。这个过程叫做 “标记”。
具体打标签的方法是:为0~9每个数字建立一个目录,目录名称为相应数字(相当于标签)人为判定 图片内容,并将图片拖到指定数字目录中每个目录中存放100张左右的素材一般情况下,标记的素材越多,那么训练出的模型的分辨能力和预测能力越强。
例如本文中,标记素材为十多张的时候,对新的测试图片识别率基本为零,但是到达100张时,则可以达到近乎100%的识别率14 特征选择对于切割后的单个字符图片,像素级放大图如下:从宏观上看,不同的数字图片的本质就是将黑色按照一定规则填充在相应的像素点上,所以这些特征都是最后围绕像素点进行。
字符图片 宽6个像素,高10个像素 ,理论上可以最简单粗暴地可以定义出60个特征:60个像素点上面的像素值。但是显然这样高维度必然会造成过大的计算量,可以适当的降维。
通过查阅相应的文献 [2],给出另外一种简单粗暴的特征定义:每行上黑色像素的个数,可以得到10个特征每列上黑色像素的个数,可以得到6个特征最后得到16维的一组特征,实现代码如下:defget_feature(img): """ 获取指定图片的特征值, 1.按照每排的像素点,高度为10,则有10个维度,然后为6列,总共16个维度 :paramimg_path: :return:一个维度为10(高度)的列表 """ width,height= pixel_cnt_list=[] height=10 foryinrange(height): pix_cnt_x=0 forxinrange(width): ifimg.getpixel((x,y))==0: #黑色点 pix_cnt_x+=1 pixel_cnt_list.append(pix_cnt_x) forxinrange(width): pix_cnt_y=0 foryinrange(height): ifimg.getpixel((x,y))==0: #黑色点 pix_cnt_y+=1 pixel_cnt_list.append(pix_cnt_y) returnpixel_cnt_list然后就将图片素材特征化,按照 libSVM 指定的格式生成一组带特征值和标记值的向量文。
如何用神经网络 识别图片中的个数?
您的问题可以作为目标检测问题。目标检测目前有很多开源的模型可以使用,如有有自己的数据集需要用自己的数据集再训练一下,叫做迁移学习。
使用模型就需要用到深度学习框架,推荐您可以使用以下飞桨,百度出品的深度学习框架。飞桨PPDB。
如何通过人工神经网络实现图像识别
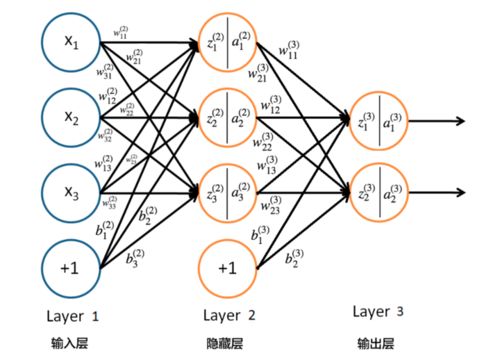
神经网络实现图像识别的过程很复杂。但是大概过程很容易理解。我也是节选一篇图像识别技术的文章,大概说一下。图像识别技术主要是通过卷积神经网络来实现的。
这种神经网络的优势在于,它利用了“同一图像中相邻像素的强关联性和强相似度”这一原理。具体而言就是,在一张图像中的两个相邻像素,比图像中两个分开的像素更具有关联性。
但是,在一个常规的神经网络中,每个像素都被连接到了单独的神经元。这样一来,计算负担自然加重了。卷积神经网络通过削减许多不必要的连接来解决图像识别技术中的这一问题。
运用图像识别技术中的术语来说就是,卷积神经网络按照关联程度筛选不必要的连接,进而使图像识别过程在计算上更具有可操作性。
卷积神经网络有意地限制了图像识别时候的连接,让一个神经元只接受来自之前图层的小分段的输入(假设是3×3或5×5像素),避免了过重的计算负担。因此,每一个神经元只需要负责处理图像的一小部分。
大大加快了速度和准确率。
卷积神经网络在实施的过程中,实际上是分为两层,一个是卷积层,一个是汇聚层,简单理解就是卷积层将图片分散成一个一个或者3*3/5*5的小像素块,然后把这些输出值排列在图组中,用数字表示照片中各个区域的内容,数轴分别代表高度、宽度和颜色。
那么,我们就得到了每一个图块的三维数值表达。汇聚层是将这个三维(或是四维)图组的空间维度与采样函数结合起来,输出一个仅包含了图像中相对重要的部分的联合数组。
这一联合数组不仅能使卷积神经网络计算负担最小化,还能有效避免过度拟合的问题。以上大概就是使用卷积神经网络进行图像识别的过程。
具体可以关注ATYUN人工智能平台的文章:揭秘图像识别技术,机器如何利用卷积神经网络“看见”这个世界。
学习Python应该掌握哪些知识点
阶段一:Python开发基础Python全栈开发与人工智能之Python开发基础知识学习内容包括:Python基础语法、数据类型、字符编码、文件操作、函数、装饰器、迭代器、内置方法、常用模块等。
阶段二:Python高级编程和数据库开发Python全栈开发与人工智能之Python高级编程和数据库开发知识学习内容包括:面向对象开发、Socket网络编程、线程、进程、队列、IO多路模型、Mysql数据库开发等。
阶段三:前端开发Python全栈开发与人工智能之前端开发知识学习内容包括:Html、CSS、JavaScript开发、Jquery&bootstrap开发、前端框架VUE开发等。
阶段四:WEB框架开发Python全栈开发与人工智能之WEB框架开发学习内容包括:Django框架基础、Django框架进阶、BBS+Blog实战项目开发、缓存和队列中间件、Flask框架学习、Tornado框架学习、RestfulAPI等。
阶段五:爬虫开发Python全栈开发与人工智能之爬虫开发学习内容包括:爬虫开发实战。
阶段六:全栈项目实战Python全栈开发与人工智能之全栈项目实战学习内容包括:企业应用工具学习、CRM客户关系管理系统开发、路飞学城在线教育平台开发等。
阶段七:算法&设计模式阶段八:数据分析Python全栈开发与人工智能之数据分析学习内容包括:金融量化分析。
阶段九:机器学习、图像识别、NLP自然语言处理Python全栈开发与人工智能之人工智能学习内容包括:机器学习、图形识别、人工智能玩具开发等。
阶段十:Linux系统&百万级并发架构解决方案阶段十一:高并发语言GO开发Python全栈开发与人工智能之高并发语言GO开发学习内容包括:GO语言基础、数据类型与文件IO操作、函数和面向对象、并发编程等。