Transformer - 李宏毅笔记
Transformer
- 1.Sequence-to-sequence简介
- 2.transformer结构
-
- 2.1 transformer的Encoder
-
- 2.1.1 Encode结构
- 2.1.2 Encoder具体结构分解
- 2.2 transformer的Decoder
-
- 2.2.1 Decode结构
- 2.2.2 Mask
- 2.2.3 Cross attention
- 3.self-attention(pytorch实现)
1.Sequence-to-sequence简介
前一章提到过,模型在处理文本或者语音的数据时,是输入一个序列,输出一个class或者一个序列
Seq2seq表示的不是一个模型的名称而是一种模型的类型的统称(即输入序列输出也是序列),在有了self-attention后,通过self-attention的变体模型结构transformer,可以很好的应用到Seq2seq的各种模型应用中
在输入一个序列输出一个序列的模型应用,有如下几种:
语音识别,机器翻译,语音翻译
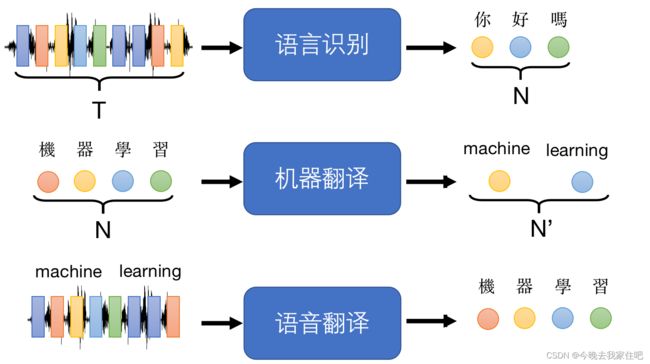
聊天机器人
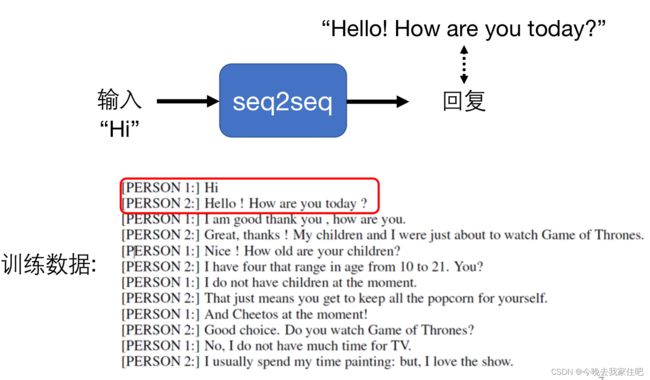
在深度学习中还有很多的人类语言处理模型
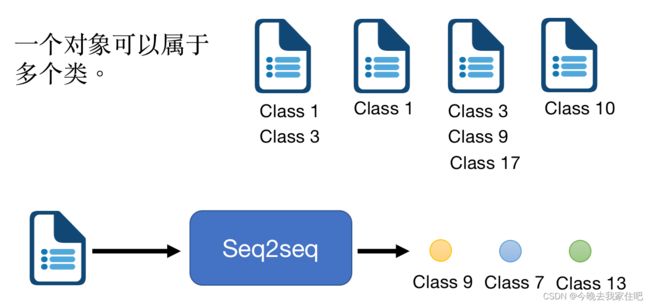
Seq2seq也可以用于多标签分类
2.transformer结构
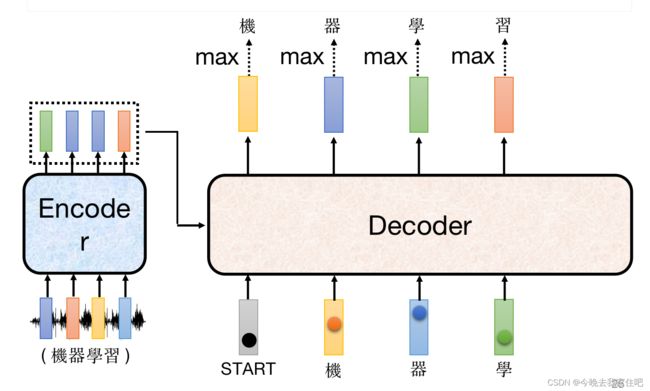
先从seq2seq的结构来看:
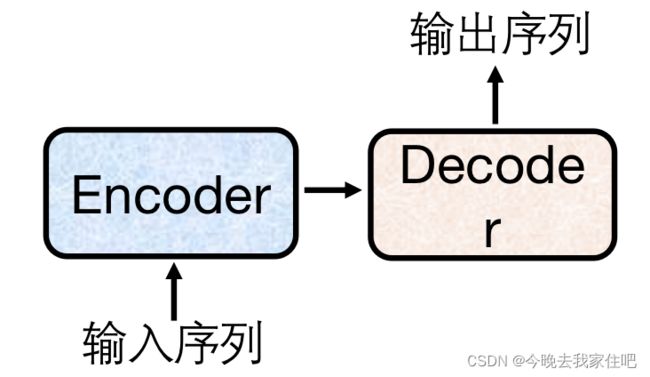
seq2seq这一类模型的结构,通常都是由一个编码器(Encoder)和一个解码器(Decode)组成。
那对应到transformer也是如此如下图所示:
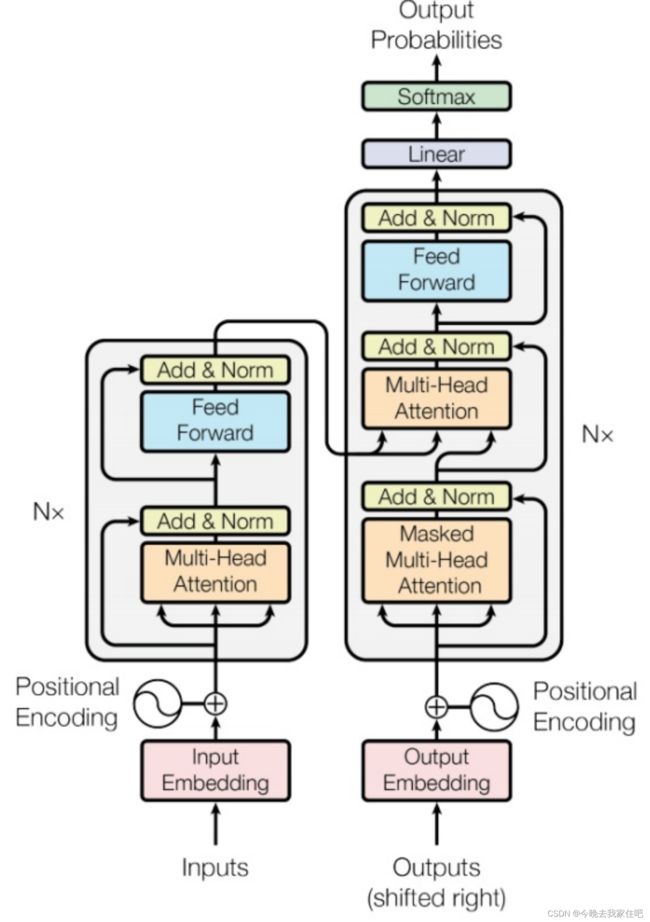
下文将详细对transformer结构展开解释
2.1 transformer的Encoder
2.1.1 Encode结构
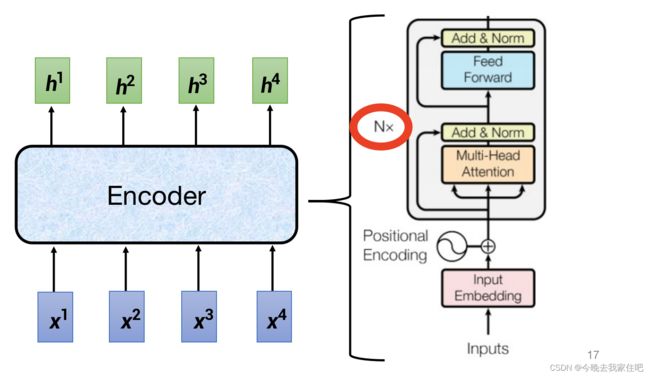
注意这里是由N个上图的结构组成的哦,N个组合的方式如下图:
这里Block就有N个,每一个Block就对应上图里的结构
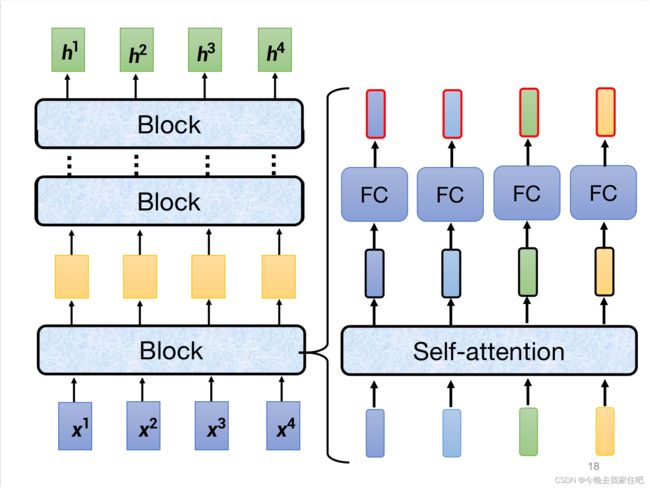
2.1.2 Encoder具体结构分解
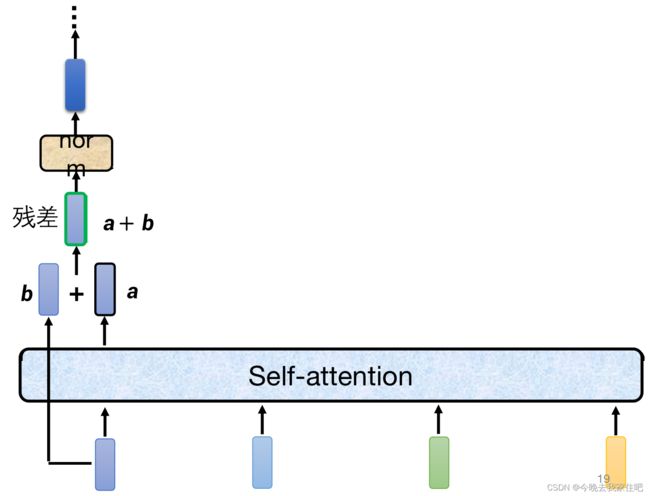
1.多头注意力+残差,再进行layer norm
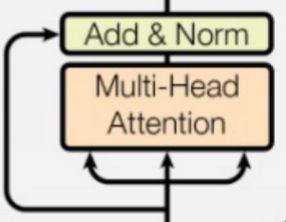
具体计算过程
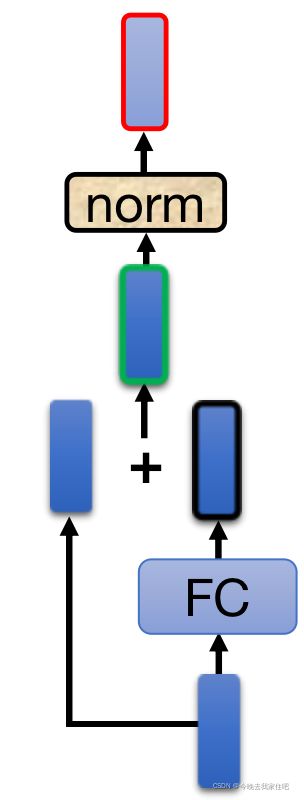
2.前馈神经网络+残差,进行layer norm
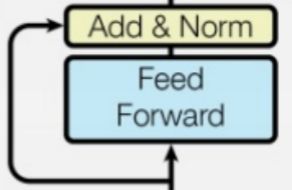
具体计算过程
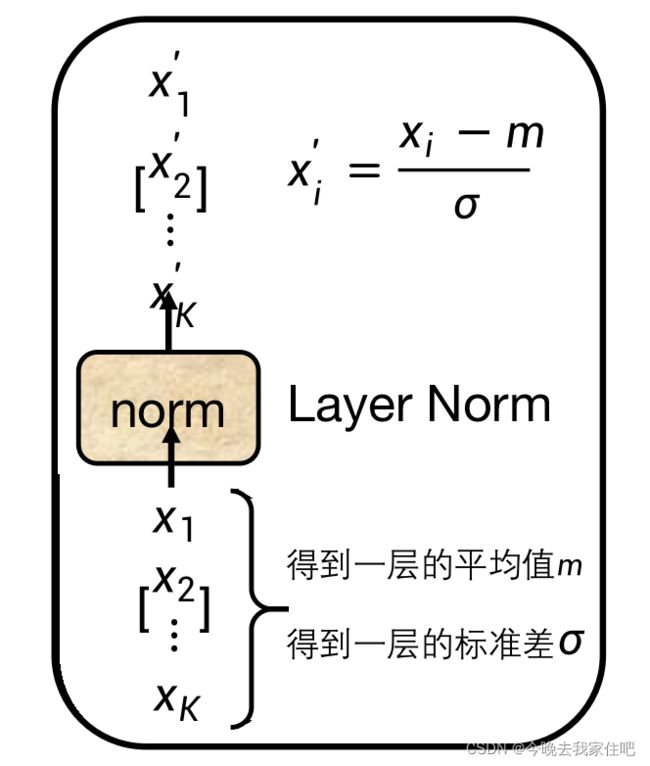
3.layer norm
在神经网络中norm有不同的比如batch norm和layer norm具体区别
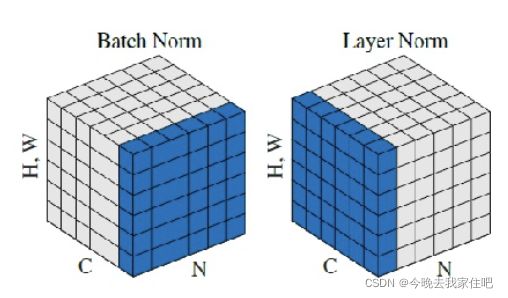
layer norm具体步骤,就是对每一蓝色层,一层层求解,先计算出这一层的平均值与标准差,在进行标准化,转换即可。
2.2 transformer的Decoder
2.2.1 Decode结构
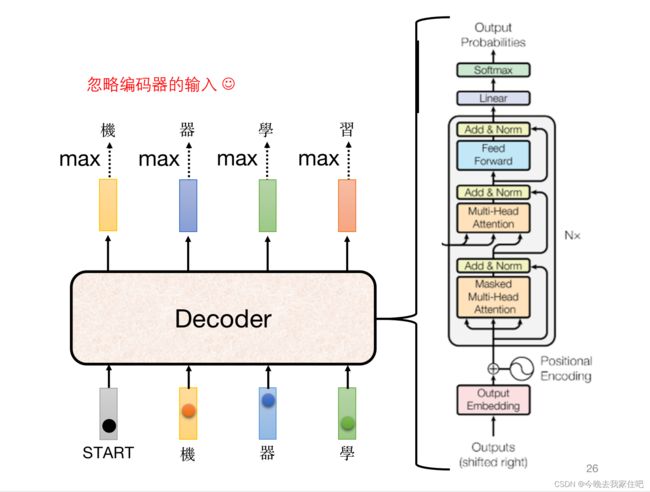
这里详细介绍一下在self-attention使用mask的含义的,实现过程
2.2.2 Mask
在self-attention里mask是一个参数设置,mask有二个作用:
1. key_padding_mask
我们在输入文本的时候,每一个batch的每一个句子的长度一般是不可能完全相同的,所以我们会使用padding把一些空缺补上。而这里的这个key_padding_mask是用来“遮挡”这些padding的。
这个mask是二元(binary)的,也就是说,它是一个矩阵和我们key的大小是一样的,里面的值是1或0,我们先取得key中有padding的位置,然后把mask里相应位置的数字设置为1,这样attention就会把key相应的部分变为"-inf". (为什么变为-inf我们稍后再说)
保持输入文本的每个句子长度一致。用mask填充
2.attn_mask
这个mask经常是用来遮挡“正确答案”的:
假如你想要用这个模型每次预测下一个单词,我们每一个位置的attention输出是怎么得来的?是不是要看一遍整个序列,然后每一个单词都计算一个attention weight?那也就是说,你在预测第5个词的时候,你其实会看到整个序列,这样的话你在预测之前不就已经知道第5个单词是什么了,这就是作弊了。
我们不想让模型作弊,因为在真实使用这个模型去预测的时候,我们是没有整个序列的信息的。那么怎么办?那就让第5个单词的attention weight=0吧,即声明:我不想看这个单词,我的注意力一点也别分给它。
保持输出预测的文本句子长度一致
2.2.3 Cross attention
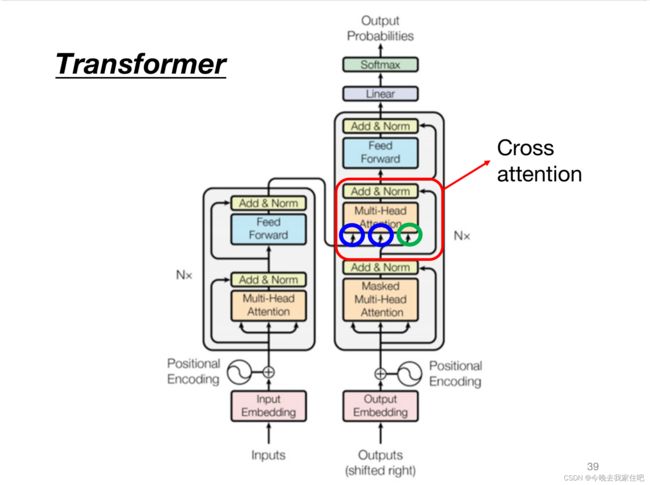
这里蓝色和绿色输入的部分,以及后续三者如何结合的过程如下图所示:
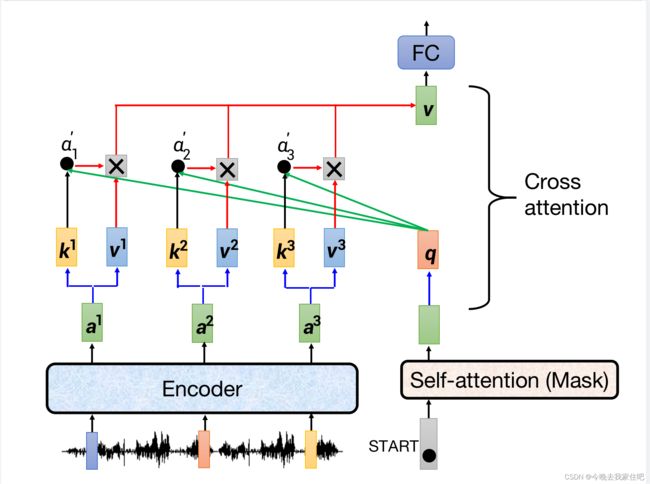
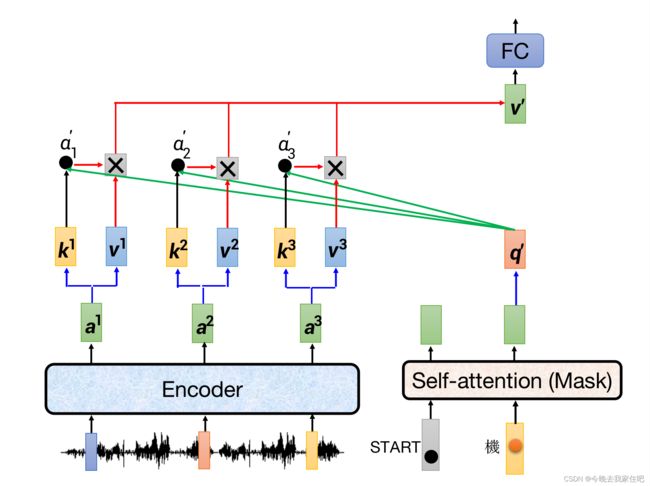
3.self-attention(pytorch实现)
import torch
import torch.nn as nn
import numpy as np
import math
class SelfAttention(nn.Module):
def __init__(self, hidden_size, num_attention_heads, dropout_prob):
"""
假设 hidden_size = 128, num_attention_heads = 8, dropout_prob = 0.2
即隐层维度为128,注意力头设置为8个
"""
super(SelfAttention, self).__init__()
if hidden_size % num_attention_heads != 0: # 整除
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
# 参数定义
self.num_attention_heads = num_attention_heads # 8
self.attention_head_size = int(hidden_size / num_attention_heads) # 16 每个注意力头的维度
self.all_head_size = int(self.num_attention_heads * self.attention_head_size)
# all_head_size = 128 即等于hidden_size, 一般自注意力输入输出前后维度不变
# query, key, value 的线性变换(上述公式2)
self.query = nn.Linear(hidden_size, self.all_head_size) # 128, 128
self.key = nn.Linear(hidden_size, self.all_head_size)
self.value = nn.Linear(hidden_size, self.all_head_size)
# dropout
self.dropout = nn.Dropout(dropout_prob)
def transpose_for_scores(self, x):
# INPUT: x'shape = [bs, seqlen, hid_size] 假设hid_size=128
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size) # [bs, seqlen, 8, 16]
x = x.view(*new_x_shape) #
return x.permute(0, 2, 1, 3) # [bs, 8, seqlen, 16]
def forward(self, hidden_states, attention_mask):
# eg: attention_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]]) shape=[bs, seqlen]
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2) # [bs, 1, 1, seqlen] 增加维度
attention_mask = (1.0 - attention_mask) * -10000.0 # padding的token置为-10000,exp(-1w)=0
# 线性变换
mixed_query_layer = self.query(hidden_states) # [bs, seqlen, hid_size]
mixed_key_layer = self.key(hidden_states) # [bs, seqlen, hid_size]
mixed_value_layer = self.value(hidden_states) # [bs, seqlen, hid_size]
query_layer = self.transpose_for_scores(mixed_query_layer) # [bs, 8, seqlen, 16]
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer) # [bs, 8, seqlen, 16]
# Take the dot product between "query" and "key" to get the raw attention scores.
# 计算query与title之间的点积注意力分数,还不是权重(个人认为权重应该是和为1的概率分布)
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
# [bs, 8, seqlen, 16]*[bs, 8, 16, seqlen] ==> [bs, 8, seqlen, seqlen]
attention_scores = attention_scores / math.sqrt(self.attention_head_size) # [bs, 8, seqlen, seqlen]
# 除以根号注意力头的数量,可看原论文公式,防止分数过大,过大会导致softmax之后非0即1
attention_scores = attention_scores + attention_mask
# 加上mask,将padding所在的表示直接-10000
# 将注意力转化为概率分布,即注意力权重
attention_probs = nn.Softmax(dim=-1)(attention_scores) # [bs, 8, seqlen, seqlen]
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# 矩阵相乘,[bs, 8, seqlen, seqlen]*[bs, 8, seqlen, 16] = [bs, 8, seqlen, 16]
context_layer = torch.matmul(attention_probs, value_layer) # [bs, 8, seqlen, 16]
context_layer = context_layer.permute(0, 2, 1, 3).contiguous() # [bs, seqlen, 8, 16]
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,) # [bs, seqlen, 128]
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer # [bs, seqlen, 128] 得到输出
attention=SelfAttention(4,2,0.2)
x_in=torch.randn(3,5,4)
x_mask=torch.Tensor([[1,1,1,0,0],
[1,1,0,0,0],
[1,1,1,1,1],])
print(x_mask.shape)
x_out=attention(x_in,x_mask)