Object Detection in 20 Years A Survey 论文阅读笔记
文章链接:https://arxiv.org/pdf/1905.05055.pdf
1.Introduction
作为计算机视觉的基本问题之一,目标检测构成了许多其他计算机视觉任务的基础,例如实例分割,图像捕获,对象跟踪等。从应用的角度来看,目标检测可分为两个研究主题“general object detection”和“detection applications”,前者旨在探索在统一框架下检测不同类型目标的方法,以模拟人类的视觉和认知,后一种指的是特定应用场景下的检测,例如行人检测,面部检测,文本检测等。目标检测面临的挑战包括但不限于以下方面:物体旋转和尺度变化(例如小物体),精确的物体定位,密集和封闭的物体检测,检测速度的加快等。
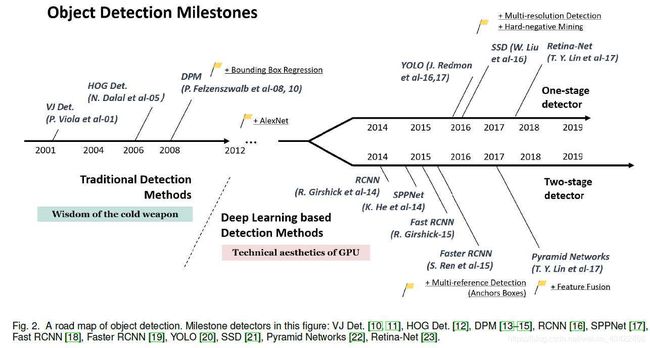
2.OBJECT DETECTION IN 20 YEARS
2.1 A Road Map of Object Detection
2.1.1Milestones: Traditional Detectors
Viola Jones Detectors:
通过滑窗来检测人脸,计算量巨大,采用了三个方法加速运算:“integral image”, “feature selection”,and “detection cascades”.
1.积分图像加速了框滤波(box filtering)和卷积过程,且使得每个窗口的计算复杂度与窗口尺寸无关
2.特征选择:作者使用Adaboost算法,从大量的随机特征池(约18万维)中选择了一小部分对大多数人脸检测有用的特征。
3.检测级联:引入了一种多阶段检测范例(也称为“检测级联”),在背景窗口上花费较少的计算而在面部目标上花费更多的计算,来减少其计算量。
HOG Detector:
平衡了特征的不变性(invariance)和非线性,经过
1.颜色空间归一化(图像灰度化,Gamma校正)
2.梯度计算
3.梯度直方图(每个cell)梯度分为n个bin,4个cell构成一个block,block内进行归一化
4.形成HOG向量,4n*block数量
Deformable Part-based Model (DPM)
“devide and conquer”:训练过程就是学习一种decomposing an object的正确方式,学习分解物体。inference就是用一个物体不同部分的集合来表示这个物体。
DPM detector由一个root-filter 和若干个 part-filter 组成,part-filters由弱监督学习方法detector学习而来。(“hard negative mining”, “bounding box regression”, and “context priming”)To speed up the detection, Girshick developed a technique for “compiling” detection models into a much faster one(使用了级联结构)
2.1.2 Milestones: CNN based Two-stage Detectors
RCNN
1.首先提取一系列object proposals(使用selective search)
2.将每一个proposal,resize到一个固定size丢到CNN模型中在ImageNet上进行训练来提取feature
3.最后使用线性SVM分类器来predict每个区域中目标的位置以及label
drawback:太多重叠的、过多的proposals的计算量巨大,导致检测速度太慢
SPPNet(Spatial Pyramid Pooling Networks)
提出了一个SPP层(spatial pyramid pooling layer),可以在不对image或ROI进行resize的情况下,处理生成一个固定长度的representation。
SPPNet可以直接对整个图像进行计算一次就得到Feature map,然后得到每个ROI的固定维度的representation来训练detector,避免了重复的卷积计算。
drawback:training仍然是multi-stage的(detector与bbox),SPPNet只微调它的FC层,而忽略了之前的层。
Fast RCNN
可以在同一个网络中同时训练detector和bounding box regressor,
但是仍局限在proposal detection,速度被局限
Faster RCNN
Faster RCNN is the first end-to-end(原始数据输入,输出结果), and the first near-realtime deep learning detector.
提出了Region Proposal Network(RPN),将目标检测中之前独立的环节都整合到了一个框架中,共享计算。(proposal detection, feature extraction, bounding box regression, etc)
drawback:在后续的检测阶段仍有一些多余的计算
FPN(Feature Pyramid Networks)
因为CNN越深层的特征对于目标分类来说越有效,所以FPN之前的框架,都是只在最深一层运行detector,但是深层的特征对目标的定位不一定好。
FPN提出带有侧面连接的up-down结构,对不同尺度的feature map进行predict,而不是只关注最后一层map,这样可以在不同层输出不同尺度目标的检测结果。在那些有着多种尺度目标的检测中效果很好。
2.1.3 Milestones: CNN based One-stage Detectors
YOLO
第一个one-stage的detector,速度很快。
逻辑:将整张图片提供给一个神经网络,网络将图片分区域然后预测bbox,同时给出各个区域的label概率。
drawback:定位准确率不够高,对小物体效果稍差。
Single Shot MultiBox Detector(SSD)
提出了multi-reference 和multi-resolution技术(2.3.2中讲解),极大地改善了one-stage探测器的准确率以及对小目标的探测能力。
SSD与其他早先的探测器的主要不同在于,之前的探测器,探测不同尺度的目标时在网络的不同层进行,而SSD只在top layers进行。
RetinaNet
认为one-stage准确率不如two-stage的主要原因是,在训练dense detector时,会发生前景和背景class的不平衡。
提出了一种新的loss函数“focal loss”,它reshape了标准的交叉熵,使得探测器可以在训练时更加注意hard、misclassified examples.
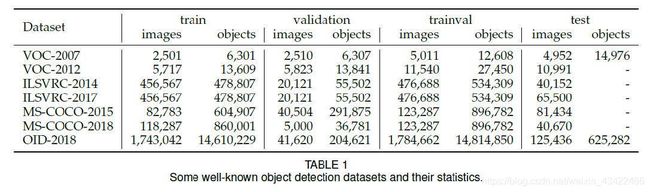
2.2 Object Detection Datasets and Metrics
Pascal VOC
比赛包括多种任务:分类、目标检测、语义分割、动作捕捉等
数据集
VOC07,5k images, 12k标注好的目标
VOC12,11k + 27k
慢慢落后了
ILSVRC(The ImageNet Scale Visual Recognition Challenge)
使用ImageNet数据集进行detection challenge
包括 200 种visual objects,ILSVRC-14包含517k images 以及 534k 标注目标
MS-COCO
比ILSVRC相比来说类别少,但是标注的目标多。
MS-COCO-17包含 80类别、164k images、897k object
与上面两个最大的不同在于,不是使用bbox标注位置,而是使用了per-instance segmentation来对每个目标进行精确定位。
此外,MS-COCO数据集还包含了更多的小目标(小于图片大小1%),以及更多的密集分布的目标。
Open Images
Open Images Detection(OID)Challenge包含两个任务:
1.标准的目标检测
2.在目标检测中,检测paired objects的visual relationship
包含 600类、1910k images、15440k 标注目标

Other Datasets


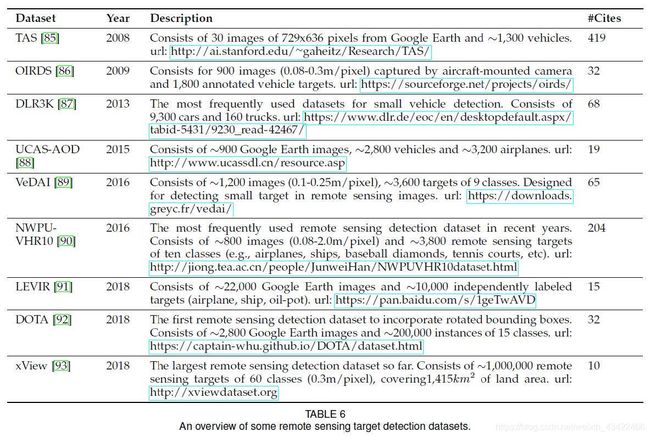
2.2.1 Metrics
“Average Precision (AP)”:在一个特定类别中,检测的准确率(预测中实际为正的数量/预测为正的数量)
mean AP (mAP):综合所有类别的准确率。
定位的准确性:使用IoU,预测框与ground truth 的IoU大于某个值,认为成功检测。0.5-IoU based mAP是现在比较常用的metrics
MS-COCO AP 将IoU从0.5-0.95的AP进行平均
2.3 Technical Evolution in Object Detection
2.3.1 Early Time’s Dark Knowledge
Components, shapes and edges
recognition by components是早期目标检测的core idea,早期认为目标检测就是计算目标的成分、形状和轮廓的相似性。(Distance Transforms ,Shape Contexts, and Edgelet),效果不够好,ML方法兴起。
ML based检测方法(appearance的统计模型、小波特征表示(Haar小波)、梯度based 表示)
Early time’s CNN for object detection
早在1990s就使用了CNN,受限于计算能力,没有很好地发展,层数很浅,LeCun提出了许多tricks来摆脱这个限制。
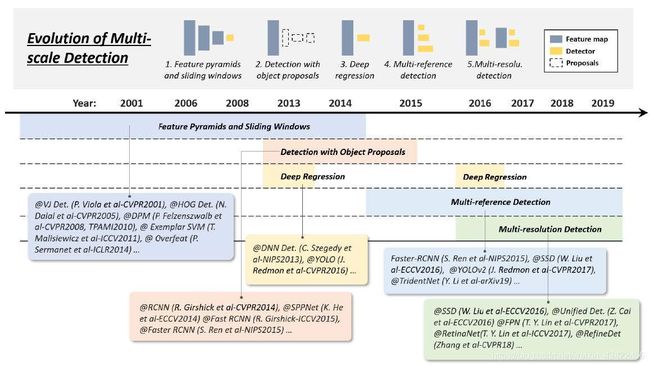
2.3.2 Technical Evolution of Multi-Scale Detection
Feature pyramids + sliding windows (before 2014)
eg:HOG、DPM、OverFeat
原始的特征金字塔+滑窗只能针对固定size以及长宽比的目标检测
mixture model进行了改进:使用多个model训练不同ratio的目标检测
exemplar-based detection:为训练集中每个object训练individual models
但是随着数据集中越来越多样,上面两种方式的模型越来越冗杂(miscellaneous),需要一种方法能够同时检测不同ratio的目标
Detection with object proposals (2010-2015)
object proposals指的是一组可能包含任意目标的候选框(candidate boxes),它的出现避免了在整张图片的全面的(exhaustive)滑窗。
一个object proposals detection algorithm需要满足:
1.高召回率
2.高定位准确率
3.在1.2的基础上,提升准确率以及降低处理的时间
现代object proposals methods可分为三种:
1.segmentation grouping approaches
2.window scoring approaches
3.neural network based approaches
从bottom-up vision到“overfitting to a specific set of object classes”
Deep regression (2013-2016)
idea:based on 深度学习的特征直接预测bounding box的坐标
优点是简单易于应用,缺点是对于小目标定位可能不够准确
Multi-reference/-resolution detection (after 2015)
Multi-reference
main idea:首先定义一系列reference boxes(anchor boxes),它们位于图片的不同位置,有着不同的size和ratio,然后根据这些predefined的anchor来预测bounding box。
每一个anchor box的Loss由两部分组成,用于分类的交叉熵loss 以及用于定位的L1/L2 regression loss
Multi-resolution detection
idea:在网络的不同层来检测不同尺度的目标。由于CNN通常通过前向传播形成feature pyramid,it is easier to detect larger objects in deeper layers and smaller ones in shallower layers.
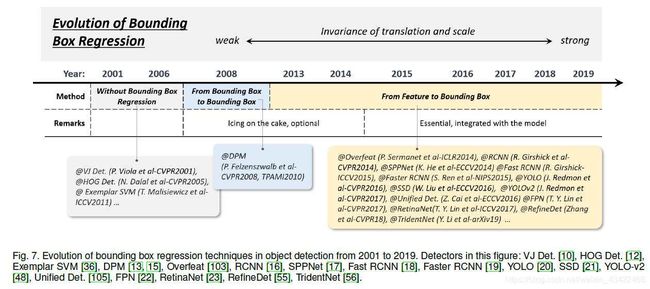
2.3.3 Technical Evolution of Bounding Box (BB)Regression
BB regression就是based初始的proposal or anchor来refine 预测的BB。
Without BB regression (before 2008)
VJdetector、HOG等没有BB regression,直接滑窗之后当作检测结果,为了获得精确结果,只能设计very dense pyramid,滑窗也要densely滑过每个位置。
From BB to BB (2008-2013)
DPM中首先提出了BB regression,那时的BB regression是一个post-processing block,是可选的。
R. Girshick提出了一种更复杂的方式,基于object 假设,将过程转化为最小二乘回归问题。
From features to BB (after 2013)
在Faster RCNN提出之后,BB regression整合到了detector之中,同样直接基于CNN features来预测BB,为了得到更鲁棒的预测结果,使用smooth-L1 function或 root-square function
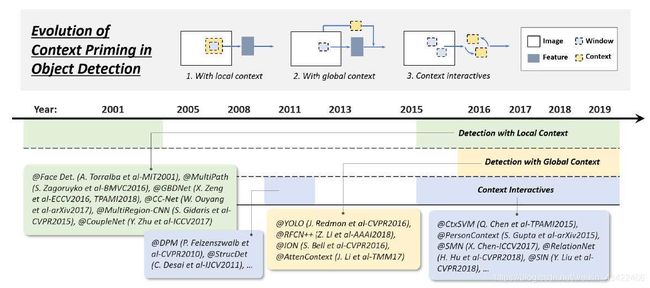
2.3.4 Technical Evolution of Context Priming
visual objects通常都embedded在带有环境的typical context中,人的大脑可以利用目标和环境之间的联系来形成视觉感知以及认知。context priming一直被用来提升detection,它有三种方式:
1)detection with local context, 2) detection with global context,
and 3) context interactives
Detection with local context
local context指的是目标周围区域的视觉信息。
2000s早期人们就发现,包含local context的区域,比如面部轮廓,可以极大提升面部检测的表现。在行人检测中,包含一点背景信息可以提高准确率。
深度学习中,通过扩大网络感受野或者提高object proposal的size完成
Detection with global context
global context 将场景配置(scene configuration)用作对象检测的附加信息源。
早期,整合global context的方法是将组成scene的成分进行统计总结,比如GIST向量。
深度学习时代,有两种整合global context的方式:
1.使用比input image还大的感受野或对CNN feature全局pooling操作
2.把global context当作一种sequential 信息,使用RNN学习
Context interactive
Context interactive指的是通过视觉元素的交互传达的信息,例如约束和依赖性。
大部分目标检测认为检测是各个object是独立的,没有联系的,考虑context interactive可能会提升能力
1.explore the relationship between individual objects
2.explore modeling the dependencies between objects and scenes
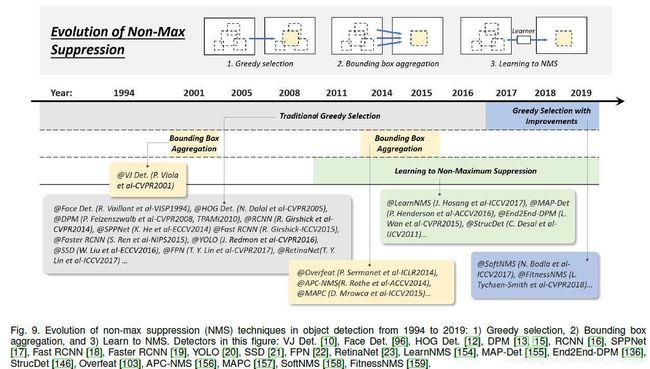
2.3.5 Technical Evolution of Non-Maximum Suppression
NMS用来post-processing,去除重复的bb,获得最后的检测结果
三种方法:1.greedy selection 2.bounding box aggregation 3. learning to NMS
Greedy selection
idea:对一组重叠的检测结果,有最大检测得分的bounding box被选择,其他的检测框(超过一定的重叠阈值)被移除。
但是得分最高的不一定是最好的,同时它可能会抑制邻近的objects,并且它对假阳性没有抑制效果。但这种方法仍是效果最强的baseline

BB aggregation(聚合)
idea:将多个重叠的BB聚合成一个最终的BB检测结果。这种方法的好处在于考虑了objects之间的关系和空间布局
Learning to NMS
idea:把NMS当做一个新的filter来训练,让它可以对所有的raw-detections进行re-score,把filter作为网络的一部分进行端对端训练。
目前取得了一些超出人工NMS的效果
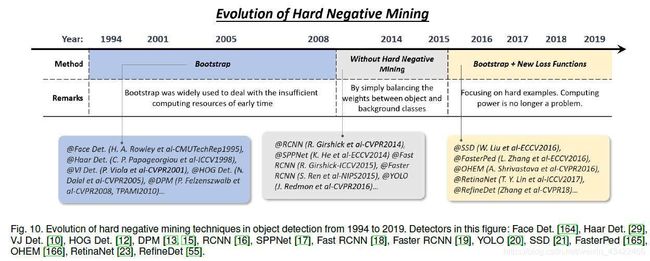
2.3.6 Technical Evolution of Hard Negative Mining
object detector的训练是一个十分不平衡数据学习的问题,在滑窗based训练中,背景和目标数据的不平衡甚至达到10^6:1级别(背景数据较大,目标数据小,数据不平衡),此时,使用全部的背景数据进行训练会损害训练结果。
Hard Negative Mining(HNM)就是在训练过程中处理这种数据的不平衡的方法。
Bootstrap
指的是一组training techniques,训练首先从一小部分的background sample开始,然后重复迭代添加新的miss-classified background
最开始它的提出是为了降低训练计算量,后来在DPM和HOG就成为解决data不平衡的标准训练技巧。
HNM in deep learning based detectors
为了缓解data imbalance过程,Faster RCNN以及YOLO直接在positive和negative windows之间balance the weights,但是无法彻底解决这个问题。
所以Bootstrap又重新被引入,SSD和OHEM中,只有很小一部分的samples的梯度会被回传。RefineDet中,一个“anchor refinement module”用来filter easy negative。
另一种可能的improvement是设计一种新的loss函数,通过reshape标准的交叉熵loss使其更多的关注hard、misclassified sample。
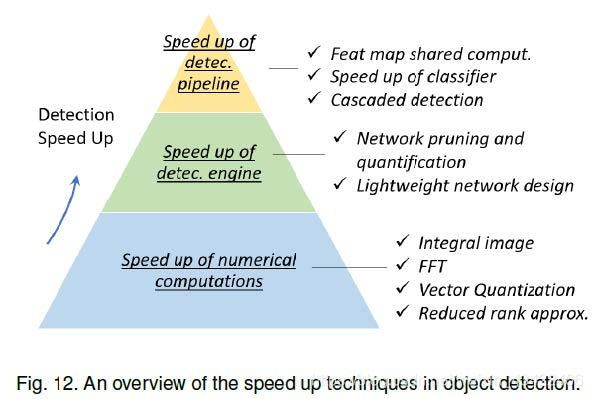
3. SPEED-UP OF DETECTION
object detection的加速技术可以分为以下三种类型:“speed up of detection
pipeline”, “speed up of detection engine”, and “speed up of numerical computation”
3.1 Feature Map Shared Computation
通常情况下,特征提取(feature extraction)占据了主要的计算量。对于滑窗based的方法,位置和尺度均会产生计算冗余,计算位置的时候,邻近的windows的重叠引起大量计算,对于尺度,相邻尺度之间的特征的关联也需要大量计算。
3.1.1 Spatial Computational Redundancy and Speed Up
最基本的idea是:通过feature map共享计算来减少空间冗余。即在滑窗之前,只对整个图像计算一次得到特征图。
比如计算HOG时,对整个图像计算HOG map。但是会导致feature map分辨率被闲置,很小的目标可能就被忽略了。
3.1.2 Scale Computational Redundancy and Speed Up
减少尺度计算冗余的最成功方法是:直接对features进行scale而不是图片,但是对HOG-like feature 由于模糊效应,不能直接使用。
后来,有人通过统计分析发现了neighbor scales of HOG和integral channel features之间的log-linear关系。这个关系就可以用来近似预测相邻尺度的特征图来加速计算。
另外还可以build detector pyramid来降低尺度计算:若要detect不同尺度的目标,直接在一个特征图上使用多个尺度的detector进行滑窗,而不是re-scaling image or features
3.2 Speed up of Classifiers
早期传统的滑窗based detector因为计算能力限制,通常使用线性的分类器。后来常使用非线性分类器,比如kernel SVM,但是作为一个标准非参数方法,传统kernel method没有固定的计算复杂度,如果training set较大,detection速度会很慢。
在object detection中,通常使用model approximation来加速kernelized classifier。在经典内核的SVM中,决策边界只有训练样本中的一小部分(支持向量)来决定,因此它的计算复杂度与支持向量数成正比,Reduced Set Vectors就是一种对kernel SVM近似的方法,旨在使用少量的合成向量来获得等效的决策边界。另一种加速kernel SVM的方法是将决策边界近似为分段线性形式,或使用稀疏编码方法进行加速。
3.3 Cascaded Detection
级联检测采用一种粗到细的策略:首先使用简单的计算过滤掉大部分的simple background windows,再使用复杂计算处理复杂的滑窗。
这种方式被广泛应用,尤其是在“small objects in large scenes”的检测中,除了加速算法,它同时也被用来解决问题:提升hard examples的检测效果,提升定位准确率,integrate context information。
3.4 Network Pruning and Quantification
网络剪枝和网络定量化是加速CNN model的常用方法,前者指的是修建网络结构或权重来减小网络尺寸,后者是减少激活和权重的代码长度
3.4.1 Network Pruning
近年来,网络剪枝take an iterative training and pruning process,即每次训练之后,移除一小部分不重要的权重,然后重复训练,重复剪枝过程。由于只移除一部分不重要的权重只会导致卷积层的一些连接变得稀疏,而不能直接压缩CNN模型,一种解决方法是直接移除整个filter的权重,而不是独立的权重。
3.4.2 Network Quantification
最近的网络定量化主要关注在网络二值化(network binarization),目的是通过使激活和权重的值二值化(0/1),来使得浮点数运算改变为AND、OR、NOT的逻辑运算,以此来加速。这种方法可以大幅加速且降低网络的存储,因此可以部署到移动设备上。
也研究出了一些方法来使用二值化的网络进行卷积操作等
3.4.3 Network Distillation
Network Distillation是一种general framework,来compress一个大型网络(teacher net)的知识,into 小型网络(student net)
用在object detection中,一种方法是使用teacher net对student的训练过程进行指导,因此加速了训练过程。另一种方法是对候选区域进行transform,使其在teacher和student之间的feature distance最小。
3.5 Lightweight Network Design
In addition to some general designing principles like “fewer channels
and more layers”,some other approaches have been proposed in recent years: 1) factorizing convolutions, 2) group convolution, 3) depth-wise separable convolution, 4) bottle-neck design, and 5) neural architecture search.
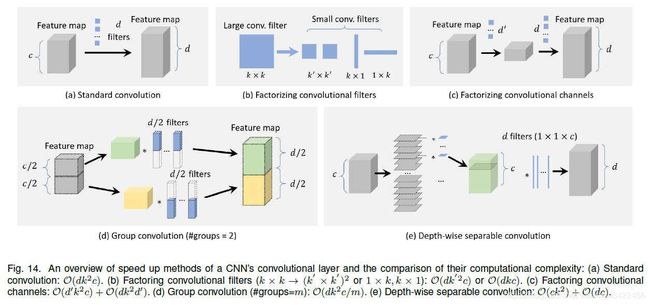
3.5.1 Factorizing Convolutions
分解卷积,是最简单和最直接来build lightweight CNN model的方式。有两组方法:
第一组是将大的卷积filter转化为一组在他们空间维度的小卷积filter。比如可以将一个77的转化为三个33的filter,他们share相同的感受野,但是更加有效。
或者是将一个kk的转化为一个1k,一个k1的filter,这种方法对于非常大的filter(比如1515)很有效。
另一组方法是把一大组卷积分解成两小组卷积(依照channel 维度),大大降低了计算复杂度。(factorizing convolutional channels)

3.5.2 Group Convolution
为了降低卷积层的参数数量,将feature channels 分成许多不同的组,之后每个组分别进行卷积。
3.5.3 Depth-wise Separable Convolution
可以看做是group convolution的一种特殊情况:当group数量==channel数量时
这种想法广泛用于object detection和fine-grain classification(细粒度分类)
3.5.4 Bottle-neck Design
一种方法是压缩输入层来从detection pipeline的最开始降低计算,另一种是压缩detection engine的输出,来使feature map更加thin
3.5.5 Neural Architecture Search(NAS)
使用NAS来自动地设计网络,已被用于大尺度图像分类、目标检测、图像分割中,在设计轻量网络也展现出很好的效果。它的限制在于searching过程中的计算量和准确性还有待提高。
3.6 Numerical Acceleration(数值加速)
3.6.1 Speed Up with Integral Image
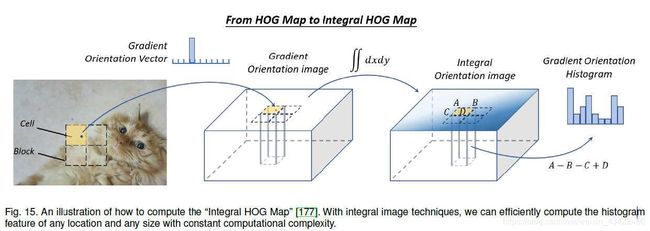
Integral image(积分图像)可以快速的over sub-regions,直接计算得到图像的总结(summations)。积分图像方法的本质是信号处理中卷积的积分微分可分离性,如果存在离散信号(dg(x)/dx),则卷积过程可被以下公式加速。
同样。积分图像也可以用来加速更普通的特征,比如color直方图、梯度直方图等,最常用的就是计算积分HOG map来加速HOG过程,HOG map统计像素值,积分HOGmap统计的是图的梯度。可直接用于行人检测,在没有损失准确率的情况下大大加速。
2009年,提出了一种新的image feature,Integral Channel Features(ICF),更为general的一种integral image feature,取得了接近实时检测的效果。
3.6.2 Speed Up in Frequency Domain
对于大型filter的卷积运算,傅里叶变换转到频域进行运算,再转回空域。
使用快速傅里叶变换大大减少了时间。

3.6.3 Vector Quantization
矢量量化(VQ)是信号处理中的一种经典量化方法,旨在使用一小部分典型向量来近似一大组数据的分布。可以用来压缩数据以及目标检测的加速。比如使用一部分典型vector代表HOG features,在检测阶段直接查表操作。
3.6.4 Reduced Rank Approximation
FC层涉及到矩阵乘法运算,计算量很大,The reduced rank approximation is a method to accelerate matrix multiplications.它旨在对矩阵进行降阶(截断奇异值分解降维),减少了参数量,提升了计算速度。
4. RECENT ADVANCES IN OBJECT DETECTION
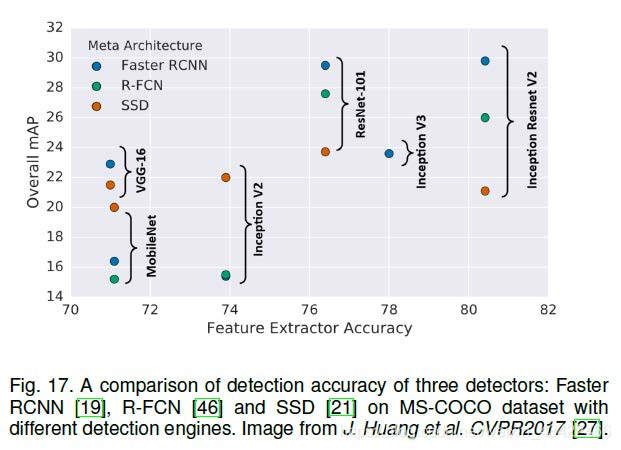
4.1 Detection with Better Engines
detector的准确率极大依赖于特征提取网络层,下面介绍深度学习时代的几种重要的engine(backbone,比如VGG、ResNet)
AlexNet:八层网络,第一个CNN model
VGG:16-19层,使用了很小的卷积核(33)代替了55,7*7
GoogLeNet(Inception):最多到22层。最大贡献是factorizing convolution
and batch normalization
ResNet:最深152层,残差块,快捷恒等映射
DenseNet:在Resnet基础上,提出了更为dense的层,每一层都由快捷恒等映射相连
SENet(Squeeze and Excitation Networks):主要贡献是global pooling以及shuffling的整合,来逐通道(channel)学习feature map
4.2 Detection with Better Features
最近,研究人员致力于提升image features的质量,使用以下两种方法:1) feature fusion and 2) learning high-resolution features with large receptive fields
4.2.1 Why Feature Fusion is Important?
不变性和等方差性(equivariance)是图像特征表示中的两个重要属性。分类需要特征有不变性,才能学到高层次的语义信息,定位需要等方差性的特征,才能适应辨析位置和尺度的改变。
因为CNN越深层的特征,不变性越好但是等方差性越差,浅层特征分类效果较差,但是适合用来定位,因为浅层特征包含更多的轮廓和边缘。因此,将深层特征和浅层特征进行特征融合很重要。
4.2.2 Feature Fusion in Different Ways
主要介绍两方面的方法:1.processing flow(处理流程) 2.element-wise operation
Processing flow
目前特征融合方法可以分为两类,1) bottom-up fusion, 2) top-down fusion
前者通过skip connections feed到深层网络中。相反,后者把深层特征feed back到浅层中。除了这两种,还有更复杂的方法,比如weaving features across different layers
由于不同层的feature map的空域size和channel dimensions都可能不同,需要对低分辨率map进行上采样,或者高分辨率map进行下采样以达到匹配。、,最简单的方式就是采用最近邻或双线性插值。另外,fractional strided
convolution (a.k.a. transpose convolution)也是一种resize 特征图和调整通道数的好方法,采用这种方法的优点在于它可以自主学习到最适应的方法进行上采样。
Element-wise operation
对图中每一点来说,特征融合可以看做是不同特征图之间的按元素操作。有三种方法:1) element-wise sum, 2) element-wise product(乘积), and 3) concatenation(级联)
1.2是最简单最常用的方法,2使用乘积,优点在于可以用来使用一块区域来suppress or highlight特征,这对之后的小目标检测更有效。
3的优点在于,它可以用来整合不同区域的context information,但是它的缺点在于对memory需求的增长
4.2.3 Learning High Resolution Features with Large Receptive Fields
感受野大小(receptive field)和特征的分辨率(feature resolution)是CNN based的两个重要参数,前者是输入像素的空间范围,决定了每个输出像素的计算量;后者对应于输入和特征图之间的下采样率。有更大感受野的网络可以获取更大尺度的context information,smaller one更关注local details。
提升特征分辨率的最简单方法就是去掉池化层或者较少下采样率,但是这会引起感受野变得太小,导致对一些稍微大的目标的检测失败。
可以同时完成上面两个参数的一个方法是膨胀卷积dilated convolution (a.k.a. atrous convolution, or convolution with holes)。它的主要思想是expand卷积filter and use 稀疏参数。比如33的filter,膨胀率2,拥有55的感受野但是只有9个参数。目前这种方法被广泛应用,效果很好。
4.3 Beyond Sliding Window
目前目标检测主流方法仍是“在特征图上滑窗”,但也出现了一些beyond sliding windows的探测器。
Detection as sub-region search
一种方法是将检测视为从初始网格开始并最终收敛到所需的地面真实框的路径规划过程。
另一种方法是将检测视为一个迭代更新的过程,不断对预测的bb的边角进行refine
Detection as key points localization
关键点定位已经有了广泛应用,比如面部表情识别、位姿识别等。
图像中的目标可以被ground truth左上角和右下角决定,因此目标检测可以视作成对的关键点定位问题。
这个方法的优点在于应用于语义分割框架之下,并且目标检测中不需要涉及多尺度的anchor box
4.4 Improvements of Localization
最近研究中主要有两种方法来提升定位,1.BB refinement 2.为准确定位设计一个新的loss函数
4.4.1 Bounding Box Refinement
bbox refinement是提升定位准确率的最有效方法,可认为是对检测结果的post-processing过程。尽管BB regression已经广泛应用,还是存在一些目标不能被predifined anchor找到的情况。所以,“iterative bounding box refinement”被提出,通过将检测结果不断地丢到BB regressor之中,直到结果收敛到正确的位置和尺寸。然而一些研究人员声称这种方法不是百分之百有效,当进行许多次操作之后,结果可能退化。
4.4.2 Improving Loss Functions for Accurate Localization
现代目标检测中,定位过程是一个参数回归问题,然而有两个缺陷。一是回归loss 函数大小与最后定位结果的评价无关,比如regression loss 很小,不一定会得到IoU很大的预测结果,尤其是目标的长宽比很大的时候。二是BB regression没有定位的信度信息,当多个BB重叠在一起的时候,可能会导致NMS的失败。
设计一个新的Loss Function来解决上面的问题,比如直接使用IoU作为定位的loss函数,还有研究人员进一步提出了 IoU-guided NMS 来在训练和检测阶段同时提升定位准确性。同时,一些人通过概率推断框架(probabilistic inference framework)来提升定位,与上面直接预测box 参数不同,这种方法预测边界框位置的可能性分布。
4.5 Learning with Segmentation
目标检测和语义分割是CV的重要任务,目前的一些研究表明目标检测可以通过使用语义分割学习来提升
4.5.1 Why Segmentation Improves Detection?
Segmentation helps category recognition
CV中目标与背景的不同主要在于前者通常有闭合并且well defined的边界而后者没有。而语义分割任务通常会找到目标的边界特征,因此分割对分类识别来说可能会有帮助。
Segmentation helps accurate localization
由于ground-truth BB通常是定义好的矩形框,对于一些特殊形状的目标(比如一只尾巴很长的猫),很难获得高IoU的定位。由于目标边界可以很好的编码到语义分割特征中,Learning with Segmentation可能会提升定位准确性。
Segmentation can be embedded as context
通常情况下,目标被许多常见背景包围,所有的这些背景构成了目标的context,通过语义分割整合这些context会对目标检测有所帮助。比如,飞机更可能出现在天空中而不是水中。
4.5.2 How Segmentation Improves Detection?
Learning with enriched features
最简单方法是把分割网络党雒一个固定的特征提取器,把提取到的特征作为额外的features送入检测框架中。
这种方法很容易实现应用,但是带来了额外的计算量。
Learning with multi-task loss functions
另一种方法是在原有的框架前增加一个segmentation branch,让model的loss变为多任务loss(分割loss+检测loss)通常,在推理阶段(test阶段?)移除分割branch,这样检测速度会提升,但是缺点是训练时需要图像为像素级别的annotations。为此,一些研究人员使用了弱监督学习的方法,在训练segmentation branch时,使用bounding box level的annotation替代像素级别的annotation
4.6 Robust Detection of Rotation and Scale Changes
目标检测中,目标的旋转和尺度改变是主要的挑战。由于CNN学习的特征大部分对于旋转和尺度大范围改变有不变性,目前已取得很大进展。
4.6.1 Rotation Robust Detection
最简单解决旋转问题的方法就是数据增强,使得任意方向的目标都可以检测到。另一种方法就是针对不同方向训练不同的探测器。除了这些传统法,目前有几个新的方法。
Rotation invariant loss functions
为原有的检测loss增加了一个约束,使得对于旋转目标提取到不变的特征。
Rotation calibration
对候选目标进行几何变换,这在multi-stage的探测器中尤其有效,使得前面阶段的相关性(correlation)对后续阶段的探测有好处。代表idea是Spatial Transformer Networks(STN),已被应用于旋转文本检测和旋转面部检测
Rotation RoI Pooling
在two-stage检测中,feature pooling旨在为object proposal提取到固定长度的特征表示,步骤是先将proposal等分成网格,再将网格的特征级联得到长度一致。由于网格划分是在笛卡尔坐标系中进行的,因此特征对于旋转变换而言并非不变。最近的一种改进是网络划分在极坐标系中进行,这样对旋转变换有很好的的鲁棒性。
4.6.2 Scale Robust Detection
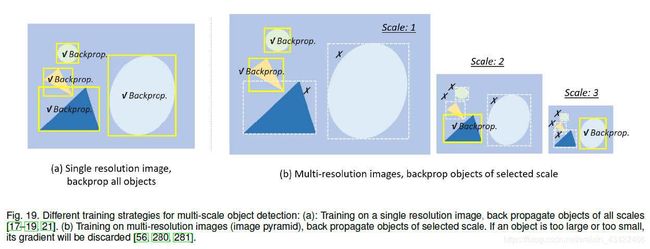
Scale adaptive training(尺度自适应训练)
大部分网络训练过程都是将输入图像re-scale到固定尺寸进行backpropagate,会造成“scale imbalance”问题,构建图像金字塔会缓解这个问题但不能从根本上解决。最新的进展是Scale Normalization for Image Pyramids (SNIP),它在训练和检测stage都构建图像金字塔,但是每次只选择一部分尺度的进行回传。它的升级版SNIP with Efficient Resampling (SNIPER),将图像裁剪之后re-scale到一系列子区域(sub-regions),以从大批量(large batch)训练中获益。
Scale adaptive detection
大部分detector对于不同尺寸目标检测,使用一样的配置环境,例如传统CNN model,我们需要定义anchor的尺寸。这样的缺点在于,固定的配置无法适应于unexpected 的尺度改变。
一些“adaptive zoom-in”技术被提出来自动enlarge 小目标使其可以被检测。另一种改进是学习去预测图像中的目标尺度分布(scale distribution of objects),然后依照分布自适应的re-scale 图像。
4.7 Training from Scratch(从头开始训练)
目前通常情况下使用迁移学习,使用在大尺度数据及不如ImageNet上预训练好的模型,再进行进一步训练。但实际上,对于一些实际情况,比如ImageNet与训练集有较大差异,或者目标训练集与ImageNet通道数不符等,就不适合进行迁移学习。
一些研究也发现,从头开始训练可以取得很好效果,迁移学习虽然可以较快收敛,但是可能效果不如从头开始训练。
4.8 Adversarial Training
生成对抗网络目前比较火,典型GAN包括两个神经网络:生成网络和辨别网络。生成网络学习如何从latent space映射到感兴趣的特定分布,辨别网络用来判断instances,哪些是data distribution,哪些是生成器生成的。GAN目前也应用于目标检测方面,尤其是用来提升小目标和有遮挡目标的探测效果。
GAN用来提升小目标检测原理是,不断narrow the representations between small and largeones。提升遮挡物目标原理:通过对抗训练来生成遮挡物mask,对抗网络不会直接在像素空间生成遮挡的图片例子,而是直接修改特征(features)来模仿遮挡。
另一种叫做“adversarial attack”的方法也很流行,它旨在学习如何使用adversarial examples来攻击detector,这个对无人驾驶的测试尤为重要。
4.9 Weakly Supervised Object Detection
训练detector通常需要大量的人工标注data,费时费力。Weakly Supervised Object Detection (WSOD)旨在只通过image level annotations替代bounding box来对detector进行训练。
multi-instances learning用来WSOD,它是一组监督学习方法,与学习一组实例(每个被单独标注)不同,multi-instances learning model receive与一组labeled bags,每个都包含许多实例。如果我们将一幅图像中的候选目标视为bag,而将图像级注释视为label,则WSOD可以表述为多实例学习过程。
Class activation mapping(类激活映射) is another recently group of methods for WSOD。CNN的卷积层behaves类似detector,尽管它没有对目标位置的supervision。Class activation mapping使得CNN尽管在图像级别label进行训练,仍有定位的能力。
有一些研究者把WSOD当做是一个对proposal进行ranking的过程,选择最informative的区域,然后使用图像级的注释来训练这些区域。
WSOD的另一种简单方法是掩盖图像的不同部分。 如果检测分数急剧下降,则物体被覆盖的可能性很高。
此外,交互式注释在训练过程中考虑了人的反馈,从而改善了WSOD
目前,生成对抗训练也被用在了WSOD中。
5. APPLICATIONS
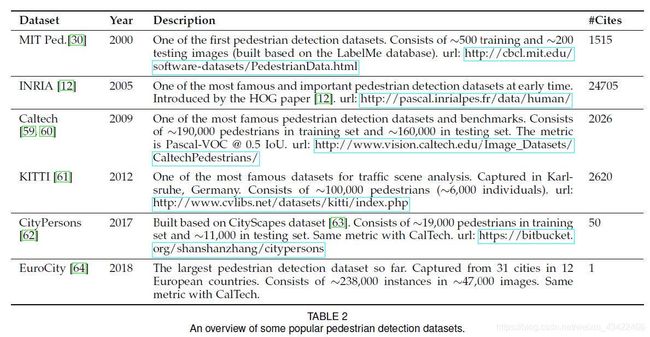
5.1 Pedestrian Detection
autonomous driving, video surveillance(视频监控), criminal investigation等多个领域都需要行人检测。从早期的HOG detector、ICF detector,到深度学习领域的Faster RCNN等,都推动了这个领域的发展。
5.1.1 Difficulties and Challenges
Small pedestrian
Hard negatives:一些街道的背景物外表与行人很相似。
Dense and occluded pedestrian(密集与遮挡的行人)
Real-time detection:无人驾驶和视频监控中很重要。

5.1.2 Literature Review
Traditional pedestrian detection methods
早期行人检测主要使用哈尔小波特征,“detection by components”是当时为了提升遮挡行人的检测效果而提出的一种方法:它把行人检测看作是许多个part detectors的集合,每个detector分别检测人身体的一部分。
2005年开始,梯度based方法以及DPM成为行人检测的主流。2009,Integral Channel Features (ICF)提出,它使用积分图像进行加速,是一种有效的lightweight feature,成为了新主流。
Deep learning based pedestrian detection methods
提升小的行人检测:传统深度学习detector对小目标效果不好,因为他们的feature分辨率较低。一些方法:特征融合、提出新的高分辨率人工特征、集合不同分辨率的检测结果…
improve hard negative detection:整合boosted decision tree、语义分割、跨模式学习(cross-modal learning,使用RGB和红外图像来enrich feature)
To improve dense and occluded pedestrian detection:如2.3.2中所说,CNN深层特征有丰富的语义,但是检测dense目标不是很有效,研究人员设计新的loss函数来同时考虑目标的吸引(attraction)和背景目标的排斥(repulsion)
part detectors的集合以及attention mechanism(注意机制)是解决遮挡目标的主要方法。
5.2 Face Detection
5.2.1 Difficulties and Challenges
Intra-class variation(类内变化):人类面部由于肤色、动作、表情、情绪有着很大的变化性。
Occlusion:面部可能会被部分遮挡
Multi-scale detection:小尺度的tiny faces,检测难度较大
Real-time detection:移动设备上的面部检测需要CPU的实时检测速度

5.2.2 Literature review
Early time’s face detection (before 2001)
早期人脸检测分为三种,1) Rule-based methods:对人类关于面部构成以及面部元素联系的知识进行编码;2) Subspace analysis-based methods(基于子空间分析):分析了基础线性子空间中的人脸分布,典型代表是Eigenfaces;3) Learning based methods:滑窗+二分类问题(目标/背景),典型有SVM、神经网络。
Traditional face detection (2000-2015)
这个阶段有两种人脸检测方法,第一种是基于boosted决策树,计算容易但是在复杂场景下检测准确率较低。第二种是基于早期的CNN,使用共享计算来加速。
Deep learning based face detection (after 2015)
To speed up face detection:使用级联检测(3.3节)来加速人脸detectors,另一种加速方式是预测图像中人脸的尺度分布(scale distribution),然后选择一些尺度进行检测过程。
To improve multi-pose and occluded face detection:使用“face calibration”来提升multi-pose 人脸检测,通过在多个检测阶段估计校准参数(calibration parameters),或使用progressive calibration。提升遮挡人脸检测,两种方法,一是使用注意机制“attention mechanism”,来highlight被遮挡的人脸特征,二是“detection based on parts”,继承自DPM
To improve multi-scale face detection:见2.3.2或4.2.2,进行多尺度特征融合、多分辨率检测。
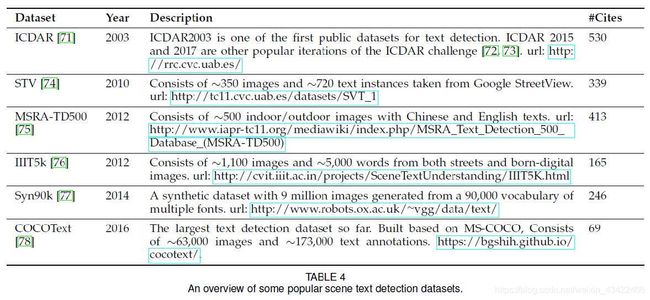
5.3 Text Detection
检测图片中是否有文字,如果有的话,定位并且识别它。
5.3.1 Difficulties and Challenges
Different fonts and languages:文字有不同语言、字体、颜色
Text rotation and perspective distortion(视角变形)
Densely arranged text localization
Broken and blurred characters

5.3.2 Literature Review
文本检测主要包含两个相关又相对独立的任务,文字定位+文字识别。
目前文本检测方法可分为两类:“step-wise detection” and “integrated detection”
Step-wise detection vs integrated detection
前者包含一系列的处理流程:字符分割,候选区域验证,字符分组和单词识别。这种方法的好处在于,大部分的背景信息在粗分割阶段已被过滤,大大减少计算量,缺点在于所有步骤的参数必须设计的很小心、巧妙,而且误差随着过程进行逐渐积累。
相反,后者把文本检测看作一个联合概率推断问题,上面的所有steps都在一个联合的框架下进行。因此避免了累计误差,并且很容易整合到language models中,缺点是数据量大时,计算量很大。
Traditional methods vs deep learning methods
大部分传统方法使用非监督方式生成text candidates,经常用的方法有Maximally Stable Extremal Regions (MSER) segmentation(最大稳定极值区域分割)以及形态学过滤(morphological filtering)。这些方法还考虑了一些领域知识,例如文本的对称性和笔画的结构。
近年来,相比如文本识别,研究者更注重于提升文本的定位,提出了两类方法。第一类把文本检测当作目标检测的一种特殊情况,但是使用现有的检测框架,针对文本的旋转和大的长宽比效果不好。另一类方法是把文本检测看作是图像分割问题,好处在于这对文本的形状和方向没有特别的限制,缺陷在于在密集的文本中,仅仅依靠分割结果很难将它们区分出来。
For text rotation and perspective changes:主要解决方法是为RoI Pooling层和anchor引入与旋转与视角有关的额外参数
To improve densely arranged text detection:基于分割的方法对于密集文本效果更好,提出了两类方法来解决相邻文本的却分问题。一是“segment and linking”,segment指的是character(字符)之间的分隔,link指的是不同segment之间的相连来表示它们属于同一个单词或同一行。第二类是引入额外的corner/border detection来帮助分离密集文本。
To improve broken and blurred text detection:主要是使用word level recognition and sentence level recognition。要解决不同字体的问题,最好方法是使用混合的合成samples进行训练。
5.4 Traffic Sign and Traffic Light Detection
5.4.1 Difficulties and Challenges
Illumination changes:光照的改变影响很大,太阳直射时和夜间完全不一样。
Motion blur(运动模糊):由于车在运动,车上的相机捕捉到的图像会模糊
Bad weather
Real-time detection:对于无人驾驶尤为重要

5.4.2 Literature Review
Traditional detection methods
因为交通标志、灯有着特殊的形状和颜色,传统检测方法通常基于颜色阈值、视觉显著性检测(visual saliency detection)、形态学滤波以及边缘/轮廓分析。由于上述方法都是基于浅层特征,环境复杂情况下容易失败,因此研究人员开始尝试寻找超越基于视觉的方法,比如在交通信号灯检测中综合GPS和电子地图。尽管“特征金字塔+滑窗”方法在那时已经成为目标检测的标准框架,但是交通标志检测没有follow。
Deep learning based detection methods
深度学习时代,Faster RCNN以及SSD等都被应用于交通标志检测,在这些基础上,注意机制、对抗学习等技术也用来提升复杂环境下的检测效果。
5.5 Remote Sensing Target Detection
5.5.1 Difficulties and Challenges
Detection in “big data”:由于遥感数据的数据量很大,如何快速准确的检测到遥感目标仍是一个问题。
Occluded targets:每天地球上超过50%的表面被云覆盖。
Domain adaptation:由不同的遥感传感器获得的遥感图像可能有很大不同。
5.5.2 Literature Review
[382] L. Zhang, L. Zhang, and B. Du, “Deep learning for remote sensing data: A technical tutorial on the state of the art,”
IEEE Geoscience and Remote Sensing Magazine, vol. 4, no. 2,pp. 22–40, 2016.
Traditional detection methods
大多数传统遥感目标检测都是two-stage :1) candidate extraction and 2) target verification
候选提取阶段,经常采用的方法是有,基于灰度值滤波方法、基于视觉显著性方法、小波变换方法、异常检测(anomaly detection)方法等。它们的共同点在于都是非监督方法,因此在复杂环境下经常失败。
目标verification阶段,通常采用HOG\LBP\SIFT等特征,还有一些基于滑窗的方法。
在一些任务中,也用到了domain knowledge。
提升遮挡目标的检测,使用“detection by parts”
检测不同方向的目标,使用“mixture model”来训练不同方向的的detectors
Deep learning based detection methods
由于遥感图像与日常图像有很大的不同,许多人研究了深层CNN特征在遥感目标的效果。人们发现,在某些特定的数据中,深层CNN并没有比传统方法取得更好的效果。为了检测不同方向的目标,研究人员改善了RoI pooling层来增强旋转不变性。为了改善domain adaptation,一些研究人员从贝叶斯观点出发制定了检测方法,即在检测阶段,该模型会根据测试图像的分布进行自适应更新。 此外,注意力机制和特征融合策略也已用于改善小目标检测。
6. CONCLUSION AND FUTURE DIRECTIONS
本文介绍了一些milestone detectors(e.g. VJ detector, HOG detector,
DPM, Faster-RCNN, YOLO, SSD, etc),关键技术、加速方法、目标监测的应用、数据集以及评价尺度,并且讨论了目前遇到的挑战,以及这些detectors未来如何发展改进,未来目标检测的研究将focus on但不仅限于以下几个方面:
Lightweight object detection:加速算法使其能够部署在移动设备上。
Detection meets AutoML:目前的detectors十分依赖之前的经验,未来发展方向是在设计model时减少人的干预(design engine,set anchor boxes)
Detection meets domain adaptation:目前detectors的训练过程仍被认为一种可能性估计的过程,训练data都假设为独立均匀分布,而真实世界中data是不均匀分布的,让存在挑战。GAN可能会很好的帮助解决。
Weakly supervised detection:训练通常需要大量标注好的图片,标注过程太耗时间。要发展弱监督方法,只用image-level 标注或一部分bounding box标注进行训练,减少人力花费,增强检测灵活性。
Small object detection:通过视觉注意机制的集成整合,以及设计高分辨率轻量级网络来实现。
Detection in videos:HD视频中的实时目标检测与跟踪在视频监控和无人驾驶中非常重要。传统方法只按照image-wise detection,忽略了视频帧之间的联系。探索时间与空间相关性来改善检测是重要的研究方向。
Detection with information fusion:具有多种数据源/模式的对象检测,比如RGB-D image, 3d point cloud, LIDAR等格式,这对于无人驾驶和无人机应用很重要。一些待解决的问题包括:如何将训练好的检测器迁移到不同的数据形式,如何进行信息融合以改善检测等。