pytorch图像分类篇:搭建VGG网络
model.py
import torch.nn as nn
import torch
# official pretrain weights
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
#定义VGG的类,继承于nn.moudel这个父类
class VGG(nn.Module):
#初始化函数(self,通过make_features(cfg: list)函数生成的提取特征网络结构,所需要分类的类别个数,是否对网络进行权重初始化)
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential( #生成分类网络结构
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),#50%的比例进行随机失活
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)#num_classes输出节点个数就是分类类别的个数
)
if init_weights:#是否需要对网络进行参数的初始化,若init_weights为True则进行初始化权重函数
self._initialize_weights()
#正向传播的过程
def forward(self, x):#x表示输入的图像数据
# N x 3 x 224 x 224
x = self.features(x) #将数据传入features结构得到输出x
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)#将输出进行展平处理,start_dim=1表示从哪个维度进行展平处理
# N x 512*7*7
x = self.classifier(x)#将特征矩阵输出的提前定义好的分类网络结构classifier函数中,得到输出
return x
#权重初始化函数
def _initialize_weights(self):
for m in self.modules(): #进行遍历网络的每一个字模块(每一层)
if isinstance(m, nn.Conv2d): #如果遍历的当前层是卷积层
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) #使用函数初始化卷积核的权重
if m.bias is not None: #如果卷积核使用了偏置的话
nn.init.constant_(m.bias, 0) #则把偏置默认初始化为0
elif isinstance(m, nn.Linear):#如果遍历的当前层是全连接层
nn.init.xavier_uniform_(m.weight)#使用函数初始化全连接层的权重
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)#则把偏置默认初始化为0
#提取生成特征网络
def make_features(cfg: list):#传入的是配置变量,是列表类型
layers = [] #定义空列表,用来存放每一层的结构
in_channels = 3 #由于输入的是彩色图片,定义输入通道为3
for v in cfg: #通过for循环来遍历配置列表
if v == "M": #如果当前的配置元素是一个M字符的话
layers += [nn.MaxPool2d(kernel_size=2, stride=2)] #表示该层是最大池化层,则创建一个最大池化下采样层
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) #创建一个卷积操作,stride默认是1,不需要写进去
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers) #利用nn.Sequential()函数通过非关键字的形式传进去
cfgs = {
#vgg11表示11层的网络,vgg16就是16层。。。。
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
#数字代表的是卷积层卷积核的个数,M表示是的是池化层的一个架构。
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
#定义vgg()函数,实例化给定的配置模型
def vgg(model_name="vgg16", **kwargs):#model_name表示需要实例化哪个配置
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name] #将配置传入字典,得到需要的配置列表
model = VGG(make_features(cfg), **kwargs)#通过VGG类进行实例化网络,**kwargs可变长度的字典变量
return model
train.py
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import vgg
"""
VGG网络训练的过程非常漫长,准确率达到了80%左右,若要使用VGG网络的话,可以使用迁移学习的方法去训练自己的样本集。
"""
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
#对训练集和测试集进行预处理操作
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),#随机裁剪
transforms.RandomHorizontalFlip(),#随机水平翻转
transforms.ToTensor(),#转化成tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),#进行标准化处理
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)#num_workers 表示使用的线程个数,window系统无法设置非0值,只能是0
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
model_name = "vgg16"
#实例化vgg网络的方法,调用model_name表示要使用哪一个VGG配置,分类的个数,是否进行初始化,最后会保存在**kwargs这个可变长度字典中
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
epochs = 30
best_acc = 0.0
save_path = './{}Net.pth'.format(model_name)
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import vgg
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = vgg(model_name="vgg16", num_classes=5).to(device)
# load model weights
weights_path = "./vgg16Net.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()

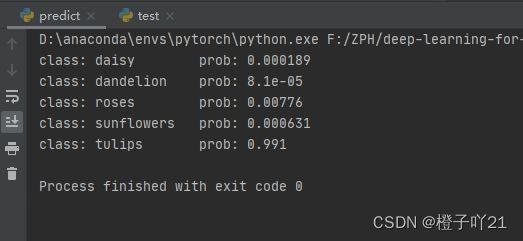
测试了一张郁金香的图片: