二手房数据分析预测系统
©作者 | leo
随着科技的进步,信息已经成为了推动科技发展的重要元素。通过对海量数据的分析能够更好的服务于未来的生产生活,并且能够及时调整策略,未雨绸缪。
今天我们为大家展示一个全方位,多维度的数据分析场景——二手房数据分析预测系统。该系统全面展示了数据分析过程中的数据获取,数据预处理,数据分析,可视化呈现以及分析结果的生成。
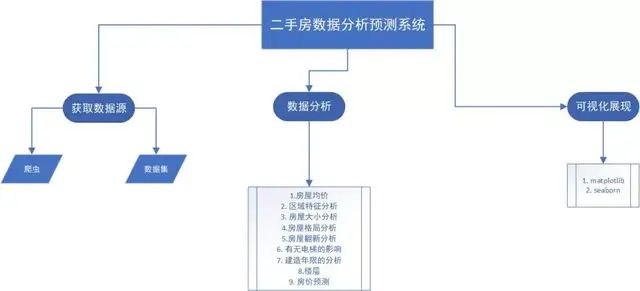
01 数据获取
数据获取的方式分为两种:可靠数据渠道采购和Python网络爬虫等技术手段实现。
数据集链接:
链接:
https://pan.baidu.com/s/1-rGGM6tuoDbxtaG9gV4B2w 提取码: ftvk
爬虫实现:主要通过requests库和xpath数据解析技术来提取相关字段数据。

02 数据载入
将上述提取到的信息进行数据整合:
2.1 导入相关的python包

2.2 加载数据

数据呈现:

查看数据的基本情况,这是做数据分析非常重要的一步,需要查看数据类型,数据缺失情况等等。


通过数据观察,可以发现Elevator(电梯)字段存在严重的数据缺失情况,Size字段也就是房屋大小里面的最大值和最小值出现了1019平米和2平米的面积,根据常识可以判断其中存在异常值。
但是电梯字段的缺失可能是信息未采集或者未上传导致的,我们可以暂时不做处理。对于面积过大的处理,我们在接下来的分析步骤中查看。
03 数据分析
3.1 添加房屋均价字段
该字段显示的是某区内的房屋每平米均价,能够为接下来的数据分析提供更多依据。


通过上述数据,可以发现ID字段对于分析没有意义,通过重排列名提取关键字段,房屋单价使用总价/平米数计算得来。
3.2 区域特征分析
区域特征主要使用了pandas中groupby方法对地区进行分类,然后分别计算得到不同地区的总价和单价的汇总信息,最终通过Seaborn库的柱状图和箱线图可视化展现并得出最终结论。


可视化代码:
最终输出图形:

分析结果综述:
a. 二手房均价(每平米):均价最高的城区是西城区,11万/平米,主要的原因是西城区是整个北京市区最为繁华的区域,同时是重点中学的集中地,因此房价最高比较合理;均价次之的区域是东城区,10万/平米,海淀区8.5万/平米,剩余地区均低于8万/平米。
b. 二手房数量:数量比较多的区域是海淀区和朝阳区,均接近3000套,丰台区紧随其后。
c. 二手房总价分布:通过箱线图,可以看出各区域的房价中位数主要集中在1000万以下,离散度比较高,西城区的最高离散值达到6000万,说明二手房总价数据分布并不理想。
3.3 房屋面积Size分析
通过直方图呈现房屋面积的分布状态,散点图来面描述房价和面积的相关性。

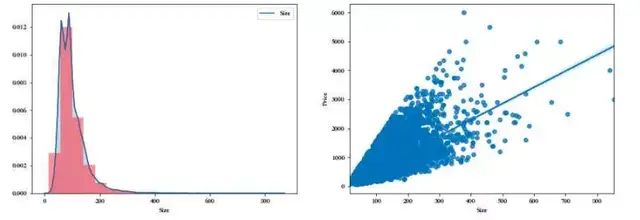
分析结果综述:
通过以上可视图可以发现,房屋尺寸类型主要集中在100平米左右,箱型图中的长拖尾现象说明了有少量大平米的户型分布,但是数量有限。
通过散点图的相关性展示,发现房价和面积基本呈现线性相关的关系,这点比较符合尝试,即面积越大、房价越高。
异常值分析:

通过上述表达式筛选,存在部分面积低于10平米但是卖价超过1000万的房屋。

对比头部数据:

对比两份数据,可以发现第一个结果集中的数据存在字段错位的情况,且查看房屋类别,小平米的房子多为别墅类型,不属于二手商品房分析范畴,因此可以删除这类数据。
通过如下表达式,发现存在少量大平米单价远低于市场价的房产。


进一步研究发现,该信息极有可能代表的是写字楼,也不再本次分析范畴,需要剔除,最后通过以下表达式实现以上数据的筛选。

重新做可视化分析:

如图所示,异常数据基本消失。
3.4 房屋格局分析
通过Seaborn计数图呈现不同户型房屋的数量分布情况。


分析结果:
主要的房屋类型依次是2室1厅,3室1厅,2室2厅,3室2厅。户型名称不具备规范性要求,不利于后续的机器学习使用,因此需要做特征化处理。
3.5 房屋翻新状态分析
使用value_counts()方法统计不同翻新状态的房屋数量:

使用计数图,条形图,箱线图对以上四种户型分别进行可视化呈现:



分析结果:
精装房二手房的数量最多,简装其次,价格方面,毛坯最贵,精装修次之。
3.6 是否有电梯分析
通过info()函数统计不同字段的数量、空值情况、数据类型,可以很快发现异常字段。
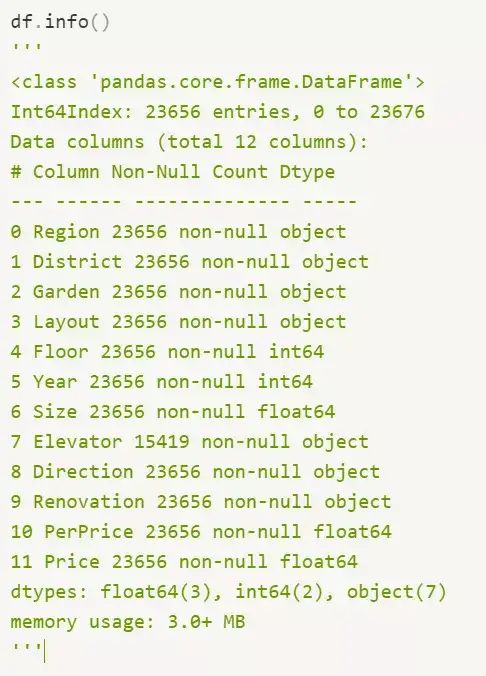
通过代码结果,发现电梯字段存在大量缺失值,可选方案如下:
a. 删除空值。
b. 替换,并使用填充值:中位数,平均值,拉格朗日插值等。
这里不能忽略一个简单常识,那就是楼层超过6层的肯定有电梯,6层以下则无,因此层数6可作为筛选条件,值得注意的是,如果使用Floor字段来进行判断,也可能出现问题,因为Floor代表楼层,而不是整楼,因此只能作为参考使用。

对电梯字段进行可视化呈现:

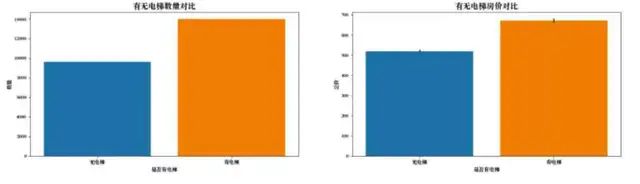
分析结果:
根据分析结果发现,有电梯的二手房数量比较多,主要原因是北京人多地少,高层楼房比较普遍。
3.7 建筑年份分析

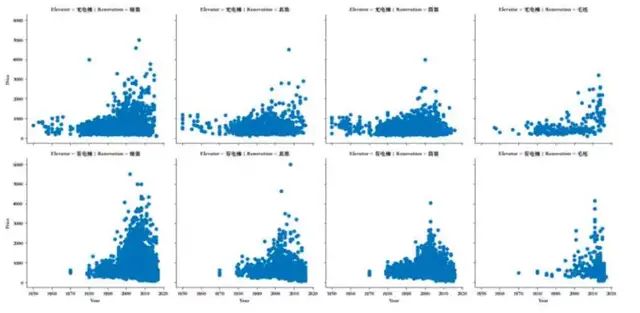
以翻新状态和有无电梯作为分类条件的情况下,使用FaceGrid分析年份特征,可得到如下结果:
a. 1980年前的二手房不存在有电梯的数据,说明在这个年代之前还没有大量安装电梯。
b. 整个二手房房价趋势随着时间增长而增长。
c. 2000年后的二手房房价相较于2000年之前的有明显的价格上涨。
3.8 楼层分析
通过计数图分析不同楼层的数量分布:

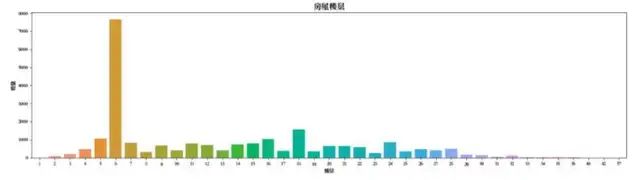
分析结果:
通过可视图发现,6层的二手房数量最多,但是并不能说明楼层对房价有太大的影响,楼层也需要结合一定的民间文化来做联系,俗语七上八下,可能七层更受欢迎,4层和18层一般不受欢迎,此外中高层房屋视野相对较好,因此价格相对较高。
3.9 房价预测
本例主要使用线性回归和随机森林两种模型进行了预测,限于篇幅,特征处理这里就不演示了。


运行结果:
线性回归的均方误差是5.87E8,R方得分0.482,随机森林三种分支模型R方得分均超过0.65,其中极端随机森林模型的预测能力最好,线性回归相较随机森林模型的预测能力明显偏下。
04 总结
本案例通过常见的数据分析方法对二手房数据进行了全面的数据分析和可视化展现,完整的体现了整个数据分析的流程,通过本案例能够掌握基础和经典python数据分析手段。
当然还有更多的分析维度可以添加,正在学习的你,是否跃跃欲试了呢?