【MIMIC-IV/pytorch实战】基于word2vec、transformer进行英文影像报告文本分类
完整流程可以分以下几步
- 数据整理
- word2vec
- 构建transformer模型
- 训练模型
- 测试模型
- 资源下载介绍
若懒得看程序,也可以直接下载全部程序,在最后一部分进行了资源的介绍。
【MIMIC-IV/pytorch实战】基于word2vec、transformer进行英文影像报告文本分类
数据整理
MIMIC-IV中的文本数据在MIMIC-CXR模块中,影像报告以txt格式储存,每份报告为一个txt文件,如下
 病人与报告之间通过一个cxr-study-list表相关,通过这张表我们可以获取报告对应病人的其他信息,如是否死亡、患病等情况作为标签。
病人与报告之间通过一个cxr-study-list表相关,通过这张表我们可以获取报告对应病人的其他信息,如是否死亡、患病等情况作为标签。
这部分程序主要完成两步,
- 一是通过疾病筛选患者,因为都是胸片报告,因此我筛选出肺癌患者
- 二是提取findings部分文本,并删除所有换行符,这步主要程序可见这篇博客: python导入txt文件并删除换行符并提取部分内容—MIMIC-IV/MIMIC-CXR文本报告预处理
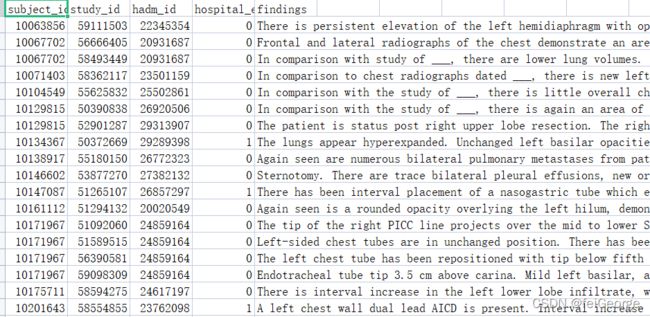
最终获得的文件如下图,标签为是否发生院内死亡。
word2vec
这部分是为了将文本转化成向量,以输入神经网络,主要分为以下几步
- 删除标点、分词
- 使用word2vec进行向量化,gensim库
- 形成可以输入神经网络的向量,embedding层
(新手仔细看,老手掠过下面这部分)
我们首先要明白,文本是如何输入到pytorch的神经网络中的。
文本需要形成一个词表,尽可能包含输入的所有词,每个词对应一个id,和一个vector。加入输入的是i love you,那么可以有如下一个表:
| id | word |
|---|---|
| 1 | i |
| 2 | love |
| 3 | you |
| 这样,输入的词就可以变成[1,2,3]这样一个由id构成的表 | |
| 放入pytorch 的embedding层中,便可以被转换为自定义维度的tensor。 | |
| 但这样获得的tensor通常是随机的,因此我们可以使用word2vec来定义每个词的向量。 | |
| 使用word2vec可以获得一个类似于下面这样的表。使用id-vec两列初始化embedding层,即可将每个词按这个表转化成tensor。 | |
| id | word |
| – | – |
| 1 | i |
| 2 | love |
| 3 | you |
| 下面放实战代码。 |
def tokenizer(ori_list): #去除标点符号,分词
SYMBOLS = re.compile('[\s;\"\",_().!?\\/\[\]]+')
new_list = []
for q in ori_list:
words = SYMBOLS.sub(' ',q).lower().strip() #符号换成空格
words = words.split(' ') #按空格分词
new_list.append(words)
return new_list
def word2vec_train(sentences,vector_size=64, min_count=1, negative=5, epochs=5, name="word2vec.model"): #输入,分词好的句子样本
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
model = Word2Vec(sentences, vector_size=vector_size, min_count=min_count, negative=negative, epochs=epochs)
# sentences = word2vec.Text8Corpus(sentences) # 一种输入数据的方法
#https://www.cnblogs.com/MaggieForest/p/13583447.html
model.save(name) #保存模型
if __name__ =="__main__":
findings = pd.read_csv(r"findings_list.csv") #study_list文件目录
label = findings['hospital_expire_flag']
text = list(findings['findings'])
name = "../saved_modal/word2vec.model" #word2vec保存名称
sentences = tokenizer(text)
word2vec_train(sentences,vector_size=64, min_count=1, negative=5, epochs=5, name=name)
这样就获得了一个word2vec模型,这个模型本质上可以理解为一个包含id、word、vec的表。通常,这个模型需要大规模语料库进行训练。
下面,就要利用这个表初始化embeding层,并将每个句子形成一个tensor,初始话embeding的表是一个array形式的,一列是id,一列是vec。因为不是每个词都有相对应的vec,也不是每个句子都有同样多的词。因此,在此表中加入一个pading(全0向量)补全全短的句子,加入全1向量用于此表中没有的词。
def get_index(sentence): #将样本中的词替换为id
sequence = []
for word in sentence:
try:
sequence.append(word2id[word]+2) # +2 是因为加了pading和unknow
except KeyError:
sequence.append(1) # 匹配不到的 给id=1
return sequence
def get_tensor(data,w2v_model):
global word2id
word2id = w2v_model.wv.key_to_index #获取词-id表
X_data = list(map(get_index, data))
X_pad = pad_sequences(X_data, maxlen=None,padding='post') # 短的都补0
X_data_tensor = torch.tensor(X_pad) # 形成tensor
return X_data_tensor
def get_weight(w2v_model): #获取初始化embedding层的表
id2vec = w2v_model.wv.vectors #获取id-embedding表
id2vec = np.insert(id2vec, 0, values=np.zeros(id2vec.shape[1]), axis=0) # pading掉的id为0,向量为 全0
id2vec = np.insert(id2vec, 1, values=np.ones(id2vec.shape[1]), axis=0) # 匹配不到的id为1 , 向量为 全1
weight = torch.from_numpy(id2vec)
return weight
if __name__ == '__main__':
train_data, train_label,test_data, test_label = pro(path=r"../data/findings_list.csv",seed=2,rat=0.7)
w2v_model = Word2Vec.load("../saved_model/word2vec.model")
X_data_tensor = get_tensor(train_data,w2v_model)
最后形成的X_data_tensor,是将词替换成id的形式。
使用一个embedding进行测试,将id2embed词表初始化embedding层,获得的a向量即为将所有id替换成向量的结果,这个embedding层放入神经网络中即可。
weight = torch.from_numpy(id2embed)
a = nn.Embedding.from_pretrained(weight,freeze=True)(X_data_tensor)
构建transformer模型
transformer模型的构建仅使用了transformer的encoder部分,参考ViT的结构,完整ViT的实现可以参考这篇博客
Vision Transformer(ViT)PyTorch代码全解析(附图解)
在次基础上去掉了图像编码的部分,加入了文字的embedding层,及将前面获得的id转化为相对应的向量。
class ViT(nn.Module):
def __init__(self, id2vec, num_classes, dim, depth, heads, mlp_dim, pool, dim_head, dropout = 0., emb_dropout=0. ):
super().__init__()
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.word_embeds = nn.Embedding.from_pretrained(id2vec,freeze=True) #加入这一层,将词的id转化为向量,freeze冻结此层
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout) #dim:输入每个特征维度,dim_head,q和k维度
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes),
nn.LogSoftmax(dim=1)
)
def forward(self, x): #b为批大小,x(batch,feature_n) x为word对应的id,在embeding层之后才变成(batch,feature_n, dim)
x = self.word_embeds(x)
b,c,d =x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
# x = torch.unsqueeze(x, 2) #输入特征是1维的,所以要增添这一维度,否则不用
x = torch.cat((cls_tokens, x), dim=1) #(1, 65, 1024) 65:加cls之后的feature数,1024是每个特征的维度
x += nn.Parameter(torch.randn(1, c+1, d))[:, :(c+1)] #加位置编码
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
另外,最后一层输入分类概率,原博客使用的是linear层,这样可以根据两类值的大小判断分类。但我想计算AUC,需要知道分类为1的概率,因此需要加入softmax层。但如果我在测试时使用nn.CrossEntropyLoss()当损失函数,就会重复softmax。
因为nn.CrossEntropyLoss()相当于softmax+log+NLLLoss,也就相当于logSoftmax+NLLLoss,所以我加了一层logSoftmax,并用NLLLoss作为损失函数进行训练。
这样模型就可以输出分类的概率,并且在训练时依旧相当于使用了CrossEntropyLoss()交叉熵损失函数。
这部分借鉴了以下两篇博客
- pytorch损失函数之nn.CrossEntropyLoss()【内含softmax推导】
- Pytorch中Softmax、Log_Softmax、NLLLoss以及CrossEntropyLoss的关系与区别详解
训练模型
训练函数代入了搭建的模型,可以更改模型中的各个参数
def train_ViT(
id2vec, #id2vec词表
train_data, #训练数据
train_label, #训练标签
num_classes, #分类数量
num_epochs, #训练轮数
batch_size, #批大小
learning_rate, #学习率
dim = 1 , #每个特征的维度
depth= 1, #encoder层数
heads=1, #注意力头数
mlp_dim=32, #encoder MLP 输出
pool = 'cls', #分类方式 cls mean
dim_head = 32, #注意力输出向量维度
dropout = 0., #transformer里的
emb_dropout = 0. #emb的
):
torch_dataset = Data.TensorDataset(train_data, train_label)
loader = Data.DataLoader( #批训练数据加载器
dataset=torch_dataset,
batch_size=batch_size,
shuffle=True, # 每次训练打乱数据, 默认为False
num_workers=0, # 使用多进行程读取数据, 默认0,为不使用多进程
drop_last=False
)
# 构造vit模型
model = allmodel.ViT(id2vec, num_classes, dim, depth, heads, mlp_dim, pool , dim_head , dropout , emb_dropout )
print(model)
model.train()
# Loss and optimizer
criterion = nn.NLLLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
total_step = math.ceil(len(train_data)/batch_size)
for epoch in range(num_epochs):
for i, (input_data, labels) in enumerate(loader):
# 前向传播
outputs = model(input_data)
loss = criterion(outputs, labels.long())
# 后向优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每一百步打印一次
if (i + 1) % 10 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch + 1, num_epochs, i + 1, total_step, loss.item()))
print("ViT训练完毕")
# 保存训练完的模型
torch.save(model, '../saved_model/ViT.pth')
测试模型
def test_ViT(test_data, test_label):
model = torch.load('../saved_model/ViT.pth')
model.eval()
with torch.no_grad():
outputs = model(test_data)
predict_rate = outputs[:, 1]
_, predicted = torch.max(outputs.data, 1)
predicted = predicted.numpy()
labels = test_label.numpy()
Acc = metrics.accuracy_score(labels, predicted)
Precision = metrics.precision_score(y_true = labels, y_pred = predicted, zero_division=0)
Auc = metrics.roc_auc_score(labels, predict_rate)
F1 = metrics.f1_score(labels, predicted)
Recall = metrics.recall_score(labels, predicted)
print('Acc: {} %, Auc: {} %, Pre: {} %, F1: {} %, Recall: {} %'.format(100 * Acc,
100 * Auc, 100 * Precision, 100 * F1 , 100 * Recall ))
资源下载介绍
若懒得看以上内容,可以下载资源
【MIMIC-IV/pytorch实战】基于word2vec、transformer进行英文影像报告文本分类
提示,本资源仅为demo,为经过深度调试。在搭建时为了节约时间,仅使用了少量数据进行训练和测试。在应用时,请自行增加数据量,并根据需要更改模型结构。
本资源包括三个文件夹
- data文件夹中包括三个文件,其中findings_list为直接应用于程序的数据,其他是在预处理是产生的数据。

- saved_model文件夹中包含训练产生的word2vec和transformer模型。
- code文件夹中包含所有程序代码
main 可以直接运行,完成word2vec和transformer模型的训练与测试
提取文本代码用于从数据库中提取文本,得到findings_list文件
data_processing用于划分训练集测试集并进行分词
word2vec用于训练word2vec模型
embedding用于根据word2vec产生词表和产生可输入模型的tensor
allmodel用于搭建transformer
train 用于训练模型
test_model用于测试模型
