Bert总结
Bert总结
文章目录
- Bert总结
- 前言
- 一、自监督学习
- 二、Bert
-
- 1.Masked LM
- 2.Next Sentence Prediction(NSP)
- 三、Bert的使用
-
- 1.输入是一个序列 输出是一个类别(情感分析)
- 2.输入一个序列 输出另一个序列且长度一样(词性标注)
- 3.输入两个句子,输入一个类别(NLI自然语言推断)
- 4.QA问题
- 四、Bert为什么有用(可能不严谨)
- 五、芝麻街系列的自监督模型
-
- 1.ELMO
- 2.Bert
- 3.ERNIE
- 3.Spanbert
前言
该篇博客是笔者学习李宏毅老师课程后所写的学习笔记,如文中有错误,感谢大家指正
笔者学习了李宏毅老师的Bert讲解和李沐老师对论文的精讲,相比之下李宏毅老师的课程更加容易理解,通过观看视频能知道Bert能完成什么任务,而学习李沐老师的论文精讲能对一些细节有更好的掌握
Bert模型是以transformer模型为基础的,在此放上笔者学习transformer模型的笔记,希望对学习Bert模型同学有帮助
学习李沐老师论文精读后批注的论文如下:
https://pan.baidu.com/s/1gF11XwtNOn8DZsnqrKzc4A?pwd=mmo8
提取码:mmo8
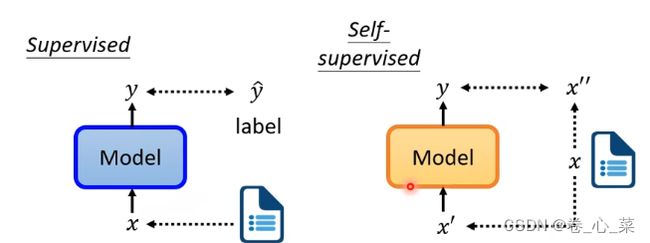
一、自监督学习
传统的监督学习的方式是将数据集和标签一起给模型,模型通过预测并和标签比对从而完成学习并修正的过程。而自监督的学习的工作方式与之不同,自监督学习只提供数据,而不给标签。例如在文本分类任务中,将一批文章送给模型,要将其分为两部分,让一部分作为模型的输入,另一部分作为模型的label。
二、Bert
Bert是一个预训练模型,对与一个具体的下游任务,可以将预训练好多Bert加上一下线性变换层,对具体数据再进行训练做参数微调,从而达到更好的效果。Bert模型的输入为一排向量,输出是一排长度与输入相同的向量。其架构是一个transformer的encoder ,因为没有decoder的部分,Bert不太擅长做seq2seq的任务 。
Bert模型完成的任务有两个,一个是将给输入的一个句子中某个字盖住,然后让模型通过前后文预测出这个字;第二个任务是给Bert一次输入两个句子,让模型来判断他们是不是连在一起的。下面我们来分别介绍这两件任务。
1.Masked LM
Bert的Masking input会随机的盖住输入序列中的一些字,然后一部分将它换成[MASK],另一部分随机换成另一个字。(与李沐老师讲解原论文有区别,应该是三种方法,细节见论文)。盖住的部分对应的输出对他做一个线性变换(和矩阵相乘,再softmax),然后输出概率最大的字。
注意:Bert模型本身是不知道盖住的字是什么,但通过是看未盖住输入是能知道盖住了什么,所以训练是要让Bert的预测更接近盖住的这个概率更大,在训练的过程中 encoder 和linear是一起训练的。

2.Next Sentence Prediction(NSP)
Bert能做的第二个事是输入两个句子,判断它们是否是相连的(现在很多论文说这个功能作用不大)。
输入第一个句子前先输入[CLS]作为开始的标记,在两个句子间用[SEQ进行]分割。两个句子一起送入bert,只看[CLS]对应的输出,把它的输出做线性变化进行二元分类,分类结果为yes和no,预测两个句子是不是相接的。

三、Bert的使用
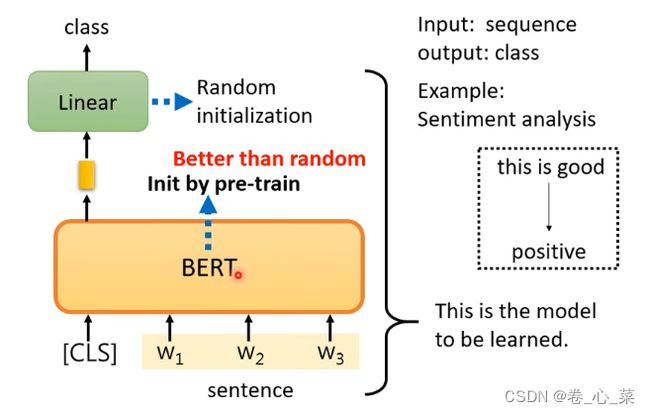
1.输入是一个序列 输出是一个类别(情感分析)
在该应用中,输入是一个句子(前面有[CLS]),每个输入都会对应一个输出,但是只看cls的输出经过线性变化的结果。
注意:此时是利用Bert进行下游任务的学习,此时的输出是需要标签的。 Bert和linear部分一起构成这个模型。在进行参数初始化时,linear的参数是随机初始化,Bert的初始化参数是预训练的参数。
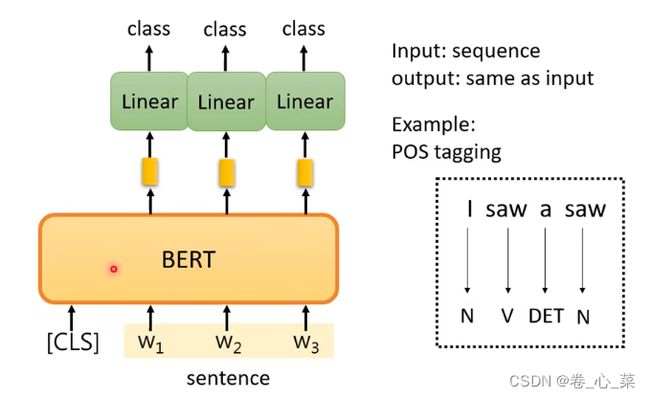
2.输入一个序列 输出另一个序列且长度一样(词性标注)
每一个输入都有一个输出向量与之对应,对每个向量分别进行线性变换从而得到每个词的词性(忽略[CLS]),训练方式与上述相同。
3.输入两个句子,输入一个类别(NLI自然语言推断)
输入的两个句子一个是前提 另一个是假设,输出这两个句子的关系,在这个问题中只看cls的部分做线性变换
4.QA问题
例如一个问答系统,输入是给一篇文章和一个问题,输出是这个问题的答案(限制:答案一定在文中)
文章和问题都是序列,他们的输出是两个正整数s和e,从s开始到e,串起来就是答案。
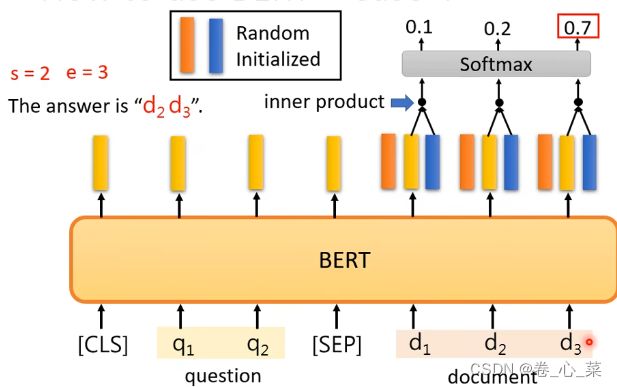
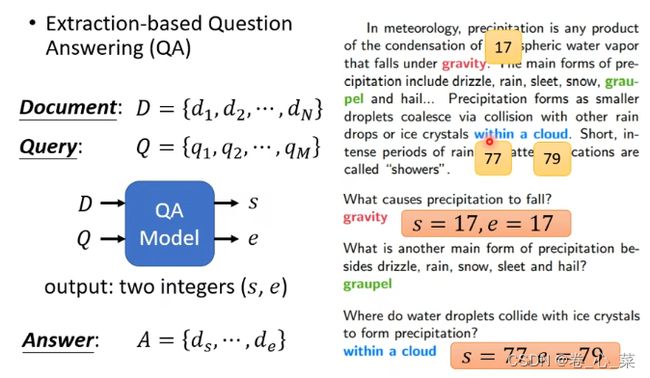 在这个任务的训练中,要训练的只有两个向量,它们的维数和Bert中一个输入的维度是相同的,
在这个任务的训练中,要训练的只有两个向量,它们的维数和Bert中一个输入的维度是相同的,
把文章的每个输出拿出来和橙色做内积,然后softamx,把分数最高的就让s等于他,然后蓝色的再做一遍,最后输出的就是答案开始到结束位置的索引下标。
四、Bert为什么有用(可能不严谨)
Bert的输入是一串向量,输出词嵌入的embedding向量,而这个向量代表的就是这个字的意思,意思相近的空间距离会接近。因为Bert是根据上下文判断,同一个字意思不同的话,他们的向量也会不同。
例如:句子1:这个苹果真好吃;句子2:苹果手机出新款了
两个句子中都有苹果这个词,但显然他们的意思是不同的,而Bert可以识别出它们之间的不同。
五、芝麻街系列的自监督模型
该部分李宏毅老师也只是简单介绍模型完成的任务
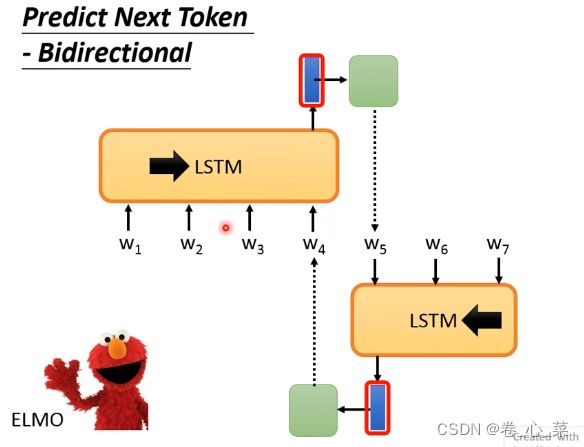
1.ELMO
是一个双向的LSTM网络,一个从前向后产生,另一个从后向前,所以一个网络生成结果的前一半,另一个生成结果的后一半
2.Bert
见本文第二部分
3.ERNIE
一次盖住一整个词,而不是一个字,然后将这个词预测出来
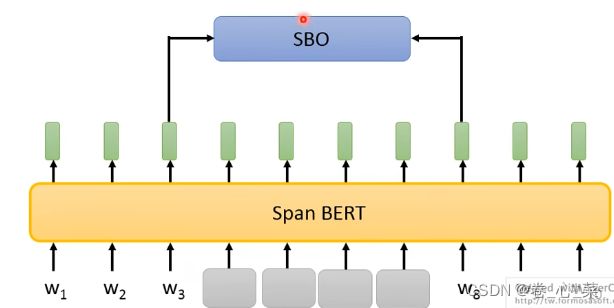
3.Spanbert
一次盖出一排的字,盖住不同的长度会有不同的效果
SBO训练方法:根据被盖住范围左右的输出,去预测被盖住地方的输出